nlp培训重点-2
1. 贝叶斯公式
import math
import jieba
import re
import os
import json
from collections import defaultdictjieba.initialize()"""
贝叶斯分类实践P(A|B) = (P(A) * P(B|A)) / P(B)
事件A:文本属于类别x1。文本属于类别x的概率,记做P(x1)
事件B:文本为s (s=w1w2w3..wn)
P(x1|s) = 文本为s,属于x1类的概率. #求解目标#
P(x1|s) = P(x1|w1, w2, w3...wn) = P(w1, w2..wn|x1) * P(x1) / P(w1, w2, w3...wn)P(x1) 任意样本属于x1的概率。x1样本数/总样本数
P(w1, w2..wn|x1) = P(w1|x1) * P(w2|x1)...P(wn|x1) 词的独立性假设
P(w1|x1) x1类样本中,w1出现的频率公共分母的计算,使用全概率公式:
P(w1, w2, w3...wn) = P(w1,w2..Wn|x1)*P(x1) + P(w1,w2..Wn|x2)*P(x2) ... P(w1,w2..Wn|xn)*P(xn)
"""class BayesApproach:def __init__(self, data_path):self.p_class = defaultdict(int)self.word_class_prob = defaultdict(dict)self.load(data_path)def load(self, path):self.class_name_to_word_freq = defaultdict(dict)self.all_words = set() #汇总一个词表with open(path, encoding="utf8") as f:for line in f:line = json.loads(line)class_name = line["tag"]title = line["title"]words = jieba.lcut(title)self.all_words = self.all_words.union(set(words))self.p_class[class_name] += 1 #记录每个类别样本数量word_freq = self.class_name_to_word_freq[class_name]#记录每个类别下的词频for word in words:if word not in word_freq:word_freq[word] = 1else:word_freq[word] += 1self.freq_to_prob()return#将记录的词频和样本频率都转化为概率def freq_to_prob(self):#样本概率计算total_sample_count = sum(self.p_class.values())self.p_class = dict([c, self.p_class[c] / total_sample_count] for c in self.p_class)#词概率计算self.word_class_prob = defaultdict(dict)for class_name, word_freq in self.class_name_to_word_freq.items():total_word_count = sum(count for count in word_freq.values()) #每个类别总词数for word in word_freq:#加1平滑,避免出现概率为0,计算P(wn|x1)prob = (word_freq[word] + 1) / (total_word_count + len(self.all_words))self.word_class_prob[class_name][word] = probself.word_class_prob[class_name]["<unk>"] = 1/(total_word_count + len(self.all_words))return#P(w1|x1) * P(w2|x1)...P(wn|x1)def get_words_class_prob(self, words, class_name):result = 1for word in words:unk_prob = self.word_class_prob[class_name]["<unk>"]result *= self.word_class_prob[class_name].get(word, unk_prob)return result#计算P(w1, w2..wn|x1) * P(x1)def get_class_prob(self, words, class_name):#P(x1)p_x = self.p_class[class_name]# P(w1, w2..wn|x1) = P(w1|x1) * P(w2|x1)...P(wn|x1)p_w_x = self.get_words_class_prob(words, class_name)return p_x * p_w_x#做文本分类def classify(self, sentence):words = jieba.lcut(sentence) #切词results = []for class_name in self.p_class:prob = self.get_class_prob(words, class_name) #计算class_name类概率results.append([class_name, prob])results = sorted(results, key=lambda x:x[1], reverse=True) #排序#计算公共分母:P(w1, w2, w3...wn) = P(w1,w2..Wn|x1)*P(x1) + P(w1,w2..Wn|x2)*P(x2) ... P(w1,w2..Wn|xn)*P(xn)#不做这一步也可以,对顺序没影响,只不过得到的不是0-1之间的概率值pw = sum([x[1] for x in results]) #P(w1, w2, w3...wn)results = [[c, prob/pw] for c, prob in results]#打印结果for class_name, prob in results:print("属于类别[%s]的概率为%f" % (class_name, prob))return resultsif __name__ == "__main__":path = "../data/train_tag_news.json"ba = BayesApproach(path)query = "中国三款导弹可发射多弹头 美无法防御很急躁"ba.classify(query)2. 支持向量机(SVM)
