Direct Preference Optimization (DPO) 简介与流程解析:中英双语
Direct Preference Optimization (DPO) 简介与流程解析
Direct Preference Optimization (DPO) 是一种基于人类偏好的强化学习优化方法,用于训练语言模型,使其更好地满足用户需求或偏好。本文将详细介绍 DPO 的核心思想、优化流程,并结合代码示例分析其具体实现方式。
1. 什么是 DPO?
DPO 是一种优化策略,它通过最小化损失函数来直接学习人类偏好数据,而无需依赖复杂的强化学习框架,如 Proximal Policy Optimization (PPO)。
DPO 的关键思想:
- 使用人类偏好数据集来构建训练样本,包含“偏好”和“非偏好”对比项。
- 通过直接优化偏好损失函数,引导策略模型学习偏好分布,同时控制 KL 散度,避免模型过度偏离参考分布。
DPO 的优势:
- 不依赖环境交互: DPO 在离线数据上训练,无需与环境实时交互,降低了训练复杂度。
- 直接利用人类偏好: 简化了强化学习的步骤,将人类偏好直接应用于优化过程。
- 更稳定的训练过程: 通过 KL 散度约束保持策略分布平稳,减少训练不稳定性。
2. DPO 的主要流程
Step 1: 数据集准备
假设我们有一个人类偏好标注的数据集 ( D D D):
D = { ( x i , y w i , y l i ) } i = 1 N D = \{(x_i, y_w^i, y_l^i)\}_{i=1}^N D={(xi,ywi,yli)}i=1N
其中:
- ( x i x_i xi):提示(prompt)或输入样本。
- ( y w i y_w^i ywi):偏好的输出(preferred completion)。
- ( y l i y_l^i yli):不偏好的输出(less preferred completion)。
示例数据:
| Prompt | Preferred Output (( y w y_w yw)) | Less Preferred Output (( y l y_l yl)) |
|---|---|---|
| “Summarize this text.” | “Key points are…” | “The main topic is…” |
| “Translate to French.” | “Bonjour tout le monde.” | “Salut à tous.” |
Step 2: 初始化参考模型 (( π r e f \pi_{ref} πref))
- 如果已有监督微调模型 (( π S F T \pi_{SFT} πSFT)),则直接使用它作为参考模型:
π r e f = π S F T \pi_{ref} = \pi_{SFT} πref=πSFT
- 如果没有 ( π S F T \pi_{SFT} πSFT),则通过最大似然估计 (MLE) 预训练一个参考模型:
π r e f = arg max π E ( x , y w ) ∼ D [ log π ( y w ∣ x ) ] \pi_{ref} = \arg\max_{\pi} \mathbb{E}_{(x, y_w) \sim D} [\log \pi(y_w | x)] πref=argπmaxE(x,yw)∼D[logπ(yw∣x)]
解释:
参考模型用于提供基准分布,帮助控制训练过程中的分布偏移,确保策略模型不会偏离参考分布太远。
Step 3: 损失函数定义与优化
DPO 的损失函数旨在优化策略模型 ( π θ \pi_\theta πθ) 相对于参考模型 ( π r e f \pi_{ref} πref) 的表现,同时引入 KL 散度惩罚项控制更新幅度:
损失函数公式:
L D P O ( θ ) = − log σ ( β [ log π θ ( y w ∣ x ) π θ ( y l ∣ x ) − log π r e f ( y w ∣ x ) π r e f ( y l ∣ x ) ] ) L_{DPO}(\theta) = - \log \sigma\left(\beta \left[\log \frac{\pi_\theta(y_w | x)}{\pi_\theta(y_l | x)} - \log \frac{\pi_{ref}(y_w | x)}{\pi_{ref}(y_l | x)}\right]\right) LDPO(θ)=−logσ(β[logπθ(yl∣x)πθ(yw∣x)−logπref(yl∣x)πref(yw∣x)])
其中:
- ( β \beta β):控制 KL 散度强度的超参数。
- ( σ ( ⋅ ) \sigma(\cdot) σ(⋅)):Sigmoid 函数,用于平滑处理。
- ( π θ \pi_\theta πθ):当前策略模型的输出概率。
- ( π r e f \pi_{ref} πref):参考模型的输出概率。
直观解释:
- 比较策略模型与参考模型在偏好和非偏好输出上的概率比率,优化模型使得偏好输出的概率更大,同时限制变化幅度。
代码实现:
摘录自原paper: https://arxiv.org/pdf/2305.18290
import torch.nn.functional as Fdef dpo_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, beta):"""计算 DPO 损失函数Args:pi_logps: 策略模型的对数概率, shape (B,)ref_logps: 参考模型的对数概率, shape (B,)yw_idxs: 偏好输出的索引, shape (T,)yl_idxs: 不偏好输出的索引, shape (T,)beta: KL 惩罚项超参数Returns:losses: 损失值rewards: 奖励信号"""# 取出偏好与非偏好对应的对数概率pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]# 计算策略与参考模型的概率比率pi_logratios = pi_yw_logps - pi_yl_logpsref_logratios = ref_yw_logps - ref_yl_logps# 损失函数losses = -F.logsigmoid(beta * (pi_logratios - ref_logratios))# 奖励信号rewards = beta * (pi_logps - ref_logps).detach()return losses, rewards
Step 4: 模型训练设置
摘录自原paper: https://arxiv.org/pdf/2305.18290
-
优化器与超参数设置:
- 使用 RMSprop 优化器。
- 学习率:( 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6)。
- 批量大小:64。
- 学习率线性预热 150 步,从 0 增加到 ( 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6)。
-
特定任务调整:
- 摘要任务:将 ( β = 0.5 \beta = 0.5 β=0.5)。
-
训练过程:
- 从参考模型加载初始参数。
- 根据数据集批量计算损失和奖励。
- 逐步更新策略模型,平衡偏好学习和 KL 散度控制。
3. DPO 的实际应用与优势分析
应用场景:
- 对话生成:
- 使用人类反馈优化对话质量,使模型更符合用户期望。
- 摘要生成:
- 根据偏好数据训练模型生成更简洁或更详细的摘要。
- 翻译任务:
- 微调翻译模型使其符合语言习惯和文化背景。
与传统方法对比:
| 方法 | 特点 | 优势 |
|---|---|---|
| PPO | 在线交互式优化,依赖环境反馈 | 强鲁棒性,但实现复杂,训练成本高 |
| DPO | 离线偏好优化,无需环境交互,直接优化损失函数 | 简单易实现,训练更稳定,适合大规模预训练模型微调 |
4. 总结
