Python编程技术
设计目的
该项目框架Scrapy可以让我们平时所学的技术整合旨在帮助学习者提高Python编程技能并熟悉基本概念:
1. 学习基本概念:介绍Python的基本概念,如变量、数据类型、条件语句、循环等。
2. 掌握基本编程技巧:教授学生如何使用Python编写简单的程序,如计算器、字符串处理等。
3. 熟悉Python样式指南:学习Python的官方样式指南(PEP 8),如编码风格、行长限制等,以确保代码的可读性和可维护性。
4. 掌握常见数据结构和算法:介绍列表、元组、字典、栈、队列等常见数据结构,以及相关的算法,如排序、搜索等。
5. 学习基于对象的编程:教授学生如何使用Python的面向对象编程(OOP)概念,如类、对象、继承、多态等。
6. 掌握网络编程:介绍Python网络编程中的基本概念和技术,如网络请求、网络服务器、套接字等。
7. 学习多线程和多进程编程:教授学生如何使用Python的多线程和多进程编程技术,以提高程序性能和可扩展性。
8. 熟悉Python库和模块:介绍Python的常用库和模块,如from os import remove from time import sleep等,以便学生在实际项目中应用Python编程技能。
9. 实践项目:通过完成实践项目,帮助学生将所学知识应用到实际编程场景,提高实际编程能力。
代码审查和优化:教授学生如何对自己和他人的Python代码进行审查,以提高代码质量和可读性。
10.通过这个课程,学生将掌握Python编程的基本技能,了解Python的编程风格和最佳实践,并学会应用Python编程技能来解决实际问题
11. Scrapy框架介绍:介绍Scrapy的主要功能和使用场景,以便学习者了解如何使用Scrapy进行爬取。Scrapy的使用步骤:详细介绍如何使用Scrapy编写爬虫脚本,包括定义爬虫项目、设置爬虫设置、编写爬虫规则和处理爬取结果等。实际爬取案例:通过实际爬取案例,如爬取广东各城市天气预报,帮助学习者了解如何使用Scrapy爬取实际世界中的天气预报数据。处理HTML标签和网页源代码:教授学习者如何识别和处理常见HTML标签,以及如何理解网页源代码结构。使用Beautiful Soup库:介绍Beautiful Soup库的功能,并通过实际例子教授学习者如何使用Beautiful Soup从网页中提取数据。
设计内容与要求
1、熟练安装 Python 扩展库 scrapy。
2、熟悉常见 HTML 标签的用法。
3、理解网页源代码结构。
4、理解 scrapy 框架工作原理。实验内容:
5.安 装 Python 扩 展 库 scrapy , 然 后 编 写 爬 虫 项 目 , 从 网 站 http://www.weather.com.cn/guangdong/index.shtml 爬取广东各城市的天气预报数据,并把爬取到的天气数据写入本地文本 weather.txt。
设计思路
学习使用Scrapy框架爬取天气预报,提高Python爬虫技能
在这次课程考核实验中,我们将使用Python和Scrapy框架编写一个爬取天气预报的项目。具体实验步骤如下:
1. 安装Scrapy:首先,确保已安装Python扩展库Scrapy。可以通过`pip install scrapy`命令安装。
2. 创建爬虫项目:创建一个新的Python文件,例如`weather_spider.py`,并在其中定义爬虫类。在爬虫类中,我们将编写代码来爬取天气预报信息。
3. 编写爬虫代码:在爬虫类的`parse`方法中,我们将使用Scrapy的API来提取网页中的天气信息。具体实现方法可能因网站的结构和布局而异,但通常可以使用XPath或CSS选择器来提取所需的元素。
4. 运行爬虫:在命令行中运行爬虫项目,并指定爬取的城市和天气预报的时间范围。例如:`scrapy crawl weather_spider -a start_dates=2023-12-15,end_dates=2023-12-24 -s OUTPUT=file:///path/to/output.txt`.
5. 保存爬取结果:爬虫运行完成后,将爬取到的天气信息保存到指定的文件中,例如`output.txt`。
通过这个实验,您将学习如何使用Python和Scrapy框架爬取天气预报信息。在实际应用中,您可以根据需要调整爬虫代码以适应不同的网站结构和布局。同时,您还可以尝试使用其他爬虫技术,如 Beautiful Soup 和 Selenium,以进一步提高爬取效率和灵活性。以下是设计的流程图
实现过程
实验过程和实验步骤如下以及详细的核心代码解释
1.在命令提示符环境使用 pip install scrapy 命令安装 Python 扩展库 scrapy
2.在vscode的终端中使用命令提示符 scrapy startproject GuangDongWeather创建爬虫项目文件
3.进入爬虫项目文件夹,然后执行命令 scrapy genspider GuangDongWeatherSpider www.weather.com.cn 创建爬虫程序。
4.使用浏览器打开网址http://www.weather.com.cn/guangdong/index.shtml,
5.找到下面位置 广东天气预报 - 广东

