解析在OceanBase创建分区的常见问题|OceanBase 用户问题精粹
在《分区策略和管理分区计划的实践方案》这篇文章中,我们介绍了在ODC中制定分区策略及有效管理分区计划的经验。有不少用户在该帖下提出了使用中的问题,其中一个关于创建分区的限制条件的问题,也是很多用户遭遇的老问题。因此本文以其为切入,将创建分区的几个问题进行解析,与大家共同探讨分享。
为什么主键必须包含全部分区键?
用户问:“有一张订单流水表,数据很大,想考虑按年份对数据进行分区。现在只有 ID 列是主键。尝试了一下好像无法按日期进行分区。是必须要把日期做成和 ID 的联合主键才可以分区么?”
答案是对的,主键必须包含所有分区键。因为主键的唯一性检查是在各个分区内部进行的,如果主键不包含全部分区键,这个检查就会失效,所以 MySQL 及其他数据库,也一样会有这个要求。
-- 如果主键不包含全部分区键,建表就会失败报错,报错信息也挺明确的。
create table t1(c1 int, c2 int,c3 int,primary key (c1))
partition by range (c2) (partition p1 values less than(3),partition p1 values less than(6));ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function下面举个例子:
create table t1(c1 int, c2 int,c3 int,primary key (c1, c2))
partition by range (c2) (partition p0 values less than(3),partition p1 values less than(6));
Query OK, 0 rows affected (0.146 sec)obclient [test]> insert into t1 values(1, 2, 3);
Query OK, 1 row affected (0.032 sec)obclient [test]> insert into t1 values(1, 5, 3);
Query OK, 1 row affected (0.032 sec)obclient [test]> select * from t1;
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
| 1 | 5 | 3 |
+----+----+------+
2 rows in set (0.032 sec)我们创建了一张表,主键是 c1 和 c2,分区键是 c2,小于 3 的值在 p0 分区,大于等于 3 且小于 6 的值在 p1 分区。然后插入了两个行,第一行在 p0 分区,第二行在 p1 分区。
obclient [test]> select * from t1 PARTITION(p0);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
+----+----+------+
1 row in set (0.033 sec)obclient [test]> select * from t1 PARTITION(p1);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 5 | 3 |
+----+----+------+
1 row in set (0.034 sec)如果主键只有 c1 而没有 c2,那么在 p0 和 p1 分区内对 c1 列的唯一性检测都会成功,因为在各个分区内 c1 列的值都不重复,然后就会判定插入的数据符合主键约束。但实际上在分区间会有重复值,数据并不符合主键约束,所以所有数据库在分区时,都要求主键包含全部分区键。
为什么分区能让查询变快?
用户另外一个问题:“按日期分区是否能达到让查询变快的目的?”
个人理解,分区除了可以让一张超级大表的数据比较被均衡地被负载在不同的数据库节点上,另外一个目的就是加速查询。因为查询时会利用过滤条件里面的分区键进行分区裁剪。例如下面这两个例子:
如果过滤条件里有分区键,计划中可以看到 partitions(p0),说明只扫描了 p0 这一个分区的数据。
obclient [test]> explain select * from t1 where c2 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |3 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c2 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
11 rows in set (0.034 sec)如果过滤条件里没有分区键,计划中可以看到 partitions(p[0-1]),说明扫描了 p0 和 p1 全部所有分区的数据。其中 PX PARTITION ITERATOR 算子就是用来循环扫描所有分区的迭代器。
obclient [test]> explain select * from t1 where c3 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ============================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |6 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000|1 |6 | |
| |2 | └─PX PARTITION ITERATOR| |1 |5 | |
| |3 | └─TABLE FULL SCAN |t1 |1 |5 | |
| ============================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| dop=1 |
| 2 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil), rowset=16 |
| force partition granule |
| 3 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c3 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p[0-1]) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
