【c++高阶DS】图

🔥个人主页:Quitecoder
🔥专栏:c++笔记仓

目录
- 01.并查集
- 02.图的介绍
- 03.图的存储结构
- 03.1.邻接矩阵
- 03.2.邻接表
- 03.3.矩阵版本代码实现
- 03.4.邻接表版本代码实现
- 完整代码:
01.并查集
在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集(union-find set)
比如:某公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; 给以下数组用来存储该小集体,数组中的数字代表:该小集体中具有成员的个数

毕业后,学生们要去公司上班,每个地方的学生自发组织成小分队一起上路,于是:
西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长,负责大家的出行。


从上图可以看出:编号6,7,8同学属于0号小分队,该小分队中有4人(包含队长0);编号为4和9的同学属于1号小分队,该小分队有3人(包含队长1),编号为3和5的同学属于2号小分队,该小分队有3个人(包含队长1)
仔细观察数组中内融化,可以得出以下结论:
- 数组的下标对应集合中元素的编号
- 数组中如果为负数,负号代表根,数字代表该集合中元素个数
- 数组中如果为非负数,代表该元素双亲在数组中的下标
在公司工作一段时间后,西安小分队中8号同学与成都小分队1号同学奇迹般的走到了一起,两个小圈子的学生相互介绍,最后成为了一个小圈子

现在0集合有7个人,2集合有3个人,总共两个朋友圈
通过以上例子可知,并查集一般可以解决一下问题:
- 查找元素属于哪个集合
沿着数组表示树形关系以上一直找到根(即:树中中元素为负数的位置) - 查看两个元素是否属于同一个集合
沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在 - 将两个集合归并成一个集合
将两个集合中的元素合并
将一个集合名称改成另一个集合的名称 - 集合的个数
遍历数组,数组中元素为负数的个数即为集合的个数
代码实现:
class UnionFindSet
{
public:UnionFindSet(size_t n):_ufs(n, -1){}void Union(int x1, int x2){int root1 = FindRoot(x1);int root2 = FindRoot(x2);if (root1 == root2)return;_ufs[root1] += _ufs[root2];_ufs[root2] = root1;}int FindRoot(int x){int parent = x;while (_ufs[parent] >= 0){parent = _ufs[parent];}return parent;}bool InSet(int x1,int x2){return FindRoot(x1) == FindRoot(x2);}size_t SetSize(){size_t size= 0;for (int i = 0; i < _ufs.size(); i++){if (_ufs[i] < 0) ++size;}return size;}
private:vector<int> _ufs;
};
题目链接1:LCR 116. 省份数量
题目描述:

class Solution {
public: int findCircleNum(vector<vector<int>>& isConnected) {UnionFindSet ufs(isConnected.size());for(int i=0;i<isConnected.size();i++){for(int j=0;j<isConnected[i].size();j++){if(isConnected[i][j]==1){ufs.Union(i,j);}}}return ufs.SetSize();}
};
题目链接2:990. 等式方程的可满足性
题目描述:

class Solution {
public:bool equationsPossible(vector<string>& equations) {UnionFindSet _ufs(26);for(auto& str: equations){if(str[1]=='='){_ufs.Union(str[0]-'a',str[3]-'a');}}for(auto& str2: equations){if(str2[1]=='!'){if(_ufs.InSet(str2[0]-'a',str2[3]-'a')) return false;}}return true;}
};
02.图的介绍
并查集是后面的铺垫,这里我们对图进行讲解:
图是由顶点集合及顶点间的关系组成的一种数据结构:G = (V, E),其中:顶点集合V = {x|x属于某个数据对象集}是有穷非空集合;
E = {(x,y)|x,y属于V}或者E = {<x, y>|x,y属于V && Path(x, y)}是顶点间关系的有穷集合,也叫做边的集合。(x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path(x, y)表示从x到y的一条单向通路,即Path(x, y)是有方向的

