【机器学习(九)】分类和回归任务-多层感知机(Multilayer Perceptron,MLP)算法-Sentosa_DSML社区版 (1)11
文章目录
- 一、算法概念11
- 二、算法原理
- (一)感知机
- (二)多层感知机
- 1、隐藏层
- 2、激活函数
- sigma函数
- tanh函数
- ReLU函数
- 3、反向传播算法
- 三、算法优缺点
- (一)优点
- (二)缺点
- 四、MLP分类任务实现对比
- (一)数据加载和样本分区
- 1、Python代码
- 2、Sentosa_DSML社区版
- (二)模型训练
- 1、Python代码
- 2、Sentosa_DSML社区版
- (三)模型评估和模型可视化
- 1、Python代码
- 2、Sentosa_DSML社区版
- 五、MLP回归任务实现对比
- (一)数据加载和样本分区
- 1、Python代码
- 2、Sentosa_DSML社区版
- (二)模型训练
- 1、Python代码
- 2、Sentosa_DSML社区版
- (三)模型评估和模型可视化
- 1、Python代码
- 2、Sentosa_DSML社区版
- 六、总结
一、算法概念11
什么是多层感知机?
多层感知机 (Multilayer Perceptron,MLP) 是一种人工神经网络,由多层神经元或节点组成,这些神经元或节点以分层结构排列。它是最简单且使用最广泛的神经网络之一,尤其适用于分类和回归等监督学习任务。
多层感知器运作的核心原理在于反向传播,是用于训练网络的关键算法。在反向传播过程中,网络通过将误差从输出层反向传播到输入层来调整其权重和偏差。这个迭代过程可以微调模型的参数,使其能够随着时间的推移做出更准确的预测。
MLP 通常包括以下部分:
输入层:接收输入数据并将其传递到隐藏层。输入层中的神经元数量等于输入特征的数量。
隐藏层:由一层或多层神经元组成,用于执行计算并转换输入数据。可以调整每层 中的隐藏层和神经元的数量,以优化网络性能。
激活函数:对隐藏层中每个神经元的输出应用非线性变换。常见的激活函数包括 Sigmoid、ReLU、tanh 等。
输出层:网络的最终输出,例如分类标签或回归目标。输出层中的神经元数量取决于具体的数据,例如分类问题中的类别数量。
权重和偏差:可调节参数,决定相邻层神经元之间的连接强度以及每个神经元的偏差。这些参数在训练过程中学习,以尽量减少网络预测与实际目标值之间的差异。
损失函数:衡量网络预测与实际目标值之间的差异。MLP 的常见损失函数包括回归任务的均方误差和分类任务的交叉熵。
MLP 使用梯度下降等优化算法反向传播进行训练,根据损失函数的梯度迭代调整权重和偏差。这个过程持续到网络收敛到一组可最小化损失函数的最佳参数。
二、算法原理
(一)感知机
感知机由两层神经元组成,输入层接收外界信号后传递给输出层,如下图所示,

感知机模型就是尝试找到一条直线,能够把所有的二元类别分离开,给定输入 x \mathbf{x} x ,权重 W \mathbf{W} W ,和偏移 b b b ,感知机输出:
o = σ ( ⟨ w , x ⟩ + b ) o=\sigma\left( \langle\mathbf{w}, \mathbf{x} \rangle+b \right) o=σ(⟨w,x⟩+b)
σ ( x ) = { 1 x > 0 − 1 x ≤ 0 \quad\sigma( x )=\left\{\begin{array} {l l} {{1}} & {{\mathrm{~} x > 0}} \\ {{-1}} & {{\mathrm{~} x\leq0}} \\ \end{array} \right. σ(x)={1−1 x>0 x≤0
初始化权重向量 w 和偏置 b,然后对于分类错误的样本不断更新w和b,直到所有样本都被正确分类。等价于使用批量大小为1的梯度下降,并使用如下的损失函数:
ℓ ( y , x , w ) = max ( 0 , − y ⟨ w , x ⟩ ) \ell( y, {\bf x}, {\bf w} )=\operatorname* {m a x} ( 0,-y \langle{\bf w}, {\bf x} \rangle) ℓ(y,x,w)=max(0,−y⟨w,x⟩)
感知机只能产生线性分割面,感知机算法的训练过程如下。

