《机器学习》——KNN算法
文章目录
- KNN算法简介
- KNN算法——sklearn
- sklearn是什么?
- sklearn 安装
- sklearn 用法
- KNN算法 ——距离公式
- KNN算法——实例
- 分类问题
- 完整代码——分类问题
- 回归问题
- 完整代码 ——回归问题
KNN算法简介
- 一、KNN介绍
-
全称是k-nearest neighbors,通过寻找k个距离最近的数据,来确定当前数据值的大小或类别。是机器学习中最为简单和经典的一个算法。

-
- 二、KNN算法的基本要素
- K值的选择:K值代表选择与新测试样本距离最近的前K个训练样本数,通常K是不大于20的整数。K值的选择对算法结果有重要影响,需要通过交叉验证等方法来确定最优的K值。
- 距离度量:常用的距离度量方式包括闵可夫斯基距离、欧氏距离、曼哈顿距离、切比雪夫距离、余弦距离等。其中,欧氏距离在KNN算法中最为常用。
- 分类决策规则:一般采用多数投票法,即选择K个最相似数据中出现次数最多的类别作为新数据的分类。
- 三、KNN算法的工作流程
- 准备数据:对数据进行预处理,包括收集、清洗和归一化等步骤,以确保所有特征在计算距离时具有相等的权重。
- 计算距离:计算测试样本点到训练集中每个样本点的距离。
- 排序与选择:根据距离对样本点进行排序,并选择距离最小的K个样本点作为测试样本的邻居。
- 分类决策:根据K个邻居的类别信息,采用多数投票法确定测试样本的类别。
- 四.KNN算法的优缺点
- 优点:
1.简单,易于理解,易于实现,无需训练;
2.适合对稀有事件进行分类;
3.对异常值不敏感。 - 缺点:
1.样本容量比较大时,计算时间很长;
⒉.不均衡样本效果较差;
- 优点:
KNN算法——sklearn
sklearn是什么?
- Sklearn (Scikit-Learn) 是基于 Python 语言的第三方机器学习库。它建立在 NumPy, SciPy, Pandas 和 Matplotlib库 之上,里面的 API 的设计非常好,所有对象的接口简单,很适合新手上路。
sklearn 安装
pip install scikit-learn
# 也可以自行选择版本,注意不同版本可能会有差异,还可以在后面加-i 镜像地址
# 如:
pip install scikit-learn==1.0.2 -i https://pypi.mirrors.ustc.edu.cn/simple/
sklearn 用法
- 使用sklearn官网API:https://scikit-learn.org/,knn算法的介绍 搜索k-nearest neighbors,注意版本1.0和1.2问题。
- sklearn中有两种KNN算法的用法:KNeighborsClassifier(分类问题), KNeighborsRegressor(回归问题),故此要使用KNN算法时首先要判断需求是分类问题还是回归问题。
KNN算法 ——距离公式


