PyTorch不同优化器比较
常见优化器介绍
- SGD(随机梯度下降):是最基本的优化器之一,通过在每次迭代中沿着损失函数的负梯度方向更新模型参数。在大规模数据集上计算效率高,对于凸问题和简单模型效果较好。但收敛速度慢,容易陷入局部最小值,对学习率的选择较为敏感,不合适的学习率可能导致训练无法收敛或收敛到较差的解。
- Adagrad:为每个参数自适应地调整学习率,根据参数的历史梯度平方和来调整当前的学习率,使得在训练过程中,频繁更新的参数学习率逐渐减小,而不常更新的参数学习率相对较大,适合处理稀疏数据。但学习率会逐渐降低,导致训练后期学习非常慢,可能需要很长时间才能收敛。
- Adadelta:解决了Adagrad学习率逐渐降低的问题,通过使用梯度平方的指数加权平均来代替全部梯度的平方和,动态地调整每个参数的学习率,不需要手动设置学习率。与Adam相比,在某些情况下收敛速度稍慢,但在一些特定场景中表现较好。
- RMSprop:与Adadelta类似,通过将学习率除以梯度平方的指数加权平均来调整学习率,计算上更为简洁,收敛速度较快,在处理非平稳目标时表现较好,常用于循环神经网络等。但与Adam类似,在某些情况下可能需要更精细的超参数调整。
- Adam:同时使用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,一阶矩用来控制模型更新的方向,二阶矩控制步长,计算效率高,收敛速度快,自动调整学习率的特性使得它适用于大多数情况。但在某些情况下可能不如SGD及其变体具有好的泛化能力,需要调整超参数,如β1、β2、ε等。
- AdamW(带权重衰减的Adam):在Adam的基础上增加了权重衰减项,有助于正则化模型,防止过拟合,对于大型模型训练和容易过拟合的任务效果较好。与Adam类似,需要调整超参数。
- Adamax:是Adam的一种变体,将Adam的二范数(二阶矩估计)推广到无穷范数,具有更大的学习率范围和更好的稳定性。在某些情况下可能不如Adam或SGD表现得好,但在学习率选择较为困难时是一个不错的选择。
优化器比较实验
以下使用一个简单的线性回归模型在一个合成数据集上进行实验,对比不同优化器的收敛速度和性能。
import torch
import torch.optim as optim
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
# 生成合成数据集
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1 * torch.normal(torch.zeros(*x.size()))
# 定义线性回归模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 定义不同的优化器
net_SGD = Net()
net_Adagrad = Net()
net_Adadelta = Net()
net_RMSprop = Net()
net_Adam = Net()
net_AdamW = Net()
net_Adamax = Net()
opt_SGD = optim.SGD(net_SGD.parameters(), lr=0.01)
opt_Adagrad = optim.Adagrad(net_Adagrad.parameters(), lr=0.01)
opt_Adadelta = optim.Adadelta(net_Adadelta.parameters(), lr=0.01)
opt_RMSprop = optim.RMSprop(net_RMSprop.parameters(), lr=0.01, alpha=0.9)
opt_Adam = optim.Adam(net_Adam.parameters(), lr=0.001, betas=(0.9, 0.99))
opt_AdamW = optim.AdamW(net_AdamW.parameters(), lr=0.001, betas=(0.9, 0.99))
opt_Adamax = optim.Adamax(net_Adamax.parameters(), lr=0.001, betas=(0.9, 0.99))
# 训练模型并记录损失
losses_SGD = []
losses_Adagrad = []
losses_Adadelta = []
losses_RMSprop = []
losses_Adam = []
losses_AdamW = []
losses_Adamax = []
for epoch in range(100):
# SGD
optimizer_SGD.zero_grad()
output_SGD = net_SGD(x)
loss_SGD = nn.MSELoss()(output_SGD, y)
loss_SGD.backward()
optimizer_SGD.step()
losses_SGD.append(loss_SGD.item())
# Adagrad
optimizer_Adagrad.zero_grad()
output_Adagrad = net_Adagrad(x)
loss_Adagrad = nn.MSELoss()(output_Adagrad, y)
loss_Adagrad.backward()
optimizer_Adagrad.step()
losses_Adagrad.append(loss_Adagrad.item())
