AMP 混合精度训练中的动态缩放机制: grad_scaler.py函数解析( torch._amp_update_scale_)
AMP 混合精度训练中的动态缩放机制
在深度学习中,混合精度训练(AMP, Automatic Mixed Precision)是一种常用的技术,它利用半精度浮点(FP16)计算来加速训练,同时使用单精度浮点(FP32)来保持数值稳定性。为了在混合精度训练中避免数值溢出,PyTorch 提供了一种动态缩放机制来调整 “loss scale”(损失缩放值)。本文将详细解析动态缩放机制的实现原理,并通过代码展示其内部逻辑。
动态缩放机制简介
动态缩放机制的核心思想是通过一个可动态调整的缩放因子(scale factor)放大 FP16 的梯度,从而降低舍入误差对训练的影响。当检测到数值不稳定(例如 NaN 或无穷大)时,缩放因子会被降低;当连续多步未检测到数值问题时,缩放因子会被提高。其调整策略基于以下两个参数:
growth_factor: 连续成功步骤后用于增加缩放因子的乘数(通常大于 1,如 2.0)。backoff_factor: 检测到数值溢出时用于减少缩放因子的乘数(通常小于 1,如 0.5)。
此外,动态缩放还使用 growth_interval 参数控制连续成功步骤的计数阈值。当达到这个阈值时,缩放因子才会增加。
AMP 缩放更新核心代码解析
PyTorch 实现了一个用于更新缩放因子的 CUDA 核函数以及相关的 Python 包装函数。以下是核心代码解析:
CUDA 核函数实现
// amp_update_scale_cuda_kernel 核函数实现
__global__ void amp_update_scale_cuda_kernel(float* current_scale,int* growth_tracker,const float* found_inf,double growth_factor,double backoff_factor,int growth_interval) {if (*found_inf) {// 如果发现梯度中存在 NaN 或 Inf,缩放因子乘以 backoff_factor,并重置 growth_tracker。*current_scale = (*current_scale) * backoff_factor;*growth_tracker = 0;} else {// 未发现数值问题,增加 growth_tracker 的计数。auto successful = (*growth_tracker) + 1;if (successful == growth_interval) {// 当 growth_tracker 达到 growth_interval,尝试增长缩放因子。auto new_scale = static_cast<float>((*current_scale) * growth_factor);if (isfinite_ensure_cuda_math(new_scale)) {*current_scale = new_scale;}*growth_tracker = 0;} else {*growth_tracker = successful;}}
}
核函数逻辑
-
发现数值溢出(
found_inf > 0):- 缩放因子
current_scale乘以backoff_factor。 - 重置成功计数器
growth_tracker为 0。
- 缩放因子
-
未发现数值溢出:
- 增加成功计数器
growth_tracker。 - 如果
growth_tracker达到growth_interval,则将缩放因子乘以growth_factor。 - 保证缩放因子不会超过 FP32 的数值上限。
- 增加成功计数器
C++ 包装函数实现
在 PyTorch 中,这一 CUDA 核函数通过 C++ 包装函数 _amp_update_scale_cuda_ 被调用。以下是实现代码:
