后端开发-Maven
环境说明:
windows系统:11版本
idea版本:2023.3.2
Maven
介绍
Apache Maven 是一个 Java 项目的构建管理和理解工具。Maven 使用一个项目对象模型(POM),通过一组构建规则和约定来管理项目的构建,报告和文档。Maven 可以处理 Java 项目从构建、文档化到部署的整个生命周期。
特点
依赖管理:Maven 能够自动下载项目所需的库,并且处理这些库之间的依赖关系。它还能够解析版本冲突并选择合适的版本。
项目构建:自动画项目构建方式
统一的项目结构:提供标准统一的项目结构
Jar包
介绍
JAR(Java ARchive)是一种压缩文件格式,主要用于打包 Java 类和相关的元数据和资源(如图像、属性文件等)。JAR 文件格式本质上类似于 ZIP 格式,但它提供了额外的功能,比如对类路径的支持和数字签名能力。
用途
打包类和资源:
JAR 文件可以包含多个 .class 文件(编译后的 Java 字节码),以及相关的资源文件。这样可以将一个或多个相关的类文件打包成单个文件,便于管理和分发。
类路径管理:
JAR 文件可以被添加到 Java 应用程序的类路径中。这意味着当应用程序运行时,Java 虚拟机(JVM)会搜索类路径中的 JAR 文件来查找需要加载的类。
自包含应用程序:
通过使用 jar 工具的 mf 参数指定清单文件(Manifest file),可以在 JAR 文件中包含必要的元数据,使 JAR 文件成为自包含的应用程序。清单文件可以指定主类(Main-Class),这是应用程序的入口点。
签名:
JAR 文件可以被数字签名,这允许用户验证 JAR 文件的来源和完整性,确保没有被篡改过。
创建jar文件
- 编译 Java 源代码生成 .class 文件。
- 使用 jar 工具或者 IDE 中的功能来创建 JAR 文件。
- 如果需要的话,可以使用 jar 工具的 -C 参数来指定目录,将目录下的所有文件打包进 JAR 文件。
- 添加清单文件以指定主类或者其他元数据。
- 对于需要签名的 JAR 文件,还需要使用 Java 的 jarsigner 工具来进行签名。
仓库:
用于存储资源,管理各种jar包。
- 本地仓库:自己计算机上的一个目录
- 中央仓库:由Maven团队维护的全球唯一的
(仓库地址:Central Repository:)
- 远程仓库(私服):一般由公司团队搭建的私有仓库
安装Maven
(IDEA集成了Maven,如果使用IDEA作为开发工具,这一步可以省略)
1.官网下载安装包:
Maven – Welcome to Apache Maven![]() https://maven.apache.org/
https://maven.apache.org/

2. 配置本地仓库:
找到conf文件夹下的settings.xml中的<localRepository>标签,修改本地仓库路径


<localRepository>
D:\Users\maven\apache-maven-3.6.1-bin\apache-maven-3.6.1\maven_repository
</localRepository>3.配置阿里云私服:
修改conf文件夹下的settings.xml中的<mirrors>标签,为其添加如下子标签
仓库服务![]() https://developer.aliyun.com/mvn/guide
https://developer.aliyun.com/mvn/guide
<mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云公共仓库</name><url>https://maven.aliyun.com/repository/public</url>
</mirror>Maven环境配置
1.MAVEN_HOME变量
在设置中打开编辑系统环境变量


