《机器学习》——利用OpenCV库中的KNN算法进行图像识别
文章目录
- KNN算法介绍
- 下载OpenCV库
- 实验内容
- 实验结果
- 完整代码
- 手写数字传入模型训练
KNN算法介绍
- 一、KNN算法的基本要素
- K值的选择:K值代表选择与新测试样本距离最近的前K个训练样本数,通常K是不大于20的整数。K值的选择对算法结果有重要影响,需要通过交叉验证等方法来确定最优的K值。
- 距离度量:常用的距离度量方式包括闵可夫斯基距离、欧氏距离、曼哈顿距离、切比雪夫距离、余弦距离等。其中,欧氏距离在KNN算法中最为常用。
- 分类决策规则:一般采用多数投票法,即选择K个最相似数据中出现次数最多的类别作为新数据的分类。
- 二、KNN算法的工作流程
- 准备数据:对数据进行预处理,包括收集、清洗和归一化等步骤,以确保所有特征在计算距离时具有相等的权重。
- 计算距离:计算测试样本点到训练集中每个样本点的距离。
- 排序与选择:根据距离对样本点进行排序,并选择距离最小的K个样本点作为测试样本的邻居。
- 分类决策:根据K个邻居的类别信息,采用多数投票法确定测试样本的类别。
下载OpenCV库
pip install opencv-python
# 后面可以加上指定版本,和镜像文件
#如:
pip install opencv-python==3.4.18.65
- 调用包和其他包有所不同:
import cv2
实验内容
- 实验目的
- 通过OpenCV库中的KNN算法对数据进行分类,并验证。
- 实验流程
- 下面是一张已经经过一些初步处理过的图片,其中含有0~9的手写数字,且每一个数字都是5行,100列,共有5000个数字。
- 本次通过对这张分辨率为2000*1000的图片进行切分。
- 将其划分成独立的数字,每个数字大小为20*20像素,共计5000个;并平均切分为左右两个等份,一份作为训练集,一份作为测试集。
- 将训练集放到模型中训练后,再传入测试集进行测试,得到结果后,通过与正确结果比较得出准确率。
- 最后自己手写一些数字,放入实验项目下,并处理后放入模型,测试出结果。

