【论文阅读笔记】SCI算法与代码 | 低照度图像增强 | 2022.4.21

目录
一 SCI
1 SCI网络结构
核心代码(model.py)
2 SCI损失函数
核心代码(loss.py)
3 实验
二 SCI效果
1 下载代码
2 运行
一 SCI

💜论文题目:Toward Fast, Flexible, and Robust Low-Light Image Enhancement
💚论文地址:https://arxiv.org/pdf/2204.10137
💙代码地址:https://github.com/vis-opt-group/SCI
【摘要】现有的低照度图像增强技术大多不仅难以兼顾视觉质量和计算效率,而且在未知复杂场景下往往失效。在本文中,我们开发了一种新的自校准照明( Self-Calibrated Illumination,SCI )学习框架,用于实际低照度场景中快速、灵活和鲁棒的亮化图像。具体来说,我们建立了一个带有权重共享的级联光照学习过程来处理这个任务。考虑到级联模式的计算负担,我们构造了自校准模块,实现了每个阶段结果之间的收敛,产生了仅使用单个基本块进行推理(但在以前的工作中尚未得到利用)的增益,极大地减少了计算开销。然后,我们定义了无监督训练损失,以提高模型的能力,使其能够适应一般的场景。进一步,我们对挖掘SCI固有属性(现有工作中的欠缺),包括操作不敏感适应性(在不同的设置下获得稳定的性能)和模型无关通用性(可以应用于现有的基于光照的工作中,以提高性能)进行了全面探索。最后,大量的实验和消融研究充分表明了我们在质量和效率上的优越性。在低照度人脸检测和夜间语义分割上的应用充分显示了SCI的潜在实用价值。
见图1。最近最先进的方法和我们的方法的比较。
Kin D [ 34 ]是具有代表性的成对监督方法。
EnGAN [ 11 ]考虑了非成对监督学习。
Zero DCE [ 7 ]和RUAS [ 14 ]引入了无监督学习。
我们的方法(只包含3个大小为3 × 3的卷积)也属于无监督学习。如放大区域显示的那样,这些比较方法出现了不正确的曝光,颜色失真和结构不足以降低视觉质量。相比之下,我们的结果呈现出生动的颜色和清晰的轮廓。进一步,我们报告了( b )中的计算效率( SIZE , FLOPs和TIME)和( c )中的增强( PSNR , SSIM和EME)、检测( mAP )和分割( mIoU )三种任务中5种度量指标的数值得分,可以很容易地观察到我们的方法明显优于其他方法。

更具体地说,论文的主要贡献可以归结为:
① 开发了一个权重共享的光照学习自校准模块,以保证每个阶段的结果之间的收敛性,提高曝光稳定性,并大幅降低计算负担。据我们所知,利用学习过程加速低照度图像增强算法是第一项工作。
② 在自校准模块的作用下,我们定义了无监督的训练损失来约束每个阶段的输出,从而赋予模型对不同场景的适应能力。属性分析表明,SCI具有操作不敏感的自适应性和模型无关的一般性,这是现有工作中没有发现的。
③ 进行了大量的实验来说明我们相对于其他先进方法的优越性。在暗人脸检测和夜间语义分割上的应用进一步展示了我们的实用价值。简而言之,在基于网络的低照度图像增强领域,SCI重新定义了视觉质量、计算效率和下游任务性能的峰值点。
1 SCI网络结构
见图2。SCI的整个框架。在训练阶段,SCI由光照估计和自校准模块组成。在原始低照度输入中加入自校准模块映射,作为下一阶段照度估计的输入。注意这两个模块分别是整个训练过程中的共享参数。在测试阶段,只使用了单一的光照估计模块。

