【保姆级爬虫】微博关键词搜索并获取博文和评论内容(python+selenium+chorme)
微博爬虫记录
写这个主要是为了防止自己忘记以及之后的组内工作交接,至于代码美不美观,写的好不好,统统不考虑,我只能说,能跑就不错了,上学压根没学过python好吧,基本上是crtl+c&ctrl+v丝滑小连招教会了我一点。
写的很简单,认真看完就会用了
文中筛选元素用到的一些筛选元素的正则匹配、beautifulsoup,css等相关方法我也不太懂,现学现用呗,还是那句话,能跑就行。
配置简介:
python3.6、selenium3.13.0,chorme以及与chorme版本对应的chormedriver
(selenium在4版本后的一些语句会需要修改,网上一大把自己查)
目录
1、启动程序控制的chorme,手动登录微博
2、在微博进行关键词的检索
3、微博的发布信息获取
4、保存数据
5、实现自动翻页
6、微博的评论信息获取
1、先启动一个由程序控制的chorme
(1)win+R,输入cmd打开命令行,输入代码进入chorme的安装位置
C:Program FilesGoogleChromeApplication
(2)分配chorme的端口号(我这里设置的是9527)和数据目录(我这里是在D:seleniumAutomationProfile)
chrome.exe --remote-debugging-port=9527 --user-data-dir="D:seleniumAutomationProfile"
每次执行(1)(2)两行命令就能打开同一个chorme了,建议放在程序解析的最上方,这样浏览器关闭后下次可以通过命令行快速打开
(3)浏览器已经打开了,登录一下自己的微博
(4)链接一下程序和浏览器
# 这部分代码我直接扔在了所有函数之前,搞全局
# 把chormedriver的路径写到这里
chromedriver_path= "D:/Users/16653/AppData/Local/Programs/Python/Python36/chromedriver.exe"
option = ChromeOptions()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
web = webdriver.Chrome(executable_path=chromedriver_path, options=option)
web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""
})
web.implicitly_wait(10)# 等待网页的加载时间
2、进行关键词的检索
从这里开始写函数的主体,自己搞个函数名把这些代码放进去
关键词搜索的链接如下:
https://s.weibo.com/weibo?q=这里填关键词&Refer=index
搜索页面翻页直接在后面加一个page=页码,如第二页
https://s.weibo.com/weibo?q=这里填关键词&Refer=index&page=2
selenium获取初步搜索结果
web.get(url) # url就是搜索的链接
html = web.page_source
print (html) # 输出当前程序获取到的网页信息,用于检查网页是否正常获取
在浏览器里点击右键选择检查,在浏览器里面可以用检查页面左上角的框框箭头符号方便得在左边选择图案或者文字,然后实时在右边看到这个被选择的要素在哪个标签
可以发现每个博文都在action-type="feed_list_item"的div标签下(结合下图左右蓝色部分理解,标签就是一个<>包含的东西)这是一个很重要的地方,学会用浏览器的这个功能选取自己需要的信息在哪个标签里面,下面所有获取信息的代码几乎都是基于此

那我们可以通过beautifulsoup的findAll函数把所有这些标签的内容选择出来放进list(其他标签下提取信息也适用这个函数哦,只需要对应修改div,action-type,feed_list_item就行)
如果只想要找到的第一个div标签下的信息就用find函数,而不是findAll
soup = bs(html, 'html.parser')
list = soup.findAll("div", {'action-type': "feed_list_item"})
3、解析多种数据
(1)获取博文的文本内容,微博的文章字数太长会收起来,为了文本内容获取完整必须先将所有文本展开。

