Clickhouse集群部署(3分片1副本)
Clickhouse集群部署
3台Linux服务器,搭建Clickhouse集群3分片1副本模式
1、安装Java、Clickhouse、Zookeeper
dpkg -i clickhouse-client_23.2.6.34_amd64.deb
dpkg -i clickhouse-common-static_23.2.6.34_amd64.deb
dpkg -i clickhouse-server_23.2.6.34_amd64.deb
# 默认安装在/etc文件夹下,/etc/clickhouse-server /etc/clickhouse-client,傻瓜式安装即可tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz # zookeeper解压启动即可
2、修改Clickhouse配置文件config.xml,加入到clickhouse标签内,尽量是加入到主配置文件中,单独配置然后在包含进主配置,容易因为一些权限问题导致集群部署不成功
3、修改Zookeeper配置文件,zoo.cfg
4、重启Clickhouse、zookeeper
systemctl restart clickhouse-server
./ZkServer.sh stop/start
5、配置application-pro.yml
clickhouse: # Clickhouse集群,3分片每个分片一个副本driver-class-name: ru.yandex.clickhouse.ClickHouseDriver #具体看pom文件中引用的是哪个jdbc-url: jdbc:clickhouse://192.168.3.19:8123,192.168.3.20:8123,192.168.3.21:8123/ck_cluster #集群名称username: janepassword: 123456hikari:connection-timeout: 20000maximum-pool-size: 60minimum-idle: 60
config.xml
<!--新增--><!--ck集群节点--><remote_servers><!-- 集群名称,可以修改--><ck_cluster><!-- 配置三个分片, 每个分片对应一台机器, 为每个分片配置一个副本 --><!--分片1--><shard><!-- 权重:新增一条数据的时候有多大的概率落入该分片,默认值:1 --><weight>1</weight><internal_replication>true</internal_replication><replica><host>192.168.3.19</host><port>9000</port> <!-- 注意集群内部之间通讯用9000端口 --><user>default</user><password>Jane</password><compression>true</compression></replica></shard><!--分片2--><shard><weight>1</weight><internal_replication>true</internal_replication><replica><host>192.168.3.20</host><port>9000</port> <!-- 注意集群内部之间通讯用9000端口 --><user>default</user><password>Jane</password><compression>true</compression></replica></shard><!--分片3--><shard><weight>1</weight><internal_replication>true</internal_replication><replica><host>192.168.3.21</host><port>9000</port> <!-- 注意集群内部之间通讯用9000端口 --><user>default</user><password>Jane</password><compression>true</compression></replica></shard></ck_cluster></remote_servers><!--zookeeper相关配置--><zookeeper><node index="1"><host>192.168.3.19</host><port>2181</port></node><node index="2"><host>192.168.3.20</host><port>2181</port></node><node index="3"><host>192.168.3.21</host><port>2181</port></node></zookeeper><macros><shard>1</shard> <!--当前所属哪个分片--><replica>192.168.3.19</replica> <!--分片所属副本的编号,可以是数字也可以是IP,在创建表时会用到--></macros><networks><ip>::/0</ip></networks><!--压缩相关配置--><clickhouse_compression><case><min_part_size>10000000000</min_part_size><min_part_size_ratio>0.01</min_part_size_ratio><method>lz4</method><!--压缩算法lz4压缩⽐zstd快, 更占磁盘--></case></clickhouse_compression>
zoo.cfg --增加
dataDir=/data/zookeeper #zookeeper数据文件存储路径
server.1=192.168.3.19:2888:3888
server.2=192.168.3.20:2888:3888
server.3=192.168.3.21:2888:3888
验证
SELECT * FROM system.zookeeper WHERE path = '/clickhouse';
GRANT CREATE TABLE ON . TO 'default' WITH GRANT OPTION;
GRANT ALTER TABLE, DROP TABLE ON . TO 'default' WITH GRANT OPTION;
SHOW GRANTS FOR 'default';
SELECT * FROM system.clusters;
dpkg -i clickhouse-client_23.2.6.34_amd64.deb
./clickhouse-client --host="192.168.3.19" --port="9000" --user="default" --password="Jane"
--在各个节点建库、本地表
create database testdb;
--在各个节点建分布表
CREATE TABLE person_local
(`ID` Int8,`Name` String,`BirthDate` Date
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(BirthDate)
ORDER BY (Name, BirthDate)
SETTINGS index_granularity=8192;--分布表(Distributed)本⾝不存储数据,相当于路由,需要指定集群名、数据库名、数据表名、分⽚KEY. 这⾥分⽚⽤rand()函数,表⽰随机分⽚。
CREATE TABLE person_all AS person_local