- 实验步骤
- 1、获取数据
- 2、处理数据
- 3、分配标签
- 4、模型构建和训练
- 5、测试
- 6、通过测试集校验准确率
- 1.获取数据
本实验数据已经提供了,只需要将图片拉入到项目目录中,再用以下代码进行读取:
# 通过opencv中的cv2.imread()方法进行读取:
img =cv2.imread('shu_zi.png')
- 2.处理数据
通常在实验项目中,获取数据和处理数据通常需要花费很长时间,在此实验中要进行一下数据处理:- 首先给的图片是一个黑底白字的图片,但是图片是一个三通道彩色图片,为了简化图像数据和计算量,故此我们要将图片转换成灰度图。
- 再对图片进行切分,分别首先将行切分成50份每一份20个像素值,再将切分过一次的数据进行一次对列的切分,切分100份每一份20个像素值。
- 将切分得到的数据转化成数组。
- 划分训练集和测试集,对得到的数组进行划分,从中间一分为二,一份为训练集一份为测试集。
- 对训练集和测试集中的数据构造为符合KNN的输入,将每个数字的尺寸由20*20调整为1*400。
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
x =np.array(cells)train = x[:,:50]
test =x[:,50:100]# 将数据构造为符合KNN的输入,将每个数字的尺寸由20*20调整为1*400
train_new = train.reshape(-1,400).astype(np.float32)
test_new = test.reshape(-1,400).astype(np.float32)注意:.astype(np.float32): 是为了将reshape后的数组的数据类型转换为np.float32,即32位浮点数。这是因为在机器学习或深度学习中,通常会使用浮点数来表示特征或标签,而np.float32相比于64位浮点数(np.float64)可以节省内存,同时对于大多数应用来说,其精度已经足够。
- 3.分配标签
- 分别为训练集、测试集分配标签。
# 分配标签:分别为训练数据、测试数据分配标签
k = np.arange(10)
labels = np.repeat(k,250)
train_labels = labels[:,np.newaxis] # np.newaxis是numpy库中一个特殊对象用于增加一个新的维度
test_labels = np.repeat(k,250)[:,np.newaxis]- 4.模型构建和训练
# # # 构建+训练
knn =cv2.ml.KNearest_create() # 通过cv2创建一个knn模型
knn.train(train_new,cv2.ml.ROW_SAMPLE,train_labels)
# cv2.ml.ROW_SAMPLE是用来告诉模型,一行是一组数据,每一列是一个特征。
- 5.测试
- 传入训练集,并指定K的值,可以更改不同的K值来找到最佳的测试结果
# findNearest测试方法
ret,result,neighbours,dist=knn.findNearest(test_new,k=3)
# # ret:表示查找操作是否成功
# # result:浮点数数组,表示测试样本的预测标签
# # neighbours:这是一个整数数组,表示与测试样本最近的k个索引。
# # dist:这是一个浮点数组,表示测试样本与每一个最近邻居之间的距离。
- 6、通过测试集校验准确率
matches = result==test_labels
correct = np.count_nonzero(matches)
accuracy = correct*100.0/result.size
print("当前图片的准确率为:",accuracy)
- matches = result == test_labels:这行代码通过比较result(KNN算法预测的结果)和test_labels(测试集的真实标签)来生成一个布尔数组matches。如果result中的某个预测值与test_labels中对应的真实标签相等,则matches中对应位置的值为True,否则为False。
- correct = np.count_nonzero(matches):这行代码使用np.count_nonzero函数计算matches数组中True的数量,即正确预测的数量。np.count_nonzero函数会统计数组中所有非零元素(在这个场景下,即True)的数量。
- accuracy = correct * 100.0 / result.size:这行代码计算准确率。首先,将正确预测的数量correct乘以100.0(为了得到百分比),然后除以result.size(即预测结果的总数,也就是测试集的大小)。这样得到的accuracy就是准确率,以百分比形式表示。
- print(“当前使用KNN识别手写数字的准确率为:”, accuracy):最后,这行代码将计算得到的准确率打印出来。
实验结果
- 打印准确率

完整代码
import numpy as np
import cv2
img =cv2.imread('shu_zi.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
x =np.array(cells)
train = x[:,:50]
test =x[:,50:100]
# 将数据构造为符合KNN的输入,将每个数字的尺寸由20*20调整为1*400
train_new = train.reshape(-1,400).astype(np.float32)
test_new = test.reshape(-1,400).astype(np.float32)# 分配标签:分别为训练数据、测试数据分配标签
k = np.arange(10)
labels = np.repeat(k,250)
train_labels = labels[:,np.newaxis] # np.newaxis是numpy库中一个特殊对象用于增加一个新的维度
test_labels = np.repeat(k,250)[:,np.newaxis]
knn =cv2.ml.KNearest_create() # 通过cv2创建一个knn模型
knn.train(train_new,cv2.ml.ROW_SAMPLE,train_labels)
ret,result,neighbours,dist=knn.findNearest(test_new,k=3)
matches = result==test_labels
correct = np.count_nonzero(matches)
accuracy = correct*100.0/result.size
print("当前使用KNN识别手写数字的准确率为:",accuracy)
手写数字传入模型训练
- 下图是通过电脑自带的画图工具,写出的三个数字,并且已经将大小调整为20*20像素大小的图片

