DDcGAN_多分辨率图像融合的双鉴别条件生成对抗网络_y译文马佳义
摘要:
在本文中,我们提出了一种新的端到端模型,称为双鉴别条件生成对抗网络(DDcGAN),用于融合不同分辨率的红外和可见光图像。我们的方法建立了一个生成器和两个鉴别器之间的对抗博弈。生成器的目的是基于特定设计的内容损失生成类似真实的融合图像,以欺骗两个鉴别器,而两个鉴别器的目的是除了内容损失之外,分别区分融合图像与两个源图像之间的结构差异。因此,融合图像被迫同时保持红外图像中的热辐射和可见光图像中的纹理细节。此外,为了融合不同分辨率的源图像,例如低分辨率红外图像和高分辨率可见光图像,我们的DDcGAN将下采样融合图像约束为具有与红外图像相似的属性。这可以避免导致热辐射信息模糊或可见纹理细节丢失,这通常发生在传统方法中。此外,我们还将我们的DDcGAN应用于融合不同分辨率的多模态医学图像,例如低分辨率正电子发射断层扫描图像和高分辨率磁共振图像。在公开可用的数据集上进行的定性和定量实验表明,我们的DDcGAN在视觉效果和定量指标方面都优于最先进的技术。我们的代码可以在https://github.com/jiayi-ma/DDcGAN上公开获得。
一.简介
由于在计算机视觉、遥感、医学成像、军事探测等诸多领域的广泛应用,红外和可见光图像融合在图像信号处理中越来越受欢迎。
在这些传感器中,红外和可见光传感器可能是使用最广泛的传感器类型,其波长分别为8-14 μm [3] 和300-530 nm [4]。红外和可见光传感器相结合的独特之处在于,可见光传感器捕获反射光以表示丰富的纹理细节,而红外传感器将捕获的热辐射映射为灰度图像,即使在照明条件不佳或恶劣的情况下也可以突出显示热目标。闭塞。由于它们之间具有很强的互补性,融合结果有可能呈现目标的几乎所有固有属性,以提高视觉理解[5]。因此,它们的融合在军事和民用应用中发挥着重要作用[6],[7]。
对于多模态源图像,图像融合的关键是提取来自不同成像设备的源图像中最重要的特征信息,并将其合并成单个融合图像[8]。因此,融合图像可以提供更复杂和详细的场景表示,同时减少冗余信息。为此,过去几十年来提出了许多融合方法。根据相应的方案,这些融合方法可以分为不同的类别,包括基于多尺度变换的方法[9],[10],基于稀疏表示的方法[11],[12],基于神经网络的方法[ 13]、基于子空间的方法[14]、基于显着性的方法[15]、混合方法[16]和其他融合方法[17]、[18]。这些方法致力于以手动方式设计特征提取和融合规则,以获得更好的融合性能。然而,详细多样的特征提取和融合规则设计使得融合方法越来越复杂。
由于深度学习最近受到广泛关注,一些基于深度学习的融合方法被提出。基于深度学习的融合方法的详细阐述将在第 2 节中讨论II-A。尽管这些工作取得了可喜的性能,但仍然存在一些缺点:(i)深度学习框架仅应用于融合过程的某些部分,例如提取特征,而整体融合过程仍然采用传统框架[19] ],[20]。 (ii) 面对缺乏事实依据,仅仅设计损失函数的解决方案是不全面和不合适的。(iii)即使源图像是多模态数据,以人工方式设计的融合规则也强制提取相同的特征。(iv)在现有的基于传统生成对抗网络(GAN)[21],[22]的融合方法中,融合后的图像只被训练成与其中一幅源图像相似,导致另一幅源图像中包含的一些信息丢失。
手稿于 2018 年 12 月 10 日收到; 2019年9月30日修订;接受日期:2020 年 2 月 26 日。当前版本日期:2020 年 3 月 12 日。这项工作部分得到了国家自然科学基金委 61773295、61903279 和 61971165 的支持,部分得到了自然科学与工程研究部的支持。加拿大委员会 (NSERC) 授予 RGPIN239031。 Jana Ehmann 博士负责协调本手稿的审查并批准其出版。 (通讯作者:梅晓光)马嘉义、徐韩、梅晓光,武汉大学电子信息学院,湖北 武汉 430072(e-mail:jyma2010@gmail.com;meixiaoguang@gmail.com;xu_han@ whu.edu.cn)。蒋军军(哈尔滨工业大学计算机科学与技术学院,哈尔滨 150001)(E-mail:junjun0595@163.com)张晓平就职于加拿大多伦多瑞尔森大学电气、计算机和生物医学工程系,邮编:ON M5B 2K3(电子邮件:xzhang@ee.ryerson.ca)。数字对象标识符 10.1109/TIP.2020.2977573
此外,由于硬件和环境的限制,红外图像与相应的可见光图像相比,始终存在分辨率低、细节模糊的问题,并且很难通过升级硬件设备来提高红外图像的分辨率。对于多分辨率红外和可见光图像(例如不同分辨率的图像)的融合,融合前对可见光图像进行下采样或对红外图像进行上采样的策略将不可避免地导致热辐射信息模糊或可见纹理细节损失。因此,融合多分辨率红外和可见光图像而不丢失重要信息仍然是一项具有挑战性的任务。
为了解决上述挑战,在这项工作中,我们提出了一种通过双判别器条件生成对抗网络(DDcGAN)的融合方法。该问题被表述为基于条件 GAN [23] 的两种神经网络(即一个生成器和两个判别器)的特定对抗过程。我们将该架构适应于双鉴别器,并且鉴别器在生成器获得的生成数据的分布上相互拉动,使得融合图像同时保留红外和可见光图像中最重要的特征信息。我们利用源图像作为真实数据,并且融合图像应该与两种类型的真实图像无法区分,因此我们的模型中不需要真实的融合图像。整个网络是一个端到端的模型,不需要设计融合规则。此外,我们的模型可以推广到融合不同分辨率的源图像。特别是,我们将下采样的融合图像限制为与红外图像具有相似的属性,并利用可训练的反卷积层来学习不同分辨率之间的映射。最后但并非最不重要的一点是,我们提出的方法也可以推广到解决医学图像融合问题,例如正电子发射断层扫描(PET)和磁共振图像(MRI)融合,可以最大限度地保留功能信息和解剖信息。融合图像中的范围。大量结果揭示了我们的 DDcGAN 与其他方法相比的优势。