❤️核心代码(model.py)
主要由EnhanceNetwork 、CalibrateNetwork、Network、Finetunemodel四个类组成。
① EnhanceNetwork: 对输入图像进行增强。
🦋🦋🦋通过多次堆叠卷积块,来学习图像的特征。增强后的图像通过与输入相加并进行截断,以确保像素值在合理范围内。
首先,通过__init__初始化超参数和网络层。
然后,将输入图像通过3*3的卷积层,得到特征 fea,对特征fea多次应用相同的卷积块进行叠加,通过输出卷积层获得最终的特征 fea。
接着,将生成的特征与输入图像相加,得到增强后的图像,通过 clamp 函数将图像像素值限制在 0.0001 和 1 之间。
最后,返回增强后的图像 illu。
② CalibrateNetwork:定义了一个校准网络。
🦋🦋🦋在前向传播时,输入经过一系列卷积操作后,对于最终的特征 fea再与原始输入相减,得到最终的增益调整结果delta。
③ Network:组合了上述图像增强网络 (EnhanceNetwork) 和校准网络(CalibrateNetwork),并多次执行这两个操作。
首先,初始化网络结构,并创建EnhanceNetwork、CalibrateNetwork以及loss损失函数的实例。
接着,定义权重初始化的方法。
然后,通过多次迭代,每次迭代中进行下述的步骤:
◆ 将当前输入保存到列表中。
◆ 使用图像增强网络 EnhanceNetwork 处理当前输入,得到增强后的图像。
◆ 计算增强前后的比例,并将比例值限制在 [0, 1] 范围内。
◆ 使用校准网络 CalibrateNetwork 对比例进行校准,得到校准值。
◆ 将原始输入与校准值相加,得到下一阶段的输入。
◆ 将当前阶段的增强图像、比例、输入和校准值的绝对值保存到对应的列表中。
◆ 返回四个列表,分别包含不同阶段的增强图像、比例、输入和校准值。
最后,计算损失。
④ Finetunemodel:进行模型的微调。
import torch
import torch.nn as nn
from loss import LossFunctionclass EnhanceNetwork(nn.Module):def __init__(self, layers, channels):super(EnhanceNetwork, self).__init__()kernel_size = 3dilation = 1padding = int((kernel_size - 1) / 2) * dilationself.in_conv = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),nn.ReLU())self.conv = nn.Sequential(nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),nn.BatchNorm2d(channels),nn.ReLU())self.blocks = nn.ModuleList()for i in range(layers):self.blocks.append(self.conv)self.out_conv = nn.Sequential(nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),nn.Sigmoid())def forward(self, input):fea = self.in_conv(input)for conv in self.blocks:fea = fea + conv(fea)fea = self.out_conv(fea)illu = fea + inputillu = torch.clamp(illu, 0.0001, 1)return illuclass CalibrateNetwork(nn.Module):def __init__(self, layers, channels):super(CalibrateNetwork, self).__init__()kernel_size = 3dilation = 1padding = int((kernel_size - 1) / 2) * dilationself.layers = layersself.in_conv = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),nn.BatchNorm2d(channels),nn.ReLU())self.convs = nn.Sequential(nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),nn.BatchNorm2d(channels),nn.ReLU(),nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),nn.BatchNorm2d(channels),nn.ReLU())self.blocks = nn.ModuleList()for i in range(layers):self.blocks.append(self.convs)self.out_conv = nn.Sequential(nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),nn.Sigmoid())def forward(self, input):fea = self.in_conv(input)for conv in self.blocks:fea = fea + conv(fea)fea = self.out_conv(fea)delta = input - feareturn deltaclass Network(nn.Module):def __init__(self, stage=3):super(Network, self).__init__()self.stage = stageself.enhance = EnhanceNetwork(layers=1, channels=3)self.calibrate = CalibrateNetwork(layers=3, channels=16)self._criterion = LossFunction()def weights_init(self, m):if isinstance(m, nn.Conv2d):m.weight.data.normal_(0, 0.02)m.bias.data.zero_()if isinstance(m, nn.BatchNorm2d):m.weight.data.normal_(1., 0.02)def forward(self, input):ilist, rlist, inlist, attlist = [], [], [], []input_op = inputfor i in range(self.stage):inlist.append(input_op)i = self.enhance(input_op)r = input / ir = torch.clamp(r, 0, 1)att = self.calibrate(r)input_op = input + attilist.append(i)rlist.append(r)attlist.append(torch.abs(att))return ilist, rlist, inlist, attlistdef _loss(self, input):i_list, en_list, in_list, _ = self(input)loss = 0for i in range(self.stage):loss += self._criterion(in_list[i], i_list[i])return lossclass Finetunemodel(nn.Module):def __init__(self, weights):super(Finetunemodel, self).__init__()self.enhance = EnhanceNetwork(layers=1, channels=3)self._criterion = LossFunction()base_weights = torch.load(weights)pretrained_dict = base_weightsmodel_dict = self.state_dict()pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}model_dict.update(pretrained_dict)self.load_state_dict(model_dict)def weights_init(self, m):if isinstance(m, nn.Conv2d):m.weight.data.normal_(0, 0.02)m.bias.data.zero_()if isinstance(m, nn.BatchNorm2d):m.weight.data.normal_(1., 0.02)def forward(self, input):i = self.enhance(input)r = input / ir = torch.clamp(r, 0, 1)return i, rdef _loss(self, input):i, r = self(input)loss = self._criterion(input, i)return loss2 SCI损失函数
❗❗❗总损失函数:Ltotal = αLf + βLs
Lf :表示保真度;Ls :表示平滑损失。
🌸保真度损失是为了保证估计的照度与每级输入之间的像素级一致性,表示如公式(4)所示。

