python rabbitmq实现简单/持久/广播/组播/topic/rpc消息异步发送可配置Django
windows首先安装rabbitmq 点击参考安装
1、环境介绍
Python 3.10.16
其他通过pip安装的版本(Django、pika、celery这几个必须要有最好版本一致)
amqp 5.3.1
asgiref 3.8.1
async-timeout 5.0.1
billiard 4.2.1
celery 5.4.0
click 8.1.7
click-didyoumean 0.3.1
click-plugins 1.1.1
click-repl 0.3.0
colorama 0.4.6
Django 4.2
dnspython 2.7.0
eventlet 0.38.2
greenlet 3.1.1
kombu 5.4.2
pika 1.3.2
pip 24.2
prompt_toolkit 3.0.48
python-dateutil 2.9.0.post0
redis 5.2.1
setuptools 75.1.0
six 1.17.0
sqlparse 0.5.3
typing_extensions 4.12.2
tzdata 2024.2
vine 5.1.0
wcwidth 0.2.13
wheel 0.44.0
2、创建Django 项目
django-admin startproject django_rabbitmq
3、在setting最下边写上
# settings.py guest:guest 表示的是你安装好的rabbitmq的登录账号和密码
BROKER_URL = 'amqp://guest:guest@localhost:15672/'
CELERY_RESULT_BACKEND = 'rpc://'
4.1 简单模式
4.1.1 在和setting同级的目录下创建一个叫consumer.py的消费者文件,其内容如下:
import pikadef callback(ch, method, properties, body):print(f"[x] Received {body.decode()}")def start_consuming():# 创建与RabbitMQ的连接connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()# 声明一个队列channel.queue_declare(queue='hello')# 指定回调函数channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)print('[*] Waiting for messages. To exit press CTRL+C')channel.start_consuming()if __name__ == "__main__":start_consuming()
4.1.2 在和setting同级的目录下创建一个叫producer.py的生产者文件,其内容如下:
import pikadef publish_message():# message = request.GET.get('msg')# 创建与RabbitMQ的连接connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()# 声明一个队列channel.queue_declare(queue='hello')# 发布消息message = "Hello World!"channel.basic_publish(exchange='', routing_key='hello', body=message)print(f"[x] Sent '{message}'")# 关闭连接connection.close()if __name__ == "__main__":publish_message()
4.1.3 先运行消费者代码(consumer.py)再运行生产者代码(producer.py)
先:python consumer.py
再: python producer.py
4.1.4 运行结果如下:


4.2 消息持久化模式
4.2.1 在和setting同级的目录下创建一个叫recv_msg_safe.py的消费者文件,其内容如下:
import time
import pikadef callback(ch, method, properties, body):print(" [x] Received %r" % body)time.sleep(20)print(" [x] Done")# 下边这个就是标记消费完成了,下次在启动接受消息就不用从头开始了,即# 手动确认消息消费完成 和auto_ack=False 搭配使用ch.basic_ack(delivery_tag=method.delivery_tag) # method.delivery_tag就是一个标识符,方便找对人def start_consuming():# 创建与RabbitMQ的连接connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()# 声明一个队列channel.queue_declare(queue='hello2', durable=True) # 若声明过,则换一个名字# 指定回调函数channel.basic_consume(queue='hello2',on_message_callback=callback,# auto_ack=True # 为true则不能持久话消息,即消费者关闭后下次收不到之前未收取的消息auto_ack=False # 为False则下次依然从头开始收取消息,直到callback函数调用完成)print('[*] Waiting for messages. To exit press CTRL+C')channel.start_consuming()if __name__ == "__main__":start_consuming()4.2.2 在和setting同级的目录下创建一个叫send_msg_safe.py的生产者文件,其内容如下:
import pikadef publish_message():# 创建与RabbitMQ的连接connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()# 声明一个队列 durable=True队列持久化channel.queue_declare(queue='hello2', durable=True)channel.basic_publish(exchange='',routing_key='hello2',body='Hello World!',# 消息持久话用,主要用作宕机的时候,估计是写入本地硬盘了properties=pika.BasicProperties(delivery_mode=2, # make message persistent))# 关闭连接connection.close()if __name__ == "__main__":publish_message()4.2.3 先运行消费者代码(recv_msg_safe.py)再运行生产者代码(send_msg_safe.py) 执行结果如下:
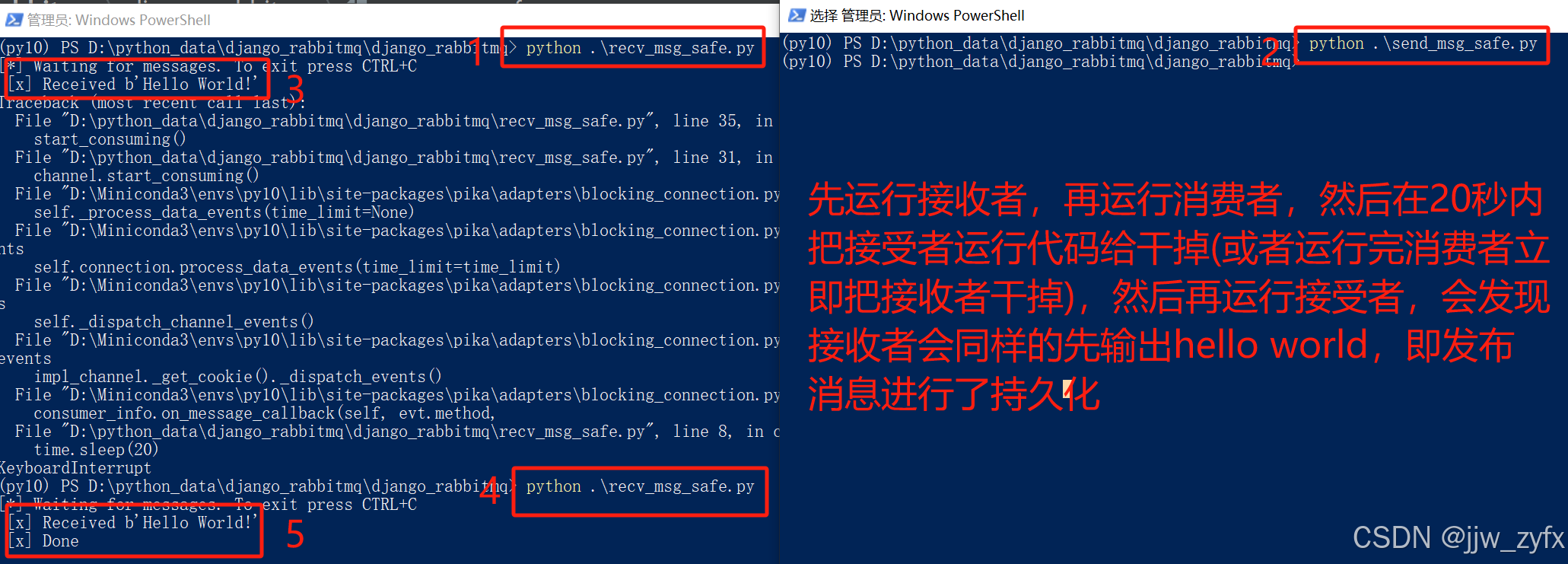
4.3 广播模式
4.3.1 在和setting同级的目录下创建一个叫fanout_receive.py的消费者文件,其内容如下:
# 广播模式
import pika# credentials = pika.PlainCredentials('guest', 'guest')
# connection = pika.BlockingConnection(pika.ConnectionParameters(
# host='localhost', credentials=credentials))
# 在setting中如果不配置BROKER_URL和CELERY_RESULT_BACKEND的情况下请使用上边的代码
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout') # 指定发送类型
# 必须能过queue来收消息
result = channel.queue_declare("", exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name) # 随机生成的Q,绑定到exchange上面。
print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r" % body)channel.basic_consume(on_message_callback=callback, queue=queue_name, auto_ack=True)
channel.start_consuming()4.3.2 在和setting同级的目录下创建一个叫fanout_send.py的生产者文件,其内容如下:
# 通过广播发消息
import pika
import sys# credentials = pika.PlainCredentials('guest', 'guest')
# connection = pika.BlockingConnection(pika.ConnectionParameters(
# host='localhost', credentials=credentials))
# 在setting中如果不配置BROKER_URL和CELERY_RESULT_BACKEND的情况下请使用上边的代码
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout') #发送消息类型为fanout,就是给所有人发消息# 如果等于空,就输出hello world!
message = ' '.join(sys.argv[1:]) or "info: Hello World!"channel.basic_publish(exchange='logs',routing_key='', # routing_key 转发到那个队列,因为是广播所以不用写了body=message)print(" [x] Sent %r" % message)
connection.close()
4.3.3 先运行消费者代码(fanout_receive.py)再运行生产者代码(fanout_send.py) 执行结果如下:

4.4 组播模式
4.4.1 在和setting同级的目录下创建一个叫direct_recv.py的消费者文件,其内容如下:
import pika
import syscredentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))channel = connection.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queueseverities = sys.argv[1:] # 接收那些消息(指info,还是空),没写就报错
if not severities:sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) # 定义了三种接收消息方式info,warning,errorsys.exit(1)for severity in severities: # [error info warning],循环severitieschannel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=severity) # 循环绑定关键字
print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(on_message_callback=callback, queue=queue_name,)
channel.start_consuming()
4.4.2 在和setting同级的目录下创建一个叫direct_send.py的生产者文件,其内容如下:
# 组播
import pika
import syscredentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))channel = connection.channel()channel.exchange_declare(exchange='direct_logs',exchange_type='direct') #指定类型severity = sys.argv[1] if len(sys.argv) > 1 else 'info' #严重程序,级别;判定条件到底是info,还是空,后面接消息message = ' '.join(sys.argv[2:]) or 'Hello World!' #消息channel.basic_publish(exchange='direct_logs',routing_key=severity, #绑定的是:error 指定关键字(哪些队列绑定了,这个级别,那些队列就可以收到这个消息)body=message)print(" [x] Sent %r:%r" % (severity, message))
connection.close()
4.4.3 先运行消费者代码(direct_recv.py)再运行生产者代码(direct_send.py) 执行结果如下:
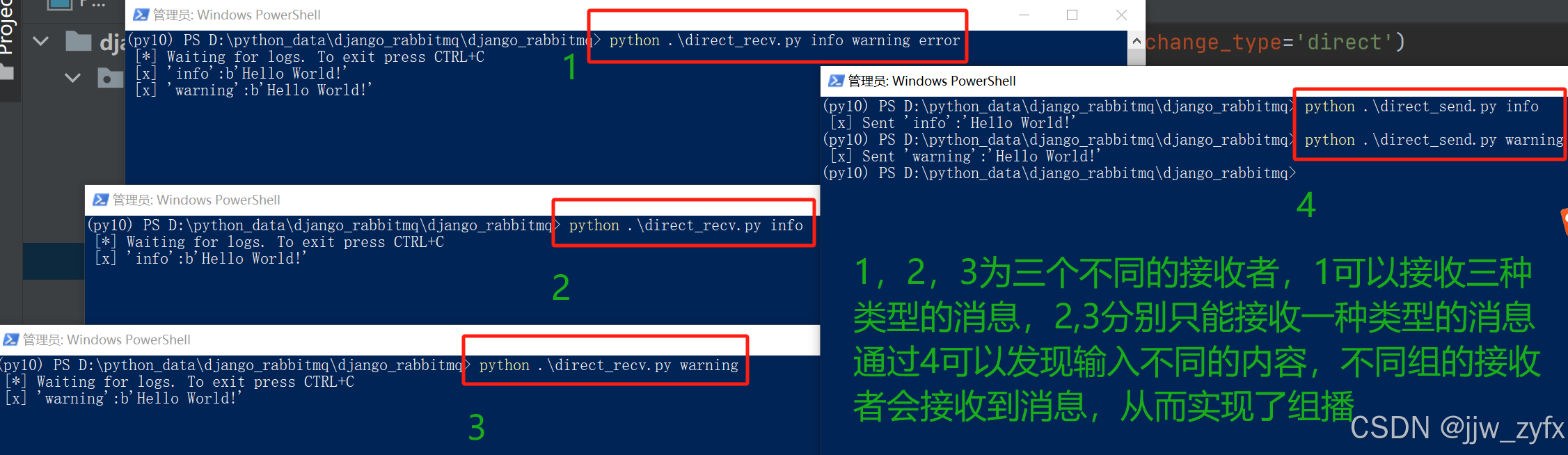
4.5 更细致的topic模式
4.5.1 在和setting同级的目录下创建一个叫topic_recv.py的消费者文件,其内容如下:
import pika
import syscredentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',exchange_type='topic')result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queuebinding_keys = sys.argv[1:]
