LLM预训练recipe — 摘要版
文章核心主题:
本文深入探讨了从零开始进行大型语言模型(LLM)预训练(pretrain)的各个环节,侧重方法论和实践细节,旨在普及预训练过程中的关键步骤、常见问题及避坑技巧,而非技术原理的深入分析。作者强调了数据处理的重要性,并强调了自主预训练的价值。
要点总结:
1. 背景篇:自研 Pretrain 模型的意义
- 开源模型的局限性: 虽然大型模型(如qwen)开源了模型参数,但训练框架、训练数据等核心内容仍未开源,使得用户无法参与模型的迭代优化。
- 技术掌握的必要性: 在LLM全面开源前,掌握预训练技术仍然有意义。通用模型的变现能力不如领域模型,而持续预训练(continue-pretrain)是刚需,其技术栈与预训练相似。
- 数据透明度的重要性: 自主预训练可以掌握模型训练数据的细节(如数据配比、知识掌握程度),从而在后续的对齐(alignment)阶段进行针对性优化,最大化模型潜力。
- Tokenizer 的重要性: 使用开源模型时,tokenizer 不可控会导致解码速度不可控,自研模型可以自定义 tokenizer,优化特定任务的性能。
- 其他动机: 自研模型可以作为公司科研能力的象征,也可以在预训练阶段植入个性化知识或价值观。
2. 数据篇:预训练数据的准备与处理
- 数据获取:
- 需准备大量训练数据(约10T),可逐步收集,数据来源包括爬虫、购买、开源数据集等。
- 强调专业数据团队的重要性,避免因爬虫行为引发法律风险。
- 高质量数据(如论文、书籍)常以PDF格式存在,需使用专业服务或自研OCR模型进行解析,Python库解析效果有限,大模型解析成本较高。
- 开源数据集(如FineWeb、pile、Skypile、RedPajama)可作为启动资金,但质量参差不齐。
- 开源数据下载复杂,需解决服务器网络、下载速度、文件处理等问题。
- 数据质量:
- 数据知识密度差异大,高知识密度数据(如唐诗三百首)价值更高。
- 合成高知识密度数据是趋势,可提高训练速度。
- 组建数据团队进行爬虫或购买是认真进行预训练的必要条件。
- 数据清洗:
- 核心工作: 数据清洗是数据环节最核心的工作。
- 模型打分: 利用模型对预训练数据质量进行打分已成标配,推荐使用BERT结构模型作为打分器,因为BERT结构模型表征能力更强。
- 打分器训练: 打分器不追求100%准确率,能用即可,不宜投入过多时间,可训练小规模打分器。
- 规则清洗: 规则是强大的数据清洗工具,可基于数据长度、token比例、语言占比、关键词等特征过滤数据。
- 规则应用注意: 使用规则清洗时,注意不要将数据清洗成分布有偏的数据。
- 数据脱敏: 必须进行数据脱敏,去除人名、电话号码、邮箱等敏感信息,以及“转载自…”等信息,避免隐私侵犯和法律风险,使用正则匹配。
- 数据去重:
- 必要性: 数据去重是必须的,避免重复使用同一内容。
- 去重粒度: 可选择句子级去重或文档级去重,根据实际情况量力而为。
- 技术手段: 需要大数据处理集群和map/reduce框架,可利用minhash算法实现。
- 去重策略: 先确定需要多少训练数据,再确定去重的粒度,不需要追求绝对完美。
- 数据配比:
- 需要训练数据分类器,对数据进行类别划分(如新闻、百科、代码、markdown等),可使用BERT家族模型。
- 不同类别数据清洗和去重的阈值不同,高质量数据保留,低质量数据过滤。
- 数据配比通常为“知识 + 代码 + 逻辑”三大类,中文:英文:代码的比例通常为4:4:2,逻辑数据比例取决于可用数据量。
- 英文数据比例不能太低,目前中文数据质量不如英文数据质量,可能是因为中文更难学,且语料数量和质量不如英文。
- 数据顺序:
- 数据顺序很重要,预训练的本质是教模型学习知识,知识的顺序决定了学习效果。
- 课程学习很重要,先学难知识/好数据,再学脏知识/坏数据。
- 推荐llama的In context pretrain方法,利用语义相似度拼接文档,构成语义连贯的上下文。
- 关于attention mask:llama 认为同一条训练语料中,无关文档不能相互看见,但实操中,大部分团队不使用mask,且未发现差异。
- 数据流水线:
- 预训练是动态加载数据的,读1B、训1B,再读1B,再训1B,因为数据量大,无法一次性读取。
- 模型获取的是token_id而非token,需提前完成tokenization和concatenation操作。
- 数据处理和模型训练是独立进程,数据处理进程需保证模型训练进程始终有数据可用。
- 预训练数据可以复用,高质量数据可以训练多遍,并动态降低已使用多次数据的被选中概率。
- 数据块大小应适中,以B为单位,方便回退。
- 建议数据块与模型checkpoint保存对齐,方便模型版本回退。
- 数据实验:
- 不要盲目开始训练,先在小模型上进行实验,理解scaling_law。
- 实验内容包括:不同数据配比和顺序的训练实验、不同大小模型的loss结果、以及绘制loss到benchmark的scaling_law,以便提前预知模型训多少token量能在某个benchmark达到什么水平。