Tensor& _amp_update_scale_cuda_(Tensor& current_scale,Tensor& growth_tracker,const Tensor& found_inf,double growth_factor,double backoff_factor,int64_t growth_interval) {TORCH_CHECK(growth_tracker.is_cuda(), "growth_tracker must be a CUDA tensor.");TORCH_CHECK(current_scale.is_cuda(), "current_scale must be a CUDA tensor.");TORCH_CHECK(found_inf.is_cuda(), "found_inf must be a CUDA tensor.");// 核函数调用amp_update_scale_cuda_kernel<<<1, 1, 0, at::cuda::getCurrentCUDAStream()>>>(current_scale.mutable_data_ptr<float>(),growth_tracker.mutable_data_ptr<int>(),found_inf.const_data_ptr<float>(),growth_factor,backoff_factor,growth_interval);C10_CUDA_KERNEL_LAUNCH_CHECK();return current_scale;
}
Python 调用入口
AMP 的 GradScaler 类通过 _amp_update_scale_ 函数更新缩放因子,以下是相关代码:
代码来源:anaconda3/envs/xxxx/lib/python3.10/site-packages/torch/amp/grad_scaler.py
具体调用过程可以参考笔者的另一篇博文:PyTorch到C++再到 CUDA 的调用链(C++ ATen 层) :以torch._amp_update_scale_调用为例
def update(self, new_scale: Optional[Union[float, torch.Tensor]] = None) -> None:"""更新缩放因子"""if not self._enabled:return_scale, _growth_tracker = self._check_scale_growth_tracker("update")if new_scale is not None:# 设置用户定义的新缩放因子。self._scale.fill_(new_scale)else:# 收集所有优化器中的 found_inf 数据。found_infs = [found_inf.to(device=_scale.device, non_blocking=True)for state in self._per_optimizer_states.values()for found_inf in state["found_inf_per_device"].values()]found_inf_combined = found_infs[0]if len(found_infs) > 1:for i in range(1, len(found_infs)):found_inf_combined += found_infs[i]# 更新缩放因子。torch._amp_update_scale_(_scale,_growth_tracker,found_inf_combined,self._growth_factor,self._backoff_factor,self._growth_interval,)
总结
PyTorch 的动态缩放机制通过 CUDA 核函数和 Python 包装函数协作完成。其核心逻辑是:
- 检测数值不稳定(如 NaN 或 Inf),通过缩小缩放因子提高数值稳定性。
- 当连续多次未出现数值不稳定时,逐步增大缩放因子以充分利用 FP16 的动态范围。
- 所有更新操作都在 GPU 上异步完成,最大限度地减少同步开销。
通过动态调整缩放因子,AMP 有效地加速了深度学习模型的训练,同时避免了梯度溢出等数值问题。
推荐阅读
- PyTorch 官方文档
- 混合精度训练介绍
后记
2025年1月2日15点38分于上海,在GPT4o大模型辅助下完成。
相关文章:
)
AMP 混合精度训练中的动态缩放机制: grad_scaler.py函数解析( torch._amp_update_scale_)
AMP 混合精度训练中的动态缩放机制 在深度学习中,混合精度训练(AMP, Automatic Mixed Precision)是一种常用的技术,它利用半精度浮点(FP16)计算来加速训练,同时使用单精度浮点(FP32…...
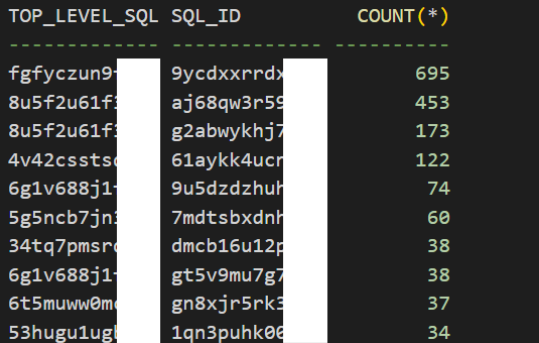
Oracle数据库如何找到 Top Hard Parsing SQL 语句?
有一个数据库应用程序存在过多的解析问题,因此需要找到产生大量硬解析的主要语句。 什么是硬解析 Oracle数据库中的硬解析(Hard Parse)是指在执行SQL语句时,数据库需要重新解析该SQL语句,并创建新的执行计划的过程。这…...