6.在页面上单击鼠标右键,选择“查看网页源代码”,然后找到与“城市预报列表” 对应的位置。

7.选择并打开广东省内任意城市的天气预报页面,此处以深圳为例

8.在页面上单击鼠标右键,选择“查看网页源代码”,找到与上图中天气预报相对应 的位置。

9.修改items.py文件,定义要爬取的内容如下
import scrapyclass GuangDongWeatherSpiderItem(scrapy.Item):city = scrapy.Field()weather = scrapy.Field()# define the fields for your item here like:# name = scrapy.Field()pass
10.修改爬虫文件 GuangDongWeatherSpider.py,定义如何爬取内容,其中用到的规则参考前面对页面的分析,如果无法正常运行,有可能是网页结构有变化,可以回到前面的步骤重新分析网页源代码,代码如下
import scrapy
from os import remove
from time import sleep
from GuangDongWeather.items import GuangDongWeatherSpiderItemclass EveryCitySpider(scrapy.Spider):name = 'GuangDongWeatherSpider'allowed_domains = ['www.weather.com.cn']# 首页,爬虫开始工作的页面start_urls = ['http://www.weather.com.cn/shengzhen/index.shtml']try:remove('lqf.txt')except:passdef parse(self, response):# 获取每个地市的链接地址,针对每个链接地址发起请求urls = response.css('dt>a[title]::attr(href)').getall()for url in urls:yield scrapy.Request(url=url, callback=self.parse_city)sleep(0.3)def parse_city(self, response):'''处理每个地市天气预报链接地址的实例方法'''# 用来存储采集到的信息的对象item = GuangDongWeatherSpiderItem()# 获取城市名称city = response.xpath('//div[@class="crumbs fl"]/a[3]/text()')item['city'] = city.get()# 定位包含天气预报信息的ul节点,其中每个li节点存放一天的天气selector = response.xpath('//ul[@class="t clearfix"]')[0]weather = []# 遍历当前ul节点中的所有li节点,提取每天的天气信息for li in selector.xpath('./li'):# 提取日期date = li.xpath('./h1/text()').get()# 云的情况cloud = li.xpath('./p[@title]/text()').get()# 晚上不显示高温high = li.xpath('./p[@class="tem"]/span/text()').get('none')low = li.xpath('./p[@class="tem"]/i/text()').get()wind = li.xpath('./p[@class="win"]/em/span[1]/@title').get()wind += ','+li.xpath('./p[@class="win"]/i/text()').get()weather.append(f'{date}:{cloud},{high}/{low},{wind}')item['weather'] = '\n'.join(weather)return [item]
11.修改 settings.py 文件,分派任务,指定处理数据的程序如下,这里划线的名称要对应你的文件名,相当于再找信道,在GuangDongWeather这个文件下找pipelines然后再找里面的GuangDongWeathersSpiderPipeline
BOT_NAME = "GuangDongWeather"SPIDER_MODULES = ["GuangDongWeather.spiders"]
NEWSPIDER_MODULE = "GuangDongWeather.spiders"
ITEM_PIPELINES = {
'GuangDongWeather.pipelines.GuangDongWeatherSpiderPipeline':1,
}
12.修改 pipelines.py 文件,把爬取到的数据写入文件 lqf.txt代码如下
from itemadapter import ItemAdapterclass GuangDongWeatherSpiderPipeline(object):def process_item(self, item, spider):with open('lqf.txt', 'a', encoding='utf8') as fp: fp.write(item['city']+'\n') fp.write(item['weather']+'\n\n')return item
13.最后就可以通过命令去运行框架如下,你需要去到对应的目录下运行,不然会报错
scrapy crawl GuangDongWeatherSpider最后需要注意以下几点,第一需要注意的就是版本的问题,第二框架问题,第三电脑问题,这个时候你就要多留意一下报错的原因,然后代码都要进行分析看看它再说的什么,这样子就可以解决大部分问题
相关文章:
Python编程技术
设计目的 该项目框架Scrapy可以让我们平时所学的技术整合旨在帮助学习者提高Python编程技能并熟悉基本概念: 1. 学习基本概念:介绍Python的基本概念,如变量、数据类型、条件语句、循环等。 2. 掌握基本编程技巧:教授学生如何使…...