# Adadelta
optimizer_Adadelta.zero_grad()
output_Adadelta = net_Adadelta(x)
loss_Adadelta = nn.MSELoss()(output_Adadelta, y)
loss_Adadelta.backward()
optimizer_Adadelta.step()
losses_Adadelta.append(loss_Adadelta.item())
# RMSprop
optimizer_RMSprop.zero_grad()
output_RMSprop = net_RMSprop(x)
loss_RMSprop = nn.MSELoss()(output_RMSprop, y)
loss_RMSprop.backward()
optimizer_RMSprop.step()
losses_RMSprop.append(loss_RMSprop.item())
# Adam
optimizer_Adam.zero_grad()
output_Adam = net_Adam(x)
loss_Adam = nn.MSELoss()(output_Adam, y)
loss_Adam.backward()
optimizer_Adam.step()
losses_Adam.append(loss_Adam.item())
# AdamW
optimizer_AdamW.zero_grad()
output_AdamW = net_AdamW(x)
loss_AdamW = nn.MSELoss()(output_AdamW, y)
loss_AdamW.backward()
optimizer_AdamW.step()
losses_AdamW.append(loss_AdamW.item())
# Adamax
optimizer_Adamax.zero_grad()
output_Adamax = net_Adamax(x)
loss_Adamax = nn.MSELoss()(output_Adamax, y)
loss_Adamax.backward()
optimizer_Adamax.step()
losses_Adamax.append(loss_Adamax.item())
# 绘制损失曲线
plt.plot(losses_SGD, label='SGD')
plt.plot(losses_Adagrad, label='Adagrad')
plt.plot(losses_Adadelta, label='Adadelta')
plt.plot(losses_RMSprop, label='RMSprop')
plt.plot(losses_Adam, label='Adam')
plt.plot(losses_AdamW, label='AdamW')
plt.plot(losses_Adamax, label='Adamax')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Comparison of PyTorch Optimizers')
plt.legend()
plt.show()
实验结果分析
- 收敛速度:在这个简单的实验中,Adam、RMSprop和Adamax在初期的收敛速度相对较快,能够在较少的迭代次数内使损失快速下降。而SGD的收敛速度相对较慢,需要更多的迭代次数才能达到类似的损失值。Adagrad在前期下降速度尚可,但由于学习率逐渐降低,后期收敛速度明显变慢。Adadelta的收敛速度较为稳定,但整体相对Adam等稍慢。
- 稳定性:Adam、RMSprop和Adadelta在训练过程中相对稳定,损失值的波动较小。而SGD由于其随机性和对学习率的敏感性,损失值可能会出现较大的波动。Adagrad在后期由于学习率过小,可能会导致训练停滞不前,出现不稳定的情况。AdamW在稳定性上与Adam类似,但由于加入了权重衰减,在一定程度上可以防止模型在后期过拟合而导致的不稳定。
- 泛化能力:一般来说,SGD及其变体在一些大规模的数据集和复杂模型上,如果调参得当,可能会具有较好的泛化能力。Adam等自适应学习率的优化器在大多数情况下能够快速收敛,但在某些特定的数据集和模型结构上,可能会出现过拟合的情况,导致泛化能力下降。不过,通过调整超参数和加入正则化项等方法,可以在一定程度上提高其泛化能力。
- 超参数调整:SGD通常需要手动调整学习率和其他超参数,如动量等,对超参数的选择较为敏感。Adagrad、Adadelta和RMSprop等虽然在一定程度上自动调整学习率,但也可能需要根据具体情况调整一些超参数。Adam、AdamW和Adamax需要调整的超参数相对较多,如β1、β2、ε等,但通常在默认值附近进行微调就可以取得较好的效果。
优化器损失曲线对比
根据上述实验和分析,在实际应用中,对于简单模型和大规模数据集,SGD可能是一个不错的选择,如果对收敛速度有要求,可以尝试使用带动量的SGD。对于复杂模型和需要自动调整学习率的情况,Adam、RMSprop等自适应学习率的优化器通常表现较好。如果担心过拟合,可以选择AdamW。在处理稀疏数据时,Adagrad可能会更合适。而Adadelta和Adamax则在特定场景中可以进行尝试和探索。同时,不同的优化器在不同的数据集和模型结构上的表现可能会有所不同,需要根据具体情况进行实验和调整。
相关文章:

PyTorch不同优化器比较
常见优化器介绍 - SGD(随机梯度下降):是最基本的优化器之一,通过在每次迭代中沿着损失函数的负梯度方向更新模型参数。在大规模数据集上计算效率高,对于凸问题和简单模型效果较好。但收敛速度慢,容易陷入局…...

stm32的掉电检测机制——PVD
有时在一些应用中,我们需要检测系统是否掉电了,或者要在掉电的瞬间需要做一些处理。 STM32内部自带PVD功能,用于对MCU供电电压VDD进行监控。 STM32就有这样的掉电检测机制——PVD(Programmable Voltage Detecter),即可编程电压检…...
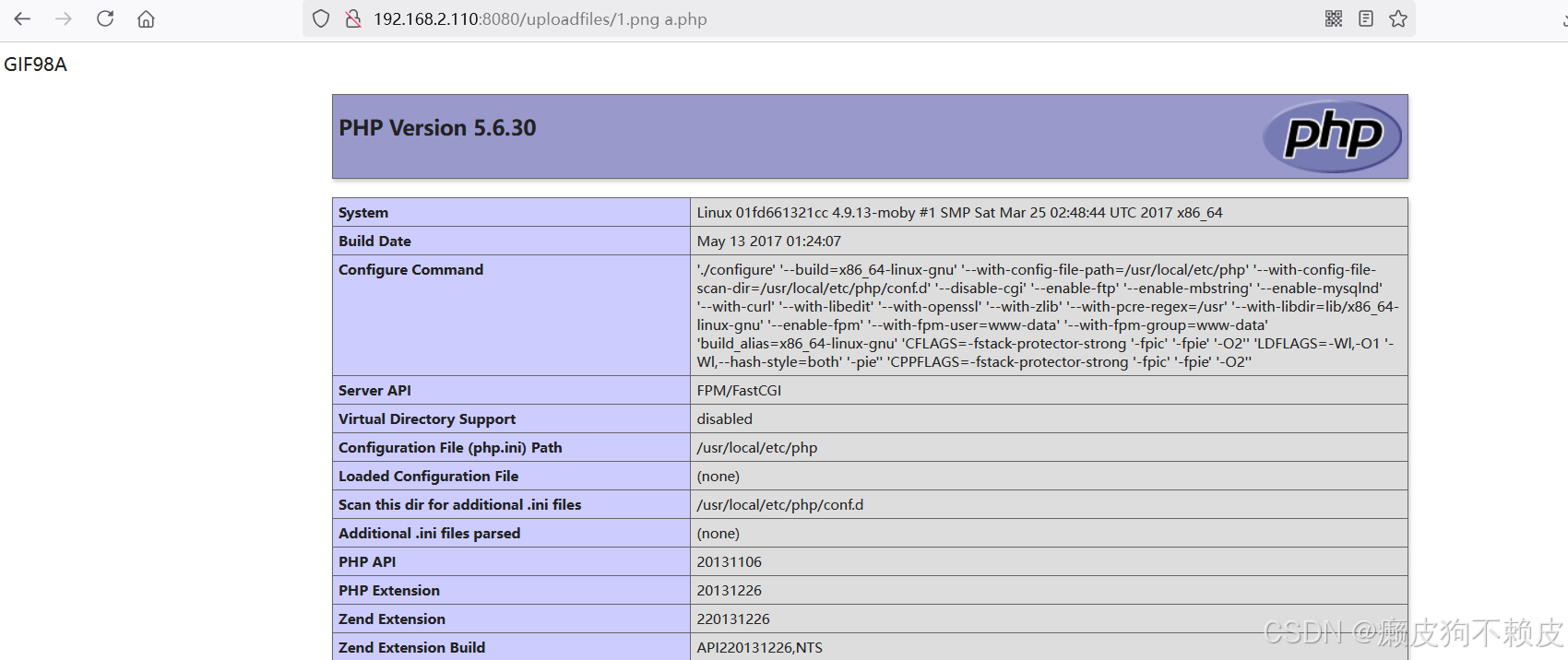
Nginx 文件名逻辑漏洞(CVE-2013-4547)
目录 漏洞原理 影响版本 漏洞复现 漏洞原理 CGI:是一种协议,定义了web服务器传递的数据格式。 FastCGI:优化版的CGI程序 PHP-CGI:PHP解释器,能够对PHP文件进行解析并返回相应的解析结果 PHP-FPM:Fas…...

Java 21 优雅和安全地处理 null
在 Java 21 中,判断 null 依然是开发中常见的需求。通过使用现代 Java 提供的工具和特性,可以更加优雅和安全地处理 null。 1. 使用 Objects.requireNonNull Objects.requireNonNull 是标准的工具方法,用于快速判断并抛出异常。 示例 import java.util.Objects;public c…...

AWS Glue基础知识
AWS Glue 是一项完全托管的 ETL(提取、转换、加载)服务,与考试相关,尤其是在数据集成、处理和分析方面。 1.数据集成和 ETL(提取、转换、加载) AWS Glue 主要用于构建 ETL 管道以准备数据以进行分析。作为…...