DPO 提供了一种高效稳定的方式,将人类偏好直接融入语言模型训练过程。通过对比参考模型与策略模型的输出概率,并结合 KL 散度控制,DPO 避免了传统强化学习中的不稳定性,尤其适合大规模预训练模型的偏好微调任务。
关键点回顾:
- 准备偏好数据集,标注“偏好”和“非偏好”输出。
- 初始化参考模型,确保稳定的分布基础。
- 计算损失函数,通过 KL 散度控制更新幅度。
- 利用超参数调优,平衡偏好优化与探索能力。
DPO 简化了强化学习流程,为语言模型的微调提供了一种高效且实用的解决方案。
Introduction to Direct Preference Optimization (DPO): Process and Implementation
Direct Preference Optimization (DPO) is a reinforcement learning-based optimization method that trains language models to better align with user preferences. This blog provides a detailed explanation of DPO’s core concepts, step-by-step pipeline, and practical implementation using code examples.
1. What is DPO?
DPO is an optimization strategy that directly learns from human preference data by minimizing a preference-based loss function, eliminating the need for complex reinforcement learning frameworks like Proximal Policy Optimization (PPO).
Key Ideas of DPO:
- Utilize human preference datasets containing pairs of “preferred” and “less preferred” completions.
- Optimize a preference-based loss function to guide the policy model while controlling KL divergence to prevent distributional shifts.
Advantages of DPO:
- No Environment Interaction Required: DPO trains offline, reducing complexity compared to traditional reinforcement learning.
- Direct Use of Human Preferences: Simplifies optimization by directly leveraging preference data.
- Stable Training Process: KL divergence constraints ensure smooth updates and prevent instability.
2. Main Workflow of DPO
Step 1: Prepare the Dataset
Assume we have a human-annotated preference dataset ( D D D):
D = { ( x i , y w i , y l i ) } i = 1 N D = \{(x_i, y_w^i, y_l^i)\}_{i=1}^N D={(xi,ywi,yli)}i=1N
Where:
- ( x i x_i xi): Prompt or input example.
- ( y w i y_w^i ywi): Preferred output (completion).
- ( y l i y_l^i yli): Less preferred output.
Sample Data:
| Prompt | Preferred Output (( y w y_w yw)) | Less Preferred Output (( y l y_l yl)) |
|---|---|---|
| “Summarize this text.” | “Key points are…” | “The main topic is…” |
| “Translate to French.” | “Bonjour tout le monde.” | “Salut à tous.” |
Step 2: Initialize Reference Model (( π r e f \pi_{ref} πref))
- If a supervised fine-tuned model (( π S F T \pi_{SFT} πSFT)) is available, use it as the reference model:
π r e f = π S F T \pi_{ref} = \pi_{SFT} πref=πSFT
- If ( π S F T \pi_{SFT} πSFT) is not available, pre-train a reference model via Maximum Likelihood Estimation (MLE):
π r e f = arg max π E ( x , y w ) ∼ D [ log π ( y w ∣ x ) ] \pi_{ref} = \arg\max_{\pi} \mathbb{E}_{(x, y_w) \sim D} [\log \pi(y_w | x)] πref=argπmaxE(x,yw)∼D[logπ(yw∣x)]
Explanation:
The reference model provides a baseline distribution that prevents distributional shifts during training, ensuring stability.
Step 3: Define and Optimize the Loss Function
DPO’s loss function is designed to optimize the policy model ( π θ \pi_\theta πθ) relative to the reference model ( π r e f \pi_{ref} πref) while introducing a KL-divergence penalty to constrain updates.
Loss Function Formula:
L D P O ( θ ) = − log σ ( β [ log π θ ( y w ∣ x ) π θ ( y l ∣ x ) − log π r e f ( y w ∣ x ) π r e f ( y l ∣ x ) ] ) L_{DPO}(\theta) = - \log \sigma\left(\beta \left[\log \frac{\pi_\theta(y_w | x)}{\pi_\theta(y_l | x)} - \log \frac{\pi_{ref}(y_w | x)}{\pi_{ref}(y_l | x)}\right]\right) LDPO(θ)=−logσ(β[logπθ(yl∣x)πθ(yw∣x)−logπref(yl∣x)πref(yw∣x)])
Where:
- ( β \beta β): Temperature parameter controlling KL penalty strength.
- ( σ ( ⋅ ) \sigma(\cdot) σ(⋅)): Sigmoid function for smoothing.
- ( π θ \pi_\theta πθ): Current policy model probabilities.