- 等距离公式还有很多:距离公式
KNN算法——实例
分类问题
- 导入模块
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# sklearn中的neighbors模块的KNeighborsClassifier方法
- 导入数据
data = np.loadtxt('datingTestSet2.txt')
# 使用numpy中的loadtxt方法读取txt文件,读取后内容为数组
-
提取数据
-
data[:, -1]:这部分是数组的切片操作。data是一个二维数组,: 表示选取所有行,-1 表示选取最后一列。因此,data[:, -1] 获取了data数组中所有行的最后一列的数据。
-
data[:, -1] == 1:这部分将上一步得到的所有最后一列的值与1进行比较,生成一个布尔数组(或类似布尔索引的结构),其中True表示对应位置的值为1,False表示不是1
-
data[data[:, -1] == 1]:最后,这个布尔数组被用作索引来筛选data数组。具体来说,它会选取data中所有最后一列值为1的行。
-
x = data[:,:-1]
# 逗号前后分别代表行和列,可以看出data[:,:-1]取从头到尾的行和从头到倒数第二个的列,且最后一个不取。
y = data[:,-1]
# 取从头到尾的行和最后一列。
- KNN模型——KNeighborsClassifier
- API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights=‘uniform’, algorithm=‘auto’, leaf_size=30, p=2, metric=‘minkowski’, metric_params=None, n_jobs=None)
- n_neighbors : k值,邻居的个数,默认为5。【关键参数】
- weights : 权重项,默认uniform方法。
Uniform:所有最近邻样本的权重都一样。【一般使用这一个】
Distance:权重和距离呈反比,距离越近的样本具有更高的权重。【确认样本分布情况,混乱使用这种形式】
Callable:用户自定义权重。 - algorithm :用于计算最近邻的算法。
ball_tree:球树实现
kd_tree:KD树实现, 是一种对n维空间中的实例点进行存储以便对其进行快速搜索的二叉树结构。
brute:暴力实现
auto:自动选择,权衡上述三种算法。【一般按自动即可】 - leaf_size :空值KD树或者球树的参数,停止建子树的叶子节点的阈值。
- p : 距离的计算方式。P=1为曼哈顿距离,p=2为欧式距离。
- metric : 用于树的距离度量
1.曼哈顿距离2.欧式距离3.切比雪夫距离4.闵可夫斯基距离5.带权重闵可夫斯基距离
6 .标准化欧式距离7.马氏距离 - metric_params :用于比较复杂的距离的度量附加参数。
neigh = KNeighborsClassifier(n_neighbors=10,p=2)
# k = 10,使用欧式距离公式计算。
- 训练模型
neigh.fit(x,y)
# 使用KNN模型中的fit方法进行训练。
- 测试模型
print(neigh.predict([[15004,0.08800,0.671355]]))
# neigh.predict():这是 neigh 模型的一个方法,用于对输入数据进行预测。
predict_data = [[9744,11.440364,0.760461],[16191,0.100000,0.605619],[42377,6.519522,1.058602],[27353,11.475155,1.528626]]
print(neigh.predict(predict_data))
# 测试多组数据时
- 测试结果
可以看到第一组数据分到2类别,第二组几个数据分别分到第2、2、1、3类别中。

完整代码——分类问题
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
data = np.loadtxt('datingTestSet2.txt')
x = data[:,:-1]
y = data[:,-1]
neigh = KNeighborsClassifier(n_neighbors=10,p=2)
neigh.fit(x,y) # 训练模型print(neigh.predict([[15004,0.08800,0.671355]]))predict_data = [[9744,11.440364,0.760461],[16191,0.100000,0.605619],[42377,6.519522,1.058602],[27353,11.475155,1.528626]]
print(neigh.predict(predict_data))
回归问题
- 使用数据
- 波士顿房价数据
- 导入模块
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
# 回归问题使用KNeighborsRegressor方法
- 导入数据
data = np.loadtxt('boston.txt')
# 使用numpy中的loadtxt方法读取txt文件,读取后内容为数组
- 提取数据
x = data[:,:-1]
# 逗号前后分别代表行和列,可以看出data[:,:-1]取从头到尾的行和从头到倒数第二个的列,且最后一个不取。
y = data[:,-1]
# 取从头到尾的行和最后一列。
- KNN模型——KNeighborsRegressor
- API
class sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, *, weights=‘uniform’, algorithm=‘auto’, leaf_size=30, p=2, metric=‘minkowski’, metric_params=None, n_jobs=None)
- n_neighbors : k值,邻居的个数,默认为5。【关键参数】
- weights : 权重项,默认uniform方法。
Uniform:所有最近邻样本的权重都一样。【一般使用这一个】
Distance:权重和距离呈反比,距离越近的样本具有更高的权重。【确认样本分布情况,混乱使用这种形式】
Callable:用户自定义权重。 - algorithm :用于计算最近邻的算法。
ball_tree:球树实现
kd_tree:KD树实现, 是一种对n维空间中的实例点进行存储以便对其进行快速搜索的二叉树结构。
brute:暴力实现
auto:自动选择,权衡上述三种算法。【一般按自动即可】 - leaf_size :空值KD树或者球树的参数,停止建子树的叶子节点的阈值。
- p : 距离的计算方式。P=1为曼哈顿距离,p=2为欧式距离。
- metric : 用于树的距离度量
1.曼哈顿距离2.欧式距离3.切比雪夫距离4.闵可夫斯基距离5.带权重闵可夫斯基距离
6 .标准化欧式距离7.马氏距离 - metric_params :用于比较复杂的距离的度量附加参数。
neigh = KNeighborsRegressor(n_neighbors=5,p=2)
# k = 5,使用欧式距离公式计算。
neigh2 = KNeighborsRegressor(n_neighbors=7,p=2)
# k = 7,使用欧式距离公式计算。
- 训练模型
neigh.fit(x,y)
# 使用KNN模型中的fit方法进行训练。
neigh2.fit(x,y)
- 测试模型
print(neigh.predict([[2.82838,0.00,18.120,0,0.5320,5.7620,40.32,4.0983,24,666.0,20.21,392.93,10.42]]))
print(neigh2.predict([[2.82838,0.00,18.120,0,0.5320,5.7620,40.32,4.0983,24,666.0,20.21,392.93,10.42]]))
- 测试结果
从结果可以看到根据不同的k值,会产生不同的回归值。

