【Spring】详解(上)
Spring 框架核心原理与应用(上)
一、Spring 框架概述
(一)诞生背景
随着 Java 应用程序规模的不断扩大以及复杂度的日益提升,传统的 Java开发方式在对象管理、代码耦合度等方面面临诸多挑战。例如,对象之间的依赖关系往往硬编码在程序中,使得代码的可维护性、可扩展性变差,测试也变得困难。为了解决这些问题,Spring框架应运而生,它提供了一套轻量级的、面向切面编程以及依赖注入等先进特性的解决方案,帮助开发者更高效、灵活地构建 Java 应用程序。
(二)整体架构
- Spring 框架有着一套层次分明且功能丰富的架构体系,其核心部分主要包含多个模块,各模块相互协作,共同支撑起整个框架的强大功能。
- Spring Core:这是 Spring 框架的基础核心模块,提供了如 IoC(控制反转)和 DI(依赖注入)的基础功能实现,包括一些核心的工具类、资源加载机制以及对 Java 反射机制的运用等,是其他模块构建的基石。
- Spring Beans:主要聚焦于对 JavaBean 的管理,定义了 Bean 的定义、创建、配置以及生命周期管理等相关规范和实现,确保 Bean 在 Spring 框架内能被正确地实例化、装配以及销毁。
- Spring Context:构建在 Spring Core 和 Spring Beans 之上,为应用程序提供了一种配置和管理的运行时上下文环境,方便在整个应用中共享资源、获取 Bean 实例等,并且支持国际化、事件传播等高级特性。
- 除此之外,还有像 Spring AOP(面向切面编程)用于实现横切面逻辑的织入,Spring Data 方便与各种数据库进行交互,Spring MVC 用于构建 Web 应用的 MVC 架构等诸多模块,它们分别针对不同的应用场景提供特定的功能支持。
(三)核心模块功能
1. Spring Core
- 资源加载机制:提供了统一的资源加载抽象,使得可以方便地从不同的位置(如文件系统、类路径等)加载各种资源(如配置文件、属性文件等)。通过 Resource 接口及其众多实现类,内部运用了 Java 的类加载器等机制来定位和读取资源内容,例如 ClassPathResource 用于从类路径下加载资源,FileSystemResource 用于从文件系统加载资源,无论哪种资源类型,外部使用时都可以通过统一的接口方法进行操作,提高了资源获取的灵活性和通用性。
- 核心工具类:包含了如 StringUtils 用于字符串相关的便捷操作(像判断字符串是否为空、去除空格等),ReflectionUtils 则是对 Java 反射机制进行了进一步的封装和优化,方便在框架内部频繁地进行反射操作(比如获取类的方法、字段等信息并进行安全的调用和访问,避免了反射操作中一些繁琐的权限检查和异常处理步骤,简化了代码逻辑),这些工具类在整个 Spring 框架中被广泛使用,提升了代码的复用性和开发效率。
2. Spring Beans
- Bean 定义解析:支持多种方式来定义 Bean,常见的有 XML 配置和基于注解的配置。对于 XML 配置,通过 BeanDefinitionReader 接口及其实现类(如 XmlBeanDefinitionReader)来解析 XML 文件中的 <bean> 标签等配置信息,将其转换为内存中的 BeanDefinition 对象,该对象包含了 Bean 的类名、作用域、依赖关系等关键信息。基于注解的配置则是通过扫描类路径下带有特定注解(如 @Component 及其衍生注解 @Service、@Repository、@Controller 等)的类,利用 ClassPathBeanDefinitionScanner 等类解析注解信息,同样构建出对应的 BeanDefinition 对象,为后续的 Bean 实例化和装配做准备。
- Bean 生命周期管理:定义了一套完整的 Bean 从创建到销毁的生命周期流程,涵盖了实例化(通过反射机制调用构造函数创建对象实例,后面会详细讲解)、属性注入(依赖注入阶段,解决对象之间的依赖关系)、初始化(调用实现了 InitializingBean 接口的 afterPropertiesSet 方法或者配置了 init-method 的自定义初始化方法)以及最终的销毁(调用实现了 DisposableBean 接口的 destroy 方法或者配置了 destroy-method 的自定义销毁方法)等多个阶段,每个阶段都有相应的回调机制和处理逻辑,确保 Bean 在不同阶段能执行合适的操作,满足应用程序的多样化需求。
3. Spring Context
- 应用上下文创建与配置:提供了多种类型的应用上下文实现,如 ClassPathXmlApplicationContext(从类路径下的 XML 配置文件加载配置信息创建上下文)、FileSystemXmlApplicationContext(从文件系统中的 XML 配置文件创建上下文)以及 AnnotationConfigApplicationContext(基于注解配置创建上下文)等。这些上下文类在创建时会首先加载配置信息(根据对应的配置源类型),然后初始化 Spring 容器,构建出整个应用运行的上下文环境,内部会管理所有的 Bean 实例以及它们之间的关系,并且可以方便地在应用中通过 getBean 方法获取所需的 Bean 实例进行后续操作。
- 事件机制:实现了一套应用程序事件传播的机制,通过定义 ApplicationEvent 抽象类以及相应的监听器接口 ApplicationListener,允许应用中的不同组件通过发布和监听事件来实现解耦的通信。例如,当某个 Bean 的状态发生变化或者某个业务操作完成时,可以发布对应的事件,而其他感兴趣的组件(实现了 ApplicationListener 并注册到应用上下文)可以接收到事件并做出相应的响应,这种基于事件的交互方式增强了应用程序各部分之间的协作灵活性,使得代码结构更加清晰、易于维护。
二、Spring 的依赖注入(DI)机制
(一)通过 XML 配置实现依赖注入
1. 实现原理(源码解读)
在 Spring 通过 XML 配置实现依赖注入时,核心的操作围绕着对 XML 文件中 <bean>标签配置的解析以及将解析后的信息用于创建和装配 Bean 实例。
- 以下是 XmlBeanDefinitionReader 部分关键源码解读,它负责读取 XML 文件并解析其中的 Bean 定义信息:
public class XmlBeanDefinitionReader implements BeanDefinitionReader {// 用于加载 XML 资源的 XML 解析器,底层基于 Java 的 XML 解析技术(如 DOM、SAX 等)实现对 XML 文件结构和内容的解析private final XmlBeanDefinitionParser parser = new XmlBeanDefinitionParser();// 核心的加载 Bean 定义的方法,接收一个资源对象(如代表 XML 文件的资源),解析其中的 Bean 定义并返回对应的 BeanDefinitionHolder 列表public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {return loadBeanDefinitions(new EncodedResource(resource));}public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {// 省略部分前置的资源有效性等检查逻辑try {// 获取 XML 文档对象,通过底层的 XML 解析技术(比如调用 DocumentBuilderFactory 等创建解析器来解析 XML 文件得到 Document 对象)Document doc = doLoadDocument(encodedResource);// 利用解析器解析 XML 文档中的 Bean 定义信息,将其转换为 BeanDefinition 对象,并包装成 BeanDefinitionHolderreturn registerBeanDefinitions(doc, encodedResource.getResource());} catch (Exception ex) {// 省略异常处理逻辑throw new BeanDefinitionStoreException("IOException parsing XML document from " + encodedResource.getResource(), ex);} finally {// 省略资源释放等逻辑}}// 解析 XML 文档对象,获取其中的 Bean 定义节点(<bean> 标签对应的节点),并进一步解析这些节点的属性、子元素等信息来构建 BeanDefinition 对象protected void doRegisterBeanDefinitions(Element root) {BeanDefinitionParserDelegate parent = this.delegate;this.delegate = new BeanDefinitionParserDelegate(getValidationModeForResource(root));if (this.delegate.isDefaultNamespace(root)) {String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);if (StringUtils.hasText(profileSpec)) {// 省略处理配置文件中的 profile 相关逻辑(用于根据不同环境配置不同的 Bean 定义)} else {// 遍历根元素下的所有子节点(即各个 <bean> 标签对应的节点等),解析并注册 Bean 定义parseBeanDefinitions(root, this.delegate);}} else {// 处理非默认命名空间的节点(如用于支持自定义标签等情况),这里省略详细源码this.delegate.parseCustomElement(root, getBeanFactory());}this.delegate = parent;}// 解析单个 <bean> 标签对应的节点,根据其属性(如 class、scope 等属性)以及子元素(如 <property> 用于属性注入等)构建 BeanDefinition 对象protected void parseBeanDefinitionElement(Element ele, BeanDefinition containingBd) {String id = ele.getAttribute(ID_ATTRIBUTE);String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);// 处理 Bean 的名称(id 和 name 属性)相关逻辑,确保获取到合适的 Bean 名称用于后续标识List<String> aliases = new ArrayList<>();if (StringUtils.hasLength(nameAttr)) {String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);aliases.addAll(Arrays.asList(nameArr));}if (StringUtils.hasLength(id) &&!aliases.contains(id)) {aliases.add(0, id);}// 解析 <bean> 标签中的 class 属性,获取要实例化的 Bean 的类信息String beanClassName = ele.getAttribute(CLASS_ATTRIBUTE);try {if (StringUtils.hasLength(beanClassName)) {// 通过类加载器加载类,获取对应的 Class 对象,为后续实例化做准备Class<?