OpenAI 故障复盘 - 阿里云容器服务与可观测产品如何保障大规模 K8s 集群稳定性

本文作者:
容器服务团队:刘佳旭、冯诗淳
可观测团队:竺夏栋、麻嘉豪、隋吉智
一、前言
Kubernetes(K8s)架构已经是当今 IT 架构的主流与事实标准(CNCF Survey[1])。随着承接的业务规模越来越大,用户也在使用越来越大的 K8s 集群。Kubernetes 官方建议的最大集群规模是 5000 节点。甚至,如 OpenAI 通过技术优化,曾将 K8s 集群扩展至 7500 节点(Scaling Kubernetes to 7,500 nodes[2])。这种千级别节点的大规模 K8s 集群,会容易引起分布式系统内部瓶颈,但也增加了系统的脆弱性。
1.1 OpenAI 故障复盘分析
近日 OpenAI 旗下 AI 聊天机器人平台 ChatGPT、视频生成工具 Sora 及其面向开发人员的 API 自太平洋时间 12 月 11 日下午 3 点左右起发生严重中断。故障的根因是在上线获取集群控制面监控数据的新的新可观测功能时,可观测的组件会在每个集群节点上对 K8s Resource API 发起访问,突发造成巨大的 Kubernetes API 负载,导致 K8s 控制平面瘫痪,进而使 DNS 服务发现功能中断,最终影响到了业务。(OpenAI 故障报告[3])
1.2 阿里云如何保障大规模 K8s 集群稳定性,以应对如此故障
这次故障在阿里云产品体系中直接相关的是阿里云容器服务(Kubernetes),以及阿里云可观测产品(Prometheus、Telemetry)产品。
故,我们对本次 OpenAI 故障高度重视,希望借此机会介绍我们在大规模 K8s 场景下我们的建设与沉淀。以及分享对类似故障问题的应对方案:包括在 K8s 和 Prometheus 的高可用架构设计方面、事前事后的稳定性保障体系方面。
阿里云容器服务团队(负责 Kubernetes 云产品)与阿里云可观测团队(负责 Prometheus 云产品)旨在为用户提供稳定可靠的 K8s 集群环境,以及使用可观测体系帮助用户构建全面的稳定性保障体系。我们的客户也有非常多上千节点的大规模 K8s 集群环境,在大规模 K8s 集群的稳定性保障体系方面有一定经验沉淀。
OpenAI 的大规模集群故障也是我们很好的学习案例,这里本文想借助这次案例为契机:
1. 介绍阿里云容器服务(K8s)、可观测团队(Prometheus)的大规模集群稳定性建设。
2. 以及用户在大规模 K8s 集群场景下的最佳实践,用户也需要采用正确的使用方式才能一起保障大规模 K8s 集群的稳定性。
二、当 K8s 集群规模过大会遇到哪些风险与挑战