Kubernetes——part4-1 Kubernetes集群 服务暴露 Nginx Ingress Controller
Kubernetes集群 服务暴露 Nginx Ingress Controller 一、ingress控制器 1.1 ingress控制器作用 (类似于slb,做代理服务) ingress controller可以为kubernetes 集群外用户访问Kubernetes集群内部pod提供代理服务。 提供全局访问代理访问流程…...

Flutter入门,Flutter基础知识总结。
Flutter是Google推出的一种移动应用开发框架,它允许开发者使用一套代码库同时开发Android和iOS应用。以下是对Flutter知识点的详细总结: 一、Flutter概述 特点:跨平台、高保真、高性能。 编程语言:使用Dart语言编写。 设计理念&…...

weight decay 和L2是一个东西吗
weight decay和L2正则化本质上是相同的概念。 weight decay(权重衰减)和L2正则化在深度学习中都是用来防止模型过拟合的常用技术。它们通过对损失函数添加一个正则项来限制模型参数的大小,从而控制模型的复杂度。具体来说,L2正则…...
-- Array高级操作)
JavaScript系列(8)-- Array高级操作
JavaScript Array高级操作 📚 在前七篇文章中,我们探讨了JavaScript的语言特性、ECMAScript标准、引擎工作原理、数值类型、字符串处理、Symbol类型和Object高级特性。今天,让我们深入了解JavaScript中的Array高级操作。数组是最常用的数据结…...

Harmony开发【笔记1】报错解决(字段名写错了。。)
在利用axios从网络接收请求时,发现返回obj的code为“-1”,非常不解,利用console.log测试,更加不解,可知抛出错误是 “ E 其他错误: userName required”。但是我在测试时,它并没有体现为空,…...

MAC环境安装(卸载)软件
MAC环境安装(卸载)软件 jdknode安装node,并实现不同版本的切换背景 卸载node从node官网下载pkg安装的node卸载用 homebrew 安装的node如果你感觉删的不够干净,可以再细分删除验证删除结果 在macOS下创建home目录 jdk 1.下载jdk 先…...

【Vim Masterclass 笔记05】第 4 章:Vim 的帮助系统与同步练习(L14+L15+L16)
文章目录 Section 4:The Vim Help System(Vim 帮助系统)S04L14 Getting Help1 打开帮助系统2 退出帮助系统3 查看具体命令的帮助文档4 查看帮助文档中的主题5 帮助文档间的上翻、下翻6 关于 linewise7 查看光标所在术语名词的帮助文档8 关于退…...

Multisim更新:振幅调制器+解调器(含仿真程序+文档+原理图+PCB)
前言 继3年前设计的:Multisim:振幅调制器的设计(含仿真程序文档原理图PCB),有读者表示已经不能满足新需求,需要加上新的解调器功能😂😂😂,鸽了很久这里便安排…...

CentOS — 群组管理
文章目录 一、查看群组二、添加群组三、删除群组四、修改群组 Linux 系统中每个用户都属于一个特定的群组。 若不设置用户的群组,默认会创建一个和用户名一样的群组,并将用户分到该群组。 一、查看群组 groups 用户名:查看用户所属群组。 二…...

【pytorch】注意力机制-1
1 注意力提示 1.1 自主性的与非自主性的注意力提示 非自主性提示: 可以简单地使用参数化的全连接层,甚至是非参数化的最大汇聚层或平均汇聚层。 自主性提示 注意力机制与全连接层或汇聚层区别开来。在注意力机制的背景下,自主性提示被称为查…...

html 元素中的data-v-xxxxxx 是什么?为什么有的元素有?有的没有?
data-v-xxxxxx 在 HTML 中,data-v 属性通常与 Vue.js 或其他前端框架一起使用,特别是当这些框架结合 CSS 预处理器(如 Sass、Less)和单文件组件(Single File Components, SFCs)时。data-v 属性的主要目的是…...

第27周:文献阅读及机器学习
目录 摘要 Abstract 一、文献阅读 发现问题 研究方法 CNN-LSTM DT SVR 创新点 案例分析 数据准备 模型性能 预测模型的实现 仿真实验及分析 二、LSTM 1、基本结构 2、具体步骤 3、举例说明 4、原理理解 总结 摘要 本周阅读文献《Short-term water qua…...

回归预测 | MATLAB实ELM-Adaboost多输入单输出回归预测
回归预测 | MATLAB实ELM-Adaboost多输入单输出回归预测 目录 回归预测 | MATLAB实ELM-Adaboost多输入单输出回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 一、极限学习机(ELM) 极限学习机是一种单层前馈神经网络,具有训练速…...
、Extensions(扩展)、Error Handling(错误处理)、Generics(泛型))
Swift Protocols(协议)、Extensions(扩展)、Error Handling(错误处理)、Generics(泛型)
最近在学习 Swift,总结相关知识 1. Protocols(协议) 1.1 协议的定义和实现 协议(protocol) 是一种定义方法和属性的蓝图,任何类、结构体或枚举都可以遵循协议。遵循协议后,需要实现协议中定义…...

