Neo4j的部署和操作
注:本博文展示部署哥操作步骤和命令,具体报告及运行截图可通过上方免费资源绑定下载
一.数据库的部署与配置
在单个节点上对进行数据库的单机部署
(1)上传neo4j-community-3.5.30-unix.tar.gz到hadoop1的/export/software目录
(2)解压缩neo4j:$ tar -xzf /export/software/neo4j-community-3.5.30-unix.tar.gz -C /export/servers/
(3)进入Neo4j解压缩目录,修改conf目录下的配置文件neo4j.conf
·cd /export/servers/neo4j-community-3.5.30
·vi conf/neo4j.conf
修改内容如下:
(4)启动Neo4j数据库:bin/neo4j start
(5)停止Neo4j数据库:bin/neo4j stop
(6)重启Neo4j数据库:bin/neo4j restart
- 查看Neo4j数据库的状态:bin/neo4j status
(8)使用web访问http://hadoop1:7474, 默认用户名和密码均为“neo4j”
(9)在输入框中输入指令可以显示教程:play start
二.使用命令访问数据库
1.节点和关系的创建:创建节点(包括属性)、创建关系、创建唯一节点。
(1)创建节点:创建三个Person节点,分别代表 Alice、Bob 和 Charlie,每个节点都有name和age属性。
·CREATE (a:Person {name: 'Alice', age: 28})
·CREATE (b:Person {name: 'Bob', age: 32})
·CREATE (c:Person {name: 'Charlie', age: 25})
- 创建关系:使用MATCH找到指定的节点(Alice, Bob, Charlie),然后使用CREATE创建关系KNOWS,表示他们之间相互认识。
// Alice 认识 Bob
·MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'})
·CREATE (a)-[:KNOWS]->(b)
// Bob 认识 Charlie
·MATCH (b:Person {name: 'Bob'}), (c:Person {name: 'Charlie'})
·CREATE (b)-[:KNOWS]->(c)
(3)创建唯一节点:确保只有一个名为 'Charlie' 的节点存在
·MERGE (d:Person {name: 'Charlie'})
2.节点和关系的查询:查询节点、条件查询、查询关系
(1)查询节点:查询所有Person节点并查看它们的name和age属性。
·MATCH (n:Person)
·RETURN n.name, n.age
- 条件查询:查询年龄大于30的用户,并返回他们的name和age。
·MATCH (n:Person)
·WHERE n.age > 30
·RETURN n.name, n.age
- 查询关系:查询所有的KNOWS关系,并返回两个节点(a和b)以及它们之间的关系(r)
·MATCH (a:Person)-[r:KNOWS]->(b:Person)
·RETURN a.name, b.name, r
3.更新标签或属性:更新属性、更新标签
(1)更新属性:更新name为'Alice'的Person节点的age属性为30
·MATCH (n:Person {name: 'Alice'})
·SET n.age = 30
(2)更新标签:给name为'Alice'的Person节点添加了一个新的标签Employee,表示她同时是Employee类型的节点。
·MATCH (n:Person {name: 'Alice'})
·SET n:Employee
上述操作更新后的节点表如下:
4.删除节点和关系:删除属性、删除节点、删除关系、删除所有的节点和关系
(1)删除属性:删除name为'Alice'的Person节点的age属性。
·MATCH (n:Person {name: 'Alice'})
·REMOVE n.age
(2)删除节点:删除name为'Bob'的Person节点
·MATCH (n:Person {name: 'Bob'})
·DETACH DELETE n
- 删除关系:删除名为 Alice 和 Bob 之间的 KNOWS 关系
·MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person {name: 'Bob'})
·DELETE r
(4)删除所有的节点和关系:
·MATCH (n)
·DETACH DELETE n
三.数据库的设计
图书管理系统包含两个主要实体:图书和读者。它们之间通过一个关系来进行联系,借阅记录表示图书与读者之间的借阅关系,本系统共设计两个节点标签,分别是图书(存储图书的相关信息)和读者(存储读者的基本信息),一个关系标签借阅关系(表示图书与读者之间的借阅关系)。
1.数据库设计
(1)图书节点标签
标签名称:Book
属性:
title:图书名称
category:图书类别,如文学、小说等
published_date:图书出版日期
author_name:作者名称
author_birth_date:作者出生日期
publisher_name:出版商名称
publisher_address:出版商地址
(2)读者节点标签
标签名称:Reader
属性:
name:读者姓名
dob:读者出生日期
email:电子邮件
phone_number:联系电话
address:住址
(3)借阅关系标签
标签名称:BORROWED
连接节点:Reader与Book