顶点和边:图中结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边,图中的第k条边记作ek,ek = (vi,vj)或<vi,vj>
-
有向图和无向图:在有向图中,顶点对
<x, y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边(弧),<x, y>和<y, x>是两条不同的边,比如图G3和G4为有向图。在无向图中,顶点对(x, y)是无序的,顶点对(x,y)称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,比如图G1和G2为无向图。注意:无向边(x, y)等于有向边<x, y>和<y, x> -
完全图:在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图**,比如上图G1;在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图,比如上图G4(任意两个顶点之间都相连,最稠密的图)
-
邻接顶点:在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u和v;在有向图G中,若
<u, v>是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边<u, v>与顶点u和顶点v相关联 -
顶点的度:顶点v的度是指与它相关联的边的条数,记作deg(v)。在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶点的入度和出度,即dev(v) = indev(v) = outdev(v)
-
路径:在图G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径
-
路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和

简单路径与回路:若路径上各顶点v1,v2,v3,…,vm均不重复,则称这样的路径为简单路径。若路径上第一个顶点v1和最后一个顶点vm重合,则称这样的路径为回路或环

子图:设图G = {V, E}和图G1 = {V1,E1},若V1属于V且E1属于E,则称G1是G的子图

- 连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。
- 强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到vi的路径,则称此图是强连通图。
- 生成树:一个连通图(无向图)的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。
03.图的存储结构
因为图中既有节点,又有边(节点与节点之间的关系),因此,在图的存储中,只需要保存:节点和边关系即可。节点保存比较简单,只需要一段连续空间即可,那边关系该怎么保存呢
03.1.邻接矩阵
因为节点与节点之间的关系就是连通与否,即为0或者1,因此邻接矩阵(二维数组)即是:先用一个数组将定点保存,然后采用矩阵来表示节点与节点之间的关系

无向图的邻接矩阵是对称的,第i行(列)元素之和,就是顶点i的度。有向图的邻接矩阵则不一定是对称的,第i行(列)元素之和就是顶点i 的出(入)度
如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通,则使用无穷大代替

邻接矩阵存储方式非常适合稠密图
邻接矩阵O(1)判断两个顶点的连接关系,并取到权值
用邻接矩阵存储图的有点是能够快速知道两个顶点是否连通,缺陷是如果顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求,同时也不好求一个顶点连接的边数
03.2.邻接表
邻接表:使用数组表示顶点的集合,使用链表表示边的关系。
- 无向图邻接表存储