Mono里运行C#脚本25—mono_codegen
前面分析怎么样找到主函数Main的入口点功能,也就是说已经找到了这个函数的CIL代码。虽然找到了代码,但是还不能执行它的,因为它是一种虚拟机的代码。也就是说它是假的代码,不是现实世界存在的机器的代码,因此不能直接执行,必须经过后端编译器的再次编译才能真正运行它。下…...

flink cdc oceanbase(binlog模式)
接上文:一文说清flink从编码到部署上线 环境:①操作系统:阿里龙蜥 7.9(平替CentOS7.9);②CPU:x86;③用户:root。 预研初衷:现在很多项目有国产化的要求&#…...

【WPF】 数据绑定机制之INotifyPropertyChanged
INotifyPropertyChanged 是 WPF 中的一个接口,用于实现 数据绑定 中的 属性更改通知。它的主要作用是,当对象的某个属性值发生更改时,通知绑定到该属性的 UI 控件更新其显示内容。 以下是有关 INotifyPropertyChanged 的详细信息和实现方法&…...
为例及实战应用)
机器学习算法深度解析:以支持向量机(SVM)为例及实战应用
机器学习算法深度解析:以支持向量机(SVM)为例及实战应用 在当今数据驱动的时代,机器学习作为人工智能的一个核心分支,正以前所未有的速度改变着我们的生活与工作方式。从金融风控到医疗诊断,从自动驾驶到智…...

网络编程基础:连接Java的秘密网络
1 网络编程的重要性 网络编程允许Java应用程序与其他计算机或设备进行通信。这包括从简单的数据传输到复杂的分布式系统和Web服务。 2 Java网络编程的核心类 Java提供了多个类来支持网络编程: InetAddress:表示网络上的IP地址。 URL:表示统…...

无监督学习:自编码器(AutoEncoder)
自编码器:数据的净化之旅 引言 自编码器作为一种强大的特征学习方法,已经经历了从简单到复杂的发展历程。本文综述了多种类型的自编码器及其演进过程,强调了它们在数据降维、图像处理、噪声去除及生成模型等方面的关键作用。随着技术的进步…...

在不到 5 分钟的时间内将威胁情报 PDF 添加为 AI 助手的自定义知识
作者:来自 Elastic jamesspi 安全运营团队通常会维护威胁情报报告的存储库,这些报告包含由报告提供商生成的大量知识。然而,挑战在于,这些报告的内容通常以 PDF 格式存在,使得在处理安全事件或调查时难以检索和引用相关…...

Memcached prepend 命令
Memcached prepend 命令用于向已存在 key(键) 的 value(数据值) 前面追加数据 。 语法: prepend 命令的基本语法格式如下: prepend key flags exptime bytes [noreply] value参数说明如下: key:键值 key-value 结构中的 key&a…...

Win10 VScode配置远程Linux开发环境
Windows VScode配置远程Linux开发环境 记录一下在Windows下VScode配置远程连接Linux环境进行开发的过程。 VScode的远程编程与调试的插件Remote Development,使用这个插件可以在很多情况下代替vim直接远程修改与调试服务器上的代码,搭配上VScode的语言…...

微信小程序校园自助点餐系统实战:从设计到实现
随着移动互联网的发展,越来越多的校园场景开始智能化、自助化。微信小程序凭借其轻量化、便捷性和强大的生态支持,成为了各类校园应用的首选工具之一。今天,我们将通过实际开发一个微信小程序“校园自助点餐系统”来展示如何设计和实现这样一…...

解决sublime编译无法输入问题
在使用sublime编译简单的c语言的时候,发现编译过程中,带有scanf的程序,无法正确的输入。 需要提前配置好gcc 和g++ 一、新增配置 新建编译系统文件:C.sublime-build 具体步骤:菜单中选择Tools——Build System——New Build System——保存文件名C.sublime-build ,填写以…...

const修饰指针总结
作者简介: 一个平凡而乐于分享的小比特,中南民族大学通信工程专业研究生在读,研究方向无线联邦学习 擅长领域:驱动开发,嵌入式软件开发,BSP开发 作者主页:一个平凡而乐于分享的小比特的个人主页…...

uniapp实现后端数据i18n国际化
1.在main.js配置请求获取到数据再设置到i18n中, 我这里是通过后端接口先获取到一个多个数据的的json链接,通过链接再获取数据,拿到数据后通过遍历的方式设置i18n //接口数据示例:{"vi": "http://localhost:8899/…...

什么是国密设计
国密设计,全称为“国家密码算法设计”,是指中国自主研发的一系列密码学算法和相关的技术标准。这些算法旨在提供安全可靠的加密、解密、签名验证等服务,并且在中国的信息安全领域中扮演着至关重要的角色。以下是关于国密设计的详细解释&#…...

Android IO 问题:java.io.IOException Operation not permitted
问题描述与处理策略 1、问题描述 java.io.IOException: Operation not permittedjava.nio.file.FileSystemException: /storage/emulated/0/test/test.txt: Operation not permittedjava.io.IOException: Operation not permitted:异常为操作不被允许 java.nio.f…...