K8s 集群控制面/数据面数据流图
2.1 K8s 集群的本质是分布式系统,剖析其中瓶颈才能对症下药
首先我们要简单介绍下 K8s 集群控制面、数据面的大致架构:
控制面负责集群的 API 层、调度、资源管理、云资源管理等控制面功能,K8s 组件:
apiserver/etcd/scheduler/kube-controller-manger/cloud-controller-manager
数据面负责集群的节点管理、Pod 生命周期管理、Service 实现等数据面功能,承载业务 Pod 的主体。包含:K8s 组件,kubelet/kube-proxy;系统组件,日志、监控、安全等组件;其他组件,用户业务组件。
控制面、数据面和云资源是有机结合的整体!集群的全链路中,任何一个组件、子链路成为瓶颈,都可能影响到集群的整体稳定性。
我们需要从 K8s 系统中发现瓶颈、治理以及优化瓶颈,最终实现 K8s 系统在给定云资源情况下的稳定、高效的利用。
三、稳定性增强-阿里云在大规模 K8s 集群场景的保障增强
3.1 大规模容器服务 ACK 集群的稳定性保障机制增强
大规模 ACK 集群通过高可用配置、托管组件稳定性增强和系统组件优化等综合技术,对集群的的稳定性进行全面优化和提升。
通过控制面可用区级别和节点级别的高可用配置,全部控制面组件实现高可用打散。以 APIServer 为例,多副本跨 AZ、跨节点高可用部署方式,任何一个 AZ 失效不影响服务可用性。在 3AZ 地域,ACK 托管集群控制面的 SLA 是 99.95%。对于不具备 3AZ 的地域,ACK 托管集群控制面 SLA 是 99.5%(不具备单可用区的故障容忍)。
托管核心组件进行弹性、资源隔离、限流、请求处理能力等方面的稳定性优化,例如:APIServer 支持自动弹性 VPA+HPA、etcd 支持基于推荐资源画像的 VPA、APIServer 的动态限流等等。
ACK 系统组件严格按照最佳规范进行优化和改造,降低对控制面的压力,包括:对控制面的 LIST 请求、消除对控制面资源消耗大的请求;对非 CRD 资源的 API 序列化协议不使用 JSON,统一使用 Protobuf 等等。
3.2 阿里云 Prometheus 对大规模集群场景的增强
本次导致 OpenAI 故障的根因是上线新的可观测能力时发生的,这里在阿里云体系中,直接对应着可观测团队容器监控产品-阿里云 Prometheus。
阿里云 Prometheus 与容器服务一直以来深度合作,对上千节点的大规模 K8s 场景也有很多深入的沉淀和建设。
不管是本次 OpenAI 故障直接相关的容器服务 K8s 控制面观测能力[4],还是数据可靠性上,还是可观测组件本身对集群造成的负载上,都有重点优化建设。以下是一些具体的工作内容:
更智能的服务发现与多副本采集架构 - 消除热点
阿里云 Prometheus 结合支撑众多阿里云产品、阿里集团内部大规模生产集群中可观测能力建设的多年经验,首先对采集探针架构完成了升级改造,实现控制本次 OpenAI 所遇到故障爆炸半径与影响面的目标。
我们采用两级角色体系解耦了 Prometheus 采集过程中的两类关注点:
1. Master 角色负责实时地服务发现、任务调度与配置分发
• 所有标准类型的资源对象数据均通过二进制 Protobuf 编码获取,以便在大规模环境中获得更好的性能
• 默认仅一个 Pod 实例对 K8s API Server 建立 List && Watch 通信,降低 API Server 访问压力
• 在必要情况下通过主备双副本实现高可用工作
2. Worker 角色负责高效地指标采集、Metric Relabel 处理与数据上报
• 可依据采集目标规模以及各个目标上暴露的指标量规模进行 Scale Out
• 由于 Worker 不直接对 K8s API Server 通信,扩大角色实例数量对 API Server 无影响