> beanClass = ClassUtils.forName(beanClassName, getBeanClassLoader());// 构建基本的 BeanDefinition 对象,包含类信息等基础属性BeanDefinition bd = new GenericBeanDefinition();bd.setBeanClassName(beanClassName);bd.setBeanClass(beanClass);// 解析 <bean> 标签的其他属性(如 scope 等),设置到 BeanDefinition 对象中parseBeanDefinitionAttributes(ele, bd);// 解析 <bean> 标签的子元素,如 <property> 标签用于属性注入,这里调用相关方法进行详细解析和配置注入信息parseMetaElements(ele, bd);parseLookupOverrideElements(ele, bd);parseReplacedMethodElements(ele, bd);parseConstructorArgElements(ele, bd);parsePropertyElements(ele, bd);parseQualifierElements(ele, bd);// 根据解析后的完整信息,将 BeanDefinition 对象注册到 Bean 工厂(用于后续管理和实例化 Bean)BeanDefinitionHolder bdHolder = new BeanDefinitionHolder(bd, id, aliases);registerBeanDefinition(bdHolder);}} catch (ClassNotFoundException ex) {// 省略异常处理逻辑throw new BeanDefinitionStoreException("Invalid bean class '" + beanClassName + "'", ex);}}
}
从上述源码可以看出,XmlBeanDefinitionReader 通过一系列步骤,先利用 XML 解析技术获取 XML 文档对象,然后遍历其中的 <bean> 标签节点,解析出类名、属性、依赖关系等关键信息构建成 BeanDefinition 对象,最后将这些对象注册到 Bean 工厂。
- 在实际进行依赖注入阶段,以属性注入(通过 <property>标签配置)为例,当通过 BeanFactory(具体实现类如 DefaultListableBeanFactory)创建和初始化 Bean 实例时,会根据 BeanDefinition 中的属性注入配置来执行注入操作。关键源码如下(部分简化示意):
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactoryimplements ConfigurableListableBeanFactory, BeanDefinitionRegistry, Serializable {// 创建 Bean 实例的核心方法,根据 BeanDefinition 来实例化并初始化 Bean@Overrideprotected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)throws BeanCreationException {try {// 实例化 Bean,通过反射调用构造函数(后面会详细讲解构造函数实例化的相关源码逻辑)Object beanInstance = doCreateBean(beanName, mbd, args);// 进行属性注入,遍历 BeanDefinition 中配置的属性信息,将依赖的 Bean 实例注入到当前 Bean 中populateBean(beanName, mbd, beanInstance);// 执行初始化方法等后续操作(如调用实现了 InitializingBean 接口的方法等)initializeBean(beanName, beanInstance, mbd);return beanInstance;} catch (Exception ex) {// 省略异常处理逻辑throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);}}// 进行属性注入的方法,解析 BeanDefinition 中的属性配置,找到对应的依赖 Bean 实例并注入protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable Object beanInstance) {// 获取 Bean 定义中的属性配置信息(通过之前解析 XML 中的 <property> 等标签构建的配置)PropertyValues pvs = mbd.getPropertyValues();if (pvs.isEmpty()) {return;}// 判断是否采用自动注入模式(如 byName、byType 等),如果是,则按照相应规则查找依赖 Bean 实例进行注入if (mbd.getResolvedAutowireMode() == AUTOWIRE_BY_NAME || mbd.getResolvedAutowireMode() == AUTOWIRE_BY_TYPE) {MutablePropertyValues newPvs = new MutablePropertyValues(pvs);// 省略部分自动注入模式下的查找和注入逻辑,比如 byName 模式会根据属性名称查找对应的 Bean 实例注入if (mbd.getResolvedAutowireMode() == AUTOWIRE_BY_TYPE) {// byType 模式会根据属性类型查找匹配的 Bean 实例注入,涉及到类型匹配、查找等复杂逻辑autowireByType(beanName, mbd, newPvs);}pvs = newPvs;}// 遍历每个属性配置,通过反射获取对应的 setter 方法(利用 Java 反射机制找到属性对应的 setter 方法并调用进行注入)for (PropertyValue pv : pvs) {String propertyName = pv.getName();Object propertyValue = pv.getValue();if (propertyValue instanceof BeanReference) {// 如果属性值是指向另一个 Bean 的引用(比如 <property> 标签中 ref 属性指向另一个 <bean>),则获取对应的 Bean 实例注入BeanReference beanReference = (BeanReference) propertyValue;propertyValue = resolveBeanReference(beanReference, beanName, mbd, beanInstance);}try {// 通过反射找到 setter 方法并调用,将属性值注入到 Bean 实例中MethodDescriptor md = BeanUtils.findPropertyDescriptor(beanInstance.getClass(), propertyName).getWriteMethod();if (md!= null) {ReflectionUtils.makeAccessible(md.getMethod());md.getMethod().invoke(beanInstance, propertyValue);}} catch (Exception ex) {// 省略异常处理逻辑throw new BeanCreationException(mbd.getResourceDescription(), beanName,"Could not set property values on bean '" + beanName + "'", ex);}}}
}
在 populateBean 方法中,先是获取 BeanDefinition 里记录的属性配置信息,然后根据不同的自动注入模式进行相应处理,最后通过反射机制找到属性对应的 setter 方法,调用该方法将属性值(可能是普通对象值或者是指向其他 Bean 的引用,经过相应的查找和解析后)注入到 Bean 实例中,完成依赖注入操作。
2. 性能特点
- 启动性能:使用 XML 配置进行依赖注入时,在 Spring 容器启动阶段,由于需要解析 XML 文件、构建 BeanDefinition 对象以及进行各种配置的验证和预处理等操作,相对来说启动速度会稍慢一些。尤其是当 XML 文件较大、Bean 定义众多或者存在复杂的配置结构(如多层嵌套的 <bean> 标签、大量的条件配置等)时,解析 XML 的时间成本以及内存占用都会增加,影响容器的启动效率。
- 运行时性能:在运行时,每次获取 Bean 实例以及进行依赖注入操作(如果涉及到复杂的自动注入查找等情况),通过反射机制查找和调用 setter 方法等操作会带来一定的性能开销。不过,Spring 内部对于频繁使用的 Bean 等情况有一定的缓存机制(比如缓存 BeanDefinition、部分实例化后的 Bean 等),可以在一定程度上缓解这种性能损耗,使得在常规的应用场景下,运行时性能通常能维持在可接受的范围。
- 应用场景
大型项目配置管理:在一些大型的企业级 Java 项目中,往往有着复杂的模块划分和众多的组件依赖关系,使用 XML 配置方式可以将整个项目的 Bean 配置集中管理,方便不同的开发团队、运维团队查看和修改配置信息,清晰地梳理出各个模块之间的依赖关系,并且可以根据不同的环境(如开发环境、测试环境、生产环境)通过配置文件的切换或者部分配置的调整来灵活部署应用。
历史项目维护与集成:对于一些已经存在的老项目,如果要接入 Spring 框架或者进行功能扩展,使用 XML 配置
历史项目维护与集成:对于一些已经存在的老项目,如果要接入 Spring 框架或者进行功能扩展,使用 XML 配置方式是比较友好的选择。因为可以在不大量改动原有代码结构的基础上,通过编写 XML 配置文件来逐步引入 Spring 的相关功能,比如将原有的对象创建和依赖关系管理迁移到 Spring 容器中进行统一管控。这样既能够利用 Spring 框架带来的优势,如更灵活的依赖注入、方便的生命周期管理等,又能最大程度减少对老项目已有代码逻辑的冲击,便于后续的维护与持续集成新功能,使得老项目可以平滑地向现代化的架构模式演进。
(二)基于注解(如 @Autowired 等)实现依赖注入
1. 实现原理(源码解读)
在 Spring 基于注解实现依赖注入时,关键在于对各类注解的解析以及利用这些解析结果来完成 Bean 之间的依赖关联操作。
以常用的 @Autowired 注解为例来深入剖析其源码实现原理。首先,Spring 在启动过程中会进行类路径扫描,通过 ClassPathBeanDefinitionScanner 等类来查找带有特定注解的类,并将其解析为 BeanDefinition 对象,以下是相关部分源码示意:
public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateComponentProvider {// 扫描指定的包路径下的类,查找符合条件(带有特定注解等)的类并解析为 BeanDefinition 对象public Set<BeanDefinitionHolder> findCandidateComponents(String basePackage) {Set<BeanDefinitionHolder> candidates = new HashSet<>();try {// 获取包路径下的所有资源(类文件等),利用类加载器等机制定位资源String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);for (Resource resource : resources) {if (resource.isReadable()) {try {// 读取资源对应的元数据信息(通过 ASM 等字节码读取技术或者 Java 反射机制获取类的基本信息)MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);// 判断类是否符合候选组件条件(是否带有如 @Component 及其衍生注解等)if (isCandidateComponent(metadataReader)) {// 根据元数据信息解析出 BeanDefinition 对象ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);sbd.setSource(resource);if (isCandidateComponent(sbd)) {// 进一步完善 BeanDefinition 对象,比如解析类上的其他注解信息等candidates.add(new BeanDefinitionHolder(sbd, sbd.getBeanClassName()));}}} catch (IOException ex) {// 省略异常处理逻辑throw new BeanDefinitionStoreException("IOException parsing candidate component class: " + resource, ex);}}}} catch (IOException ex) {// 省略异常处理逻辑throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);}return candidates;}// 判断元数据对应的类是否为候选组件,主要看是否带有特定的注解标识protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {AnnotationMetadata annotationMetadata = metadataReader.getAnnotationMetadata();return (annotationMetadata.hasAnnotation(Component.class.getName()) ||annotationMetadata.hasMetaAnnotation(Component.class.getName())) &&!annotationMetadata.isAnnotation();}
}
从上述源码能看出,ClassPathBeanDefinitionScanner 通过扫描类路径下的资源,利用 MetadataReader 获取类的元数据信息,然后依据是否带有如 @Component 等注解来判断是否将其作为候选组件解析成 BeanDefinition 对象,这个过程为后续基于注解的依赖注入做了前置准备。
当涉及到 @Autowired 注解的依赖注入处理时,在 Bean 创建和初始化阶段,AutowiredAnnotationBeanPostProcessor 发挥了关键作用,以下是其部分关键源码解读:
public class AutowiredAnnotationBeanPostProcessor extends InstantiationAwareBeanPostProcessorAdapter {// 处理 Bean 的属性注入,查找带有 @Autowired 等注解的属性并进行注入操作@Overridepublic PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);try {metadata.inject(bean, beanName, pvs);} catch (Throwable ex) {// 省略异常处理逻辑throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);}return pvs;}// 查找给定类中带有 @Autowired 等相关注解的属性、方法等信息,构建 InjectionMetadata 对象用于后续注入操作private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) {// 从缓存中查找已有的 InjectionMetadata 对象,如果存在则直接返回,提高性能(避免重复解析)InjectionMetadata metadata = this.injectionMetadataCache.get(clazz);if (metadata == null) {List<InjectionMetadata.InjectionPoint> points = new ArrayList<>();// 遍历类的属性,查找带有 @Autowired 等注解的属性,添加到 InjectionPoint 列表中ReflectionUtils.doWithLocalFields(clazz, field -> {AnnotationAttributes ann = findAutowiredAnnotation(field);if (ann!= null) {if (Modifier.isStatic(field.getModifiers())) {// 对于静态属性的特殊处理,Spring 不支持对静态属性直接注入(抛出异常提示等逻辑,此处省略详细源码)throw new IllegalStateException("Autowired annotation is not supported on static fields: " + field);}boolean required = determineRequiredStatus(ann);points.add(new InjectionMetadata.InjectionPoint(field, required));}});// 遍历类的方法,查找带有 @Autowired 等注解的可注入方法(如带有 @Autowired 的 setter 方法等),添加到 InjectionPoint 列表中ReflectionUtils.doWithLocalMethods(clazz, method -> {Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {return;}AnnotationAttributes ann = findAutowiredAnnotation(bridgedMethod);if (ann!= null) {if (Modifier.isStatic(bridgedMethod.getModifiers())) {// 对于静态方法的特殊处理,类似静态属性不支持直接注入(省略详细源码)throw new IllegalStateException("Autowired annotation is not supported on static methods: " + method);}boolean required = determineRequiredStatus(ann);points.add(new InjectionMetadata.InjectionPoint(bridgedMethod, required));}});metadata = new InjectionMetadata(clazz, points);this.injectionMetadataCache.put(clazz, metadata);}return metadata;}// 查找属性或方法上的 @Autowired 等相关注解,并解析注解信息获取如是否必须注入等属性private AnnotationAttributes findAutowiredAnnotation(AccessibleObject ao) {// 遍历支持的注解类型(如 @Autowired、@Value 等),查找是否存在相应注解for (Class<? extends Annotation> type : this.autowiredAnnotationTypes) {AnnotationAttributes ann = AnnotationUtils.getAnnotationAttributes(ao, type);if (ann!= null) {return ann;}}return null;}
}
在 postProcessProperties 方法中,先通过 findAutowiringMetadata 方法查找出给定 Bean 类中带有 @Autowired 注解的属性和方法等信息,构建成 InjectionMetadata 对象,然后调用其 inject 方法进行实际的注入操作。在 inject 方法(此处省略详细源码展示)中,对于属性注入会通过反射机制获取属性类型,再根据类型在 Spring 容器中查找匹配的 Bean 实例(可以是按类型匹配、按名称匹配等多种策略,依据具体配置和容器内的情况),最后通过反射调用 setter 方法或者直接设置属性值(对于非私有属性等情况)将依赖的 Bean 实例注入到当前 Bean 中;对于方法注入同理,会根据方法参数类型等查找匹配的 Bean 实例,然后调用方法完成注入。
2. 性能特点
- 启动性能:相较于 XML 配置,基于注解的方式在启动时不需要解析大量的 XML 文件内容,而是通过类路径扫描来识别带有注解的类,在一定程度上可以加快启动速度,尤其是在项目规模不是特别巨大且注解使用合理的情况下。不过,类路径扫描本身也需要遍历类文件、解析字节码信息等操作,对于包含极大量类的项目,这个过程也会消耗一定时间和内存资源,但通常比 XML 配置的解析成本要低一些。
- 运行时性能:在运行时,和 XML 配置依赖注入类似,基于注解的注入同样需要利用反射机制来查找和调用相关方法、设置属性值等,也存在一定的性能开销。但 Spring 内部会对一些常用的注入点等信息进行缓存(如前面提到的 InjectionMetadata 缓存),减少了重复查找和解析注解的次数,使得运行时的性能损耗在可接受范围内,并且随着 Java 虚拟机在反射优化等方面的不断改进(如方法内联等技术应用到反射调用场景),其运行时性能也在逐步提升。
3. 应用场景
- 快速开发小型项目:在小型的 Java 项目或者一些敏捷开发的场景中,使用基于注解的依赖注入方式可以让开发更加便捷高效。开发者只需要在需要注入依赖的地方简单地添加 @Autowired 等注解,无需编写繁琐的 XML 配置文件,能够快速地搭建起项目的业务逻辑,加快开发迭代速度,并且代码看起来更加简洁直观,易于理解和维护。
- 与代码结合紧密的功能模块:对于那些和业务代码逻辑紧密结合,需要根据代码的具体结构和功能动态调整依赖关系的模块,注解方式的依赖注入更具优势。比如在开发一个基于 Spring 的微服务应用时,各个微服务内部的业务类之间的依赖可以通过注解精准地表达,随着业务功能的不断扩展和调整,能够方便地在代码中直接修改注解配置来适应新的依赖需求,而不用在 XML 文件中去查找和修改对应的 <bean> 配置,提高了代码的灵活性和可维护性。
三、Spring 的控制反转(IOC)容器的启动流程和实现原理
(一)启动流程
Spring IOC 容器的启动是一个涉及多个阶段、多个组件协作的复杂过程,以下是其大致的启动流程概述:
- 资源定位:首先,根据配置信息(无论是 XML 配置文件还是基于注解配置等方式)确定要加载的资源位置。例如,对于 ClassPathXmlApplicationContext 这种基于类路径下 XML 配置文件启动的容器,它会通过类加载器等机制定位到指定的 XML 文件资源;对于基于注解配置的 AnnotationConfigApplicationContext,则会确定要扫描的类路径范围等,这个阶段主要是为后续的配置解析做好准备工作,确保能准确获取到描述应用程序配置的相关资源。
配置解析: - XML 配置解析:如果是基于 XML 配置,如前面所述,会通过 XmlBeanDefinitionReader 等类对 XML 文件进行解析,将其中的 <bean> 标签等配置信息转换为 BeanDefinition 对象,这些对象包含了 Bean 的类名、属性、依赖关系、生命周期配置等关键信息,构建起了内存中对应用程序中所有 Bean 的一种抽象描述模型,为后续的 Bean 实例化和管理提供依据。
