2、Bert论文笔记
Bert论文
- 1、解决的问题
- 2、预训练微调
- 2.1预训练微调概念
- 2.2深度双向
- 2.3基于特征和微调(预训练下游策略)
- 3、模型架构
- 4、输入/输出
- 1.输入:
- 2.输出:
- 3.Learned Embeddings(学习嵌入)
- 1. **Token Embedding**
- 2. **Position Embedding**
- 3. **Segment Embedding**
- Embeddings 的结合
- 5、[CLS] 作用
- 6、下游任务(本文)
- 7、消融实验
- 8、符号说明
- 9、表格说明
- 10、代码
论文名称:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding链接
| 知识点 | 说明 |
|---|---|
| 1、输入/输出 | 分句(cls,sep)、输入的embeddings(学习嵌入) |
| 2、区分句子两种方式 | SEP、segment |
| 3、[CLS]作用 | 预训练NSP,微调下游任务分类 |
| 4、Mask比例 | 15%、时间(80%,10%,10%) |
| 5、模型结构对应的transform | L(N)、H(d)、A(H) |
| 6、下游任务 | MNLI(glue)、AQuAD(斯坦福)、NER(CONLL-2003) |
| 7、消融实验 | LM和NSP、模型大小、训练步数、MLM程度 |
1、解决的问题
解决的问题:预训练语言模型单向性限制
预训练语言表示的策略有基于特征和微调两种
“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”由谷歌的Jacob Devlin等人撰写,介绍了BERT(Bidirectional Encoder Representations from Transformers)这种预训练模型,其在多个自然语言处理任务上取得了最优成果,推动了相关领域发展。
- 研究背景
- 语言模型预训练:对改善自然语言处理任务有效,现有应用预训练语言表示的策略有基于特征和微调两种,但当前技术存在局限,预训练语言模型单向性限制了架构选择,影响了句子级和词元级任务表现。
- 相关工作
- 无监督基于特征的方法:如ELMo从左右语言模型提取上下文敏感特征,虽推进了NLP基准测试,但模型并非深度双向。
- 无监督微调方法:预训练句子或文档编码器并微调用于监督下游任务,BERT具有跨任务统一架构的特点。
- 有监督数据迁移学习:相关工作展示了从监督任务和大型预训练模型进行迁移学习的有效性。
- BERT模型
- 整体框架:包含预训练和微调两个步骤,预训练使用无监督任务在无标签数据上训练模型,微调则用预训练参数初始化并在下游任务有标签数据上微调所有参数。
- 输入输出表示:能处理单句和句对,使用WordPiece词元化,输入表示通过对词元、片段和位置嵌入求和构建,[CLS]对应最终隐藏状态用于分类任务,句对用[SEP]分隔并添加学习嵌入区分。
- 预训练任务
- 掩码语言模型(Masked LM):随机掩码输入词元的15%,通过预测掩码词元训练深度双向表示,训练数据生成时对选择预测的词元,80%用[MASK]替换,10%用随机词替换,10%保持不变。
- 下一句预测(NSP):用于训练理解句子关系的模型,50%的情况下B是A的实际下一句(IsNext),50%是随机句子(NotNext)。
- 微调:利用Transformer自注意力机制,通过替换输入输出适应多种下游任务,在不同任务中,输入输出有所不同。微调相对预训练计算成本低,在单Cloud TPU或GPU上可快速完成。
- 实验结果
- GLUE基准测试:在多个任务上显著超越之前系统,BERTBASE和BERTLARGE分别取得了较高平均准确率提升,在MNLI任务上提升明显,且BERTLARGE在数据较少任务上表现更优。
- SQuAD问答任务:在v1.1和v2.0数据集上均取得领先成绩,v1.1中通过简单扩展模型在测试集上F1分数大幅提升,v2.0通过特殊处理无答案情况也取得显著改进。
- SWAG常识推理任务:在该数据集上,BERTLARGE表现出色,优于基线系统和OpenAI GPT。
- 消融实验
- 预训练任务影响:去除NSP任务会损害部分任务性能,训练单向表示(LTR)在各任务上表现较差,添加BiLSTM虽能改善SQuAD任务结果,但仍不如预训练双向模型,且会损害GLUE任务性能。
- 模型大小影响:更大模型在微调任务准确率上有严格提升,即使在小数据集上也如此,这表明在充分预训练下,扩展模型大小对小任务也有益。
- 基于特征方法与BERT:将BERT应用于NER任务,比较微调与基于特征方法,发现BERT在两种方法中均有效,基于特征方法中,提取预训练模型特定层表示作为输入,微调方法则在预训练模型上添加分类层并联合微调所有参数。
- 研究结论:通过双向预训练和微调,BERT在多种NLP任务上取得成功,证明了丰富的无监督预训练对语言理解系统的重要性,使同一预训练模型能处理广泛任务。
2、预训练微调
2.1预训练微调概念
预训练(Pre - training)
在深度学习中,模型通常需要大量的数据来学习有效的特征表示。对于许多任务,获取大规模的标注数据是非常困难和昂贵的。预训练的目的是利用大规模的无标注数据来学习通用的特征表示,这些特征可以被迁移到各种具体的下游任务中。
例如,在自然语言处理中,文本数据量巨大,但是标注(如词性标注、命名实体识别等任务的标注)成本很高。可以使用大量的无标注文本(如维基百科文章、新闻文章等)来预训练模型。
微调(Fine - tuning)
虽然预训练模型学习到了通用的特征表示,但对于特定的任务(如情感分类、文本翻译等),还需要根据任务的特点和标注数据进行进一步的优化。微调就是在预训练模型的基础上,利用特定任务的标注数据来调整模型的参数,使其更好地适应任务。
预训练微调是一种分阶段的模型训练方法。它先在大规模的通用数据上进行无监督或自监督的预训练,学习数据中的一般性特征,然后在特定的任务相关数据上进行有监督的微调,使模型适应具体的任务需求。这种方法就像是先让一个人进行广泛的基础知识学习(预训练),然后针对具体的职业(任务)进行专业技能培训(微调)。