19 rows in set (0.038 sec)range 分区不支持 datetime 类型咋办?
用户的另另外一个问题:“range 分区不支持 datetime 类型咋办?”。
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE(UNIX_TIMESTAMP(a))(PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),PARTITION pn VALUES less than MAXVALUE);ERROR 1486 (HY000): Constant or random or timezone-dependent expressions in (sub)partitioning function are not allowed试了下,OB 的 MySQL 模式,为了兼容 MySQL 行为,会和 MySQL 对 random expressions 进行一些限制。我第一时间想到的是用生成列绕过,不过很快发现,为了兼容 MySQL 行为,OB 对生成列的使用也进行了限制,生成列里也不允许出现 UNIX_TIMESTAMP 这个特殊的表达式,所以并没什么卵用:
CREATE TABLE ff01 (a datetime , b timestamp as (UNIX_TIMESTAMP(a)))
PARTITION BY RANGE(b)(PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),PARTITION pn VALUES less than MAXVALUE);ERROR 3102 (HY000): Expression of generated column contains a disallowed function至于为啥 UNIX_TIMESTAMP 在生成列里属于 disallowed function,猜测大概率是因为它是个非 deterministic 的系统函数。非 deterministic 简单来说就是这个 UNIX_TIMESTAMP() 函数在前一秒执行,和在后一秒执行,可能会返回不同的结果。像分区表达式、生成列表达式、check 约束里面的表达式,都不允许出现这种非确定性的函数。
下面举个简单的例子,解释一下上面 ERROR 1486 这个报错里 random 一词,以及非 deterministic 的含义:
obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008180 |
+------------------+
1 row in set (0.042 sec)obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008419 |
+------------------+
1 row in set (0.041 sec)-- 是不是一下子就明白,为啥 UNIX_TIMESTAMP 这么特殊,在哪里都不受待见了吧?不过不得不说,OB 的 MySQL 兼容性做的还挺好的,不仅是兼容了 MySQL 各种使用上的限制,甚至是一些 MySQL 的 bug 都给兼容了,虽然给使用带来了一些不便,不过迁移 MySQL 大概会变得比较轻松。
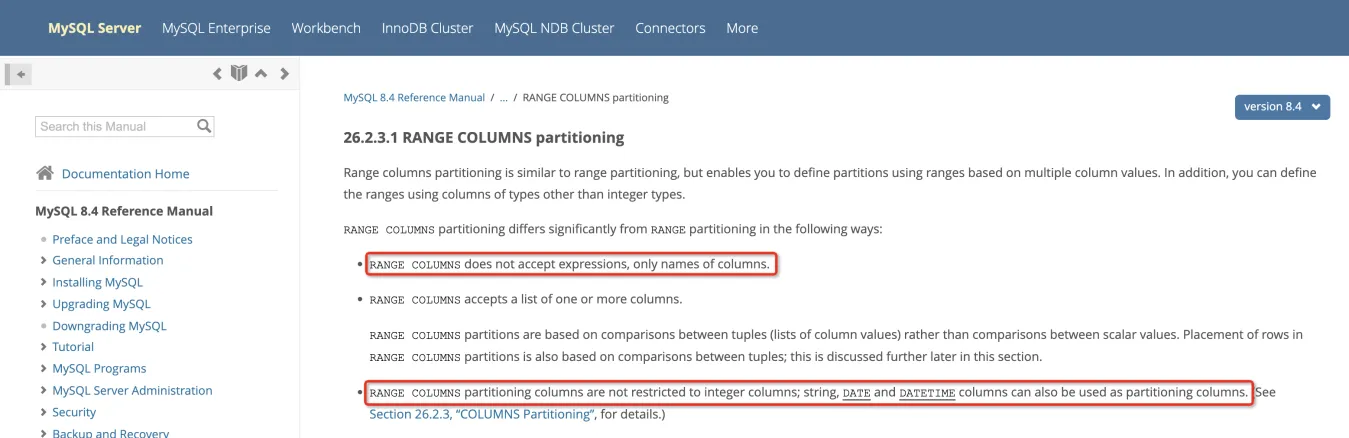
扯远了,回归正题,后面查了下 OB 官网,发现有一种分区方式叫 Range Columns,和 Range 分区十分类似,优点是相比 Range 分区可以支持更多的数据类型,例如用户需要的 datetime 类型,缺点是分区定义不支持表达式。
因为 Range 不支持 UNIX_TIMESTAMP 这类特殊的非 deterministic 表达式,所以个人理解这里可以通过 Range Columns 解决用户的问题。例如:
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE COLUMNS(a)(PARTITION p0 VALUES less than ('2023-01-01'),PARTITION p1 VALUES less than ('2023-01-02'),PARTITION pn VALUES less than MAXVALUE);Query OK, 0 rows affected (0.101 sec)说来惭愧,我之前也一直没注意过 Range 分区和 Range Columns 分区的区别,一直是把他们等价的,今天也算是学习到了,哈哈~
最后附上一个 MySQL 的官网文档链接,感觉它对 RANGE COLUMNS partitioning 的介绍比 OB 的官网要更清楚些,在这里推荐给对分区方式感兴趣的朋友阅读~
What else?
有同学提出还可以通过利用 to_days 函数代替 UNIX_TIMESTAMP 函数的方式解决第三个问题,这样就不需要更改 range 分区为 range columns 分区了。例如:
##创建range分区表
-- 分区字段是start_time,类型datetime
CREATE TABLE dba_test_range_1 (id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) NOT NULL COMMENT 'name',start_time datetime NOT NULL COMMENT '开始时间',
PRIMARY KEY (id,start_time)
)AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT = 'test range'
PARTITION BY RANGE(to_days(start_time))(PARTITION M202301 VALUES LESS THAN(to_days('2023-02-01')),PARTITION M202302 VALUES LESS THAN(to_days('2023-03-01')),PARTITION M202303 VALUES LESS THAN(to_days('2023-04-01')));相关文章:
解析在OceanBase创建分区的常见问题|OceanBase 用户问题精粹
在《分区策略和管理分区计划的实践方案》这篇文章中,我们介绍了在ODC中制定分区策略及有效管理分区计划的经验。有不少用户在该帖下提出了使用中的问题,其中一个关于创建分区的限制条件的问题,也是很多用户遭遇的老问题。因此本文以其为切入&…...