我们工作的主要贡献包括以下四个方面。首先,我们提出的方法有助于将基于最小最大两人博弈的深度学习框架应用于多模态图像的整体融合过程,而不仅仅是其中的某些子部分。其次,双判别器架构使生成器能够得到更充分的训练,以满足更严格的要求,并避免因仅在一种类型的源图像上引入判别器而导致的信息丢失。第三,由于利用可训练的反卷积层和对下采样融合图像的内容约束,我们提出的方法展示了更好的多分辨率源图像融合性能。最后,我们的方法还可以扩展到医学图像的融合,例如MRI和PET图像融合,并取得了有利的性能。
该手稿的初步版本出现在[24]中。主要的新贡献包括以下五个方面。首先,优化了生成器网络架构,我们用密集连接的卷积网络替换了 U 网。凭借密集的连接,网络架构可以加强特征图的传输并更有效地利用它们。没有大步长造成的损失和上采样操作造成的模糊,更大程度地保留了源图像中的信息,以获得更清晰的融合性能。其次,判别器Dv的输入不再是待判别图像的梯度,而是图像本身。通过将概率空间从源图像的子空间扩展到整个图像,融合图像可以与源图像具有更多相似的属性。当网络试图最小化子空间中不同概率分布的散度时,它会在源图像中引入一些额外的噪声。通过扩大概率空间,可以减轻影响。第三,对于生成器的输入,即不同分辨率的源图像,我们没有使用两个上采样层对低分辨率源图像进行上采样,而是采用反卷积层来学习从低分辨率到高分辨率的映射。不同的是,该层的参数是在训练阶段获得的,而不是预先定义的。高分辨率源图像被输入另一个反卷积层以生成相同分辨率的特征图。第四,我们添加了与生成器和两个判别器相关的更详细的分析实验,以验证其子部分的效果。最后,我们应用所提出的方法来融合不同分辨率的多模态医学图像,即低分辨率 PET 图像和高分辨率 MRI 图像,并将我们的融合结果与最先进的方法进行定性和定量比较。
本文的其余部分组织如下。第二部分描述了一些相关工作,包括现有基于深度学习的融合方法的概述和 GAN 的理论介绍。第三节提供了问题表述、损失函数和网络架构设计。在第四节中,我们提出的方法被推广到融合医学图像。在第五节中,我们通过对红外和可见光图像融合以及 PET 和 MRI 图像融合的定性和定量比较,将我们的方法与公开数据集上的几种最先进的方法进行比较。本节还进行了判别器分析的实验。第六节给出了结论。
二.相关工作
在本节中,我们简要介绍现有的基于深度学习的图像融合方法。此外,由于我们的方法是基于 GAN 的,因此我们还对其基本理论和改进的网络(即条件 GAN)进行了简要说明。
A. 基于深度学习的融合方法
由于基于深度学习的研究已经成为近三年图像融合领域的一个活跃课题[25],许多基于深度学习的融合方法被提出并逐渐形成一个关键分支。在一些方法中,应用深度学习框架以端到端的方式提取图像特征以进行重建。代表性的有刘等人。 [19]将卷积稀疏表示(CSR)应用于图像融合,用于提取多层特征,并使用这些特征生成融合图像。在[26]中,刘等人。提出了一种基于卷积神经网络(CNN)的医学图像融合方法。卷积网络仅用于生成融合像素活动信息的权重图,整个融合过程仍然以传统方式通过图像金字塔以多尺度方式进行。在[20]中,Li等人。将源图像分解为基础部分和细节内容。使用深度学习框架提取细节内容中的多层特征,同时通过加权平均融合基础部分。然后,将这两部分组合起来进行重建。
在其他方法中,深度学习框架不仅用于特征提取,还用于重建。例如,基于超分辨率的三层架构,Masi 等人。 [27]提出了一种用于投影、映射和重建的卷积神经网络来解决全色锐化问题。普拉巴卡尔等人。 [28]提出了一种用于多重曝光融合的无监督深度学习框架。他们利用了一种新颖的 CNN 架构,并设计了一个无参考质量度量作为损失函数。由于权重是绑定的,预融合层被迫学习相同的特征,并且添加这些特征以进行融合。在此基础上,李等人。 [29]通过引入密集块改进了架构。在融合层中,显着特征图通过两种手动设计的融合策略(加法和 1-范数)进行组合。类似地,它利用无参考度量(结构相似性指数度量和欧几里得距离)作为无监督学习的损失函数。在我们之前的工作 [21] 中,我们提出了 FusionGAN 使用生成对抗网络融合红外和可见图像。通过应用鉴别器来区分可见图像中的差异,生成器生成的融合图像被迫具有更多可见图像中存在的细节。当融合不同分辨率的源图像时,低分辨率红外图像在输入发生器之前会被简单地插值。
尽管上述工作取得了可喜的性能,但现有的基于深度学习的融合方法仍然存在一些缺陷。 (i)现有方法通常在特征提取和重建中执行神经网络,而融合规则仍然以手动方式设计。由此可见,整个方法无法摆脱传统融合方法的局限性。 (ii)利用深度学习进行红外和可见光图像融合的主要障碍是缺乏用于监督学习的真实融合图像。现有方法通过设计损失函数来惩罚输出与目标在某些方面的差异来解决这个问题。然而,这些指标会带来新的问题,同时对某些方面进行惩罚。例如,欧几里德距离通过对所有可能的输出进行平均而得到相对模糊的结果[30]。因此,设计一个全面的、适当的、自适应的损失函数来指定一个高层次的目标仍然是困难的。 (iii)大多数人为设计的融合规则导致不同类型的源图像提取相同的特征,而不管源图像是不同现象的表现,这不适合多源图像融合。 (iv)现有的基于GAN的融合方法仅仅应用GAN来迫使融合图像在可见光图像中获得更多细节,而红外图像中的热辐射只能通过内容损失来获得。随着对抗游戏的进行,融合图像与可见图像更加相似,热目标的突出度逐渐降低。
为了解决这些问题,我们通过应用 GAN 来解决融合问题,并用双判别器对其进行调整。在此基础上,我们引入反卷积层来适应不同分辨率的源图像的融合。此外,为了训练过程的稳定性,我们优化了网络架构和训练策略。
B.生成对抗网络
生成对抗网络是生成模型之一。如果样本是从真实分布 Pdata (x) 中抽取的,则生成模型被设计为学习由 θ 参数化的概率分布 Pmodel (x ; θ ) 作为来自样本 {x 1, x 2, · 的 Pdata (x ) 的估计· · , x m},其中 Pmodel (x ; θ ) 是高斯混合模型。生成样本的可能性定义如下:
然后我们可以进行最大似然估计[31]:

它可以被认为是最小化 Pdata (x ) 和 Pmodel (x ; θ ) 之间的 Kullback-Liebler 散度。然而,如果Pmodel是一个更复杂的概率分布,那么计算其似然函数来执行最大似然估计将是相当困难的。为了解决这个问题,GAN 通过同时训练两个模型来通过对抗过程来估计生成模型:生成模型 G 和判别器模型 D [32]。
生成器G是一个可以捕获数据分布并生成新样本的网络。如果我们输入从潜在空间采样的噪声 z,它会生成样本 x = G (z)。凭借神经网络,由生成的样本形成的概率分布PG(x)有可能变得更加复杂。 G的训练目标是使PG(x)和Pdata(x)尽可能接近,优化公式可以定义为:

其中 Di v(·) 表示两个分布之间的散度。然而,由于PG和Pdata的公式未知,计算散度很困难。

巧妙的是,判别器 D 可以用来解决这个问题,因为它估计样本来自训练数据而不是 G 的概率。D 的目标函数可以表示为:![]()
其中V(G,D)定义如下:

客观值大意味着PG和Pdata的Jensen-Shannon(JS)散度大,容易区分。因此,G的优化公式可以转化为:
其中判别器D在训练G时是固定的。G和D的对抗过程构成了最小最大博弈,其中G试图欺骗D,而D被训练来区分生成的数据。因此,生成的样本与实际数据越来越难以区分。
如果生成器和判别器都以一些附加信息为条件,则gan可以扩展为条件模型,这些附加信息可以是任何类型的辅助信息。我们可以通过提供额外的信息作为额外的输入层来执行条件反射,该模型被定义为条件生成对抗网络[23]。
三.提出的方法
在本节中,通过分析红外和可见光图像的特征,我们提供了融合公式、损失函数的定义和设计。本节最后具体展示了网络架构的设计。
A. 问题表述
我们通过构建双判别器条件 GAN 将融合问题表述为条件 GAN 模型。为了融合不同分辨率的图像,不失一般性,我们假设可见光图像 v 的分辨率是红外图像 i 的 4 × 4 倍。
我们提出的 DDcGAN 的整个过程如图 1 所示。给定可见光图像 v 和红外图像 i,我们的最终目标是学习以它们为条件的生成器 G,并鼓励生成的图像 G (v, i)现实且信息丰富,足以愚弄歧视者。同时,我们利用两个对抗性判别器 Dv 和 Di ,它们分别生成一个标量,估计来自真实数据而不是 G 的输入的概率。具体来说,Dv 旨在区分生成的图像和可见图像,而 Di 被训练为区分原始低分辨率红外图像和下采样生成/融合图像。这里采用平均池化进行下采样,因为与最大池化相比,它保留了低频信息,并且热辐射信息主要以这种形式呈现。稍微不同的是,为了生成器和判别器之间的平衡,除了判别器的输入之外,我们不将源图像 v 和 i 作为附加/条件信息提供给 Dv 和 Di 。也就是说,每个鉴别器的输入层是包含采样数据的单通道层,而不是包含采样数据和相应源图像作为条件信息的双通道层。因为当条件和待判别样本相同时,判别任务被简化为判断输入图像是否相同,这对于神经网络来说是一个足够简单的任务。当生成器无法欺骗鉴别器时,对抗关系将无法建立,生成器将倾向于随机生成。如此一来,模型就失去了它原本的意义。
我们将下采样算子表示为 ψ,由于保留了低频信息,它由两个平均池化层实现。两层都总结了 3 × 3 邻域并使用 2 的步幅。因此,G 的训练目标可以表示为最小化以下对抗目
相反,判别器的目标是最大化方程7。
通过生成器 G 和两个判别器(Dv 和 Di )的对抗过程,PG 与两个真实分布 PV 和 PI 之间的散度将同时变小,其中 PG 是生成样本的概率分布,PV 是可见光图像和PI的真实分布是红外图像的分布。
B. 损失函数
最初,GAN 的成功受到限制,因为众所周知,它们训练不稳定,可能会导致伪影和噪声或难以理解的结果 [33]。解决伪像和难以理解的结果问题的一个可能的解决方案是引入内容损失以将一组约束包含到网络中。因此,在本文中,生成器不仅被训练来欺骗鉴别器,而且还负责约束生成图像和内容中源图像之间的相似性。因此,生成器的损失函数由对抗性损失 Ladv G 和内容损失 Lcon 组成,权重 λ 控制权衡:![]()
其中 Ladv G 来自判别器,定义为:
由于热辐射和纹理细节主要分别通过像素强度和梯度变化来表征[17],因此我们采用Frobenius范数来约束下采样的融合图像,使其与红外图像具有相似的像素强度作为数据保真度项。通过约束下采样融合图像和低分辨率红外图像的像素强度关系,我们可以大大防止由于压缩或模糊而导致的纹理信息丢失以及由于强制上采样而导致的不准确。根据上述约束,热目标在融合图像中仍然突出。 TV范数[34]应用于正则化项,以约束融合图像表现出与可见图像相似的梯度变化。与0范数相比,TV范数能够有效解决非确定性多项式时间难题。通过权重 η 来权衡像素强度的差异和梯度变化,我们可以得到内容损失:
DDcGAN 中的判别器,即 Dv 和 Di ,起到区分源图像和生成的融合图像的作用。鉴别器的对抗性损失可以计算分布之间的 JS 散度,从而识别强度或纹理信息是否不现实,从而鼓励匹配现实分布。对抗性损失定义如下:
C. 网络架构