属性:
borrow_date:借阅日期
return_date:归还日期
(4)实体与关系的增删改查
①新增操作
新增图书:使用 CREATE 命令添加新的图书节点(Book)。图书节点包括图书的标题、类别、出版日期、作者信息、出版商等属性。
新增借阅记录:使用 CREATE 命令在图书与读者之间建立一个新的借阅关系(BORROWED)。该关系包含借阅日期、归还日期等属性,连接已存在的读者节点(Reader)和图书节点(Book)。
新增读者:使用 CREATE 命令添加新的读者节点(Reader)。读者节点包括读者的姓名、出生日期、联系信息(如电话、地址、电子邮件等)等属性。
②删除操作
删除图书:使用 DELETE 命令删除指定的图书节点(Book)。删除时需要先找到该图书节点,可以通过图书标题等属性进行匹配。
删除借阅记录:使用 DELETE 命令删除图书与读者之间的借阅关系(BORROWED)。通过匹配读者和图书的具体信息,删除它们之间的借阅关系。
删除读者:使用 DELETE 命令删除指定的读者节点(Reader)。删除时需要先找到该读者节点,并确认与该读者相关的借阅关系(如果有)是否也需要删除。
③更新操作
更新图书信息:使用 SET 命令更新图书节点的某些属性,如图书的标题、作者、出版商等信息。通过匹配图书的具体属性(如标题),更新节点中的内容。
更新借阅记录:使用 SET 命令更新借阅关系的属性,如借阅日期、归还日期等。通过匹配特定的读者和图书,更新相应的借阅记录。
更新读者信息:使用 SET 命令更新读者节点的某些属性,如读者的姓名、电子邮件、联系电话等。通过匹配读者的具体信息(如姓名),更新该节点的内容。
④查询操作
查询某本图书的详细信息:使用 MATCH 命令查询图书节点的相关信息。可以根据图书的标题、作者或其他属性来查询图书的详细信息。
查询某本图书的借阅记录:使用 MATCH 命令查询所有借阅特定图书的记录。可以通过图书的标题或ID,找到借阅该图书的所有读者,以及借阅的日期和归还日期等信息。
查询某位读者的借阅记录:使用 MATCH 命令查询特定读者的所有借阅记录。通过读者的姓名或ID,查询该读者借阅的所有图书,并返回图书的详细信息(如标题、作者等)。
查询某位读者的详细信息:使用 MATCH 命令查询读者的详细信息。可以根据读者的姓名或ID,返回该读者的姓名、出生日期、联系方式等信息。
2.图设计与填充数据
(1)图书节点数据填充
CREATE (b1:Book {
title: '活着',
category: '文学',
published_date: '1993-06-01',
author_name: '余华',
author_birth_date: '1960-04-03',
publisher_name: '作家出版社',
publisher_address: '北京市朝阳区'
})
CREATE (b2:Book {
title: '百年孤独',
category: '小说',
published_date: '1967-06-05',
author_name: '加西亚·马尔克斯',
author_birth_date: '1927-03-06',
publisher_name: '南海出版公司',
publisher_address: '上海市徐汇区'
})
(2)读者节点数据填充
CREATE (r1:Reader {
name: '张三',
dob: '1990-05-15',
email: 'zhsan@email.com',
phone_number: '123-4567-8901',
address: '北京市海淀区'
})
CREATE (r2:Reader {
name: '李四',
dob: '2005-02-28',
email: 'lisi@email.com',
phone_number: '987-6543-2100',
address: '上海市浦东新区'
})
(3)借阅关系节点数据填充
MATCH (r:Reader {name: '张三'}), (b:Book {title: '活着'})
CREATE (r)-[:BORROWED {borrow_date: '2024-11-01', return_date: '2024-11-15'}]->(b)
MATCH (r:Reader {name: '李四'}), (b:Book {title: '百年孤独'})
CREATE (r)-[:BORROWED {borrow_date: '2024-11-02', return_date: '2024-11-20'}]->(b)
四.编程实现数据库的访问
使用Python访问实现设计的图书管理系统的Neo4j数据库,步骤如下:
(1)在Python中连接到Neo4j数据库:
import neo4j
# 数据库连接
uri = "neo4j://localhost:7687" # Neo4j默认连接端口
username = "neo4j"
password = "neo4j"
driver = neo4j.GraphDatabase.driver(uri, auth=(username, password))
(2)图书管理系统包含以下节点类型和关系:
Book:图书节点,包含书名、作者、出版日期等属性。
Reader:读者节点,包含姓名、联系方式等属性。
BORROWED:借阅关系,表示图书与读者之间的借阅关系,包含借阅日期和归还日期。
创建这些节点的函数:
def create_book(tx, title, category, published_date, author_name, author_birth_date, publisher_name, publisher_address):
query = (