阿里云 Prometheus 部署、数据流架构图
这正是阿里云 Prometheus 采集探针相对于目前业界众多社区开源或商业版本探针的重要区别,该架构实现保障了采集能力的扩展绝不会对 API Server 等关键组件造成冲击——并不是直接引入 StatefulSet、DaemonSet 工作负载模式实现多副本的采集。
特别地,通过“配置管理中心”的服务端能力建设解除了配置分发行为对 K8s API Server 的依赖,进一步降低访问压力。此外,Master 与 Worker 的自监控指标同步上报云端存储,供云产品工程师实时掌握各采集探针的运行状况、性能水位与异常信息,确保及时对故障集群进行告警与应急。
适应大规模集群的 Exporters 优化改造 - 减少负载
完成采集探针自身改造,支撑万级目标稳定高效采集的同时,我们也对 Kubernetes+Prometheus 社区生态中常见 Exporter 在大规模集群中的运行稳定性进行了重写与优化。
以 kube-state-metrics 为例,作为 K8s 集群资源可观测事实意义上的标准,它在面临海量资源对象(不仅仅 Pod,还有 ConfigMap、Ingress、Endpoint 等)情况下需要更多的内存运行资源来避免 OOMKilled,当节点规格限制不足以执行 VPA 操作时,官方推荐方案仍然是通过 StatefulSet 工作负载拉起多个 kube-state-metrics 副本,并且每个实例都对 K8s API Server 执行完整的 List&Watch 访问后,再通过 Shard Hash 的方式来实现 HPA 的目标——这同样会酿生本次 OpenAI 的故障。
为此,我们也积极拥抱大数据社区的前沿技术,如:通用内存列式数据格式,对 kube-state-metrics 进行重构改写,获得更高的数据压缩比,通过单副本运行即可实现大规模集群中资源状态指标的稳定产出,避免造成对 K8s API Server 的访问压力。
实现业务故障隔离的托管采集探针 - 旁路采集方案
传统 Prometheus 采集探针直接部署在用户容器集群内,对集群内服务发现的采集目标定期抓取指标数据并上报阿里云 Prometheus 数据网关。
虽然云产品工程师具备对采集探针专业化的运维监控技能,但由于没有直接操作集群环境的权限,以往线上技术支持流程,都依赖将命令发给用户执行操作,不仅效率低,并且可能遇到交流中理解不一致导致的排查方向错误。
另外当灾难发生时,由于采集探针与业务同集群无法正常工作,但灾难阶段又正是用户最需要一双“眼睛”来观测系统与业务的受损程度的时候。
因而,我们着手转向 Serverless 这种服务模型。Prometheus 采集探针本质上是个 Probe,不一定要部署在用户集群,只要满足网络打通的条件,所有探针运行在云产品托管的集群池中,即可将采集能力 Serverless 化,不仅可降低用户集群资源负担,也有助于提升组件运维的灵活度。
在 OpenAI 本次故障中,由可观测组件引起 K8s API Server/ CoreDNS 服务不可用,同时导致集群内所有的观测活动陷入瘫痪,在最需要可观测的时刻,却进入了盲区。而使用托管探针模式,则将观测组件本身与集群的故障隔离开来。尽管由于 API Server 不可用,无法及时发现新的监控目标,但已调度下发的采集任务仍可继续执行,数据上报至云端存储也不再依赖于集群内的 CoreDNS。
综上,使用托管形态的阿里云 Prometheus 容器监控服务可以屏蔽用户环境复杂性,组件运行稳定性得到了更好的保障,为更快的灾难恢复提供架构支撑,在这种灾难性故障下,托管探针模式的阿里云 Prometheus 容器监控服务依然能够确保一定程度的数据完整性。
可靠的数据链路 - "out-of-band" 带外数据链路建设
可观测性的另一个挑战是,监控采集组件如果部署在用户集群侧,当集群环境出现问题时,监控系统也会一并宕掉,不能起到观测异常现场的作用。
阿里云容器服务通过建设“带外数据链路(out-of-band)”来解决此问题。
ControlPlane 组件自身监控数据的带外数据链路
反映集群稳定性的关键指标、ControlPlane 组件的监控指标[5]数据,通过托管侧的组件透出数据,不受集群本身环境影响,我们内部称为“带外数据链路(out-of-band)”。当集群本身异常时,只会影响和集群内部环境相关的“带内链路(in-band)”,而不会影响这些“带外数据链路(out-of-band)”。保证了集群稳定性的关键数据的可靠性。
阿里云容器服务托管集群,通过部署单独的组件监控 ControlPlane 组件自身的监控数据。当关键控制面组件异常时,保证监控数据的可靠性。
容器层以下的节点的虚拟机、硬件、操作系统层问题的带外数据链路
同理,集群关键组件的事件、能感知集群中的节点(ECS)底层异常的主动运维事件,也通过“带外数据链路”(out-of-band)直接写入到用户的 SLS 事件中心中。
以此方案形成与用户集群环境完全解耦的数据源、数据采集链路,保证监控数据的可靠性。
参考文档:容器服务托管节点池[6]对 ECS 系统事件[7]的透出。
四、最佳实践 - 用户如何正确地使用大规模 K8s 集群
K8s 本质是一个非常易用的分布式系统,分布式系统由于 PAC 原则,永远都存在承载能力的上限。
这里就还是需要 K8s 集群的用户,不管作为 K8s 组件开发者,还是 K8s 运维人员,采用正确的使用方式来使用 K8s 集群,才能在千级别节点的大规模 K8s 集群中保证集群的稳定性。
在此经过阿里云容器服务团队的经验沉淀,我们提供涵盖事前预防观测、事后快速定位和恢复的成熟产品能力,帮助用户构建集群稳定性运维体系。
4.1 集群规模控制(容量规划)&正确的发布流程(安全发布流程)
首先,站在运维的角度来看,我们需要时刻考虑减小爆炸半径。
首先当用户的业务规模还未发展成需要一个大规模 K8s 集群来承载的程度时,我们建议用户通过合理的容量规划来控制集群规模的大小,如可以通过微服务架构等方式,拆分业务的部署结构在不同的集群上,以此来减小 K8s 规模。
其次,站在发布的安全生产流程上,我们需要考虑可灰度、可回滚、可监控的安全发布最佳实践。且每批灰度间隔需要充分观测逻辑是否符合预期,且在观测到异常问题后应该马上回滚。
4.2 事前 - 观测能力与关键报警配置
成熟的集群控制面观测能力
首先用户可以通过我们阿里云容器服务提供的集群 ControlPlane 观测能力,清晰感知到集群控制面组件的当前状态。我们提供 ACK 集群控制面监控大盘[8],以及控制面组件日志监控[9]功能,帮助用户清晰透明地观测集群稳定性问题。