「Mac玩转仓颉内测版55」应用篇2 - 使用函数实现更复杂的计算
本篇教程基于仓颉编程语言扩展了计算器功能,支持加减乘除的基础运算,以及幂运算和开平方等高级功能。代码经过简化后,移除了对输入的复杂校验,提升了程序的可维护性和交互效率。 关键词 仓颉编程语言函数封装高级运算 一、功能说…...

map参数详解
const items new Array(15).fill(null).map((_, index) > ({key: index 1,label: nav ${index 1}, })); $.map() 函数用于使用指定函数处理数组中的每个元素(或对象的每个属性),并将处理结果封装为新的数组返回。 注意:1. 在jQuery 1.6 之前&#…...

OSI 七层模型 | TCP/IP 四层模型
注:本文为 “OSI 七层模型 | TCP/IP 四层模型” 相关文章合辑。 未整理去重。 OSI 参考模型(七层模型) BeretSEC 于 2020-04-02 15:54:37 发布 OSI 的概念 七层模型,亦称 OSI(Open System Interconnection…...

高转速风扇|无刷暴力风扇方案设计
在当今科技高速发展的时代,电子设备的性能不断提升,散热问题也日益成为关注的焦点。而 13w 高转速暴力风扇方案的出现,为解决各种设备的散热难题提供了强大的技术支持。 一、高转速暴力风扇的重要性 随着电子设备的不断升级,其功率…...

GPU 进阶笔记(三):华为 NPU/GPU 演进
大家读完觉得有意义记得关注和点赞!!! 1 术语 1.1 CPU1.2 GPU1.3 NPU / TPU1.4 小结2 华为 DaVinci 架构:一种方案覆盖所有算力场景 2.1 场景、算力需求和解决方案2.2 Ascend NPU 设计3 路线一:NPU 用在手机芯片&…...

计算机网络 (13)信道复用技术
前言 计算机网络中的信道复用技术是一种提高网络资源利用率的关键技术。它允许在一条物理信道上同时传输多个用户的信号,从而提高了信道的传输效率和带宽利用率。 一、信道复用技术的定义 信道复用(Multiplexing)就是在一条传输媒体上同时传输…...

数据库约束和查询
一 约束意义 这个后面的字段是什么意思呢? 先前说数据类型是一种约束,约束我们只能放该类型的数据,还有其它的约束来保证数据的合法性,下面的字段就和约束有关。 编译器的编译就是一个约束,保证我们的代码一定是语法合格的。我们…...

网工日记:FTP两种工作模式的区别
FTP 的主动模式和被动模式在连接建立的发起方、数据传输端口以及对网络环境的适应性等方面存在明显区别: 1. 连接发起方 主动模式:数据连接由服务器主动发起。在控制连接建立后,客户端通过 PORT 命令告知服务器自己用于接收数据的临时端口号…...