安装bert_embedding遇到问题
在使用命令: pip install bert-embedding 安装bert_embedding的时候,遇到如下问题: ERROR: Failed cleaning build dir for numpy Successfully built gluonnlp Failed to build numpy ERROR: ERROR: Failed to build installable wheel…...

cka考试-03-k8s版本升级
一、原题 二、解答 [root@master ~]# kubectl get node NAME STATUS ROLES AGE VERSION master Ready control-plane,master 25h v1.22.12 node1 Ready worker 25h v1.22.12 node2 Ready worker …...

【insert 插入数据语法合集】.NET开源ORM框架 SqlSugar 系列
系列文章目录 🎀🎀🎀 .NET开源 ORM 框架 SqlSugar 系列 🎀🎀🎀 文章目录 系列文章目录一、前言 🍃二、插入方式 💯2.1 单条插入实体2.2 批量 插入实体2.3 根据字典插入2.4 根据 Dat…...
)
Gemini电脑版下载(gemini电脑下载)
Gemini 是由 Google 开发的一款原生桌面端人工智能助手,它是 Google 历代 AI 技术(如 Bard)的集大成者。如果你在日常工作中需要高频率调用 AI 来处理复杂任务,特别是那些涉及跨应用协同或海量数据分析的需求,那么 Gem…...

三分钟快速定位:Windows热键冲突终极解决方案指南
三分钟快速定位:Windows热键冲突终极解决方案指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经按…...

【踩坑实录】前端开发必看:一次由CSS缓存引发的线上事故与SEO反思
各位老铁,今天不聊虚的,来复盘一下我上周五晚上亲手制造的一场“线上事故”。作为一名前端开发,我一直以为接入CDN就是改个CNAME那么简单,直到我用实际行动证明了:不懂缓存策略,就是在给线上环境埋雷。一、…...

5分钟极速部署:为Windows 11 LTSC系统解锁微软商店完整生态
5分钟极速部署:为Windows 11 LTSC系统解锁微软商店完整生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 当企业管理员面对Windows 11 L…...
)
PSIM仿真实战:反激电源从理论到实现的5个关键步骤(附避坑指南)
PSIM仿真实战:反激电源从理论到实现的5个关键步骤(附避坑指南) 反激电源作为开关电源中的经典拓扑,凭借其结构简单、成本低廉的优势,在中小功率场景中占据重要地位。但纸上得来终觉浅,许多工程师在将理论转…...

如何为你的技术项目找到完美的编程语言图标?这50+高清资源库就是答案
如何为你的技术项目找到完美的编程语言图标?这50高清资源库就是答案 【免费下载链接】programming-languages-logos Programming Languages Logos 项目地址: https://gitcode.com/gh_mirrors/pr/programming-languages-logos 你是否在为技术文档、博客文章或…...

SITS2026前沿发布:如何用AI在3秒内生成高精准度代码告警?附可落地的Prompt工程模板
第一章:SITS2026前沿发布:如何用AI在3秒内生成高精准度代码告警?附可落地的Prompt工程模板 2026奇点智能技术大会(https://ml-summit.org) SITS2026正式开源了CodeGuardian v3.1——一个面向生产级代码静态分析的轻量级AI推理引擎ÿ…...

给产品经理和业务同学的深度学习入门:看懂吴恩达课程里的神经网络到底在干嘛
给产品经理的深度学习第一课:像理解商业决策一样读懂神经网络 想象你正在策划一场新品上市活动——你需要分析用户画像、预测市场反应、优化投放渠道。这其实和深度学习的工作流程惊人地相似:收集数据、训练模型、预测结果。吴恩达教授的深度学习课程之所…...

3大核心功能深度解析:UnrealPakViewer如何彻底改变UE4资源管理方式
3大核心功能深度解析:UnrealPakViewer如何彻底改变UE4资源管理方式 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer 作为虚幻引擎开发者&…...

前端路由管理方案
前端路由管理方案是现代Web应用开发中的核心技术之一,它决定了用户如何与单页面应用(SPA)交互,以及页面如何在不刷新的情况下实现动态切换。随着前端框架的普及,路由管理从简单的URL跳转演变为复杂的导航控制、权限校验…...