Kafka 快速实战及基本原理详解解析-01
一、Kafka 介绍
1. MQ 的作用
消息队列(Message Queue,简称 MQ)是一种用于跨进程通信的技术,核心功能是通过异步消息的方式实现系统之间的解耦。它在现代分布式系统中有着广泛的应用,主要作用体现在以下三个方面:
异步处理
在传统的同步调用中,生产者和消费者需要同时在线,并且生产者在完成任务后才能继续执行其他工作。这种模式限制了系统的性能。而引入消息队列后,生产者可以将任务提交到队列中,消费者按需消费任务,从而提升系统的吞吐量。
- 示例:快递员送快递到客户家,效率低下。而菜鸟驿站的出现让快递员只需将包裹放置在驿站,客户可以根据自己的时间安排取件。这种方式大大提高了效率。
解耦
解耦是消息队列最重要的功能之一。服务之间通过消息队列传递数据,而不是直接调用对方的服务接口,这样可以有效降低系统的耦合度。
- 示例:《Thinking in JAVA》原书是英文版,但通过翻译社将内容翻译成多种语言,满足不同读者的需求。翻译社起到了桥梁作用,不同语言之间的沟通不再直接依赖于作者和读者。
削峰填谷
在高并发场景下,系统往往会遇到流量高峰,导致系统负载过重。通过消息队列,可以将流量暂存并按固定速率处理,从而避免系统崩溃。
- 示例:长江每年都会涨水,但通过三峡大坝的调节,下游的出水速度保持稳定,避免了洪水泛滥。
2. 为什么要用 Kafka
Kafka 是一种高吞吐量、低延迟、分布式的消息队列系统,适合在大规模数据处理场景中使用。以下是 Kafka 的典型使用场景和优势:
日志聚合场景
在大规模分布式系统中,各个服务都会产生大量的日志信息。传统的日志收集方式往往存在以下问题:
- 数据量大:需要快速收集和处理来自各个渠道的海量日志。
- 容错性要求高:集群中允许少量节点出现故障而不影响整体服务。
- 功能专注:Kafka 专注于高吞吐量、低延迟的消息传递,不追求复杂的消息处理功能。
核心优势
- 高吞吐量:Kafka 能够处理数百万 TPS(每秒事务处理量)。
- 低延迟:通常在毫秒级别的延迟时间内完成消息传递。
- 可扩展性:通过增加节点和分区数量,可以线性扩展处理能力。
- 容错性:通过副本机制保证消息的高可用性。
- 持久化:Kafka 使用磁盘存储消息,保证消息的持久性。
二、Kafka 快速上手
1. 实验环境准备
要快速上手 Kafka,首先需要搭建实验环境。以下是推荐的实验环境配置:
- 虚拟机数量:3 台
- 操作系统:CentOS 7
- Java 版本:Java 8
环境配置步骤
- 下载 Kafka 和 Zookeeper。
- 将 Kafka 解压到
/app/kafka目录,将 Zookeeper 解压到/app/zookeeper目录。 - 配置环境变量,确保系统能够识别 Kafka 和 Zookeeper 的命令。
- 关闭防火墙,以避免端口阻塞:
systemctl stop firewalld.service
2. 单机服务体验
为了更直观地理解 Kafka 的工作原理,我们可以先体验单机版 Kafka 服务。
步骤 1:启动 Zookeeper
Kafka 依赖 Zookeeper 进行元数据管理和选举机制。在实际部署中,通常使用独立的 Zookeeper 集群。
启动 Zookeeper 服务:
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
检查 Zookeeper 是否正常启动:
jps
确认输出中有 QuorumPeerMain 进程。
步骤 2:启动 Kafka
启动 Kafka 服务前,需要确保 Zookeeper 服务正常运行。
启动 Kafka 服务:
nohup bin/kafka-server-start.sh config/server.properties &
确认 Kafka 是否正常启动:
jps
检查输出中是否包含 Kafka 进程。
步骤 3:创建和使用 Topic
Kafka 的基础工作机制是通过 Topic 进行消息的传递。
-
创建 Topic
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 -
发送消息 启动生产者端并发送消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test > 这是一条测试消息 -
消费消息 启动消费者端并接收消息:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
3. 理解 Kafka 的消息传递机制
Kafka 的消息传递机制可以通过以下核心组件来理解:
- 生产者(Producer):将消息发送到指定的 Topic。
- 消费者(Consumer):从指定的 Topic 消费消息。
- Topic:逻辑概念,表示一类业务消息的集合。
- Partition:物理概念,实际存储消息的分区。
- Broker:Kafka 服务器实例,存储和管理 Partition。
Kafka 的设计目标是通过这些组件实现高效、可靠的消息传递,满足企业级数据管道的需求。
四、Kafka 集群服务
1. 为什么要使用集群
单机部署的 Kafka 在性能上虽然已经非常出色,但在实际生产环境中通常需要使用 Kafka 集群来进一步提升数据存储能力和系统的高可用性。集群可以解决以下问题:
1.1 解决海量数据存储问题
单个 Broker 服务器的存储能力有限,当数据量增长到一定程度时,单机难以承载。通过集群部署,可以将数据分散存储在多个 Broker 中,从而提升整体存储能力。
1.2 提高系统容错能力
单机环境中,如果 Broker 崩溃,所有数据都会丢失。而集群环境下,每个 Partition 都有多个副本,即使部分 Broker 节点宕机,系统依然可以正常运行,保证数据的高可用性。
五、理解服务端的 Topic、Partition 和 Broker
Kafka 的核心架构由 Topic、Partition 和 Broker 组成,这三者之间的关系至关重要:
- Topic:一个逻辑的消息分类,每个 Topic 包含多条消息。