ENGINE = Distributed(ck_cluster, testdb, person_local, rand());
1、检查集群状态:
登录Clickhouse集群某一节点数据库
cd /usr/bin
./clickhouse-client --host='192.168.3.19' --port='9000' --user='Jane' --password='Jane1234'
select * from system.cluster; # 查看集群信息,有输出
┌─cluster────┬─shard_num─┬─replica_num─┬─host_name──┬─host_address─┬─default_database─┐
│ ck_cluster │ 1 │ 1 │ 192.168.3.19 │ 192.168.3.19 │ │
│ ck_cluster │ 2 │ 1 │ 192.168.3.20 │ 192.168.3.20 │ │
│ ck_cluster │ 3 │ 1 │ 192.168.3.21 │ 192.168.3.21 │ │
└────────────┴───────────┴─────────────┴────────────┴──────────────┴──────────────────┘
select database,table,is_readonly,replica_name,replica_path from system.replicas; # 了解每个副本的同步情况和状态,从而进行相应的管理和优化操作。
┌─database─┬─table─────────┬─replica_name─┬─replica_path───────────────────────────────────────────┐
│ default │ channelLog │ 192.168.3.19 │ /clickhouse/tables/1/channelLog/replicas/192.168.3.19 │
│ default │ cycle │ 192.168.3.19 │ /clickhouse/tables/1/cycle/replicas/192.168.3.19 │
│ default │ info │ 192.168.3.19 │ /clickhouse/tables/1/info/replicas/192.168.3.19 │
│ default │ newChannelLog │ 192.168.3.19 │ /clickhouse/tables/1/newChannelLog/replicas/192.168.3.19 │
│ default │ record │ 192.168.3.19 │ /clickhouse/tables/1/record/replicas/192.168.3.19 │
│ default │ step │ 192.168.3.19 │ /clickhouse/tables/1/step/replicas/192.168.3.19 │
│ default │ test_ck │ 192.168.3.19 │ /clickhouse/tables/1/test_ck/replicas/192.168.3.19 │
└──────────┴───────────────┴──────────────┴─────────────────────────────────────────────────────select * from system.macros; # 查看分片|副本信息
┌─macro───┬─substitution─┐
│ replica │ 192.168.3.19 │
│ shard │ 1 │
└─────────┴──────────────┘
2、检查ZooKeeper配置:
如果使用ZooKeeper,可以直接在ClickHouse数据库中输入命令来验证ZooKeeper配置是否正确:
SELECT * FROM system.zookeeper WHERE path = '/clickhouse'; #可以实时监控ZooKeeper节点的状态和数据,确保集群的协调和同步正常进行.
3、创建ReplicatedMergeTree测试表:
在任一节点上创建一个使用ReplicatedMergeTree引擎的测试表,以测试ZooKeeper同步功能是否正常:
4、创建Distributed引擎测试表/验证数据同步:
创建一个Distributed引擎的测试表,并进行数据插入和查询操作,以验证集群的分布式功能是否正常工作。
# 创建一个分布式测试表测试数据分片是否正常。已经配置了zookeeper,所以创建表的DDL语句也会同步到其他节点上
CREATE TABLE test_local ON CLUSTER ck_cluster (id Int32,name String) ENGINE = MergeTree()ORDER BY id;CREATE TABLE test ON CLUSTER ck_cluster AS test_localENGINE = Distributed(ck_cluster, default, test_local, rand());
# 参数含义:ck_cluster集群名称,default数据库,test_local表,rand()分布式表采用的分配算法,除了这个还有sipHash64(字段名)
# 注意:分布式表是基于已经存在的本地表来实现的,分布式表相当于视图,本身并不存储数据,写分布式表,分布式表会将数据发送到各个机器上。查分布式表,会聚合所有机器的数据显示)
INSERT INTO test (id, name) VALUES (1, 'Alice'), (2, 'Bob'); # 在某个节点上执行插入操作
select * from test; # 在任一Clickhouse节点,直接查询分布式表可以看到这些数据,数据存在,则表示数据同步配置成功
select * from test_local; # 在其他Clickhouse节点上查询,只能看到自己本地的数据
SHOW databases;
show tables;
SELECT currentDatabase();5、检查服务状态:
在每台节点上启动/查看/重启/停止ClickHouse服务,以确保服务运行正常:
service clickhouse-server start # 或者systemctl restart clickhouse-server
service clickhouse-server status
service clickhouse-server restart
service clickhouse-server stop
通过以上步骤,可以全面验证ClickHouse集群是否部署成功并且正常运行
参考文章:
https://blog.csdn.net/weixin_44123540/article/details/119042654
https://blog.csdn.net/clearlxj/article/details/121774940
相关文章:
)
Clickhouse集群部署(3分片1副本)
Clickhouse集群部署 3台Linux服务器,搭建Clickhouse集群3分片1副本模式 1、安装Java、Clickhouse、Zookeeper dpkg -i clickhouse-client_23.2.6.34_amd64.deb dpkg -i clickhouse-common-static_23.2.6.34_amd64.deb dpkg -i clickhouse-server_23.2.6.34_amd64…...