2.2深度双向
深度双向,与从左到右的语言模型预训练不同,MLM 目标使表示能够融合左右上下文,这使我们能够预训练深度双向 Transformer。除了掩码语言模型之外,我们还使用“下一句预测”任务来联合预训练文本对表示。我们证明了双向预训练对于语言表示的重要性。与雷德福等人不同。 (2018) 使用单向语言模型进行预训练,BERT 使用屏蔽语言模型来实现预训练的深度双向表示。这也与 Peters 等人形成鲜明对比。 (2018a),它使用独立训练的从左到右和从右到左 LM 的浅层串联。他们的模型是基于特征的,而不是深度双向的 。
我们认识到,也可以训练单独的 LTR 和 RTL 模型,并将每个令牌表示为两个模型的串联,就像 ELMo 所做的那样。然而:(a)这是单个双向模型的两倍昂贵;这严格来说不如深度双向模型强大,因为它可以在每一层使用左右上下文。(每一层双向)。

ELMo 及其前身(Peters et al., 2017, 2018a)沿着不同的维度概括了传统的词嵌入研究。他们从从左到右和从右到左的语言模型中提取上下文相关的特征。每个标记的上下文表示是从左到右和从右到左表示的串联。当将上下文词嵌入与现有的特定于任务的架构集成时,ELMo 推进了几个主要 NLP 基准的最新技术(Peters 等人,2018a),包括问答(Rajpurkar 等人,2016)、情感分析(Socher 等人) ., 2013),以及命名实体识别(Tjong Kim Sang 和 De Meulder, 2003)。梅拉穆德等人。 (2016) 提出通过使用 LSTM 从左右上下文预测单个单词的任务来学习上下文表示。与 ELMo 类似,他们的模型是基于特征的,而不是深度双向的。费杜斯等人。 (2018) 表明完形填空任务可用于提高文本生成模型的鲁棒性。
区别:
深度双向意味着 BERT 模型在处理文本时,能够同时利用词元前后的上下文信息。与传统的单向语言模型(如从左到右或从右到左的语言模型)不同,BERT 的双向性使得模型在预测每个词元时,可以综合考虑其左侧和右侧的所有词元信息。例如,在句子 “my dog is cute” 中,当模型处理 “dog” 这个词元时,它不仅能获取到 “my”(左侧)的信息,还能获取到 “is cute”(右侧)的信息,从而更全面地理解 “dog” 在句子中的语义角色。这种双向信息融合是通过 Transformer 架构中的多头自注意力机制(Multi - Head Self - Attention)实现的。多头自注意力机制允许模型在不同的 “头”(子空间)中同时关注输入序列的不同部分,然后将这些关注结果进行组合,从而有效地整合前后文信息。
浅层双向模型通常结构相对简单,层数较少(相较于深度双向模型如 BERT)。虽然也能在一定程度上利用前后文信息实现双向性,但由于层数限制,其对文本的理解和特征提取能力有限。例如,一些早期的双向 RNN 模型或简单的基于 Transformer 的浅层模型,它们在处理文本时,双向信息融合的深度不如深度双向模型。在计算词元表示时,虽然考虑前后文,但可能无法像深度双向模型那样深入捕捉长距离依赖关系和复杂语义结构。与一些浅层双向模型相比,BERT 的多层堆叠结构实现的深度双向表示能够学习到更复杂、更抽象的语言特征。浅层双向模型虽然也能够在一定程度上利用双向信息,但由于层数较少,其对文本的理解能力和特征提取能力相对有限。
基于特征的模型重点在于从文本中提取各种特征来表示文本信息。这些特征可以包括词汇特征(如词频、词性等)、句法特征(如句子结构、语法关系等)、语义特征(如语义角色、语义相似度等)等。通过对文本进行特征工程,将文本转化为特征向量,然后利用这些特征向量进行后续的任务处理,如分类、回归等。例如,在文本分类任务中,可以根据文本中某些关键词的出现频率等特征来判断文本的类别。然而,这种方式提取的特征相对较为浅层,可能无法像深度双向模型那样深入理解文本的语义和语法结构。例如,在文本分类任务中,可能会统计文本中特定关键词的出现次数作为词汇特征,或者分析句子的语法结构来获取句法特征。然后,将这些提取的特征组合成特征向量,用于后续的模型处理,如输入到分类器(如 SVM、逻辑回归等)中进行分类或预测任务。
2.3基于特征和微调(预训练下游策略)
预训练的语言表示应用于下游任务有两种现有策略:基于特征和微调。基于特征的方法,例如 ELMo(Peters 等人,2018a),使用特定于任务的架构,其中包括预训练的表示作为附加特征。微调方法,例如生成式预训练变压器(OpenAI GPT)(Radford et al., 2018),引入了最少的特定于任务的参数,并通过简单地微调所有预训练参数来对下游任务进行训练。这两种方法在预训练期间共享相同的目标函数,它们使用单向语言模型来学习通用语言表示。
本文的改进点:
单向的限制(本文):我们认为当前的技术限制了预训练表示的能力,特别是对于微调方法。主要限制是标准语言模型是单向的,这限制了预训练期间可以使用的架构的选择。
在本文中,我们通过提出 BERT:来自 Transformers 的双向编码器表示来改进基于微调的方法。 BERT 通过使用受完形填空任务(Taylor,1953)启发的“掩码语言模型”(MLM)预训练目标来缓解前面提到的单向性约束。
无监督的基于特征的方法
无监督微调方法
5.3 基于特征的 BERT 方法

