迈向Z级计算:Cloud4Science范式加速科学发现进程
传统超级计算机作为科学计算的核心支柱,在推动技术进步方面发挥了不可替代的作用,但随着科学智能时代下需求的多样化和复杂化,其扩展性和能效的局限逐渐显现。
针对这一挑战, 微软亚洲研究院 的研究员提出了 Cloud4Science 的新范式,以云计算、 人工智能 和高性能计算技术的深度融合为核心,重新定义科学计算的架构,加速科学智能的研究进展。
在此框架下,研究员们已对关键科学计算算法如 Stencil、FFT、SpMV 等进行了优化,并成功开发了一系列创新算法,为科学家利用云计算及 人工智能 平台进行科学计算和研究开辟了新的途径。
相关工作已连续发表在 SC、PPoPP 等高性能计算与并行计算领域顶会,并获得了 PPoPP’24 唯一最佳论文奖。

在刚刚落幕的国际超算大会 SC’24 上,最新揭晓的戈登贝尔奖获奖应用成功突破了 E 级计算的瓶颈,标志着超级计算机应用正式迈入下一个关键阶段——万 P 级计算(每秒千亿亿次浮点运算)。作为高性能计算(HPC)的巅峰代表,超级计算机长期以来一直是推动科学和技术进步的重要力量。
科学计算作为超级计算机的核心应用领域,利用其强大的计算能力,通过数值模拟、数据分析和数学建模,旨在解决科学、工程和技术中的复杂问题,在揭示自然规律、预测未知现象以及推动技术创新中发挥着不可或缺的作用。
然而,随着科学智能(AI for science)时代的到来,超级计算机在追求更高性能的同时,也面临着一些新的挑战:
-
架构碎片化:各超算系统采用不同的硬件架构和编程模型,科学应用需要复杂的定制化适配才能运行。这不仅限制了科学应用的多样性,还难以兼顾传统科学计算与智能计算的双重需求。
-
开发难度高:科学智能时代强调多学科、多技术领域的交叉与协作。不同的超级计算机架构不仅增加了软件开发和维护的复杂度,开发者还需要不断重新学习并掌握跨领域的专业知识,阻碍了科学研究的灵活性和快速推进。
-
能耗与成本压力:当前 E 级超算每年耗电可达上亿度,未来 Z 级超算能耗可能更高。同时,系统更新换代成本巨大,应用需重新设计和部署,进一步增加了科研投入的时间和经济成本。
「传统科学计算的优势在于数值求解,通过高精度计算模拟复杂的物理过程。然而,随着问题规模的快速扩大和计算复杂度的持续攀升,单纯依赖数值求解的模式难以充分释放未来万 P 级甚至 Z 级超算的全部潜力。」 微软亚洲研究院 高级研究员李琨表示,「科学计算正在从传统数值求解向融合知识推理的科学智能转型。通过将高性能计算技术与未来的 Z 级算力结合,全面支撑科学智能时代对极限计算和智能推理的双向扩展需求,才会为更多突破性发现提供全新的可能性。」
Cloud4Science 范式加速科学计算进程
为了应对这些挑战, 微软亚洲研究院 的研究员提出了 Cloud4Science 范式,希望通过融合现有的云基础设施、 人工智能 和高性能计算技术,重塑科学计算的模式。这一范式为传统超算范式提供了有效的补充,也为科学智能提供了一种更加灵活、高效且可扩展的解决方案。
「Cloud4Science 范式通过将科学计算任务迁移到云平台或 人工智能 架构上,实现了计算架构的统一,降低了科学计算的访问门槛。」 微软亚洲研究院 首席研究员曹婷表示,「这使得科研人员能够在单一平台上使用多种算法和应用,同时,云平台和 人工智能 的强大算力也将大幅提升科学计算效率,为未来的科学研究与计算应用开辟新的可能性。」
为了实现 Cloud4Science 范式,研究员们计划分两个阶段来推进:

Cloud4Science:融合云计算、AI 与高性能计算,驱动科学智能新未来
第一阶段是以问题为导向,从算法角度对传统科学计算进行迁移,确保这些计算任务能够在云计算或人工智能 硬件架构上顺利运行。这一阶段的核心任务是将经典的科学计算算法,如 Stencil、FFT(快速傅里叶变换)、SpMV(稀疏矩阵-向量乘法)等,转换为基于矩阵乘法的计算模式,以便充分利用云计算和 人工智能 的强大计算能力。通过这一转化,传统科学计算算法的性能得以显著提升,同时大幅降低了科学应用对硬件适配的复杂性,并为下一步科学计算的智能化奠定了基础。
第二阶段的目标是推动科学计算算法与人工智能 的深度融合。传统的科学计算算法更注重数值计算,而科学智能则强调推理能力的提升。科学计算模型与大语言模型虽然在某些方面可以互相借鉴,但二者之间存在显著差异。科学计算模型通常包含大量的物理信息和生物信息,这些专业知识需要被有效地整合到算法设计中。因此,这一阶段的任务是设计融合传统科学计算模型与 人工智能 技术的创新解决方案,通过 人工智能 技术有效整合领域知识、生成洞见并促进科学创新,充分利用云原生和 人工智能 原生架构的优势,进一步推动 Cloud4Science 范式的发展。
传统科学算法向云计算与人工智能 硬件的无缝迁移
目前,第一阶段的研究目标已经基本完成,即实现传统科学计算算法向云计算和 人工智能 硬件的无缝迁移。
研究员们从 Stencil 算法入手,设计了全新的算法 Jigsaw 和 ConvStencil,将 Stencil 算法向量化并重新张量化成矩阵乘法模式,使 Stencil 算法成功映射到 Tensor Core 等 人工智能 加速器硬件单元。
随后,研究员们又引入了 人工智能 驱动的低秩适应(Low-Rank Approximation,LoRA)技术,进一步优化 Stencil 性能,推出了 LoRAStencil 以及融合三种经典算法的 FlashFFTStencil,这些创新让多种科学计算算法能够更高效地部署在 人工智能 加速单元上,实现性能的显著提升并同时降低了硬件适配的复杂性。
扩展矩阵计算边界,连接科学与 AI 硬件
为突破科学计算的性能瓶颈,研究员们提出了 ConvStencil [1],通过将传统的科学计算算法映射为矩阵乘法,进一步扩展了矩阵计算的应用边界,为科学计算与 AI 硬件的高效协同奠定了坚实基础。
基于 Stencil 算法与 人工智能 领域广泛应用的卷积计算模式有着相似之处,研究员们专门开发了一套针对 GPU Tensor Core 的优化算法,使得其能够充分利用 Tensor Core 强大的矩阵计算能力。
通过引入布局转换与冲突消除机制,ConvStencil 不仅显著提升了科学计算与云计算及 人工智能 硬件的兼容性,还促进了科学计算从传统的 CPU 计算向现代 GPU 计算的顺利过渡。

基于矩阵乘法的 ConvStencil 计算系统(PPoPP’24 唯一最佳论文奖)
为了实现内存访问效率的大幅提高,研究员们在 ConvStencil 的基础上设计了 LoRAStencil [4],通过融入 LoRA 技术,巧妙地结合了数据的低秩特征与计算需求。利用分解权重矩阵,优化数据的加载与复用过程,LoRAStencil 有效减少了不必要的内存访问,解决了维度残差问题。
实验评估显示,LoRAStencil 相比现有技术,性能提升最高可达2.16倍。LoRAStencil 为在 Tensor Core 单元上实现高效的张量化 Stencil 计算开辟了新的途径,使其在科学计算中能发挥更大作用。
尽管 Tensor Core 单元在处理 人工智能 任务时表现出色,但在处理如 Stencil 这样涉及大量稀疏数据的高性能计算算法时,仍面临计算资源利用率不高和内存带宽受限的问题。
为了解决这些挑战,研究员们创造性地将 Stencil、FFT 和矩阵乘法三种经典科学计算算法融为一体,提出了更为高效的 FlashFFTStencil 计算系统 [3]。
实验结果证实,FlashFFTStencil 实现了无稀疏性的边界转换,其性能较现有最先进的技术平均提升了 2.57 倍。
FlashFFTStencil 在实现了多种科学计算算法统一的同时,还成功地将这些算法与 Tensor Core 单元等先进的 人工智能 硬件连接起来,为科学计算的未来发展提供了新的可能性。