刷服务器固件
猫眼淘票票 大麦 一 H3C通用IP 注:算力服务器不需要存储 二 刷服务器固件 1 登录固定IP地址 2 升级BMC版本 注 虽然IP不一致但是步骤是一致的 3 此时服务器会出现断网现象,若不断网等上三分钟ping一下 4 重新登录 5 断电拔电源线重新登录查看是否登录成功...

数据结构C语言描述9(图文结合)--二叉树和特殊书的概念,二叉树“最傻瓜式创建”与前中后序的“递归”与“非递归遍历”
前言 这个专栏将会用纯C实现常用的数据结构和简单的算法;有C基础即可跟着学习,代码均可运行;准备考研的也可跟着写,个人感觉,如果时间充裕,手写一遍比看书、刷题管用很多,这也是本人采用纯C语言…...

CSS——2.书写格式一
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title></title></head><body><!--css书写中:--><!--1.css 由属性名:属性值构成--><!--style"color: red;font-size: 20px;&quo…...

Elasticsearch 创建索引 Mapping映射属性 索引库操作 增删改查
Mapping Type映射属性 mapping是对索引库中文档的约束,有以下类型。 text:用于分析和全文搜索,通常适用于长文本字段。keyword:用于精确匹配,不会进行分析,适用于标签、ID 等精确匹配场景。integer、long…...

【NLP高频面题 - 分布式训练篇】ZeRO主要为了解决什么问题?
【NLP高频面题 - 分布式训练篇】ZeRO主要为了解决什么问题? 重要性:★★ 零冗余优化器技术由 DeepSpeed 代码库提出,主要用于解决数据并行中的模型冗余问题,即每张 GPU 均需要复制一份模型参数。 ZeRO的全称是Zero Redundancy …...

kubernetes-循序渐进了解coredns
文章目录 概要基础知识Kubernetes 集群中对对象名称的 DNS 流量解析 Kubernetes 集群外的名称的 DNS 流量CoreDNS 如何确定向哪个本地 DNS 请求解析?修改 CoreDNS 的配置 概要 CoreDNS 是 Kubernetes 的核心组件之一。只有在 Kubernetes 集群中安装了 容器网络接口…...