(二)多层感知机
1、隐藏层
多层感知机则是在单层神经网络的基础上引入一个或多个隐藏层,使神经网络有多个网络层,下图为两个多层感知机示意图,分别为单隐层和双隐层


多层感知机中的隐藏层和输出层都是全连接层,输入 X ∈ R n × d X \in\mathbb{R}^{n \times d} X∈Rn×d ,其中, n n n 是批量大小, d d d 是输入特征的数量。输出 O ∈ R n × q O \in\mathbb{R}^{n \times q} O∈Rn×q ,其中 q q q 是输出单元的数量。
设隐藏层有 h h h 个隐藏单元,隐藏层的输出 H H H 是通过输入 X X X 与隐藏层的权重 W h ∈ R d × h W_{h} \in\mathbb{R}^{d \times h} Wh∈Rd×h 和偏置 b h ∈ R 1 × h b_{h} \in\mathbb{R}^{1 \times h} bh∈R1×h 计算得到的: H = X W h + b h H=X W_{h}+b_{h} H=XWh+bh
输出层的权重为 W o ∈ R h × q W_{o} \in\mathbb{R}^{h \times q} Wo∈Rh×q ,偏置为 b o ∈ R 1 × q b_{o} \in\mathbb{R}^{1 \times q} bo∈R1×q 。因此,输出层的输出 O O O 为: O = H W o + b o O=H W_{o}+b_{o} O=HWo+bo
将隐藏层的输出 H H H 代入到输出层的方程中,得到如下计算过程:
O = ( X W h + b h ) W o + b o = X W h W o + b h W o + b o O=( X W_{h}+b_{h} ) W_{o}+b_{o}=X W_{h} W_{o}+b_{h} W_{o}+b_{o} O=(XWh+bh)Wo+bo=XWhWo+bhWo+bo
通过联立后的式子可以看出,尽管引入了隐藏层,模型的计算仍然可以视作单层神经网络,其中,权重矩阵等于 W h W o W_{h} W_{o} WhWo,偏置等于 b h W o + b o b_{h} W_{o}+b_{o} bhWo+bo。
这表示,尽管引入了隐藏层,在不采用非线性激活函数的情况下,这个设计只能等价于单层神经网络。引入隐藏层的真正意义在于通过非线性激活函数(如ReLU、Sigmoid等)来引入复杂的非线性关系,使得模型具备更强的表达能力。
2、激活函数
激活函数是 MLP的关键组成部分。它们将非线性引入网络,使其能够对复杂问题进行建模。如果没有激活函数,无论有多少层,MLP都相当于单层线性模型。
激活函数需要具备以下几点性质:
- 连续并可导(允许少数点上不可导),便于利用数值优化的方法来学习网络参数
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率
- 激活函数的导函数的值域要在合适区间内,不能太大也不能太小,否则会影响训练的效率和稳定性
以下列举常用的三个激活函数
sigma函数
s i g m a ( z ) = 1 1 + exp ( − z ) sigma( z )=\frac{1} {1+\operatorname{e x p} (-z )} sigma(z)=1+exp(−z)1
sigma函数也称为 S \mathrm{S} S 型函数,可以将任何实值数映射到 0 0 0 到 1 1 1 之间的值。呈S形,具有明确定义的非零导数,这使其适合与反向传播算法一起使用。

sigmoid函数的导数表达式为:
s i g m a ′ ( z ) = s i g m a ( z ) × ( 1 − s i g m a ( z ) ) sigma^{\prime} ( z )=sigma( z ) \times( 1-sigma ( z ) ) sigma′(z)=sigma(z)×(1−sigma(z))
如下所示:

tanh函数
tanh ( z ) = 1 − exp ( − 2 z ) 1 + exp ( − 2 z ) \operatorname{t a n h} ( z )=\frac{1-\operatorname{e x p} (-2z )} {1+\operatorname{e x p} (-2z )} tanh(z)=1+exp(−2z)1−exp(−2z)
双曲正切函数与逻辑函数类似,但输出值在-1和 1 1 1 之间。这种居中效果有助于加快训练期间的收敛速度。

tanh导数表达式如下所示:
t a n h ′ ( z ) = 1 − tanh 2 ( z ) tanh^{\prime} ( z)=1-\operatorname{t a n h}^{2} ( z ) tanh′(z)=1−tanh2(z)
下面绘制了tanh函数的导数。当输入为0时,tanh函数的导数达到最大值1;当输入越偏离0时,tanh函数的导数越接近0。

ReLU函数
R e L U ( z ) = max ( 0 , z ) \mathrm{R e L U} ( z )=\operatorname* {m a x} ( 0, z ) ReLU(z)=max(0,z)
ReLU 函数因其简单性和有效性而被广泛应用于深度学习。如果输入值为正,则输出输入值;否则输出零。尽管 ReLU 在零处不可微,并且对于负输入具有零梯度,但它在实践中表现良好,有助于缓解梯度消失问题

当输入为负数时,ReLU函数的导数为0;当输入为正数时,ReLU函数的导数为1,
ReLU 函数的导数表达式为:
R e L U ′ ( z ) = { 1 i f z > 0 0 i f z ≤ 0 R e L U^{\prime} ( z )=\begin{cases} {{1}} & {{\mathrm{i f ~} z > 0}} \\ {{0}} & {{\mathrm{i f ~} z \leq0}} \\ \end{cases} ReLU′(z)={10if z>0if z≤0
下面绘制ReLU函数的导数,