web_object = {}html = web.page_source# 获取这一网页的所有未展开的文章的展开按钮button_list = web.find_elements_by_css_selector('a[action-type="fl_unfold"]') #点击所有展开# 在for循环里面每个都点击展开for bt in button_list:try :bt.click()except Exception as e:print(e.args)# html转beautifulsoup格式soup = bs(html, 'html.parser')# 已经展开了,开始正常获取这一页的微博列表listlist = soup.findAll("div", {'action-type': "feed_list_item"})for i in list:# 获取微博的文本信息,strip用于跳过字符前面的空白txt = i.findAll("p", {'class':"txt"})[-1].get_text().strip()print(txt) # 输出获得的内容web_object['text'] = txt
(2)获取微博的mid
mid = i.get("mid")print("mid",mid)web_object['mid'] = mid
(3)获取发布者的昵称
user_name = i.find("a", {'class': "name"}).get_text()#名字放在class为name的a标签里面print("昵称", user_name)web_object['user_name'] = user_name
(4)获取时间
i = i.find("div",{'class':"card"})itime = i.find("div", {'class': "from"})uptime = itime.find("a").get_text().strip()print("发布时间:", uptime)web_object['date'] = uptime
(5)点赞、评论、转发的人数
cardact = i.find("div", {'class': "card-act"})repost_num = cardact.findAll("li")[0].get_text().strip()if repost_num =="转发":repost_num = 0print("转发人数:", repost_num)web_object['repost_num'] = repost_numcomment_num = cardact.findAll("li")[1].get_text().strip()if comment_num == "评论":comment_num = 0print("评论人数:", comment_num)web_object['comment_num'] = comment_numlike_num = cardact.findAll("li")[2].get_text().strip()if like_num == "赞":like_num =0print("点赞人数:", like_num)web_object['like_num'] = like_num
(6)获取更多关于微博博主的信息
需要先从微博的搜索页面跳转到用户的界面,获取完信息后需要再跳转回来
# 控制跳转user_link=i.find("a").get("href")print("用户主页:", user_link)web_object['user_link'] = user_link# 拼出用户的主页链接user_urluser_url = "'" + "https:" + user_link+ "'"js = "window.open(" + user_url + ");"web.execute_script(js)time.sleep(random.randint(2, 5))# 切换到新窗口# 获得打开的第一个窗口句柄window_1 = web.current_window_handle# 获得打开的所有的窗口句柄windows = web.window_handles# 切换到最新的窗口for current_window in windows:if current_window != window_1:web.switch_to.window(current_window)html = web.page_sourcesoup = bs(html, 'html.parser')print("切换到用户主页")
(7)获取用户类型(红V,蓝V,黄V等)
同样的,先获取这个类型所在的网页标签,然后得到具体内容,如果没有红V,蓝V,黄V则程序执行异常,通过try语句抓取异常,将用户类型设置为普通用户
try:typehtml = soup.find("div",{'class':"woo-avatar-main woo-avatar-hover ProfileHeader_avatar2_1gEyo"})user_type = typehtml.find("span").get("title")web_object['user_type'] = user_typeprint("用户类型", user_type)except AttributeError as e:web_object['user_type'] = '普通用户'print("用户类型:", '普通用户')
(8)获取用户性别
genderhtml = soup.find("div",{'class': "woo-box-flex woo-box-alignCenter ProfileHeader_h3_2nhjc"})gender = genderhtml.find("span").get("title").strip()print("用户性别:", gender)web_object['gender'] = gender
(9)获取用户的粉丝和关注人数
fanshtml = soup.find("div",{'class': "woo-box-flex woo-box-alignCenter ProfileHeader_h4_gcwJi"})
followers = fanshtml.findAll("a")[0].get_text().strip('粉丝')
followers =followers[3:]
follow = fanshtml.findAll("a")[1].get_text().strip('关注')
follow = follow[3:]
print("粉丝数量:",followers,"关注人数:",follow)
web_object['follow'] = follow
web_object['followers'] = followers
(10)获取用户的ip以及年龄,
地址有两种,一种直接在用户界面写ip属地后面接ip地址,另一种是地点的小图标后接ip地址,所以需要先判断是不是能用第一种拿到ip,不行就用第二种,都不行就是没有ip
浏览器检查网页可以发现,展开后的一条条的信息标签都是一样的,不好区分,这里采用获取文本信息后进行关键词的监测来从中获取ip属地和出生日期