指针数组:自己连接顶点边全都挂在下面 - 有向图邻接表存储

注意:有向图中每条边在邻接表中只出现一次,与顶点vi对应的邻接表所含结点的个数,就是该顶点的出度,也称出度表,要得到vi顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的dst取值是i。
邻接表适合存储稀疏图,也适合查找一个顶点连接出去的边,不适合去确定两个顶点是否相连及权值
03.3.矩阵版本代码实现
template<class V,class W, W MAX_W = INT_MAX,bool Direction = false>
class Graph
{private:vector<V> _vertexs;//顶点集合;map<V, int> _indexMap;//顶点映射下标;vector<vector<W>> _matrix;// 存储边集合的矩阵
};
构造函数:
Graph(const V* a,size_t n)
{_vertexs.reserve(n);for (size_t i = 0; i < n; i++){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_matrix.resize(n);for (size_t i = 0; i < _matrix.size(); i++){_matrix[i].resize(n, MAX_W);}
}
这是一个带顶点数组 a 和顶点数量 n 的构造函数,作用是:
- 初始化图的顶点集合 _vertexs。
- 使用一个映射 _indexMap 存储顶点到索引的映射关系,方便后续操作。
- 使用二维矩阵 _matrix 初始化边的权值集合
_vertexs.reserve(n):为顶点集合预留容量,避免后续动态扩展的开销。
遍历顶点数组,将每个顶点添加到 _vertexs,并记录其在数组中的索引到 _indexMap,实现顶点到索引的快速查找
_matrix.resize(n):将矩阵调整为 n×n大小。
每行使用 resize(n, MAX_W) 将所有初始值设置为 MAX_W,表示无连接边
添加边:
size_t GetVertexIndex(const V& v)
{auto it = _indexMap.find(v);if (it != _indexMap.end()){return it->second;}else{throw invalid_argument("不存在的顶点");return -1;}
}
void AddEdge(const V& src, const V& dst, consy W& w)
{size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);_matrix[srci][dsti] = w; if (Direction == false){_matrix[dsti][srci] = w;}
}
这段代码实现了两个关键功能:
GetVertexIndex函数:查找顶点的索引。AddEdge函数:在图中添加边(支持有向图和无向图)。
实现逻辑:
- 使用
_indexMap.find(v)在映射_indexMap中查找顶点v。 - 如果找到,返回对应的索引
it->second。 - 如果未找到,抛出异常
invalid_argument("不存在的顶点"),提示顶点不存在。
在图中添加一条边,支持有向图和无向图。
输入参数:
const V& src:边的起点顶点。const V& dst:边的终点顶点。const W& w:边的权值,引用方式传递,避免复制。
处理方向性:
- 有向图:只设置
_matrix[srci][dsti]。 - 无向图:同时设置
_matrix[srci][dsti]和_matrix[dsti][srci]。
打印函数:
void Print()
{// 打印顶点和下标映射关系for (size_t i = 0; i < _vertexs.size(); ++i){cout << _vertexs[i] << "-" << i << " ";}cout << endl << endl;cout << " ";for (size_t i = 0; i < _vertexs.size(); ++i){cout << i << " ";}cout << endl;// 打印矩阵for (size_t i = 0; i < _matrix.size(); ++i){cout << i << " ";for (size_t j = 0; j < _matrix[i].size(); ++j){if (_matrix[i][j] != MAX_W)cout << _matrix[i][j] << " ";elsecout << "#" << " ";}cout << endl;}cout << endl << endl;// 打印所有的边for (size_t i = 0; i < _matrix.size(); ++i){for (size_t j = 0; j < _matrix[i].size(); ++j){if (i < j && _matrix[i][j] != MAX_W){cout << _vertexs[i] << "-" << _vertexs[j] << ":" <<_matrix[i][j] << endl;}}}
}
进行测试:

03.4.邻接表版本代码实现
template<class W>
struct LinkEdge
{int _srcindex; // 边的起点索引int _dstindex; // 边的终点索引W _w; // 边的权值LinkEdge<W>* _next; // 指向下一个边的指针,用于链式存储LinkEdge(const W& w): _srcIndex(-1) // 默认起点索引为 -1, _dstIndex(-1) // 默认终点索引为 -1, _w(w) // 初始化权值, _next(nullptr) // 指向下一个边的指针初始化为 nullptr{}
};
template<class V, class W, bool Direction = false>
class Graph
{typedef LinkEdge<W> Edge;
public:private:vector<V> _vertexs;//顶点集合;map<V, int> _indexMap;//顶点映射下标;vector<Edge*> _tables;// 邻接表
};
初始化:
Graph(const V* a, size_t n)
{_vertexs.reserve(n);for (size_t i = 0; i < n; i++){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_tables.resize(n,nullptr);
}
增加边:
void AddEdge(const V& src, const V& dst, const W& w)
{size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);Edge* sd_edge = new Edge(w);sd_edge->_srcindex = srci;sd_edge->_dstindex = dsti;sd_edge->_next = _tables[srci];_tables[srci] = sd_edge;if (Direction == false){Edge* ds_edge = new Edge(w);ds_edge->_srcIndex = dstindex;ds_edge->_dstIndex = srcindex;ds_edge->_next = _tables[dstindex];_tables[dstindex] = ds_edge;}
}
下面是详细的步骤说明,基于图中有四个顶点 ( A, B, C, D )。我们逐步构建它们的邻接表,同时解释代码的详细逻辑。
假设
- 图的顶点集合为:[A, B, C, D]。
- 图的边集合为:
- ( A \to B )(权值 1)
- ( A \to C )(权值 2)
- ( B \to D )(权值 3)
- ( C \to D )(权值 4)
- 图是 有向图(即 ( Direction = true ))。
初始状态
邻接表 _tables 是一个数组,初始时,每个顶点的邻接表为空:
_tables: [nullptr, nullptr, nullptr, nullptr]
- ( _tables[0] ) 表示顶点 ( A ) 的邻接表头。
- ( _tables[1] ) 表示顶点 ( B ) 的邻接表头。
- ( _tables[2] ) 表示顶点 ( C ) 的邻接表头。
- ( _tables[3] ) 表示顶点 ( D ) 的邻接表头。
Step 1: 插入边 ( A \to B )(权值 1)
-
调用
AddEdge("A", "B", 1)。 -
获取顶点索引:
GetVertexIndex("A")返回 0。GetVertexIndex("B")返回 1。
-
创建新边
sd_edge:sd_edge->_srcindex = 0; // A 的索引 sd_edge->_dstindex = 1; // B 的索引 sd_edge->_w = 1; // 权值 1 sd_edge->_next = _tables[0]; // 当前 A 的邻接表头(nullptr) _tables[0] = sd_edge; // 更新 A 的邻接表头为 sd_edge -
更新邻接表:
_tables: [sd_edge, nullptr, nullptr, nullptr]此时,邻接表内容为:
A: B (权值 1) -> nullptr B: nullptr C: nullptr D: nullptr
Step 2: 插入边 ( A \to C )(权值 2)
-
调用
AddEdge("A", "C", 2)。 -
获取顶点索引:
GetVertexIndex("A")返回 0。GetVertexIndex("C")返回 2。
-
创建新边
sd_edge:sd_edge->_srcindex = 0; // A 的索引 sd_edge->_dstindex = 2; // C 的索引 sd_edge->_w = 2; // 权值 2 sd_edge->_next = _tables[0]; // 当前 A 的邻接表头(指向 B 的边) _tables[0] = sd_edge; // 更新 A 的邻接表头为 sd_edge -
更新邻接表:
_tables: [sd_edge, nullptr, nullptr, nullptr]此时,邻接表内容为:
A: C (权值 2) -> B (权值 1) -> nullptr B: nullptr C: nullptr D: nullptr
Step 3: 插入边 ( B \to D )(权值 3)
-
调用
AddEdge("B", "D", 3)。 -
获取顶点索引:
GetVertexIndex("B")返回 1。GetVertexIndex("D")返回 3。
-
创建新边
sd_edge:sd_edge->_srcindex = 1; // B 的索引 sd_edge->_dstindex = 3; // D 的索引 sd_edge->_w = 3; // 权值 3 sd_edge->_next = _tables[1]; // 当前 B 的邻接表头(nullptr) _tables[1] = sd_edge; // 更新 B 的邻接表头为 sd_edge -
更新邻接表:
_tables: [sd_edge, sd_edge, nullptr, nullptr]此时,邻接表内容为:
A: C (权值 2) -> B (权值 1) -> nullptr B: D (权值 3) -> nullptr C: nullptr D: nullptr
Step 4: 插入边 ( C \to D )(权值 4)
-
调用
AddEdge("C", "D", 4)。 -
获取顶点索引:
GetVertexIndex("C")返回 2。GetVertexIndex("D")返回 3。
-
创建新边
sd_edge:sd_edge->_srcindex = 2; // C 的索引 sd_edge->_dstindex = 3; // D 的索引 sd_edge->_w = 4; // 权值 4 sd_edge->_next = _tables[2]; // 当前 C 的邻接表头(nullptr) _tables[2] = sd_edge; // 更新 C 的邻接表头为 sd_edge -
更新邻接表:
_tables: [sd_edge, sd_edge, sd_edge, nullptr]此时,邻接表内容为:
A: C (权值 2) -> B (权值 1) -> nullptr B: D (权值 3) -> nullptr C: D (权值 4) -> nullptr D: nullptr
最终邻接表
最终的邻接表结构如下:
A: C (权值 2) -> B (权值 1) -> nullptr
B: D (权值 3) -> nullptr
C: D (权值 4) -> nullptr
D: nullptr
邻接表的 _tables 数据结构是:
_tables:
[sd_edge (A->C), sd_edge (B->D), sd_edge (C->D), nullptr]
最后完成打印函数;
void Print()
{for (size_t i = 0; i < _vertexs.size(); ++i){cout << _vertexs[i] << "-" << i << " ";}cout << endl << endl;for (int i = 0; i < _tables.size(); i++){cout << _vertexs[i] << "[" << i << "]->";Edge* cur = _tables[i];while (cur){cout << _vertexs[cur->_dstindex] << "[" << cur->_dstindex << "]" << cur->_w << "->";cur = cur->_next;}cout << "nullptr" << endl;}
}

