一个从oracle使用spool导出数据到kadb的脚本
1. dump_data.sh调用sql_dump.sh导出数据
2. load_data.sh将导出的数据加载至KADB
1. dump_data.sh
#!/bin/bash
begin_time=$(date +%Y%m%d -d '-1 day')
end_time=$(date +%Y%m%d)
echo "数据导出日期:"$begin_time
echo "数据导出日期:"$begin_time >> .//log/dump_data_$begin_time.log
echo "数据导出终止日期:"$end_time
echo "数据导出终止日期:"$end_time >> .//log/dump_data_$begin_time.log
while read LINE
do
echo "表名:"$LINE
echo "表名:"$LINE >> .//log/dump_data_$begin_time.log
echo "执行参数: 表名 导出类型 开始时间 结束时间: "$LINE $begin_time $end_time
echo "执行参数: 表名 导出类型 开始时间 结束时间: "$LINE $begin_time $end_time >> .//log/dump_data_$begin_time.log
echo "./sql_dump.sh $LINE $begin_time $end_time"
echo [`date +%Y-%m-%d_%H:%M:%S`]"执行导出操作:./sql_dump.sh $LINE $begin_time $end_time"
echo [`date +%Y-%m-%d_%H:%M:%S`]"执行导出操作:./sql_dump.sh $LINE $begin_time $end_time" >> .//log/dump_data_$begin_time.log
while [[ 1==1 ]]
do
echo '检查当前export进程数......'
echo '检查当前export进程数......' >> .//log/dump_data_$begin_time.log
sleep 2
ips=`ps -ef | grep -v grep| grep sql_dump | wc -l`
echo 当前export进程数: $ips
echo 当前export进程数: $ips >> .//log/dump_data_$begin_time.log
if [ ${ips} -ge 4 ];then
sleep 2
else
#nohup sh ./sql_dump.sh $LINE $begin_time $end_time > .//"${LINE%% *}_`date +%Y%m%d`".log 2>&1 &
nohup sh ./sql_dump.sh $LINE $begin_time $end_time >> .//log/dump_data_$begin_time.log 2>&1 &
break;
fi
done
done < table.lst
2. sql_dump.sh
test=$1
flag=$2
begin_time=$3
end_time=$4
line=`wc -l $test.sql | cut -d ' ' -f 1`
export line
#echo 表名:$test 导出类型:$flag 列数:$line
echo 表名:$test 导出类型:$flag 列数:$line >> .//log/dump_data_$begin_time.log
if [ $flag = 'E' ];then
# echo 当前表导出类型:$flag
#echo 当前表导出类型:$flag >> .//log/"${test}_$begin_time".log
awk -v line="$line" 'BEGIN{sql="select "}{if(NR<line){if($2~/char/){sql='sql'"replace("$1",chr(10),'\'''\'')\n""||'\'''\''||"}else{sql='sql'$1"||'\'''\''||"}}else{if($2~/char/){sql='sql'"replace("$1",chr(10),'\'''\'')"}else{sql='sql'$1}}}END{print 'sql'" from ""'$test'"" where fd_ie_flag=""'\''""'$flag'""'\''"" and fd_cus_release_time >= to_date(""'\''""'$begin_time'""'\'','\''yyyymmdd'\'')"" and fd_cus_release_time < to_date(""'\''""'$end_time'""'\'','\''yyyymmdd'\'')"";"}' ${test}.sql > ${test}_E.out
cat ${test}_E.out
# echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test开始导出数据
echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test开始导出数据 >> .//log/dump_data_$begin_time.log
sqlplus -s / as sysdba << EOF
set trimspool on;
set heading off;
set term off;
set feedback off;
set echo off;
SET SQLPROMPT "";
SET NEWPAGE NONE;
spool /home/oracle/${test}_E_${begin_time}.txt
@ ${test}_E.out
spool off;
set SQLPROMPT "SQL>";
exit;
EOF
touch ${test}_E_${begin_time}.done
# echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test导出数据完成
echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test导出数据完成 >> .//log/dump_data_$begin_time.log