# 点击展开用户主页信息button = web.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[2]/main/div/div/div[2]/div[1]/div[1]/div[3]/div/div/div[2]')button.click()html = web.page_sourcesoup = bs(html, 'html.parser')ipflag = 0# 为1时表示已经获取ip信息infohtml = soup.findAll("div",{'class': "woo-box-item-flex ProfileHeader_con3_Bg19p"})for info in infohtml:str1 = str(info.get_text()).strip()print(str1)try:if (keywords_check('加入微博', str1)):#日期后面跟一个“加入微博”,排除print("加入微博时间,不是生日")else: # 正则匹配日期格式result = re.findall("d{4}[-|.|/]?d{2}[-|.|/]?d{2}", str1)if(result):print("生日", result[0])age = age_calc(result[0], '2024-01-06')#网上搜的一个生日计算的方法print(age)web_object['age'] = ageexcept TypeError as e:print('')if (keywords_check('IP属地', str1)):# 检查用户主页是否有ip属地这种格式的ipipflag = 1 # 有的话标记为1,表示已经拿到ipip = str1[5:] # 将(ip属地:)五个字符去掉,保留后面的地址print("地址", ip)if ipflag == 0: #如果前面没找到ip属地,则找ip图标来判断try:iphtml = soup.find("div",{'class':"ProfileHeader_box3_2R7tq"})ip = iphtml.find("i",{'class':"woo-font woo-font--proPlace"}).parent.parent.get_text()print("ip:", ip)except AttributeError as e:print("该用户没有ip信息")
网上随便找的根据日期计算生日的方法
def age_calc(birth_date, end_date):# 将日期转化为datetime类型birth_date = datetime.strptime(birth_date, '%Y-%m-%d')end_date = datetime.strptime(end_date, '%Y-%m-%d')# 分别计算年月日day_diff = end_date.day - birth_date.daymonth_diff = end_date.month - birth_date.monthyear_diff = end_date.year - birth_date.yearif day_diff >= 0:if month_diff >= 0:years_old = year_diffelse:years_old = year_diff - 1else:if month_diff >= 1:years_old = year_diffelse:years_old = year_diff - 1return years_old
检查关键词的方法,keywords是要找的关键词,text是全部文本
def keywords_check(keyswords, text):keyswordsresult = re.search(keyswords, text)return result
4、保存数据
# 保存数据
def save_data(web_data,filename):fieldnames = ['mid', 'text', 'date', 'user_name', 'gender', 'follow', 'followers','age','ip','user_type','user_link','repost_num','comment_num','like_num']with open(filename, mode='a', newline='', encoding='utf-8-sig') as f:writer = csv.DictWriter(f, fieldnames=fieldnames)# 判断表格内容是否为空,如果为空就添加表头if not os.path.getsize(filename):writer.writeheader() # 写入表头writer.writerows([web_data])
如此一来,一个微博内容以及发布者的信息获取就完成了,我们保存数据后再次切换网页到搜索页面,在此之后就是继续对前文提到的微博列表list里面的下一个微博进行上述处理,文章3.1写到的for已经帮助我们进行了循环功能,所以这下面的代码放在for循环里面就可以了
save_data(web_object, filename)# 保存web.close()# 回到主页面web.switch_to.window(web.window_handles[0])
5、搜索结果翻页
前面我们只实现了一页网页的数据,下面实现翻页
page_count = 50 # 总页数设置for page in range(page_count):print('开始获取第%d页的搜索结果'%(page+1))temp =str(page+1)url ='https://s.weibo.com/weibo?q=关键词&Refer=index&page=%s'%(temp)filename = os.getcwd()+'/data/微博/搜索结果.csv' # 没有目录就新建一个目录start_crawler(url, filename)
将以上内容串起来
下面的start_crawler函数就是爬虫的主体,也就是写
web.get(url)
print(“=开始了开始啦====”)
html = web.page_source
等等等上述代码
if __name__ == '__main__':# 测试用的url链接page_count = 50 # 总页数设置for page in range(page_count):# for循环进行翻页print('开始获取第%d页的搜索结果'%(page+1))temp =str(page+1)url ='https://s.weibo.com/weibo?q=关键词&Refer=index&page=%s'%(temp)filename = os.getcwd()+'/data/关键词.csv' # 没有目录就先新建一个目录start_crawler(url, filename)
6、微博的评论信息获取
这是另一个python文件了,这里用的评论链接获取的网页和前面的网页不同,是json格式的数据,解析数据时用到的方法不同,详情可以自行搜索
6.1先看主函数
read_mid读取目标微博的mid号列表,然后用mid拼成每条微博评论所在的链接url,通过start_crawler爬取每条微博的所有评论
if __name__ == '__main__':# 测试用的url链接filename = r"放你上面步骤爬取得到的的文件路径"write_path = r"随意路径微博评论.csv"midlist = read_mid(filename)count = 1for i in midlist:if count >9:print("====================第%d篇微博==============="%count)mid = i[3:]url = 'https://m.weibo.cn/comments/hotflow?id=%s&mid=%s'%(mid,mid)print(url)start_crawler(url, write_path,i)# 也存一下评论属于哪一条微博count = count+1
6.2 read_mid函数
def read_mid(filename):data = pd.read_csv(filepath_or_buffer=filename, encoding="utf-8",converters={"mid":str})return data['mid'][data['comment_num']>=10] # 获取评论数不少于10的微博mid