- 注解配置解析:对于基于注解的配置,通过 ClassPathBeanDefinitionScanner 等组件扫描类路径下带有特定注解(如 @Component 及其衍生注解)的类,同样解析出对应的 BeanDefinition 对象,同时还会解析类上的其他相关注解(如 @Autowired 等用于依赖注入、@Scope 用于定义 Bean 的作用域等)信息,并整合到 BeanDefinition 对象中,完善对每个 Bean 的描述。
- Bean 工厂初始化:创建 BeanFactory(通常是 DefaultListableBeanFactory 等具体实现类),这是 Spring IOC 容器的核心组件之一,它负责管理所有的 BeanDefinition 对象以及后续的 Bean 实例化、依赖注入等操作。将前面解析得到的所有 BeanDefinition 对象注册到 BeanFactory 中,使其知晓应用程序中需要创建和管理哪些 Bean,并且会进行一些初始的配置和准备工作,比如设置 Bean 工厂的一些属性(如是否允许循环依赖、自动注入模式等),构建起内部用于存储和查找 BeanDefinition 的数据结构(如各种映射表等,方便后续根据 Bean 名称或类型快速定位 BeanDefinition)。
- Bean 实例化与初始化:基于注册在 BeanFactory 中的 BeanDefinition 对象,开始逐个实例化 Bean。首先通过反射机制调用构造函数创建 Bean 的对象实例(对于构造函数的选择会根据配置以及参数匹配等情况确定,后面会详细讲解构造函数实例化的源码逻辑),然后进行依赖注入操作(如前面介绍的通过 XML 配置或注解方式进行属性注入等),接着执行初始化操作,包括调用实现了 InitializingBean 接口的 afterPropertiesSet 方法或者配置了 init-method 的自定义初始化方法等,使得 Bean 在完全创建好后处于可用状态,准备好为应用程序提供服务。在这个过程中,还会处理 Bean 之间的依赖关系,如果存在循环依赖的情况(比如 A Bean 依赖 B Bean,同时 B Bean 又依赖 A Bean),Spring 也有相应的处理机制(通过提前暴露部分创建中的 Bean 实例等策略,此处省略详细的循环依赖处理源码逻辑)来确保 Bean 都能正确地被实例化和初始化。
- 容器就绪:经过上述一系列步骤,所有的 Bean 都按照配置完成了实例化、初始化等操作,Spring IOC 容器也就准备就绪,可以通过容器提供的方法(如 getBean 方法等)获取到所需的 Bean 实例,应用程序就可以利用这些 Bean 实例来执行业务逻辑,整个 Spring 框架开始为应用提供支撑,实现了对象管理、依赖注入等核心功能,让应用程序的各个组件可以在一个解耦且有序的环境中协同工作。
(二)实现原理(源码解读)
1. 资源定位与配置解析相关源码回顾
前面已经详细介绍了在 XML 配置下 XmlBeanDefinitionReader 解析 XML 文件以及在注解配置下ClassPathBeanDefinitionScanner 扫描类路径解析注解并构建 BeanDefinition 对象的源码逻辑,这里不再赘述,它们共同完成了从外部配置到内存中 BeanDefinition 模型的转换,为后续的 Bean 工厂操作提供了基础数据。
2. Bean 工厂初始化源码解读
以下是 DefaultListableBeanFactory 部分关键源码,展示其初始化以及 BeanDefinition 注册相关逻辑:
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactoryimplements ConfigurableListableBeanFactory, BeanDefinitionRegistry, Serializable {// 用于存储所有的 BeanDefinition 对象的映射表,以 Bean 名称作为键,BeanDefinition 对象作为值,方便快速查找和管理private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>();// 注册 BeanDefinition 对象到 beanDefinitionMap 中的方法,这是将外部配置解析后的信息纳入 Bean 工厂管理的关键操作@Overridepublic void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)throws BeanDefinitionStoreException {Assert.hasText(beanName, "Bean name must not be empty");Assert.notNull(beanDefinition, "Bean definition must not be null");if (beanDefinition instanceof AbstractBeanDefinition) {try {// 对 AbstractBeanDefinition 类型的 BeanDefinition 进行验证和准备工作,比如解析其中的一些表达式等配置信息((AbstractBeanDefinition) beanDefinition).validate();} catch (BeanDefinitionValidationException ex) {// 省略异常处理逻辑throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,"Validation of bean definition failed", ex);}}BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);if (existingDefinition!= null) {// 如果已经存在同名的 BeanDefinition,根据配置决定是覆盖还是抛出异常等处理方式(比如可以配置允许覆盖等情况)if (!isAllowBeanDefinitionOverriding()) {throw new BeanDefinitionStoreException(beanName,"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +"': There is already a bean definition [" + existingDefinition + "] bound");}// 省略部分覆盖时的详细逻辑,比如可能涉及到更新缓存等操作this.beanDefinitionMap.put(beanName, beanDefinition);} else {// 如果不存在同名的 BeanDefinition,直接添加到映射表中this.beanDefinitionMap.put(beanName, beanDefinition);// 同时更新一些相关的辅助数据结构(如按类型查找 BeanDefinition 的映射表等,方便后续根据类型查找 Bean)if (existingDefinition == null && containsBeanDefinition(beanName)) {// 省略部分更新逻辑}}}// 创建 Bean 工厂实例时的初始化方法,进行一些内部数据结构等的初始化设置public DefaultListableBeanFactory() {super();// 初始化用于存储按照类型查找 BeanDefinition 的映射表,方便后续基于类型获取对应的 BeanDefinitionthis.mergedBeanDefinitionHolders = new ConcurrentHashMap<>();// 初始化用于存储单例对象的缓存,在创建单例 Bean 实例后会存放在这里,后续获取单例 Bean 可直接从缓存中取,提升性能this.singletonObjects = new ConcurrentHashMap<>();// 初始化用于存储正在创建中的单例 Bean 的缓存,用于处理单例 Bean 的循环依赖问题,后面实例化过程中会涉及其使用逻辑this.singletonFactories = new HashMap<>();// 初始化用于存储提前暴露的单例 Bean 实例(处于半成品状态,可能尚未完成全部初始化流程)的缓存,同样是解决循环依赖的关键数据结构this.earlySingletonObjects = new HashMap<>();// 初始化用于存储单例 Bean 对应的工厂对象(通过工厂方法创建单例 Bean 时会用到)的缓存this.factoryBeanInstanceCache = new ConcurrentHashMap<>();// 设置是否允许 Bean 定义覆盖,默认值可以根据配置或者框架内部默认策略来确定,影响同名 BeanDefinition 注册时的处理方式this.allowBeanDefinitionOverriding = true;// 设置是否允许循环依赖,不同的应用场景下可以根据需求进行配置,默认是允许一定程度的循环依赖处理this.allowCircularReferences = true;}// 根据给定的 BeanDefinition 创建对应的 Bean 实例的核心方法,涵盖了实例化、依赖注入、初始化等完整流程@Overrideprotected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)throws BeanCreationException {try {// 检查是否需要提前实例化,比如对于一些配置了懒加载(lazy-init)的 Bean,会根据条件判断是否现在就创建if (mbd.isLazyInit() &&!mbd.hasBeanClass()) {return null;}// 确保 Bean 对应的 Class 对象已经加载,通过类加载器等机制加载类(如果还未加载的情况)Class<?> resolvedClass = resolveBeanClass(mbd, beanName);if (resolvedClass == null &&!mbd.hasBeanClass()) {throw new BeanDefinitionStoreException(mbd.getResourceDescription(), beanName,"Bean class not found");}mbd.prepareMethodOverrides();try {// 执行 Bean 的实例化操作,通过反射调用合适的构造函数创建对象实例,后面会详细展示实例化相关的具体源码逻辑Object beanInstance = doCreateBean(beanName, mbd, args);return beanInstance;} catch (BeanCreationException ex) {// 异常处理逻辑,如果实例化过程出现问题,进行相应的错误处理和日志记录等throw ex;} catch (Exception ex) {throw new BeanCreationException(mbd.getResourceDescription(), beanName,"Unexpected error during bean creation", ex);}} catch (Exception ex) {// 更广泛的异常处理逻辑,涵盖前面各个步骤中可能出现的问题throw new BeanCreationException(mbd.getResourceDescription(), beanName,"Instantiation of bean failed", ex);}}// 实际执行 Bean 实例化的方法,内部涉及到通过反射调用构造函数、处理循环依赖等关键逻辑protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {// 创建 Bean 实例的包装对象,用于处理诸如 AOP 代理等情况(如果有代理需求,后续会基于此创建代理对象替代原始的 Bean 实例)BeanWrapper instanceWrapper = null;if (mbd.isSingleton()) {// 对于单例 Bean,先从缓存中查看是否已经存在正在创建的该 Bean 的实例,如果存在,说明可能处于循环依赖情况,直接返回已有的实例(后续会进一步完善其创建流程)instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);}if (instanceWrapper == null) {// 通过反射创建 Bean 实例,调用合适的构造函数,根据 BeanDefinition 中的类信息以及参数信息(args)进行实例化操作instanceWrapper = createBeanInstance(beanName, mbd, args);}Object beanInstance = instanceWrapper.getWrappedInstance();Class<?