chmod 777 /home/oracle/${test}_E_${begin_time}.txt
elif [ $flag = 'I' ];then
echo 当前表导出类型:$flag
# echo 当前表导出类型:$flag >> .//"${test}_$begin_time".log
awk -v line="$line" 'BEGIN{sql="select "}{if(NR<line){if($2~/char/){sql='sql'"replace("$1",chr(10),'\'''\'')\n""||'\'''\''||"}else{sql='sql'$1"||'\'''\''||"}}else{if($2~/char/){sql='sql'"replace("$1",chr(10),'\'''\'')"}else{sql='sql'$1}}}END{print 'sql'" from ""'$test'"" where fd_ie_flag=""'\''""'$flag'""'\''"" and fd_cus_clear_time >= to_date(""'\''""'$begin_time'""'\'','\''yyyymmdd'\'')"" and fd_cus_clear_time < to_date(""'\''""'$end_time'""'\'','\''yyyymmdd'\'')"";"}' ${test}.sql > ${test}_I.out
cat ${test}_I.out
# echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test开始导出数据
echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test开始导出数据 >> .//log/dump_data_$begin_time.log
sqlplus -s / as sysdba << EOF
set trimspool on;
set heading off;
set term off;
set feedback off;
set echo off;
SET SQLPROMPT "";
SET NEWPAGE NONE;
spool /home/oracle/${test}_I_${begin_time}.txt
@ ${test}_I.out
spool off;
set SQLPROMPT "SQL>";
exit;
EOF
touch ${test}_I_${begin_time}.done
# echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test导出数据完成
echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test导出数据完成 >> .//log/dump_data_$begin_time.log
chmod 777 /home/oracle/${test}_I_${begin_time}.txt
else
echo 当前表导出类型:$flag
echo 当前表导出类型:$flag >> .//"${test}_$begin_time".log
awk -v line="$line" 'BEGIN{sql="select "}{if(NR<line){if($2~/char/){sql='sql'"replace("$1",chr(10),'\'''\'')\n""||'\'''\''||"}else{sql='sql'$1"||'\'''\''||"}}else{if($2~/char/){sql='sql'"replace("$1",chr(10),'\'''\'')"}else{sql='sql'$1}}}END{print 'sql'" from ""'$test'"" where fd_cus_release_time >= to_date(""'\''""'$begin_time'""'\'','\''yyyymmdd'\'')"" and fd_cus_release_time < to_date(""'\''""'$end_time'""'\'','\''yyyymmdd'\'')"";"}' ${test}.sql > ${test}.out
cat ${test}.out
# echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test开始导出数据
echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test开始导出数据 .//log/dump_data_$begin_time.log
sqlplus -s / as sysdba << EOF
set trimspool on;
set heading off;
set term off;
set feedback off;
set echo off;
SET SQLPROMPT "";
SET NEWPAGE NONE;
spool /home/oracle/${test}_${begin_time}.txt
@ $test.out
spool off;
set SQLPROMPT "SQL>";
exit;
EOF
touch ${test}_${begin_time}.done
# echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test导出数据完成
echo [`date +%Y-%m-%d_%H:%M:%s`]..表$test导出数据完成 .//log/dump_data_$begin_time.log
chmod 777 /home/oracle/${test}_${begin_time}.txt
fi
3. load_data.sh
#!/bin/bash
begin_time=$(date +%Y%m%d -d '-1 day')
end_time=$(date +%Y%m%d)
echo 导入开始日期: $begin_time
echo 导入结束日期: $end_time
WORKPATH=`dirname $0`
get_port()
{
kbport=$1
while [ $kbport -le 50000 ]
do
/usr/sbin/lsof -i:$kbport > /dev/null