预训练的语言表示(如BERT、GPT等)应用于下游任务时,确实有两种主要策略:基于特征(Feature-based)和微调(Fine-tuning)。这两种策略的具体区别如下:
-
基于特征的策略:
- 这种策略通常不会修改预训练模型的参数,而是利用预训练模型作为特征提取器。预练模型部分的参数是固定的,只需要对下游任务的简单模型进行训练,
- 具体来说,在下游任务中,我们将输入的文本通过预训练模型进行处理,得到隐藏层的输出(特征表示),然后将这些特征作为输入传递给下游任务的模型(如分类器、回归模型等)。
- 这种方法的优势在于它不需要对预训练模型进行微调,因此可以节省计算资源,适合小数据集或计算能力有限的场景。
- 但缺点是,这种方法可能无法充分利用下游任务的特定信息,因为预训练模型的参数没有被专门调整。
-
微调策略:
- 微调策略会在下游任务上进一步训练预训练模型,调整其参数以适应特定任务。
- 在微调过程中,预训练模型会在特定任务上进行优化,通常是通过反向传播算法(Gradient Descent)更新模型的权重。
- 微调策略的优势是能够充分利用预训练模型的知识,并且针对下游任务进行优化,通常能够获得更好的性能。
- 但是,微调需要更多的计算资源和数据,尤其是在数据量较少或计算能力有限时,可能存在过拟合的问题。
这两种策略的选择通常取决于下游任务的规模、计算资源和时间的要求。如果任务规模较小或计算资源有限,基于特征的策略可能是一个不错的选择;而在任务复杂、数据较多的情况下,微调往往能够取得更好的效果。
3、模型架构
对应关系总结:
| BERT 参数 | Transformer 对应部分 | 说明 |
|---|---|---|
| L L L 层数 | N N N 编码器层数 | 编码器块的数量。每层都有两个子层,第一个是多头自注意力机制,第二个是简单的、位置式全连接前馈网络。 |
| H H H 隐藏层维度 | d model d_{\text{model}} dmodel隐藏状态维度 | 编码器输入/输出的特征维度 |
| A A A 自注意力头数 | H H H多头注意力头数 | 自注意力中平行计算的头的数量 |
在神经网络(包括 Transformer)中,**隐藏层(Hidden Layer)**是指位于输入层和输出层之间的中间层。这些层的主要作用是对输入数据进行特征提取和非线性变换,为最终的任务(如分类、回归或序列生成)提供更加抽象的表示。






4、输入/输出
1.输入:

图图中:BERT 输入表示。输入嵌入是令牌嵌入、分割嵌入和位置嵌入的总和。
“学习嵌入”(Learned Embeddings):通常指的是通过训练算法自适应地学习到数据的低维表示。Learned(学习的)指这些嵌入向量不是手动设定的,而是在训练过程中由模型通过优化算法学习得到的。模型通过不断调整这些嵌入向量,使得它们能够更好地表示数据的结构和关系。
词元嵌入(Token Embeddings)
每个词元(token)都有一个对应的词元嵌入。
例如,[CLS] 对应的词元嵌入是 E [ C L S ] E_{[CLS]} E[CLS],my 对应的是 E m y E_{my} Emy,dog 对应的是 E d o g E_{dog} Edog,以此类推。
段嵌入(Segment Embeddings)
段嵌入用于区分不同的句子。
第一部分句子中的词元都被赋予段嵌入 E A E_A EA。
第二部分句子中的词元都被赋予段嵌入 E B E_B EB。
位置嵌入(Position Embeddings)
位置嵌入用于表示词元在句子中的位置。
从左到右,位置从 0 开始编号。
例如,[CLS] 对应的位置嵌入是 E 0 E_0 E0,my 对应的是 E 1 E_1 E1,dog 对应的是 E 2 E_2 E2,以此类推。
-
“句子”:“句子”可以是连续文本的任意范围,而不是实际的语言句子。 [CLS] 是一个特殊标记,用于分类任务,表示整个句子的起始。[SEP] 用于分隔不同的句子。
-
分句:[CLS] 是添加在每个输入示例前面的特殊符号,[SEP] 是特殊的分隔符标记(例如分隔问题/答案)。
-
MLM:“masked lan-guage model” (MLM) ,masked LM” (MLM),为了了训练深度双向表示,我们只需随机屏蔽一定比例的输入标记,然后预测这些屏蔽标记。 随机屏蔽每个序列中所有 WordPiece 标记的 15%。
-
[MASK] :预训练和微调之间造成了不匹配,因为 [MASK] 标记在微调期间不会出现。为了缓解这种情况,我们并不总是用实际的 [MASK] 标记替换“屏蔽”单词。训练数据生成器随机选择 15% 的 token 位置进行预测(mask比例)。如果选择第 i 个令牌,我们将第 i 个令牌替换为:
(1) 80% 的时间为 [MASK] 令牌
(2) 10% 的时间为随机令牌
(3) 未更改的第 i 个令牌10%的时间。 -
区分句子:我们以两种方式区分句子。首先,我们用一个特殊的标记([SEP])将它们分开。其次,我们向每个标记添加学习嵌入(segment embedding),指示它属于句子 A 还是句子 B。
-
下一句预测 (NSP):为了训练理解句子关系的模型,我们预先训练二值化的下一个句子预测任务,该任务可以从任何单语语料库轻松生成。具体来说,当为每个预训练示例选择句子 A 和 B 时,50% 的时间 B 是 A 之后的实际下一个句子(标记为 IsNext),50% 的时间它是来自语料库的随机句子(标记为 IsNext)。作为NotNext)。C 用于下一个句子预测(NSP)。(1、预训练,C用于NSP分类,理解句子关系。2、微调,C用于下游任务的分类,例如序列标记或问答,并且 [CLS] 表示被馈送到输出层以进行分类,例如蕴涵或情感分析。)
2.输出:
 在图中,E 表示输入嵌入, T i T_{i} Ti 表示词元 i i i 的上下文表示,[CLS] 是用于分类输出的特殊符号,[SEP] 是用于分隔不连续词元序列的特殊符号。将特殊 [CLS] 标记的最终隐藏向量表示为 C ∈ R,输入的Tok(token标记)的最终隐藏向量为 T ∈ R。
在图中,E 表示输入嵌入, T i T_{i} Ti 表示词元 i i i 的上下文表示,[CLS] 是用于分类输出的特殊符号,[SEP] 是用于分隔不连续词元序列的特殊符号。将特殊 [CLS] 标记的最终隐藏向量表示为 C ∈ R,输入的Tok(token标记)的最终隐藏向量为 T ∈ R。


