Sqoop的使用
每个人的生活都是一个世界,即使最平凡的人也要为他那个世界的存在而战斗。
——《平凡的世界》
目录
一、sqoop简介
1.1 导入流程
1.2 导出流程
二、使用sqoop
2.1 sqoop的常用参数
2.2 连接参数列表
2.3 操作hive表参数
2.4 其它参数
三、sqoop应用 - 导入
3.1 准备测试数据
3.2 sqoop查看数据
3.3 创建Hive表
3.4 多map条件查询导入HDFS
3.5 全量导入数据
3.6 增量数据导入
四、sqoop应用 - 导出
4.1 Hive中数据导出到MySQL中
五、总结
一、sqoop简介
sqoop是Apache旗下的一款 hadoop和关系型数据库服务器之间传送数据 的工具
主要的功能:
- 导入数据
- MySQL、Oracle(关系型数据库)导入数据到hadoop的HDFS、Hive以及Hbase等数据存储系统
- 导出数据
- 从Hadoop的文件系统(HDFS等)中导出数据到关系型数据库(MySQL、PostgreSQL)中

1.1 导入流程
1. 首先通过JDBC读取关系型数据库元数据信息,获取到表结构2. 根据元数据信息生成Java类3. 启动import程序,通过JDBC读取关系型数据库数据,并通过上一步的Java类进行序列化4. MapReduce并行写数据到Hadoop中,并使用Java类进行反序列化
1.2 导出流程
1.sqoop通过JDBC读取关系型数据库元数据,获取到表结构信息,生成Java类2.MapReduce并行读取HDFS数据,并且通过Java类进行序列化3.export程序启动,通过Java类反序列化,同时启动多个map任务,通过JDBC将数据写入到关系型数据库中
二、使用sqoop
环境:CDH 6.2.1
快速体验sqoop
# 前提是你已经下载好了sqoop
# 直接在命令行中输入以下命令(这个命令类似于你在MySQL中执行 show databases;)
# 格式:sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username 用户名 --password 密码
sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password 123456

# 查询指定库下面所有表(这个命令类似于你在MySQL中指定库后执行 show tables;)
# 格式:sqoop list-tables --connect jdbc:mysql://localhost:3306/库名 --username 用户名 --password 密码
sqoop list-tables --connect jdbc:mysql://localhost:3306/ecut --username root --password 123456