Flutter组件————Container
Container Container 是 Flutter 中最常用的布局组件之一 参数 参数名称类型描述alignmentAlignmentGeometry定义子组件在其内部的对齐方式,默认为 null,即不改变子组件的位置。paddingEdgeInsetsGeometry内边距,用于在子组件周围添加空间…...
:SpringMyBatis)
Java重要面试名词整理(二):SpringMyBatis
文章目录 Spring篇Spring核心推断构造方法AOP动态代理Advice的分类Advisor的理解AOP相关的概念 定义BeanASM技术JFR依赖注入循环依赖LifecycleSpring AOT Spring事务Spring事务传播机制Spring事务传播机制是如何实现的呢?Spring事务传播机制分类 SpringMVCHandlerHandlerMappi…...

Excel生成DBC脚本源文件
Excel制作 新建一个Excel,后缀为“.xls” 工作本名称改为“CAN_Matrix” 在首行按照列来起名字,在里面只需要填写必须的内容即可。 列数名称第0列Message Name第1列Message Format第2列Message ID第3列Message Length (byte)第4列Message Transmitte…...

Git进阶:本地或远程仓库如何回滚到之前的某个commit
在Git的使用过程中,我们经常会遇到需要回滚到之前某个commit的情况。无论是为了修复错误、撤销更改,还是为了重新组织代码,回滚到特定commit都是一个非常有用的技能。本文将介绍几种常用的回滚方法,帮助读者更好地掌握Git版本控制…...
)
linux 中文输入法设置的宏观思路 (****)
乱是永远的不乱,变是永远的不变。 $ ibus help # 注意:help 前没有杠符号 $ setxkbmap -help # 注意:help 前只有一个杠符号 $ localectl --help # 注意:help 前有 2 个杠符号 $ man im-config # 注意:-h, --help 只出来提示信息:请参考。。。。。。。 $ man abc…...

271-基于XC7V690T的12路光纤PCIe接口卡
一、板卡概述 基于XC7V690T的12路光纤PCI-E接口卡,用于实现多通道高速光纤数据接收和发送,板卡兼容PCIe 2.0和PCIe 3.0规范,利用PCI-E Switch PEX 8748实现FPGA芯片与计算机的通信,计算机与板卡接口处提供PCI-e 16速接口ÿ…...