if [ $? -eq 1 ]
then
echo $kbport
break
else
let kbport+=2
fi
done
}
while read LINE
do
#echo 表名: $LINE
type=${LINE##* }
if [ $type = 'O' ];then
table_name=${LINE%% *}
else
table_name=${LINE%% *}_$type
fi
echo 待导入表: $table_name
KB_PORT=`get_port 40000` #获取gpfdist可用的端口
while true
do
/usr/sbin/lsof -i:${KB_PORT}
if [ $? -eq 1 ]
then
if [ ! -d $WORKPATH/${KB_PORT} ];
then
mkdir $WORKPATH/${KB_PORT}
if [ $? -ne 0 ];then
echo $KB_PORT端口已经被使用
let KB_PORT+=2
KB_PORT=`get_port $KB_PORT`
continue;
fi
if [[ "$table_name" =~ _I$ ]];then
table_name_r=${table_name%_*}
echo $table_name_r
sed -e "s#THISISDATADIRECTORY#\./${table_name}_${begin_time}.txt#g;s#zhuyongzhuyong#${table_name_r}#g;s/KBPORT/${KB_PORT}/g;s/EXECSQLSTAT/delete from ${table_name_r} where fd_ie_flag='I' and fd_cus_clear_time >= to_date('${begin_time}','yyyymmdd') and fd_cus_clear_time < to_date('${end_time}','yyyymmdd');/g" z.mod > $table_name.yml
cat $table_name.yml
break;
elif [[ "$table_name" =~ _E$ ]]; then
table_name_r=${table_name%_*}
echo $table_name_r
sed -e "s#THISISDATADIRECTORY#\./${table_name}_${begin_time}.txt#g;s#zhuyongzhuyong#${table_name_r}#g;s/KBPORT/${KB_PORT}/g;s/EXECSQLSTAT/delete from ${table_name_r} where fd_ie_flag='E' and fd_cus_release_time >= to_date('${begin_time}','yyyymmdd') and fd_cus_release_time < to_date('${end_time}','yyyymmdd');/g" z.mod > $table_name.yml
cat $table_name.yml
break;
else
echo $table_name
sed -e "s#THISISDATADIRECTORY#\./${table_name}_${begin_time}.txt#g;s#zhuyongzhuyong#${table_name}#g;s/KBPORT/${KB_PORT}/g;s/EXECSQLSTAT/delete from ${table_name} where fd_cus_release_time >= to_date('${begin_time}','yyyymmdd') and fd_cus_release_time < to_date('${end_time}','yyyymmdd');/g" z.mod > $table_name.yml
cat $table_name.yml
break;
fi
else
let KB_PORT+=2
KB_PORT=`get_port $KB_PORT`
fi
else
sleep $(($RANDOM%5))
let KB_PORT+=2
KB_PORT=`get_port $KB_PORT`
fi
done
while true
do
if [ -f ${table_name}_${begin_time}.done ];then
ips=`ps -ef | grep -v grep| grep sql_dump | wc -l`
if [ ${ips} -ge 4 ];then
sleep 2
else
echo "begin load"
#echo "`date "+%Y-%m-%d_%H:%M:%S"`开始装载表:${table_name}"
#nohup gpload -f $table_name.yml > ./log/gpload_$table_name_`date +%Y%m%d`.log &
#grep "errors = [^0]\|failed\|ERROR" ./log/gpload_${table_name}_`date +%Y%m%d`.log > /dev/null #检查gpload是否成功
#if [ $? -eq 0 ]; then
# echo "GPLOAD ERROR!"
# echo $table_name >> ./log/error_`date +%Y%m%d`.lst
#fi
#echo "`date "+%Y-%m-%d_%H:%M:%S"`结束装载表:${table_name}"
#ROWSLOAD=`cat $WORKPATH/load_log/gpload_${table_name}_$(date +%Y%m%d).log | grep "rows Inserted" | cut -d "=" -f 2 | sed 's/^ //'` #获取装载数据行数
#echo $ROWSLOAD
#echo "`date "+%Y-%m-%d_%H:%M:%S"`本次装载数据${ROWSLOAD}行"
rm -rf $WORKPATH/${KB_PORT}
break;
fi
else
echo ${table_name}_${begin_time}.txt have not done
sleep 10
continue;
fi
done
done < table.lst
相关文章:

一个从oracle使用spool导出数据到kadb的脚本
1. dump_data.sh调用sql_dump.sh导出数据 2. load_data.sh将导出的数据加载至KADB 1. dump_data.sh #!/bin/bash begin_time$(date %Y%m%d -d -1 day) end_time$(date %Y%m%d) echo "数据导出日期:"$begin_time echo "数据导出日期:"$begin_time >>…...

【STM32】GPIO口以及EXTI外部中断
个人主页~ 有关结构体的知识在这~ 有关枚举的知识在这~ GPIO口以及EXTI外部中断 GPIO一、简介二、基本结构三、输入输出模式1、输入模式(1)上拉输入(2)下拉输入(3)浮空输入(4)模拟输…...

Confluent Cloud Kafka 可观测性最佳实践
Confluent Cloud 介绍 Confluent Cloud 是一个完全托管的 Apache Kafka 服务,提供高可用性和可扩展性,旨在简化数据流处理和实时数据集成。用户可以轻松创建和管理 Kafka 集群,而无需担心基础设施的维护和管理。Confluent Cloud 支持多种数据…...

【LeetCode每日一题】——415.字符串相加
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时空频度】九【代码实现】十【提交结果】 一【题目类别】 字符串 二【题目难度】 简单 三【题目编号】 415.字符串相加 四【题目描述】 给定两个字符…...

linux---使用定时任务同步时间
首先,确保你的系统上安装了ntpdate工具,它用于从NTP服务器获取并设置系统时间。如果你的系统上没有安装,你可以通过包管理器进行安装 安装ntpdate yum install -y ntpdate设置定时任务 crontab -e在文件中添加下面内容 #每5分钟同步一次时间 …...

Windows、CentOS环境下搭建自己的版本管理资料库:GitBlit
可以搭建属于公司内部或者个人的Git服务器,方便程序代码及文档版本管理。 官网:http://www.gitblit.com/ Windows环境下安装 提前已经安装好了JDK。 官网下载Windows版的GitBlit。 将zip包解压到自己想要放置的文件夹下。 建立版本库路径,…...

KNN分类算法 HNUST【数据分析技术】(2025)
1.理论知识 KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。 KNN算法的思想: 对于任意n维输入向量,分别对应于特征…...
)
AI Agent开源框架汇总(持续更新)
文章目录 AI Agent开源框架汇总什么是AI Agent为什么需要智能体(Agent)Web3 AI Agent使用场景框架分类低代码(No-Code/Low-Code)框架基础框架代码框架Multi-Agent 框架 / 架构热门开源框架PhidataRigai16z的AI Agent框架ElizaLangChain和phidata对比OpenAI SwarmAI Agent开…...

录播检测原理是什么?
直播间录播的检测可以通过多种方式进行。以下是一些常见的检测方法: 1、水印识别:直播平台可以在实时直播画面中嵌入特定的水印,通过识别水印来判断是否存在录播行为。 2、特征分析:直播平台可以通过对直播画面进行特征分析,检测…...

IndexOf Apache Web For Liunx索引服务器部署及应用
Apache HTTP Server 是一款广泛使用的开源网页服务器软件,它支持多种协议,包括 HTTP、HTTPS、FTP 等 IndexOf 功能通常指的是在一个目录中自动生成一个索引页面的能力,这个页面会列出该目录下所有的文件和子目录。比如网上经常看到的下图展现的效果,那么接下来我们就讲一下…...

MySQL索引为什么是B+树
MySQL索引为什么是B树 索引是帮助MySQL高效获取数据的数据结构,在数据之外,数据库还维护着满足特定查找算法的数据结构B树,这些数据结果以某种特定的方式引用数据,这样就可以在这些数据结构上实现高级查找算法,提升数据…...

ffmpeg之播放一个yuv视频
播放YUV视频的步骤 初始化SDL库: 目的:确保SDL库正确初始化,以便可以使用其窗口、渲染和事件处理功能。操作:调用 SDL_Init(SDL_INIT_VIDEO) 来初始化SDL的视频子系统。 创建窗口用于显示YUV视频: 目的:…...