"CREATE (b:Book {title: $title, category: $category, published_date: $published_date, "
"author_name: $author_name, author_birth_date: $author_birth_date, "
"publisher_name: $publisher_name, publisher_address: $publisher_address})"
)
tx.run(query, title=title, category=category, published_date=published_date,
author_name=author_name, author_birth_date=author_birth_date,
publisher_name=publisher_name, publisher_address=publisher_address)
def create_reader(tx, name, dob, email, phone_number, address):
query = (
"CREATE (r:Reader {name: $name, dob: $dob, email: $email, "
"phone_number: $phone_number, address: $address})"
)
tx.run(query, name=name, dob=dob, email=email, phone_number=phone_number, address=address)
(3)插入图书和读者:
def insert_data():
with driver.session() as session:
# 新增图书
session.write_transaction(create_book, "活着", "文学", "1993-06-01", "余华", "1960-04-03", "作家出版社", "北京市朝阳区")
session.write_transaction(create_book, "百年孤独", "小说", "1967-06-05", "加西亚·马尔克斯", "1927-03-06", "南海出版公司", "上海市徐汇区")
# 新增读者
session.write_transaction(create_reader, "张三", "1990-05-15", "zhsan@email.com", "123-4567-8901", "北京市海淀区")
session.write_transaction(create_reader, "李四", "2005-02-28", "lisi@email.com", "987-6543-2100", "上海市浦东新区")
(4)查询所有图书及其属性:
def get_all_books(tx):
query = "MATCH (b:Book) RETURN b.title AS title, b.author_name AS author, b.published_date AS published_date"
result = tx.run(query)
for record in result:
print(f"Title: {record['title']}, Author: {record['author']}, Published Date: {record['published_date']}")
(5)更新图书的出版日期:
def update_book(tx, title, new_publish_date):
query = "MATCH (b:Book {title: $title}) SET b.published_date = $new_publish_date"
tx.run(query, title=title, new_publish_date=new_publish_date)
更新《活着》:session.write_transaction(update_book, "活着", "1993-07-01")
(6)删除某本图书和读者节点:
def delete_book(tx, title):
query = "MATCH (b:Book {title: $title}) DELETE b"
tx.run(query, title=title)
def delete_reader(tx, name):
query = "MATCH (r:Reader {name: $name}) DELETE r"
tx.run(query, name=name)
(7)建立图书与读者之间的借阅关系:
def create_borrowed_relationship(tx, book_title, reader_name, borrow_date, return_date):
query = (
"MATCH (b:Book {title: $book_title}), (r:Reader {name: $reader_name}) "
"CREATE (r)-[:BORROWED {borrow_date: $borrow_date, return_date: $return_date}]->(b)"
)
tx.run(query, book_title=book_title, reader_name=reader_name, borrow_date=borrow_date, return_date=return_date)
建立张三与《活着》之间的关系:session.write_transaction(create_borrowed_relationship, "活着", "张三", "2024-11-01", "2024-11-15")
相关文章:

Neo4j的部署和操作
注:本博文展示部署哥操作步骤和命令,具体报告及运行截图可通过上方免费资源绑定下载 一.数据库的部署与配置 在单个节点上对进行数据库的单机部署 (1)上传neo4j-community-3.5.30-unix.tar.gz到hadoop1的/export/so…...

react axios 优化示例
使用 axios 是 React 项目中非常常见的 HTTP 请求库。为了提升 axios 在 React 中的性能、可维护性和用户体验,我们可以从 代码组织、请求优化 和 用户体验优化 多个角度进行详细的优化。 一、安装与基础配置 安装 axios npm install axios创建 Axios 实例 为了更好地管理…...

探索数字化展馆:开启科技与文化的奇幻之旅
在科技飞速发展的当下,数字展馆作为一种新兴的展示形式,正逐渐走进大众的视野。数字展馆不仅仅是传统展馆的简单“数字化升级”,更是融合了多媒体、数字化技术以及人机交互等前沿科技的创新产物。 数字展馆借助VR、AR、全息投影等高科技手段&…...

基于深度学习的视觉检测小项目(七) 开始组态界面
开始设计和组态画面。 • 关于背景和配色 在组态画面之前,先要确定好画面的风格和色系。如果有前端经验和美术功底,可以建立自己的配色体系。像我这种工科男,就只能从网络上下载一些别人做好的优秀界面,然后在photo shop中抠取色…...

AI赋能跨境电商:魔珐科技3D数字人破解出海痛点
跨境出海进入狂飙时代,AI应用正在深度渗透并重塑着跨境电商产业链的每一个环节,迎来了发展的高光时刻。生成式AI时代的大幕拉开,AI工具快速迭代,为跨境电商行业的突破与飞跃带来了无限可能性。 由于跨境电商业务自身特性鲜明&…...

【C/C++】nlohmann::json从文件读取json,并进行解析打印,实例DEMO
使用 json::parse 函数将JSON格式的字符串解析为 nlohmann::json 对象。这个函数支持多种输入源,包括字符串、文件流等。 #include <iostream> #include <nlohmann/json.hpp> #include <fstream>using json nlohmann::json;int main() {// 解析…...

安装Anaconda搭建Python环境,并使用VSCode作为IDE运行Python脚本
下面详细说明如何安装Anaconda搭建Python环境,并使用VSCode作为编辑器运行Python脚本的过程: 1. 下载Anaconda 访问Anaconda的官方网站:https://www.anaconda.com/products/distribution 3. 根据您的操作系统选择适合的版本下载。Anaconda支…...
)
我用AI学Android Jetpack Compose之入门篇(1)
这篇我们先来跑通第一个Android Jetpack Compose工程,现在新版本的Android Studio,新建工程选择Empty Activity默认就会开启Jetpack Compose的支持,再次声明,答案来自 通义千问Ai 文章目录 1.用Android Jetpack Compose需要安装什…...

使用 Docker 查看 Elasticsearch 错误日志
在使用 Elasticsearch(简称 ES)的过程中,我们可能会遇到各种问题。为了快速定位和解决这些问题,查看错误日志是关键。本文将介绍如何使用 Docker 查看 Elasticsearch 的错误日志,并提供一些实用技巧。 1. 安装 Docker…...

使用Apache Mahout制作 推荐引擎
目录 创建工程 基本概念 关键概念 基于用户与基于项目的分析 计算相似度的方法 协同过滤 基于内容的过滤 混合方法 创建一个推荐引擎 图书评分数据集 加载数据 从文件加载数据 从数据库加载数据 内存数据库 协同过滤 基于用户的过滤 基于项目的过滤 添加自定…...

Elasticsearch:利用 AutoOps 检测长时间运行的搜索查询
作者:来自 Elastic Valentin Crettaz 了解 AutoOps 如何帮助你调查困扰集群的长期搜索查询以提高搜索性能。 AutoOps 于 11 月初在 Elastic Cloud Hosted 上发布,它通过性能建议、资源利用率和成本洞察、实时问题检测和解决路径显著简化了集群管理。 Au…...

python二元表达式 三元表达式
目录 二元表达式必须要有else,示例: 二元表达式: 三元表达式 可以嵌套成多元表达式 python 代码中,有时写 if else比较占行,把代码变一行的方法就是二元表达式, 二元表达式必须要有else,示例: if img is None:breakcv2.imwrite("aaa.jpg", img) if coun…...

计算机网络 (22)网际协议IP
一、IP协议的基本定义 IP协议是Internet Protocol的缩写,即因特网协议。它是TCP/IP协议簇中最核心的协议,负责在网络中传送数据包,并提供寻址和路由功能。IP协议为每个连接在因特网上的主机(或路由器)分配一个唯一的IP…...

【UI自动化测试】selenium八种定位方式
🏡个人主页:謬熙,欢迎各位大佬到访❤️❤️❤️~ 👲个人简介:本人编程小白,正在学习互联网求职知识…… 如果您觉得本文对您有帮助的话,记得点赞👍、收藏⭐️、评论💬&am…...