打开环境变量

在系统变量下,新建一个变量,变量名位MAVEN_HOME,变量值为maven的解压目录
2.加入path
在用户变量下新建%MAVEN_HOME%\bin

3.检查环境
查看maven环境是否配置成功

输入:
mvn -v 
若能输出版本号,则说明配置成功
IDEA
创建maven项目


Maven坐标
介绍
在 Maven 中,"坐标"(Coordinates)是指定一个项目的唯一标识符集合。Maven 使用这些坐标来唯一确定一个库或项目的位置,这对于依赖管理和构建过程非常重要。
组成
| 组成 | 说明 |
|---|---|
| groupId | 表示项目的组织名或公司名。通常使用反向域名的形式来避免命名冲突,例如 com.example。 |
| artifactId | 表示项目中的具体模块或者组件的名字。例如,在一个名为 myproject 的 groupId 下,可能有 core, ui, service 等不同的 artifactId。 |
| version | 表示项目的版本号。版本号遵循一定的规则,如 1.0.0 或者 2.3.1-SNAPSHOT。SNAPSHOT 版本是指尚未发布的版本,常用于开发中的版本 |
| packaging | 表示项目的主要打包类型,默认是 jar。其他常见的打包类型包括 war(Web 应用程序)、ear(企业应用程序)、pom(项目描述符文件)等。 |
| classifier | 这是一个可选的部分,用于区分具有相同 groupId、artifactId 和 version 的不同打包类型。例如,如果你有两个 JAR 文件,一个是普通的 JAR 文件,另一个是包含源代码的 JAR 文件,你可以分别为它们指定 null 和 sources 作为 classifier。 |
eg:
<groupId>com.example</groupId>
<artifactId>myproject</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<classifier>sources</classifier>使用坐标
当你在 pom.xml 文件中声明依赖时,你需要提供完整的坐标来指定你要使用的库
<dependencies><dependency><groupId>com.example</groupId><artifactId>myproject</artifactId><version>1.0.0</version></dependency>
</dependencies>依赖配置
介绍
指当前项目运行所需要的jar包,一个项目可以引入多个依赖
pom.xml中依赖配置查询网址:
https://mvnrepository.com/

配置
1. 在pom.xml中编写<dependencies>标签
2.在<dependencies>标签中使用<dependency>引入坐标
3.定义坐标的groupId,artifactId,version
<!-- 导入当前项目所需的所有依赖资源 --><dependencies><dependency><!-- 组织名 --><groupId>ch.qos.logback</groupId><!-- 模块名 --><artifactId>logback-classic</artifactId><!-- 版本号 --><version>1.2.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version><scope>test</scope></dependency></dependencies>依赖特点
依赖传递
1.依赖具有传递性:
直接依赖:在当前项目中通过依赖配置建立的依赖关系
间接依赖:被依赖的资源如果依赖其它资源,当前项目也和其它资源具有依赖关系
2.排除传递
排除依赖指主动断开依赖资源,被排除的资源无需指定版本
依赖范围
在Maven中,依赖范围是在pom.xml文件中通过<scope>元素定义的
1.Compile(编译)
这些依赖项是项目编译期间必需的,也是最常见的依赖范围。它们会被包含在编译类路径中,因此在编译源代码时会被使用到。
2.Provided(已提供)
类似于编译范围,但在运行时假设该依赖项会被容器或框架提供,因此不会打包到最终的应用程序中。例如,在Java Web应用中,Servlet API通常会被Web容器提供。
3.Runtime(运行时)
这些依赖项在编译期间不需要,但在运行应用程序时是必要的。例如,JDBC驱动通常只在运行时需要。
4.Test(测试)
测试范围的依赖项仅用于构建和运行测试代码,不会被包含在生产环境中。JUnit或Mockito这样的测试框架就属于此类。
生命周期

1. Clean 生命周期
Clean 生命周期主要用于清理项目,删除之前构建时生成的所有文件。这对于重新开始构建非常有用,以确保没有旧的输出影响新的构建。它包括以下几个阶段:
- pre-clean: 执行任何必要的特殊清理前任务。
- clean: 清除先前构建的所有输出。
- post-clean: 清理之后的任务。
2. Default 生命周期
这是最常用的生命周期,涵盖了项目的构建过程,从源码编译到最后的部署。Default 生命周期包括但不限于:
- validate: 验证项目是否正确,所有需要的资源都存在,并且系统处于稳定状态。
- compile: 编译源代码。
- test: 使用适当的单元测试/集成测试框架来测试编译后的代码。这些测试不允许失败。
- package: 将编译好的代码打包成可分发的形式,如 JAR、WAR、EAR 文件等。
- integration-test: 处理集成测试(如果必要的话)。
- verify: 运行任何检查以验证包是否有效且符合质量要求。
- install: 将包安装到本地存储库,以供其他项目作为依赖来使用。
- deploy: 将最终的包复制到远程存储库,以与其他团队成员共享此包。
3. Site 生命周期
Site 生命周期用于生成项目文档,这些文档通常被称为站点。站点提供了关于项目的重要信息,比如报告和其他文档。
- pre-site: 在生成站点之前做准备工作。
- site: 生成项目站点文档。
- post-site: 在站点生成之后的操作。
- site-deploy: 将生成的站点文档部署到服务器上。
SpringBoot