🌸光照的平滑特性在这个任务[ 7、34]中是一个广泛的共识。这里我们采用一个具有空间变化l1范数的光滑项[ 4 ],表示如公式(5)所示。

❤️核心代码(loss.py)
SCI使用的是无监督损失训练,由fifidelity loss和smoothing loss的线性组合构成。
◆ Fidelity Loss
🌸采用均方误差损失函数 nn.MSELoss 计算输入图像 input 与增强后的图像 illu 之间的均方误差。
正则化项基于像素梯度和其指数权重的计算。
◆ Smooth Loss
🌸采用 SmoothLoss 类的实例 self.smooth_loss 计算输入图像 input 与增强后的图像 illu 之间的光滑损失。
通过 YCbCr 色彩空间的梯度计算来衡量图像的光滑性。
import torch
import torch.nn as nnclass LossFunction(nn.Module):def __init__(self):super(LossFunction, self).__init__()self.l2_loss = nn.MSELoss()self.smooth_loss = SmoothLoss()def forward(self, input, illu):Fidelity_Loss = self.l2_loss(illu, input)Smooth_Loss = self.smooth_loss(input, illu)return 1.5*Fidelity_Loss + Smooth_Lossclass SmoothLoss(nn.Module):def __init__(self):super(SmoothLoss, self).__init__()self.sigma = 10def rgb2yCbCr(self, input_im):im_flat = input_im.contiguous().view(-1, 3).float()mat = torch.Tensor([[0.257, -0.148, 0.439], [0.564, -0.291, -0.368], [0.098, 0.439, -0.071]]).cuda()bias = torch.Tensor([16.0 / 255.0, 128.0 / 255.0, 128.0 / 255.0]).cuda()temp = im_flat.mm(mat) + biasout = temp.view(input_im.shape[0], 3, input_im.shape[2], input_im.shape[3])return out# output: output input:inputdef forward(self, input, output):self.output = outputself.input = self.rgb2yCbCr(input)sigma_color = -1.0 / (2 * self.sigma * self.sigma)w1 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :] - self.input[:, :, :-1, :], 2), dim=1,keepdim=True) * sigma_color)w2 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :] - self.input[:, :, 1:, :], 2), dim=1,keepdim=True) * sigma_color)w3 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, 1:] - self.input[:, :, :, :-1], 2), dim=1,keepdim=True) * sigma_color)w4 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, :-1] - self.input[:, :, :, 1:], 2), dim=1,keepdim=True) * sigma_color)w5 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :-1] - self.input[:, :, 1:, 1:], 2), dim=1,keepdim=True) * sigma_color)w6 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, 1:] - self.input[:, :, :-1, :-1], 2), dim=1,keepdim=True) * sigma_color)w7 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :-1] - self.input[:, :, :-1, 1:], 2), dim=1,keepdim=True) * sigma_color)w8 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, 1:] - self.input[:, :, 1:, :-1], 2), dim=1,keepdim=True) * sigma_color)w9 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :] - self.input[:, :, :-2, :], 2), dim=1,keepdim=True) * sigma_color)w10 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :] - self.input[:, :, 2:, :], 2), dim=1,keepdim=True) * sigma_color)w11 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, 2:] - self.input[:, :, :, :-2], 2), dim=1,keepdim=True) * sigma_color)w12 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, :-2] - self.input[:, :, :, 2:], 2), dim=1,keepdim=True) * sigma_color)w13 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :-1] - self.input[:, :, 2:, 1:], 2), dim=1,keepdim=True) * sigma_color)w14 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, 1:] - self.input[:, :, :-2, :-1], 2), dim=1,keepdim=True) * sigma_color)w15 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :-1] - self.input[:, :, :-2, 1:], 2), dim=1,keepdim=True) * sigma_color)w16 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, 1:] - self.input[:, :, 2:, :-1], 2), dim=1,keepdim=True) * sigma_color)w17 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :-2] - self.input[:, :, 1:, 2:], 2), dim=1,keepdim=True) * sigma_color)w18 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, 2:] - self.input[:, :, :-1, :-2], 2), dim=1,keepdim=True) * sigma_color)w19 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :-2] - self.input[:, :, :-1, 2:], 2), dim=1,keepdim=True) * sigma_color)w20 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, 2:] - self.input[:, :, 1:, :-2], 2), dim=1,keepdim=True) * sigma_color)w21 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :-2] - self.input[:, :, 