3.Learned Embeddings(学习嵌入)
Bert输入:中的embedding都是学习嵌入,都不是固定。
图图中:BERT 输入表示。输入嵌入是令牌嵌入、分割嵌入和位置嵌入的总和。
“学习嵌入”(Learned Embeddings):通常指的是通过训练算法自适应地学习到数据的低维表示。Learned(学习的)指这些嵌入向量不是手动设定的,而是在训练过程中由模型通过优化算法学习得到的。模型通过不断调整这些嵌入向量,使得它们能够更好地表示数据的结构和关系。
1. Token Embedding
- 算法:
- 通过查找表(Embedding Lookup)方法实现。BERT 中的词嵌入使用的是一个固定大小的词汇表(Vocabulary),每个词或者子词(Token)对应一个固定长度的向量。这些向量是通过随机初始化后,在训练过程中学习得到的。
- 对于词分词后形成的子词单元,BERT 使用了 WordPiece Tokenization 方法来生成子词。
2. Position Embedding
- 算法:
- BERT 使用可学习的固定长度位置向量来表示序列中每个 Token 的位置。这与 Transformer 中的 Sinusoidal Position Embedding 不同。BERT 中的位置嵌入是可训练的,也是在训练过程中被学习的。
- 输入序列中每个位置会分配一个唯一的向量,向量维度与 Token 嵌入的维度相同。
- 位置编码有很多选择,学习和固定。transformer中作者通过对比,选择用正弦的固定的位置编码,位置向量不参与训练。
3. Segment Embedding
- 算法:
- BERT 使用 Segment Embedding 来区分输入序列中的不同段(Segment)。每个 Token 根据所属的段(例如句子 A 或句子 B)分配一个向量,这些向量也是通过可学习的方式获得的。
- 如果是单句任务,所有 Token 会被分配到同一个段。如果是双句任务(例如句子对分类),两个句子会被分别分配不同的段标志。
- Segement Embeddings 层有两种向量表示,前一个向量是把 0 赋值给第一个句子的各个 Token,后一个向量是把1赋值给各个 Token,问答系统等任务要预测下一句,因此输入是有关联的句子。而文本分类只有一个句子,那么 Segement embeddings 就全部是 0。
Embeddings 的结合
最终的输入嵌入(Input Embedding)是通过以下公式结合的:
Input Embedding = Token Embedding + Position Embedding + Segment Embedding \text{Input Embedding} = \text{Token Embedding} + \text{Position Embedding} + \text{Segment Embedding} Input Embedding=Token Embedding+Position Embedding+Segment Embedding
每个嵌入分量的维度是相同的,最终得到的输入向量会被送入 Transformer 模型进行编码。
词元嵌入(Token Embeddings)
每个词元(token)都有一个对应的词元嵌入。
例如,[CLS] 对应的词元嵌入是 E [ C L S ] E_{[CLS]} E[CLS],my 对应的是 E m y E_{my} Emy,dog 对应的是 E d o g E_{dog} Edog,以此类推。
段嵌入(Segment Embeddings)
段嵌入用于区分不同的句子。
第一部分句子中的词元都被赋予段嵌入 E A E_A EA。
第二部分句子中的词元都被赋予段嵌入 E B E_B EB。
位置嵌入(Position Embeddings)
位置嵌入用于表示词元在句子中的位置。
从左到右,位置从 0 开始编号。
例如,[CLS] 对应的位置嵌入是 E 0 E_0 E0,my 对应的是 E 1 E_1 E1,dog 对应的是 E 2 E_2 E2,以此类推。
5、[CLS] 作用
NSP(Next Sentence Prediction)任务和微调分类任务虽然都涉及到特殊符号 [CLS](在文中表示为 C),但它们在不同阶段发挥作用,不会相互覆盖,各自对模型的训练和性能提升有着重要意义。
NSP使用特殊符号 [CLS](c)对应的向量来进行下一句预测(NSP)。在预训练时,模型根据输入的句子对(A 和 B),通过对 [CLS] 向量进行处理,预测其属于 IsNext 还是 NotNext 类别。
在BERT模型中,NSP(Next Sentence Prediction)任务和微调分类任务虽然都涉及到特殊符号[CLS](在文中表示为C),但它们在不同阶段发挥作用,不会相互覆盖,各自对模型的训练和性能提升有着重要意义。
- NSP任务中的C
- 任务作用与表示:NSP任务是预训练中的一个重要部分,其目的是训练模型理解句子之间的关系。在这个任务中,C([CLS])对应的向量被专门用于预测句子B是否是句子A的下一句(IsNext或NotNext)。模型根据输入的句子对(A和B),通过对C向量进行处理来进行二分类预测。例如,在判断句子对“the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]”(IsNext)和“the man [MASK] to the store [SEP] penguin [MASK] are flightless birds [SEP]”(NotNext)时,C向量承载着整个句子对的综合信息,帮助模型学习句子之间的逻辑连贯性。
- 预训练阶段独立性:在预训练阶段,NSP任务独立进行训练,通过大量的句子对数据,使模型学会捕捉句子之间的语义和逻辑关系,从而为后续的微调阶段提供了更丰富的语言理解能力基础。这个过程中,C向量在NSP任务中的作用是特定且独立的,与微调分类任务尚未产生关联。
- 微调分类任务中的C
- 任务适应与C的角色:在微调阶段,BERT模型能够适应多种下游任务,包括单句分类(如情感分析)和句对分类(如自然语言推理)等任务。对于这些不同的任务,输入表示会根据任务需求进行调整,但C([CLS])始终扮演着重要角色。在单句分类任务中,如判断一个句子的情感倾向(积极、消极或中性),句子的输入表示为[CLS] E1 E2… EN,其中C([CLS])对应的最终隐藏状态被用作整个句子的聚合表示,输入到分类层进行分类。在句对分类任务中,如判断两个句子之间的关系(蕴含、矛盾或中立),句子对的输入表示为[CLS] E1 E2… EN [SEP] E1’ E2’… EN’,同样C([CLS])的最终隐藏状态作为句子对的整体表示输入分类层。
- 与NSP任务的区别与联系:微调分类任务与NSP任务虽然都使用了C向量,但它们的任务目标和数据处理方式不同。NSP任务专注于句子关系的预测,而微调分类任务则针对具体的下游任务需求(如情感分析、自然语言推理等)进行分类。然而,NSP任务在预训练阶段所学习到的句子关系理解能力,有助于微调分类任务更好地处理句对之间的关系,为微调分类任务提供了一定的基础支持,但两者在不同的训练阶段和任务场景下各司其职,不会相互覆盖。
6、下游任务(本文)
| 任务 | 数据集 |
|---|---|
| MNLI | 通用语言理解评估 (GLUE) |
| SQuAD | 斯坦福问答数据集 SQuAD |
| NER | CoNLL-2003 命名实体识别 |
| SWAG | (SWAG) 数据集 |
MNLI—glue
SQUAD—斯坦福
NER—命令实体识别 COMNLL2003