基于全稠密矩阵计算的 FlashFFTStencil 系统
时空数据向量对齐,提升 CPU 计算效率
Jigsaw 算法 [5] 专注于 Stencil 算法的向量化,通过采用基于通道的蝶形向量化、基于奇异值分解的维度展平(SVD-based Dimension Flattening)技术以及基于迭代的时间合并策略,有效解决了空间和时间维度上的数据对齐冲突(Data Alignment Conflict, DAC)问题,大幅提升了科学计算在 CPU 上的效率。
实验结果显示,在多种测试环境中,Jigsaw 相对于当前最先进的技术平均实现了2.31倍的加速效果,适用于广泛的 Stencil 内核。
在此基础上,研究员们还对另一种重要的科学计算算法——稀疏矩阵-向量乘(Sparse Matrix-Vector Multiplication, SpMV)进行了深入优化,提出了 VNEC 算法 [6]。
这是一种创新的 SpMV 存储格式,旨在优化数据局部性和向量化操作,同时缓解现有算法的局限性。VNEC 通过剔除冗余列和改进数据局部性,大幅度减少了内存访问开销,增强了向量计算的效率。
实验表明,在多核处理器环境下,VNEC 在 x86 CPU 上相较于标准 MKL SpMV 例程最高实现了 6.94 倍(平均 2.10 倍)的加速,在 ARM CPU 上的加速比最高可达 5.92 倍(平均 1.73 倍)。
由于 VNEC 格式转换的预处理成本较低,特别适用于实际的迭代应用场景,展现出了极高的实用价值。
Cloud4Science 范式在量子化学中的实践探索
为了验证 Cloud4Science 范式能否为科学计算带来更好的性能提升, 微软亚洲研究院 的研究员们与微软研究院科学智能中心(Microsoft Research AI for Science)团队合作,共同开发了一种端到端的优化编译器 EPT(Elastic Parallel Transformation)[2]。利用弹性并行转换技术,EPT 可以把传统的科学计算算法,特别是从头算量子化学计算,自动适配至 GPU 架构。因此,EPT 能够将复杂的量子化学问题分解为适合并行处理的单元,优化任务的划分粒度,并生成专为 GPU 架构优化的高效计算内核。

弹性并行转换(EPT)编译器系统框架图
通过在多种 GPU 硬件(如 NVIDIA V100、A6000、A100 等)上对13种具有代表性的分子进行测试,实验结果显示,EPT 在保证从头算精度的前提下,相较于现有的顶级 CPU 和 GPU 解决方案,性能分别提升了高达34.90倍和9.89倍。
通过 Cloud4Science 范式,量子化学研究的计算效率和精度得到了显著提升,这为加速新材料开发、药物设计和基础科学探索提供了坚实的技术基础。
Cloud4Science 范式推动 HPC 领域变革,加速科学研究发现
在科学研究迈向智能时代的进程中,矩阵计算正逐渐成为连接传统数值计算与科学智能的关键桥梁,而 Cloud4Science 范式凭借其 Z 级计算潜力,不但为科学在时间和空间尺度上带来了质的飞跃的可能,同时也为科学计算向智能化与推理驱动方向的演进注入了动力。
以量子化学为例,Cloud4Science 不仅能缩短计算周期,将复杂分子相互作用的模拟时间从数年压缩至数周甚至数天,还能通过矩阵计算与 AI 推理的融合,使得系统能够基于海量计算数据进行模式识别与智能推理,例如预测药物分子与蛋白靶点的相互作用趋势,自动发现可能的抗性突变路径。
正如个人计算机从单机时代迈入云计算时代,彻底革新了信息处理的广度与效率,未来 Cloud4Science 范式的成功应用也有望在 人工智能 时代为高性能科学计算带来新的变革。
通过融合云计算的可扩展性、AI 的智能决策能力以及高性能计算技术,Cloud4Science 将在未来迈向 Z 级计算的过程中,实现科学计算在极限求解与智能推理两大方向的双向突破,赋予科学智能更强的灵活性、更高的效率与更广泛的可扩展性,为科学研究带来新的创新动力与发展空间。
「Cloud4Science 新范式将显著降低高性能计算基础设施的开发成本,并提升其对科研人员的易用性。」曹婷表示,「尤其是对于那些资源有限的小型研究团队或初创企业而言,这一范式将赋能他们获取 E 级乃至万 P 级科学计算的潜力。这意味着更多的科研工作者可以参与到之前仅限于顶尖机构和大型企业才能涉足的前沿科学计算研究中,极大地拓宽了科学研究的边界,加速科学发现的步伐。」
更多内容可以访问我的博客 https://ai.tmqcjr.com
相关文章:
迈向Z级计算:Cloud4Science范式加速科学发现进程
传统超级计算机作为科学计算的核心支柱,在推动技术进步方面发挥了不可替代的作用,但随着科学智能时代下需求的多样化和复杂化,其扩展性和能效的局限逐渐显现。 针对这一挑战, 微软亚洲研究院 的研究员提出了 Cloud4Science 的新范…...