完整代码 ——回归问题
import numpy as np
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressordata = np.loadtxt('boston.txt')
x = data[:,:-1]
y = data[:,-1]
neigh = KNeighborsRegressor(n_neighbors=5,p=2)
neigh.fit(x,y)
print(neigh.predict([[2.82838,0.00,18.120,0,0.5320,5.7620,40.32,4.0983,24,666.0,20.21,392.93,10.42]]))
neigh2 = KNeighborsRegressor(n_neighbors=7,p=2)
neigh2.fit(x,y)
print(neigh2.predict([[2.82838,0.00,18.120,0,0.5320,5.7620,40.32,4.0983,24,666.0,20.21,392.93,10.42]]))
相关文章:
《机器学习》——KNN算法
文章目录 KNN算法简介KNN算法——sklearnsklearn是什么?sklearn 安装sklearn 用法 KNN算法 ——距离公式KNN算法——实例分类问题完整代码——分类问题 回归问题完整代码 ——回归问题 KNN算法简介 一、KNN介绍 全称是k-nearest neighbors,通过寻找k个距…...

GAMES101:现代计算机图形学入门-作业五
作业五 这次作业给了许多脚本,我们现在可以把每个脚本的代码逐行细细分析一下。 main.cpp #include "Scene.hpp" #include "Sphere.hpp" #include "Triangle.hpp" #include "Light.hpp" #include "Renderer.hpp&quo…...

GPU 进阶笔记(二):华为昇腾 910B GPU
大家读完觉得有意义记得关注和点赞!!! 1 术语 1.1 与 NVIDIA 术语对应关系1.2 缩写2 产品与机器 2.1 GPU 产品2.2 训练机器 底座 CPU功耗操作系统2.3 性能3 实探:鲲鹏底座 8*910B GPU 主机 3.1 CPU3.2 网卡和网络3.3 GPU 信息 3.3…...
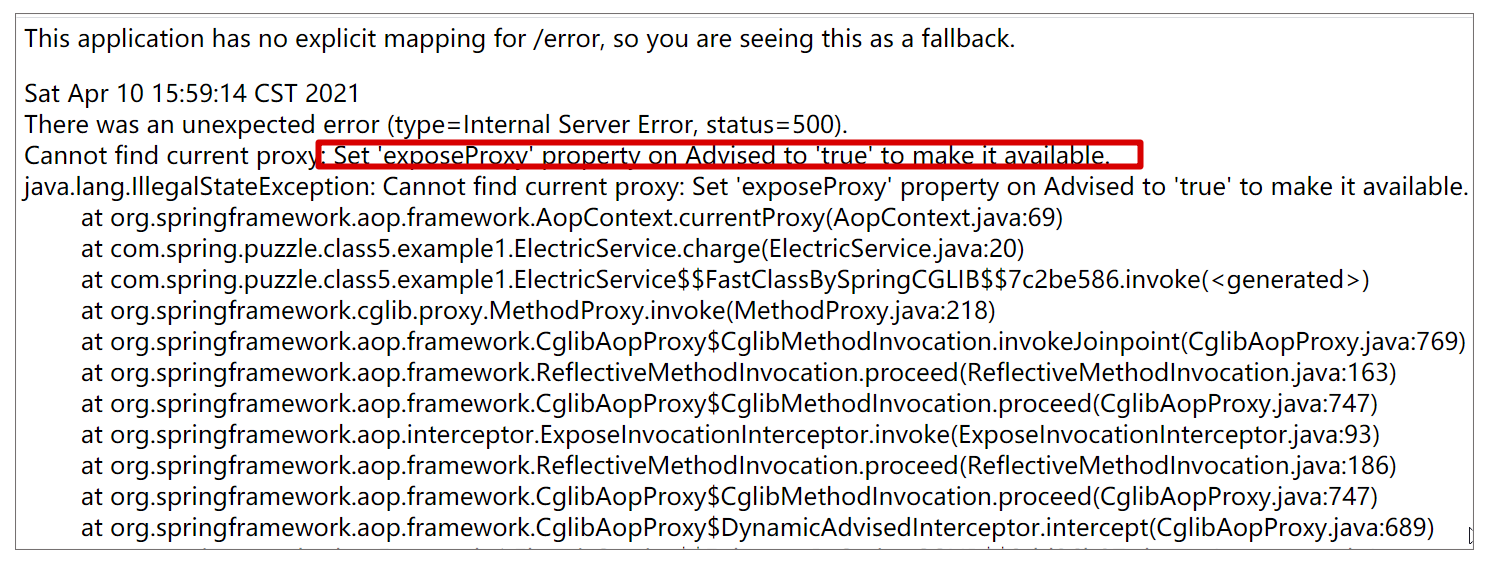
Spring AOP:this 调用当前类方法无法被拦截
问题复现 假设我们正在开发一个宿舍管理系统,这个模块包含一个负责电费充值的类 ElectricService,它含有一个充电方法 charge(): Service public class ElectricService {public void charge() throws Exception {System.out.println("E…...