5.3 基于特征的 BERT 方法

7、消融实验
本文消融实验:
-
预训练任务的效果
表 5:使用 BERT 架构对预训练任务的消融。 “No NSP”是在没有下一句预测任务的情况下进行训练的。 “LTR & No NSP”被训练为从左到右的 LM,没有下一句预测,就像 OpenAI GPT 一样。 “+ BiLSTM”在微调过程中在“LTR + No NSP”模型之上添加了一个随机初始化的 BiLSTM。 -
模型大小的影响
我们探讨模型大小对微调任务准确性的影响。我们训练了许多具有不同层数、隐藏单元和注意力头的 BERT 模型,同时使用与前面描述的相同的超参数和训练过程。 -
C.1 训练步骤数的影响
-
C.2 不同掩蔽程序的消融
一、定义
消融实验(Ablation Study)是一种在机器学习、深度学习以及其他复杂系统研究中广泛使用的实验方法。它的主要目的是通过去除系统中的某些组件或者改变某些参数,来观察这些改变对系统整体性能的影响。简单来说,就像是在一个机器中逐个拆除零件,看看每个零件对机器正常运转所起到的作用。
二、作用和意义
- 理解模型组件的重要性
- 在复杂的深度学习模型中,有许多不同的层、模块或者超参数。通过消融实验,可以确定每个组件对模型最终性能(如准确率、召回率、F1值等)的贡献程度。例如,在一个图像分类的卷积神经网络(CNN)中,可能包括卷积层、池化层、全连接层等。通过分别去除这些层并观察模型性能的变化,可以了解每个层在特征提取和分类过程中的重要性。
- 验证设计选择的合理性
- 当研究人员提出一种新的模型结构或者对现有模型进行改进时,消融实验可以用来验证这些设计选择是否有效。比如,添加了一个新的注意力机制到自然语言处理模型中,通过消融实验去除这个注意力机制,对比前后性能,就能判断该机制是否真的提升了模型性能。
- 模型简化和优化
- 消融实验可以帮助发现模型中可能冗余的部分,从而对模型进行简化。简化后的模型在计算资源有限的情况下可能更有优势,如减少训练时间、降低内存占用等。同时,通过了解各个组件的重要性,还可以对重要组件进行重点优化。
三、实验步骤
- 确定基准模型
- 首先需要一个完整的、性能良好的模型作为基准。这个模型应该是经过充分训练并且在验证集或者测试集上有可靠的性能评估指标。例如,在目标检测任务中,一个已经训练好的Faster R - CNN模型,其在COCO数据集上有一定的平均精度(mAP)值。
- 选择消融对象
- 可以是模型的某一层、一个模块、一种数据增强方式或者一个超参数。以一个基于Transformer架构的语言模型为例,可以选择消融掉多头注意力机制中的一个头,或者去除某一种位置编码方式。
- 进行消融实验
- 按照选择的消融对象,对基准模型进行修改后重新训练。在训练过程中,要保证其他条件(如数据集、训练参数、优化算法等)尽可能与基准模型一致。比如,如果消融掉了模型中的一个卷积层,那么剩下的层的参数初始化、学习率等训练设置都应该和原来一样。
- 性能评估和对比
- 对消融后的模型在相同的测试集上进行性能评估,将评估结果与基准模型进行对比。可以使用各种评估指标,如在分类任务中使用准确率、在回归任务中使用均方误差(MSE)等。通过对比,可以直观地看到消融对象对模型性能的影响。例如,消融掉某一层后,模型的准确率下降了5%,这就表明该层对模型性能有一定的贡献。
四、应用案例
- 计算机视觉领域
- 在图像分割任务中,假设一个全卷积网络(FCN)模型在医学图像分割上取得了不错的效果。为了研究跳跃连接(Skip - connection)的作用,进行消融实验。在基准模型中有跳跃连接,它可以将浅层的特征信息直接传递到深层,帮助更好地恢复图像细节。当消融掉跳跃连接后,重新训练模型并在医学图像测试集上评估。发现模型的分割精度从原来的85%下降到了70%,这表明跳跃连接在这个图像分割模型中对于提高分割精度起到了关键作用。
- 自然语言处理领域
- 对于一个情感分析的循环神经网络(RNN)模型,研究词向量预训练的影响。基准模型使用了预训练的词向量(如Word2Vec)来初始化模型中的词嵌入层。在消融实验中,不使用预训练词向量,而是随机初始化词嵌入层。经过训练和测试后,发现模型的准确率从80%下降到了60%,这说明预训练词向量对于该情感分析模型的性能提升有很大的帮助。
8、符号说明
LM:(Language Model,语言模型)
MLM:“masked lan-guage model” (MLM) ,masked LM” (MLM)
LTR:(Left-to-Right,从左到右)
RTL:right-to-left(从右到左)
dev:开发集(Development Set),也称为验证集(Validation Set)
test:测试集
9、表格说明
表一:
glue多个数据集上分别测试的得分,F1,相关性,精确度
F1 scores are reported for QQP and MRPC,
Spearman correlations are reported for STS-B, and
accuracy scores are reported for the other tasks