2:, 2:], 2), dim=1,keepdim=True) * sigma_color)w22 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, 2:] - self.input[:, :, :-2, :-2], 2), dim=1,keepdim=True) * sigma_color)w23 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :-2] - self.input[:, :, :-2, 2:], 2), dim=1,keepdim=True) * sigma_color)w24 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, 2:] - self.input[:, :, 2:, :-2], 2), dim=1,keepdim=True) * sigma_color)p = 1.0pixel_grad1 = w1 * torch.norm((self.output[:, :, 1:, :] - self.output[:, :, :-1, :]), p, dim=1, keepdim=True)pixel_grad2 = w2 * torch.norm((self.output[:, :, :-1, :] - self.output[:, :, 1:, :]), p, dim=1, keepdim=True)pixel_grad3 = w3 * torch.norm((self.output[:, :, :, 1:] - self.output[:, :, :, :-1]), p, dim=1, keepdim=True)pixel_grad4 = w4 * torch.norm((self.output[:, :, :, :-1] - self.output[:, :, :, 1:]), p, dim=1, keepdim=True)pixel_grad5 = w5 * torch.norm((self.output[:, :, :-1, :-1] - self.output[:, :, 1:, 1:]), p, dim=1, keepdim=True)pixel_grad6 = w6 * torch.norm((self.output[:, :, 1:, 1:] - self.output[:, :, :-1, :-1]), p, dim=1, keepdim=True)pixel_grad7 = w7 * torch.norm((self.output[:, :, 1:, :-1] - self.output[:, :, :-1, 1:]), p, dim=1, keepdim=True)pixel_grad8 = w8 * torch.norm((self.output[:, :, :-1, 1:] - self.output[:, :, 1:, :-1]), p, dim=1, keepdim=True)pixel_grad9 = w9 * torch.norm((self.output[:, :, 2:, :] - self.output[:, :, :-2, :]), p, dim=1, keepdim=True)pixel_grad10 = w10 * torch.norm((self.output[:, :, :-2, :] - self.output[:, :, 2:, :]), p, dim=1, keepdim=True)pixel_grad11 = w11 * torch.norm((self.output[:, :, :, 2:] - self.output[:, :, :, :-2]), p, dim=1, keepdim=True)pixel_grad12 = w12 * torch.norm((self.output[:, :, :, :-2] - self.output[:, :, :, 2:]), p, dim=1, keepdim=True)pixel_grad13 = w13 * torch.norm((self.output[:, :, :-2, :-1] - self.output[:, :, 2:, 1:]), p, dim=1, keepdim=True)pixel_grad14 = w14 * torch.norm((self.output[:, :, 2:, 1:] - self.output[:, :, :-2, :-1]), p, dim=1, keepdim=True)pixel_grad15 = w15 * torch.norm((self.output[:, :, 2:, :-1] - self.output[:, :, :-2, 1:]), p, dim=1, keepdim=True)pixel_grad16 = w16 * torch.norm((self.output[:, :, :-2, 1:] - self.output[:, :, 2:, :-1]), p, dim=1, keepdim=True)pixel_grad17 = w17 * torch.norm((self.output[:, :, :-1, :-2] - self.output[:, :, 1:, 2:]), p, dim=1, keepdim=True)pixel_grad18 = w18 * torch.norm((self.output[:, :, 1:, 2:] - self.output[:, :, :-1, :-2]), p, dim=1, keepdim=True)pixel_grad19 = w19 * torch.norm((self.output[:, :, 1:, :-2] - self.output[:, :, :-1, 2:]), p, dim=1, keepdim=True)pixel_grad20 = w20 * torch.norm((self.output[:, :, :-1, 2:] - self.output[:, :, 1:, :-2]), p, dim=1, keepdim=True)pixel_grad21 = w21 * torch.norm((self.output[:, :, :-2, :-2] - self.output[:, :, 2:, 2:]), p, dim=1, keepdim=True)pixel_grad22 = w22 * torch.norm((self.output[:, :, 2:, 2:] - self.output[:, :, :-2, :-2]), p, dim=1, keepdim=True)pixel_grad23 = w23 * torch.norm((self.output[:, :, 2:, :-2] - self.output[:, :, :-2, 2:]), p, dim=1, keepdim=True)pixel_grad24 = w24 * torch.norm((self.output[:, :, :-2, 2:] - self.output[:, :, 2:, :-2]), p, dim=1, keepdim=True)ReguTerm1 = torch.mean(pixel_grad1) \+ torch.mean(pixel_grad2) \+ torch.mean(pixel_grad3) \+ torch.mean(pixel_grad4) \+ torch.mean(pixel_grad5) \+ torch.mean(pixel_grad6) \+ torch.mean(pixel_grad7) \+ torch.mean(pixel_grad8) \+ torch.mean(pixel_grad9) \+ torch.mean(pixel_grad10) \+ torch.mean(pixel_grad11) \+ torch.mean(pixel_grad12) \+ torch.mean(pixel_grad13) \+ torch.mean(pixel_grad14) \+ torch.mean(pixel_grad15) \+ torch.mean(pixel_grad16) \+ torch.mean(pixel_grad17) \+ torch.mean(pixel_grad18) \+ torch.mean(pixel_grad19) \+ torch.mean(pixel_grad20) \+ torch.mean(pixel_grad21) \+ torch.mean(pixel_grad22) \+ torch.mean(pixel_grad23) \+ torch.mean(pixel_grad24)total_term = ReguTerm1return total_term
3 实验
见图7。在LSRW数据集上对当前最先进的低照度图像增强方法进行了视觉比较。