- ( π r e f \pi_{ref} πref): Reference model probabilities.
Intuitive Explanation:
- Compare the probability ratios between preferred and less preferred outputs.
- Optimize the model to increase probabilities for preferred outputs while limiting deviation from the reference model.
Code Implementation:
import torch.nn.functional as Fdef dpo_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, beta):"""Compute DPO loss.Args:pi_logps: Log-probabilities from the policy model, shape (B,)ref_logps: Log-probabilities from the reference model, shape (B,)yw_idxs: Indices of preferred completions, shape (T,)yl_idxs: Indices of less preferred completions, shape (T,)beta: KL penalty strengthReturns:losses: Loss valuesrewards: Reward signals"""# Extract log-probs for preferred and less preferred completionspi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]# Compute log-ratiospi_logratios = pi_yw_logps - pi_yl_logpsref_logratios = ref_yw_logps - ref_yl_logps# Compute losslosses = -F.logsigmoid(beta * (pi_logratios - ref_logratios))# Compute rewardsrewards = beta * (pi_logps - ref_logps).detach()return losses, rewards
Step 4: Model Training Settings
-
Optimizer and Hyperparameters:
- Optimizer: RMSprop.
- Learning Rate: ( 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6).
- Batch Size: 64.
- Linear warmup: Gradually increase learning rate from 0 to ( 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6) over 150 steps.
-
Task-Specific Adjustments:
- For summarization: Set ( β = 0.5 \beta = 0.5 β=0.5).
-
Training Process:
- Load initial parameters from the reference model.
- Compute losses and rewards in batches using the preference dataset.
- Update the policy model step-by-step, balancing preference optimization and KL divergence constraints.
3. Applications and Advantages
Use Cases:
- Dialogue Generation:
- Optimize conversational quality to better match user expectations.
- Summarization Tasks:
- Train models to generate concise or detailed summaries based on preferences.
- Translation Models:
- Fine-tune translations to match linguistic and cultural nuances.
Comparison with Traditional Methods:
| Method | Features | Advantages |
|---|---|---|
| PPO | Online optimization, requires environment feedback | Robust but complex implementation and expensive |
| DPO | Offline preference optimization, no interaction needed | Simple implementation, more stable training |
4. Conclusion
DPO provides an efficient and stable method for integrating human preferences into language model training. By comparing probabilities between preferred and less preferred outputs and applying KL-divergence constraints, DPO avoids instability often seen in traditional reinforcement learning, making it ideal for fine-tuning large language models.
Key Takeaways:
- Prepare a preference dataset labeled with “preferred” and “less preferred” outputs.
- Initialize a reference model for stable training.
- Optimize the preference loss function while controlling distribution shifts.
- Tune hyperparameters to balance preference learning and exploration.
DPO simplifies reinforcement learning and offers a practical solution for preference-based fine-tuning of pre-trained language models.
参考
[1] DPO(Direct Preference Optimization)算法解释:中英双语
后记
2024年12月26日21点19分于上海,在GPT4o大模型辅助下完成。
相关文章:
 简介与流程解析:中英双语)
Direct Preference Optimization (DPO) 简介与流程解析:中英双语
Direct Preference Optimization (DPO) 简介与流程解析 Direct Preference Optimization (DPO) 是一种基于人类偏好的强化学习优化方法,用于训练语言模型,使其更好地满足用户需求或偏好。本文将详细介绍 DPO 的核心思想、优化流程,并结合代码…...