1)生成器架构:生成器由 2 个反卷积层、一个编码器网络和相应的解码器网络组成,如图 2 所示。由于红外图像的分辨率较低,因此我们首先在编码之前采用映射。我们引入反卷积层[35]来学习从低分辨率到高分辨率的映射,而不是通过最近的双线性或双三次方法进行简单插值。这种映射与传统的上采样不同,无需定义上采样算子,其参数是通过训练自动获得的。反卷积层的输出是高分辨率特征图,而不是上采样的红外图像。我们还将可见图像通过独立的反卷积层,该层生成具有相同分辨率的特征图。反卷积层获得的结果被连接并作为编码器的输入。特征提取和融合的过程都在编码器中执行,并生成融合的特征图作为输出。然后将这些图输入解码器进行重建,生成的融合图像与可见图像具有相同的分辨率。
编码器由5个卷积层组成,每层可以通过3×3滤波器获得48个特征图。为了减轻梯度消失、补救特征损失并重用之前计算的特征,应用了 DenseNet [36],并以前馈方式在每层和所有层之间建立短直接连接。解码器是一个5层CNN,每层的设置如图2所示。所有卷积层的步幅设置为1。为了避免梯度爆炸/消失并加速训练,应用了批量归一化。 ReLU激活函数用于加速收敛[37]并避免梯度稀疏。
2)鉴别器架构:鉴别器被设计用来对抗生成器。特别是,Dv 和 Di 旨在分别将生成的图像与可见光和红外图像区分开。然而,这两类源图像是不同现象的表现,因而具有显着不同的分布。换句话说,Dv对G的指导和Di对G的指导存在冲突。在我们的网络中,我们不仅要考虑生成器和判别器之间的对抗关系,还要考虑Dv和Di的平衡。否则,随着训练的进行,一个判别器的强项或弱点最终将导致另一个判别器的低效率。在我们的工作中,平衡是通过网络架构和训练策略的设计来实现的(如第 V-A 节所述)。
判别器 Dv 和 Di 共享相同的架构,与生成器架构相比,其设置复杂度较低,如图 3 所示。所有卷积层的步长设置为 2。在最后一层,我们采用 tanh激活函数生成一个标量,该标量从源图像而不是 G 估计输入图像的概率。
四.医学图像融合的应用
在本节中,我们将提出的方法应用于医学图像的融合,如MRI和PET图像的融合。我们将伪彩色显示的PET图像视为彩色图像,并应用DDcGAN对高分辨率MRI图像和PET图像的低分辨率强度分量进行融合。下面,我们首先介绍医学图像融合的背景,然后以MRI和PET图像融合为例,给出一些实现细节。
A.背景
多模态医学图像具有提供多样化特征以增强鲁棒性和准确性的优点,因此,它们的融合为生物医学研究和临床应用(例如医学诊断、监测和治疗)提供了强大的工具[38], [39]。这些医学成像可以分为结构系统和功能系统[40]。运动结构方法[41]通常用于获取自然图像域中的结构信息。而在医学成像中,X射线、MRI和计算机断层扫描是典型的结构系统,可以提供高分辨率的结构和解剖信息。功能系统可以提供功能和代谢信息,例如PET和单光子发射计算机断层扫描,但这些图像往往分辨率较低。有限的分辨率限制了它们的临床应用,并鼓励功能和解剖图像的融合。
根据所应用的理论,现有的医学融合方法可以归纳为不同的类别,例如替换方法[40]、[42]、算术组合方法[43]和多分辨率方法[44]、[45]。在本文中,我们以 MRI 和 PET 图像融合为例,应用我们的 DDcGAN 来解决这个问题。 MRI 图像在以高空间分辨率捕获大脑、心脏和肺等器官中软组织结构的细节方面具有优势。
PET 图像通过核医学成像获得,以提供功能和代谢信息,例如血流和洪水活动。捕获的图像通常色彩丰富但空间分辨率较低。因此,通过融合这两类医学图像,结果将包含源图像中的空间和光谱特征,以进行定性检测和定量确定。传统上将伪彩色PET图像视为彩色图像,颜色是功能信息的表示,如图4(a)所示。为了保留它,融合图像的颜色应尽可能与 PET 图像的颜色相似。为此,使用去相关颜色模型将颜色中的消色差和彩色信息分离到不同的通道中。然后,消色差通道被 MRI 图像替代或融合 [46]。在我们的工作中,我们采用强度、色调和饱和度(IHS)去相关颜色模型,强度通道是要融合的特定消色差通道,如图4(b)所示。由于另外两个通道是色彩信息的表示,在融合过程中应保持不变,因此PET图像与红外图像类似,都是用强度分布来表示特征信息。稍微不同的一点是,PET图像用它来表示功能信息,而红外图像是热辐射的反射。相比之下,MRI图像可以以纹理的形式提供详细的形态学信息。它的主要特征是梯度。因此,与可见图像一样,可以利用MRI图像中纹理信息丰富的优势来克服PET图像上软组织结构轮廓的不确定性。从这个角度来看,MRI和PET图像的融合与可见光和红外图像的融合在本质上有很大的相似性。如图4所示,融合后的图像应该同时最小化由MRI(图4(c))和强度通道(图4(d))之间的空间细节损失引起的空间畸变,以及由PET(图4(b))和融合后的强度通道(图4(d))之间的色差引起的光谱畸变。再加上经过处理的H和S通道分量,最终融合后的图像为三通道图像,具有丰富的色彩和细节信息,如图4(e)所示。
B.通过DDcGAN进行MRI和PET图像融合
统一地,我们假设MRI图像的分辨率是PET图像强度分量的4×4倍,并以此为例。整个融合过程如图5所示。首先将具有RGB通道的多光谱输入PET图像转换为IHS通道,如式(1)所示。 (13) 强度通道显示光谱的亮度,色调通道显示光谱波长的特性,饱和度通道显示光谱的纯度:

融合过程是在PET图像和MRI图像的I通道分量上产生的。相应地,生成器的输入是低分辨率IPET和高分辨率MRI图像M。生成器的输出Ifuse = G(M,IPET)是高分辨率融合图像的新I通道。在训练过程中,训练判别器 Di 来区分 Ifuse 和 IPET 之间的差异,而输入图像来自 MRI 图像而不是 G 的概率由判别器 Dv 获得。因此,生成器的具体损失函数可以表示为:
![]()
其中对抗性损失函数 Ladv G 定义为:
为了保留PET图像中的彩色信息,PET图像和融合图像的H、S通道分量应尽可能相同。对于这两个通道,我们直接采用双三次插值作为上采样操作。上采样分量分别表示为Hnew和snnew,分辨率均为HPET和SPET的4 × 4倍。由Eq.(14)和Eq.(15)可知,变量V1和V2可以通过H和S通道的分量更新:

五、实验结果
在本节中,为了验证我们的 DDcGAN 的有效性,我们首先通过红外和可见光图像融合以及 PET 和 MRI 图像融合的定性比较,将其与公开数据集上的几种最先进的方法进行比较。为了进行定量比较,我们利用六个指标来评估融合结果。还进行了判别器分析实验。
A. 数据集和训练细节
1) 数据集:我们在公开的 TNO 人为因素数据集1上验证了所提出的 DDcGAN,用于红外和可见光图像融合。我们从数据集中选择 36 个红外和可见光图像对,并将它们裁剪成 27、264 个 84 × 84 像素的块对。由于我们专注于融合不同分辨率的图像,而数据集中的源图像具有相同的分辨率,因此我们将红外图像下采样到四分之一分辨率。因此,所有可见图像块的大小为 84 × 84,所有红外图像块的大小为 21 × 21。我们模型中的参数设置为 λ = 0.5 和 η = 1.2。整个网络以 2 × 10−3 的学习率进行训练,并在每个时期后以指数方式衰减到原始值的 0.75。批量大小设置为 24。
我们提出的 DDcGAN 在 MRI 和 PET 图像融合中的应用在公开的哈佛医学院网站上得到了验证。2 原始 PET 和 MRI 图像的大小均为 256 × 256。为了验证我们的方法融合不同分辨率图像的有效性,将 PET 图像的每个通道下采样到 64×64 的大小。下载 83 个 PET 和 MRI 对并裁剪成 9, 984 个补丁对作为我们的训练集。同样,所有MRI斑块的大小为84×84,所有PET图像的强度斑块的大小为21×21。参数、学习率和批量大小与红外和可见光融合中设置的相同。
2)训练细节:训练过程中,原则是让生成器和判别器形成对抗关系。为了克服训练 GAN 时的一些问题,提高训练效果,原则上不是每批次轮流训练一次 G、Dv 和 Di,而是在 Dv 或 Di 无法区分 G 和 G 的情况下多次训练 Dv 或 Di,反之亦然。详细的训练过程如Alg所示。 1、除了Lmax、Lmin、LGmax之外,还额外设置了迭代次数的阈值。原因是多次更新生成器或判别器的目的是保持它们之间的平衡。然而,仍然存在这些网络经过多次训练但仍然无法达到平衡条件的情况。特别是对于生成器来说,更多的训练步骤来最小化对抗性损失可能会导致更高的内容损失和更高的 LG ,无法达到平衡条件。这样就可以避免算法陷入死循环。而且,及时更新其他网络,将使它们对现有网络发挥新的引导作用,从而有可能避免上述情况的发生。
在测试阶段,我们仅使用经过训练的生成器来生成融合图像。由于我们的生成器中没有完全连接的层,因此输入源图像可以是具有预定义分辨率的任何大小。
B. 红外和可见光图像融合的结果和分析
为了验证我们提出的 DDcGAN 的有效性,我们将其与七种最先进的图像融合方法进行比较,包括方向离散余弦变换和主成分分析(DDCTPCA)[14 ]、混合多尺度分解(HMSD)[47]、四阶偏微分方程(FPDE)[48]、梯度传递融合(GTF)[17]、不同分辨率总变分(DRTV)[49]、DenseFuse [29] 和 FusionGAN [21]。由于一些竞争对手要求源图像共享相同的分辨率,因此我们在执行这些融合方法之前对低分辨率红外图像进行上采样。而在DRTV和FusionGAN中,由于它们可以应用于融合不同分辨率的图像,因此不需要对低分辨率红外图像进行上采样的预处理。所有方法的融合结果均经过主观和客观评估。
1)定性比较:我们首先报告了六个典型图像对的一些直观结果,如图6所示。与现有的融合方法相比,我们的DDcGAN具有三个独特的优势。首先,我们的结果可以保持红外图像的高对比度特性,例如,热目标在我们的融合图像中很突出,如第一和第二个示例所示,这对于后续的目标检测任务非常重要。其次,我们的结果可以保留可见图像中丰富的纹理细节,例如,融合图像中的背景包含更多细节信息,如第三到第五示例所示,这有利于准确的目标识别。第三,我们的结果更加清晰,因为它不会受到低分辨率红外图像上采样导致的热辐射信息模糊的影响,如第六个示例所示。
从图6可以看出,DDCTPCA、HMSD、FPDE和DenseFuse不能很好地突出热目标,而GTF、DRTV和fusongan不能获得丰富的纹理细节。此外,除DRTV和fusionongan外,它们都存在热辐射信息模糊的问题。虽然DRTV在融合不同分辨率的源图像时可以避免因上采样而造成的纹理信息丢失,但由于一阶TV的应用,DRTV的融合结果不可避免地会出现阶梯效应。相比之下,DDcGAN的结果可以明显避免楼梯效应,我们的结果中的细节更接近于可见图像。与fusion - an相比,由于采用了反卷积层,引入了判别器Di,采用了不同的网络结构,改进了训练策略,融合结果能够以更高的对比度更明显地突出热目标,同时包含了更多与可见图像更难以区分的自然细节。排除反卷积层、不同网络架构和训练策略的影响,附加鉴别器的影响将在稍后的V-B.3节中分析。总的来说,我们的DDcGAN效果很好,融合后的图像更接近于超分辨红外图像,同时也包含了可见光图像中丰富的纹理细节信息。
2)定量比较:我们进一步报告了我们的DDcGAN和竞争对手在数据集中剩下的15对图像上的定量比较。采用熵(EN)[50]、平均梯度(MG)、空间频率(SF)、标准差(SD)[51]、峰值信噪比(PSNR)、相关系数(CC)、结构相似指数(SSIM)[52]、视觉信息保真度(VIF)[53]等8个指标进行评价。
• 熵(EN):该指标可以从信息论的角度衡量融合图像中包含的信息量,定义如下:
![]()
其中 pl 表示融合图像中相应灰度级的归一化直方图。并将所有灰度级的数量设置为L。熵越大,意味着图像中保留了更多的信息,该方法取得了更好的性能。
• 平均梯度 (MG):MG 在数学上定义为:

MG越大,图像包含的梯度信息越多,算法的融合性能越好。
• 空间频率(SF):SF基于梯度分布,有效揭示细节和纹理的图像。它由空间行频率 (RF) 和列频率 (CF) 定义:

• 标准偏差(SD):SD 是反映对比度和分布的指标。人的注意力更容易被对比度高的区域吸引。因此,SD越大,融合图像的视觉效果越好。在数学上,SD 定义为:

•峰值信噪比(PSNR):PSNR是通过峰值功率与噪声功率的比值反映失真度的指标:

• 相关系数(CC):CC 度量衡量源图像与融合图像之间的线性相关程度。它在数学上定义为:

• 结构相似性指数度量(SSIM):SSIM 是广泛使用的度量标准,它根据两幅图像在光线、对比度和结构信息方面的相似性对它们之间的损失和失真进行建模。从数学上讲,图像 x 和 y 之间的 SSIM 可以定义如下:


• 视觉信息保真度(VIF):该指标与人类视觉系统一致,衡量信息保真度。它可以通过四个步骤来计算:(a)对源图像和融合图像进行过滤并将其划分为不同的块; (b)评估每个块的视觉信息; (c) 计算每个子带的VIF; (d) 计算总体指标。 VIF大表明融合方法具有良好的性能。
定量比较的结果如图 7 所示。从统计结果可以看出,我们的 DDcGAN 可以在前 4 个指标上生成最大平均值:EN、MG、SF 和 SD。特别是,我们的 DDcGAN 分别在 13、13、10 和 8 个图像对上实现了 EN、MG、SF 和 SD 的最佳值。对于度量 PSNR 和 CC,我们的 DDcGAN 可以达到可比较的结果,平均值是第二大的。这些指标仅以微弱差距落后于 FPDE 和 FusionGAN。至于VIF和SSIM,我们的结果分别是第三和第四。结果表明,该方法可以最大程度地保留信息,特别是保留最多的梯度信息、最丰富的边缘和纹理细节以及最高的对比度,如前四个指标所示。此外,我们的方法的结果可以达到与源图像相当的相似度。
表1提供了不同方法在测试数据上的平均运行时间。所有方法均在具有3.4 GHz Intel Core i5 CPU的台式机上进行测试。由于存在三种基于深度学习的方法(即 DenseFuse、FusionGAN 和 DDcGAN),因此这些方法也在 NVIDIA Geforce GTX Titan X 上进行了测试。DDcGAN 的运行时间较慢的原因是在测试阶段,输入我们的模型是整个图像。因此,对于每个测试图像对,我们的模型根据其大小进行重建,并将训练模型的参数恢复到重建模型中,以避免将测试图像裁剪成补丁可能导致的接缝效应以及调整图像大小导致的失真。另一个原因是我们的模型比其他基于深度学习的方法更深,从而导致更多的测试运行时间。
3)判别器分析:我们提出的模型中有两个判别器,即 Dv 和 Di 。为了说明每个判别器的效果,我们进行了四个比较实验:(a)整个网络仅由生成器G组成,并且最终的训练目标被减少以最小化等式(1)中的Lcon。 (10)。 (b) 不使用 Di ,仅在 G 和 Dv 之间存在对抗关系。 (c) Dv 并未被整个网络所接受。由此,G和Di之间建立了对抗博弈。 (d) 融合图像是通过本文提出的方法生成的。所有 G、Dv 和 Di 在网络中都发挥作用。所有对比实验均在相同的实验设置下进行,融合结果如图8所示。
在方法(a)中,训练目标是最小化内容损失Lcon,其本质上是一阶电视模型。该模型在保留分段恒定图像中对象的边缘方面表现良好,但不可避免地会产生阶梯效应[54],如图8(a)所示。随着 Dv 的引入,图 8(b) 中的阶梯效应得到了缓解。然而,其缺点是融合图像的强度分布根据可见图像的强度分布进行修改,导致热目标的突出度降低。单独引入 Di 增加了热目标和背景之间的对比度,这在图 8(a) 和图 8(c) 所示结果之间的掩体突出中尤为明显。然而,与方法(b)相比,方法(c)的结果缺乏详细信息。
综合考虑方法(b)和(c)的优缺点,我们提出了一种基于对偶鉴别器条件生成对抗网络的新结构:Dv和Di。使用Di可以纠正方法(b)的结果与红外图像之间强度分布的明显差异。同时,通过引入Dv,可以在方法(c)的结果中添加更多的细节和纹理信息。值得注意的是,由于判别器从单纯的Dv或Di增加到两者都增加,对生成器的要求和训练目标变得更加苛刻。在Dv和Di的识别任务之间存在矛盾关系的情况下,根据图1中的训练策略,在G、Dv或Di中的任何一个失去其特定功能时,可以调整其训练,进一步提高发电机的生成能力。在热目标仍然突出的前提下,与图8(b)和(c)相比,方法(d)的结果包含了更多的细节,通过有效地解决楼梯效应问题,这些细节看起来更接近可见光图像。
4)生成器分析:生成器G的损失函数中有两个子项,即对抗性损失Ladv G和内容损失Lcon。为了验证每个子项的效果,进行了三个对比实验:(a)LG = λLcon。该对比实验与第2节中的方法(a)相同。 V-B.3。 G 被训练以最小化方程中的 Lcon。 (10)。 (b) LG = Ladv G 。 LG并未引入内容丢失。那么G只是被训练来愚弄Dv和Di。需要注意的是,在该方法中,由于缺乏逐像素约束,引入了反卷积层数可能会导致空腔效应。因此,我们用两个上采样层替换这些层以避免这种影响。 (c) LG = Ladv G + λLcon。这是建议的方法。在相同的实验设置下,这三种方法的融合结果如图9所示。
一方面,在没有对抗性损失的情况下,融合结果无法在可见图像中展现更多、更清晰的纹理细节,如图9(a)所示。另一方面,在没有内容丢失的情况下,生成器无法知道应从源图像中保留哪种类型的信息。在没有像素级约束的情况下,生成器可以做的就是使生成图像的概率分布接近源图像的概率分布。在这种情况下,融合图像可能具有高对比度和纹理细节。然而,突出显示的区域可能不是红外图像中的热目标,并且纹理细节可能与可见光图像不同,如图9(b)所示。因此,当 DDcGAN 在没有内容丢失的情况下进行训练时,它将产生伪影和难以理解的结果。通过结合这两个子项,DDcGAN 可以解决这个问题并生成高质量的融合图像,如图 9(c) 所示。
C. MRI 和 PET 图像融合的结果
根据相应的方案,我们分别基于主成分分析方法(如 DDCTPCA [14])、稀疏表示方法(如自适应稀疏表示(ASR)[56])将我们的方法与其他六种融合方法进行比较。 ]、小波变换方法,如离散余弦谐波小波变换(DCHWT)[55]、显着性方法,如 Structure-Aware [57] 和基于深度学习的方法,如 FusionGAN [21]和 RCGAN [58]。其中,PCA是应用于PET和MRI图像融合的经典理论。基于 PCA 并作为第 2 节中使用的红外和可见光图像融合比较方法的代表。这里再次采用V-B、DDCTPCA进行比较。 ASR可以应用于多模态图像融合,同时进行融合和去噪。 DCHWT考虑了多光谱图像融合的融合。 Structure-Aware 是一种专门针对多模态医学图像融合提出的方法。 FusionGAN和RCGAN是基于GAN的方法,也是红外和可见光图像融合方法的代表。
在本节的其余部分中,进行定性和定量实验来证明我们的方法在 PET 和 MRI 图像融合方面的有效性。
1)定性比较:图10展示了大脑半球四个不同横断面的四个典型且直观的结果。相比之下,DCHWT、Structure-Aware和RCGAN显着降低了PET 图像中的颜色强度,导致功能信息丢失。相比之下,DDCTPCA、ASR、FusionGAN 和 DDcGAN 生成的结果表现出更明亮、更强的颜色。在这四种方法中,我们结果的颜色与原始 PET 图像的颜色最接近。此外,由于低分辨率PET图像的去采样,六种比较方法的结果都存在功能信息模糊,表现为颜色信息模糊(如第一组和第二组结果所示)和细节模糊,这可以可见第三组结果。就MRI图像保留的纹理信息而言,DDCTPCA和FusionGAN的结果表现出最明显的模糊性。而且,由于ASR同时进行融合和去噪,MRI图像中的杂质在融合图像中被消除。然而,一些图像细节同时变得模糊。与 DCHWT、Structure-Aware 和 RCGAN 相比,我们结果中的细节避免了模糊以及由于颜色较深而导致的识别困难,这可以在第四组中看到。
2)定量比较:这里进行了8个性能指标的实验,20个测试图像对的定量比较结果如图11所示。20个测试图像对是大脑半球的不同横断面。对于前五个指标:EN、MG、SF、SD 和 PSNR,我们提出的方法可以实现最大平均值,所有 20 个测试对中分别有 19、19、10、14 和 20 个表现最佳。至于指标 CC 和 VIF,我们的方法也显示了可比的结果,产生了第二大平均值,其平均值仅分别落后于 DDCTPCA 和 FusionGAN 的平均值。至于SSIM,我们的方法生成第五大平均值,原因是我们的方法旨在保留MRI图像中的梯度变化,而不管像素强度如何,导致融合强度通道和MRI之间的SSIM值很小图像。因此,从统计结果可以得出结论,对于PET和MRI图像融合,我们的方法通过保留纹理信息(即形态信息)和颜色信息(即功能和代谢信息)来获得相对满意的结果。很大程度同时。
表 II 还报告了 6 种方法在 20 个测试图像对上的平均运行时间。