完整代码:
#pragma once
#include<vector>
#include<map>using namespace std;namespace matrix
{template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph{public://手动添加边,方便测试Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; i++){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_matrix.resize(n);for (size_t i = 0; i < _matrix.size(); i++){_matrix[i].resize(n, MAX_W);}}size_t GetVertexIndex(const V& v){auto it = _indexMap.find(v);if (it != _indexMap.end()){return it->second;}else{throw invalid_argument("不存在的顶点");return -1;}}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);_matrix[srci][dsti] = w;if (Direction == false){_matrix[dsti][srci] = w;}}void Print(){// 打印顶点和下标映射关系for (size_t i = 0; i < _vertexs.size(); ++i){cout << _vertexs[i] << "-" << i << " ";}cout << endl << endl;cout << " ";for (size_t i = 0; i < _vertexs.size(); ++i){cout << i << " ";}cout << endl;// 打印矩阵for (size_t i = 0; i < _matrix.size(); ++i){cout << i << " ";for (size_t j = 0; j < _matrix[i].size(); ++j){if (_matrix[i][j] != MAX_W)cout << _matrix[i][j] << " ";elsecout << "#" << " ";}cout << endl;}cout << endl << endl;// 打印所有的边for (size_t i = 0; i < _matrix.size(); ++i){for (size_t j = 0; j < _matrix[i].size(); ++j){if (i < j && _matrix[i][j] != MAX_W){cout << _vertexs[i] << "-" << _vertexs[j] << ":" <<_matrix[i][j] << endl;}}}}private:vector<V> _vertexs;//顶点集合;map<V, int> _indexMap;//顶点映射下标;vector<vector<W>> _matrix;// 存储边集合的矩阵};
}
namespace LinkTable
{template<class W>struct LinkEdge{int _srcindex;int _dstindex;W _w;//权值LinkEdge<W>* _next;LinkEdge(const W& w): _srcindex(-1), _dstindex(-1), _w(w), _next(nullptr){}};template<class V, class W, bool Direction = false>class Graph{typedef LinkEdge<W> Edge;public:Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; i++){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_tables.resize(n,nullptr);}size_t GetVertexIndex(const V& v){auto it = _indexMap.find(v);if (it != _indexMap.end()){return it->second;}else{throw invalid_argument("不存在的顶点");return -1;}}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);Edge* sd_edge = new Edge(w);sd_edge->_srcindex = srci;sd_edge->_dstindex = dsti;sd_edge->_next = _tables[srci];_tables[srci] = sd_edge;if (Direction == false){Edge* ds_edge = new Edge(w);ds_edge->_srcindex = dsti;ds_edge->_dstindex = srci;ds_edge->_next = _tables[dsti];_tables[dsti] = ds_edge;}}void Print(){for (size_t i = 0; i < _vertexs.size(); ++i){cout << _vertexs[i] << "-" << i << " ";}cout << endl << endl;for (int i = 0; i < _tables.size(); i++){cout << _vertexs[i] << "[" << i << "]->";Edge* cur = _tables[i];while (cur){cout << _vertexs[cur->_dstindex] << "[" << cur->_dstindex << "]" << cur->_w << "->";cur = cur->_next;}cout << "nullptr" << endl;}}private:vector<V> _vertexs;//顶点集合;map<V, int> _indexMap;//顶点映射下标;vector<Edge*> _tables;// 邻接表};
}
void TestGraph()
{matrix::Graph<char, int, INT_MAX, true> g("0123", 4);g.AddEdge('0', '1', 1);g.AddEdge('0', '3', 4);g.AddEdge('1', '3', 2);g.AddEdge('1', '2', 9);g.AddEdge('2', '3', 8);g.AddEdge('2', '1', 5);g.AddEdge('2', '0', 3);g.AddEdge('3', '2', 6);g.Print();
}
void TestGraph2()
{string a[] = { "张三", "李四", "王五", "赵六" };LinkTable::Graph<string, int> g1(a, 4);g1.AddEdge("张三", "李四", 100);g1.AddEdge("张三", "王五", 200);g1.AddEdge("王五", "赵六", 30);g1.Print();
}
相关文章:
【c++高阶DS】图
🔥个人主页:Quitecoder 🔥专栏:c笔记仓 目录 01.并查集02.图的介绍03.图的存储结构03.1.邻接矩阵03.2.邻接表03.3.矩阵版本代码实现03.4.邻接表版本代码实现 完整代码: 01.并查集 在一些应用问题中,需要将…...