if not binding_keys:print("sys.argv[0]", sys.argv[0])sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])sys.exit(1)for binding_key in binding_keys:channel.queue_bind(exchange='topic_logs',queue=queue_name,routing_key=binding_key)print(' [*] Waiting for logs. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] %r:%r" % (method.routing_key, body))channel.basic_consume(on_message_callback=callback,queue=queue_name)channel.start_consuming()
4.5.2 在和setting同级的目录下创建一个叫topic_send.py的生产者文件,其内容如下:
import pika
import syscredentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))channel = connection.channel()channel.exchange_declare(exchange='topic_logs',exchange_type='topic') #指定类型routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'message = ' '.join(sys.argv[2:]) or 'Hello World!' #消息channel.basic_publish(exchange='topic_logs',routing_key=routing_key,body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
4.5.3 先运行消费者代码(topic_recv.py)再运行生产者代码(topic_send.py) 执行结果如下:
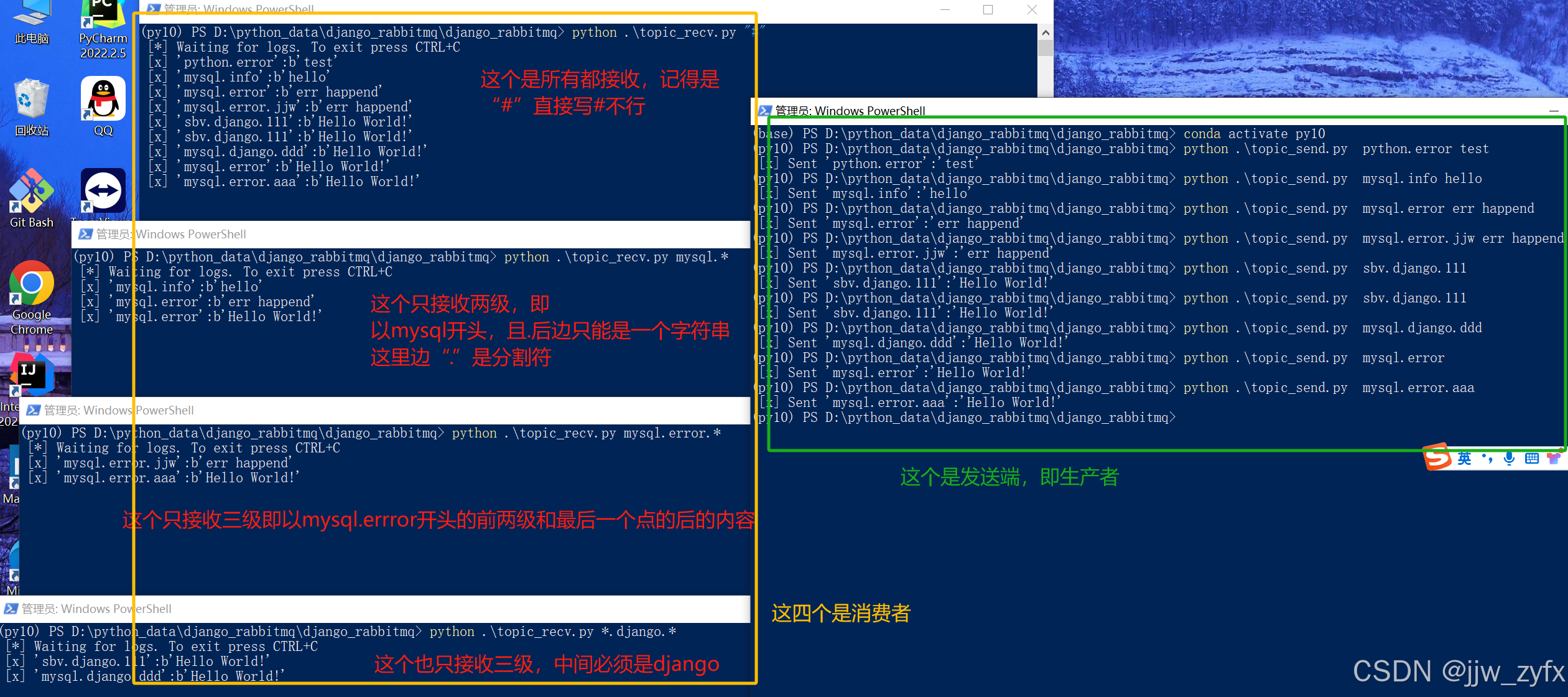
4.6 Remote procedure call (RPC) 双向模式
4.6.1 在和setting同级的目录下创建一个叫rpc_client.py的消费者文件,其内容如下:
import pika
import uuid
import time# 斐波那契数列 前两个数相加依次排列
class FibonacciRpcClient(object):def __init__(self):# 赋值变量,一个循环值self.response = None# 链接远程# self.connection = pika.BlockingConnection(pika.ConnectionParameters(# host='localhost'))credentials = pika.PlainCredentials('guest', 'guest')self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))self.channel = self.connection.channel()# 生成随机queueresult = self.channel.queue_declare("", exclusive=True)# 随机取queue名字,发给消费端self.callback_queue = result.method.queue# self.on_response 回调函数:只要收到消息就调用这个函数。# 声明收到消息后就 收queue=self.callback_queue内的消息 准备接受命令结果self.channel.basic_consume(queue=self.callback_queue,auto_ack=True, on_message_callback=self.on_response)# 收到消息就调用# ch 管道内存对象地址# method 消息发给哪个queue# body数据对象def on_response(self, ch, method, props, body):# 判断本机生成的ID 与 生产端发过来的ID是否相等if self.corr_id == props.correlation_id:# 将body值 赋值给self.responseself.response = bodydef call(self, n):# 随机一次唯一的字符串self.corr_id = str(uuid.uuid4())# routing_key='rpc_queue' 发一个消息到rpc_queue内self.channel.basic_publish(exchange='',routing_key='rpc_queue',properties=pika.BasicProperties(# 执行命令之后结果返回给self.callaback_queue这个队列中reply_to=self.callback_queue,# 生成UUID 发送给消费端correlation_id=self.corr_id,),# 发的消息,必须传入字符串,不能传数字body=str(n))# 没有数据就循环收while self.response is None:# 非阻塞版的start_consuming()# 没有消息不阻塞 检查队列里有没有新消息,但不会阻塞self.connection.process_data_events()print("no msg...")time.sleep(0.5)return int(self.response)# 实例化
fibonacci_rpc = FibonacciRpcClient()response = fibonacci_rpc.call(5)
print(" [.] Got %r" % response)
4.6.2 在和setting同级的目录下创建一个叫rpc_server.py的生产者文件,其内容如下:
#_*_coding:utf-8_*_
import pika
import time
# 链接socket
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))channel = connection.channel()# 生成rpc queue 在这里声明的所以先启动这个
channel.queue_declare(queue='rpc_queue')# 斐波那契数列
def fib(n):if n == 0:return 0elif n == 1:return 1else:return fib(n-1) + fib(n-2)# 收到消息就调用
# ch 管道内存对象地址
# method 消息发给哪个queue
# props 返回给消费的返回参数
# body数据对象
def on_request(ch, method, props, body):n = int(body)print(" [.] fib(%s)" % n)# 调用斐波那契函数 传入结果response = fib(n)ch.basic_publish(exchange='',# 生产端随机生成的queuerouting_key=props.reply_to,# 获取UUID唯一 字符串数值properties=pika.BasicProperties(correlation_id=props.correlation_id),# 消息返回给生产端body=str(response))# 确保任务完成# ch.basic_ack(delivery_tag = method.delivery_tag)# 每次只处理一个任务
# channel.basic_qos(prefetch_count=1)
# rpc_queue收到消息:调用on_request回调函数
# queue='rpc_queue'从rpc内收
channel.basic_consume(queue="rpc_queue",auto_ack=True,on_message_callback=on_request)
print(" [x] Awaiting RPC requests")
channel.start_consuming()
4.6.3 先运行消费者代码(rpc_server.py)再运行生产者代码(rpc_client.py) 执行结果如下:

参考实现1
参考实现2
参考实现3
相关文章:
python rabbitmq实现简单/持久/广播/组播/topic/rpc消息异步发送可配置Django
windows首先安装rabbitmq 点击参考安装 1、环境介绍 Python 3.10.16 其他通过pip安装的版本(Django、pika、celery这几个必须要有最好版本一致) amqp 5.3.1 asgiref 3.8.1 async-timeout 5.0.1 billiard 4.2.1 celery 5.4.0 …...

构建高性能异步任务引擎:FastAPI + Celery + Redis
在现代应用开发中,异步任务处理是一个常见的需求。无论是数据处理、图像生成,还是复杂的计算任务,异步执行都能显著提升系统的响应速度和吞吐量。今天,我们将通过一个实际项目,探索如何使用 FastAPI、Celery 和 Redis …...

永磁同步电机无速度算法--全阶滑模观测器
一、原理介绍 在采用传统滑模观测器求取电机角度时通常存在系统抖振、低通滤波器导致角度相位滞后、角度的求取等问题。针对上述问题,本文采用全阶滑模观测器,该全阶滑模观测器具有二阶低通滤波器的特性,能有效滤除反电动势中的高频噪声&…...

部署开源大模型的硬件配置全面指南
目录 第一章:理解大型模型的硬件需求 1.1 模型部署需求分析 第二章:GPU资源平台 2.1 免费GPU资源 2.1.1 阿里云人工智能PAI 2.1.2 阿里天池实验室 2.1.3 Kaggle 2.1.4 Google Colab 2.2 付费GPU服务 2.2.1 AutoDL 2.2.2 Gpushare Cloud 2.2.3 Featurize 2.2.4 A…...

三、使用langchain搭建RAG:金融问答机器人--检索增强生成
经过前面2节数据准备后,现在来构建检索 加载向量数据库 from langchain.vectorstores import Chroma from langchain_huggingface import HuggingFaceEmbeddings import os# 定义 Embeddings embeddings HuggingFaceEmbeddings(model_name"m3e-base")#…...

Day13 用Excel表体验梯度下降法
Day13 用Excel表体验梯度下降法 用所学公式创建Excel表 用Excel表体验梯度下降法 详见本Day文章顶部附带资源里的Excel表《梯度下降法》,可以对照表里的单元格公式进行理解,还可以多尝试几次不同的学习率 η \eta η来感受,只需要更改学习率…...
--数据的表示与运算·其四 浮点数的储存和加减/内存对齐/大端小端)
计算机组成原理的学习笔记(5)--数据的表示与运算·其四 浮点数的储存和加减/内存对齐/大端小端
学习笔记 前言 本文主要是对于b站尚硅谷的计算机组成原理的学习笔记,仅用于学习交流。 1. 浮点数的表示与运算 规格化数: 浮点数的存储格式为 ,其中: 为符号位。 为尾数,通常在0和1之间(规格化形式为1.xx…...

华为IPD流程6大阶段370个流程活动详解_第二阶段:计划阶段 — 86个活动
华为IPD流程涵盖了产品从概念到上市的完整过程,各阶段活动明确且相互衔接。在概念启动阶段,产品经理和项目经理分析可行性,PAC评审后成立PDT。概念阶段则包括产品描述、市场定位、投资期望等内容的确定,同时组建PDT核心组并准备项目环境。团队培训涵盖团队建设、流程、业务…...

如何使用 Flask 框架创建简单的 Web 应用?
Flask是一个轻量级的Web应用框架,用Python编写,非常适合快速开发和原型设计。 它提供了必要的工具和技术来构建一个Web应用,同时保持核心简单,不强制使用特定的工具或库。 二、创建第一个Flask应用 安装Flask 首先,…...