见图8。在一些具有挑战性的实例上进行视觉比较。更多的结果可以在补充材料中找到。

二 SCI效果
Requirements:python3.7 pytorch==1.8.0 cuda11.1
1 下载代码
git clone https://github.com/vis-opt-group/SCI.git2 运行
python3 test.py原图:

效果图:

至此,本文分享的内容就结束啦💕💕💕💕💕💕。
相关文章:
【论文阅读笔记】SCI算法与代码 | 低照度图像增强 | 2022.4.21
目录 一 SCI 1 SCI网络结构 核心代码(model.py) 2 SCI损失函数 核心代码(loss.py) 3 实验 二 SCI效果 1 下载代码 2 运行 一 SCI 💜论文题目:Toward Fast, Flexible, and Robust Low-Light Image …...

RAG实战:本地部署ragflow+ollama(linux)
1.部署ragflow 1.1安装配置docker 因为ragflow需要诸如elasticsearch、mysql、redis等一系列三方依赖,所以用docker是最简便的方法。 docker安装可参考Linux安装Docker完整教程,安装后修改docker配置如下: vim /etc/docker/daemon.json {…...

前路漫漫,曙光在望 !
起始 从20年大一开始写作至今,转眼五年时光已经过去了,最开始在CSDN这个平台写博客也只是因为一次机缘巧合情况下得知写博客可以获取奖赏,所以那个时期开始疯狂在CSDN发文记录自己编程学习过程,但是至今也未从写作中获利一分哈…...

特征工程-特征预处理
1.7 特征工程-特征预处理 学习目标 目标 了解什么是特征预处理知道归一化和标准化的原理及区别 1 什么是特征预处理 1.1 特征预处理定义 scikit-learn的解释 provides several common utility functions and transformer classes to change raw feature vectors into a represe…...

代码随想录算法训练营day22
代码随想录算法训练营 —day22 文章目录 代码随想录算法训练营前言回溯算法理论基础回溯法解决的问题回溯法模板 一、77. 组合二、216. 组合总和 III三、17. 电话号码的字母组合总结 前言 今天是算法营的第22天,希望自己能够坚持下来! 今日任务&#x…...

2024秋语法分析作业-B(满分25分)
特别注意:第17条产生式改为 17) Stmt → while ( Cond ) Stmt 【问题描述】 本次作业只测试一个含简单变量声明、赋值语句、输出语句、if语句和while语句的文法: 0) CompUnit → Block 1) Block → { BlockItemList } 2) BlockItemList → BlockItem…...
)
Python爬虫入门(1)
在互联网时代,数据成为了最宝贵的资源之一。Python作为一种功能强大的编程语言,因其简洁的语法和丰富的库支持,成为了编写网络爬虫的首选。本文将带你入门Python爬虫技术,让你能够从互联网上自动获取数据。 什么是爬虫࿱…...

鸿蒙1.2:第一个应用
1、create Project,选择Empty Activity 2、配置项目 project name 为项目名称,建议使用驼峰型命名 Bundle name 为项目包名 Save location 为保存位置 Module name 为模块名称,即运行时需要选择的模块名称,见下图 查看模块名称&…...