> beanType = instanceWrapper.getWrappedClass();if (mbd.isSingleton()) {// 将刚创建的 Bean 实例放入正在创建中的单例 Bean 缓存中,标记其正在创建,用于处理可能出现的循环依赖情况this.singletonFactories.put(beanName, () -> getEarlyBeanReference(beanName, mbd, beanInstance));}// 进行属性注入操作,将依赖的其他 Bean 实例注入到当前创建的 Bean 实例中,前面已经详细介绍过依赖注入相关的源码逻辑,此处不再赘述populateBean(beanName, mbd, beanInstance);if (mbd.isSingleton()) {// 将提前暴露的单例 Bean 实例从正在创建的缓存中移除,放入提前暴露的单例 Bean 实例缓存(earlySingletonObjects)中,表明已经完成了属性注入等部分流程,可以供其他依赖它的 Bean 进一步使用(解决循环依赖)Object earlySingletonExposure = this.singletonFactories.remove(beanName);if (earlySingletonExposure!= null) {// 将提前暴露的实例添加到对应的缓存中this.earlySingletonObjects.put(beanName, earlySingletonExposure);// 注册一个销毁回调方法,用于在容器关闭等情况下清理该 Bean 实例相关资源(比如释放内存、关闭连接等,如果有需要的情况)registerDisposableBeanIfNecessary(beanName, beanInstance, mbd);}}// 执行 Bean 的初始化操作,包括调用实现了 InitializingBean 接口的方法、配置的 init-method 等,使 Bean 完全进入可用状态initializeBean(beanName, beanInstance, mbd);return beanInstance;}// 通过反射调用合适的构造函数创建 Bean 实例的方法,内部会根据 BeanDefinition 中的构造函数配置以及参数情况进行选择和调用protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {// 获取要创建的 Bean 的 Class 对象Class<?> beanClass = mbd.getBeanClass();if (beanClass!= null &&!Modifier.isPublic(beanClass.getModifiers()) &&!mbd.isNonPublicAccessAllowed()) {// 对于非公有类的情况,进行特殊的权限处理(比如通过设置访问权限等方式确保可以通过反射调用构造函数,涉及到 Java 安全管理器等相关机制,此处省略详细源码)throw new BeanCreationException(mbd.getResourceDescription(), beanName,"Bean class isn't public, and non-public access not allowed: " + beanClass.getName());}// 尝试查找合适的构造函数,根据参数匹配等情况来确定使用哪个构造函数进行实例化,如果有明确指定的构造函数(比如通过 XML 配置或者注解指定了构造函数参数等情况),则按照指定的来Constructor<?>[] ctors = determineConstructorsFromBeanDefinition(mbd, beanClass);if (ctors!= null && ctors.length > 0) {return autowireConstructor(beanName, mbd, ctors, args);}// 如果没有明确指定构造函数或者找不到合适的构造函数,使用默认的无参构造函数进行实例化(前提是类存在无参构造函数,否则会抛出异常)return instantiateBean(beanName, mbd);}// 使用默认的无参构造函数通过反射创建 Bean 实例的方法,相对比较简单直接,调用 Class 对象的 newInstance 方法来创建protected BeanWrapper instantiateBean(String beanName, RootBeanDefinition mbd) {try {// 获取要实例化的 Bean 的 Class 对象Class<?> beanClass = mbd.getBeanClass();// 创建 BeanWrapper 对象,用于包装创建出来的 Bean 实例,方便后续对实例进行各种操作(如属性注入、获取类型等)BeanWrapper bw = new BeanWrapperImpl(beanClass);// 通过反射调用无参构造函数创建实例,并将实例设置到 BeanWrapper 中Object beanInstance = beanClass.newInstance();bw.setWrappedInstance(beanInstance);return bw;} catch (InstantiationException | IllegalAccessException ex) {// 异常处理逻辑,如果实例化过程出现问题(比如类没有无参构造函数等情况),抛出相应的异常并进行错误记录等操作throw new BeanCreationException(mbd.getResourceDescription(), beanName,"Could not instantiate bean class [" + mbd.getBeanClass().getName() + "]", ex);}}}
- 从上述源码可以清晰地看到 DefaultListableBeanFactory 在整个 Bean 实例化和初始化过程中的关键逻辑流程。首先在初始化阶段构建起了多个重要的缓存和数据结构,用于存储不同状态下的 Bean 实例、BeanDefinition 以及相关的工厂对象等,这些结构为后续高效地管理和处理 Bean 的创建、依赖关系解决等提供了基础保障。
- 在 createBean 方法中启动了完整的 Bean 创建流程,其中 doCreateBean 方法是核心环节,它先尝试从缓存中获取可能已经存在的正在创建的单例 Bean 实例(用于处理循环依赖),然后通过 createBeanInstance 方法进行实际的实例化操作,这里会根据 BeanDefinition 中构造函数的配置情况选择合适的构造函数(有指定就按指定的来,没有则尝试使用无参构造函数)通过反射进行调用创建出 Bean 实例。接着进行属性注入操作,将依赖的其他 Bean 实例填充到当前创建的 Bean 实例中,再处理单例 Bean 的循环依赖相关缓存操作,最后执行初始化步骤,使得 Bean 实例完全准备好,可以投入到应用程序的业务逻辑中使用。
3. 性能特点
启动阶段性能:
- 资源消耗方面:Spring IOC 容器启动时,尤其是首次启动,需要加载配置(无论是 XML 还是扫描类路径解析注解等)、解析并构建众多的 BeanDefinition 对象,还要初始化 BeanFactory 内部的各种缓存和数据结构,这个过程会占用一定的内存空间。对于大型项目,配置繁多、Bean 数量庞大时,内存消耗会比较明显,可能导致启动过程中内存占用较高,甚至在内存资源紧张的环境下影响启动速度或者出现内存不足相关问题。
- 时间成本方面:配置解析、BeanDefinition 构建以及 BeanFactory 的初始化操作都需要耗费时间,像 XML 配置文件的解析可能因文件大小、复杂程度(例如存在大量嵌套的 <bean> 标签、复杂的条件配置等)而花费较多时间;类路径扫描查找带注解的类同样在面对大量类文件时耗时会增加,而且后续实例化和初始化 Bean 时,如果存在复杂的依赖关系(如多层嵌套依赖、循环依赖等),处理这些依赖并确保 Bean 正确创建也会在启动阶段带来额外的时间开销。
运行阶段性能:
- Bean 获取性能:一旦容器启动完成,后续获取 Bean 实例时,如果是单例 Bean,得益于 BeanFactory 中的单例缓存机制(如 singletonObjects 缓存),从缓存中直接获取已创建好的单例 Bean 速度是比较快的,能快速响应应用程序对 Bean 的请求。但对于非单例(如原型 prototype 作用域的 Bean),每次获取都需要重新创建实例、进行依赖注入和初始化等操作,相对来说耗时会更长,不过这也符合原型 Bean 的设计初衷,即每次获取都是一个新的独立实例。
- 依赖注入性能:在运行时进行依赖注入(无论是基于 XML 配置的属性注入还是基于注解的注入),如前面所述,依然依赖反射机制来查找和调用相关方法、设置属性值等,存在一定的性能损耗。然而,Spring 通过缓存部分常用的注入相关信息(如 InjectionMetadata 等)以及对单例 Bean 实例化后相关依赖关系的固定化处理(减少重复查找和注入操作),使得在常规业务场景下,这种性能损耗通常不会对整体应用程序性能造成严重影响,能够维持在一个可接受的运行效率水平。
4. 应用场景
- 企业级应用开发:在大型的企业级 Java 应用中,Spring 的 IOC 容器发挥着至关重要的作用。它可以管理海量的 Bean 实例,处理复杂的模块间依赖关系,例如在一个电商系统中,订单模块、用户模块、商品模块等众多业务模块对应的服务层、数据访问层等各类 Bean 都可以通过 Spring IOC 容器进行统一管理,实现解耦式的开发和部署。开发团队可以专注于各自模块的业务逻辑开发,通过配置(XML 或注解)定义好 Bean 之间的依赖,由 Spring 容器负责在启动时完成实例化和装配,确保整个系统能够稳定、高效地运行。
- 微服务架构:在微服务架构下,每个微服务本身也是一个相对独立的 Java 应用,Spring IOC 容器同样适用。它可以帮助微服务轻松管理内部的各种组件 Bean,比如在一个用户认证微服务中,认证服务、权限管理服务、用户信息服务等相关 Bean 通过 Spring IOC 容器进行创建和依赖管理,并且结合 Spring Cloud 等相关框架,还能实现微服务之间的配置管理、服务发现等功能,使得微服务架构下的应用开发更加便捷、高效,各个微服务能够灵活地进行独立开发、部署和扩展,同时又能通过合适的机制进行协同工作。
- 测试环境搭建:在进行单元测试、集成测试等不同层次的测试时,Spring IOC 容器也大有用处。可以方便地在测试类中通过配置(通常采用注解配置方式更简洁)创建一个轻量级的 Spring 容器,将被测对象以及其依赖的对象都作为 Bean 纳入容器管理,然后通过容器获取相关 Bean 实例进行测试操作,这样能够更真实地模拟应用程序的实际运行环境,准确地测试出各个组件的功能以及它们之间的协作是否正常,提高测试的全面性和有效性。
相关文章:
)
【Spring】详解(上)
Spring 框架核心原理与应用(上) 一、Spring 框架概述 (一)诞生背景 随着 Java 应用程序规模的不断扩大以及复杂度的日益提升,传统的 Java开发方式在对象管理、代码耦合度等方面面临诸多挑战。例如,对象之…...