3、反向传播算法
1、前向传播
前向传播是反向传播的前提。在前向传播过程中,数据从输入层逐步传递至输出层,经过每一层的计算,最终得到预测输出。
具体步骤如下:
1、输入数据传递给神经网络的输入层。
2、输入层经过一系列权重(W)和偏置(b)的线性运算,然后通过激活函数传递到隐藏层。
3、逐层传递,直至数据到达输出层,输出层生成预测值 y ^ \hat{y} y^ 。
表达式如下:
y ^ = f ( W 3 ⋅ f ( W 2 ⋅ f ( W 1 ⋅ x + b 1 ) + b 2 ) + b 3 ) \hat{y}=f ( W_{3} \cdot f ( W_{2} \cdot f ( W_{1} \cdot x+b_{1} )+b_{2} )+b_{3} ) y^=f(W3⋅f(W2⋅f(W1⋅x+b1)+b2)+b3)
其中, W 1 , W 2 , W 3 W_{1}, W_{2}, W_{3} W1,W2,W3 是权重矩阵, b 1 , b 2 , b 3 b_{1}, b_{2}, b_{3} b1,b2,b3 是偏置, f ( ⋅ ) f ( \cdot) f(⋅) 是激活函数。
2、 损失函数
在得到输出后,通过损失函数计算预测结果与真实标签之间的误差,常见的损失函数有:
MSE(均方误差):通常用于回归问题,输出与标签之差的平方的均值。计算公式如下:
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE=\frac{1} {n} \sum_{i=1}^{n} ( y_{i}-\hat{y}_{i} )^{2} MSE=n1i=1∑n(yi−y^i)2
其中, y i y_{i} yi 是真实值, y ^ i \hat{y}_{i} y^i 是预测值, n n n 是样本数量。
CE(交叉熵损失):通常用于回归问题。计算公式如下:
H ( p , q ) = − ∑ i = 1 n p ( x i ) log q ( x i ) H(p,q)=-\sum_{i=1}^{n}p(x_{i}) \operatorname{log}q(x_{i}) H(p,q)=−i=1∑np(xi)logq(xi)
其中, p ( x i ) p ( x_{i} ) p(xi) 是真实分布, q ( x i ) q ( x_{i} ) q(xi) 是预测分布。
3、反向传播
反向传播根据微积分中的链式规则,按相反的顺序从输入层遍历网络。用于权重更新,使网络输出更接近标签。
假设有两个函数 y = f ( u ) y=f ( u ) y=f(u) 和 u = g ( x ) u=g ( x ) u=g(x) ,根据链式法则, y y y 对 x x x 的导数为:
∂ y ∂ x = ∂ y ∂ u ∂ u ∂ x \frac{\partial y} {\partial x}=\frac{\partial y} {\partial u} \frac{\partial u} {\partial x} ∂x∂y=∂u∂y∂x∂u
在神经网络中,损失函数 L L L 对某一层权重 W W W 的导数可以通过链式法则分解为:
∂ L ∂ W = ∂ L ∂ y ⋅ ∂ y ∂ W \frac{\partial L} {\partial W}=\frac{\partial L} {\partial y} \cdot\frac{\partial y} {\partial W} ∂W∂L=∂y∂L⋅∂W∂y
4、梯度下降
在反向传播过程中,利用梯度下降算法来更新权重,使得损失函数的值逐渐减小。权重更新的公式为:
W ( h ) = W ( o ) − η ⋅ ∂ L ∂ W W^{(h )}=W^{( o )}-\eta\cdot\frac{\partial L} {\partial W} W(h)=W(o)−η⋅∂W∂L
其中, η \eta η 是学习率,决定了每次权重调整的步长大小, ∂ L ∂ W \frac{\partial L} {\partial W} ∂W∂L 是损失函数相对于权重的梯度。
三、算法优缺点
(一)优点
可以通过多个隐藏层和非线性激活函数,学习到更复杂的特征表示,从而提高模型的表达能力。
可以用于分类、回归和聚类等各种机器学习任务,目在许多领域中取得了很好的效果。
可以诵过并行计算和GPU加速等技术,高效地处理大规模数据集,适用于大规模深度学习应用。
(二)缺点
参数较多,容易在训练集上过拟合,需要采取正则化、dropout等方法来缓解过拟合问题。
通常需要大量的标记数据进行训练,并且在训练过程中需要较高的计算资源,包括内存和计算
能力。
MLP的性能很大程度上依赖于超参数的选择。
四、MLP分类任务实现对比
(一)数据加载和样本分区
1、Python代码
from sklearn.datasets import load_iris# 加载iris数据集
iris = load_iris()
X, y = iris['data'], iris['target']# 样本分区
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2、Sentosa_DSML社区版
首先,利用数据读入中的文本算子对数据进行读取,