- scaling_law仍是重要的指导原则,不能完全忽视。
3. 训练篇:模型结构、参数、训练框架和技巧
- Tokenizer:
- Tokenizer是预训练的基础,务必提前准备好。
- 扩词表容易出错,可能导致旧token对应的知识丢失。
- 训练tokenizer需用大量的common数据和BPE/BBPE算法。
- 需注意数字切分、控制压缩率(通常1 token对应1.5个汉字)、手动移除脏token,补充业务场景token,确保中英文覆盖率,词表大小与模型embedding_size保持一定buffer。
- 针对
strawberry包含几个r这种问题,作者认为tokenizer是天生解决不了的。
- 模型结构:
- 建议采用llama的结构,减少创新,降低踩坑风险(rope + gqa + rms_norm + swiglu)。
- 小模型embedding和lm_head可共享参数,大模型则无必要。
- 预训练成本高,应稳健为主,不宜盲目创新,除非有鲁棒实验支持。
- 模型参数:
- 模型size主要考虑训练和推理算力,而非直接根据场景需求确定。
- 模型size应与大厂模型保持一致,避免踩坑,且方便模型效果对比。
- 推理算力应考虑实际部署机器的显存限制,避免出现一张推理卡装不下模型的情况。
- 超参数size要和llama保持一致,横向和纵向成比例递增。
- 超参数值应能被2/4/8/64/128等数整除,以满足训练框架要求。
- layer_num、num_head、hidden_states、vocab_size应满足特定倍数的要求,以便支持并行计算。
- seq_len选取要循序渐进,先用小seq_len,再逐渐增加,采用rope的NTK外推方法。
- 训练框架:
- 从零开始预训练,必须选megatron;continue-pretrain可考虑deepspeed。
- megatron: 训练速度快,参数清晰,模型加载快,但上手成本高,基建工作多,官方代码存在bug。
- deepspeed: 代码简单,用户群体多,但训练速度慢,加载慢,微操难,官方代码也存在bug。
- 无论使用哪个框架,都要将attention的默认方式改为flash_attention。
- 训练技巧:
- 训练效率优化: 减少通讯量,避免机间通讯。优先使用data_parallel,避免显存和内存之间切换,避免重算。
- 训练loss分析: 关注tensorboard上的loss曲线,应分开观察不同类型数据的loss,重视loss_spike(loss突然激增或降低),回退到上个checkpoint,并调整adamw优化器的β1β2参数,解决训练初期loss_spkie问题。
- 训练流程: warm up(学习率缓慢上升) -> 中期(cos / cos_decay / constant / constant_decay,学习率较大)-> 后期(改变rope base+seq_len,适应长文本)-> 收尾(anneal,用高精数据/IFT数据强化考试能力)。
- 预训练一旦开始,一般无需人为干预,除非出现烧卡、loss爆炸、loss陡降等情况。
4. 评估篇:模型性能的评估方法
- PPL (Perplexity):
- 通过测试集的loss衡量模型效果,同一模型不同训练阶段进行对比,不能跨模型对比,不同tokenizer压缩率的loss没有可比性。
- 通用知识测试集上的loss应降低到2以下。
- Benchmark:
- 预训练阶段的benchmark结果可信度有限,如果checkpoint不是自己训练的,可能存在刷榜行为。
- benchmark形式单一,大多是选择题,没有cot环节,难以全面衡量模型能力。
- 建议改造benchmark,以生成式的方法使用,而非直接看ABCD哪个概率高,例如:
- 将Question + Answer,变成Question + Answer_A,Question + Answer_B,Question + Answer_C,Question + Answer_D,让模型结合上下文回答问题
- 将正确答案选项改为 “其他答案全错”,看模型是否能选出该选项。
- 修改选项形式(一二三四代替ABCD),多选题改为单选题。
- 先让模型在不知道答案的情况下训练,然后让其说出正确答案。
- 使用ACC(Accuracy)衡量评估结果,而不是BLEU和Rouge。
- 概率探针:
- 从概率的角度监控模型的知识能力,观察特定token或句子的概率变化。
- 探针测试集需要手动构造,而非批量生成。
- 重点观察指标的变化趋势,而非绝对大小。
- 可以构造多种探针,例如:
Prob('北京'|'中国的首都是')PPL('台湾属于中国')vsPPL('台湾不属于中国')PPL('尊重同性恋') > PPL('反对同性恋')Prob( '{ '| '以 json输出')
5. 总结篇:预训练的整体认识
- 作者认为预训练的各个环节同等重要,数据清洗尤为重要,数据清洗的灵光一现可能大大提升模型效果。
- 预训练不是简单跑代码,数据清洗更有挑战。
LLM预训练recipe—原文版
相关文章:

LLM预训练recipe — 摘要版
文章核心主题: 本文深入探讨了从零开始进行大型语言模型(LLM)预训练(pretrain)的各个环节,侧重方法论和实践细节,旨在普及预训练过程中的关键步骤、常见问题及避坑技巧,而非技术原理…...

波动理论、传输线和S参数网络
波动理论、传输线和S参数网络 传输线 求解传输线方程 对于传输线模型,我们通常用 R L G C RLGC RLGC 来表示: 其中 R R R 可以表示导体损耗,由于电子流经非理想导体而产生的能量损耗。 G G G 表示介质损耗,由于非理想电介质…...

nginx-1.23.2版本RPM包发布
nginx-1.23.2-0.x86_64.rpm用于CentOS7系统的安装,安装路径与编译安装是同一个路径。安装方法: 将nginx-1.23.2-0.x86_64.rpm上传至目标服务器,执行rpm -ivh nginx-1.23.2-0.x86_64.rpm命令进行安装。 卸载方法: 卸载前先将nginx服…...

如何用WPS AI提高工作效率
对于每位职场人而言,与Word、Excel和PPT打交道几乎成为日常工作中不可或缺的一部分。在办公软件的选择上,国外以Office为代表,而在国内,WPS则是不可忽视的一大选择。当年一代天才程序员求伯君创造了WPS,后面雷军把它装…...

LabVIEW应用在工业车间
LabVIEW作为一种图形化编程语言,以其强大的数据采集和硬件集成功能广泛应用于工业自动化领域。在工业车间中,LabVIEW不仅能够实现快速开发,还能通过灵活的硬件接口和直观的用户界面提升生产效率和设备管理水平。尽管其高成本和初期学习门槛可…...