- 将图片经过与实验中相同的处理方法,加以处理并传入到模型中进行测试
import numpy as np
import cv2
from numpy.ma.core import array
img = cv2.imread('shu_zi.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
x = np.array(cells)
train = x[:, :50]
train_new = train.reshape(-1, 400).astype(np.float32)
i = ('a2.png', 'a1.png', 'a3.png')
# wary = (1,3,9)
# for n in wary:
for w in i:a1 = cv2.imread(w)a2 = cv2.cvtColor(a1, cv2.COLOR_BGR2GRAY)a3 = a2.reshape(-1, 400).astype(np.float32)k = np.arange(10)labels = np.repeat(k, 250)train_labels = labels[:, np.newaxis] # np.newaxis是numpy库中一个特殊对象用于增加一个新的维度knn = cv2.ml.KNearest_create() # 通过cv2创建一个knn模knn.train(train_new, cv2.ml.ROW_SAMPLE, train_labels)ret, result, neighbours, dist = knn.findNearest(a3, k=3)matches = result ==int(input('请输入猜测的数字:'))correct = np.count_nonzero(matches)accuracy = correct * 100.0 / result.sizeprint(f"当前使用KNN识别手写数字{w}的准确率为:", accuracy)
-
结果:

-
由此可以看出,此次实验的模型还是相对比较准确的
相关文章:
《机器学习》——利用OpenCV库中的KNN算法进行图像识别
文章目录 KNN算法介绍下载OpenCV库实验内容实验结果完整代码手写数字传入模型训练 KNN算法介绍 一、KNN算法的基本要素 K值的选择:K值代表选择与新测试样本距离最近的前K个训练样本数,通常K是不大于20的整数。K值的选择对算法结果有重要影响,…...

StarRocks 存算分离在得物的降本增效实践
编者荐语: 得物优化数据引擎布局,近期将 4000 核 ClickHouse 迁移至自建 StarRocks,成本降低 40%,查询耗时减半,集群稳定性显著提升。本文详解迁移实践与成果,文末附丁凯剑老师 StarRocks Summit Asia 2024…...

Tube Qualify弯管测量系统在汽车管路三维检测中的应用
从使用量上来说,汽车行业是使用弯管零件数量最大的单一行业。在汽车的燃油,空调,排气,转向,制动等系统中都少不了管路。汽车管件形状复杂,且由于安装空间限制,汽车管件拥有不同弯曲半径…...

udp分片报文发送和接收
读文件通过udp分片发送的目的端:(包含错误的分片包) #!/usr/bin/python # -*- coding: utf-8 -*-#python send_100frag_file.py -p 55432 -f snatdownloadimport argparse import loggingfrom scapy.all import *# Define the maximum size …...

【从零开始入门unity游戏开发之——C#篇39】C#反射使用——Type 类、Assembly 类、Activator 类操作程序集
文章目录 前言一、前置知识1、编译器2、程序集(Assembly)3、元数据(Metadata) 二、反射1、反射的概念2、反射的作用3、反射的核心Type 类3.1 Type 类介绍3.2 不同方法获取 Type3.3 获取type类型所在的程序集的相关信息 4、反射的常…...

安卓触摸事件的传递
setOnTouchListener()返回值的副作用(触摸事件是否继续往下或往后传递)如下: 返回值效果是否往下层view传递是否往当前view的后续监听传递true该pointer离开屏幕前的后续所有触摸事件都会传递给该TouchListener否否false该pointer离开屏幕前…...
idea项目导入gitee 码云
1、安装gitee插件 IDEA 码云插件已由 gitosc 更名为 gitee。 1 在码云平台帮助文档http://git.mydoc.io/?t153739上介绍的很清楚,推荐前两种方法, 搜索码云插件的时候记得名字是gitee,gitosc已经搜不到了。 2、使用码云托管项目 如果之…...

典型常见的基于知识蒸馏的目标检测方法总结三
来源:Google学术2023-2024的顶会顶刊论文 NeurIPS 2022:Towards Efficient 3D Object Detection with Knowledge Distillation 为3D目标检测提出了一种知识蒸馏的Benchmark范式,包含feature的KD,Logit的cls和reg的KD,…...

端口被占用
端口8080被占用 哈哈哈,我是因为后端项目跑错了,两个项目后端名称太像了; (1)netstat -aon | findstr 8080,找到占用8080端口的进程号,获取对应的进程号pid; (2&#…...
)
Javascript知识框架图(待完善)
以下是一个清晰且详细的 JavaScript 知识框架,涵盖基础知识到高级概念,适合学习和参考: JavaScript 知识框架 1. 基础知识 数据类型 原始类型:Number,String,Boolean,Null,Undefin…...