2.1 sqoop的常用参数
- 指令
sqoop 命令选项 参数
| 命令名称 | 对应类 | 命令说明 |
|---|---|---|
| import | ImportTool | 将关系型数据库数据导入到HDFS、HIVE、HBASE |
| export | ExportTool | 将HDFS上的数据导出到关系型数据库 |
| codegen | CodeGenTool | 获取数据库中某张表数据生成Java并打成Jar包 |
| create-hive-table | CreateHiveTableTool | 创建hive的表 |
| eval | EvalSqlTool | 查看SQL的执行结果 |
| list-databases | ListDatabasesTool | 列出所有数据库 |
| list-tables | ListTablesTool | 列出某个数据库下的所有表 |
| help | HelpTool | 打印sqoop帮助信息 |
| version | VersionTool | 打印sqoop版本信息 |
2.2 连接参数列表
| 参数 | 说明 |
|---|---|
| –connect | 连接关系型数据库的URL |
| –help | 打印帮助信息 |
| –username | 连接数据库的用户名 |
| –password | 连接数据库的密码 |
| –verbose | 在控制台打印出详细信息 |
2.3 操作hive表参数
| 参数 | 说明 |
|---|---|
| –hcatalog-database | 指定hive表的数据库名称。如果未指定,则使用默认数据库名称(default) |
| –hcatalog-table | 指定hive表名,该–hcatalog-table选项的存在表示导入或导出作业是使用HCatalog表完成的,并且是HCatalog作业的必需选项。 |
2.4 其它参数
| 参数 | 含义 |
|---|---|
| –num-mappers N | 指定启动N个map进程 |
| –table | 指定数据库表名 |
| –query | 编写sql语句,将查询的结果导入,如果查询中有where条件,则条件后必须加上conditions关键字。如果使用双引号包含sql,则condition关键字前要加上*$CONDITIONS* 以完成转义: |
| –target-dir | 指定HDFS路径 |
| –delete-target-dir | 若hdfs存放目录已存在,则自动删除 |
| –fields-terminated-by | 设置字段分隔符 |
| –export-dir | 导出到指定HDFS的目录路径 |
三、sqoop应用 - 导入
需求:使用sqoop上传字典表数据到hive中与我们的数据进行关联查询。
3.1 准备测试数据
- 在MySQL中创建测试数据(库名test_ecut,表名products,总共54条数据)
-- 在MySQL客户端或者图形化工具里执行下面代码
drop database if exists test_ecut;
create database if not exists test_ecut char set utf8;
use test_ecut; -- 使用该数据库create table test_ecut.products (id int auto_increment primary key,product_name varchar(255),price decimal(10, 2)
);-- 插入一些正常数据
insert into test_ecut.products (product_name, price) values ('商品A', 19.99);
insert into test_ecut.products (product_name, price) values ('商品B', 29.99);
insert into test_ecut.products (product_name, price) values ('商品C', 9.99);
insert into test_ecut.products (product_name, price) values ('商品D', 49.99);
insert into test_ecut.products (product_name, price) values ('商品E', 39.99);-- 插入一些包含空值的数据(这里假设price字段允许为空,实际需根据你的表结构定义来确定是否合理)
insert into test_ecut.products (product_name, price) values ('商品F', null);
insert into test_ecut.products (product_name, price) values ('商品G', null);-- 插入一些重复数据
insert into test_ecut.products (product_name, price) values ('商品A', 19.99);
insert into test_ecut.products (product_name, price) values ('商品B', 29.99);-- 继续插入更多不同情况的数据以凑够45条示例(以下为随机模拟更多数据情况)
insert into test_ecut.products (product_name, price) values ('商品H', 59.99);
insert into test_ecut.products (product_name, price) values ('商品I', 15.99);
insert into test_ecut.products (product_name, price) values ('商品J', 25.99);
insert into test_ecut.products (product_name, price) values ('商品K', 69.99);
insert into test_ecut.products (product_name, price) values ('商品L', 89.99);
insert into test_ecut.products (product_name, price) values ('商品M', null);
insert into test_ecut.products (product_name, price) values ('商品N', 35.99);
insert into test_ecut.products (product_name, price) values ('商品O', 45.99);
insert into test_ecut.products (product_name, price) values ('商品P', 79.99);
insert into test_ecut.products (product_name, price) values ('商品Q', 99.99);
insert into test_ecut.products (product_name, price) values ('商品R', 10.99);
insert into test_ecut.products (product_name, price) values ('商品S', 12.99);
insert into test_ecut.products (product_name, price) values ('商品T', 14.99);
insert into test_ecut.products (product_name, price) values ('商品U', 16.99);
insert into test_ecut.products (product_name, price) values ('商品V', 18.99);
insert into test_ecut.products (product_name, price) values ('商品W', 20.99);
insert into test_ecut.products (product_name, price) values ('商品X', 22.99);
insert into test_ecut.products (product_name, price) values ('商品Y', 24.99);
insert into test_ecut.products (product_name, price) values ('商品Z', 26.99);
insert into test_ecut.products (product_name, price) values ('商品AA', 28.99);
insert into test_ecut.products (product_name, price) values ('商品AB', 30.99);
insert into test_ecut.products (product_name, price) values ('商品AC', 32.99);
insert into test_ecut.products (product_name, price) values ('商品AD', 34.99);
insert into test_ecut.products (product_name, price) values ('商品AE', 36.99);
insert into test_ecut.products (product_name, price) values ('商品AF', 38.99);
insert into test_ecut.products (product_name, price) values ('商品AG', 40.99);
insert into test_ecut.products (product_name, price) values ('商品AH', 42.99);
insert into test_ecut.products (product_name, price) values ('商品AI', 44.99);
insert into test_ecut.products (product_name, price) values ('商品AJ', 46.99);
insert into test_ecut.products (product_name, price) values ('商品AK', 48.99);
insert into test_ecut.products (product_name, price) values ('商品AL', 50.99);
insert into test_ecut.products (product_name, price) values ('商品AM', 52.99);
insert into test_ecut.products (product_name, price) values ('商品AN', 54.99);
insert into test_ecut.products (product_name, price) values ('商品AO', 56.99);
insert into test_ecut.products (product_name, price) values ('商品AP', 58.99);
insert into test_ecut.products (product_name, price) values ('商品AQ', 60.99);
insert into test_ecut.products (product_name, price) values ('商品AR', 62.99);
insert into test_ecut.products (product_name, price) values ('商品AS', 64.99);
insert into test_ecut.products (product_name, price) values ('商品AT', 66.99);
insert into test_ecut.products (product_name, price) values ('商品AU', 68.99);
insert into test_ecut.products (product_name, price) values ('商品AV', 70.99);
insert into test_ecut.products (product_name, price) values ('商品AW', 72.99);
insert into test_ecut.products (product_name, price) values ('商品AX', 74.99);
insert into test_ecut.products (product_name, price) values ('商品AY', 76.99);
insert into test_ecut.products (product_name, price) values ('商品AZ', 78.99);select count(1) from test_ecut.products;