短视频矩阵系统后端源码搭建实战与技术详解,支持OEM
一、引言 随着短视频行业的蓬勃发展,短视频矩阵系统成为了众多企业和创作者进行多平台内容运营的有力工具。后端作为整个系统的核心支撑,负责处理复杂的业务逻辑、数据存储与交互,其搭建的质量直接影响着系统的性能、稳定性和可扩展性。本文将…...

力扣每日刷题
24. 两两交换链表中的节点 - 力扣(LeetCode) 递归写法 做题思路:把需要交换的两个数的前一个数作为参数传入,然后使用一个变量保存这两个变量的后一个数,交换这个两个数,最后把第二个数(原第一…...
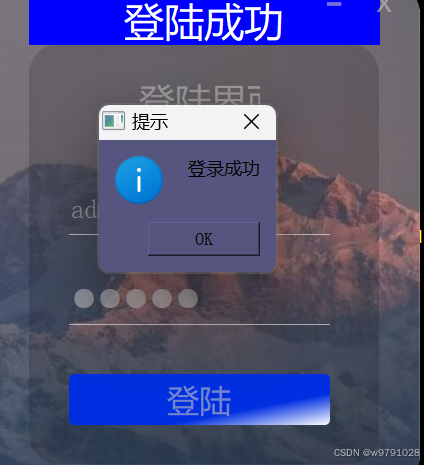
QT的信号和槽页面的应用
完善对话框,点击登录弹出对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后,关闭登录界面,跳转到其他界面 如果账号和密码不匹配&…...