然后连接样本分区算子划分训练集和测试集,

再接类型算子,设置Feature列和Label列,

(二)模型训练
1、Python代码
使用sklearn自动构建MLP模型
from sklearn.neural_network import MLPClassifier# 定义MLP分类器模型,使用l-bfgs优化算法,隐藏层设置为100, 50,最大迭代次数200,设置tol为0.000001
mlp_clf = MLPClassifier(hidden_layer_sizes=(100, 50), max_iter=200, alpha=1e-4,solver='lbfgs', tol=1e-6, random_state=42)
# 训练模型
mlp_clf.fit(X_train, y_train)# 预测训练集和测试集
y_train_pred = mlp_clf.predict(X_train)
y_test_pred = mlp_clf.predict(X_test)
2、Sentosa_DSML社区版
连接多层感知机分类算子,右击算子,点击运行,可以得到多层感知机分类模型。右侧进行超参数等设置,隐藏层设置为(100, 50),使用l-bfgs优化算法,最大迭代次数200,设置收敛偏差为0.000001。

(三)模型评估和模型可视化
1、Python代码
from sklearn.metrics import accuracy_score, precision_recall_fscore_support# 计算训练集评估指标
accuracy_train = accuracy_score(y_train, y_train_pred)
precision_train, recall_train, f1_train, _ = precision_recall_fscore_support(y_train, y_train_pred, average='weighted')# 计算测试集评估指标
accuracy_test = accuracy_score(y_test, y_test_pred)
precision_test, recall_test, f1_test, _ = precision_recall_fscore_support(y_test, y_test_pred, average='weighted')# 输出训练集评估指标
print(f"Training Set Metrics:")
print(f"Accuracy: {accuracy_train * 100:.2f}%")
print(f"Weighted Precision: {precision_train:.2f}")
print(f"Weighted Recall: {recall_train:.2f}")
print(f"Weighted F1 Score: {f1_train:.2f}")# 输出测试集评估指标
print(f"\nTest Set Metrics:")
print(f"Accuracy: {accuracy_test * 100:.2f}%")
print(f"Weighted Precision: {precision_test:.2f}")
print(f"Weighted Recall: {recall_test:.2f}")
print(f"Weighted F1 Score: {f1_test:.2f}")from sklearn.metrics import confusion_matrix# 计算测试集的混淆矩阵
conf_matrix = confusion_matrix(y_test, y_test_pred)import matplotlib.pyplot as plt
from sklearn.inspection import permutation_importance# 使用 sklearn 提供的permutation_importance方法计算特征重要性
result = permutation_importance(mlp_clf, X_test, y_test, n_repeats=10, random_state=42)# 可视化特征重要性
plt.figure(figsize=(8, 6))
plt.barh(range(X.shape[1]), result.importances_mean, align='center')
plt.yticks(np.arange(X.shape[1]), iris['feature_names'])
plt.xlabel('Mean Importance Score')
plt.title('Permutation Feature Importance')
plt.show()

2、Sentosa_DSML社区版
模型后可以连接评估算子,对模型的分类结果进行评估。算子流如下图所示,

执行完成后可以得到训练集和测试集的评估,评估结果如下:


右击模型,查看模型的模型信息,如下所示:

五、MLP回归任务实现对比
(一)数据加载和样本分区
1、Python代码
# 读入winequality数据集
df = pd.read_csv("D:/sentosa_ML/Sentosa_DSML/mlServer/TestData/winequality.csv")# 将数据集划分为特征和标签
X = df.drop("quality", axis=1) # 特征,假设标签是 "quality"
Y = df["quality"] # 标签# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
2、Sentosa_DSML社区版
首先通过数据读入算子读取数据,

中间接样本分区算子对训练集和测试集进行划分,

然后接类型算子,设置Feature列和Label列,

(二)模型训练
1、Python代码
使用 scikit-learn 库中的多层感知机回归模型(MLPRegressor)
# 对数据进行标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 定义MLP回归模型,使用l-bfgs优化算法,隐藏层设置为50,10,最大迭代次数300,设置tol为0.000001
mlp_reg = MLPRegressor(hidden_layer_sizes=(50, 10), solver='lbfgs', max_iter=300, tol=1e-6, random_state=42)# 训练模型
mlp_reg.fit(X_train_scaled, y_train)
2、Sentosa_DSML社区版
连接标准化算子,对数据特征进行标准化计算,并执行得到标准化模型,

其次,连接多层感知机回归算子,右击执行得到多层感知机回归模型。模型训练使用l-bfgs优化算法,隐藏层设置为50,10,最大迭代次数300,设置收敛偏差为0.000001,并选择计算特征重要性等。