#!/usr/bin/env python3
#coding: utf-8#使用基于词向量的分类器
#对比几种模型的效果import json
import jieba
import numpy as np
from gensim.models import Word2Vec
from sklearn.metrics import classification_report
from sklearn.svm import SVC
from collections import defaultdictLABELS = {'健康': 0, '军事': 1, '房产': 2, '社会': 3, '国际': 4, '旅游': 5, '彩票': 6, '时尚': 7, '文化': 8, '汽车': 9, '体育': 10, '家居': 11, '教育': 12, '娱乐': 13, '科技': 14, '股票': 15, '游戏': 16, '财经': 17}#输入模型文件路径
#加载训练好的模型
def load_word2vec_model(path):model = Word2Vec.load(path)return model#加载数据集
def load_sentence(path, model):sentences = []labels = []with open(path, encoding="utf8") as f:for line in f:line = json.loads(line)title, content = line["title"], line["content"]sentences.append(" ".join(jieba.lcut(title)))labels.append(line["tag"])train_x = sentences_to_vectors(sentences, model)train_y = label_to_label_index(labels)return train_x, train_y#tag标签转化为类别标号
def label_to_label_index(labels):return [LABELS[y] for y in labels]#文本向量化,使用了基于这些文本训练的词向量
def sentences_to_vectors(sentences, model):vectors = []for sentence in sentences:words = sentence.split()vector = np.zeros(model.vector_size)for word in words:try:vector += model.wv[word]# vector = np.max([vector, model.wv[word]], axis=0)except KeyError:vector += np.zeros(model.vector_size)vectors.append(vector / len(words))return np.array(vectors)def main():model = load_word2vec_model("model.w2v")train_x, train_y = load_sentence("../data/train_tag_news.json", model)test_x, test_y = load_sentence("../data/valid_tag_news.json", model)classifier = SVC()classifier.fit(train_x, train_y)y_pred = classifier.predict(test_x)print(classification_report(test_y, y_pred))if __name__ == "__main__":main()核函数:
假设存在一个特征映射函数 ϕ,使得 K(x,y)=ϕ(x)⋅ϕ(y)。核技巧通过直接使用 K(x,y) 计算内积,而无需明确地知道或计算 ϕ(x)。核函数的作用是可以低维映射到高维,从而进行分类。
3. CNN神经网络
import torch
import torch.nn as nn
import numpy as np#使用pytorch的1维卷积层input_dim = 6
hidden_size = 8
kernel_size = 2
torch_cnn1d = nn.Conv1d(input_dim, hidden_size, kernel_size)
for key, weight in torch_cnn1d.state_dict().items():print(key, weight.shape)x = torch.rand((6, 8)) #embedding_size * max_lengthdef numpy_cnn1d(x, state_dict):weight = state_dict["weight"].numpy()bias = state_dict["bias"].numpy()sequence_output = []for i in range(0, x.shape[1] - kernel_size + 1):window = x[:, i:i+kernel_size]kernel_outputs = []for kernel in weight:kernel_outputs.append(np.sum(kernel * window))sequence_output.append(np.array(kernel_outputs) + bias)return np.array(sequence_output).Tprint(x.shape)
print(torch_cnn1d(x.unsqueeze(0)))
print(torch_cnn1d(x.unsqueeze(0)).shape)
print(numpy_cnn1d(x.numpy(), torch_cnn1d.state_dict()))4. LSTM

