机器学习经典算法——逻辑回归
目录
算法介绍
算法概念
算法的优缺点
LogisticRegression()函数理解
环境准备
算法练习
算法介绍
算法概念
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的机器学习算法。 它基于线性回归的思想,但通过引入一个逻辑函数(如 Sigmoid 函数)将线性回归的输出值映射到 0 到 1 之间,从而得到事件发生的概率估计。

算法的优缺点
逻辑回归的优点包括:
-
计算效率高,训练速度快。
-
模型简单易懂,可解释性强。
-
能够处理线性可分和近似线性可分的数据。
逻辑回归的缺点:
容易欠拟合,分类精度可能不高。
LogisticRegression()函数理解
def __init__(self,penalty="l2",*,dual=False,tol=1e-4,C=1.0,fit_intercept=True,intercept_scaling=1,class_weight=None,random_state=None,solver="lbfgs",max_iter=100,multi_class="auto",verbose=0,warm_start=False,n_jobs=None,l1_ratio=None,
):
#参数理解
'''
Penalty:正则化方式,有l1和l2两种。用于指定惩罚项中使用的规范。newton-cg、sag和lbfgs求解算法只支持L2规范。L1G规范假设的是模型的参数满足拉普拉斯分布,L2假设的模型参数满足高斯分布,所谓的范式就是加上对参数的约束,使得模型更不会过拟合(overfit),理论上加了约束泛化能力更强。
Dual:按默认即可。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
Tol:float,默认值:1e-4,容许停止标准,即我们说的要迭代停止所需达到的精度要求。
C:正则化强度。为浮点型数据。正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数!像SVM一样,越小的数值表示越强的正则化。
fit_intercept:指定是否应该将常量(即偏差或截距)添加到决策函数中。相当于是否加入截距项b。默认加入。
intercept_scaling:仅在正则化项为”liblinear”,且fit_intercept设置为True时有用。float类型,默认为1。
class_weight:用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为None,
也就是不考虑权重,在出现样本不平衡时,可以考虑调整class_weight系数去调整,防止算法对训练样本多的类别偏倚。用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为不输入,也就是不考虑权重,即为None。如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者自己输入各个类型的权重。举个例子,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9,1:0.1},这样类型0的权重为90%,而类型1的权重为10%。如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3]。
那么class_weight有什么作用呢?
在分类模型中,我们经常会遇到两类问题:
第一种是误分类的代价很高。比如对合法用户和非法用户进行分类,将非法用户分类为合法用户的代价很高,我们宁愿将合法用户分类为非法用户,这时可以人工再甄别,但是却不愿将非法用户分类为合法用户。这时,我们可以适当提高非法用户的权重。
第二种是样本是高度失衡的,比如我们有合法用户和非法用户的二元样本数据10000条,里面合法用户有9995条,非法用户只有5条,如果我们不考虑权重,则我们可以将所有的测试集都预测为合法用户,这样预测准确率理论上有99.95%,但是却没有任何意义。这时,我们可以选择balanced,让类库自动提高非法用户样本的权重。提高了某种分类的权重,相比不考虑权重,会有更多的样本分类划分到高权重的类别,从而可以解决上面两类问题。
random_state:伪随机数产生器在对数据进行洗牌时使用的种子。仅在正则化优化算法为sag,liblinear时有用。
Solver:{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’},优化拟合参数算法选择,默认为liblinear。solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
liblinear:使用坐标轴下降法来迭代优化损失函数。使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
newton-cg:牛顿法,sag方法使用一阶导数,而牛顿法采用了二阶泰勒展开,这样缩减了迭代轮数,但是 需要计算Hsssian矩阵的逆,所以计算复杂度较高。【也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。】
Lbfgs:拟牛顿法,考虑到牛顿法的Hessian矩阵求逆太过复杂,尤其在高维问题中几乎不可行,想到了用较低的代价寻找Hessian矩阵的近似逆矩阵,便有了拟牛顿法。【拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。】
Sag:即随机平均梯度下降,类似于我们的stocGradAscent1函数,思想是常用的一阶优化方法,是求解无约束优化问题最经典,最简单的方法之一。【即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。】
Saga:线性收敛的随机优化算法。【线性收敛的随机优化算法的的变种。】
总结:
liblinear适用于小数据集,而sag和saga适用于大数据集因为速度更快。
对于多分类问题,只有newton-cg,sag,saga和lbfgs能够处理多项损失,而liblinear受限于一对剩余(OvR)。啥意思,就是用liblinear的时候,如果是多分类问题,得先把一种类别作为一个类别,剩余的所有类别作为另外一个类别。依次类推,遍历所有类别,进行分类。