清华大学Python包镜像站点
清华大学提供了一个Python包镜像站点,其中包括了许多常用的Python包。使用这个镜像站点可以提高下载Python包时的速度,因为包已经存储在国内的服务器上,从而减少了网络延迟。 要使用清华的pip镜像,你可以在pip命令中指定-i参数来…...

逆境清醒文章总目录表
逆境清醒文章总目录表 零、时光宝盒🌻 (https://blog.csdn.net/weixin_69553582 逆境清醒) 《你的答案》歌曲原唱:阿冗,填 词:林晨阳、刘涛,谱曲:刘涛 也许世界就这样,…...

LeetCode算法题——移除元素
题目描述 给你一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。 假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作࿱…...

常见的中间件漏洞
1.Tomcat Tomcat介绍 tomcat是⼀个开源而且免费的jsp服务器,默认端口 : 8080,属于轻量级应⽤服务器。它可以实现 JavaWeb程序的装载,是配置JSP(Java Server Page)和JAVA系统必备的⼀款环境。 在历史上也披露出来了很…...
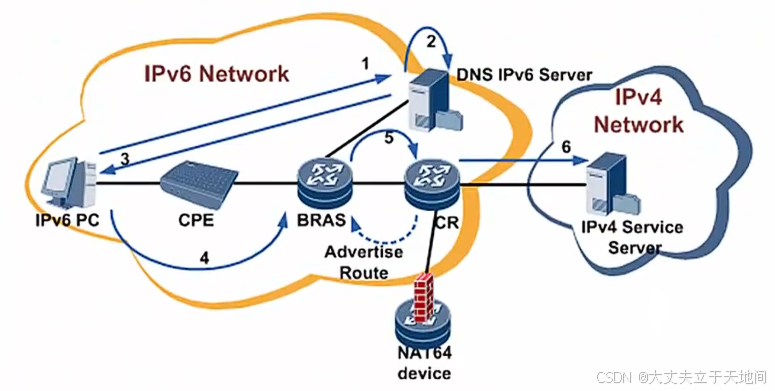
IPv6的过度技术
如何界定手动与自动? 主要是隧道目标地址能否自动获取 👯1. 双栈 必须支持IPv4和IPv6协议 链接双栈网络的接口必须同时配置v4和v6地址 路由器能够根据二层标记识别协议,type:0x0800代表IPV4,type:0x…...

Python用K-Means均值聚类、LRFMC模型对航空公司客户数据价值可视化分析指标应用|数据分享...
全文链接:https://tecdat.cn/?p38708 分析师:Yuling Fang 信息时代的来临使得企业营销焦点从产品中心转向客户中心,客户关系管理成为企业的核心问题(点击文末“阅读原文”获取完整代码数据)。 客户关系管理的关键是客…...

WebRTC的三大线程
WebRTC中的三个主要线程: signaling_thread,信号线程:用于与应用层交互worker_thread,工作线程(最核心):负责内部逻辑处理network_thread,网络线程:负责网络数据包的收发…...

Spring SpEL表达式由浅入深
标题 前言概述功能使用字面值对象属性和方法变量引用#this 和 #root变量获取类的类型调用对象(类)的方法调用类构造器类型转换运算符赋值运算符条件(关系)表达式三元表达式Elvis 操作符逻辑运算instanceof 和 正则表达式的匹配操作符 安全导航操作员数组集合(Array 、List、Map…...

数据设计规范
目录 一、数据库设计的原则 二、表设计原则 三、其他设计规范 四、最佳实践 数据库设计(Database Design)是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,使之能够有效地存储数据&#…...