相关文章:
nlp培训重点-2
1. 贝叶斯公式 import math import jieba import re import os import json from collections import defaultdictjieba.initialize()""" 贝叶斯分类实践P(A|B) (P(A) * P(B|A)) / P(B) 事件A:文本属于类别x1。文本属于类别x的概率,记做…...

设计模式(1)——面向对象和面向过程,封装、继承和多态
文章目录 一、day11. 什么是面向对象2. 面向对象的三要素:继承、封装和多态2.1 封装**2.1.1 封装的概念****2.1.2 如何实现封装****2.1.3 封装的底层实现**2.1.4 为什么使用封装?(好处)**2.1.5 封装只有类能做吗?结构体…...

培训机构Day24
今天讲了一些javaee比较过时的技术,虽然已经过时,该学的还得学学。 知识点: http://localhost:8080/demo01/demo1?a1&b2&c3 pattern: /demo1 上下文路径:ContextPath,/demo01,不包含请求参数。 …...

1/7 C++
练习:要求在堆区连续申请5个int的大小空间用于存储5名学生的成绩,分别完成空间的申请、成绩的录入、升序排序、成绩输出函数,并在主程序中完成测试 要求使用new #include <iostream>using namespace std; double *addr_new() {double …...

C语言初阶习题【23】输出数组的前5项之和
1. 题目描述 求Snaaaaaaaaaaaaaaa的前5项之和,其中a是一个数字, 例如:222222222222222 2.思路 分析下,222222222222222,怎么把它每一项算出来 2 210222 22102222 2221022222 我们的多项式就是a a*102,…...
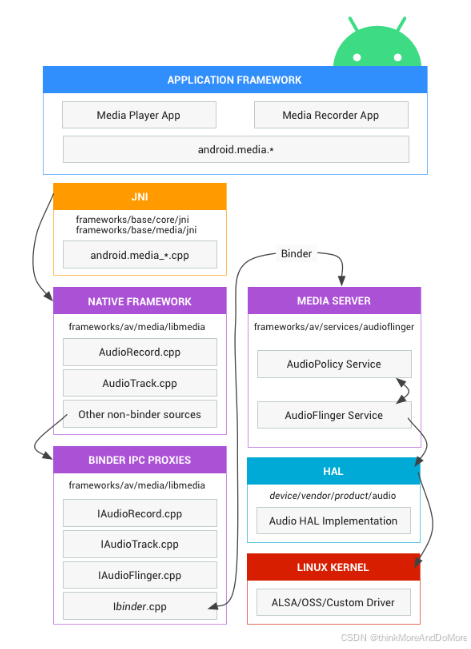
Android audio(1)-音频模块概述
Audio模块是Android系统的重要组成部分,在 Android 中负责音频路由,数据处理,音频控制,音频设备管理/切换。 下面的内容大多翻译自android官网,读者可跳过阅读后面的博客。 一、系统架构 下图说明了音频模块的组成,并指出各组成部分所涉及的相关源代码。所谓架构就是说模…...

园林与消防工程:选择正确工程项目管理软件的重要性
在园林与消防工程领域,选择正确的工程项目管理软件对于提高项目效率、优化资源配置以及确保项目质量至关重要。以下是对园林与消防工程中选择正确工程项目管理软件重要性的详细分析: 1.提升项目管理效率 实时监控与跟踪:工程项目管理软件能够…...

分布式环境下定时任务扫描时间段模板创建可预订时间段
🎯 本文详细介绍了场馆预定系统中时间段生成的实现方案。通过设计场馆表、时间段模板表和时间段表,系统能够根据场馆的提前预定天数生成未来可预定的时间段。为了确保任务执行的唯一性和高效性,系统采用分布式锁机制和定时任务,避…...

SQL刷题笔记——高级条件语句
目录 1题目:SQL149 根据指定记录是否存在输出不同情况 2 作答解析 3 知识点 3.1 count函数 3.2 内连接与左连接 1题目:SQL149 根据指定记录是否存在输出不同情况 2 作答解析 #正确答案 select uid, incomplete_cnt, incomplete_rate from (select …...

与 Oracle Dataguard 相关的进程及作用分析
与 Oracle Dataguard 相关的进程及作用分析 目录 与 Oracle Dataguard 相关的进程及作用分析与 Oracle Dataguard 相关的进程及作用分析一、主库的进程1、LGWR 进程2、ARCH进程3、LNS 进程 二、备库的进程1、RFS 进程2、ARCH3、MRP(Managed Recovery Process&#x…...