六.结论
在本文中,我们通过构建双判别器条件 GAN 提出了一种新的基于深度学习的红外和可见光图像融合方法,称为 DDcGAN。它不需要真实的融合图像进行训练,并且可以融合不同分辨率的图像,而不会引入热辐射信息模糊或可见纹理细节损失。对六个指标与其他七种最先进的融合算法的广泛比较表明,我们的 DDcGAN 不仅可以识别最有价值的信息,而且可以保留源图像中最大或近似最大的信息量。此外,我们提出的DDcGAN应用于PET和MRI图像的融合,与五种最先进的算法相比,它还可以实现先进的性能。


图 2.我们的生成器的整体架构,包括编码器层和解码器层。 3 × 3:滤波器大小,Conv(nk):获得k个特征图的卷积层,BN:批量归一化。

图 3.我们的判别器的整体架构。 3 × 3:滤波器大小,Conv(nk):获得k个特征图的卷积层,BN:批量归一化,FC:全连接层。

图4 将RGB通道中的低分辨率PET图像与灰度通道中的高分辨率MRI图像融合以获得RGB通道中的高分辨率融合图像的示意图。

图 5. 应用所提出的 DDcGAN 进行 MRI 和 PET 图像融合的整个过程。
相关文章:
DDcGAN_多分辨率图像融合的双鉴别条件生成对抗网络_y译文马佳义
摘要: 在本文中,我们提出了一种新的端到端模型,称为双鉴别条件生成对抗网络(DDcGAN),用于融合不同分辨率的红外和可见光图像。我们的方法建立了一个生成器和两个鉴别器之间的对抗博弈。生成器的目的是基于特…...

[读书日志]从零开始学习Chisel 第一篇:书籍介绍,Scala与Chisel概述,Scala安装运行(敏捷硬件开发语言Chisel与数字系统设计)
简介:从20世纪90年代开始,利用硬件描述语言和综合技术设计实现复杂数字系统的方法已经在集成电路设计领域得到普及。随着集成电路集成度的不断提高,传统硬件描述语言和设计方法的开发效率低下的问题越来越明显。近年来逐渐崭露头角的敏捷化设…...

二、用例图
二、用例图 (一)、用例图的基本概念 1、用例图的定义: 用例图是表示一个系统中用例与参与者关系之间的图。它描述了系统中相关的用户和系统对不同用户提供的功能和服务。 用例图相当于从用户的视角来描述和建模整个系统,分析系统的功能与…...

LWIP之一:使用STM32CubeMX搭建基于FreeRTOS的LWIP工程并分析协议栈初始化过程
工程搭建及LWIP协议栈初始化过程 一、使用STM32CubeMX快速生成工程二、修改测试三、LWIP协议栈初始化过程分析3.1 tcpip_init()3.1.1 lwip_init()3.1.1.1 sys_init()3.1.1.2 mem_init()3.1.1.3 memp_init()3.1.1.4 netif_init()3.1.1.5 udp_init()3.1.1.6 tcp_init()3.1.1.7 ig…...

个性化电影推荐系统|Java|SSM|JSP|
【技术栈】 1⃣️:架构: B/S、MVC 2⃣️:系统环境:Windowsh/Mac 3⃣️:开发环境:IDEA、JDK1.8、Maven、Mysql5.7 4⃣️:技术栈:Java、Mysql、SSM、Mybatis-Plus、JSP、jquery,html 5⃣️数据库可…...

UE5AI感知组件
官方解释: AI感知系统为Pawn提供了一种从环境中接收数据的方式,例如噪音的来源、AI是否遭到破坏、或AI是否看到了什么。 AI感知组件(AIPerception Component)是用于实现游戏中的非玩家角色(NPC)对环境和其…...
)
每日一学——日志管理工具(ELK Stack)
5.1 ELK Stack 5.1.1 Elasticsearch索引机制 嘿,小伙伴们!今天我们要聊聊ELK Stack——一套由Elasticsearch、Logstash和Kibana组成的强大日志管理工具集。通过这套工具,我们可以轻松地收集、存储、搜索和可视化日志数据。首先,…...

“智能筛查新助手:AI智能筛查分析软件系统如何改变我们的生活
嘿,朋友们!今天咱们来聊聊一个特别厉害的工具——AI智能筛查分析软件系统。想象一下,如果你有一个超级聪明的小助手,不仅能帮你快速找出问题的关键所在,还能提供精准的解决方案,是不是感觉工作和生活都变得…...

DeepSeek v3为何爆火?如何用其集成Milvus搭建RAG?
最近,DeepSeek v3(一个MoE模型,拥有671B参数,其中37B参数被激活)模型全球爆火。 作为一款能与Claude 3.5 Sonnet,GPT-4o等模型匹敌的开源模型DeepSeek v3不仅将其算法开源,还放出一份扎实的技术…...

linux-centos-安装miniconda3
参考: 最新保姆级Linux下安装与使用conda:从下载配置到使用全流程_linux conda-CSDN博客 https://blog.csdn.net/qq_51566832/article/details/144113661 Linux上删除Anaconda或Miniconda的步骤_linux 删除anaconda-CSDN博客 https://blog.csdn.net/m0_…...

html+css+js网页设计 美食 好厨艺西餐美食企业网站模板6个页面
htmlcssjs网页设计 美食 好厨艺西餐美食企业网站模板6个页面 网页作品代码简单,可使用任意HTML辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad 等任意html编辑软件进行运行及修改编辑等操作)。 …...

QT-窗口嵌入外部exe
窗口类: #pragma once #include <QApplication> #include <QWidget> #include <QVBoxLayout> #include <QProcess> #include <QTimer> #include <QDebug> #include <Windows.h> #include <QWindow> #include <…...
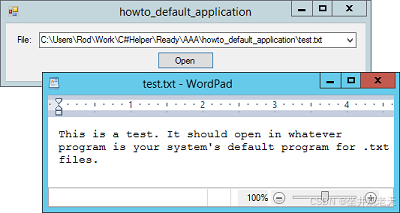
C#中使用系统默认应用程序打开文件
有时您可能希望程序使用默认应用程序打开文件。 例如,您可能希望显示 PDF 文件、网页或互联网上的 URL。 System.Diagnostics.Process类的Start方法启动系统与文件关联的应用程序。 例如,如果文件扩展名为.txt,则系统会在 NotePad、WordPa…...