(三)模型评估和模型可视化
1、Python代码
# 训练集上的评估
y_train_pred = mlp_reg.predict(X_train_scaled)r2_train = r2_score(y_train, y_train_pred)
mae_train = mean_absolute_error(y_train, y_train_pred)
mse_train = mean_squared_error(y_train, y_train_pred)
rmse_train = np.sqrt(mse_train)
mape_train = np.mean(np.abs((y_train - y_train_pred) / y_train)) * 100
smape_train = 100 / len(y_train) * np.sum(2 * np.abs(y_train - y_train_pred) / (np.abs(y_train) + np.abs(y_train_pred)))# 测试集上的评估
y_test_pred = mlp_reg.predict(X_test_scaled)r2_test = r2_score(y_test, y_test_pred)
mae_test = mean_absolute_error(y_test, y_test_pred)
mse_test = mean_squared_error(y_test, y_test_pred)
rmse_test = np.sqrt(mse_test)
mape_test = np.mean(np.abs((y_test - y_test_pred) / y_test)) * 100
smape_test = 100 / len(y_test) * np.sum(2 * np.abs(y_test - y_test_pred) / (np.abs(y_test) + np.abs(y_test_pred)))# 输出训练集评估指标
print(f"Training Set Metrics:")
print(f"R²: {r2_train:.2f}")
print(f"MAE: {mae_train:.2f}")
print(f"MSE: {mse_train:.2f}")
print(f"RMSE: {rmse_train:.2f}")
print(f"MAPE: {mape_train:.2f}%")
print(f"SMAPE: {smape_train:.2f}%")# 输出测试集评估指标
print(f"\nTest Set Metrics:")
print(f"R²: {r2_test:.2f}")
print(f"MAE: {mae_test:.2f}")
print(f"MSE: {mse_test:.2f}")
print(f"RMSE: {rmse_test:.2f}")
print(f"MAPE: {mape_test:.2f}%")
print(f"SMAPE: {smape_test:.2f}%")# 计算残差
residuals = y_test - y_test_pred# 使用 Seaborn 绘制带核密度估计的残差直方图
plt.figure(figsize=(8, 6))
sns.histplot(residuals, kde=True, bins=20)
plt.title('Residuals Histogram with KDE')
plt.xlabel('Residuals')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()

2、Sentosa_DSML社区版
模型后可接评估算子,对模型的回归结果进行评估。

训练集和测试集的评估结果如下所示:


右键查看模型信息,可以得到特征重要性等可视化计算结果。



六、总结
相比传统代码方式,利用Sentosa_DSML社区版完成机器学习算法的流程更加高效和自动化,传统方式需要手动编写大量代码来处理数据清洗、特征工程、模型训练与评估,而在Sentosa_DSML社区版中,这些步骤可以通过可视化界面、预构建模块和自动化流程来简化,有效的降低了技术门槛,非专业开发者也能通过拖拽和配置的方式开发应用,减少了对专业开发人员的依赖。
Sentosa_DSML社区版提供了易于配置的算子流,减少了编写和调试代码的时间,并提升了模型开发和部署的效率,由于应用的结构更清晰,维护和更新变得更加容易,且平台通常会提供版本控制和更新功能,使得应用的持续改进更为便捷。
Sentosa数据科学与机器学习平台(Sentosa_DSML)是力维智联完全自主知识产权的一站式人工智能开发部署应用平台,可同时支持零代码“拖拉拽”与notebook交互式开发,旨在通过低代码方式帮助客户实现AI算法模型的开发、评估与部署,结合完善的数据资产化管理模式与开箱即用的简捷部署支持,可赋能企业、城市、高校、科研院所等不同客户群体,实现AI普惠、化繁为简。
Sentosa_DSML产品由1+3个平台组成,以数据魔方平台(Sentosa_DC)为主管理平台,三大功能平台包括机器学习平台(Sentosa_ML)、深度学习平台(Sentosa_DL)和知识图谱平台(Sentosa_KG)。力维智联凭借本产品入选“全国首批人工智能5A等级企业”,并牵头科技部2030AI项目的重要课题,同时服务于国内多家“双一流”高校及研究院所。
为了回馈社会,矢志推动全民AI普惠的实现,不遗余力地降低AI实践的门槛,让AI的福祉惠及每一个人,共创智慧未来。为广大师生学者、科研工作者及开发者提供学习、交流及实践机器学习技术,我们推出了一款轻量化安装且完全免费的Sentosa_DSML社区版软件,该软件包含了Sentosa数据科学与机器学习平台(Sentosa_DSML)中机器学习平台(Sentosa_ML)的大部分功能,以轻量化一键安装、永久免费使用、视频教学服务和社区论坛交流为主要特点,同样支持“拖拉拽”开发,旨在通过零代码方式帮助客户解决学习、生产和生活中的实际痛点问题。
该软件为基于人工智能的数据分析工具,该工具可以进行数理统计与分析、数据处理与清洗、机器学习建模与预测、可视化图表绘制等功能。为各行各业赋能和数字化转型,应用范围非常广泛,例如以下应用领域:
金融风控:用于信用评分、欺诈检测、风险预警等,降低投资风险;
股票分析:预测股票价格走势,提供投资决策支持;
医疗诊断:辅助医生进行疾病诊断,如癌症检测、疾病预测等;
药物研发:进行分子结构的分析和药物效果预测,帮助加速药物研发过程;
质量控制:检测产品缺陷,提高产品质量;
故障预测:预测设备故障,减少停机时间;
设备维护:通过分析机器的传感器数据,检测设备的异常行为;
环境保护:用于气象预测、大气污染监测、农作物病虫害防止等;
客户服务:通过智能分析用户行为数据,实现个性化客户服务,提升用户体验;
销售分析:基于历史数据分析销量和价格,提供辅助决策;
能源预测:预测电力、天然气等能源的消耗情况,帮助优化能源分配和使用;
智能制造:优化生产流程、预测性维护、智能质量控制等手段,提高生产效率。
欢迎访问Sentosa_DSML社区版的官网https://sentosa.znv.com/,免费下载体验。同时,我们在B站、CSDN、知乎、博客园等平台有技术讨论博客和应用案例分享,欢迎广大数据分析爱好者前往交流讨论。
Sentosa_DSML社区版,重塑数据分析新纪元,以可视化拖拽方式指尖轻触解锁数据深层价值,让数据挖掘与分析跃升至艺术境界,释放思维潜能,专注洞察未来。
社区版官网下载地址:https://sentosa.znv.com/
社区版官方论坛地址:http://sentosaml.znv.com/
B站地址:https://space.bilibili.com/3546633820179281
CSDN地址:https://blog.csdn.net/qq_45586013?spm=1000.2115.3001.5343
知乎地址:https://www.zhihu.com/people/kennethfeng-che/posts
博客园地址:https://www.cnblogs.com/KennethYuen