创建项目:
1.在idea中用spring initializer的方式创建一个项目
2.会自动生成启动类Application
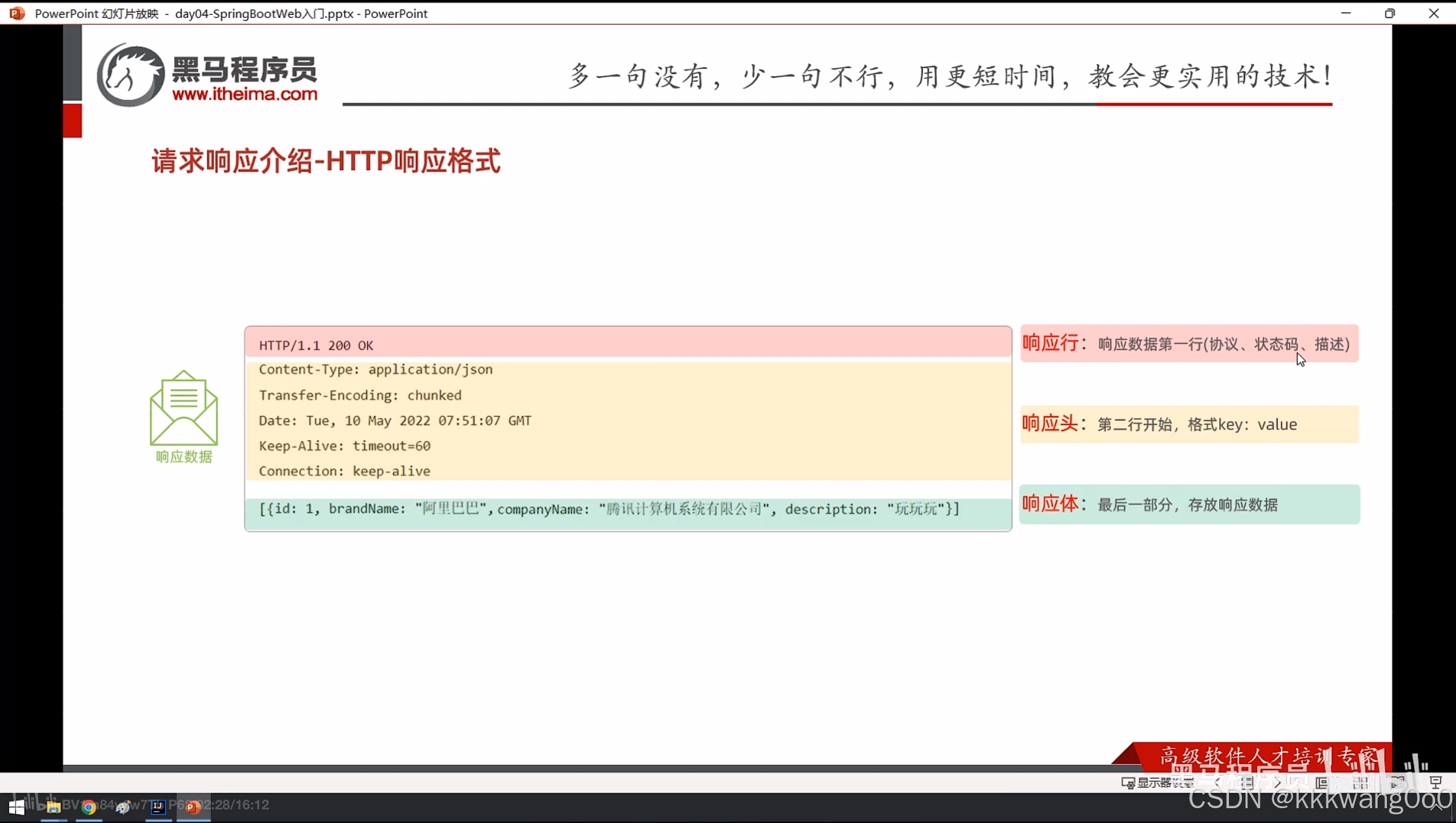
Http协议:
定义:
超文本传输协议,规定了浏览器和服务器之间数据传输的规则