ES IK分词字典热更新
前言 在使用IK分词器的时候,发现官方默认的分词不满足我们的需求,那么有没有方法可以自定义字典呢? 官方提供了三种方式 一、ik本地文件读取方式 k插件本来已为用户提供自定义词典扩展功能,只要修改配给文件即可: …...

Mac连接云服务器工具推荐
文章目录 前言步骤1. 下载2. 安装3. 常用插件安装4. 连接ssh测试5. 连接sftp测试注意:ssh和sftp的区别注意:不同文件传输的区别解决SSL自动退出 前言 Royal TSX是什么: Royal TSX 是一款跨平台的远程桌面和连接管理工具,专为 mac…...

从零开始:如何在 .NET Core 中优雅地读取和管理配置文件
在.net中的配置文件系统支持丰富的配置源,包括文件(json、xml、ini等)、注册表、环境变量、命令行、Azure Key Vault等,还可以配置自定义配置源并跟踪配置的改变,然后按照优先级进行覆盖,总之对文件的配置有很多方法,这…...

JVM学习:CMS和G1收集器浅析
总框架 一、Java自动内存管理基础 1、运行时数据区 运行时数据区可分为线程隔离和线程共享两个维度,垃圾回收主要是针对堆内存进行回收 (1)线程隔离 程序计数器 虚拟机多线程是通过线程轮流切换、分配处理器执行时间来实现的。为了线程切换…...

Science Robotics让软机器人“活”得更久的3D打印!
软机器人硬件在医疗、探索无结构环境等领域有广泛应用,但其生命周期有限,导致资源浪费和可持续性差。软机器人结合软硬组件,复杂组装和拆卸流程使其难以维修和升级。因此,如何延长软机器人的生命周期并提高其可持续性成为亟待解决…...

模电面试——设计题及综合分析题0x01(含答案)
1、已知某温控系统的部分电路如下图(EDP070252),晶体管VT导通时,继电器J吸合,压缩机M运转制冷,VT截止时,J释放,M停止运转。 (1)电源刚接通时,晶体…...
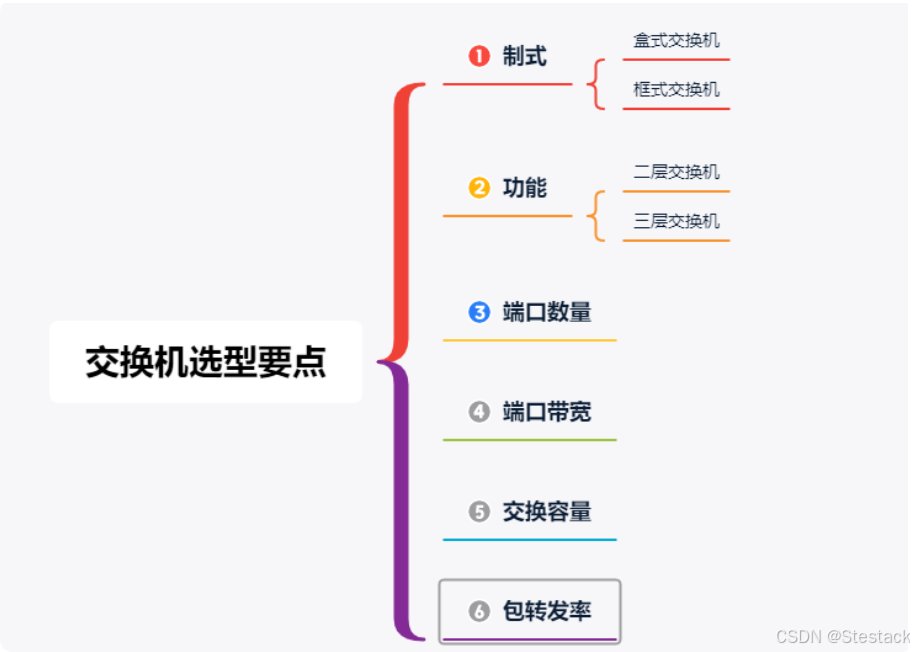
二层交换机和三层交换机
一、交换机简述 交换机的主要功能包括物理编址、网络拓扑结构、错误校验、帧序列以及流控。交换机还具备了一些新的功能,如对VLAN(虚拟局域网)的支持、对链路汇聚的支持,甚至有的还具有防火墙的功能。 交换机除了能够连接同种类型…...