mysql8 从C++源码角度看 客户端发送的sql信息 mysql服务端从网络读取到buff缓存中
MySQL 8 版本中的客户端-服务器通信相关,特别是在接收和解析网络请求的数据包时。以下是对代码各个部分的详细解释,帮助您更好地理解这些代码的作用。 代码概述 这段代码主要负责从网络读取数据包,它包含了多个函数来处理网络数据的读取、缓…...

pygame飞机大战
飞机大战 1.main类2.配置类3.游戏主类4.游戏资源类5.资源下载6.游戏效果 1.main类 启动游戏。 from MainWindow import MainWindow if __name__ __main__:appMainWindow()app.run()2.配置类 该类主要存放游戏的各种设置参数。 #窗口尺寸 #窗口尺寸 import random import p…...

【Vim Masterclass 笔记08】第 6 章:Vim 中的文本变换及替换操作 + S06L20:文本的插入、变更、替换,以及合并操作
文章目录 Section 6:Transforming and Substituting TextS06L21 Inserting, Changing, Replacing, and Joining1 定位到行首非空字符,并启用插入模式2 在紧挨光标的下一个字符位置启动插入模式3 定位到一行末尾,并启用插入模式4 定位到光标的…...

Tailwind CSS 实战:动画效果设计与实现
在现代网页设计中,动画效果就像是一位优秀的舞者,通过流畅的动作为用户带来愉悦的视觉体验。记得在一个产品展示网站项目中,我们通过添加精心设计的动画效果,让用户的平均停留时间提升了 35%。今天,我想和大家分享如何使用 Tailwind CSS 打造优雅的动画效果。 设计理念 设计动…...

【动手学电机驱动】STM32-MBD(3)Simulink 状态机模型的部署
STM32-MBD(1)安装 Simulink STM32 硬件支持包 STM32-MBD(2)Simulink 模型部署入门 STM32-MBD(3)Simulink 状态机模型的部署 【动手学电机驱动】STM32-MBD(3)Simulink 状态机模型部署…...

Linux 服务器启用 DNS 加密
DNS 加密的常用协议包括 DNS over HTTPS (DoH)、DNS over TLS (DoT) 和 DNSCrypt。以下是实现这些加密的步骤和工具建议: 1. 使用 DoH (DNS over HTTPS) 工具推荐: cloudflared(Cloudflare 提供的客户端)doh-client(…...

PyTorch不同优化器比较
常见优化器介绍 - SGD(随机梯度下降):是最基本的优化器之一,通过在每次迭代中沿着损失函数的负梯度方向更新模型参数。在大规模数据集上计算效率高,对于凸问题和简单模型效果较好。但收敛速度慢,容易陷入局…...