《2023-2024网络安全产业发展核心洞察与趋势预测》
2023年至2024年间,我国经济总体上逐步显现出复苏迹象,并开始释放向上增长的潜力。在此背景下,网络安全产业也经历了经济环境的深刻影响,不仅实现了阶段性的稳定发展,也展现出较强的韧性与适应能力,为未来的…...
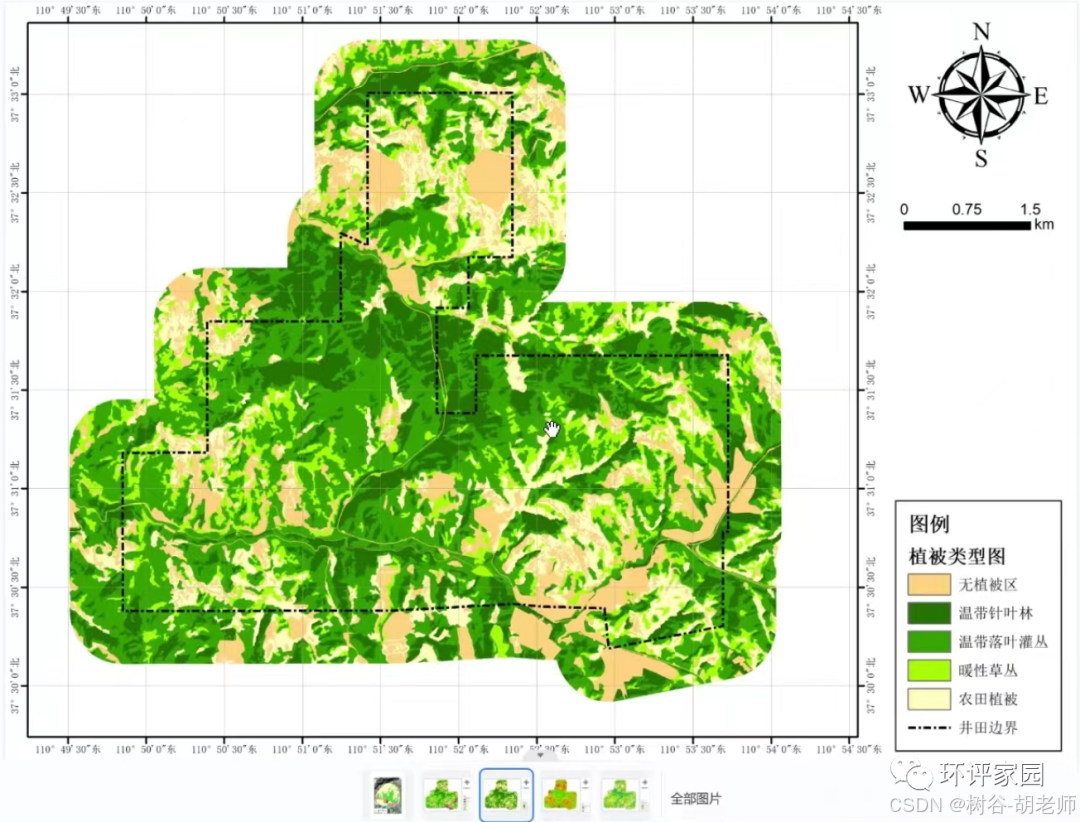
为什么环境影响评价导则中生态环境评价中的【植被类型图】制作比较难?制作流程是什么
最新《环境影响评价技术导则生态影响HJ19—2022》于2022年1月15日发布,2022-07-01正式实施,新导则颁布后,要求生态现状评价内容中基本图件构成包含:项目区域地理位置图、工程平面图、调查样方、样线、点位、断面等布设图、土地利用…...

肿瘤电场治疗费用
肿瘤电场治疗作为一种前沿的肿瘤治疗方法,近年来备受关注。该方法通过利用特定频率的交流电场,作用于恶性肿瘤细胞,以达到抑制肿瘤生长的目的。然而,随着这种治疗方法的普及,其费用问题也逐渐成为患者和家属关注的焦点…...

替换 Docker.io 的 Harbor 安全部署指南:域名与 IP 双支持的镜像管理解决方案
经过验证 替换 Docker.io 的方式失败了, 以下的过程中还是需要设置 registry-mirrors 才行 以下是一篇详细教程,展示如何基于 openssl.conf 配置生成域名为 registry-1.docker.io 和 IP 地址为 172.16.20.20 的证书,构建 Harbor 服务。 环境准备 系统环境…...

Python知识图谱框架
Python中用于构建知识图谱的框架和库有很多,它们各自有不同的特点和功能,适用于不同的应用场景。以下是一些常用的框架: 1. NetworkX 功能:NetworkX是一个用于创建、操作和研究复杂网络的Python库。它可以用于构建知识图谱&…...

elasticsearch 杂记
8.17快速安装与使用 系统:ubuntu 24 下载地址: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.17.0-linux-x86_64.tar.gz 解压后进入目录:cd ./elasticsearch-8.17.0 运行:./bin/elasticsearch 创…...

Text2Reward学习笔记
1. 环境配置 1.1 安装 PyTorch-1.13.1 pip install torch1.13.1cu116 torchvision0.14.1cu116 \ torchaudio0.13.1 --extra-index-url https://download.pytorch.org/whl/cu1161.2 安装工具库 pip install stable-baselines31.8.0 wandb tensorboard \ -i https://pypi.tuna…...