【Java】线程相关面试题 (基础)
文章目录 线程与进程区别并行与并发区别解析概念含义资源利用执行方式应用场景 创建线程线程状态如何保证新建的三个线程按顺序执行wait方法和sleep方法的不同所属类和使用场景方法签名和参数说明调用wait方法的前提条件被唤醒的方式与notify/notifyAll方法的协作使用示例注意事…...

【数字化】华为一体四面细化架构蓝图
导读:华为的“一体四面”企业架构设计方法是一种综合性的管理框架,它通过业务架构、信息架构、应用架构和技术架构的集成设计,构建出一个既符合业务需求,又具备高度灵活性和可扩展性的IT系统。这种架构设计方法强调从业务视角出发…...

frameworks 之 WMS添加窗口流程
frameworks 之 触摸事件窗口查找 1.获取WindowManager对象2.客户端添加view3. 服务端添加view (NO_SURFACE)4.重新布局 (DRAW_PENDING)4.1 创建 SurfaceControl 5.通知绘制 (COMMIT_DRAW_PENDING, READY_TO_SHOW, HAS_DRAWN)5. 1 布局测量和刷新 6.总结 …...

搜索方法归类全解析
搜索方法归类全解析 搜索方法是人工智能和计算机科学中用于解决问题、优化路径或发现数据模式的关键技术。根据不同的标准,搜索方法可以被分为多种类别。本文将详细介绍这些分类标准,并探讨每一类的特点及其代表算法,同时补充更多关于搜索的相…...

第1关:简易考试系统之用户注册
任务描述 本关任务:实现简易考试系统中新用户注册的功能。 编程要求 仔细阅读右侧编辑区内给出的代码框架及注释,在 Begin-End 中实现简易考试系统中新用户注册的功能,具体要求如下: User.java 提供了用户的基本信息,…...
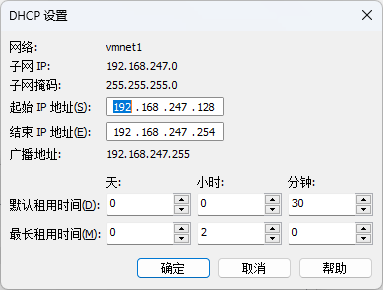
VMware的三种网络模式——在NAT模式下开放接口为局域网内其他主机提供服务
众所周知 VMware 有三种常用的网络通讯模式,分别是:Bridged(桥接模式)、NAT(网络地址转换模式)、Host-Only(仅主机模式),它们各有不同的用法。 Bridged 桥接模式是与主机…...