基于SpringBoot的宠物寄养系统的设计与实现(源码+SQL+LW+部署讲解)
文章目录 摘 要1. 第1章 选题背景及研究意义1.1 选题背景1.2 研究意义1.3 论文结构安排 2. 第2章 相关开发技术2.1 前端技术2.2 后端技术2.3 数据库技术 3. 第3章 可行性及需求分析3.1 可行性分析3.2 系统需求分析 4. 第4章 系统概要设计4.1 系统功能模块设计4.2 数据库设计 5.…...

不止是怀旧:用Docker部署超级马里奥,聊聊容器化对经典软件保存的意义
容器化时光机:用Docker守护数字文化遗产的技术实践 在数字时代洪流中,经典软件如同沙漏中的细沙,正以惊人的速度从我们的指尖流逝。那些曾经定义了一个时代的程序、游戏和工具,正面临着"数字消亡"的威胁——操作系统迭代…...
)
告别AT命令!用四博智联ESP8266固件5分钟搞定MQTT连接(带图形界面)
5分钟零代码实战:用四博智联ESP8266固件轻松玩转MQTT 第一次接触物联网开发时,我被ESP8266的AT指令折磨得够呛——那些晦涩的命令行参数、复杂的连接步骤,稍有不慎就会卡在某个环节。直到发现四博智联的定制固件,才真正体会到什么…...

二维码识读设备选购全攻略:从核心需求到实战测试
1. 项目概述:为什么选对二维码识读设备这么重要?你可能觉得,不就是扫个码吗?手机摄像头都能搞定,专门的设备能有多大区别?我刚开始接触这个领域时也是这么想的,直到自己踩过几次坑,才…...

3个实战技巧高效提取抖音1080P视频封面:自媒体素材管理效率提升90%
3个实战技巧高效提取抖音1080P视频封面:自媒体素材管理效率提升90% 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fa…...

突发外交事件3分钟响应!Perplexity国际新闻搜索应急配置清单,含12条预设Prompt与可信度评分模型
更多请点击: https://kaifayun.com 第一章:突发外交事件3分钟响应!Perplexity国际新闻搜索应急配置清单,含12条预设Prompt与可信度评分模型 面对突发外交事件(如边境冲突升级、高层会谈临时取消、制裁公告突袭发布&am…...

STC32G单片机开发实战:GPIO模式配置与寄存器详解
1. STC32G单片机GPIO基础认知 第一次拿到STC32G开发板时,我习惯性地想用STM32那套HAL库来操作GPIO,结果发现根本行不通。这就像拿着汽车钥匙去开保险箱,虽然都是"开锁",但机制完全不同。STC32G作为增强型8051架构单片机…...
)
保姆级教程:手把手教你用Amlogic刷机工具给中兴B863AV3.2T盒子刷当贝桌面(附短接神器使用心得)
中兴B863AV3.2T盒子刷机全流程实战指南:从拆机到当贝桌面的完美蜕变 第一次接触电视盒子刷机时,那种既兴奋又忐忑的心情我至今记忆犹新。手里拿着价值不过百元的中兴B863AV3.2T盒子,却像捧着一个未知的宝藏——既期待通过刷机解锁它的全部潜能…...

STM32F407移植EasyFlash:嵌入式Flash键值存储与磨损均衡实战
1. 项目概述:为什么要在STM32F407上折腾EasyFlash?最近在做一个基于STM32F407的物联网终端设备,功能上需要记录一些运行参数、用户配置,还得在意外断电后能恢复现场。最开始想着用片内Flash模拟EEPROM,自己写读写擦除逻…...

无王无帝定乾坤,来自田间第一人 海棠藏圣定山河
无王无帝定乾坤,来自田间第一人。 自古山河安定,世人皆归功于帝王镇守、朝堂统御, 仿佛万里乾坤唯有王权可镇、唯有霸业可安。 然则山河气运自有天道,世间安定自有公理, 强权只能维系一时疆域,正道方能稳固…...
)
409.最长回文串(数学算法)
题目 给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的 回文串 的长度。 在构造过程中,请注意 区分大小写 。比如 "Aa" 不能当做一个回文字符串。 题目链接如下: https://leetcode.cn/problems/longe…...