游戏语音趋势解析,社交互动有助于营造沉浸式体验
语音交互的新架构出现 2024 年标志着对话语音 AI 取得了突破,出现了结合 STT → LLM → TTS 模型来聆听、推理和回应对话的协同语音系统。 OpenAI 的 ChatGPT 语音模式将语音转语音技术变成了现实,引入了基于音频和文本信息进行端到端预训练的模型&…...

美食烹饪互动平台
本文结尾处获取源码。 一、相关技术 后端:Java、JavaWeb / Springboot。前端:Vue、HTML / CSS / Javascript 等。数据库:MySQL 二、相关软件(列出的软件其一均可运行) IDEAEclipseVisual Studio Code(VScode)Navica…...

【51单片机零基础-chapter5:模块化编程】
模块化编程 将以往main中泛型的代码,放在与main平级的c文件中,在h中引用. 简化main函数 将原来main中的delay抽出 然后将delay放入单独c文件,并单独开一个delay头文件,里面放置函数的声明,相当于收纳delay的c文件里面写的函数的接口. 注意,单个c文件所有用到的变量需要在该文…...

Redis中的主从/Redis八股
四、Redis主从 1.搭建主从架构 不像是负载均衡,这里是主从,是因为redis大多数是读少的是写 步骤 搭建实例(建设有三个实例,同一个ip不同端口号) 1)创建目录 我们创建三个文件夹,名字分别叫700…...

ROS笔记
自定义消息的发布 1.创建空间包 1.创建ROS工作空间: mkdir -p ~/catkin_ws/src cd ~/catkin_ws/ catkin_make source devel/setup.bash 创建工作空间,编译设置环境 2.创建工作空间中的ROS包: cd ~/catkin_ws/src catkin_create_pkg your_pa…...

在 Linux 上调试 C++ 程序
在 Linux 上调试 C 程序是一个常见的开发任务,Linux 提供了多种强大的工具来帮助你进行调试。以下是常用的调试方法和工具. 1. 使用 GDB (GNU Debugger) GDB 是最常用且功能强大的命令行调试器,适用于 C、C 和其他语言。它允许你逐步执行代码、设置断点…...
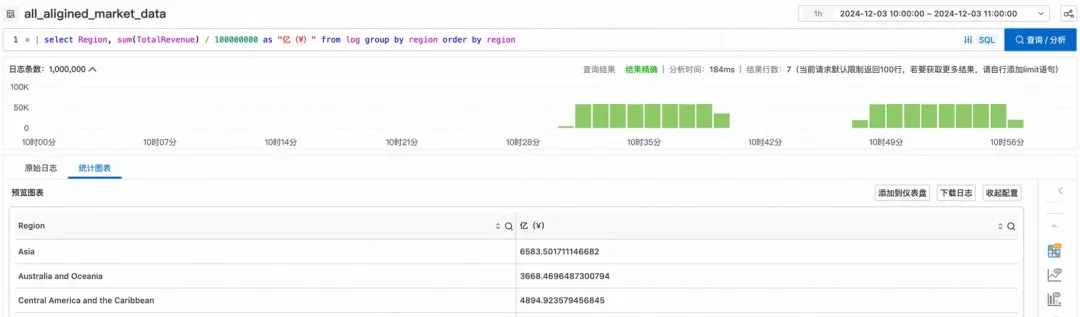
让跨 project 联查更轻松,SLS StoreView 查询和分析实践
作者:章建(处知) 概述 日志服务 SLS 是云原生观测和分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务。SLS 提供了多地域支持 [ 1] ,方便用户可以根据数据源就近接入 SLS 服务࿰…...

20240107-类型转换
1. 自动类型转换 不损失数据精度的前提下,可自动完成变量的类型转换;不损失数据精度指不将超出变量可表示范围的值赋给该变量。 2.强制类型转换 若出现精度损失,java不会自动完成类型转换,需强制进行,见下代码的第8…...