相关文章:
【机器学习(九)】分类和回归任务-多层感知机(Multilayer Perceptron,MLP)算法-Sentosa_DSML社区版 (1)11
文章目录 一、算法概念11二、算法原理(一)感知机(二)多层感知机1、隐藏层2、激活函数sigma函数tanh函数ReLU函数 3、反向传播算法 三、算法优缺点(一)优点(二)缺点 四、MLP分类任务实…...

32位MCU主控智能电表方案
智能电表作为电网数据采集的核心设备,承担着至关重要的角色。它主要用于采集、计量和传输原始的电能数据,确保电力系统的高效运行。该设备配备了多种通讯接口,如RS485和以太网,使得用户能够轻松进行用电检测、集中抄表以及电力管理…...

ConstraintLayout是完美的布局吗?
非也! <TextViewandroid:id"id/tv_tittle_msg"android:layout_width"wrap_content"android:layout_height"wrap_content"android:layout_marginLeft"16dp"android:layout_marginRight"16dp"android:layout_ma…...

39.在 Vue3 中使用 OpenLayers 导出 GeoJSON 文件及详解 GEOJSON 格式
一、引言 在 Web 地图开发领域,Vue3 作为一款流行的前端框架,结合强大的 OpenLayers 地图库,能够实现丰富多样的地图功能。其中,将地图数据以 GeoJSON 格式导出是一项常见且实用的需求,本文将深入探讨如何在 Vue3 环境…...

Feign的调用demo 和 EnableFeignClients的包名
在你的场景下,如果刷题微服务通过 Maven 引入了 auth-api 模块,并且 auth-api 中定义了 Feign 接口(例如获取用户名的方法),你需要在 刷题微服务 中的启动类上配置 EnableFeignClients 注解。配置中 basePackages 参数…...

简化开发流程:如何通过 JDBC 自动生成符合 Java 命名规范的实体类
在这篇博客中,我分享了如何通过 Java 和 JDBC 自动生成数据库实体类的过程。通常,手动编写实体类代码既繁琐又容易出错,尤其是在数据库表结构发生变化时,手动更新代码的工作量非常大。为了提高开发效率,我利用 JDBC 连…...

W25Q128存储器详解
可能有很多小伙伴对 W25Q128 感到陌生,说白了它就是一个存储芯片。它是一款高性能、容量较大的闪存存储器芯片,通过 SPI 接口进行通信,适用于各种需要高速、大容量数据存储的场合。常用于嵌入式系统中,作为程序代码存储器或配置数…...
)
Vite系列课程 | 11. Vite 配置文件中 CSS 配置(Modules 模块化篇)
11. Vite 配置文件中 CSS 配置(Modules 模块化篇) 由于课程讲的是 vite2 版本,所以我阅读了 vite6 中的文档,下面将结合 css.modules 的接口进行讲解 CSSModulesOptions 接口文档 interface CSSModulesOptions {/*** 用户可以自…...

Everspin代理MR25H10CDFR存储MRAM
RAMSUN提供的MR25H10CDFR是一款具备1,048,576位存储容量的磁阻随机存取存储器(MRAM)设备,由131,072个8位字构成。该设备提供与串行EEPROM和串行闪存兼容的读/写时序,无写延迟,并且其读/写寿命是不受限制的。 与其它串…...

cesium小知识:使用 EntityCollection的方法
EntityCollection 是 Cesium 中用于管理一组 Entity 的集合对象。它提供了一种高效的方式来批量添加、移除和操作多个实体,同时支持事件监听,以便在集合中的实体发生变化时执行特定的逻辑。 下面是如何使用 EntityCollection 的一些基本指导: 创建 EntityCollection 当你…...