Semaphore UI安装和实践
本次实验环境采用centos7.9操作系统,使用rpm包安装方式。 1.配置yum源 --下载centos华为云镜像仓库 wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.huaweicloud.com/repository/conf/CentOS-7-anon.repo[rootlocalhost ~]# wget -O /etc/yum.repos.…...

Redis篇--常见问题篇7--缓存一致性2(分布式事务框架Seata)
1、概述 在传统的单体应用中,事务管理相对简单,通常使用数据库的本地事务(如MySQL的BEGIN和COMMIT)来保证数据的一致性。然而,在微服务架构中,由于每个服务都有自己的数据库,跨服务的事务管理变…...

Docker Compose 安装 Harbor
我使用的系统是rocky Linux 9 1. 准备环境 确保你的系统已经安装了以下工具: DockerDocker ComposeOpenSSL(用于生成证书)#如果不需要通过https连接的可以不设置 1.1 安装 Docker 如果尚未安装 Docker,可以参考以下命令安装&…...

使用docker compose安装gitlab
使用docker compose安装gitlab GitLab简介设置GITLAB_HOME路径创建docker挂载目录获取可用的GitLab版本编写docker-compose.yml文件启动docker基础配置GITLAB_OMNIBUS_CONFIG修改配置 中文设置数据库配置系统邮箱配置 GitLab简介 GitLab是一个基于Git的开源项目,…...

大模型日报 2024-12-18
大模型日报 2024-12-18 大模型资讯 标题: 3B模型长思考后击败70B!HuggingFace逆向出o1背后技术细节并开源 摘要:这篇文章探讨了小模型在经过长时间思考后,如何在性能上超越更大规模模型的现象。HuggingFace通过逆向工程和开源技术…...

Linux安装mysql5.7
一、下载mysql5.7 首先我们需要去下载linux版本的mysql-5.7.24的安装包。 1.可以去官方网站链接: https://downloads.mysql.com/archives/community/ ,下载mysql-5.7.24-linux-glibc2.12-x86_64.tar压缩包。 2.在线下载,使用wget命令,直接从官网下载…...

【容器】k8s学习笔记原理详解(十万字超详细)
Pod详解 Pod介绍 Pod结构 每个Pod中都可以包含一个或者多个容器,这些容器可以分为两类: 用户程序所在的容器,数量可多可少Pause容器,这是每个Pod都会有的一个根容器,它的作用有两个: 可以以它为依据&am…...

.NET重点
B/S C/S B/S: 浏览器端:JavaScript,HTML,CSS 服务器端:ASP(.NET)PHP/JSP 优势:维护方便,易于升级和扩展 劣势:服务器负担沉重 C/S java/.NET/VC系列 …...

SMMU软件指南SMMU编程之虚拟机结构和缓存
安全之安全(security)博客目录导读 目录 一、虚拟机结构(VMS) 二、缓存 一、虚拟机结构(VMS) 虚拟机结构(VMS)是SMMU中的概念,是一个由STE.VMSPtr字段指向的结构,包含每个虚拟机的配置设置。在相同安全状态下具有相同虚拟机ID(VMID)的多个STE必须指向相同的VMS。…...

Go 语言并发实战:利用协程处理多个接口进行数据融合
高效地处理多个数据源并将其整合为有意义的结果是开发中一项重要的任务。Go 语言,以其强大的并发特性,为我们提供了优雅而高效的解决方案。那么我们探讨一下如何利用 Go 语言的协程,同时调用多个接口获取数据,并将这些数据无缝地合…...

Redis Hash Tag 知识详解
一、Redis Hash Tag概述 Redis Hash Tag是Redis集群环境里用于控制数据分片的关键机制。在Redis集群中,数据依据键的哈希值来确定分片存储位置。Hash Tag能让用户指定键的特定部分作为哈希计算核心部分,进而使相关键存储于同一节点,这对处理…...