关于Linux PAM模块下的pam_listfile
讲《Linux下禁止root远程登录访问》故事的时候,说好会另开一篇讲讲pam_listfile。我们先看看pam_listfile的man文档怎么介绍的。 下面这些就好比人物的简介,甚是恼人;让人看得不明就里,反正“他大舅他二舅都是他舅”。可以直接跳…...

OKHttp调用第三方接口,响应转string报错okhttp3.internal.http.RealResponseBody@4a3d0218
原因分析 通过OkHttp请求网络,结果请求下来的数据一直无法解析并且报错,因解析时String res response.body().toString() 将toString改为string即可!...

ComfyUI视觉AI引擎:无需编程构建稳定扩散工作流的最佳选择
ComfyUI视觉AI引擎:无需编程构建稳定扩散工作流的最佳选择 【免费下载链接】ComfyUI The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI Comfy…...
)
别再手动敲命令了!用Docker Compose一键部署MinIO(附Windows/Linux双平台配置)
告别繁琐配置:用Docker Compose三分钟搭建高可用MinIO存储系统 在云原生时代,对象存储已成为现代应用架构的标配组件。MinIO作为高性能、兼容S3协议的开源解决方案,凭借其轻量级特性和企业级功能,从测试环境到生产系统都能看到它…...

Xinference-v1.17.1在计算机网络实验教学中的应用
Xinference-v1.17.1在计算机网络实验教学中的应用 1. 引言 计算机网络实验教学一直面临着设备成本高、实验环境复杂、协议分析困难等挑战。传统的实验方式需要学生手动配置网络设备、抓包分析协议,整个过程耗时耗力且容易出错。Xinference-v1.17.1的出现为计算机网…...

CKKS 同态加密数学基础推导律
背景 StreamJsonRpc 是微软官方维护的用于 .NET 和 TypeScript 的 JSON-RPC 通信库,以其强大的类型安全、自动代理生成和成熟的异常处理机制著称。在 HagiCode 项目中,为了通过 ACP (Agent Communication Protocol) 与外部 AI 工具(如 iflow …...

如何彻底摆脱Windows系统中顽固的Microsoft Edge浏览器?
如何彻底摆脱Windows系统中顽固的Microsoft Edge浏览器? 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover 你…...
详解)
千问3.5-2B快速上手:网页端四步操作(上传→提问→设置→获取)详解
千问3.5-2B快速上手:网页端四步操作(上传→提问→设置→获取)详解 1. 开篇:认识千问3.5-2B 千问3.5-2B是Qwen系列中的一款轻量级视觉语言模型,它能像人类一样"看"图片并回答相关问题。想象一下,…...

[Linux][虚拟串口]x一个特殊的字节踊
简介 langchain专门用于构建LLM大语言模型,其中提供了大量的prompt模板,和组件,通过chain(链)的方式将流程连接起来,操作简单,开发便捷。 环境配置 安装langchain框架 pip install langchain langchain-community 其中…...

Qt QTabWidget标签页文字方向修复:手把手教你重写QProxyStyle实现左侧标签水平显示
Qt QTabWidget标签页文字方向定制:从原理到实践的深度解决方案 在桌面应用开发中,Qt框架因其跨平台特性和丰富的UI组件库而广受欢迎。然而,当开发者尝试将QTabWidget的标签页位置设置为左侧时,一个令人困扰的问题出现了——标签文…...

3步搞定黑苹果配置:OpCore-Simplify让你告别复杂手动调试的终极解决方案
3步搞定黑苹果配置:OpCore-Simplify让你告别复杂手动调试的终极解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑苹果配置…...
效果惊艳:雨天户外采访录音中分离人声与雨滴噪声)
FRCRN(16k单麦)效果惊艳:雨天户外采访录音中分离人声与雨滴噪声
FRCRN(16k单麦)效果惊艳:雨天户外采访录音中分离人声与雨滴噪声 1. 项目概述 FRCRN(Frequency-Recurrent Convolutional Recurrent Network)是阿里巴巴达摩院在ModelScope社区开源的单通道语音降噪模型,专…...