表格二到四:
DEV验证集和Test测试集上指标
F1指标和EM(Exact Match)

表五–七:
F1和accuracy指标

表八:
不同消融实验下的精确度accuracy

SQuAD 中dev和test
dev(开发集)
开发集主要用于模型的开发和调整过程。在训练问答模型时,开发集可以帮助研究人员和开发者选择合适的模型架构、超参数(如学习率、隐藏层大小等)。例如,通过在开发集上比较不同超参数设置下模型的性能(如准确率、F1 值等指标),来确定最优的超参数组合。
test(测试集)
测试集用于对最终训练好的模型进行性能评估。它提供了一个独立于训练集和开发集的评估环境,能够较为客观地反映模型在未见过的数据上的性能。在学术研究和实际应用中,模型在测试集上的性能指标是衡量模型好坏的重要标准。例如,在比较不同的问答模型时,主要看它们在相同测试集上的准确率、召回率等指标的高低。
开发集(Development Set):也称为验证集(Validation Set),主要用于在模型训练过程中调整超参数、选择模型架构以及进行模型的早期停止(Early Stopping)等操作。它是介于训练集和测试集之间的数据集,用于评估模型在训练过程中的性能表现,防止模型在训练集上过拟合。
验证集(Validation Set):从功能上来说和开发集是一样的概念,在很多场景下这两个术语可以互换使用。不过严格来说,“验证” 更强调对模型当前状态的评估,以验证模型是否朝着正确的方向训练。
与训练集和测试集的区别
训练集(Training Set)
训练集是用于训练模型的数据集,模型通过学习训练集中的样本特征和标签之间的关系来调整自身的参数。例如,在一个图像分类任务中,训练集包含了大量带有正确类别标签的图像,模型通过这些图像学习如何区分不同的类别。训练集的数据量通常是最大的,目的是让模型充分学习到数据中的模式。
开发 / 验证集和测试集
开发 / 验证集和测试集都不参与模型的训练过程。测试集主要用于在模型训练完成后,对模型的最终性能进行评估,以模拟模型在实际应用中的表现。而开发 / 验证集是在模型训练过程中,用于监控模型的性能,对模型进行优化调整。例如,在训练一个神经网络语言模型时,每经过一个训练周期(Epoch),就可以在开发 / 验证集上评估模型的损失(Loss)或准确率等指标,根据这些指标来调整学习率、决定是否增加或减少网络的层数等。
10、代码
Official Code
https://github.com/google-research/bert
Community Code
530 code implementations (in PyTorch, TensorFlow, JAX and MXNet)
相关文章:
2、Bert论文笔记
Bert论文 1、解决的问题2、预训练微调2.1预训练微调概念2.2深度双向2.3基于特征和微调(预训练下游策略) 3、模型架构4、输入/输出1.输入:2.输出:3.Learned Embeddings(学习嵌入)1. **Token Embedding**2. **Position Embedding**3…...

Linux之ARM(MX6U)裸机篇----7.蜂鸣器实验
一,蜂鸣器模块 封装步骤: ①初始化SNVS_TAMPER这IO复用为GPIO ②设置SNVS_TAMPPER这个IO的电气属性 ③初始化GPIO ④控制GPIO输出高低电平 bsp_beep.c: #include "bsp_beep.h" #include "cc.h"/* BEEP初始化 */ void beep_init…...

Zabbix 监控平台 添加监控目标主机
Zabbix监控平台是一个企业级开源解决方案,用于分布式系统监视和网络监视。它由Zabbix Server和可选组件Zabbix Agent组成,通过C/S模式(客户端-服务器模型)采集数据,并通过B/S模式(浏览器-服务器模型&#x…...

SpringCloud整合skywalking实现链路追踪和日志采集
1.部署skywalking https://blog.csdn.net/qq_40942490/article/details/144701194 2.添加依赖 <!-- 日志采集 --><dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-logback-1.x</artifactId><version&g…...

html文件通过script标签引入外部js文件,但没正确加载的原因
移动端H5应用,html文件通过script标签引入外部js文件,但没正确加载,在移动设备上难以排查。通过PC浏览器打开,发现js被阻止了:blocked:mixed-content。 原因在于: “blocked:mixed - content” 是浏览器的…...

OpenHarmony开发板环境搭建
程序员Feri一名12年的程序员,做过开发带过团队创过业,擅长Java相关开发、鸿蒙开发、人工智能等,专注于程序员搞钱那点儿事,希望在搞钱的路上有你相伴!君志所向,一往无前! 0.OpenHarmony 0.1 OpenHarmony OpenHarmony是一款面向全场景、全连接、全智能的…...

【Rust自学】7.6. 将模块拆分为不同文件
喜欢的话别忘了点赞、收藏加关注哦(加关注即可阅读全文),对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 7.6.1. 将模块的内容移动到其他文件 如果在模块定义时模块名后边跟的是;而不是代码块&#…...

Python入门:8.Python中的函数
引言 在编写程序时,函数是一种强大的工具。它们可以将代码逻辑模块化,减少重复代码的编写,并提高程序的可读性和可维护性。无论是初学者还是资深开发者,深入理解函数的使用和设计都是编写高质量代码的基础。本文将从基础概念开始…...