K8S-LLM:用自然语言轻松操作 Kubernetes
在 Kubernetes (K8s) 的日常管理中,复杂的命令行操作常常让开发者感到头疼。无论是部署应用、管理资源还是调试问题,都需要记住大量的命令和参数。Kubernetes 作为容器编排的行业标准,其强大的功能伴随着陡峭的学习曲线和复杂的命令行操作。这…...

lua和C API库一些记录
相关头文件解释 lua.h:声明lua提供的基础函数,所有内容都有个前缀lua_; luaxlib.h:声明辅助库提供的函数,所有内容都有个前缀luaL_; lualib.h:声明了打开标准库的函数; 辅助库对…...

SpringSecurity中的过滤器链与自定义过滤器
关于 Spring Security 框架中的过滤器的使用方法,系列文章: 《SpringSecurity中的过滤器链与自定义过滤器》 《SpringSecurity使用过滤器实现图形验证码》 1、Spring Security 中的过滤器链 Spring Security 中的过滤器链(Filter Chain)是一个核心的概念,它定义了一系列过…...

Slate文档编辑器-Decorator装饰器渲染调度
Slate文档编辑器-Decorator装饰器渲染调度 在之前我们聊到了基于文档编辑器的数据结构设计,聊了聊基于slate实现的文档编辑器类型系统,那么当前我们来研究一下slate编辑器中的装饰器实现。装饰器在slate中是非常重要的实现,可以为我们方便地…...
本地Docker部署Flowise并实现远程构建LLM应用程序原型高效开发
文章目录 前言1. Docker安装Flowise2. Ubuntu安装Cpolar3. 配置Flowise公网地址4. 远程访问Flowise5. 固定Cpolar公网地址6. 固定地址访问 前言 相信很多对AI感兴趣的小伙伴都会觉得正在逐渐流行的工作流自动化和AI集成特别酷炫,没错,这些技术像“秘密武…...

多点通信、流式域套接字
一、广播 1.1广播的发送端模型: #include<myhead.h>#define BEN_IP "192.168.191.129" #define BEN_PORT 8888#define PORT 6666int main(int argc, const char *argv[]) {int oldfd socket(AF_INET,SOCK_DGRAM,0);if(oldfd -1){perror("soc…...

vue3使用video-player实现视频播放(可拖动视频窗口、调整大小)
1.安装video-player npm install video.js videojs-player/vue --save在main.js中配置全局引入 // 导入视频播放组件 import VueVideoPlayer from videojs-player/vue import video.js/dist/video-js.cssconst app createApp(App) // 视频播放组件 app.use(VueVideoPlayer)2…...

模块化和面向接口的设计:深入理解和应用
模块化和面向接口的设计:深入理解和应用 在面向对象编程中,模块化 和 面向接口设计 是两种非常重要的编程理念。它们能帮助开发人员构建更加清晰、可维护和易于扩展的系统。接下来,我们将详细解释这两种设计思想,并结合 Python 中…...