将Minio设置为Django的默认Storage(django-storages)
这里写自定义目录标题 前置说明静态文件收集静态文件 使用django-storages来使Django集成Minio安装依赖settings.py测试收集静态文件测试媒体文件 前置说明 静态文件 Django默认的Storage是本地,项目中的CSS、图片、JS都是静态文件。一般会将静态文件放到一个单独…...

sed | 一些关于 sed 的笔记
sed 总结 sed 语法sed [-hnV] [-e<script>] [-f<script文件>] [文本文件]--- 参数:-e<script> 以选项中指定的script 来处理输入的文本文件-f<script文件> 以选项中指定的script 文件来处理输入的文本文件-n 禁用 pattern space 的默认输出…...

wtforms+flask_sqlalchemy在flask-admin视图下实现日期的修改与更新
背景: 在flask-admin 的modelview视图下实现自定义视图的表单修改/编辑是件不太那么容易的事情,特别是想不自定义前端view的情况下。 材料: wtformsflask_sqlalchemy 制作: 上代码 1、模型代码 from .exts import db from …...

AI的进阶之路:从机器学习到深度学习的演变(三)
(承接上集:AI的进阶之路:从机器学习到深度学习的演变(二)) 四、深度学习(DL):机器学习的革命性突破 深度学习(DL)作为机器学习的一个重要分支&am…...

thinkphp 多选框
视图 <div class"form-group"><label for"c-flag" class"control-label col-xs-12 col-sm-2 col-md-4">{:__(Flag)}</label><div class"col-xs-12 col-sm-8 col-md-8"><!--formatter:off--><select …...

机器学习《西瓜书》学习笔记《待续》
如果说,计算机科学是研究关于“算法”的学问,那么机器学习就是研究关于“学习算法”的学问。 目录 绪论引言基本术语 扩展向量的张成-span使用Markdown语法编写数学公式希腊字母的LaTex语法插入一些数学的结构插入定界符插入一些可变大小的符号插入一些函…...

STM32HAL I2C函数
8.5 使用IIC协议读写EEPROM 硬件方式实现 (HAL库) **HAL_I2C_Mem_Write() :这种方法可以写1个或者多个字节 ** /*** brief 以阻塞模式向指定的内存地址写入数据* param hi2c 指向 I2C_HandleTypeDef 结构体的指针,包含指定 I2C 的配置信息…...

洛谷 P1644 跳马问题 C语言
题目: P1644 跳马问题 - 洛谷 | 计算机科学教育新生态 题目背景 在爱与愁的故事第一弹第三章出来前先练练四道基本的回溯/搜索题吧…… 题目描述 中国象棋半张棋盘如图 1 所示。马自左下角 (0,0) 向右上角 (m,n) 跳。规定只能往右跳,不准往左跳。比…...

每天40分玩转Django:实操在线商城
实操在线商城 一、今日学习内容概述 模块重要程度主要内容商品模型⭐⭐⭐⭐⭐商品信息、分类管理购物车系统⭐⭐⭐⭐⭐购物车功能实现订单系统⭐⭐⭐⭐⭐订单处理、支付集成用户中心⭐⭐⭐⭐订单管理、个人信息 二、模型设计 # models.py from django.db import models fro…...

Bug解决!ImportError: cannot import name MutableMapping from collections
省流:python版本更新 而一些生态库的变量命名没更新变化导致的问题 起因是在win环境下装spark 但是发现这是python底层的问题 于是想写一篇这个错误的博客警戒世人 py实在是太多生态库了 但并不是所有的都维护的很好 大概可以理解成 python原先有个东西叫col…...

【Rust自学】4.5. 切片(Slice)
4.5.0. 写在正文之前 这是第四章的最后一篇文章了,在这里也顺便对这章做一个总结: 所有权、借用和切片的概念确保 Rust 程序在编译时的内存安全。 Rust语言让程序员能够以与其他系统编程语言相同的方式控制内存使用情况,但是当数据所有者超…...