Request Headers : 请求的数据
Response Headers: 响应的数据
请求行:
 GET: 请求方式
GET: 请求方式
/hello: 请求资源路径
HTTP/1.1: 请求协议/版本
请求数据方式:


响应数据方式:
// 请求读取HTTP请求boolean requestOk = false;String first = reader.readLine(); // 读取请求行if (first.startsWith("GET / HTTP/1.")){requestOk = true; // 请求成功}// 从第二行开始读取请求头的信息for (;;) {String header = reader.readLine();if (header.isEmpty()) { // 空行,请求结束break;}System.out.println(header);}
// 响应数据if (requestOk) {// 读取html文件,转换为字符串/*Server.class:这是指向Server类的Class对象的引用。getClassLoader():这个方法返回加载Server类的类加载器。类加载器负责加载类,并且也可以用来加载其他资源。getResourceAsStream(String path):这个方法根据给定的路径获取一个输入流。路径是相对于classpath的根目录。*/InputStream is = Server.class.getClassLoader().getResourceAsStream("static/01.GET-POST.html");BufferedReader br = new BufferedReader(new InputStreamReader(is));StringBuilder data = new StringBuilder();
String line = null;while ((line = br.readLine()) != null) {data.append(line);}br.close();
int len = data.toString().getBytes(StandardCharsets.UTF_8).length;// 响应数据writer.write("HTTP/1.1 200 OK\r\n");writer.write("Connection: keep-alive\r\n");writer.write("Content-Type: text/html\r\n");writer.write("Content-Length: " + len + "\r\n");writer.write("\r\n");writer.write(data.toString());writer.flush();} else {writer.write("HTTP/1.0 404 Not Found\r\n");writer.write("Content-Length: 0\r\n");writer.write("\r\n");writer.flush();}相关文章:
后端开发-Maven
环境说明: windows系统:11版本 idea版本:2023.3.2 Maven 介绍 Apache Maven 是一个 Java 项目的构建管理和理解工具。Maven 使用一个项目对象模型(POM),通过一组构建规则和约定来管理项目的构建…...

自动化办公-合并多个excel
在日常的办公自动化工作中,尤其是处理大量数据时,合并多个 Excel 表格是一个常见且繁琐的任务。幸运的是,借助 Python 语言中的强大库,我们可以轻松地自动化这个过程。本文将带你了解如何使用 Python 来合并多个 Excel 表格&#…...

mavlink移植到单片机stm32f103c8t6,实现接收和发送数据
前言: 好久没更新博客了,这两个月真的是异常的忙,白天要忙着公司里的事,晚上还要忙着修改小论文,一点自己的时间都没有了,不过确确实实是学到了很多东西,对无人机的技术研究也更深了一些。不过好…...

小程序基础 —— 08 文件和目录结构
文件和目录结构 一个完整的小程序项目由两部分组成:主体文件、页面文件: 主体文件:全局文件,能够作用于整个小程序,影响小程序的每个页面,主体文件必须放到项目的根目录下; 主体文件由三部分组…...

FIR数字滤波器设计——窗函数设计法——滤波器的时域截断
与IIR数字滤波器的设计类似,设计FIR数字滤波器也需要事先给出理想滤波器频率响应 H ideal ( e j ω ) H_{\text{ideal}}(e^{j\omega}) Hideal(ejω),用实际的频率响应 H ( e j ω ) H(e^{j\omega}) H(ejω)去逼近 H ideal ( e j ω ) H_{\text{ideal}}…...

MySQLOCP考试过了,题库很稳,经验分享。
前几天,本人参加了Oracle认证 MySQLOCP工程师认证考试 ,先说下考这个证书的初衷: 1、首先本人是从事数据库运维的,今年开始单位逐步要求DBA持证上岗。 2、本人的工作是涉及数据库维护,对这块的内容比较熟悉ÿ…...

WPF 绘制过顶点的圆滑曲线 (样条,贝塞尔)
在一个WPF项目中要用到样条曲线,必须过顶点,圆滑后还不能太走样,捣鼓一番,发现里面颇有玄机,于是把我多方抄来改造的方法发出来,方便新手: 如上图,看代码吧: ----------…...