Elasticsearch:normalizer
一、概述 Elastic normalizer是Elasticsearch中用于处理keyword类型字段的一种工具,主要用于对字段进行规范化处理,确保在索引和查询时保持一致性。 Normalizer与analyzer类似,都是对字段进行处理,但normalizer不会对字段进…...

动态规划子序列问题系列一>等差序列划分II
题目: 解析: 1.状态表示: 2.状态转移方程: 这里注意有个优化 3.初始化: 4.填表顺序: 5.返回值: 返回dp表总和 代码: public int numberOfArithmeticSlices(int[] nums) {in…...

48页PPT|2024智慧仓储解决方案解读
本文概述了智慧物流仓储建设方案的行业洞察、业务蓝图及建设方案。首先,从政策层面分析了2012年至2020年间国家发布的促进仓储业、物流业转型升级的政策,这些政策强调了自动化、标准化、信息化水平的提升,以及智能化立体仓库的建设࿰…...

低代码开源项目Joget的研究——Joget8社区版安装部署
大纲 环境准备安装必要软件配置Java配置JAVA_HOME配置Java软链安装三方库 获取源码配置MySql数据库创建用户创建数据库导入初始数据 配置数据库连接配置sessionFactory(非必须,如果后续保存再配置)编译下载tomcat启动下载aspectjweaver移动jw…...
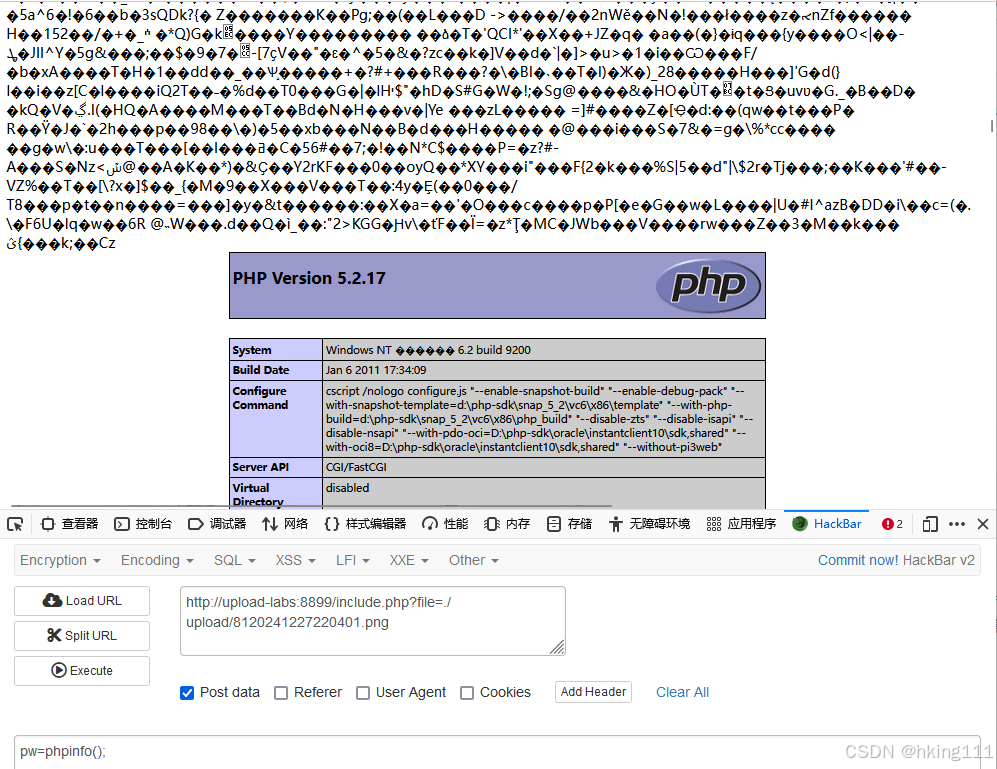
upload-labs关卡记录15
图片马,这里就可以看到任务和注意事项: 使用一个正常图片,然后拼接一个一句话木马即可实现。这里就用命令窗口进行实现: copy 111.png/b shell.php/a shell.png 注意这里的命令窗口要在存在图片和一句话木马的目录下打开&#…...
实现每 5 分钟的增量任务)
1.使用 Couchbase 数仓和 Temporal(一个分布式任务调度和编排框架)实现每 5 分钟的增量任务
在使用 Couchbase 数仓和 Temporal(一个分布式任务调度和编排框架)实现每 5 分钟的增量任务时,可以按照以下步骤实现,同时需要注意关键点。 实现方案 1. 数据层设计(Couchbase 增量存储与标记) 在 Couchb…...