6.3 start_crawler函数
涉及到评论翻页的问题,评论翻页用max_id来标记(微博自己设置的),为0时翻页完毕
将获取的网页数据识别成json处理
def start_crawler(url,filename,mid):comment_url = urlmax_id = 1 # 评论翻页的位置page = 1while (max_id):if max_id == 0:breakelif max_id != 1:url = comment_url+'&max_id='+str(max_id)print(url)print("======================第%d页===================="%page)web.get(url)time.sleep(random.randint(3, 6)) # 不要爬取太快哦,小心被关进小黑屋html = web.page_sourcesoup = bs(html, 'lxml')ss = soup.select('pre')[0]res = json.loads(ss.text) # 转json格式max_id = get_info(web,res,filename,mid) # 获取一页评论,并且返回max_id用于翻页page = page+1
6.3 get_info 函数
不太想解释了,下次有空再解释吧
计算年龄的函数同上文
def get_info(web,res,filename,mid):try :datalist = res['data']['data']except KeyError as e:returnmax_id = res['data']['max_id']for i in datalist:web_object = {}web_object['mid'] = midprint("[34m发表时间:[0m" + i['created_at'])web_object['date'] = i['created_at']print("[35m评论内容:[0m" + i['text'])web_object['text'] = i['text']print("[36m位置:[0m" + str(i['source'])[2:])web_object['ip'] = str(i['source'])[2:]print("[36m昵称:[0m" + i['user']['screen_name'])web_object['user_name'] = i['user']['screen_name']print("[31m个签:[0m" + i['user']['description'])web_object['status'] = i['user']['description']user_id = '%d' % (i['user']['id'])print("[37mid号:[0m" + user_id)web_object['user_id'] = user_iduser_link = "https://weibo.com/"+user_id+ '?refer_flag=1001030103_'print("[36m用户主页:[0m" + user_link)web_object['user_link'] = user_linkprint("[32m性别:[0m" + i['user']['gender'])web_object['gender'] = i['user']['gender']user_follow_count = '%d' % (i['user']['follow_count'])print("[31m关注人数:[0m" + user_follow_count)web_object['follow'] = user_follow_countuser_followers_count = (i['user']['followers_count'])print("[31m被关注人数:[0m" + user_followers_count)web_object['followers'] = user_followers_count# =========================================切换到用户主页的窗口user_url = "'" + user_link + "'"js = "window.open(" + user_url + ");"web.execute_script(js)time.sleep(random.randint(2, 5))# 切换到新窗口# 获得打开的第一个窗口句柄window_1 = web.current_window_handle# 获得打开的所有的窗口句柄windows = web.window_handlesfor current_window in windows:if current_window != window_1:web.switch_to.window(current_window)html = web.page_sourcesoup = bs(html, 'html.parser')print("切换到用户主页")web.implicitly_wait(4)try:typehtml = soup.find("div", {'class': "woo-avatar-main woo-avatar-hover ProfileHeader_avatar2_1gEyo"})user_type = typehtml.find("span").get("title")web_object['user_type'] = user_typeprint("用户类型:", user_type)except AttributeError as e:web_object['user_type'] = '普通用户'print("用户类型:", '普通用户')# ============================点击展开============================button = web.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[2]/main/div/div/div[2]/div[1]/div[1]/div[3]/div/div/div[2]')button.click()html = web.page_sourcesoup = bs(html, 'html.parser') # woo-box-item-inlineBlock ProfileHeader_item3_1bUM2,woo-box-item-flex ProfileHeader_con3_Bg19pinfohtml = soup.findAll("div", {'class': "woo-box-item-flex ProfileHeader_con3_Bg19p"})# print(infohtml)for info in infohtml:str1 = str(info.get_text()).strip()# print(str1)try:if (keywords_check('加入微博', str1)):print("加入微博时间,不是生日")else:result = re.findall("d{4}-d{2}-d{2}", str1)if (len(result) != 0):try :print("生日:", result[0])age = age_calc(result[0], '2024-01-06')print(age)web_object['age'] = ageexcept ValueError as e:print('')except TypeError as e:print('没有年龄信息')# sys.exit() # 退出当前程序,但不重启shelltime.sleep(random.randint(2, 6))web.close()# 回到主页面web.switch_to.window(web.window_handles[0])save_data(web_object, filename)print(max_id)return max_id
相关文章:
【保姆级爬虫】微博关键词搜索并获取博文和评论内容(python+selenium+chorme)
微博爬虫记录 写这个主要是为了防止自己忘记以及之后的组内工作交接,至于代码美不美观,写的好不好,统统不考虑,我只能说,能跑就不错了,上学压根没学过python好吧,基本上是crtlc&ctrlv丝滑小…...