Kafka 幂等性与事务
文章目录 幂等性实现机制配置使用局限性 事务使用场景配置使用实现机制事务过程事务初始化事务开始事务提交事务取消事务消费 幂等性 Producer 无论向 Broker 发送多少次重复的数据,Broker 端只会持久化一条,保证数据不丢失且不重复。 实现机制 通过引…...

day2 Linux操作系统指令
思维导图 在家目录下创建目录文件,dir 1、dir下创建dir1和dir2 2、把当前目录下的所有文件拷贝到dir1中, 3、把当前目录下的所有脚本文件拷贝到dir2中 4、把dir2打包并压缩为dir2.tar.xz 5、再把dir2.tar.xz移动到dir1中 6、解压dir1中的压缩包 7、使用…...

AI一周重要会议和活动概览
一、小模型的曙光和机会之思辨高峰论坛 会议介绍:小模型的曙光和机会之思辨”高峰论坛暨第32期CSIG图像图形学科前沿讲习班于2025年1月3—4日在杭州举办,会议由中国图象图形学学会主办,中国图象图形学学会前沿科技论坛委员会承办。本次论坛设…...

重启ubuntu服务器,如何让springboot服务自动运行
文章目录 1. 使用 systemd 服务步骤: 2. 使用 cron 的 reboot 任务步骤: 3. 使用 init.d 脚本(适用于较旧版本)步骤: 推荐方案 为了确保在重启Ubuntu服务器后,让springboot的服务test.jar象 nohup java -ja…...

python系列教程237——启动扩展功能
朋友们,如需转载请标明出处:https://blog.csdn.net/jiangjunshow 声明:在人工智能技术教学期间,不少学生向我提一些python相关的问题,所以为了让同学们掌握更多扩展知识更好地理解AI技术,我让助理负责分享…...

U盘格式化工具合集:6个免费的U盘格式化工具
在日常使用中,U盘可能会因为文件系统不兼容、数据损坏或使用需求发生改变而需要进行格式化。一个合适的格式化工具不仅可以清理存储空间,还能解决部分存储问题。本文为大家精选了6款免费的U盘格式化工具,并详细介绍它们的功能、使用方法、优缺…...

循环神经网络(RNN)入门指南:从原理到实践
目录 1. 循环神经网络的基本概念 2. 简单循环网络及其应用 3. 参数学习与优化 4. 基于门控的循环神经网络 4.1 长短期记忆网络(LSTM) 4.1.1 LSTM的核心组件: 4.2 门控循环单元(GRU) 5 实际应用中的优化技巧 5…...

马原复习笔记
文章目录 前言导论物质实践人类社会资本主义社会主义共产主义后记 前言 一月二号下午四点多考试,很友好,不是早八,哈哈哈。之前豪言壮语和朋友说这次马原要全对,多做了几次测试之后,发现总有一些知识点是自己不知道的…...

Android Room 框架的初步使用
一、简介 Room 是一个强大的对象关系映射库,它允许你将 SQLite 数据库中的表映射到 Java 或 Kotlin 的对象(称为实体)上。你可以使用简单的注解(如 Entity、Dao 和 Database)来定义数据库表、数据访问对象(…...

什么是过度拟合和欠拟合?
在机器学习中,当一个算法的预测非常接近或者直接等于它的训练数据,导致不能够准确预测除了训练数据以外的数据,我们把这种情况称为过度拟合。算法能够非常接近甚至就是训练的数据,是个非常好的事,但是它不能准确预测除…...

DotnetSpider实现网络爬虫
1. 使用DotnetSpider框架 DotnetSpider是一个开源的、轻量、灵活、高性能、跨平台的分布式网络爬虫框架,适用于.NET平台。它可以帮助开发者快速实现网页数据的抓取功能。 1.1 安装DotnetSpider NuGet包 首先,你需要在你的.NET项目中安装DotnetSpider NuGet包。你可以通过…...

锐捷WLAN产品出货量排名第一!
摘要:2024年Q3锐捷WLAN产品出货量排名第一!锐捷多形态Wi-Fi 7产品重磅出击! 近日, IT市场研究和咨询公司IDC发布《IDC中国企业级WLAN市场跟踪报告,2024年Q3》。报告显示,锐捷WLAN产品在2024年Q3出货量位居行业首位。至此,锐捷WLAN产品在2024年的Q1、Q2、Q3均实现了市场出货量的…...

win32汇编环境下,对话框程序中生成listview列表控件,点击标题栏自动排序的示例
;把代码抄进radasm里面,可以直接编译运行。重要的地方加了备注。 ;这个有点复杂,重要的地方加了备注 ;以下是ASM文件 ;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>…...