newton-cg,sag和lbfgs这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear和saga通吃L1正则化和L2正则化。
同时,sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了。要么通过对样本采样来降低样本量,要么回到L2正则化。
从上面的描述,大家可能觉得,既然newton-cg, lbfgs和sag这么多限制,如果不是大样本,我们选择liblinear不就行了嘛!错,因为liblinear也有自己的弱点!我们知道,逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种。而MvM一般比OvR分类相对准确一些。郁闷的是liblinear只支持OvR,不支持MvM,这样如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能使用L1正则化了。
max_iter:算法收敛最大迭代次数,int类型,默认为100。仅在正则化优化算法为newton-cg, sag和lbfgs才有用,算法收敛的最大迭代次数。
multi_class:分类方式选择参数,str类型,可选参数为ovr和multinomial,默认为ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
OvR和MvM有什么不同?
OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg,lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
verbose:日志冗长度,int类型。默认为0。就是不输出训练过程,1的时候偶尔输出结果,大于1,对于每个子模型都输出。
warm_start:热启动参数,bool类型。默认为False。如果为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。
n_jobs:并行数。int类型,默认为1。1的时候,用CPU的一个内核运行程序,2的时候,用CPU的2个内核运行程序。为-1的时候,用所有CPU的内核运行程序。
'''在实际应用中,逻辑回归常用于以下场景:
-
二分类问题,如预测是否患病、是否购买产品等。
-
作为基准模型与其他复杂模型进行比较。
逻辑回归的参数估计通常使用最大似然估计或梯度下降等优化算法来求解。在评估模型性能时,可以使用准确率、召回率、F1 值等指标。 然而,逻辑回归也有一些局限性,例如对于非线性关系的拟合能力有限,在处理复杂数据时可能表现不佳。但通过特征工程、与其他算法结合等方法,可以在一定程度上克服这些不足。
环境准备
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metricsfrom sklearn.preprocessing import StandardScaler:导入数据标准化处理的类StandardScaler,用于对数据进行标准化操作,使得不同特征具有相似的尺度。from sklearn.linear_model import LogisticRegression:导入逻辑回归模型LogisticRegression,用于构建逻辑回归分类器。from sklearn.model_selection import train_test_split:导入数据分割的函数train_test_split,用于将数据集分割为训练集和测试集。from sklearn import metrics:导入用于模型评估指标计算的模块,例如准确率、召回率、F1 值等的计算函数。
算法练习
下面为银行贷款分析数据的部分截图,第一列为时间,可以删除,最后一列为是否允许贷款的判定结果,视为类别,中间为特征列。
问题:
-
将数据集划分为特征集和目标变量,然后进一步划分为训练集和测试集。
-
创建逻辑回归模型并进行训练。
-
在测试集上进行预测,并计算准确率,打印分类结果报告。
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
import pandas as pd
# 读取信用卡数据集
data =pd.read_csv('creditcard.csv')
data.head()
# 创建数据标准化对象
scaler=StandardScaler()
# 获取数据中的'Amount'列,以二维数组形式
a=data[['Amount']]
# 获取数据中的'Amount'列,以一维数组形式
b=data['Amount']
# 对'Amount'列进行标准化处理
data['Amount']=scaler.fit_transform(data[['Amount']])
# 按列删除'Time'列
data=data.drop(['Time'],axis=1)
# 定义特征集,删除'Class'列
X_whole=data.drop('Class',axis=1)
# 定义目标变量,即'Class'列
Y_whole=data.Class
# 将数据集划分为训练集和测试集,测试集占比0.3,设置随机数种子为1000
x_train_w,x_test_w,y_train_w,y_test_w =\train_test_split(X_whole,Y_whole,test_size =0.3,random_state = 1000)
# 创建逻辑回归模型,C=1
lr = LogisticRegression(C=1)
# 使用训练集训练模型
lr.fit(x_train_w,y_train_w)
# 在测试集上进行预测
train_predicted =lr.predict(x_test_w)
# 计算模型在测试集上的准确率
result = lr.score(x_test_w,y_test_w)
# 获取分类结果报告
print(metrics.classification_report(y_test_w, train_predicted))
相关文章:
机器学习经典算法——逻辑回归
目录 算法介绍 算法概念 算法的优缺点 LogisticRegression()函数理解 环境准备 算法练习 算法介绍 算法概念 逻辑回归(Logistic Regression)是一种广泛应用于分类问题的机器学习算法。 它基于线性回归的思想,但通过引入一个逻辑函数&…...