React第十八节 useEffect 用法使用技巧注意事项详解
1、概述 useEffect 是React中一个用于 将组件与外部系统同步的 Hook;在函数式组件中处理副作用函数的 Hook,用于替代类式组件中的生命周期函数; 可以在副作用函数中 实现以下操作: a、请求接口,获取后台提供数据 b、操…...

C++ 指针基础:开启内存操控之门
1. 指针为何如此重要 在 C 编程领域,指针堪称一项极为关键的特性。它赋予了程序员直接访问和操控内存的能力,这使得程序在处理复杂数据结构与优化性能时具有更高的灵活性。想象一下,在编写大型程序时,高效地管理内存资源是多么重要…...

Nginx的stream模块代理四层协议TCP的流量转发
Nginx的stream模块是一个功能强大的工具,专门用于处理四层协议(即网络层和传输层,如TCP和UDP)的流量。以下是对Nginx stream模块的详细解析: 一、基本功能 Nginx的stream模块主要用于实现TCP和UDP数据流的代理、转发…...

UE5 渲染管线 学习笔记
兰伯特 SSS为散射的意思 带Bias的可以根据距离自动切换mip的卷积值 而带Level的值mipmaps的定值 #define A8_SAMPLE_MASK .a 这样应该就很好理解了 这个只采样a通道 带Level的参考上面的 朝左上和右下进行模糊 带Bias参考上面 随机数 4D 3D 2D 1D...
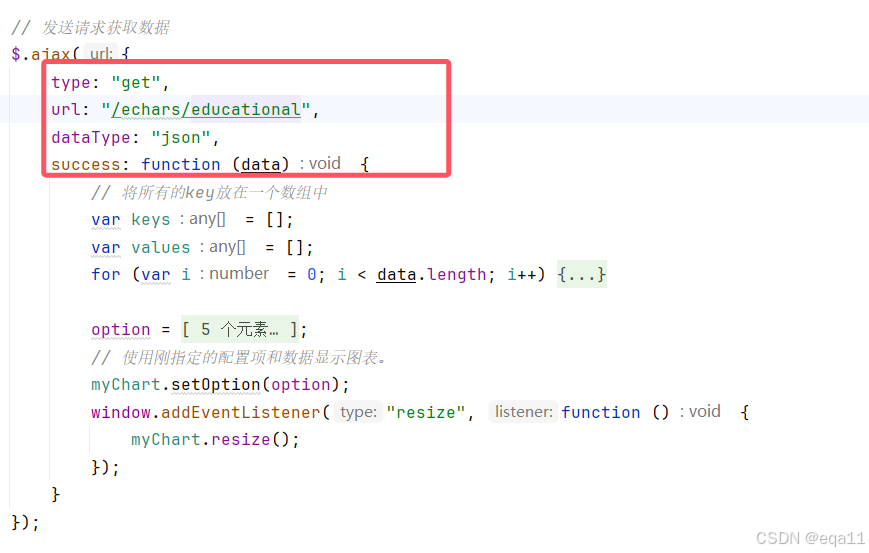
Echarts连接数据库,实时绘制图表详解
文章目录 Echarts连接数据库,实时绘制图表详解一、引言二、步骤一:环境准备与数据库连接1、环境搭建2、数据库连接 三、步骤二:数据获取与处理1、查询数据库2、数据处理 四、步骤三:ECharts图表配置与渲染1、配置ECharts选项2、动…...