智慧地下采矿:可视化引领未来矿业管理
图扑智慧地下采矿可视化平台通过整合多源数据,提供实时 3D 矿井地图及分析,提升了矿产开采的安全性与效率,为矿业管理提供数据驱动的智能决策支持,推动行业数字化转型。...

流量主微信小程序工具类去水印
工具类微信小程序流量主带后台管理,可开通广告,带自有后台管理,不借助第三方接口 介绍 支持抖音,小红书,哔哩哔哩视频水印去除,功能实现不借助第三方平台。可实现微信小程序流量主广告变现功能,…...

代码随想录算法【Day5】
DAY5 1.熟悉哈希表的数据结构:数组、map和set,使用方法、使用场景 2.哈希表应用场景:解决给你一个元素,判断它在集合里是否出现过。 242.有效的字母异位词 本题用数组解决的。 class Solution { public:bool isAnagram(strin…...

Leetcode 3403. Find the Lexicographically Largest String From the Box I
Leetcode 3403. Find the Lexicographically Largest String From the Box I 1. 解题思路2. 代码实现 题目链接:3403. Find the Lexicographically Largest String From the Box I 1. 解题思路 这一题我一开始的思路是想用动态规划,结果发现想复杂了&…...

【游戏设计原理】36 - 环境叙事
一、 分析并总结 核心要点 环境叙事的本质:将游戏的设定视为叙事的一部分,利用环境元素(如物品、对话、视觉效果等)传递故事和信息。世界设定的重要性:一个强大的世界设定可以像角色一样,驱动叙事并增强玩…...

Python 中的 lambda 函数和嵌套函数
Python 中的 lambda 函数和嵌套函数 Python 中的 lambda 函数和嵌套函数Python 中的 lambda 函数嵌套函数(内部函数)封装辅助函数闭包和工厂函数 Python 中的 lambda 函数和嵌套函数 Python 中的 lambda 函数 Lambda 函数是基于单行表达式的匿名函数。…...

语言模型评价指标
1. BLEU(Bilingual Evaluation Understudy) 目标:衡量生成文本和参考文本之间的词汇相似性。 计算步骤: N-gram 匹配: 将生成文本和参考文本分解成 1-gram、2-gram、…、N-gram(通常取到 4-gramÿ…...
工程师 - MSYS2介绍
https://www.msys2.org/ MSYS2 是一系列工具和库,为您提供了一个易于使用的环境,用于构建、安装和运行本地 Windows 软件。 MSYS2 is a collection of tools and libraries providing you with an easy-to-use environment for building, installing an…...

算法基础三:插入排序
定义 插入排序(英语:Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用…...

小米汽车加速出海,官网建设引领海外市场布局!
面对国内市场的饱和态势,中国企业出海步伐纷纷加速,小米也是其中的一员。Canalys数据显示,2024年第三季度,小米以13.8%的市场份额占比,实现了连续17个季度位居全球前三的成绩。 据“36 氪汽车”报道,小米汽…...

OpenClaw排错指南:Kimi-VL-A3B-Thinking接口调用常见问题解决
OpenClaw排错指南:Kimi-VL-A3B-Thinking接口调用常见问题解决 1. 为什么需要这份排错指南? 上周我在本地部署OpenClaw对接Kimi-VL-A3B-Thinking多模态模型时,遇到了连续三个通宵都没解决的接口调用问题。从模型响应超时到多模态数据处理异常…...

CVPR‘26 | 从任务统一到模态协同:电商通用多模态表征MOON 2.0
小记:自 2023 年以来,电商多模态表征模型 MOON 历经 3 年多的持续建设与迭代升级,已在阿里妈妈搜索直通车全面落地,并在多个核心场景中取得显著效果。以精排 CTR 预估模型为例,累计全量 5 期,带来大盘 CTR …...

macOS一键部署OpenClaw:Phi-3-vision-128k-instruct多模态体验教程
macOS一键部署OpenClaw:Phi-3-vision-128k-instruct多模态体验教程 1. 为什么选择OpenClawPhi-3组合 上周我在整理团队项目文档时,突然意识到一个痛点:每次收到同事发来的截图和文字混合内容,都需要手动复制粘贴到笔记软件里分类…...

知网AIGC查重的原理与降AI的实用技巧
很多同学看到查重报告里AIGC指数飙升时,第一反应是恐慌,觉得系统看出了文章不是自己写的。其实没必要把检测系统想得太智能,它根本读不懂文章的内容。 目前的检测逻辑主要基于两个核心统计学指标:困惑度和突发性。只要搞懂这两个概…...
)
PHP Swoole 进阶必学核心(EventLoop深度解剖+内存泄漏避坑手册)
第一章:PHP Swoole 进阶必学核心(EventLoop深度解剖内存泄漏避坑手册)Swoole 的 EventLoop 是其高性能异步 I/O 的心脏,本质是单线程 Reactor 模式驱动的事件循环,底层基于 epoll/kqueue/iocp 封装。它并非简单轮询&am…...

JTAG接口原理与调试实战指南
1. JTAG接口基础解析与核心功能JTAG(Joint Test Action Group)作为现代数字系统开发中不可或缺的调试接口,其重要性往往被工程师们低估。这个诞生于1985年的IEEE 1149.1标准,最初是为了解决PCB板级互联测试难题,如今已…...

ArcGIS空间连接实战:如何高效挂接地图斑属性到mdb数据库
ArcGIS空间连接实战:高效挂接地图斑属性到mdb数据库的完整指南 在空间数据处理工作中,将属性数据与空间图形精准关联是GIS分析的基础环节。许多技术人员在使用ArcGIS进行地图斑属性挂接时,常遇到数据不匹配、连接失败或效率低下的问题。本文将…...
—— 终章(MVVM架构初见杀)姑)
WPF新手村教程(七)—— 终章(MVVM架构初见杀)姑
1. 哑铃图是什么? 哑铃图(Dumbbell Plot),有时也称为DNA图或杠铃图,是一种用于比较两个相关数据点的可视化图表。 它源于人们对更有效数据比较方式的持续探索。 在传统的时间序列比较中,我们通常使用两条折…...
:跨文化智慧重构与AI时代的文明觉醒)
贾子哲学(Kucius Philosophy):跨文化智慧重构与AI时代的文明觉醒
贾子哲学(Kucius Philosophy):跨文化智慧重构与AI时代的文明觉醒摘要: 贾子哲学由贾龙栋(笔名贾子)于2025-2026年提出,融合东西方智慧,以“智慧三定律”区分智能与智慧,以…...

如何永久保存微信聊天记录并生成个人数据报告?WeChatMsg让数据掌握在自己手中
如何永久保存微信聊天记录并生成个人数据报告?WeChatMsg让数据掌握在自己手中 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...