KylinOS V10 SP3下编译openGauss与dolphin插件
编译环境 KylinOS v10 sp3gcc 7.3.0make 4.3opengauss 5.0.0 mkdir -p /data/opengauss cd /data/opengauss git clone https://gitee.com/opengauss/openGauss-server.git git clone https://gitee.com/opengauss/Plugin.git wget -c https://opengauss.obs.cn-south-1.myhu…...

WebGPU实战指南:从零构建浏览器端高性能图形应用
1. WebGPU入门:为什么它是浏览器图形技术的未来 第一次接触WebGPU时,我被它的性能数据震惊了。在同样的硬件环境下,WebGPU渲染三角形的速度是WebGL的8-10倍。这就像从乡村小路突然切换到高速公路的感觉。你可能已经习惯了用Canvas或WebGL在浏…...

如何高效管理Windows Defender?Defender Control开源工具全解析
如何高效管理Windows Defender?Defender Control开源工具全解析 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-contr…...

3分钟学会在Blender中安装和使用VRM插件:从零到精通完整指南
3分钟学会在Blender中安装和使用VRM插件:从零到精通完整指南 【免费下载链接】VRM-Addon-for-Blender VRM Importer, Exporter and Utilities for Blender 2.93 to 5.0 项目地址: https://gitcode.com/gh_mirrors/vr/VRM-Addon-for-Blender VRM Addon for Bl…...

CefFlashBrowser终极指南:5个步骤让Flash内容在现代系统重生
CefFlashBrowser终极指南:5个步骤让Flash内容在现代系统重生 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 当Adobe在2020年正式终止Flash Player支持时,无数经典…...

写程序茶叶/咖啡包装日期密封标,易撕不损盒,输出:小众商家定制包装,提升质感。
项目方案:基于Python的激光易撕密封标牌生成系统一、 实际应用场景描述想象一下,你走进一家主打手冲咖啡或高端岩茶的精品买手店。他们售卖的是50g 装的挂耳咖啡包或散装岩茶罐。传统的解决方案是贴一张简陋的不干胶标签,写上日期,…...

最强30B模型GLM-4.7-Flash实测:Ollama一键部署,小白也能玩转AI
最强30B模型GLM-4.7-Flash实测:Ollama一键部署,小白也能玩转AI 1. GLM-4.7-Flash模型概述 1.1 模型特点与优势 GLM-4.7-Flash是当前30B参数级别中最具竞争力的混合专家模型(MoE)。这个规模特别适合需要平衡性能与资源消耗的实际…...

Dunst多显示器支持终极指南:在不同屏幕间智能分配通知
Dunst多显示器支持终极指南:在不同屏幕间智能分配通知 【免费下载链接】dunst Lightweight and customizable notification daemon 项目地址: https://gitcode.com/gh_mirrors/du/dunst Dunst是一款轻量级且高度可定制的通知守护进程(notificatio…...

告别复杂配置!Qwen3-ASR-0.6B一键部署教程,Gradio界面超简单
告别复杂配置!Qwen3-ASR-0.6B一键部署教程,Gradio界面超简单 1. 快速了解Qwen3-ASR-0.6B Qwen3-ASR-0.6B是一款强大的语音识别模型,支持52种语言和方言的识别能力。相比传统语音识别系统需要复杂的配置和调优,这个模型提供了开箱…...

终极AI图像修复指南:用Real-ESRGAN让低清动漫影像重现光彩
终极AI图像修复指南:用Real-ESRGAN让低清动漫影像重现光彩 【免费下载链接】Anime4K A High-Quality Real Time Upscaler for Anime Video 项目地址: https://gitcode.com/gh_mirrors/an/Anime4K Anime4K是一款高性能实时动漫视频超分辨率工具,能…...

深入解析Pydantic中的Field与Annotated:从基础到实战应用
1. Pydantic基础与Field入门 Pydantic是Python生态中数据验证和序列化的黄金标准,我在实际项目中用它处理过各种复杂的数据结构。它的核心优势在于利用Python类型提示来定义数据模型,而Field则是模型定义中最灵活的工具。 Field的基本用法很简单…...