每天五分钟机器学习:凸集
本文重点 在SVM中,目标函数是一个凸函数,约束集合是一个凸集。因此,SVM问题可以转化为一个凸规划问题来求解。这使得SVM在实际应用中具有较高的计算效率和准确性。 凸集的定义 凸集是指一个集合中的任意两点之间的线段都完全包含在这个集合中。换句话说,给定集合C中的两…...

Mongodb日志报错too many open files,导致mongod进程down
【解决方案】 (1)进入到服务器,执行: ulimit -a 查看:open files这一行的数量,如果查询到的结果是1000左右,那多半是服务器限制。 (2)在当前session窗口执行如下&…...

关于 PCB线路板细节锣槽问题 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/144783817 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

硬件基础知识笔记(2)——二级管、三极管、MOS管
Part 2 二级管、三极管、MOS管 1、二级管1.1肖特基二极管和硅二极管选型比较1.2到底是什么决定了二极管的最高工作频率?1.3二极管结电容和反向恢复时间都是怎么来的 1、二级管 1.1肖特基二极管和硅二极管选型比较 肖特基二极管的优势主要在速度和压降,对…...

软件测试之非功能测试设计
非功能测试设计 非功能:除了软件功能测试,其他都是非功能测试。 1.兼容 2.易用 3.性能(专项) 4.安全(专项) Web浏览器 兼容:Chrome浏览器、Edge浏览器、Firefox浏览器、Safari苹果浏览器 易用:参考竞品,主观感受为主 总结 1.非功能测试范围 兼容性、…...

GPU 英伟达GPU架构回顾
1999 年,英伟达发明了 GPU(graphics processing unit),本节将介绍英伟达 GPU 从 Fermi 到 Blackwell 共 9 代架构,时间跨度从 2010 年至 2024 年,具体包括费米(Feimi)、开普勒&#…...

机器学习 - 线性回归
线性回归模型的定义 线性回归(Linear Regression)的目标旨在找到可以描述目标值(输出变量)与一个或多个特征(输入变量)之间关系的一个线性方程或函数。 线性回归模型的表达式为 线性回归模型表达式的“齐次…...

NestJS 性能优化:从应用到部署的最佳实践
在上一篇文章中,我们介绍了 NestJS 的微服务架构实现。本文将深入探讨 NestJS 应用的性能优化策略,从应用层到部署层面提供全方位的优化指南。 应用层优化 1. 路由优化 // src/modules/users/users.controller.ts import { Controller, Get, UseInter…...

本地快速推断的语言模型比较:Apple MLX、Llama.cpp与Hugging Face Candle Rust
本地快速推断的语言模型比较:Apple MLX、Llama.cpp与Hugging Face Candle Rust 在自然语言处理(NLP)部署中,推断速度是一个关键因素,尤其是对于支持大型语言模型(LLM)的应用来说。随着Apple M1…...

您的公司需要小型语言模型
当专用模型超越通用模型时 “越大越好”——这个原则在人工智能领域根深蒂固。每个月都有更大的模型诞生,参数越来越多。各家公司甚至为此建设价值100亿美元的AI数据中心。但这是唯一的方向吗? 在NeurIPS 2024大会上,OpenAI联合创始人伊利亚…...