柔性制造企业数字化工厂系统建设方案:制造业数字化全景图、打造5大引擎内核构建工业数字化底座、数据中台与数据治理、典型应用场景示例
本方案针对制造企业信息化痛点,提出基于无代码开发与组装式应用的数字化工厂建设思路,通过数据中台整合多源数据,结合MES、APS、WMS、数字孪生等系统,实现柔性生产、规范化管理与效率提升,助力企业低成本、高柔性、可持…...

毕业项目技术辅导:前后端与数据分析模块协作
毕业项目进入冲刺期,功能点多、时间紧、还要准备演示与答辩? 我这边提供毕业项目技术协作,主要做: 前端页面与交互实现(可配合你现有框架)后端接口、数据库与联调支持数据清洗、分析与可视化展示既有代码 b…...
实战:深度解析CATIDescendants在几何图形集遍历与筛选中的应用)
CATIA二次开发(CAA)实战:深度解析CATIDescendants在几何图形集遍历与筛选中的应用
1. CATIDescendants接口:几何图形集的"智能导航仪" 在CATIA二次开发中,处理几何图形集就像在迷宫中寻找特定房间。CATIDescendants接口就是你的智能导航仪,它能帮你快速定位目标。这个接口最常用的两个方法是GetAllChildren和GetDi…...
)
从LevelDB到自研PoolEngine:金融C++内存池测试演进史(2003–2024,12次重大架构迭代中的3次致命教训)
第一章:从LevelDB到自研PoolEngine:金融C内存池测试演进史(2003–2024,12次重大架构迭代中的3次致命教训)在高频交易系统与实时风控引擎的严苛场景下,内存分配延迟的微秒级波动即可能引发订单错配或熔断失效…...

5步解锁全球化内容生产:MoneyPrinterTurbo多语言视频创作全指南
5步解锁全球化内容生产:MoneyPrinterTurbo多语言视频创作全指南 【免费下载链接】MoneyPrinterTurbo 利用AI大模型,一键生成高清短视频 Generate short videos with one click using AI LLM. 项目地址: https://gitcode.com/GitHub_Trending/mo/MoneyP…...

5分钟快速搭建PUBG实时雷达:掌握战场信息的终极指南
5分钟快速搭建PUBG实时雷达:掌握战场信息的终极指南 【免费下载链接】PUBG-maphack-map this is a working copy online-map from jussihi/PUBG-map-hack, use nodejs webserver instead of firebase. 项目地址: https://gitcode.com/gh_mirrors/pu/PUBG-maphack-…...

QT——计算器核心算法
1.中缀表达式转后缀表达式(1)分离算法(数字和符号分离)中缀表达式中包含:数字和小数点、符号位(或-)、运算符(-*/)、括号思想:以符号作为标志对表达式中的字符逐个访问当前字符exp[i…...

利用GCC特性实现MCU固件版本号的绝对地址存储
1. 为什么需要绝对地址存储版本号 在嵌入式开发中,固件版本号是一个看似简单却至关重要的信息。想象一下你正在调试一台远程设备,突然发现它运行的是旧版本固件,但翻遍整个代码库都找不到版本号定义在哪里——这种场景我遇到过不止一次。传统…...

OpenClaw定时任务实战:gemma-3-12b-it每日凌晨自动备份重要文件
OpenClaw定时任务实战:gemma-3-12b-it每日凌晨自动备份重要文件 1. 为什么需要自动化文件备份 上周我的移动硬盘突然罢工,导致三个月的工作文档险些丢失。这次事故让我意识到:人工备份永远存在疏漏。即使设置了日历提醒,也难免因…...
)
Python+百度OCR实战:5分钟搞定批量图片经纬度提取(附完整代码)
Python百度OCR实战:5分钟搞定批量图片经纬度提取(附完整代码) 当你面对数百张带有经纬度水印的野外考察照片时,是否曾为手动记录坐标而抓狂?去年参与某生态调查项目时,团队摄影师每天传回300张带坐标水印的…...