REMARK-LLM:用于生成大型语言模型的稳健且高效的水印框架
REMARK-LLM:用于生成大型语言模型的稳健且高效的水印框架 前言 提出这一模型的初衷为了应对大量计算资源和数据集出现伴随的知识产权问题。使用LLM合成类似人类的内容容易受到恶意利用,包括垃圾邮件和抄袭。 ChatGPT等大语言模型LLM的开发取得的进展标志着人机对话交互的范式…...

Android SPRD 工模测试修改
设备有两颗led灯,工模测试需全亮 vendor/sprd/proprietories-source/factorytest/testitem/led.cpp -13,6 13,10 typedef enum{#define LED_BLUE "/sys/class/leds/blue/brightness"#define LED_RED …...
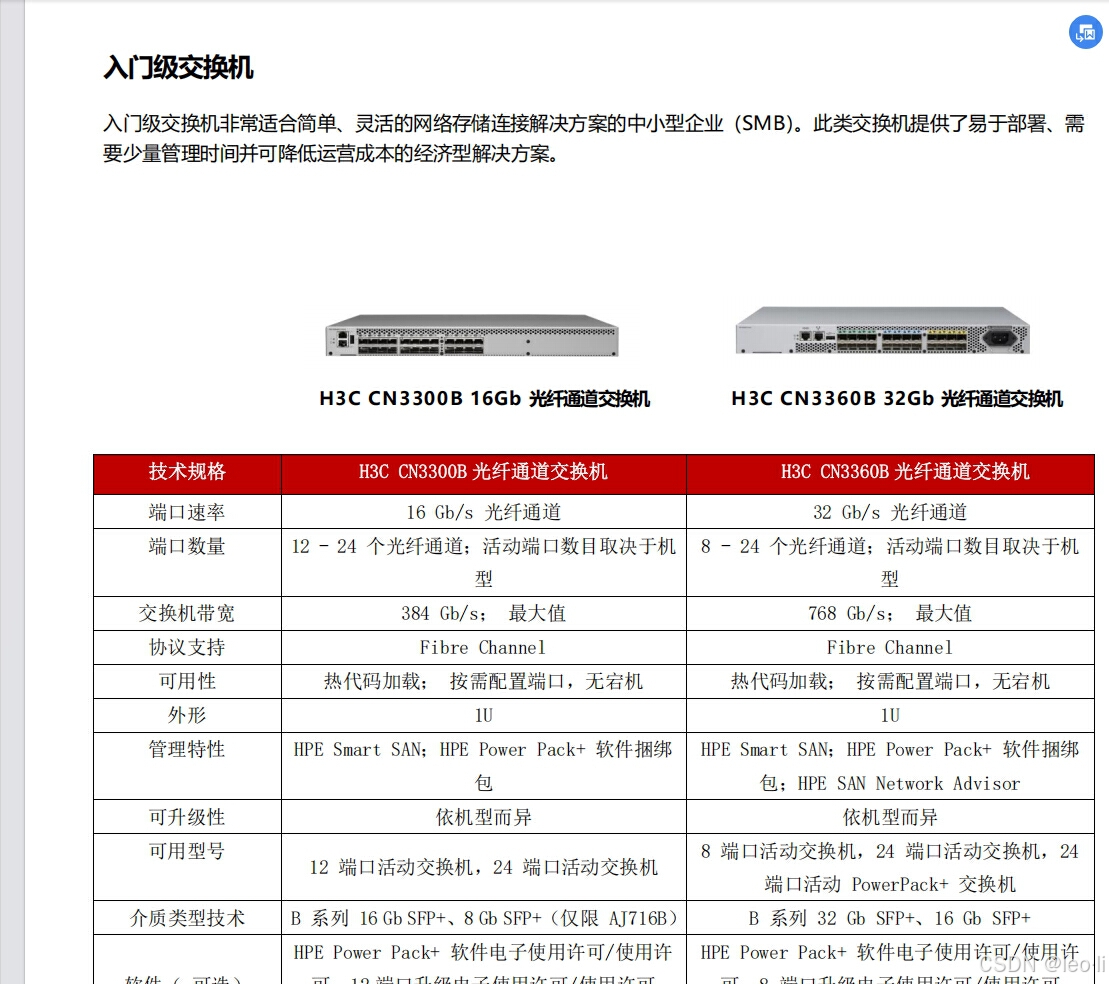
H3C CN3360B光纤存储交换机配置案例
这几天在项目里面遇到了一台光纤存储交换机,需要划Zone来实现服务器外接存储 接下来我就分享我在项目中的配置 我是通过交换机串口进去的,也可以通过网口,串口的配置我就不介绍了 网口配置的地址是:10.77.77.77/24 登入方式&…...