Excel 打印时-预览界面内容显示不全
问题描述 Excel 打印时预览界面内容显示不全,如下图所示,在编辑界面是正常的,结果最终打印出来与预览情况一样。 编辑界面 预览界面 解决办法 此时我的字体是宋体,将字体改为等线,问题得到解决。 打印预览界面...

nginx-限流(请求/并发量)
一. 简述: 在做日常的web运维工作中,难免会遇到服务器流量异常,负载过大等情况。恶意攻击访问/爬虫等非正常性请求,会带来带宽的浪费,服务器压力增大,影响业务质量。 二. 限流方案: 对于这种情…...

Vue——使用html2pdf插件,下载pdf文档到本地
1.安装 html2pdf官网地址 npm install html2pdf.js pnpm add html2pdf.js2.引入 import html2pdf from html2pdf.js3.我的项目是使用的原生avascript,table tr td画表格然后通过html2pdf插件下载pdf。 问题:下载pdf时内容被截断,如下图所示…...

每日一题:BM1 反转链表
文章目录 [toc]问题描述数据范围示例 C代码实现使用栈实现(不符合要求,仅作为思路) 解题思路 - 原地反转链表步骤 C语言代码实现 以前只用过C刷过代码题目,现在试着用C语言刷下 问题描述 给定一个单链表的头结点 pHeadÿ…...

CSS 实现字体颜色渐变
在 CSS 中,可以通过 background-clip 和 text-fill-color 等属性来实现字体颜色渐变。以下是实现字体颜色渐变的基本步骤和示例代码: 示例代码 <!DOCTYPE html><html lang"en"><head><meta charset"UTF-8" /&…...

【软考网工笔记】计算机基础理论与安全——网络安全
病毒 Melissa 宏病毒 1. 是一种快速传播的能够感染那些使用MS Word 97 和MS Office 2000 的计算机宏病毒。 2. 前面有**Macro** 表示这是宏病毒; 3. 宏病毒可以感染后缀为.xls的文件;Worm 蠕虫病毒 1. 通常是通过网络或者系统漏洞进行传播。 2. 利用信…...
)
JS数组转字符串(3种方法)
JavaScript 允许数组与字符串之间相互转换。其中 Array 方法对象定义了 3 个方法,可以把数组转换为字符串,如表所示。 Array 对象的数组与字符串相互转换方法 数组方法 说明 toString() 将数组转换成一个字符串 toLocalString() 把数组转换成本地约定的…...