【数据仓库金典面试题】—— 包含详细解答
大家好,我是摇光~,用大白话讲解所有你难懂的知识点 该篇面试题主要针对面试涉及到数据仓库的数据岗位。 以下都是经典的关于数据仓库的问题,希望对大家面试有用~ 1、什么是数据仓库?它与传统数据库有何区别? 数据仓库…...

【UE5 C++课程系列笔记】19——通过GConfig读写.ini文件
步骤 1. 新建一个Actor类,这里命名为“INIActor” 2. 新建一个配置文件“Test.ini” 添加一个自定义配置项 3. 接下来我们在“INIActor”类中获取并修改“CustomInt”的值。这里定义一个方法“GetINIVariable” 方法实现如下,其中第16行代码用于构建配…...

JS 中 json数据 与 base64、ArrayBuffer之间转换
JS 中 json数据 与 base64、ArrayBuffer之间转换 json 字符串进行 base64 编码 function jsonToBase64(json) {return Buffer.from(json).toString(base64); }base64 字符串转为 json 字符串 function base64ToJson(base64) {try {const binaryString atob(base64);const js…...

USB 驱动开发 --- Gadget 驱动框架梳理
编译链接 #----》 linux_5.10/drivers/usb/gadget/Makefileobj-$(CONFIG_USB_LIBCOMPOSITE) libcomposite.o libcomposite-y : usbstring.o config.o epautoconf.o libcomposite-y composite.o functions.o configfs.o u_f.oobj-$(CONFIG_USB_GADG…...
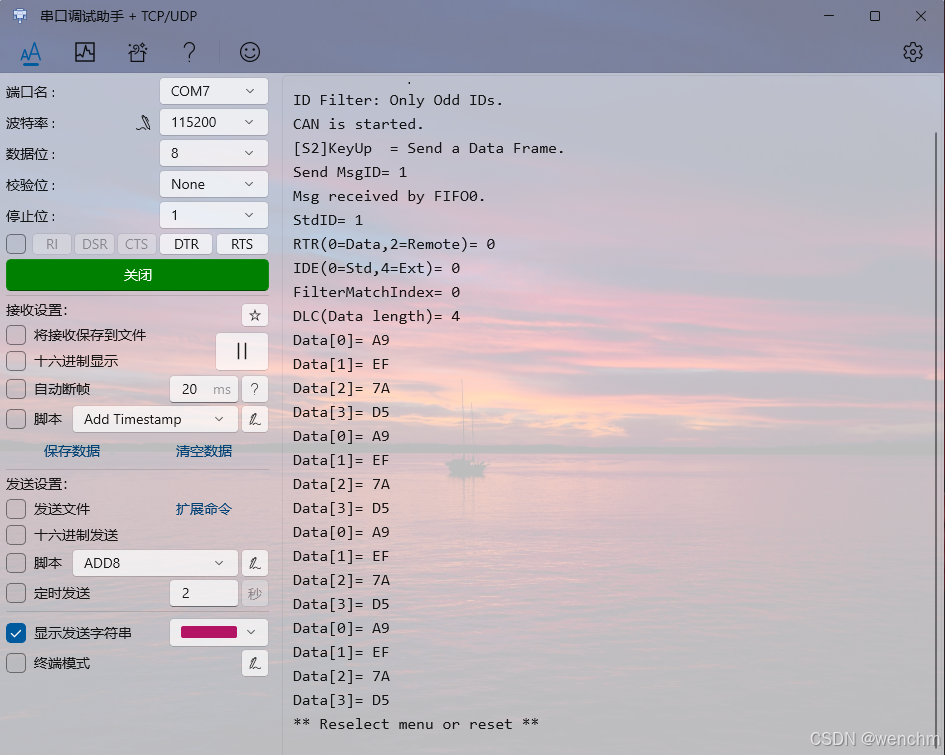
细说STM32F407单片机中断方式CAN通信
目录 一、工程配置 1、时钟、DEBUG、USART6、GPIO、CodeGenerator 2、CAN1 3、NVIC 二、软件设计 1、KEYLED 2、can.h 3、can.c (1)CAN1中断初始化 (2)RNG初始化和随机数产生 (3) 筛选器组设置…...

Python应用指南:高德交通态势数据
在现代城市的脉络中,交通流量如同流动的血液,交通流量的动态变化对出行规划和城市管理提出了更高的要求。为了应对这一挑战,高德地图推出了交通态势查询API,旨在为开发者提供一个强大的工具,用于实时获取指定区域或道路…...