管理失效)
问题:Flask应用中的用户会话(Session)管理失效
我来分享一个常见的PythonWeb开发问题: 问题:Flask应用中的用户会话(Session)管理失效 这是一个在Flask开发中经常遇到的问题。当用户登录后,有时会话会意外失效,导致用户需要重复登录。 解决方案: 1. 首先&#x…...
)
Backend - C# 操作数据库 DB(ADO.NET、LINQ to SQL、EF)
目录 一、ADO.NET(传统) 二、LINQ to SQL(已过时) 三、EF(推荐) 常见的操作数据库的方法:有三种,分别是 ADO.NET、LINQ to SQL、EF 一、ADO.NET(传统) ADO.NE…...
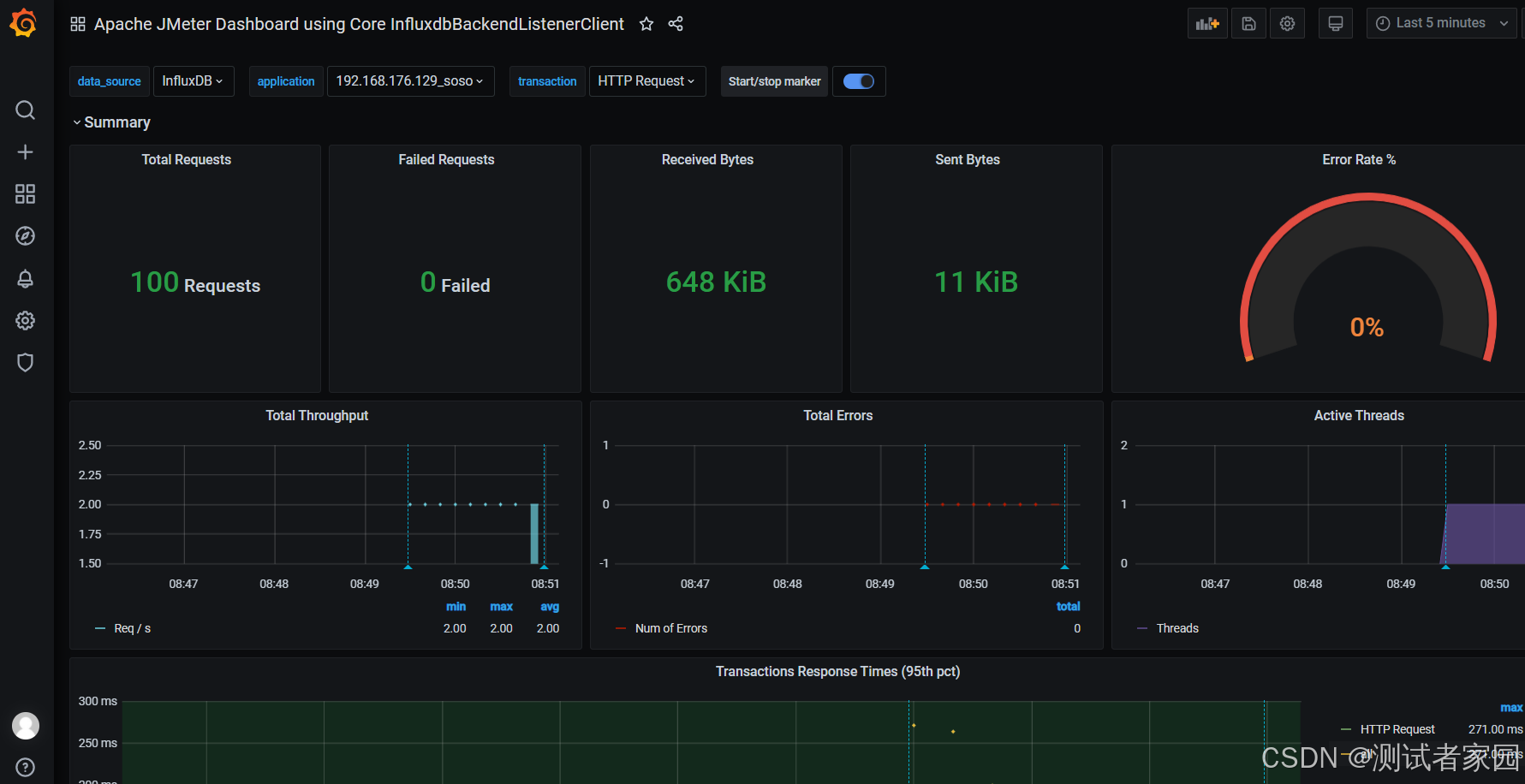
JMeter + Grafana +InfluxDB性能监控 (二)
您可以通过JMeter、Grafana 和 InfluxDB来搭建一个炫酷的基于JMeter测试数据的性能测试监控平台。 下面,笔者详细介绍具体的搭建过程。 安装并配置InfluxDB 您可以从清华大学开源软件镜像站等获得InfluxDB的RPM包,这里笔者下载的是influxdb-1.8.0.x86_…...