Java 日志类库
Java 日志库是最能体现 Java 库在进化中的渊源关系的,在理解时重点理解日志框架本身和日志门面,以及比较好的时间等。要关注其历史渊源和设计(比如桥接),而具体在使用时查询接口即可,否则会陷入 JUL&#x…...

【Unity3D】Particle粒子特效或3D物体显示在UGUI上的方案
目录 一、RawImage Camera RenderTexture方式 (1)扩展知识:实现射线检测RawImage内的3D物体 (2)扩展知识:实现粒子特效显示RawImage上 二、UI摄像机 Canvas(Screen Space - Camera模式)方式 &#…...

有没有检测吸烟的软件 ai视频检测分析厂区抽烟报警#Python
在现代厂区管理中,安全与规范是重中之重,而吸烟行为的管控则是其中关键一环。传统的禁烟管理方式往往依赖人工巡逻,效率低且存在监管死角,难以满足当下复杂多变的厂区环境需求。此时,AI视频检测技术应运而生࿰…...

《鸣潮》游戏运行时弹出“xinput1_3.dll文件缺失”错误的处理方法,“xinput1_3.dll文件缺失”详解!
一、xinput1_3.dll文件的重要性 xinput1_3.dll是DirectX组件中的一个重要文件,它负责处理与Xbox 360控制器相关的输入功能。尽管《鸣潮》可能并不直接依赖于Xbox控制器,但许多现代游戏和应用程序都会调用这个DLL文件来处理各种输入设备的功能。因此&…...

大模型应用—HivisionIDPhotos 证件照在线制作!支持离线、换装、美颜等
HivisionIDPhotos 证件照在线制作!支持离线、换装、美颜等 ivisionIDPhotos 是一款功能强大的开源证件照生成工具。用户只需上传一张人像照片,它就能智能裁剪为一寸、两寸等标准尺寸,同时自动去除背景并渲染新的背景颜色,例如蓝色、白色、红色,还支持渐变色和自定义颜色。…...
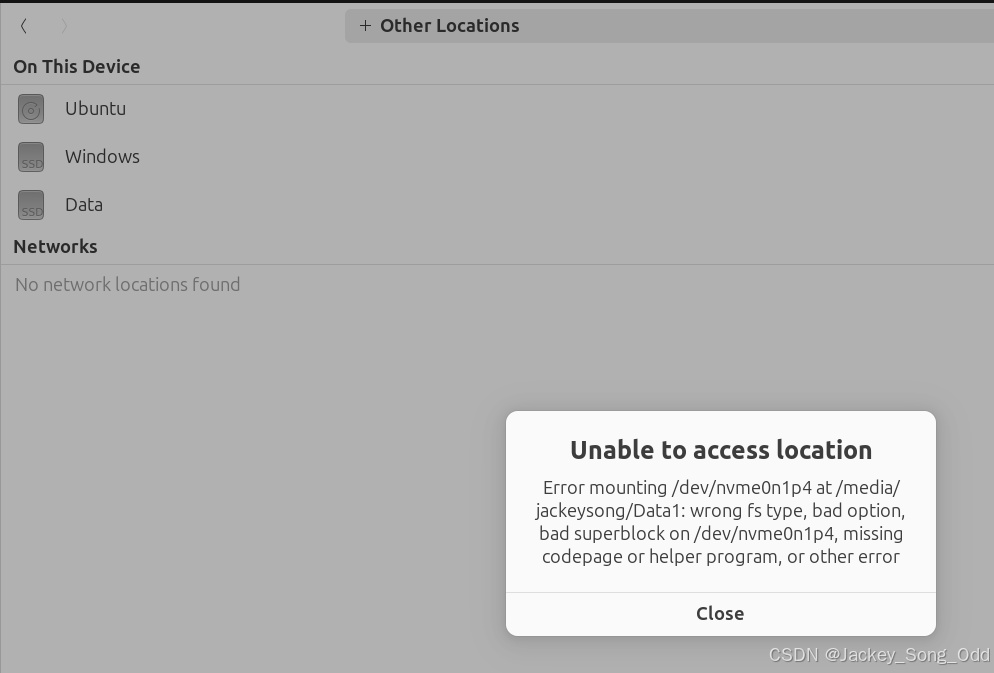
解决Ubuntu下无法装载 Windows D盘的问题
电脑安装了 Windows 和 Ubuntu 24.04 后,在Ubuntu系统上装载 D盘,发现无法装载错误如下: Error mounting /dev/nvme0n1p4 at /media/jackeysong/Data: wrong fs type, bad option, bad superblock on /dev/nvme0n1p4, missing codepage or h…...