NLP模型工程化部署
文章目录 一、理论-微服务、测试与GPU1)微服务架构2)代码测试3)GPU使用 二、实践-封装微服务,编写测试用例和脚本,并观察GPU1)微服务封装(RestFul和RPC)2)测试编写(unit_test\api_test\load_tes…...

分布式版本管理工具——git 中忽略文件的版本跟踪(初级方法及高级方法)
git工具忽略指定文件的版本跟踪 一、简单方式实现二、复杂方式实现(模式匹配)1. 相关规则2. 应用案例a) 忽略所有内容b) 忽略所有目录(不忽略当前目录的具体文件)c)忽略指定目录下的所有文件,但排除某文件d)…...
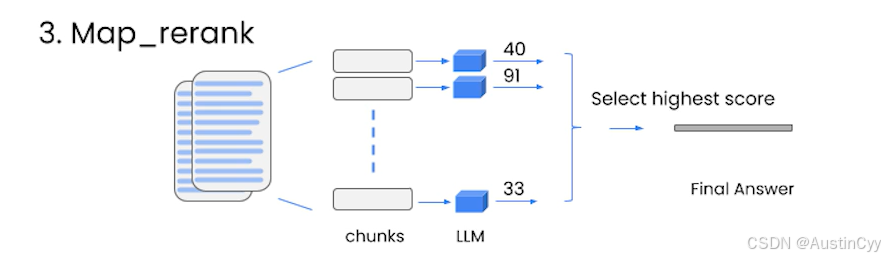
【LangChain】Chapter4 - Question and Answer Over Documents
说在前面 文档问答,是常见的一类LLM应用,给定一段可能是从 PDF文件、网页或某公司内部文档库中提取的文本,使用LLM回答关于这些文档内容的问题。这样的应用非常的强大,它可以将LLM与完全没被训练的数据相结合,可以灵活…...

TCP/IP 协议演进中的瓶颈,权衡和突破
所有(去掉 “几乎” 修饰)问题都来自于生长速度的不一致,换句话说,膨胀不是均匀的,从而产生瓶颈甚至触碰极限,TCP/IP 从协议到实现面临的多方问题与动物体型不能无限大,摩天大楼不能无限高本质上一样。 如今被高性能网…...

软件测试面试八股文,查漏补缺(附文档)
大家好,最近有不少小伙伴在后台留言,准备面试了,又不知道从何下手!为了帮大家节约时间,特意准备了一份面试相关的资料,内容非常的全面,真的可以好好补一补,希望大家在都能拿到理想的…...
IDEA工具使用介绍、IDEA常用设置以及如何集成Git版本控制工具
文章目录 一、IDEA二、建立第一个 Java 程序三、IDEA 常用设置四、IDEA 集成版本控制工具(Git、GitHub)4.1 IDEA 拉 GitHub/Git 项目4.2 IDEA 上传 项目到 Git4.3 更新提交命令 一、IDEA 1、什么是IDEA? IDEA,全称为 IntelliJ ID…...
YOLOv10-1.1部分代码阅读笔记-transformer.py
transformer.py ultralytics\nn\modules\transformer.py 目录 transformer.py 1.所需的库和模块 2.class TransformerEncoderLayer(nn.Module): 3.class AIFI(TransformerEncoderLayer): 4.class TransformerLayer(nn.Module): 5.class TransformerBlock(nn.Module)…...

机器人革新!ModbusTCP转CCLINKIE网关揭秘
在当今这个科技日新月异的时代,机器人技术正以前所未有的速度发展着,它们在工业制造、医疗服务、家庭娱乐等多个领域扮演着越来越重要的角色。而随着机器人应用的普及和多样化,如何实现不同设备之间的高效通信成为了一个亟待解决的问题。开疆…...

JWT包中的源码分析【Golang】
前言 最近在学web编程的途中,经过学长提醒,在进行登陆(Login)操作之后,识别是否登陆的标识应该要放入authorization中,正好最近也在学鉴权,就顺便来看看源码了。 正文 1. 代码示例 在进行分…...