智能工厂的设计软件 应用场景的一个例子:为AI聊天工具添加一个知识系统 之14 方案再探 之5:知识树三类节点对应的三种网络形式及其网络主机
本文要点 前面讨论过(前面有错这里做了修正),三种簿册归档 对应通过不同的网络形式(分布式、对等式和去中心式)。每种网络主机上分别提供: 分布式控制脚本、 对等式账本 和 备记手本 通过以上讨论&#x…...

JR-RLAA系20路模拟音频多功能编码器
JR-RLAA系20路模拟音频多功能编码器 产品特色 (1)工业级19英寸标准设备,内置双电源 (2)内嵌Web Server,支持远程Web页面登陆后的统一配置操作 (3)支持20路音频输入 (4)支持Dolby Digital(AC-3) ,MPEG-2,AAC-LC/HE-AAC&#x…...

基于RK3588核心板的智能无人机系统:从异构计算到实时控制的全栈实践
1. 项目概述:为什么选择RK3588作为无人机的大脑?在无人机这个领域里待了十几年,从早期的飞控板加一个简单的单片机,到后来用树莓派做视觉处理,再到如今追求全栈式的自主飞行能力,我深刻感受到主控平台的选择…...

怎样给照片去背景?2026 图片抠图方法对比|免费在线工具实测
在日常生活中,我们经常需要给照片去背景——无论是制作证件照、电商商品图、社交媒体头像,还是创意合成,去背景都是最基础的图像处理需求。但面对五花八门的工具和方法,很多人不知道如何选择。本文将从多个维度全面对比 2026 年主…...

2026年降AI工具维普检测专项实测:五款主流工具维普AIGC检测通过率完整横评
2026年降AI工具维普检测专项实测:五款主流工具维普AIGC检测通过率完整横评 拿同一篇论文,用三款工具分别处理,记录了完整检测数据。 结论先说:嘎嘎降AI(www.aigcleaner.com)效果最稳,价格也最…...

Godot-MCP终极指南:如何用AI助手5倍提升Godot游戏开发效率
Godot-MCP终极指南:如何用AI助手5倍提升Godot游戏开发效率 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP 在…...

网盘直链解析助手:一站式解决多平台文件下载难题
网盘直链解析助手:一站式解决多平台文件下载难题 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...
不加真不行)
别再踩坑了!Vue2项目里用Swiper5.4.5做轮播,这几个配置项(observer/observeParents)不加真不行
Vue2项目中Swiper5.4.5轮播图动态适配避坑指南 轮播图作为现代Web应用中最常见的交互组件之一,几乎成为每个前端项目的标配。在Vue2生态中,Swiper凭借其丰富的功能和灵活的配置,成为开发者实现轮播效果的首选库。然而,许多初中级开…...
)
保姆级教程:在Ubuntu上配置Lotus基准测试环境(含参数下载与自定义GPU支持)
在Ubuntu上配置Lotus基准测试环境的完整指南 对于Filecoin生态系统的参与者来说,理解网络性能并优化硬件配置至关重要。本文将带您完成在Ubuntu系统上搭建Lotus基准测试环境的全过程,从基础环境准备到高级GPU自定义支持,为您提供一份详尽的实…...

如何用QKeyMapper实现Windows键鼠手柄自由映射:免费开源终极指南
如何用QKeyMapper实现Windows键鼠手柄自由映射:免费开源终极指南 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&…...

ROS2进阶实践 -- 从零构建模块化差速机器人模型 -- 掌握xacro宏定义与参数化设计
1. 为什么需要xacro宏定义与参数化设计 当你第一次用URDF给机器人建模时,可能会觉得这种XML格式的描述方式很直观。但随着模型复杂度提升,问题就来了——我最近给一个差速机器人添加传感器时,发现URDF文件膨胀到了500多行,其中光是…...

第二章:Compose入门—声明式UI编程
第二章:Compose 入门 — 声明式 UI 编程 Compose 的核心理念:用 Kotlin 代码声明 UI,而不是用 XML 布局文件。 2.1 传统 View 系统 vs Compose 对比项传统 View 系统Jetpack ComposeUI 描述XML 布局文件Kotlin 代码状态更新findViewById 手…...