fisco-bcos手动搭建webase启动注意事项
手动搭建webase-front启动注意事项 Java环境变量:1.8.301时候的错误 一直提示节点连接不上,无法连接chanale端口 这是官方提供的解决办法Help wanted: solution for secp256k1 being disabled Issue #470 FISCO-BCOS/java-sdk Java SDK 2.x连接节点失败…...

ospf 的 状态机详解
OSPF(开放最短路径优先,Open Shortest Path First)协议的状态机是其核心部分之一,用于确保路由器之间的邻接关系(neighbor relationship)建立和路由信息的交换。OSPF的状态机模型由多个状态组成,…...

TP5 动态渲染多个Layui表格并批量打印所有表格
记录: TP5 动态渲染多个Layui表格每个表格设置有2行表头,并且第一行表头在页面完成后动态渲染显示内容每个表格下面显示统计信息可点击字段排序一次打印页面上的所有表格打印页面上多个table时,让每个table单独一页 后端代码示例: /*** Nod…...

spring专题笔记(六):bean的自动装配(自动化注入)-根据名字进行自动装配、根据类型进行自动装配。代码演示,通俗易懂。
目录 一、根据名字进行自动装配--byName 二、根据类型进行自动装配 byType 本文章主要是介绍spring的自动装配机制, 用代码演示spring如何根据名字进行自动装配、如何根据类型进行自动装配。代码演示,通俗易懂。 一、根据名字进行自动装配--byName Us…...

监听器listener
文章目录 监听器( listener)对Application内置对象监听的语法和配置对session内置对象监听的语法和配置 监听器( listener) 对象与对象的关系: 继承关联 tomcat一启动创建的顺序:监听器,config,application(全局初始化参数)&am…...

重温设计模式--10、单例模式
文章目录 单例模式(Singleton Pattern)概述单例模式的实现方式及代码示例1. 饿汉式单例(在程序启动时就创建实例)2. 懒汉式单例(在第一次使用时才创建实例) 单例模式的注意事项应用场景 C代码懒汉模式-经典…...

Flutter动画学习二
如何在 Flutter 中使用自定义动画和剪裁(clipping)实现一个简单的动画效果。 前置知识点学习 AnimationController AnimationController 是 Flutter 动画框架中的一个核心类,用于控制动画的生命周期和状态。它提供了一种灵活的方式来定义动…...
【React Native版】)
讯飞语音听写WebApi(流式)【React Native版】
假设已有 Base64 编码的音频文件(16kHz, s16le, pcm) 1、获取websocket url import * as CryptoJS from crypto-js;/*** 获取websocket url*/ const getWebSocketUrl () > {const config {// 请求地址hostUrl: "wss://iat-api.xfyun.cn/v2/iat",host: "i…...
框架(一)))
【Linux编程】一个基于 C++ 的 TCP 客户端异步(epoll)框架(一))
TcpClient 类的设计与实现:一个基于 C 的 TCP 客户端框架 在现代网络编程中,TCP(传输控制协议)客户端是实现网络通信的基础组件之一。本文将详细介绍一个基于 C 的 TcpClient 类的设计与实现,该类提供了创建 TCP 连接…...