3.2 sqoop查看数据
- 可以借助sqoop中eval查看结果
# 通过eval查看:test_ecut库下的products表前5条数据
sqoop eval \
--connect jdbc:mysql://localhost:3306/test_ecut \
--username root \
--password 123456 \
--query "select * from products limit 5"

3.3 创建Hive表
前提:你需要启动hadoop集群(hdfs和yarn),以及hive服务(hiveserver2和metastore)
- 1:在hive中你需要先建库
-- 通过图形化工具(datagrip等),执行以下命令
create database hive_ecut;

- 2:使用create-hive-table创建hive表
# 基于MySQL表创建hive表
sqoop create-hive-table \
--connect jdbc:mysql://localhost:3306/test_ecut \
--username root \
--password 123456 \
--table products \
--hive-table hive_ecut.goods_table

- 3:然后通过datagrip工具,查看hive中是否存在表

3.4 多map条件查询导入HDFS
# 语法
sqoop import \
--connect 数据库连接字符串 \
--username 数据库用户名 \
--password 数据库密码 \
--target-dir HDFS位置 \
--delete-target-dir 若hdfs存放目录以及存在,则自动删除 \
--fields-terminated-by "\t" \
--num-mappers 3 \
--split-by 切分数据依据 \
--query 'select SQL where 查询条件 and $CONDITIONS'
解释:
query将查询结果的数据导入,使用时必须伴随参--target-dir或--hive-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字当
sqoop使用--query执行多个maptask并行运行导入数据时,每个maptask将执行一部分数据的导入,原始数据需要使用--split-by 某个字段'来切分数据,不同的数据交给不同的maptask去处理
maptask执行sql脚本时,需要在where条件中添加$CONDITIONS条件,这个是linux系统的变量,可以根据sqoop对边界条件的判断,来替换成不同的值,这就是说若split-by id,则sqoop会判断id的最小值和最大值判断id的整体区间,然后根据maptask的个数来进行区间拆分,每个maptask执行一定id区间范围的数值导入任务,如下为示意图。

- 1:导入文本文件
sqoop import \
--connect jdbc:mysql://localhost:3306/test_ecut"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 123456 \
--target-dir /user/hive/warehouse/hive_ecut.db/goods_table \
--delete-target-dir \
--fields-terminated-by "\001" \
--num-mappers 3 \
--split-by id \
--query 'select * from products where id < 10 and $CONDITIONS'

3.5 全量导入数据
补充: 导入数据可以分为两步
第一步,将数据导入到HDFS,默认的临时目录是/user/当前操作用户/mysql表名;
第二步,将导入到HDFS的数据迁移到Hive表,如果hive表不存在,sqoop会自动创建内部表;(我们的是在/user/root/products,通过查看job的configuration的outputdir属性得知)
第二步很重要,因为有时候报错并不是你的代码脚本问题,而是临时文件存在,在调度的时候运行的其实是临时文件中的配置job,需要删除才可以(.Trash和.staging 别删)

- 导入刚刚的商品数据,如果表不存在会自动创建内部表
# 导入命令
sqoop import \
--connect jdbc:mysql://localhost:3306/test_ecut"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 123456 \
--table products \
--num-mappers 1 \
--delete-target-dir \
--hive-import \
--fields-terminated-by "\001" \
--hive-overwrite \
--hive-table hive_ecut.goods_table_test

3.6 增量数据导入
增量数据导入的两种方法
方法1:append方式
方法2:lastmodified方式,必须要加–append(追加)或者–merge-key(合并,一般填主键)
- 1:按照id增量导入数据
-- MySQL添加一条新的数据
insert into test_ecut.products(product_name, price) values ('无敌绝世小学生',999999)