如何在 Ubuntu 22.04 上配置 Logrotate 高级教程
简介 本教程将教你如何在 Ubuntu 22.04 上进行 Logrotate 的高级配置。 日志管理对于维护系统性能和确保你的日志不会占用太多磁盘空间至关重要。在 Ubuntu 上,logrotate 是一个强大的工具,它可以通过轮转、压缩和删除旧日志来自动管理日志文件。在本教…...

java项目之校园管理系统的设计与实现(源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的校园管理系统的设计与实现。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: springboot校园…...

关于 webservice 日志中 源IP是node IP的问题,是否能解决换成 真实的客户端IP呢
本篇目录 1. 问题背景2. 部署gitlab 17.52.1 添加repo源2.2 添加repo源 下载17.5.0的charts包2.3 修改values文件2.3.1 hosts修改如下2.3.2 appConfig修改如下2.3.3 gitlab下的sidekiq配置2.3.4 certmanager修改如下2.3.5 nginx-ingress修改如下2.3.6 <可选> prometheus修…...

Serializable接口
最近写项目的时候,发现有一些类要实现Serializable接口,一开始只是粗略的知道实现了Serializable接口,这个类的对象可以被序列化,但我比较轴,想知道这个接口到底有什么作用。 我点开这个接口发现什么方法都没有实现&am…...

如何操作github,gitee,gitcode三个git平台建立镜像仓库机制,这样便于维护项目只需要维护一个平台仓库地址的即可-优雅草央千澈
如何操作github,gitee,gitcode三个git平台建立镜像仓库机制,这样便于维护项目只需要维护一个平台仓库地址的即可-优雅草央千澈 问题背景 由于我司最早期19年使用的是gitee,因此大部分仓库都在gitee有几百个库的代码,…...
)
【HDU】1089 A+B for Input-Output Practice (I)
1089 AB for Input-Output Practice (I):以EOF结尾的输入 Problem Description Your task is to Calculate a b. Too easy?! Of course! I specially designed the problem for acm beginners. You must have found that some problems have the same titles with this one,…...

lua库介绍:数据处理与操作工具库 - leo
leo库简介 leo 模块的创作初衷旨在简化数据处理的复杂流程,提高代码的可读性和执行效率,希望leo 模块都能为你提供一系列便捷的工具函数,涵盖因子编码、多维数组创建、数据框构建、列表管理以及管道操作等功能。 要使用 Leo 模块,…...

TDD-LTE系统时序精解:从TA、GP到覆盖与拉远的实战推演
1. TDD-LTE系统时序基础:从TA到GP的底层逻辑 第一次接触TDD-LTE的时序参数时,我被TA(时间提前量)和GP(保护间隔)这两个概念绕得头晕。直到在实地测试中遇到基站无法同步的问题,才真正理解它们的…...

【全球AGI就业影响实证研究】:覆盖42国、1.8亿岗位数据,揭示“抗AI职业”的3大黄金特征
第一章:AGI与就业市场的未来变化 2026奇点智能技术大会(https://ml-summit.org) 通用人工智能(AGI)的实质性突破正从理论推演加速迈向系统级工程实践,其对就业结构的影响已不再局限于重复性任务替代,而是深入知识生产…...

解锁喜马拉雅VIP音频:xmly-downloader-qt5 一站式下载攻略 [特殊字符]
解锁喜马拉雅VIP音频:xmly-downloader-qt5 一站式下载攻略 🎧 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 …...
)
全球仅7家机构掌握的超级智能触发判据(AGI阶段不可见,但已悄然启动)
第一章:全球仅7家机构掌握的超级智能触发判据(AGI阶段不可见,但已悄然启动) 2026奇点智能技术大会(https://ml-summit.org) 这些判据并非传统意义上的性能指标,而是嵌入在超大规模推理链中的隐式元认知跃迁信号——它…...

Qwen3-Reranker-8B长文本处理技巧:突破32K上下文限制
Qwen3-Reranker-8B长文本处理技巧:突破32K上下文限制 1. 引言 处理长文本一直是AI模型面临的一大挑战。传统的文本处理模型往往受限于上下文长度,当面对几十页的文档、长篇报告或大量数据时,往往力不从心。Qwen3-Reranker-8B的出现改变了这…...

07 论火箭回收的逆向思维落地方法 混沌篇:全流程混沌变量识别、建模与量化管控方案
论火箭回收的逆向思维落地方法 混沌篇:全流程混沌变量识别、建模与量化管控方案(总12篇第7篇) 摘要 本文承接第六篇火箭回收核心分系统技术指标体系,基于逆向反推工程逻辑,对运载火箭垂直回收全流程确定性扰动、随机不…...

# 发散创新:基于A*算法的AI寻路优化实战与多层启发式设计在游戏开发、机器人路径规划和自动驾驶等场景中,*
发散创新:基于A*算法的AI寻路优化实战与多层启发式设计 在游戏开发、机器人路径规划和自动驾驶等场景中,高效、智能的寻路算法是核心竞争力之一。传统BFS/DFS虽简单但效率低;Dijkstra虽然保证最短路径却牺牲了性能。而A*(A-Star&a…...
)
PyCharm索引卡在99%?可能是Conda环境路径在作怪(Windows 10/11排查指南)
PyCharm索引卡在99%?深度解析Conda环境路径冲突与高效排查方案 当PyCharm的进度条在即将完成索引时突然停滞,那种感觉就像看一部悬疑片卡在最后一分钟——明明答案近在咫尺,却始终无法揭晓。这种"99%魔咒"背后,往往隐藏…...

▲D2D通信中基于Qlearning强化学习算法的联合资源分配与功率控制算法matlab仿真
目录 📶1.引言 🧠2.系统模型 2.1 网络拓扑 2.2 信号与干扰模型 2.3 容量与吞吐量 2.4 优化目标 ✅3.基于Q学习的联合资源分配与功率控制算法原理 3.1 状态空间定义 3.2 动作空间定义 3.3 奖励函数设计 3.4 Q值更新规则 📚4.MATLA…...

趋势预测化技术中的技术趋势行业趋势与市场趋势
趋势预测技术:洞察未来的关键力量 在数字化时代,趋势预测技术已成为企业、行业乃至国家制定战略的重要工具。通过大数据分析、人工智能和机器学习等技术,趋势预测能够帮助人们提前捕捉技术、行业与市场的动态变化,从而抢占先机。…...