- Partition:每个 Topic 可以分成多个 Partition,每个 Partition 是一个消息队列。
- Broker:Kafka 的服务器实例,负责存储 Partition 数据,并处理客户端请求。
5.1 创建分布式 Topic 示例
bin/kafka-topics.sh --bootstrap-server worker1:9092 --create --replication-factor 2 --partitions 4 --topic distributedTopic
5.2 查看 Topic 信息
bin/kafka-topics.sh --bootstrap-server worker1:9092 --describe --topic distributedTopic
六、章节总结:Kafka 集群的整体结构
通过前面的学习,我们可以总结 Kafka 集群的整体结构:
- Topic 是逻辑概念,Producer 和 Consumer 通过 Topic 进行消息传递。
- Partition 是实际存储单元,保证数据分散存储和负载均衡。
- Broker 是 Kafka 的服务器实例,存储 Partition 数据并处理客户端请求。
- Zookeeper 管理 Kafka 集群的元数据和选举过程。
- Controller 是 Kafka 集群的核心管理节点,负责管理 Topic 和 Partition 的分配。
七、Spring Boot 实现 Kafka 消息有序性
为了保证 Kafka 的消息有序性,可以使用 Spring Boot 和 Kafka 的整合来实现。在 Java 的 Spring Boot 项目中,我们通过指定消息的 Key 和自定义分区器来确保消息发送到相同的 Partition,从而实现有序性。
7.1 依赖配置
在 Maven 项目中,引入 Kafka 的依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-kafka</artifactId>
</dependency>
7.2 配置 KafkaProducer
创建 Kafka 的生产者配置类:
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;import java.util.HashMap;
import java.util.Map;@Configuration
public class KafkaProducerConfig {@Beanpublic ProducerFactory<String, String> producerFactory() {Map<String, Object> configProps = new HashMap<>();configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);return new DefaultKafkaProducerFactory<>(configProps);}@Beanpublic KafkaTemplate<String, String> kafkaTemplate() {return new KafkaTemplate<>(producerFactory());}
}
7.3 发送有序消息
创建一个消息发送服务,确保消息使用相同的 Key 发送到同一个 Partition:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;@Service
public class KafkaProducerService {private static final String TOPIC = "test_topic";@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String key, String message) {kafkaTemplate.send(TOPIC, key, message);}
}
7.4 自定义分区器(可选)
如果有更复杂的分区逻辑,可以自定义分区器:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;import java.util.Map;public class CustomPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 自定义分区逻辑return Math.abs(key.hashCode()) % cluster.partitionCountForTopic(topic);}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
7.5 设置一个 Topic 对应一个 Partition 的方法
如果业务需求是保证某个 Topic 的消息全局有序,可以在创建 Topic 时将 Partition 数量设置为 1,从而保证所有消息存储在同一个 Partition 中,实现全局有序。
创建一个 Partition 的 Topic
bin/kafka-topics.sh --create --topic singlePartitionTopic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
在 Spring Boot 中发送消息到该 Topic
@Service
public class KafkaSinglePartitionProducerService {private static final String TOPIC = "singlePartitionTopic";@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String message) {kafkaTemplate.send(TOPIC, message);}
}
通过这种方式,所有发送到 singlePartitionTopic 的消息都会进入同一个 Partition,确保消息顺序性。
相关文章:

Kafka 快速实战及基本原理详解解析-01
一、Kafka 介绍 1. MQ 的作用 消息队列(Message Queue,简称 MQ)是一种用于跨进程通信的技术,核心功能是通过异步消息的方式实现系统之间的解耦。它在现代分布式系统中有着广泛的应用,主要作用体现在以下三个方面&…...

wujie无界微前端框架初使用
先说一下项目需求:将单独的四套系统的登录操作统一放在一个入口页面进行登录,所有系统都使用的是vue3,(不要问我为啥会这样设计,产品说的客户要求) 1.主系统下载wujie 我全套都是vue3,所以直接…...
)
C++ 设计模式:职责链模式(Chain of Responsibility)
链接:C 设计模式 链接:C 设计模式 - 组合模式 链接:C 设计模式 - 迭代器模式 职责链模式(Chain of Responsibility Pattern)是一种行为型设计模式,它允许多个对象都有机会处理请求,从而避免请求…...

Yocto项目 - 详解PACKAGECONFIG机制
引言 Yocto项目是一个强大的嵌入式Linux开发工具,广泛应用于创建定制的嵌入式Linux发行版。在Yocto中,配置和定制化构建系统、软件包、以及生成适用于特定硬件的平台镜像是非常重要的。PACKAGECONFIG是Yocto项目中用于灵活启用或禁用软件包特性的强大工…...

Linux下部署ElasticSearch集群
Elasticsearch7.17.8集群的搭建 节点host名称节点ip节点部署内容k8s-m192.168.40.142主节点 数据节点k8s-w1192.168.40.141主节点 数据节点k8s-w2192.168.40.140数据节点 一、准备安装环境 1.下载安装包 官网 www.elastic.co 下载所有版本地址 点击跳转 下载elasticsearch-7.…...

超高分辨率 图像 分割处理
文章大纲 制造业半导体领域高分辨率图像半导体数据集开源的高分辨率晶圆图像数据集1. WM-811K数据集2. Kaggle上的WM-811K Clean Subset数据集医疗 病理领域高分辨率图像1. Camelyon+2. CAMELYON173. CPIA Dataset4. UCF-WSI-Dataset航拍 遥感中的高分辨率 图像航拍遥感领域高分…...
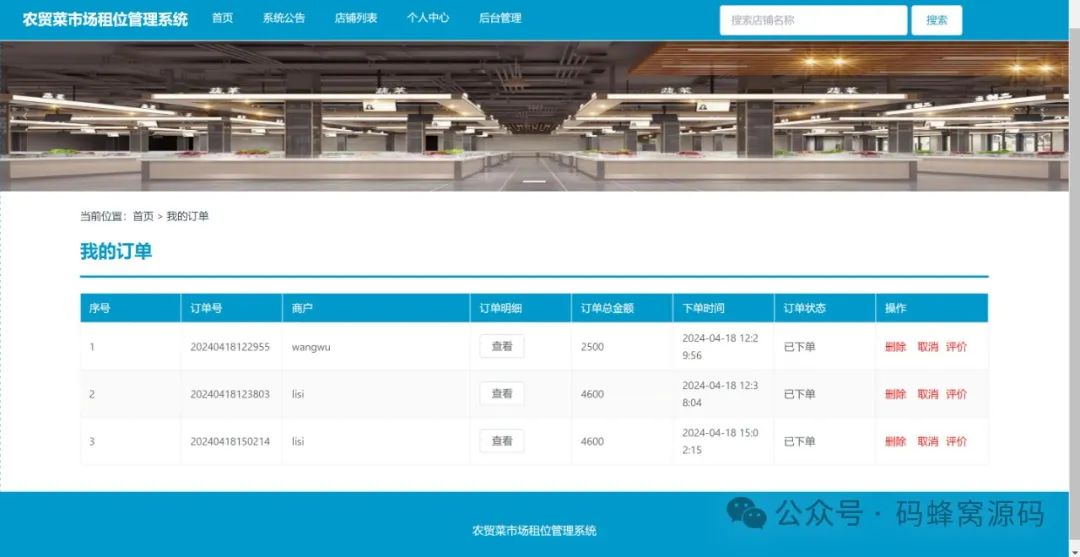
【含文档+PPT+源码】基于springboot的农贸菜市场租位管理系统的设计与实现
开题报告 本文旨在探讨基于SpringBoot框架构建的农贸菜市场租位管理系统的设计与实现。系统结合了现代化信息技术与农贸市场管理需求,为用户提供了注册登录、查看系统公告、分类搜索店铺、查看店铺详情、填写租赁信息、在线租赁、我的订单管理以及用户信息和密码修…...