医学图像分析工具01:FreeSurfer || Recon -all 全流程MRI皮质表面重建
FreeSurfer是什么 FreeSurfer 是一个功能强大的神经影像学分析软件包,广泛用于处理和可视化大脑的横断面和纵向研究数据。该软件由马萨诸塞州总医院的Martinos生物医学成像中心的计算神经影像实验室开发,旨在为神经科学研究人员提供一个高效、精确的数据…...

.NET框架用C#实现PDF转HTML
HTML作为一种开放标准的网页标记语言,具有跨平台、易于浏览和搜索引擎友好的特性,使得内容能够在多种设备上轻松访问并优化了在线分享与互动。通过将PDF文件转换为HTML格式,我们可以更方便地在浏览器中展示PDF文档内容,同时也更容…...

mamba-ssm安装
注意1:mamba-ssm要与casual-conv1d一起安装。 注意2:mamba-ssm与cuda、pytorch版本要对应。需要看你下载的代码的requirements.txt causal-conv1d与mamba的whl包官网下载: https://github.com/Dao-AILab/causal-conv1d/releases?page3 htt…...

网络IP协议
IP(Internet Protocol,网际协议)是TCP/IP协议族中重要的协议,主要负责将数据包发送给目标主机。IP相当于OSI(图1)的第三层网络层。网络层的主要作用是失陷终端节点之间的通信。这种终端节点之间的通信也叫点…...

双指针算法详解
目录 一、双指针 二、双指针题目 1.移动零 解法: 代码: 2.复写零 编辑 解法: 代码: 边界情况处理: 3.快乐数 编辑 解法:快慢指针 代码: 4.盛水最多的容器 解法:(对撞指针)…...

MySQL的最左匹配原则是什么
最左匹配原则是应用于联合索引的规则。 对于以下表F:f1,f2,f3;建立了联合索引(f2,f3),那么我们在查询的时候如果是: select * from F where f2 ? and f3 ?; 或 sele…...

LeetCode:106.从中序与后序遍历序列构造二叉树
跟着carl学算法,本系列博客仅做个人记录,建议大家都去看carl本人的博客,写的真的很好的! 代码随想录 LeetCode:106.从中序与后序遍历序列构造二叉树 给定两个整数数组 inorder 和 postorder ,其中 inorder …...

22. 【.NET 8 实战--孢子记账--从单体到微服务】--记账模块--切换主币种
这篇文章我们将结合主币种设置以及收支记录实现切换主币种后重新计算以前记录的转换后的金额。那么,为什么要在切换主币种后要重新计算转换后的金额呢?有以下两个原因: 统一的币种,方便我们统计数据方便用户按照当地的币种查看收…...

01.02周四F34-Day43打卡
文章目录 1. 地是湿的。昨晚估计下雨了。2. 你可能把包丢在餐厅里了吧?3. 她说他可能误了航班。4. 我本来应该早点来的,但路上特别堵。5. 约翰可能在那次事故中受了重伤。6. 这是一个情景对话7. 我本可以走另一条路的。8. 我准是瘦了不少,你看我这裤子现在多肥。9. 钱没了!会…...

行业商机信息付费小程序系统开发方案
行业商机信息付费小程序系统,主要是整合优质行业资源,实时更新的商机信息。在当今信息爆炸的时代,精准、高效地获取行业商机信息对于企业和个人创业者而言至关重要。 一、使用场景 日常浏览:用户在工作间隙或闲暇时间,…...

cut-命令详解
一、命令 1.cut列截取命令 cut命令的默认分隔符是制表符 2.参数: -f 列号 #提取第几列-d 分隔符 #按照指定分隔符分割列-c 字符范围 #不依赖分隔符来区分列,而是通过字符范围(行首为0)来进行字段提取。“n-”表…...

Apache MINA 反序列化漏洞CVE-2024-52046
漏洞描述: Apache MINA 是一个功能强大、灵活且高性能的网络应用框架。它通过抽象网络层的复杂性,提供了事件驱动架构和灵活的 Filter 链机制,使得开发者可以更容易地开发各种类型的网络应用。 Apache MINA 框架的 ObjectSerializationDeco…...
)
二、AI知识(神经网络)
二、AI知识(神经网络) 1.常用算法 FNN CNN RNN LSTM DNN GRU 2.深度学习中概念及算法 1. 感知机 感知机(Perceptron)是一种最早的人工神经网络模型之一,通常用来解决二分类问题。它由弗兰克罗森布拉特&#…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...