PG备份恢复--pg_dump
pg_dump pg_dump 是一个逻辑备份工具。使用 pg_dump 可以在数据库处于使用状态下进行一致 性的备份,它不会阻塞其他用户对数据库的访问 。 一致性备份是 pg_dump 开始运行时,给数据库打了一个快照,且在 pg_dump 运行过程 中发生的更新将不会被备份。 …...

pikachu靶场搭建详细步骤
一、靶场下载 点我去下载 二、靶场安装 需要的环境: mysqlApaches(直接使用小皮面板Phpstudy:https://www.xp.cn/),启动他们 设置网站,把靶场的路径对应过来 对应数据库的信息 由于没有核对数据库的信…...
:装饰器讲解)
HarmonyOS NEXT开发进阶(五):装饰器讲解
一、Provide Consume 父组件与子组件的子组件(官方叫法:后代组件)双向同步数据(即,父组件与后代组件可以相互操作 Provide 修饰的数据) 注意:Provide 与 Consume声明的变量名必须一致。 import {TestChild } from .…...

【编译原理】往年题汇总(山东大学软件学院用)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀编译原理_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前言 2. …...
)
【漏洞复现】F5 BIG-IP Next Central Manager SQL注入漏洞(CVE-2024-26026)
免责声明 请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,作者不为此承担任何责任。工具来自网络,安全性自测,如有侵权请联系删除。本次测试仅供学习使用,如若非法他用,与平台和本文作…...

设计模式-创建型-单例模式
1. 单例模式简介 单例模式(Singleton Pattern)是一种常见的创建型设计模式,它确保一个类只有一个实例,并提供全局访问点。在很多情况下,我们只希望某个类在整个应用程序中有一个唯一的实例,且该实例需要在…...
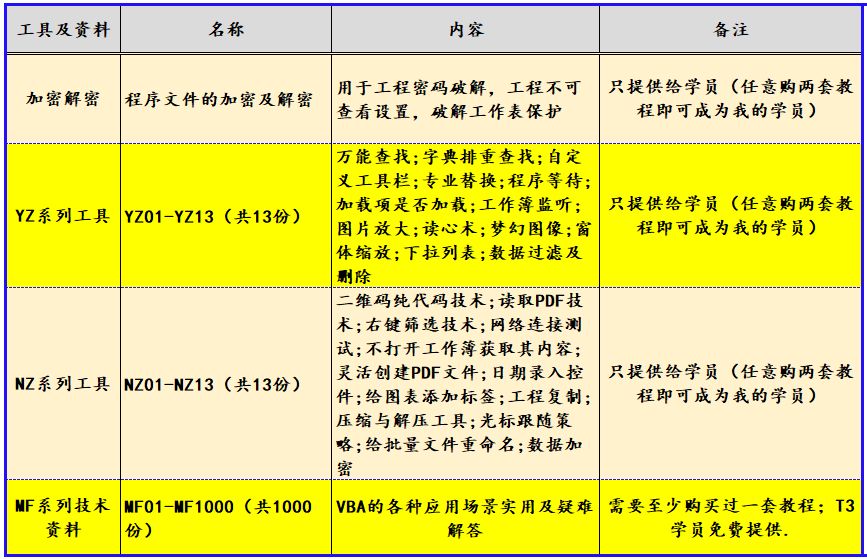
VBA技术资料MF243:利用第三方软件复制PDF数据到EXCEL
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...

【2024最新】基于Python+Mysql+django的水果销售系统Lw+PPT
作者:计算机搬砖家 开发技术:SpringBoot、php、Python、小程序、SSM、Vue、MySQL、JSP、ElementUI等,“文末源码”。 专栏推荐:SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:Java精选实战项…...