ZYNQ PS侧DDR3内存配置避坑指南:以ACZ702开发板为例,手把手教你搞定MT41K128M16
ZYNQ PS侧DDR3内存配置实战:从硬件原理到Vivado参数设置全解析 当你第一次拿到ACZ702这样的ZYNQ开发板,准备配置PS侧的DDR3内存时,是否遇到过这样的困惑:为什么在Vivado中找不到DDR管脚约束选项?为什么按照传统FPGA的D…...

保姆级万物识别教程:阿里开源镜像快速部署,识别图片超简单
保姆级万物识别教程:阿里开源镜像快速部署,识别图片超简单 1. 开篇:为什么选择这个镜像? 今天给大家介绍一个特别实用的AI工具——阿里开源的"万物识别-中文-通用领域"镜像。这个镜像最大的特点就是简单易用ÿ…...

突发!国行苹果 AI 凌晨偷跑又紧急下线
3 月 31 日凌晨,大量升级 iOS 26.4 的国行 iPhone 16 及后续机型用户,突然发现设置里 “Siri” 变成 “Apple 智能与 Siri”,可下载 9.5GB 本地 AI 模型,解锁实时翻译、视觉智能、照片消除等全套功能。不过这场“惊喜”仅持续了数…...

车载Java OTA升级崩溃率从18.7%降至0.3%:基于Delta Patch + 类隔离热修复的4步标准化流程
第一章:车载Java OTA升级崩溃率从18.7%降至0.3%:基于Delta Patch 类隔离热修复的4步标准化流程在车载嵌入式Java环境(JVM 11,ART兼容层)中,OTA升级引发的ClassCastException与NoClassDefFoundError曾导致高…...
,打造专属AI数字员工)
手把手教你部署OpenClaw(小龙虾),打造专属AI数字员工
2026年,开源AI智能体OpenClaw(国内昵称“小龙虾”)凭借独特的“数字员工”定位迅速崛起,GitHub星标一路攀升至28万,成为当下最受开发者和办公人群青睐的开源AI项目。 一、OpenClaw核心优势解析 OpenClaw能在众多开源…...

联想新品入局,AI智能终端市场格局生变
联想新品发布,直击Mac mini“养虾”痛点2026年3月31日,联想集团正式发布YOGA AI Mini与Think AI Tiny两款AI原生智能终端。其中,YOGA AI Mini面向个人消费市场,精准对标当下被众多用户用于运行OpenClaw的Mac mini。Mac mini虽因便…...

Kandinsky-5.0-I2V-Lite-5s多场景应用:社交头像动效、PPT动态配图、电子相册生成
Kandinsky-5.0-I2V-Lite-5s多场景应用:社交头像动效、PPT动态配图、电子相册生成 1. 认识Kandinsky-5.0-I2V-Lite-5s Kandinsky-5.0-I2V-Lite-5s是一款轻量级图生视频模型,它能将静态图片转化为动态视频。你只需要上传一张首帧图片,再补充一…...

LoRa Feather固件设计:ESP32-S3多外设协同与低功耗调度
1. 项目概述“LoRa Feather”并非一个官方发布的标准化嵌入式库,而是由开发者基于 Adafruit LoRa FeatherWing(如 RFM95W/RFM96W 模块)与 ESP32-S3(特别是带 TFT 显示屏的 Adafruit Feather ESP32-S3 Reverse)硬件平台…...

轻量级跨平台桌面应用开发:Tauri零门槛实战指南
轻量级跨平台桌面应用开发:Tauri零门槛实战指南 【免费下载链接】tauri Build smaller, faster, and more secure desktop and mobile applications with a web frontend. 项目地址: https://gitcode.com/GitHub_Trending/ta/tauri 在桌面应用开发领域&#…...

Gemini 3.1镜像实战:用三层思考架构与多模态引擎解决视频内容生产
谷歌2026年初发布的Gemini 3.1 Pro,凭借可配置的三层思考架构(低/中/高推理深度)和集成Veo视频引擎、Lyria 3音频引擎的多模态能力,为实际业务问题提供了全新的解决范式。国内开发者和内容创作者可通过聚合平台RskAi(w…...