Electron 学习笔记
目录 一、安装和启动electron 1. 官网链接 2. 根据文档在控制台输入 3. 打包必填 4. 安装electron开发依赖 5. 在开发的情况下打开应用 6. 修改main为main.js,然后创建main.js 7.启动 二、启动一个窗口 1. main.js 2. index.html 3. 隐藏菜单栏 三、其他…...

Debian 12 安装配置 fail2ban 保护 SSH 访问
背景介绍 双十一的时候薅羊毛租了台腾讯云的虚机, 是真便宜, 只是没想到才跑了一个月, 系统里面就收集到了巨多的 SSH 恶意登录失败记录. 只能说, 互联网真的是太不安全了. 之前有用过 fail2ban 在 CentOS 7 上面做过防护, 不过那已经是好久好久之前的故事了, 好多方法已经不…...

http反向代理
通过反向代理实现访问biying,目前访问一些网站需要绕过cloudfare还没有解决,代码如下: from fastapi import FastAPI, Request from fastapi.responses import StreamingResponse import httpx import uvicorn import logging# 设置日志 logging.basicConfig(level=logging.…...

java12.24日记
运算符: 算术运算符: 顾名思义进行算数运算的 多为:四则运算,加一个取余 ,-,*,/以及 %(取余) 而外的:自增 以及自减--,对原数进行1或者-1 i…...

vue中proxy代理配置(测试一)
接口地址:http://jsonplaceholder.typicode.com/posts 1、配置一(代理没起作用) (1)设置baseURL为http://jsonplaceholder.typicode.com (2)proxy为 ‘/api’:’ ’ (3&a…...

[OpenGL]使用TransformFeedback实现粒子效果
一、简介 本文介绍了如何使用 OpenGL 中的 Transform Feedback 实现粒子效果,最终可以实现下图的效果: 本文的粒子系统实现参考了modern-opengl-tutorial, ogldev-tutorial28 和 粒子系统–喷泉 [OpenGL-Transformfeedback]。 二、使用 TransformFeed…...

GitCode 光引计划投稿 | GoIoT:开源分布式物联网开发平台
GoIoT 是基于Gin 的开源分布式物联网(IoT)开发平台,用于快速开发,部署物联设备接入项目,是一套涵盖数据生产、数据使用和数据展示的解决方案。 GoIoT 开发平台,它是一个企业级物联网平台解决方案ÿ…...

用 gdbserver 调试 arm-linux 上的 AWTK 应用程序
很多嵌入式 linux 开发者都能熟练的使用 gdb/lldb 调试应用程序,但是还有不少朋友在调试开发板上的程序时,仍然在使用原始的 printf。本文介绍一下使用 gdbserver 通过网络调试开发板上的 AWTK 应用程序的方法,供有需要的朋友参考。 1. 下载 …...

攻防世界web第一题
最近开始学习网络安全的相关知识,开启刷题,当前第一题 题目为攻防世界web新手题 这是题目 翻译:在这个训练挑战中,您将了解 Robots_exclusion_standard。网络爬虫使用 robots.txt 文件来检查是否允许它们对您的网站或仅网站的一部…...

轮播图带详情插件,插件
超级好用的轮播图 介绍访问地址参数介绍使用方法(简单使用,参数结构点击链接查看详情)图片展示 介绍 video(15) 带有底部物品介绍以及价格的轮播图组件,持续维护,uniApp插件,直接下载填充数据就可以在项目里…...

gesp(三级)(14)洛谷:B4039:[GESP202409 三级] 回文拼接
gesp(三级)(14)洛谷:B4039:[GESP202409 三级] 回文拼接 题目描述 一个字符串是回文串,当且仅当该字符串从前往后读和从后往前读是一样的,例如, aabaa \texttt{aabaa} aabaa 和...

ISO17025最新认证消息
ISO17025认证是国际上广泛认可的实验室管理标准,全称为《检测和校准实验室能力的通用要求》,由国际标准化组织(ISO)和国际电工委员会(IEC)联合发布。以下是对ISO17025最新认证消息及相关内容的归纳…...