云计算安全需求分析与安全防护工程
23.1 概念与威胁分析 1)概念 在传统计算环境下,用户构建一个新的应用系统,需要做大量繁杂的工作,如采购硬件设备、安装软件包、编写软件,同时计算资源与业务发展难以灵活匹配,信息系统项目建设周期长。随…...

C/C++的printf会调用malloc()
排查内存问题(或相关的疑难杂症)时,可能一句printf就能让bug出现,或者赶走bug。你可能觉得很神奇,但这并不神奇。 至少我们可以在 Linux-x64 下,通过 malloc hook,来验证当前的编译环境下&…...

spring mvc源码学习笔记之五
pom.xml 内容如下 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/P…...

3272 小蓝的漆房
将devc设置支持编译就能用新的遍历方式 for(auto &x : s)//遍历容器s,变量为x /* 多循环的嵌套: 计数是否需要重置为0; 是否因为ans定义成全局变量导致ans在比较多时候会出现错误*/ /* 1.对于一个标准色,对目标数组遍历, 如…...

MySQL使用触发器进行备份
触发器脚本备份 实现方案: 1.配置mysql调用外部脚本的插件mysqludf 链接:https://pan.baidu.com/s/1MCrf1u_SRWwcZoxM9JDNiw 提取码:kgt0 解压 2.解压后放进: mysql安装路径/lib/plugin/ 3.在mysql执行命令创建自定义函数&…...

数据结构与算法-顺序表
数据结构 顺序表 基本概念 顺序表:顺序存储的线性表链式表:链式存储的线性表,简称链表 顺序存储就是将数据存储到一片连续的内存中,在C语言环境下,可以是具名的栈数组,也可以是匿名的堆数组。 存储方式…...

OpenAI CEO 奥特曼发长文《反思》
OpenAI CEO 奥特曼发长文《反思》 --- 引言:从 ChatGPT 到 AGI 的探索 ChatGPT 诞生仅一个多月,如今我们已经过渡到可以进行复杂推理的下一代模型。新年让人们陷入反思,我想分享一些个人想法,谈谈它迄今为止的发展,…...
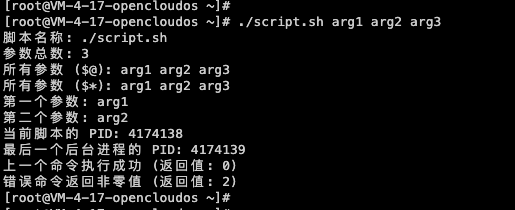
Shell编程详解
文章目录 一、Linux系统结构二、Shell介绍1、Shell简介2、Shell种类3、Shell查询和切换 三、Shell基础语法1、注释2、本地变量3、环境变量3.1、查看环境变量3.2、临时设置环境变量3.3、永久设置环境变量 4、特殊变量5、控制语句5.1、shell中的中括号5.2、if语句5.3、for循环5.4…...
详解)
跨站脚本攻击(XSS)详解
跨站脚本攻击(XSS)详解 跨站脚本攻击(XSS,Cross-Site Scripting)是一种通过在网页中注入恶意脚本,攻击用户浏览器的漏洞。攻击者可以利用XSS窃取用户敏感信息、劫持会话、或在受害者浏览器中执行恶意操作。…...

03-QT中的QMainWindow+对话框QDialog
文章目录 1.QMainWindow1.1菜单栏1.2 工具栏1.3 状态栏1.4 铆接部件1.5 核心部件(中心部件)1.6 资源文件 2.对话框2.1 基本概念2.2 标准对话框2.3 自定义消息框2.4 消息对话框2.5 标准文件对话框 1.QMainWindow QMainWindow是一个为用户提供主窗口程序的…...

c# 中Parallel.ForEach 对其中一个变量进行赋值 引发报错
在 C# 中使用 Parallel.ForEach 方法时,如果你尝试在并行循环中对共享变量进行赋值,很可能会遇到线程安全问题或竞争条件(race conditions),这可能导致数据不一致、程序崩溃或其他不可预测的行为。 问题描述 假设你有…...