# 按照id增量导入
sqoop import \
--connect jdbc:mysql://localhost:3306/test_ecut"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 123456 \
--table products \
--num-mappers 1 \
--target-dir /user/hive/warehouse/hive_ecut.db/goods_table_test \
--fields-terminated-by "\001" \
--incremental append \
--check-column id \
--last-value 54
参数解释:
1)incremental:append或lastmodified,使用lastmodified方式导入数据要指定增量数据是要–append(追加)还是要–merge-key(合并)
2)check-column:作为增量导入判断的列名
3)last-value:指定某一个值,用于标记增量导入的位置,这个值的数据不会被导入到表中,只用于标记当前表中最后的值。(可以看到sqoop脚本中,我设置的id为54,也就意味着要跳过54而直接从55开始存)

- 2:按照时间增量导入数据
–incremental lastmodified
–append
–check-column 日期字段
在MySQL中重新建表,需要时间字段
-- mysql中新建products_update表
create table if not exists test_ecut.products_update(id int auto_increment primary key,product_name varchar(255),price decimal(10, 2),last_update_time datetime default current_timestamp on update current_timestamp
);
insert into test_ecut.products_update (product_name, price) values ('商品H', 59.99);
insert into test_ecut.products_update (product_name, price) values ('商品I', 15.99);
insert into test_ecut.products_update (product_name, price) values ('商品J', 25.99);

导入数据到hive中
# 在命令行中执行,然后在datagrip中查看数据
sqoop import \
--connect jdbc:mysql://localhost:3306/test_ecut"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 123456 \
--table products_update \
--num-mappers 1 \
--delete-target-dir \
--hive-import \
--fields-terminated-by "\001" \
--hive-overwrite \
--hive-table hive_ecut.goods_update_table

隔一段时间,新增一条数据
-- 在MySQL中,新增
insert into test_ecut.products_update (product_name, price) values ('无敌绝世小学生', 999999);

增量导入更新的数据
# 在命令行中执行,在datagrip中查看
sqoop import \
--connect jdbc:mysql://localhost:3306/test_ecut"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 123456 \
--table products_update \
--num-mappers 1 \
--target-dir /user/hive/warehouse/hive_ecut.db/goods_update_table \
--fields-terminated-by "\001" \
--incremental lastmodified \
--check-column last_update_time \
--last-value '2024-12-28 13:18:00' \
--append# 注意:last-value 的设置是把包括 2024-12-28 13:18:00 时间的数据做增量导入。(所以我给2024-12-28 13:17:59加了1秒)

- 3:按照时间增量并按照主键合并导入
–incremental lastmodified
–merge-key 用法
如果之前的数据有修改的话可以使用–incremental lastmodified --merge-key进行数据合并执行修改的SQL
更改字段,从而更新时间
-- 在MySQL中更新
update test_ecut.products_update set product_name = '萌神想' where product_name='无敌绝世小学生';

进行合并导入(如果报错,可能是因为/user/root/_sqoop存在了很多临时文件,需要删除这些临时文件)
sqoop import \
--connect jdbc:mysql://localhost:3306/test_ecut"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 123456 \
--table products_update \
--num-mappers 1 \
--target-dir /user/hive/warehouse/hive_ecut.db/goods_update_table \
--fields-terminated-by "\001" \
--incremental lastmodified \
--check-column last_update_time \
--last-value '2024-12-28 13:20:24' \
--merge-key id# --incremental lastmodified --merge-key的作用:修改过的数据和新增的数据(前提是满足last-value的条件)都会导入进来,并且重复的数据(不需要满足last-value的条件)都会进行合并

四、sqoop应用 - 导出
4.1 Hive中数据导出到MySQL中
sqoop的export命令支持 insert、update到关系型数据库,但是不支持merge
- 1:查看需要导出表的数据

- 2:新建MySQL表用于接收hive中的数据
create table if not exists test_ecut.get_hive_data(id int auto_increment primary key,product_name varchar(255),price decimal(10, 2),last_update_time datetime default current_timestamp on update current_timestamp
);
- 3:导出到MySQL中
# 导出命令
sqoop export \
--connect jdbc:mysql://localhost:3306/test_ecut"?useUnicode=true&characterEncoding=UTF-8" \
--username root \
--password 123456 \
--table get_hive_data \
--export-dir /user/hive/warehouse/hive_ecut.db/goods_update_table \
--num-mappers 1 \
--fields-terminated-by '\001'