ASP.NET Core Web API 控制器
文章目录 一、基类:ControllerBase二、API 控制器类属性三、使用 Get() 方法提供天气预报结果 在深入探讨如何编写自己的 PizzaController 类之前,让我们先看一下 WeatherController 示例中的代码,了解它的工作原理。 在本单元中,…...

RAID5原理简介和相关问题
1、RAID5工作原理 2、RAID5单块硬盘的数据连续吗? 3、RAID5单块硬盘存储的是原始数据,还是异或后的数据? 4、RAID5的分块大小 RAID5的分块大小一般选择4KB到64KB之间较为合适。选择合适的分块大小主要取决于以下几个考量因素࿱…...

技术洞察:如何通过设备标识重置实现AI编程工具的持续高效使用
技术洞察:如何通过设备标识重置实现AI编程工具的持续高效使用 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Your request has been blocked as our system has detected suspicious activity / Youve reached your trial request …...
驱动应用程序设计)
基于STM32LXXX的数字电位器(AD5245BRJZ10-RL7)驱动应用程序设计
一、简介: AD5245是Analog Devices公司生产的一款256-位置、I2C兼容型数字电位器。它主要用于替代机械式电位器,适用于对分辨率、可靠性和温度系数有要求的场合。 二、主要技术特性: 参数 值 抽头数 (Resolution) 256 Positions 端到端电阻 (Resistance) 10 kΩ (型号中的“…...

别再只写CRUD了!用SpringBoot拦截器和自定义注解,给你的课程设计项目加上专业的权限控制
从零构建SpringBoot权限控制系统:拦截器与注解实战指南 每次课程设计答辩现场,总能看到这样的场景:学生演示着千篇一律的增删改查功能,评委老师皱着眉头问"权限控制怎么实现的",然后全场陷入尴尬的沉默。如果…...

AdvancedSessionsPlugin技术深度解析:虚幻引擎分布式会话管理解决方案
AdvancedSessionsPlugin技术深度解析:虚幻引擎分布式会话管理解决方案 【免费下载链接】AdvancedSessionsPlugin Advanced Sessions Plugin for UE4 项目地址: https://gitcode.com/gh_mirrors/ad/AdvancedSessionsPlugin 在虚幻引擎多玩家游戏开发中&#x…...

资源控制与开发者工具:重构网页资源加载的全流程解决方案
资源控制与开发者工具:重构网页资源加载的全流程解决方案 【免费下载链接】ResourceOverride An extension to help you gain full control of any website by redirecting traffic, replacing, editing, or inserting new content. 项目地址: https://gitcode.co…...

Harpy与App Store提交:为什么审核员看不到更新提示的终极指南
Harpy与App Store提交:为什么审核员看不到更新提示的终极指南 【免费下载链接】Harpy Notify users when a new version of your app is available and prompt them to upgrade. 项目地址: https://gitcode.com/gh_mirrors/ha/Harpy Harpy是一个强大的iOS应用…...

MuseTalk技术解析与实践指南:实时高质量AI唇同步视频实现方案
MuseTalk技术解析与实践指南:实时高质量AI唇同步视频实现方案 【免费下载链接】MuseTalk MuseTalk: Real-Time High Quality Lip Synchorization with Latent Space Inpainting 项目地址: https://gitcode.com/gh_mirrors/mu/MuseTalk MuseTalk作为腾讯音乐娱…...

Graphormer效果展示:同一分子不同SMILES写法下的预测一致性验证
Graphormer效果展示:同一分子不同SMILES写法下的预测一致性验证 1. 模型概述 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB(Open Graph Benchmark)和PCQM4M等分子基准测…...

突破硬件限制的开源游戏串流方案:Sunshine跨设备游戏体验指南
突破硬件限制的开源游戏串流方案:Sunshine跨设备游戏体验指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 当你拥有一台高性能游戏PC,却只能在固定位置享…...

实战深度:游戏框架渲染冲突问题全解析与解决方案
实战深度:游戏框架渲染冲突问题全解析与解决方案 【免费下载链接】REFramework Mod loader, scripting platform, and VR support for all RE Engine games 项目地址: https://gitcode.com/GitHub_Trending/re/REFramework 一、问题背景:引擎注入…...