stm32的掉电检测机制——PVD
有时在一些应用中,我们需要检测系统是否掉电了,或者要在掉电的瞬间需要做一些处理。 STM32内部自带PVD功能,用于对MCU供电电压VDD进行监控。 STM32就有这样的掉电检测机制——PVD(Programmable Voltage Detecter),即可编程电压检…...
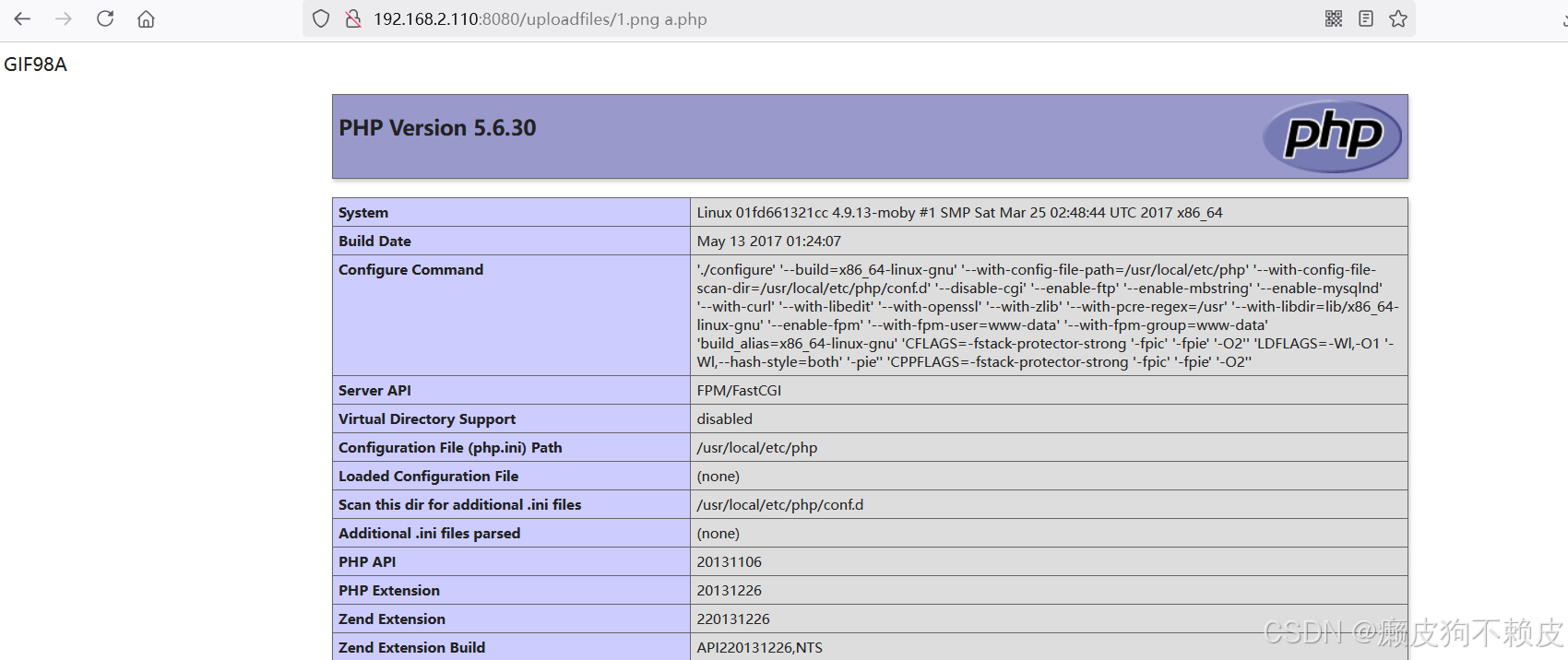
Nginx 文件名逻辑漏洞(CVE-2013-4547)
目录 漏洞原理 影响版本 漏洞复现 漏洞原理 CGI:是一种协议,定义了web服务器传递的数据格式。 FastCGI:优化版的CGI程序 PHP-CGI:PHP解释器,能够对PHP文件进行解析并返回相应的解析结果 PHP-FPM:Fas…...

Java 21 优雅和安全地处理 null
在 Java 21 中,判断 null 依然是开发中常见的需求。通过使用现代 Java 提供的工具和特性,可以更加优雅和安全地处理 null。 1. 使用 Objects.requireNonNull Objects.requireNonNull 是标准的工具方法,用于快速判断并抛出异常。 示例 import java.util.Objects;public c…...

AWS Glue基础知识
AWS Glue 是一项完全托管的 ETL(提取、转换、加载)服务,与考试相关,尤其是在数据集成、处理和分析方面。 1.数据集成和 ETL(提取、转换、加载) AWS Glue 主要用于构建 ETL 管道以准备数据以进行分析。作为…...

Kubernetes——part4-1 Kubernetes集群 服务暴露 Nginx Ingress Controller
Kubernetes集群 服务暴露 Nginx Ingress Controller 一、ingress控制器 1.1 ingress控制器作用 (类似于slb,做代理服务) ingress controller可以为kubernetes 集群外用户访问Kubernetes集群内部pod提供代理服务。 提供全局访问代理访问流程…...