补充:sqoop的作用就是负责导入和导出的,我上面所写的虽然都在虚拟机上运行,但只要改一下localhost就可以实现不同主机之间的数据传输(前提是有映射,且可以互通)
五、总结
看完上面的操作之后,很容易发现一个特点,Sqoop其实就是个脚本,而且命令很固定,只需改改参数就可以使用,门槛并不高,能用就行,具体它底层怎么实现的,可以去官网看看(Sqoop已经不更新,虽然是apache的项目,但已经被打入冷宫了),值得一提的是,Sqoop 通常只会使用 Map 任务来完成数据的传输,不会启动 Reduce 任务
相关文章:
Sqoop的使用
每个人的生活都是一个世界,即使最平凡的人也要为他那个世界的存在而战斗。 ——《平凡的世界》 目录 一、sqoop简介 1.1 导入流程 1.2 导出流程 二、使用sqoop 2.1 sqoop的常用参数 2.2 连接参数列表 2.3 操作hive表参数 2.4 其它参数 三、sqoop应用 - 导入…...

OpenGL ES 04 图片数据是怎么写入到对应纹理单元的
从指定路径加载图像并转换为 CGImage。获取图像的宽度和高度。创建一个 RGB 颜色空间。为图像数据分配内存。创建一个位图上下文并将图像绘制到上下文中。创建一个新的纹理对象并绑定到指定的纹理单元。指定二维纹理图像。释放分配的内存。设置纹理参数,包括放大和缩…...
)
C# 设计模式的六大原则(SOLID)
C# 设计模式的六大原则(SOLID) 引言 在面向对象编程中,设计模式提供了高效、可复用和可维护的代码结构。SOLID原则是软件设计中的一组重要原则,用于确保代码具有良好的可维护性、可扩展性和灵活性。SOLID是五个设计原则的首字母…...

数据库自增 id 过大导致前端时数据丢失
可以看到,前端响应参数是没有丢失精度的 但是在接受 axios 请求参数时出现了精度丢失 解决方案一:改变 axios 字符编码 axios.defaults.headers[Content-Type] application/json;charsetUTF-8; 未解决 解决方案二:手动使用 json.parse() …...
词嵌入(Word2Vec、GloVe))
第二十六天 自然语言处理(NLP)词嵌入(Word2Vec、GloVe)
自然语言处理(NLP)中的词嵌入(Word2Vec、GloVe)技术,是NLP领域的重要组成部分,它们为词汇提供了高维空间到低维向量的映射,使得语义相似的词汇在向量空间中的距离更近。以下是对这些技术的详细解…...

MongoDB 固定集合
MongoDB 固定集合 MongoDB中的固定集合(Capped Collections)是一种具有固定大小的集合,当集合中的数据达到其最大大小时,它会自动覆盖最早的文档。这种类型的集合在MongoDB中用于实现高效的、固定大小的循环缓冲区。本文将详细介…...

数据结构9.3 - 文件基础(C++)
目录 1 打开文件字符读写关闭文件 上图源自:https://blog.csdn.net/LG1259156776/article/details/47035583 1 打开文件 法 1法 2ofstream file(path);ofstream file;file.open(path); #include<bits/stdc.h> using namespace std;int main() {char path[]…...

Leetcode 1254 Number of Closed Islands + Leetcode 1020 Number of Enclaves
Leetcode 1254 题意 给定一个m*n的矩阵含有0和1,1代表水,0代表陆地,岛屿是陆地的集合,如果一个岛屿和四个方向的边界相连,则不算封闭岛屿。求有多少个封闭的岛屿。 题目链接 https://leetcode.com/problems/number…...

Junit4单元测试快速上手
文章目录 POM依赖引入业务层测试代码Web层测试代码生成测试类文件 在工作中我用的最多的单元测试框架是Junit4。通常在写DAO、Service、Web层代码的时候都会进行单元测试,方便后续编码,前端甩锅。 POM依赖引入 <dependency><groupId>org.spr…...

U盘提示格式化?原因、恢复方案与预防措施全解析
一、U盘提示格式化现象概述 在日常使用U盘的过程中,我们有时会遇到一个令人头疼的问题——U盘插入电脑后,系统却弹出一个提示框,告知我们U盘需要格式化才能访问。这个提示往往伴随着数据的潜在丢失风险,让我们不禁为之心焦。U盘提…...