信息科技伦理与道德1:绪论
1 问题描述 1.1 信息科技的进步给人类生活带来的是什么呢? 功能?智能?陪伴?乐趣?幸福? 基于GPT-3的对话Demo DeepFake 深伪技术:通过神经网络技术进行大样本学习,将个人的声音、面…...

Linux实验报告15-添加系统调用
目录 一:实验目的 二:实验内容 (1)查看系统内核版本 (2)安装内核版本源码 (3)修改注册表 (4)添加系统调用头文件 (5)实现系统调…...

logback之配置文件使用详解
目录 (一)配置文件的加载 (二)使用介绍 1、configuration:配置文件的跟元素 2、contextName:设置日志上下文名称 3、contextListener:设置上下文监听事件 4、property/variable/substituti…...

壁纸样机神器,这个工具适合专业设计师用吗?
壁纸样机神器在一定程度上适合专业设计师使用,但是否适合具体取决于设计师的需求和使用场景: 适合专业设计师的方面 快速实现设计想法:专业设计师在创作过程中,有时需要快速将设计想法变为可视化的效果图,以便进行初…...

MySQL秘籍之索引与查询优化实战指南
MySQL秘籍之索引与查询优化实战指南 目录 MySQL秘籍之索引与查询优化实战指南相关阅读索引相关EXPLAIN 版本 1. 初级篇1.1 【练体术】基础1.1.1 库操作1.1.1 表操作创建一个表增加表字段 1.1.2 增删改插入一条数据删除一条数据更新一条数据库 1.1.3 查询查询所有数据条件查询&a…...

【AI日记】25.01.03 kaggle 比赛 3-2 未来的命运
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】 工作 参加:kaggle 比赛 Forecasting Sticker Sales时间:8 小时 读书 书名:秦制两千年时间:1.5 小时评估:读完,非常不错,很…...

Linux(Centos 7.6)命令详解:ls
1.命令作用 列出目录内容(list directory contents) 2.命令语法 Usage: ls [OPTION]... [FILE]... 3.参数详解 OPTION: -l,long list 使用长列表格式-a,all 不忽略.开头的条目(打印所有条目,包括.开头的隐藏条目)…...

【Unity3D】UGUI Canvas画布渲染流程
参考文档:画布 - Unity 手册 Canvas组件:画布组件是进行 UI 布局和渲染的抽象空间。所有 UI 元素都必须是附加了画布组件的游戏对象的子对象。 参数: Render Mode 渲染模式:Screen Space - Overlay、Screen Spa…...