《SwiftUI 实现点击按钮播放 MP3 音频》
功能介绍 点击按钮时,应用会播放名为 yinpin.mp3 的音频文件。使用 AVAudioPlayer 来加载和播放音频。 关键点: 按钮触发:点击按钮会调用 playAudio() 播放音频。音频加载:通过 Bundle.main.url(forResource:) 加载音频文件。播…...

微机接口课设——基于Proteus和8086的打地鼠设计(8255、8253、8259)Proteus中Unknown 1-byte opcode / Unknown 2-byte opcode错误
原理图设计 汇编代码 ; I/O 端口地址定义 IOY0 EQU 0600H IOY1 EQU 0640H IOY2 EQU 0680HMY8255_A EQU IOY000H*2 ; 8255 A 口端口地址 MY8255_B EQU IOY001H*2 ; 8255 B 口端口地址 MY8255_C EQU IOY002H*2 ; 8255 C 口端口地址 MY8255_MODE EQU IOY003H*2 ; …...

MySQL如何执行.sql 文件:详细教学指南
在使用MySQL数据库过程中,我们经常需要执行包含SQL语句的.sql文件。这些文件通常用于数据库的备份和恢复或批量执行SQL脚本。本文将详细介绍如何在不同环境下执行MySQL的.sql文件。 前置准备 在开始之前,请确保以下条件已经满足: 已经安装…...

非周期性脑活动的动态重构支持癫痫患者的认知功能:一种神经指纹识别方法
摘要 颞叶癫痫(TLE)的特征是大脑活动模式发生大规模的变化,并且这种变化与患者的认知功能受损密切相关。本研究旨在使用神经指纹方法分析大脑活动的动态重构,以描绘TLE患者的个体特征及其认知功能相关性。本研究收集了68名TLE患者和34名对照组的10min静息…...

ZYNQ初识6(zynq_7010)clock时钟IP核
基于板子的PL端无时钟晶振,需要从PS端借用clock1(50M)晶振 接下去是自定义clock的IP核封装,为后续的simulation可以正常仿真波形,需要注意顶层文件的设置,需要将自定义的IP核对应的.v文件设置为顶层文件&a…...

使用MFC编写一个paddleclas预测软件
目录 写作目的 环境准备 下载编译环境 解压预编译库 准备训练文件 模型文件 图像文件 路径整理 准备预测代码 创建预测应用 新建mfc应用 拷贝文档 配置环境 界面布局 添加回cpp文件 修改函数 报错1解决 报错2未解决 修改infer代码 修改MFCPaddleClasDlg.cp…...
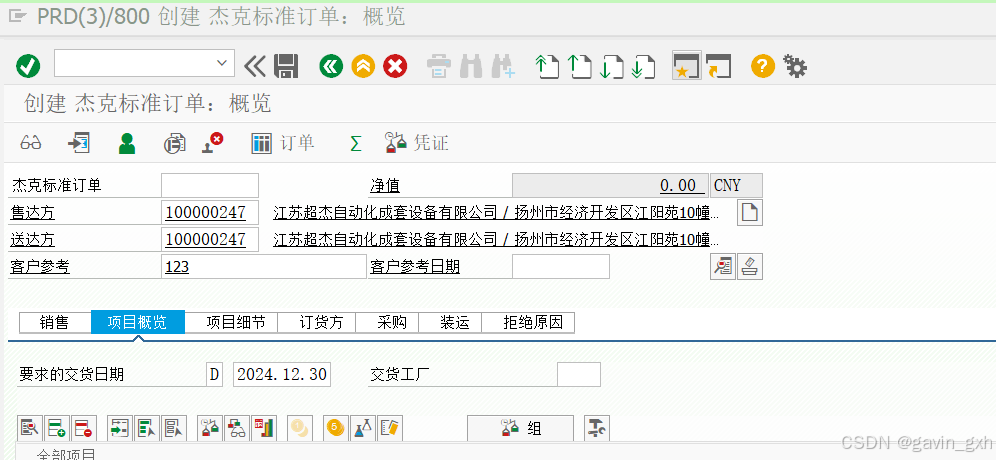
SAP SD BP名称和销售订单描述的对应不起来的问题
问题 VBPA-ADRNR地址 和 KNA1-ADRNR 指向同一个号码 销售订单读取这个地址 改正后恢复正常 原因:推测 应该是创建Y0 电商客户的时候,引起锁和混乱导致的。 具体实际时什么样,不太清楚 写于20241230 浙江台州...