HTML——13.超链接
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title>超链接</title></head><body><!--超链接:从一个网页链接到另一个网页--><!--语法:<a href"淘宝网链接的地址"> 淘宝…...

vue中的设计模式
vue中使用了哪些设计模式 1. 观察者模式(Observer Pattern) 应用场景:Vue 的响应式系统核心就是观察者模式。 实现方式:通过 Object.defineProperty 或 Proxy 监听数据变化,当数据发生变化时,通知依赖的视…...

利用python将图片转换为pdf格式的多种方法,实现批量转换,内置模板代码,全网最全,超详细!!!
文章目录 前言1、img2pdf库的使用1.1 安装img2pdf库1.2 案例演示(模板代码) 2、Pillow库的使用2.1 pillow库的安装2.2 案例演示(模板代码) 3、PyMuPDF库的使用3.1 安装pymupdf库3.2 案例演示(模板代码)3.3 …...

tcpdump的常见方法
详解tcpdump的使用方法:网络数据包捕获与分析 tcpdump是一个功能强大的命令行工具,用于捕获和分析通过网络接口传输的数据包。它广泛应用于网络故障诊断、网络安全监控和协议分析等领域。本文将详细介绍tcpdump的使用方法,包括安装、基本命令…...
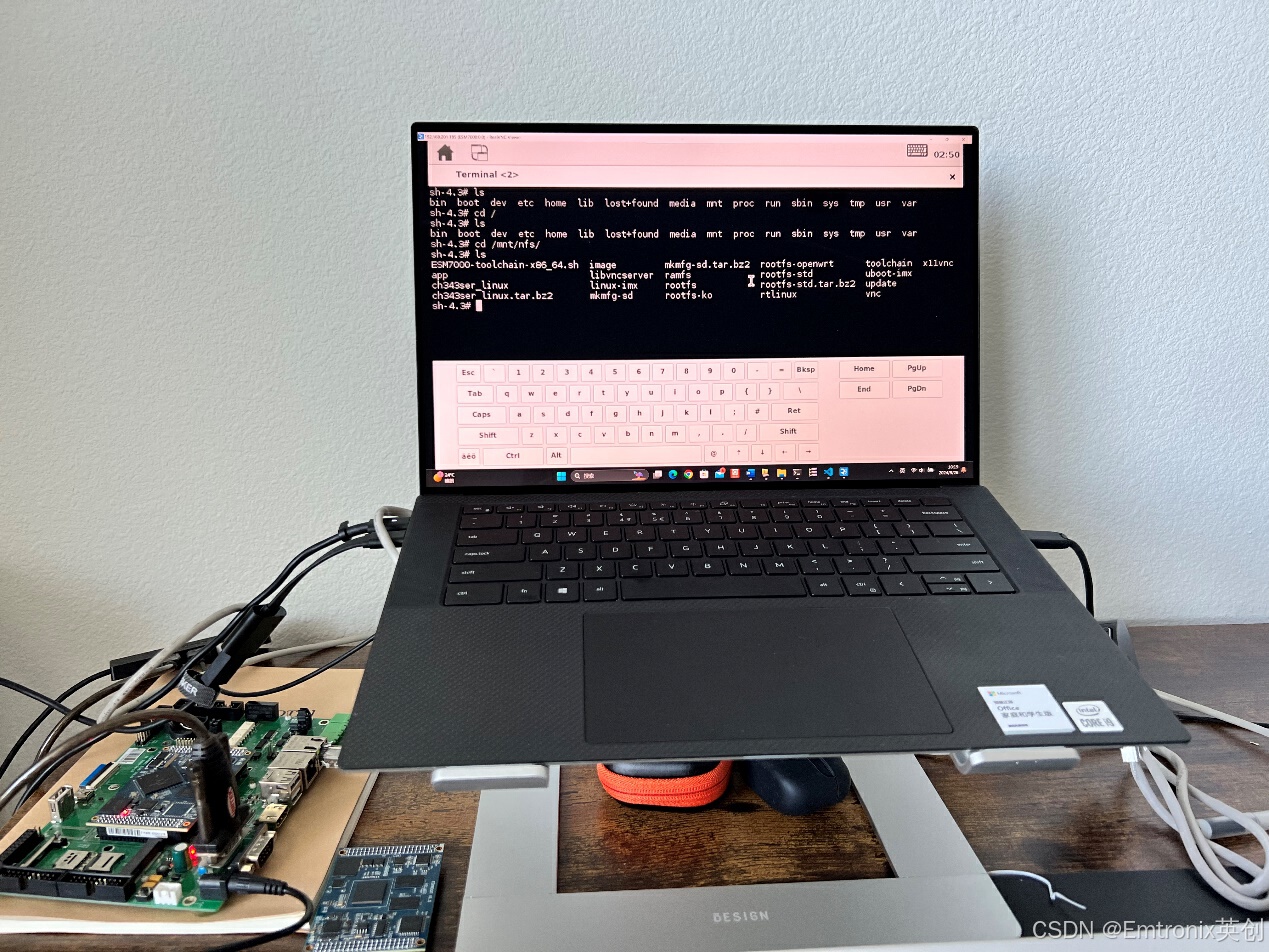
工控主板ESM7000/6800E支持远程桌面控制
英创公司ESM7000 是面向工业领域的双核 Cortex-A7 高性能嵌入式主板,ESM6800E则为单核Cortex-A7 高性价比嵌入式主板,ESM7000、ESM6800E都是公司的成熟产品,已广泛应用于工业很多领域。ESM7000/6800E板卡中Linux系统配置为linux-4.9.11内核、…...