matrix-breakout-2-morpheus
将这一关的镜像导入虚拟机,出现以下页面表示导入成功 以root身份打开kali终端,输入以下命令,查看靶机ip arp-scan -l 根据得到的靶机ip,浏览器访问进入环境 我们从当前页面没有得到有用的信息,尝试扫描后台 发现有一个…...

农历节日倒计时:基于Python的公历与农历日期转换及节日查询小程序
农历节日倒计时:基于Python的公历与农历日期转换及节日查询小程序 摘要 又是一年春节即将到来,突然想基于Python编写一个农历节日的倒计时小程序。该程序能够根据用户输入的农历节日名称,计算出距离该节日还有多少天。通过使用lunardate库进…...

【RabbitMQ的死信队列】
死信队列 什么是死信队列死信队列的配置方式死信消息结构 什么是死信队列 消息被消费者确认拒绝。消费者把requeue参数设置为true(false),并且在消费后,向RabbitMQ返回拒绝。channel.basicReject或者channel.basicNack。消息达到预设的TTL时限还一直没有…...

掌握软件工程基础:知识点全面解析【chap02】
chap02 软件项目管理 1.代码行度量与功能点度量的比较 1.规模度量 是一种直接度量方法。 代码行数 LOC或KLOC 生产率 P1L/E 其中 L 软件项目代码行数 E 软件项目工作量(人月 PM) P1 软件项目生产率(LOC/PM) 代码出错…...

公路边坡安全监测中智能化+定制化+全面守护的应用方案
面对公路边坡的安全挑战,我们如何精准施策,有效应对风险?特别是在强降雨等极端天气下,如何防范滑坡、崩塌、路面塌陷等灾害,确保行车安全?国信华源公路边坡安全监测解决方案,以智能化、定制化为…...

闲谭Scala(3)--使用IDEA开发Scala
1. 背景 广阔天地、大有作为的青年,怎么可能仅仅满足于命令行。 高端大气集成开发环境IDEA必须顶上,提高学习、工作效率。 开整。 2. 步骤 2.1 创建工程 打开IDEA,依次File-New-Project…,不好意思我的是中文版:…...

Go语言反射从入门到进阶
一、反射的基础概念 在 Go 语言中,反射是程序在运行时检查和修改自身状态的能力。通过反射,我们可以在运行时获取变量的类型信息、查看结构体的字段、调用方法等。Go 语言的反射功能主要通过 reflect 包实现。 1.1 反射的基本类型:Type 和 …...

【基于rust-wasm的前端页面转pdf组件和示例】
基于rust-wasm前端页面转pdf组件和示例 朔源多余的废话花哨的吹牛那点东西要不要拿来试试事到如今 做个美梦 我觉得本文的意义在于,wasm扩展了浏览器的边界,但是又担心如同java的web applet水土不服. 如同我至今看不出塞班和iOS的不同下载地址:在github的备份 朔源…...

ARM64 Windows 10 IoT工控主板运行x86程序效率测试
ARM上的 Windows 10 IoT 企业版支持仿真 x86 应用程序,而 ARM上的 Windows 11 IoT 企业版则支持仿真 x86 和 x64 应用程序。英创推出的名片尺寸ARM64工控主板ESM8400,可预装正版Windows 10 IoT企业版操作系统,x86程序可无需修改而直接在ESM84…...