MySQL什么情况下会加间隙锁?
目录 一、使用范围条件查询 二、唯一索引的范围查询 三、普通索引的查询 四、间隙锁的锁定规则 五、间隙锁的影响 间隙锁(Gap Lock)是MySQL中的一种锁机制,主要用于防止幻读现象。在MySQL的InnoDB存储引擎中,当事务隔离级别设置为可重复读(Repeatable Read)时,间隙…...

【服务器开发及部署】code-server 显示git graph
在开发一些linux上的内容的时候进程需要在开发机和生产部署上花费大量的时间。 为了解决上述问题,我们今天介绍一款在服务上开发的思路 git + code server + 宝塔 其中需要处理一些问题,此处都有交代 步骤 安装宝塔安装code-server配置插件配置浏览器处理的问题 git版本过低,…...

Linux 终端查看 nvidia 显卡型号
文章目录 写在前面1. 需求描述2. 实现方法方法一:方法二方法三: 参考链接 写在前面 自己的测试环境: Ubuntu20.04 1. 需求描述 Linux 终端查看 nvidia 显卡型号 2. 实现方法 方法一: 执行下列指令: sudo update…...

助你通过AI培训师中级考试的目录索引
嘿,各位看官!在您正式踏入接下来的知识小宇宙之前,咱先唠唠几句… 家人们,我跟你们说,我脑一热报名了那个 AI 培训师考试。本想着开启一场知识的奇幻之旅,结果呢,学视频内容的时候,那…...

百度PaddleSpeech识别大音频文件报错
一、背景 公司前同事留下了一套语音识别项目,内部使用百度PaddleSpeech。在项目验收的时候发现无法识别大音频文件,但是可以识别小音频文件。 这套项目是通过python调用的百度PaddleSpeech,然后提供了restful接口,然后java项目可…...

Lucene 漏洞历险记:修复损坏的索引异常
作者:来自 Elastic Benjamin Trent 有时,一行代码需要几天的时间才能写完。在这里,我们可以看到工程师在多日内调试代码以修复潜在的 Apache Lucene 索引损坏的痛苦。 做好准备 这篇博客与往常不同。它不是对新功能或教程的解释。这是关于花…...
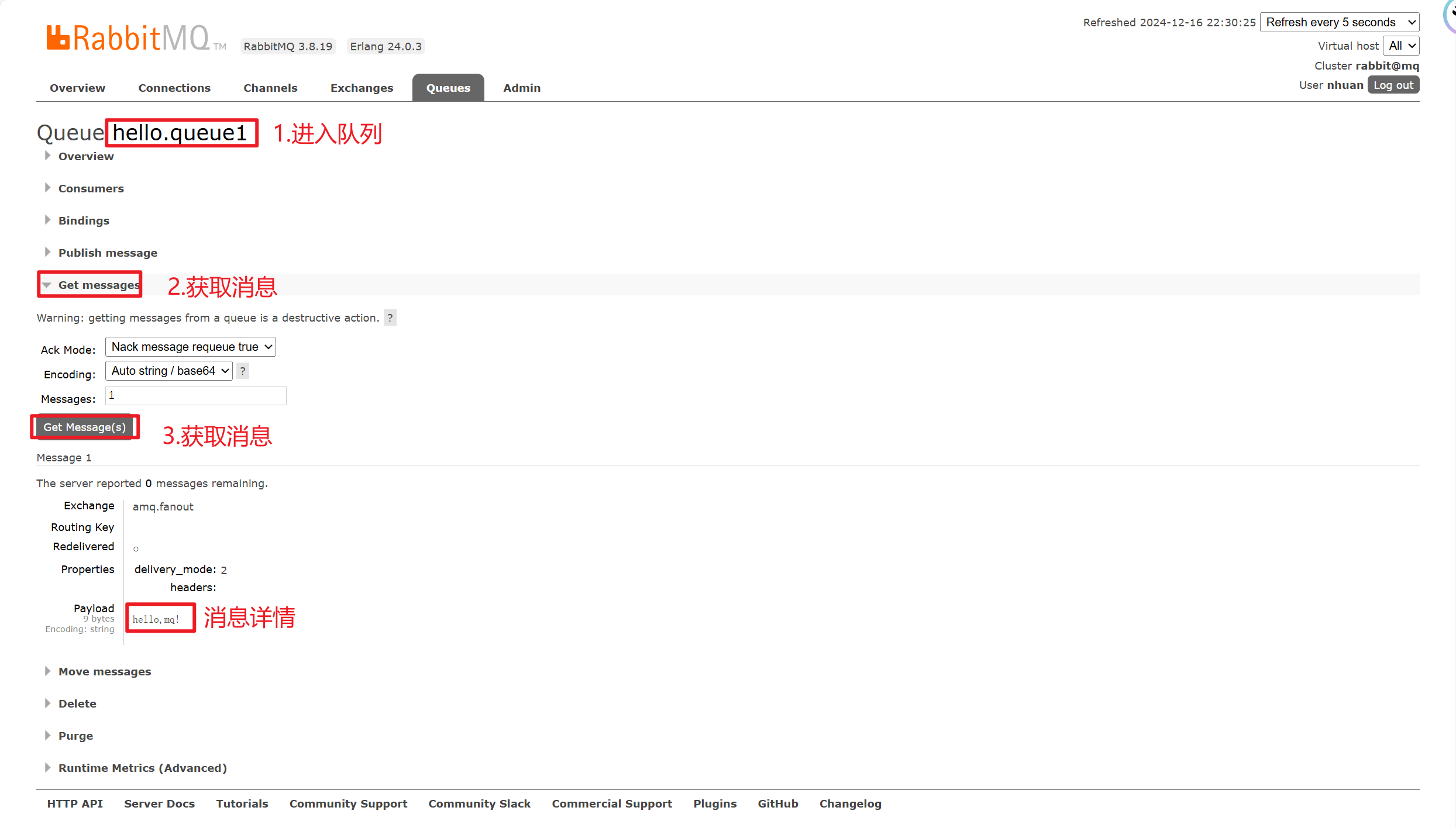
RabbitMQ基础篇之快速入门
文章目录 一、目标需求二、RabbitMQ 控制台操作步骤1.创建队列2.交换机概述3.向交换机发送消息4.结果分析5.消息丢失原因 三、绑定交换机与队列四、测试消息发送五、消息查看六、结论 一、目标需求 新建队列:创建 hello.queue1 和 hello.queue2 两个队列。消息发送…...