SpringBoot数据字典字段自动生成对应code和desc
效果:接口会返回orderType,但是这个orderType是枚举的类型(1,2,3,4),我想多返回一个orderTypeDesc给前端展示,这样前端就可以直接拿orderTypeDesc使用了。 1. 定义注解 …...

TencentOS 2.4 final 安装mysql8.0备忘录
准备 tencentOS 2.4 与Red Hat Enterprise Linux 7 是兼容的。 我们首先从oracle官网上下载mysql的源文件。 下载完成后你会得到以下文件: mysql84-community-release-el7-1.noarch.rpm 安装 首先你需要切换到root用户下。 1.安装源文件 yum localinstall my…...

电子电路中的“心脏”:电源猛
前言 Kubernetes 本身并不复杂,是我们把它搞复杂的。无论是刻意为之还是那种虽然出于好意却将优雅的原语堆砌成 鲁布戈德堡机械 的狂热。平台最初提供的 ReplicaSets、Services、ConfigMaps,这些基础组件简单直接,甚至显得有些枯燥。但后来我…...

基于Simulink的2ASK调制解调系统建模与性能对比分析
1. 2ASK调制解调系统基础入门 第一次接触通信系统仿真时,我被各种调制方式搞得头晕眼花。直到用Simulink搭建了第一个2ASK模型,才发现原来通信原理可以这么直观。**2ASK(二进制幅移键控)**是最基础的数字调制方式之一,…...

fasdfas
fasdfasd...
)
linux指令的介绍(2)
此次核心介绍新的指令1.rm 删文件2.man查指令使用3.cp 拷贝文件内容4.cat 打印文件内容5.mv 剪切内容6.less 一页一页的打印文件内容7.date 查时间1.rm删文件rmdir:只能删空目录ubuntuVM-0-2-ubuntu:~/lesson3$ ll total 12 drwxrwxr-x 3 ubuntu ubuntu 4096 Mar 2…...

面试必问:JDK 8有哪些新特性?这一篇彻底讲清楚
如果你也有这些困惑,那这篇文章就是为你准备的。 我用了一整天时间,把Java从1996年诞生到今天的发展历程彻底梳理了一遍。看完这篇,你不仅知道每个版本有哪些重要特性,还能明白"为什么企业都用JDK 8"、"新项目该选…...

网络安全:4个热门有用的开源网络入侵检测系统
网络安全:4个热门有用的开源网络入侵检测系统 入侵检测系统可以分为两种类型:网络入侵检测系统(Network IDS,NIDS)和主机入侵检测系统(Host IDS,HIDS)。NIDS监测网络流量࿰…...

手把手教你用UTM在Mac M1上轻松运行Win11虚拟机
1. 为什么要在Mac M1上运行Win11虚拟机? 作为一个长期使用Mac的开发者,我完全理解那种偶尔需要Windows应用的痛苦。特别是遇到银行插件、专业工业软件或者某些游戏时,双系统切换实在太麻烦。UTM虚拟机给了我一个完美的解决方案——在M1芯片的…...

IDM绿色直装版:无限制满速下载神器
今中午下资料,用IDM跑满1000M宽带。100MB/s的速度,三分钟下完2G文件。同事凑过看:“你这下载咋这么快?”我笑:“IDM直装版,不折腾才快。”突然觉得,好工具像高速路。不堵车,事儿就成…...

如何彻底禁用Windows Defender?开源工具Defender Control完整指南
如何彻底禁用Windows Defender?开源工具Defender Control完整指南 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-con…...

FUXA工业监控平台架构设计:构建现代化SCADA系统的技术洞察
FUXA工业监控平台架构设计:构建现代化SCADA系统的技术洞察 【免费下载链接】FUXA Web-based Process Visualization (SCADA/HMI/Dashboard) software 项目地址: https://gitcode.com/gh_mirrors/fu/FUXA FUXA是一个基于Web的SCADA/HMI平台,专为工…...