查看 ACK 集群控制面监控大盘[8]
在我们遇到的典型大规模集群故障场景,如下图:
场景 1:用户侧组件异常请求泛滥,导致 APIServer 负载过高;
场景 2:大请求导致的 K8s 集群 SLB 带宽被打满,导致 APIServerRT 飙升、或者只读请求飙升。
我们可以通过集群控制面观测能力剖析问题,样例如下:

上面可观测能力可以帮助决策出精准的诊断路径:
【问题快速发现】依据 API-Server 指标水位进行问题定位。
【根因快速定位】依据 API-Server 访问日志定位问题瓶颈应用,并精准降级,详见本文 4.3.4 节,如何快速定位对控制面组件造成主要压力的“元凶”请求组件,并快速降级。
【止血/闭环问题】停止/优化应用的 List-Watch 资源行为、性能,最佳实践参考本文 4.2.3 节,阿里云的组件稳定性优化。
经历经验沉淀的关键报警规则
虽然有强大的可观测能力,但用户不可能每时每刻盯着监控大盘,阿里云容器服务报警中心功能[10]为客户提供经过经验沉淀的 K8s 集群运维关键报警规则模版。
其中包括上文所提到的集群核心组件异常报警规则,可以覆盖如 ControlPlane 组件异常、APIServer 的 SLB 带宽打满等场景的预警。
非常推荐用户确保这些报警规则开启并订阅通知到负责集群运维的 SRE 人员。您只需要购买集群时默认开启报警规则;或在容器服务控制台,运维管理->报警配置中开启规则并添加通知对象即可订阅。