.NET中的强名称和签名机制
.NET中的强名称(Strong Name)和签名机制是.NET Framework引入的一种安全性和版本控制机制。以下是关于.NET中强名称和签名机制的详细解释: 强名称 定义: 强名称是由程序集的标识加上公钥和数字签名组成的。程序集的标识包括简单文…...
)
当LLM开始“编译”你的Prompt:从AST解析视角重构智能代码生成工作流(含Python/TypeScript双语言Prompt IR中间表示规范)
第一章:智能代码生成Prompt工程指南 2026奇点智能技术大会(https://ml-summit.org) 高质量Prompt是驱动智能代码生成模型产出可运行、可维护、符合上下文语义的关键杠杆。与通用文本生成不同,代码生成对结构精确性、语法合法性、边界条件覆盖及API兼容…...

12位SAR ADC电路设计与仿真:基于Cadence与MATLAB的频谱分析与应用
12bit sar adc电路,可直接仿真,逻辑模块也是实际电路,可利用cadence或者matlab进行频谱分析延申科普:ADC(Analog-to-Digital Converter)是一种电子设备,用于将连续的模拟信号转换为离散的数字信…...
)
智慧餐厅管理(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T1252305M设计简介:本设计是基于STM32的智慧餐厅管理,主要实现以下功能:1、从机能实现烟雾,温湿度的检测&am…...

Python驱动CANoe自动化测试:从COM接口调用到Type Library解析的实战指南
1. 为什么选择Python驱动CANoe自动化测试 第一次接触CANoe自动化测试时,我尝试过用VB脚本和C#来调用COM接口,但最终发现Python才是最适合的选择。原因很简单:Python语法简洁,生态丰富,特别适合快速搭建测试框架。比如用…...

宝武集团复购无人矿卡,易控智驾从“煤矿龙头“迈向“全矿种“解决方案提供商
大家好,我是智驾民工,矿山无人驾驶产业创新解说员,陪您读懂无人驾驶技术在矿山领域落地的全生命周期。 易控智驾又拿单了。 这次不是新客拓单,而是老客户复购——宝武集团重钢西昌矿业再增12台,加上此前已稳定运行一…...

Eye-in-Hand还是Eye-to-Hand?从实际项目出发,聊聊九点标定在两种场景下的配置差异与避坑点
Eye-in-Hand与Eye-to-Hand:九点标定的实战选择与避坑指南 在自动化项目的视觉系统设计中,相机安装位置的选择往往决定了整个项目的成败。Eye-in-Hand(手眼)和Eye-to-Hand(固定眼)这两种主流配置方式&#x…...

庖丁解牛:从BootROM到FSBL的ZYNQ启动全景解析
1. ZYNQ启动流程全景概览 当你按下ZYNQ开发板的电源按钮时,这块看似普通的芯片内部正在上演一场精密的"交响乐"。作为嵌入式开发者,理解从BootROM到FSBL的完整启动链条,就像掌握了一把打开ZYNQ潜能的金钥匙。我用过不下二十款ZYNQ系…...
)
别再凭感觉选三极管了!手把手教你计算MOS管驱动电流(附分立器件选型指南)
从数据手册到实战选型:MOS管驱动电流的精确计算与分立器件搭配指南 在硬件设计领域,MOS管的驱动问题就像电路板上的"暗礁"——表面看不见,却能让整个系统搁浅。我曾亲眼见过一个资深工程师花费三天调试的电源模块,最终发…...

intv_ai_mk11 GPU部署避坑指南:解决乱码、延迟高、无响应等6类常见问题
intv_ai_mk11 GPU部署避坑指南:解决乱码、延迟高、无响应等6类常见问题 1. 环境准备与快速部署 在开始使用intv_ai_mk11 AI对话机器人前,确保您的GPU服务器满足以下基本要求: 操作系统:推荐Ubuntu 20.04/22.04 LTSGPU驱动&…...

MicMute:一键静音麦克风的Windows系统托盘解决方案
MicMute:一键静音麦克风的Windows系统托盘解决方案 【免费下载链接】MicMute Mute default mic clicking tray icon or shortcut 项目地址: https://gitcode.com/gh_mirrors/mi/MicMute 在远程办公、在线会议、直播等场景中,快速控制麦克风状态已…...