minikube安装k8s
一、安装k8s版本 export REGISTRY_MIRRORhttps://registry.cn-hangzhou.aliyuncs.com curl -sSL https://kuboard.cn/install-script/v1.30.x/install_kubelet.sh | sh -s 1.30.0 二、安装docker及minikube useradd docker passwd docker 密码也设置为docker #创建docker组…...
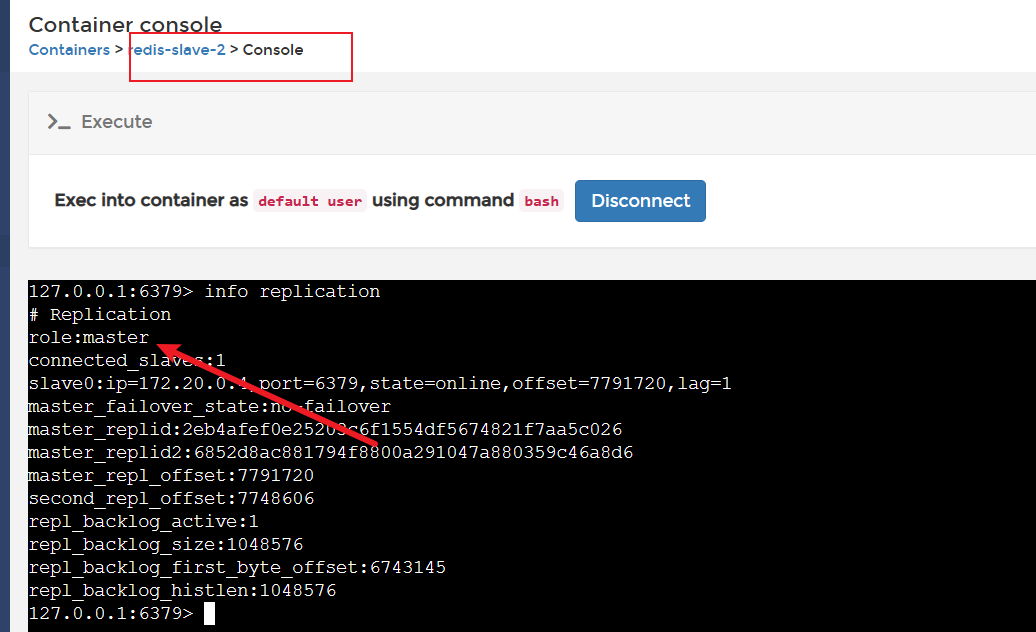
Docker图形化界面工具Portainer最佳实践
前言 安装Portainer 实践-基于Portainer安装redis-sentinel部署 Spring Boot集成Redis Sentinel 前言 本篇文章笔者推荐一个笔者最常用的docker图形化管理工具——Portainer。 安装Portainer 编写docker-compose文件 Portainer部署的步骤比较简单,我们还是以…...

借助 FinClip 跨端技术探索鸿蒙原生应用开发之旅
在当今数字化浪潮汹涌澎湃的时代,移动应用开发领域正经历着深刻的变革与创新。鸿蒙操作系统的崛起,以其独特的分布式架构和强大的性能表现,吸引了众多开发者的目光。而FinClip 跨端技术的出现,为开发者涉足鸿蒙原生应用开发提供了…...

【网络】ARP表、MAC表、路由表
ARP表 网络设备存储IP-MAC映射关系的表项,便于快速查找和转发数据包 ARP协议工作原理 ARP(Address Resolution Protocol),地址解析协议,能够将网络层的IP地址解析为数据链路层的MAC地址。 1.主机在自己的ARP缓冲区中建…...

Linux驱动开发学习准备(Linux内核源码添加到工程-Workspace)
Linux内核源码添加到VsCode工程 下载Linux-4.9.88源码: 没有处理同名文件的压缩包: https://pan.baidu.com/s/1yjIBXmxG9pwP0aOhW8VAVQ?pwde9cv 已把同名文件中以大写命名的文件加上_2后缀的压缩包: https://pan.baidu.com/s/1RIRRUllYFn2…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

基于CNN的食双星光变曲线自动化参数初估模型EBOP MAVEN
1. 项目概述与核心价值在恒星天体物理领域,食双星系统一直扮演着“宇宙实验室”的关键角色。通过分析两颗恒星相互绕转时周期性相互遮挡产生的光变曲线,我们可以像解谜一样,精确反演出恒星的质量、半径、轨道倾角等基本物理参数。这些参数是构…...

如何快速实现U盘文件自动备份:USBCopyer终极指南
如何快速实现U盘文件自动备份:USBCopyer终极指南 【免费下载链接】USBCopyer 😉 用于在插上U盘后自动按需复制该U盘的文件。”备份&偷U盘文件的神器”(写作USBCopyer,读作USBCopier) 项目地址: https://gitcode.…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...