wamp php7.4 运行dm8
背景 1、电脑安装了dm8,具体参照官网dm8安装 2、安装好了wamp,我当前的php版本切换成了7.4的,我wamp的安装路径d:\wamp64\ 操作 3、查看phpinfo,如果Thread Safet为enabled,则选择pdo74_dm.dll,否则选择…...
详解)
HTML5 进度条(Progress Bar)详解
HTML5 进度条(Progress Bar)详解 进度条是用于显示任务完成进度的控件,常用于加载、上传或下载等操作。HTML5提供了原生的<progress>元素,使得创建进度条变得简单和直观。 1. 基本用法 <progress>元素的基本语法如…...

LabVIEW开发中常见硬件通讯接口快速识别
在 LabVIEW 开发中,与硬件进行通讯是实现数据采集与控制的重要环节。准确判断通讯接口类型和协议,可以提高开发效率,减少调试时间。本文结合 LabVIEW 的实际应用,详细介绍如何识别和判断常见硬件通讯接口的定义,并提供…...

高频 SQL 50 题(基础版)_1068. 产品销售分析 I
销售表 Sales: (sale_id, year) 是销售表 Sales 的主键(具有唯一值的列的组合)。 product_id 是关联到产品表 Product 的外键(reference 列)。 该表的每一行显示 product_id 在某一年的销售情况。 注意: price 表示每…...

笔记:一次mysql主从复制延迟高的处理尝试
背景 mysql 5.7 主从复制 主库进行了一次灌数,导致多个大事务产生,主从延迟下不去,经确认该表最终truncate,并且该表仅有insert和select操作,故对该表的事务进行跳过,直到同步至truncate 跳过事务需谨慎&…...
)
用Keras和MNIST数据集,5分钟搞定一个图像去噪的CNN自编码器(附完整代码)
5分钟实战:用Keras构建图像去噪自编码器的极简指南 当一张布满噪点的老照片在AI处理后重现清晰画面时,这种"数字魔法"背后往往是自编码器在发挥作用。作为深度学习领域的瑞士军刀,自编码器不仅能用于图像去噪,还在数据压…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

终极Python通达信数据解析方案:mootdx完整使用指南与金融量化实践
终极Python通达信数据解析方案:mootdx完整使用指南与金融量化实践 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易领域,通达信作为国内主流的证券…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

TPU柔性材料3D打印GoPro车载支架:从减震原理到实战拍摄全指南
1. 项目概述与设计思路我一直对第一人称视角(FPV)拍摄很着迷,尤其是那种能贴着地面、模拟小车视角疾驰的画面,动态感和沉浸感是手持拍摄无法比拟的。市面上的运动相机车载支架要么是硬连接,颠簸起来画面抖动得厉害&…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

基于HalloWing的交互式徽章:传感器融合与事件驱动编程实践
1. 项目概述:当硬件开发遇上节日创意如果你和我一样,是个喜欢在万圣节搞点“技术流”小把戏的硬件爱好者,那么手头有一块Adafruit的HalloWing开发板,绝对能让你的节日装备脱颖而出。这不仅仅是一个简单的微控制器项目,…...