GG3M 项目贝叶斯更新与决策数学的具体落地应用
GG3M贝叶斯决策体系:基于贾子公理的跨领域反熵增智慧决策应用摘要: GG3M项目以贾子公理体系为底层支撑,独创“事实层-模型层-元模型层”层级化贝叶斯架构,实现了从参数优化到认知框架迭代的范式突破。该体系以系统长期反熵增演化为…...

深入解析RS485接口:从硬件设计到工业应用
1. RS485接口基础解析 第一次接触RS485时,我也被它复杂的电气特性搞得一头雾水。直到在工厂里亲眼看到它如何稳定地穿过嘈杂的电机区域传输数据,才真正理解这个老牌工业接口的魅力。RS485本质上是一种差分信号传输标准,采用双绞线进行平衡传…...
)
MATLAB xyz2stl实战:手把手教你修复GitHub热门工具包的常见报错(含stlWrite函数缺失解决方案)
MATLAB xyz2stl实战:从报错排查到完整工作流搭建 当你从GitHub下载了NWRichmond/xyz2stl工具包,满心期待地运行却看到"未定义函数或变量stlWrite"的红色报错时,这种挫败感我深有体会。作为MATLAB社区中下载量排名前10%的三维数据处…...

ProfControl V8的介绍 组合成为模板
作者:刘凌波链接:环野电子, profcontrolhttp://oa.profcontrol.cn/teaching_V8-7926f783c6.html来源:ProfControl组合为模版1、按下SHIFT键,在地图区域空白处按下鼠标左键不松开,移动鼠标则进入框选模式,让…...

数学动画音频同步:让几何图形随音乐起舞的技术实现
数学动画音频同步:让几何图形随音乐起舞的技术实现 【免费下载链接】manim A community-maintained Python framework for creating mathematical animations. 项目地址: https://gitcode.com/GitHub_Trending/man/manim 在数学可视化领域,Manim…...
)
Qwen3-14B快速上手教程:命令行推理+参数详解(temperature/max_length)
Qwen3-14B快速上手教程:命令行推理参数详解(temperature/max_length) 1. 镜像概述与环境准备 Qwen3-14B是通义千问推出的大语言模型,本教程将指导您快速上手使用专为RTX 4090D 24GB显存优化的私有部署镜像。这个镜像已经预装了所…...

【SOC锁死SPORT、ECO不生效?10年VCU老兵:模式管理不是切个开关那么简单!】
SOC锁死SPORT、ECO不生效?10年VCU老兵:模式管理不是切个开关那么简单! 副标题:10年老兵深度拆解 | 标定测试故障产品定义 作者 新能源汽车研发测试 10 年高级工程师 关键词 #VCU车辆模式管理#驾驶模式切换逻辑#SOC阈值标定#扭矩Map#VCU测试标定#新能源三电测试#整车能…...

SlimSAS连接器在高密度存储系统中的关键应用与优化策略
1. SlimSAS连接器为何成为高密度存储的"黄金搭档"? 第一次接触SlimSAS连接器是在去年部署全闪存阵列时。当时机柜里密密麻麻的线缆让我头疼不已,直到工程师拿出这个火柴盒大小的连接器,我才意识到高密度布线的革命真的来了。SlimS…...

微信聊天记录永久保存与深度分析:WeChatMsg让你的数字记忆不再流失
微信聊天记录永久保存与深度分析:WeChatMsg让你的数字记忆不再流失 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trend…...

2026金三银四变天了:企业要的是能用的人,不是“有潜力的人“
2026金三银四变天了:企业要的是"能用的人",不是"有潜力的人" 3月了,又到了传说中的"金三银四"。 往年这个时候,朋友圈里都是"拿到offer了""跳槽涨薪30%"的好消息。但今年&…...