开发 K8s 组件的最佳实践
规范组件 LIST 请求
必须使用全量 LIST 时添加 resourceVersion=0,从 APIServer cache 读取数据,避免一次请求访问全量击穿到 etcd;从 etcd 读取大量数据,需要基于 limit 使用分页访问。加快访问速度,降低对控制面压力。
序列化编码方式统一
对非 CRD 资源的 API 序列化协议不使用 JSON,统一使用 Protobuf,相比于 JSON 更节省传输流量。
优选使用 Informer 机制
大规模场景下,频繁 LIST 大量资源会对管控面 APIServer 和 etcd 产生显著压力。频繁 LIST 的组件需要切换使用 Informer 机制。基于 Informer 的 LIST+WATCH 机制优雅的访问控制面,提升访问速度,降低对控制面压力。
客户端访问资源频度
客户端控制访问大规模全量资源的频度,降低对管控的资源和带宽压力。
对 APIServer 访问的中继方案
大规模场景下,对于 Daemonset、ECI pod 等对 APIServer 进行访问的场景,可以设计可横向扩容的中继组件,由中继组件统一访问 APIServer,其他组件从中继组件获取数据。例如 ACK 的系统组件 poseidon 在 ECI 场景下作为 networkpolicy 中继使用。降低管控的资源和带宽压力,提升稳定性。
当前阿里云 Prometheus 也是采用此类中继逻辑来减少的集群负载,从而避免随 K8s 和部署应用的规模笛卡尔积式地增大对集群的负载,当然此类中继逻辑都需要针对组件定制开发。
4.3 事后 - 快速恢复与止血
K8s 故障的应急处理与快速恢复,不仅需要建立常态化的故障演练和应急支撑机制,还应涵盖从故障发生到恢复的全链路响应流程,包括故障的实时监测、精准定位,以及问题的及时解决。
定期演练和应急预案
需要通过定期开展演练与评估,持续优化和演进应急预案,可以提升整体故障应对能力和恢复速度,减少故障对业务的影响时长和严重程度。这种系统性的能力建设,将为 K8s 环境的稳定性和可靠性提供强有力的保障。
从具体应急措施的角度,控制面由于请求压力过大导致出现无响应、OOM 甚至雪崩,本质上需要限制请求,尤其是 LIST 大量资源的请求,这些请求处理的过程中对 etcd 和 apiserver 都会带来显著的开销;apiserver 作为 etcd 的一种缓存,集群中全部资源会缓存在 apiserver 内存中,与此同时请求到达 apiserver 后,apiserver 处理请求过程中产生的编解码也会占用缓存,如果请求频繁而且请求资源数量巨大,都会导致控制面 apiserver 内存骤增。
同时,在有条件的情况下,尽量扩容 Master 节点/组件内存和 CPU 资源。在实际应急中,这个措施出于硬件资源的限制不总是能满足,此时就需要更加依靠限流策略应急。
应急的限流策略
应急的限流策略包括(1)降低 apiserver inflight request 参数,需要重启 APIServer 或者(2)根据监控发现访问压力过大的请求,下发在故障演练充分验证过的 APF 限流规则,包括针对指定 UA(例如 OpenAI 案例中的 Telemetry 组件对应的 UA)实现动态生效的限流效果。
CoreDNS 缓存策略可能会造成误导
注意,不建议做 CoreDNS 的永久缓存[11](serve_stale 开启),当真实发生集群控制面异常时,延长 CoreDNS 内的缓存并不能延续业务 Pod 的正常运转状态,CoreDNS 内过期缓存的 DNS 解析关系会让业务 Pod 发起的访问触达到完全错误的 IP 地址。
并且 CoreDNS 的缓存时长会一定程度上掩盖控制面组件已经异常的现象,造成集群还正常运转的假象,增加排查难度与排查时间。
快速定位对控制面组件造成主要压力的“元凶”请求组件,并快速降级
如何通过控制面监控大盘,定位到主要压力来源。
通过 daemonset 方式部署的组件,并对集群控制面有高频率、大范围的 list、watch 请求是我们所遇到的集群控制面故障的最大元凶。

(阿里云容器服务 APIServer 监控大盘的客户端粒度分析)
阿里云容器服务 APIServer 监控大盘,提供追溯调用来源方 client/操作资源 resource/操作行为 verb 等细粒度指标。
帮助 K8s 集群用户在出现控制面高负载预警或故障时能准确定位到大负载压力的来源,并帮助决策快速降级掉“元凶”应用,快速恢复整个集群稳定性。
admission controller (准入控制器) 造成的压力
K8s 提供动态准入(Dynamic Admission Control)能力,由 admissionwebhook 配置以及 admissioncontroller 组成,是 K8s 非常杰出的机制,能像 AOP 一样帮助进行集群资源生命周期的改造行为。
但是 admissionwebhook 是第二大部分我们遇到的集群控制面故障的元凶,admissionwebhook 由于会把用户自定义行为加入到 K8s 关键的资源生命周期中,可能加大 K8s 集群本身的不稳定性。同时由于 admissionwebhook 会拦截所有监听的 k8s 对象的请求,若定义不当,admissionwebhook 在大规模 K8s 集群下会产生海量的 APIServer 负担。阿里云容器服务的控制面监控大盘专门设计,希望通过控制面监控大盘,定位到 admission controller 造成的压力。