2024年常用工具
作为本年度高频使用工具,手机端也好,桌面端也好,筛选出来9款产品,这里也分享给关注我的小伙伴 ,希望对你有些帮助,如果你更好的产品推荐,欢迎留言给我。 即刻 产品经理的聚集地,“让…...

【蓝桥杯】走迷宫
题目: 解题思路: 简单的广度优先算法(BFS) BFS 的特性 按层次遍历:BFS 按照节点的距离(边的数量)来逐层访问节点。保证最短路径:对于无权图(所有边权重相同࿰…...
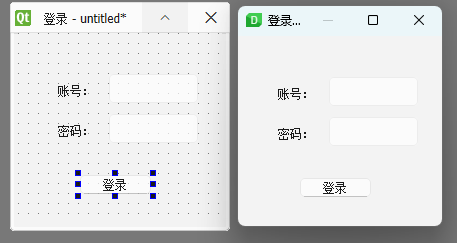
【pyqt】(三)designer
designer ui设计 在学习后续的代码之前,我们可以先学习一下designer这款工具,在安装软件的时候我们有提到过,其具体位置在虚拟环境根目录下的\Lib\site-packages\PySide6文件夹中。对于新手而言,使用这种可视化的工具可以帮助我们…...

【Go学习】-01-3-函数 结构体 接口 IO
【Go学习】-01-3-函数 结构体 接口 IO 1 函数1.1 函数概述1.1.1 函数做为参数1.1.2 函数返回值 1.2 参数1.3 匿名函数1.4 闭包1.5 延迟调用1.6 异常处理 2 结构体2.1 实例化2.2 匿名结构体2.3 匿名字段 3 类方法3.1 接收器3.2 类方法练习:二维矢量模拟玩家移动3.3 给…...

昆仑万维大数据面试题及参考答案
请介绍一下 Flume 组件。 Flume 是一个分布式、可靠、高可用的海量日志采集、聚合和传输的系统。 从架构层面来看,它主要包含以下几个关键部分。首先是 Source,它是数据的收集端,能够接收多种不同来源的数据。比如,它可以从各种服务器的日志文件中读取数据,像 Web 服务器产…...

20250103在Ubuntu20.04.5的Android Studio 2024.2.1.12中跑通Hello World
20250103在Ubuntu20.04.5的Android Studio 2024.2.1.12中跑通Hello World 2025/1/3 14:06 百度:android studio helloworld android studio hello world kotlin helloword kotlin 串口 no run configurations added android studio no run configurations added 1、…...

Hack The Box-Starting Point系列Three
答案 How many TCP ports are open?(靶机开了几个TCP端口) 2What is the domain of the email address provided in the “Contact” section of the website?(网站的“CONTACT”部分提供的电子邮件地址的域是什么?)…...

【Python其他生成随机字符串的方法】
在Python中,除了之前提到的方法外,确实还存在其他几种生成随机字符串的途径。以下是对这些方法的详细归纳: 方法一:使用random.randint结合ASCII码生成 你可以利用random.randint函数生成指定范围内的随机整数,这些整…...

redis7基础篇2 redis的主从模式1
目录 一 主从模式 1.1 主从复制的作用 1.2 配置常用命令 1.3 主从复制常见问题 1.4 主从复制的缺点 1.5 redis主从复制原理 二 redis主从复制的搭建流程 2.1 注意事项 2.2 redis的主从复制架构图 2.3 以6379.conf配置文件配置为例 2.4 以6380.conf配置文件配置为例 …...

Springboot - Web
Spring Boot 是一个用于简化 Spring 应用程序配置和部署的框架。它提供了一种快速开发的方式,通过默认配置、自动化配置等特性,使得开发者能够更快捷地构建和部署基于 Spring 的应用。 Spring Boot Web 是 Spring Boot 的一个子模块,它专注于…...

【C】动态内存管理
所谓动态内存管理,就是使得内存可以动态开辟,想使用的时候就开辟空间,使用完之后可以销毁,将内存的使用权还给操作系统,那么动态开辟内存有什么用呢? 假设有这么一种情况,你在一家公司中工作&am…...

lec5-传输层原理与技术
lec5-传输层原理与技术 1. 传输层概述 1.1. 关键职责 flow control,流量控制reliability,可靠性 1.2. TCP与UDP对比 面向连接 / 不能连接对数据校验 / 不校验数据丢失重传 / 不会重传有确认机制 / 没有确认滑动窗口流量控制 / 不会流量控制 1.3. 关…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...