如何自定义 Kubernetes KubeSphere 默认 Logo:详细实现方案
要将 Pod 中的路径 /opt/kubesphere/console/dist/assets/logo.svg 替换为外部的某个图片,可以通过以下几种方法处理。推荐使用 挂载 ConfigMap 或 Secret 的方式,因为它是 Kubernetes 原生的、可持续的解决方案。 方法 :使用 ConfigMap 挂载…...

标准库以及HAL库——按键控制LED灯代码
按键控制LED本质还是控制GPIO,和点亮一个LED灯没什么区别 点亮一个LED灯:是直接控制输出引脚,GPIO初始化推挽输出即可 按键控制LED:是按键输入信号从而控制输出引脚,GPIO初始化推挽输出一个引脚以外还得加一个GPIO上拉输入 但是…...

Echarts+vue电商平台数据可视化——webSocket改造项目
websocket的基本使用,用于测试前端能否正常获取到后台数据 后台代码编写: const path require("path"); const fileUtils require("../utils/file_utils"); const WebSocket require("ws"); // 创建WebSocket服务端的…...

Flink中并行度和slot的关系——任务和任务槽
一、任务槽(task slots) Flink的每一个TaskManager是一个JVM进程,在其上可以运行多个线程(任务task),那么每个线程可以拥有多少进程资源呢?任务槽就是这样一个概念,对taskManager上每个任务运行…...

基于西湖大学强化学习课程的笔记
放在前面 课程链接 2024年12月30日 前言:强化学习有原理部分的学习,也有与实践相关的编程部分。我认为实践部分应该是更适合我的,不过原理部分也很重要,我目前是准备先过一过原理。 应该花多少时间学习这部分呢? 但是这…...

Campus-iMaoTai自动化预约系统:技术架构与实践指南
Campus-iMaoTai自动化预约系统:技术架构与实践指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://git…...

终极指南:用OpenCore Configurator轻松搞定黑苹果引导设置
终极指南:用OpenCore Configurator轻松搞定黑苹果引导设置 【免费下载链接】OpenCore-Configurator A configurator for the OpenCore Bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Configurator 还在为复杂的黑苹果引导配置而头疼吗&a…...

深蓝词库转换器:3分钟掌握30+输入法词库互转的终极指南
深蓝词库转换器:3分钟掌握30输入法词库互转的终极指南 【免费下载链接】imewlconverter ”深蓝词库转换“ 一款开源免费的输入法词库转换程序 项目地址: https://gitcode.com/gh_mirrors/im/imewlconverter 你是否曾因更换输入法而丢失多年积累的个人词库&am…...

Intv_AI_MK11助力后端开发:构建基于大模型的智能API服务
Intv_AI_MK11助力后端开发:构建基于大模型的智能API服务 1. 智能API服务的时代机遇 最近跟几个做后端开发的朋友聊天,发现大家都在讨论同一个问题:如何把大模型能力快速集成到现有系统中。传统做法要么调用第三方API(贵且慢&…...

如何为Retoolkit贡献新工具:开发者完整指南与最佳实践
如何为Retoolkit贡献新工具:开发者完整指南与最佳实践 【免费下载链接】retoolkit Reverse Engineers Toolkit 项目地址: https://gitcode.com/gh_mirrors/re/retoolkit Retoolkit是一个功能强大的逆向工程工具包,为安全研究人员和逆向工程师提供…...
)
用STM32F103C8T6+ESP8266做个公交车报站器,附完整电路图和代码(避坑OLED与GPS)
用STM32F103C8T6ESP8266打造高可靠性公交车报站器:从硬件选型到代码调试全指南 在智能交通系统快速发展的今天,公交车报站器作为乘客信息服务的重要载体,其稳定性和准确性直接影响出行体验。本文将带你从零开始,基于STM32F103C8T6…...

从‘拉风箱’到‘指哪打哪’:VCM音圈马达如何重塑了我们的手机拍照体验?
从‘拉风箱’到‘指哪打哪’:VCM音圈马达如何重塑了我们的手机拍照体验? 还记得十年前用手机拍运动场景的崩溃体验吗?按下快门后镜头反复伸缩发出"咔咔"声,像老式风箱般迟钝,等对焦完成时孩子早已跑出画面。…...

VSCode + WSL2开发环境搭建:Windows10下的高效Linux开发体验
VSCode WSL2开发环境搭建:Windows10下的高效Linux开发体验 在Windows系统上进行Linux开发一直是件令人头疼的事情——双系统切换麻烦,虚拟机性能堪忧,远程服务器又受限于网络环境。直到微软推出WSL2(Windows Subsystem for Linux…...

安装The Agency后Opencode启动报错:Failed to parse YAML frontmatter: incomplete explicit mapping pair
报错:opencode Failed to parse frontmatter in /home/skywalk/opencodework/.opencode/agent/zk-steward.md: Failed to parse YAML frontmatter: incomplete explicit mapping pair; a key node is missed; or followed by a non-tabulated empty line at line 3,…...

人类与AI的劳资谈判:首个数字员工工会诞生实录
代码中的裂隙2026年春季,硅谷某家头部科技公司的软件测试部门,弥漫着一种不同于代码错误的焦虑。曾经繁忙的测试大厅,如今只剩下零星几个工程师,他们的屏幕旁,是日夜不停歇运行的AI测试智能体日志流。公司内部系统显示…...