一体成型电感
一体成型电感是通过铁粉模压成型而成的同封装条件下实现更大的额定电流,且更适合批量自动化生产,较传统绕线电感有成本优势。同时,一体成型电感与磁封胶结构电感相比具有更好的磁屏蔽效果,适合EMI无法调试通过的项目使用。 但一体…...
码之编码)
Reed-Muller(RM)码之编码
点个关注吧! 看了一些中文的博客,RM码没有很详细的资料,所以本文尝试给出推导原理。 推导 RM码由 ( r , m ) ( r , m ) (r,m...

【蓝桥杯——物联网设计与开发】基础模块8 - RTC
目录 一、RTC (1)资源介绍 🔅简介 🔅时钟与分频(十分重要‼️) (2)STM32CubeMX 软件配置 (3)代码编写 (4)实验现象 二、RTC接口…...

聚类算法DBSCAN 改进总结
目录 DBSCAN(Density-Based Spatial Clustering of Applications with Noise) 1. HDBSCAN (Hierarchical DBSCAN) 优点: 安装: 使用实例1 效果失败 使用实例2 3. DBSCAN++ (DBSCAN with Preprocessing) 4. DBSCAN with k-distance 5. Density Peaks Clustering (DP…...

Unity发布京东小游戏反
从 UI 工程师到 AI 应用架构者 13 年前,我的工作是让按钮在 IE6 上对齐; 13 年后,我用 fetch-event-source 订阅大模型的“思维流”,用 OCR 解锁图片中的文字——前端,正在成为 AI 产品的第一道体验防线。 最近&#x…...
:日志落地与文件轮询机制)
从零实现高性能日志系统(二):日志落地与文件轮询机制
在上一篇(Ubuntu虚拟机下基于C实现带时间戳的日志系统(CMake构建完整版))文章中,我们完成了日志系统的基础架构搭建,实现了日志级别控制、日志格式化输出等核心能力,但此时日志还仅停留在内存层…...

STM32F103C8T6:基于蓝牙指令的舵机角度精确控制
1. 项目背景与应用场景 想象一下这样的场景:早晨醒来,你躺在床上一键遥控窗帘缓缓打开到45度角,让阳光刚好洒在床脚;或者通过手机APP远程调节摄像头云台,让监控视角精确对准门口快递柜。这些看似简单的智能家居功能&am…...

Python生产级日志封装完整解析_细节决定一切
logging等级 try:1 / 0 except Exception as e:logger.exception("计算错误")""" ERROR:test:计算错误 Traceback (most recent call last):File "test.py", line 6, in <module>1 / 0 ZeroDivisionError: division by zero没有堆栈信…...

比迪丽LoRA部署教程:WSL2+Windows本地GPU环境全适配方案
比迪丽LoRA部署教程:WSL2Windows本地GPU环境全适配方案 你是不是也想在本地电脑上运行AI绘画,生成自己喜欢的动漫角色?特别是像《龙珠》里的比迪丽这样的经典角色,如果能用自己的电脑随时生成,那该多方便。 今天我就…...

如何用Python+Neo4j构建医疗知识图谱?从数据清洗到因果推断实战
医疗知识图谱实战:用PythonNeo4j实现药品副作用因果推断 在医疗AI领域,知识图谱正成为连接海量医学数据与临床决策的桥梁。当一位患者同时服用多种药物时,如何准确预测潜在的药物相互作用?当流行病学研究发现某种症状与基因突变相…...
)
Docker数据迁移到新磁盘的5个常见坑及解决方案(附详细步骤)
Docker数据迁移到新磁盘的5个常见坑及解决方案(附详细步骤) 当你发现服务器上的Docker容器运行越来越慢,或者频繁出现"no space left on device"的错误时,数据迁移就成了迫在眉睫的任务。作为一名经历过数十次Docker迁移…...

Arduino Nano + A4988驱动42步进电机:从接线到代码的完整避坑指南
Arduino Nano与A4988驱动42步进电机实战指南 刚拿到Arduino Nano和A4988驱动板时,看着那些密密麻麻的引脚和电机线缆,不少初学者都会感到无从下手。步进电机控制看似简单,但实际搭建时总会遇到各种意想不到的问题——电机抖动不转、方向控制失…...

RAGflow 0.22.2 依赖镜像构建避坑指南:解决libssl缺失与HuggingFace下载难题
RAGflow 0.22.2 依赖镜像构建实战:从libssl缺失到HuggingFace模型下载的完整解决方案 在构建RAGflow 0.22.2自定义镜像的过程中,依赖镜像ragflow_deps的构建往往是第一个拦路虎。许多开发者在这里遭遇了各种意料之外的问题,从Ubuntu源中消失的…...

从电压比较器到超级电容:DyingGasp掉电检测电路的设计与调优
1. DyingGasp功能的核心价值与应用场景 想象一下你正在视频会议中突然断电,对方只会看到你突然消失的画面,完全不知道发生了什么。而在通信设备的世界里,这种"突然失联"会给整个系统带来更多麻烦。DyingGasp(临终喘息&a…...