(阿里云容器服务 APIServer 监控大盘的准入控制 admissionwebhook 负载分析)
五、总结
K8s 是业界主流的基础设施架构,Prometheus 也已经成为新一代指标监控的实施标准,我们面对的是巨大的客户体量,超大规模的 K8s 集群可能遇到的风险及挑战是不可避免的。
我们只有持续关注故障沉淀下来的经验,希望通过一次次故障事件学习并自审,不断优化,才能在应对挑战时更加从容,以求更好地为用户提供更稳定、更可靠的基础设施。
链接
[01] CNCF Survey
https://www.cncf.io/reports/cncf-annual-survey-2023/
[02] Scaling Kubernetes to 7,500 nodes
https://openai.com/index/scaling-kubernetes-to-7500-nodes/
[03] OpenAI 故障报告
https://status.openai.com/incidents/ctrsv3lwd797
[04] 容器服务 K8s 控制面观测能力
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/monitor-control-plane-components/?spm=a2c4g.11186623.0.i1
[05] ControlPlane 组件的监控指标
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/monitor-control-plane-components/?spm=a2c4g.11186623.help-menu-85222.d_2_9_3_4.2532123eK3yhIa
[06] 容器服务托管节点池
https://www.alibabacloud.com/help/zh/ack/ack-managed-and-ack-dedicated/user-guide/overview-of-managed-node-pools?spm=a2c63.p38356.0.i5
[07] ECS 系统事件
https://www.alibabacloud.com/help/zh/ecs/user-guide/overview-of-ecs-system-events?spm=a2c63.p38356.0.i11#DAS
[08] ACK 集群控制面监控大盘
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/view-control-plane-component-dashboards-in-ack-pro-clusters?spm=a2c4g.11186623.0.i3
[09] 控制面组件日志监控
https://www.alibabacloud.com/help/zh/ack/ack-managed-and-ack-dedicated/user-guide/collect-control-plane-component-logs-of-ack-managed-cluster?spm=a2c63.p38356.help-menu-85222.d_2_9_2_5.43d44d31DICEnA
[10] 报警中心功能
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/alert-management?spm=a2c4g.11186623.0.i2
[11] CoreDNS 的永久缓存
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/dns-resolution-policies-and-caching-policies?spm=a2c4g.11186623.help-menu-85222.d_2_3_6_2.416b26cbrKataV#section-wvr-c0p-mtx
相关文章:
OpenAI 故障复盘 - 阿里云容器服务与可观测产品如何保障大规模 K8s 集群稳定性
本文作者: 容器服务团队:刘佳旭、冯诗淳 可观测团队:竺夏栋、麻嘉豪、隋吉智 一、前言 Kubernetes(K8s)架构已经是当今 IT 架构的主流与事实标准(CNCF Survey[1])。随着承接的业务规模越来越大,用户也在使…...

安卓触摸对焦
1. 相机坐标说明 触摸对焦需要通过setFocusAreas()设置对焦区域,而该方法的参数的坐标,与屏幕坐标并不相同,需要做一个转换。 对Camera(旧版相机API)来说,相机的坐标区域是一个2000*2000,原点…...

jupyter出现“.ipynb appears to have died. It will restart automatically.”解决方法
原因 解决方法:更新jupyter的版本 1.打开anaconda prompt 2、更新jupyter版本 在anaconda prompt输入以下指令 conda update jupyter如图:...

20250108-实验+神经网络
实验3. 神经网络与反向传播算法 3.1 计算图:复合函数的计算图 实验要求1:基于numpy实现 ( y 1 , y 2 ) f ( x 1 , x 2 , x 3 ) (y_1,y_2) f(x_1,x_2,x_3) (y1,y2)f(x1,x2,x3) 的反向传播算法(不允许使用自动微分)&a…...
)
【权限管理】CAS(Central Authentication Service)
CAS(Central Authentication Service)是一种广泛应用的 单点登录(SSO) 协议,它允许用户在一个集中式的身份验证系统中登录一次后,便可以无缝访问多个应用系统,而无需重复登录。CAS 通过统一的身…...