Flutter入门,Flutter基础知识总结。
Flutter是Google推出的一种移动应用开发框架,它允许开发者使用一套代码库同时开发Android和iOS应用。以下是对Flutter知识点的详细总结: 一、Flutter概述 特点:跨平台、高保真、高性能。 编程语言:使用Dart语言编写。 设计理念&…...

别急着改java.security!排查JDBC连SQL Server报TLS错误的3个更优思路
别急着改java.security!排查JDBC连SQL Server报TLS错误的3个更优思路 当你在使用JDBC连接SQL Server时遇到"The server selected protocol version TLS10 is not accepted by client preferences"的错误,大多数技术文章会直接建议你修改java.s…...

如何快速掌握网盘直链下载助手:八大网盘下载加速终极教程
如何快速掌握网盘直链下载助手:八大网盘下载加速终极教程 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

别再只盯着PSNR了!图像修复/超分实战中,SSIM、LPIPS、FID到底该怎么选?
图像修复与超分实战:如何科学选择评估指标? 当你熬了几个通宵训练出的超分辨率模型在测试集上PSNR值爆表,但生成的图像却让产品经理皱起眉头说"看起来怪怪的"时,作为工程师的你是否感到困惑?这种"指标很…...

KMS激活脚本:5分钟免费激活Windows和Office的完整指南
KMS激活脚本:5分钟免费激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否在为Windows系统和Office办公软件的激活问题而烦恼?面对复杂…...

深入XDMA数据流:用仿真带你理解H2C/C2H通道与PCIE TLP的转换过程
深入XDMA数据流:用仿真带你理解H2C/C2H通道与PCIE TLP的转换过程 在FPGA与主机间的高速数据交互场景中,XDMA(Xilinx DMA)核扮演着关键角色。许多工程师虽然能够完成基础配置和硬件连接,但当遇到数据不一致或性能瓶颈时…...

【技巧】用adb给quest眼镜安装apk
使用如下命令, #用usb连接quest眼镜 adb devices #显示连接设备 #如果显示unauthorized,则重新启动quest眼镜 adb install xxx.apk #安装apk软件...

【花雕学编程】Arduino BLDC 之6.5 寸轮毂电机自动跟随底盘的几种典型控制逻辑
基于 Arduino 平台控制 6.5 寸 BLDC(无刷直流)轮毂电机实现自动跟随底盘,是机器人开发中非常经典且实用的场景。6.5 寸轮毂电机因其集成了电机、减速箱和轮毂,具备大扭矩、结构紧凑的特点,非常适合此类应用。这里梳理了…...

终极PDF视觉对比解决方案:diff-pdf深度解析与实践指南
终极PDF视觉对比解决方案:diff-pdf深度解析与实践指南 【免费下载链接】diff-pdf A simple tool for visually comparing two PDF files 项目地址: https://gitcode.com/gh_mirrors/di/diff-pdf 在数字化文档协作、技术文档版本控制和法律合同审核等场景中&a…...

Qwen3.5-9B-GGUF效果展示:中文法律条文解释+英文合同条款对照生成
Qwen3.5-9B-GGUF效果展示:中文法律条文解释英文合同条款对照生成 1. 模型能力概览 Qwen3.5-9B-GGUF是基于阿里云通义千问3.5(2026年3月开源版本)的90亿参数稠密模型,采用GGUF格式量化后的轻量级版本。该模型融合了Gated Delta N…...

Fluent湿空气模拟避坑指南:从“组分输运模型”设置到“相对湿度云图”动画生成全流程
Fluent湿空气模拟避坑指南:从"组分输运模型"设置到"相对湿度云图"动画生成全流程 当你在Fluent中进行湿空气模拟时,是否遇到过计算结果不收敛、相对湿度分布异常,或是无法生成理想的动态云图?这些问题往往源于…...