一种寻路的应用
应用背景 利用长途车进行货物转运的寻路计算。例如从深圳到大连。可以走有很多条长途车的路线。需要根据需求计算出最合适路线。不同的路线的总里程数、总价、需要的时间不一样。客户根据需求进行选择。主要有一些细节: 全国的长途车车站的数据的更新: …...

编译openssl遇到错误Parse errors: No plan found in TAP output的解决方法
在编译openssl时 tar -zxvf openssl-1.1.1p.tar.gz cd openssl-1.1.1p ./config --prefix/usr --openssldir/etc/ssl --shared zlib make make test 遇到错误 Parse errors: No plan found in TAP output 解决方法: yum install perl-Test-Simple...

OpenClaw技能开发:为千问3.5-9B编写自定义自动化模块
OpenClaw技能开发:为千问3.5-9B编写自定义自动化模块 1. 为什么需要自定义技能? 去年冬天,当我第一次尝试用OpenClaw自动化处理日报时,发现现有的技能库无法满足我的特殊需求——需要从Jira提取数据后,自动生成符合团…...

Linux实现简易版Shell的代码详解
一、程序流程分析我们日常使用Bash时,通过输入命令执行相应的操作,比如:那么,Bash是如何进行工作的呢?观察一下,就会发现,首先Bash会打印命令行提示符,包括当前用户、主机名以及路径…...

lingbot-depth-pretrain-vitl-14多场景落地:AR实时遮挡、3D重建、工业检测一文详解
lingbot-depth-pretrain-vitl-14多场景落地:AR实时遮挡、3D重建、工业检测一文详解 想象一下,你手里只有一部普通的手机摄像头,却想让它像人眼一样“感知”距离,知道哪个物体离你近,哪个离你远。或者,你有…...

TEST文件夹:Pytest,集成测试,单元测试
在复杂的自动驾驶项目中,哪怕你只改了一行代码,都可能导致整个感知或控制系统崩溃。如果直接去训练,还会消耗大量算力。所以当你新写了一个功能(比如你改了采样逻辑),先不要急着去跑训练。先跑一下测试&…...

19c升级遇见错误,libclntsh.so.19.1和libasmclntsh19.so
错误内容:Details: [ ---------------------------Patching Failed--------------------------------- Command execution failed during patching in home: /oracle/app/19.3.0/grid, host: efb01. Command failed: /oracle/app/19.3.0/grid/OPatch/opatchauto a…...

Windows效率翻倍!这些隐藏的Win+R命令和CMD技巧你用过几个?
Windows效率革命:解锁WinR与CMD的终极生产力指南 你是否曾在同事飞速敲击键盘时暗自惊叹?那些看似简单的组合键背后,藏着Windows系统最强大的效率武器库。今天我们要探索的不仅是快捷键列表,而是一套完整的生产力操作系统——从Wi…...

Airtest+Poco自动化测试避坑指南:从环境搭建到报告生成的10个常见问题
AirtestPoco自动化测试实战避坑指南:10个高频问题深度解析与解决方案 在移动应用和游戏自动化测试领域,AirtestPoco的组合已经成为技术团队的首选工具链。这套开源框架凭借其图像识别与UI控件定位的双重能力,能够覆盖90%以上的自动化测试场景…...
)
告别魔法!Gemini 3.1 Pro 国内稳定API使用教程(开发者+普通用户双版)
一、开篇:Gemini 3.1 Pro 到底强在哪? Gemini 3.1 Pro 推理能力直接翻倍,彻底解决了AI行业“快则不精、精则太贵”的痛点。 不管你是开发者想对接API,还是普通用户想低成本体验超强推理模型,这篇文章都给你一套清晰、…...

如何快速实现文件格式伪装?apate工具完整使用指南
如何快速实现文件格式伪装?apate工具完整使用指南 【免费下载链接】apate 简洁、快速地对文件进行格式伪装 项目地址: https://gitcode.com/gh_mirrors/apa/apate 在当今数字时代,文件格式伪装技术已经成为保护数据隐私和突破平台限制的重要工具。…...

STM32大棚花卉物联网护养系统设计与实现
1. 项目概述这个大棚花卉护养系统是我去年为一个花卉种植基地设计的物联网解决方案。当时客户反映传统人工管理方式效率低下,经常出现浇水不及时、温度控制不精准等问题。经过三个月的开发和调试,这套系统成功将花卉产量提升了30%,同时减少了…...