在 Ubuntu 上安装 Muduo 网络库的详细指南
在 Ubuntu 上安装 Muduo 网络库的详细指南 首先一份好的安装教程是非常重要的 C muduo网络库知识分享01 - Linux平台下muduo网络库源码编译安装-CSDN博客 像这篇文章就和shit一样,安装到2%一定会卡住,如果你不幸用了这个那真是遭老罪了 环境…...
)
Golang Gin Redis+Mysql 同步查询更新删除操作(我的小GO笔记)
我的需求是在处理几百上千万数据时避免缓存穿透以及缓存击穿情况出现,并且确保数据库和redis同步,为了方便我查询数据操作加了一些条件精准查询和模糊查询以及全字段模糊查询、分页、排序一些小玩意,redis存储是hash表key值也就是数据ID&…...

蛋白质设计实战:基于RFdiffusion的Motif Scaffolding功能位点定制化设计
1. 认识RFdiffusion与Motif Scaffolding 第一次接触蛋白质设计时,我被这个领域的复杂性震撼到了。20种氨基酸就像乐高积木,但它们的组合方式比宇宙中的星辰还要多。而RFdiffusion就像是一把神奇的钥匙,帮我打开了蛋白质设计的大门。 RFdiffus…...

[FLAC无损下载]音乐爱好者与创作者的高效资源获取方案
[FLAC无损下载]音乐爱好者与创作者的高效资源获取方案 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 在数字音乐产业快速发展的今天,无损…...

KindEditor富文本编辑器:轻量级网页内容创作解决方案
KindEditor富文本编辑器:轻量级网页内容创作解决方案 【免费下载链接】kindeditor WYSIWYG HTML editor 项目地址: https://gitcode.com/gh_mirrors/ki/kindeditor 在当今Web开发中,内容编辑功能是许多网站的核心需求,但开发者常常面临…...

基于51单片机与74LS30的智能抢答器系统设计与实现
1. 智能抢答器系统概述 在各类知识竞赛、课堂互动和电视节目中,抢答器都是不可或缺的设备。传统机械式抢答器存在响应慢、易误触等问题,而基于51单片机的智能抢答器系统则完美解决了这些痛点。这个系统我做过不下十次,实测响应时间可以控制在…...

基于vue+springboot框架的社区居民诊疗健康管理系统设计与实现
目录技术选型与架构设计核心功能模块划分开发阶段规划关键问题解决方案测试与部署文档规范项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与架构设计 前端框架:Vue 3(Composition APIÿ…...

免费领取《MapleSim卷材加工和卷绕系统建模仿真教程》
在薄膜、纸张、电池极片、电子材料等卷对卷加工中,你是否还在为张力波动、卷材打滑、收放卷不稳而头疼?物理样机调试成本高、风险大,单纯依靠经验难以解决复杂的动态耦合问题。 Maplesoft 中国技术团队近期发布了 MapleSim 卷材处理库&#…...

投资回报不到 1 年!这套导热油炉处理油泥减量化方案,凭什么火遍行业?
行业痛点:油泥处置面临的严峻挑战随着环保政策日趋严格,HW08类含油污泥的处理已成为石化、炼油等企业的必答题。然而,传统处理方式面临四大核心痛点:成本压力巨大:传统焚烧处置费用高达3000-5000元/吨,填埋…...

低成本搭建QQ机器人:OpenClaw+nanobot消息中转方案
低成本搭建QQ机器人:OpenClawnanobot消息中转方案 1. 为什么选择OpenClawnanobot方案 去年我在管理一个小型技术社群时,经常需要处理重复性的问答和通知发布。尝试过多个机器人框架后,最终选择了OpenClawnanobot的组合方案。这个方案最吸引…...
)
你的模型评估做对了吗?深入解读泰勒图里的R、RMSE和STD(以sklearn预测为例)
你的模型评估做对了吗?深入解读泰勒图里的R、RMSE和STD(以sklearn预测为例) 泰勒图作为模型评估的经典可视化工具,表面上只是几个点和线的组合,实则暗藏玄机。许多开发者在使用泰勒图时,常常陷入"距离…...

SDMatte Web界面实操手册:从上传到下载透明PNG的完整步骤
SDMatte Web界面实操手册:从上传到下载透明PNG的完整步骤 1. 认识SDMatte:你的智能抠图助手 SDMatte是一款专为高质量图像抠图设计的AI工具,它能帮你轻松完成各种复杂的抠图任务。想象一下,你拍了一张漂亮的玻璃杯照片ÿ…...