FlastOcc-网络复现-1.环境配置及问题
研究OCC网络 1.RuntimeError: Ninja is required to load C extensions RuntimeError: Ninja is required to load C extensions #32 Ninja is required to load C extensions File “/FlashOCC/projects/mmdet3d_plugin/core/evaluation/ray_metrics.py”, line 12, in dvr …...

批量下载功能解决B站视频资源管理难题:从混乱到有序的高效工作流
批量下载功能解决B站视频资源管理难题:从混乱到有序的高效工作流 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水…...

JPG文件结构解析:从WinHex十六进制数据到实际图片属性的完整指南
JPG文件结构解析:从WinHex十六进制数据到实际图片属性的完整指南 当你用手机拍下一张照片,或是从网上下载一张图片时,这些JPG文件背后隐藏着怎样的数据结构?对于开发者、安全研究人员和逆向工程师来说,理解JPG文件的底…...

无障碍测试工具axe与WAVE使用心得:测试工程师的专业实践指南
在数字化产品日益渗透社会各领域的今天,软件的可访问性已从一个边缘议题演变为核心质量属性。作为一名软件测试从业者,我们的职责不仅是确保功能正确,更是要捍卫产品的包容性,让包括残障人士在内的所有用户都能平等地享受数字服务…...
进阶实战:从JSON Schema到企业级应用架构)
OpenAI结构化输出(Structured Outputs)进阶实战:从JSON Schema到企业级应用架构
1. 结构化输出的企业级价值与应用场景 在复杂的企业环境中,数据格式的标准化程度直接影响系统间的协作效率。想象一下财务部门需要从销售报告中提取关键指标,如果每个系统的输出格式都不一样,光是数据清洗就要耗费大量时间。这就是为什么Open…...
)
RFSOC XCZU47DR在5G射频基带开发中的实战应用(含代码示例)
RFSOC XCZU47DR在5G射频基带开发中的实战应用(含代码示例) 在5G通信系统的开发中,射频基带处理一直是工程师面临的核心挑战之一。Xilinx的RFSOC XCZU47DR凭借其独特的架构设计,将高性能RF数据转换器与可编程逻辑完美融合ÿ…...

90%嵌入式工程师必踩坑之volatile关键字,学会它轻松搞定面试官!!!
若想搞定什么是volatile关键字,首先要清楚CPU的变量读取规则:CPU 的运算单元(ALU)无法直接对内存中的变量做运算,内存里的变量(或外设寄存器中的变量)必须先加载到 CPU 内部的通用寄存器&#x…...

从理论到代码:深入理解OpenCV中NMSBoxes的双重过滤机制
从理论到代码:深入理解OpenCV中NMSBoxes的双重过滤机制 在目标检测任务中,非极大值抑制(NMS)是后处理环节的核心技术之一。OpenCV提供的cv2.dnn.NMSBoxes()函数通过双重阈值过滤机制实现了高效的目标框筛选,本文将深入…...

Matlab新手也能搞定的MFAC仿真:从侯忠生教授书上的例题4.1代码跑通说起
Matlab新手也能搞定的MFAC仿真:从侯忠生教授书上的例题4.1代码跑通说起 第一次接触无模型自适应控制(MFAC)时,很多人会被各种理论推导吓退。但作为工程师,我们更关心的是如何让代码跑起来,看到实际效果。本…...

mdp终极指南:如何将命令行Markdown演示完美转换为PDF
mdp终极指南:如何将命令行Markdown演示完美转换为PDF 【免费下载链接】mdp A command-line based markdown presentation tool. 项目地址: https://gitcode.com/gh_mirrors/md/mdp mdp是一款基于命令行的Markdown演示工具,让你可以直接在终端中展…...

PyTorch 3.0静态图≠TensorFlow旧时代:详解torch.compile + DTensor + P2P通信协同优化的4.2倍加速原理
第一章:PyTorch 3.0静态图分布式训练的范式跃迁PyTorch 3.0 引入了原生静态图编译能力(TorchDynamo Inductor 后端深度集成),配合 torch.distributed._composable API,首次实现了“声明式分布式策略”与“编译优化”的…...