3分钟掌握B站视频精髓:BiliTools AI总结功能终极指南
3分钟掌握B站视频精髓:BiliTools AI总结功能终极指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 在…...

解锁Windows无限可能:Windhawk模块化定制完全指南
解锁Windows无限可能:Windhawk模块化定制完全指南 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 你是否曾对Windows系统一成不变的界面感到…...

RV1106驱动ST7735S踩坑实录:从设备树到LVGL显示,我遇到的3个关键问题
RV1106驱动ST7735S踩坑实录:从设备树到LVGL显示的三个关键陷阱 最近在Luckfox Pico Pro Max(RV1106平台)上折腾ST7735S SPI屏幕时,遇到了几个颇具代表性的问题。这些问题不仅让我熬了几个通宵,也让我对嵌入式Linux的显…...

告别Gazebo Classic:在ROS2 Humble上为TurtleBot4配置Navigation2与Gazebo Modern
告别Gazebo Classic:在ROS2 Humble上为TurtleBot4配置Navigation2与Gazebo Modern 当ROS2 Humble遇上TurtleBot4,开发者们正站在机器人仿真技术迭代的十字路口。Gazebo Modern的崛起不仅代表着物理引擎的升级,更预示着整个ROS生态工具链的范式…...

Sentaurus TCAD Sprocess仿真坐标系详解:从晶圆坐标到离子注入,新手避坑指南
Sentaurus TCAD Sprocess仿真坐标系实战解析:从晶圆定位到离子注入精准控制 1. 初识Sentaurus TCAD坐标系:为什么新手总在第一步栽跟头? 刚接触Sentaurus TCAD的工程师常会遇到这样的场景:明明按照手册设置了离子注入角度…...

Python @overload 装饰器深度解析
一、引言:Python中的"伪重载"机制 在传统静态类型语言如Java、C中,函数重载(Function Overloading)是指允许定义多个同名函数,通过参数的数量、类型或顺序区分调用方式,实现不同输入对应不同处理…...

终极QQ聊天增强指南:10个必备功能深度解析
终极QQ聊天增强指南:10个必备功能深度解析 【免费下载链接】QAuxiliary QNotified phoenix - To make OICQ great again 项目地址: https://gitcode.com/gh_mirrors/qa/QAuxiliary QAuxiliary是一款强大的开源Xposed模块,专门为QQ和TIM用户提供全…...

我最骄傲的Python项目:判断力、取舍与排障能力,如何把一次“救火”项目变成团队能力跃升的催化剂
我最骄傲的Python项目:判断力、取舍与排障能力,如何把一次“救火”项目变成团队能力跃升的催化剂 📌 开篇:为什么在Python生态里,技术从来不是终点 客观来看,Python自1991年诞生以来,以简洁优雅…...

AI赋能传统行业:Lingbot深度估计在工业质检中的落地案例
AI赋能传统行业:Lingbot深度估计在工业质检中的落地案例 在传统的工业质检线上,质检员们常常需要面对一个棘手的难题:如何准确判断一个零件表面是否存在肉眼难以察觉的凹陷或凸起?传统的2D视觉检测系统,拍出来的照片再…...
)
提升开发效率的VsCode插件精选(开发者必备)
1. 为什么你需要这些VsCode插件? 作为一个写了十几年代码的老兵,我深刻体会到工具对开发效率的影响。记得刚入行时用记事本写代码的日子,现在回想起来简直像原始人钻木取火。VsCode之所以能成为现代开发者的标配,除了其轻量快速的…...