ElasticSearch备考 -- 整体脉络梳理
1、 search 、Update、reindex ElasticSearch 备考 -- 查询&高亮&排序 ElasticSearch 备考 -- 聚合查询 ElasticSearch 备考 -- 异步检索 2、search temple ElasticSearch备考 -- Search template 3、custom analyzer ElasticSearch 备考 -- 自定义分词 2、…...

NVIDIA Profile Inspector终极配置指南:如何解决常见问题并深度优化显卡设置
NVIDIA Profile Inspector终极配置指南:如何解决常见问题并深度优化显卡设置 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款强大的NVIDIA显卡配置管理工具&…...

node-oauth错误处理指南:如何优雅处理认证失败和重定向
node-oauth错误处理指南:如何优雅处理认证失败和重定向 【免费下载链接】node-oauth OAuth wrapper for node.js 项目地址: https://gitcode.com/gh_mirrors/no/node-oauth 在使用node-oauth进行OAuth认证时,错误处理是确保应用稳定性和用户体验的…...

Unity Shader实战:从顶点到片元,手把手教你打造第一个自定义水波纹效果
Unity Shader实战:从顶点到片元,手把手教你打造第一个自定义水波纹效果 在游戏开发中,水面效果一直是提升场景真实感的关键元素之一。想象一下,当玩家走过一片湖泊,水面泛起细腻的波纹,阳光在水面上跳跃&am…...

低浓度瓦斯处理痛点破解|GC-BLOCK瓦斯热电系统实测分享
作为深耕低浓度瓦斯利用设备领域5年的从业者,先后走访50煤矿现场(山西吕梁、陕西榆林、内蒙古鄂尔多斯等),接触过各类瓦斯处理项目,深知煤矿低浓度瓦斯(浓度<8%)处理的核心痛点与行业困境。近…...

深入解析图像感知质量指标:从PSNR到Perceptual Index的实践指南
1. 图像质量评估的两种视角:从像素匹配到主观感知 当你用手机拍完照片准备发朋友圈时,可能会纠结要不要加滤镜——原图细节更丰富但略显平淡,滤镜版色彩鲜艳可细节模糊。这种选择困境背后,正是图像质量评估的两大流派:…...

为什么Alfred Workflows能极大提升你的工作效率?7个真实案例分享
为什么Alfred Workflows能极大提升你的工作效率?7个真实案例分享 【免费下载链接】alfred-workflows Collection of Alfred workflows 项目地址: https://gitcode.com/gh_mirrors/alfr/alfred-workflows Alfred Workflows是一款强大的效率工具集合࿰…...
重构?)
第十二节:老旧系统改造——如何安全地让 AI 介入遗留代码(Legacy Code)重构?
引言 承接上一章对自动化编程安全的探讨,本章聚焦企业中最为棘手的遗留代码(Legacy Code)改造难题。面对缺乏文档、结构混乱的老旧系统,直接让AI“重新编写”往往导致更多隐患,本章将探讨如何安全、稳妥地引入AI进行重构。 核心理论 遗留代码大多缺乏设计文档、单元测试…...

避坑指南:Vue3 + Maotu流程图编辑器集成时,Token失效、样式丢失等5个常见问题怎么解决?
Vue3与Maotu流程图编辑器深度集成:5大核心问题解决方案与实战优化 在工业物联网和复杂业务系统开发中,可视化流程编辑器的集成质量直接影响开发效率和系统稳定性。Maotu作为国内领先的流程图编辑组件,与Vue3的深度整合为开发者提供了强大的可…...

2026年OpenClaw怎么集成?阿里云1分钟保姆级教程+大模型APIKey配置、Skill集成教程
2026年OpenClaw怎么集成?阿里云1分钟保姆级教程大模型APIKey配置、Skill集成教程。本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环境配置、服务启动…...
yz-bijini-cosplay一文详解:Z-Image端到端Transformer架构优势解析
yz-bijini-cosplay一文详解:Z-Image端到端Transformer架构优势解析 1. 项目概述 yz-bijini-cosplay是一个专为RTX 4090显卡优化的Cosplay风格文生图解决方案。该项目基于通义千问Z-Image端到端Transformer架构,结合专属训练的LoRA权重,实现…...