Golang笔记:使用net包进行TCP监听回环测试
文章目录 前言TCP监听回环代码演示 附:UDP监听回环 前言 TCP是比较基础常用的网络通讯方式,这篇文章将使用Go语言实现TCP监听回环测试。 本文中使用 Packet Sender 工具进行测试,其官网地址如下: https://packetsender.com/ TC…...

《浮岛风云》V1.0中文学习版
《浮岛风云》中文版https://pan.xunlei.com/s/VODadt0vSGdbrVOBEsW9Xx8iA1?pwdy7c3# 一款有着类似暗黑破坏神的战斗系统、类似最终幻想的奇幻世界和100%可破坏体素环境的动作冒险RPG。...

Day10——爬虫
爬虫概念 网络请求 爬虫分类 基本流程 请求头...

10. C语言 函数详解
本章目录: 前言1. C 语言函数概述1.1 函数的定义与结构1.2 函数声明1.3 函数调用 2. 函数参数传递2.1 传值调用2.2 传引用调用(模拟)2.3 引用调用(C 特性) 3. 内部函数与外部函数3.1 内部函数3.2 外部函数3.3 示例:多个…...

NRC优先级中比较特殊的—NRC0x13和NRC0x31
1、基础知识 大家都了解 NRC0x13,表示长度错误和格式错误 NRC0x31,表示DID不支持和数据格式不支持 2、为什么说这两个NRC比较特殊 看下图的标注部分: 2.1、先看NRC0x13 步骤一:仔细看是先判断Minmun Length Check ࿰…...
 和 reactive() 区别)
ref() 和 reactive() 区别
ref() 和 reactive() 都是 Vue 3 中用于创建响应式数据的方法,但它们之间存在一些关键差异。 首先,ref() 用于创建响应式的标量值,比如数字、字符串、布尔值等基本数据类型,以及对象和数组等复杂数据类型。当你使用 ref() 时&…...

深度学习与计算机视觉 (博士)
文章目录 零、计算机视觉概述一、深度学习相关概念1.学习率η2.batchsize和epoch3.端到端(End-to-End)、序列到序列(Seq-to-Seq)4.消融实验5.学习方式6.监督学习的方式(1)有监督学习(2)强监督学习(3)弱监督学习(4)半监督学习(5)自监督学习(6)无监督学习(7)总结:不同…...

Sprint Boot教程之五十:Spring Boot JpaRepository 示例
Spring Boot JpaRepository 示例 Spring Boot建立在 Spring 之上,包含 Spring 的所有功能。由于其快速的生产就绪环境,使开发人员能够直接专注于逻辑,而不必费力配置和设置,因此如今它正成为开发人员的最爱。Spring Boot 是一个基…...
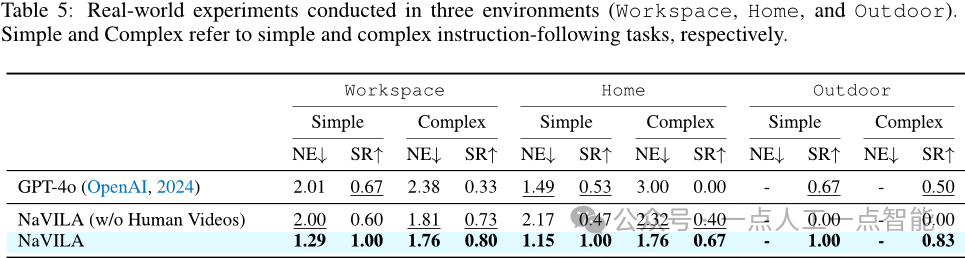
NaVILA:用于足式机器人导航的VLA模型
论文地址:https://navila-bot.github.io/static/navila_paper.pdf 项目地址:https://navila-bot.github.io/ 本文提出了一种名为NaVILA的机器人导航模型,旨在解决视觉语言导航问题,并允许机器人在更具挑战性和杂乱的场景中进行导…...
大语言模型提示技巧(七)-扩展
扩展是将较短的文本,例如一组提示或主题列表,输入到大型语言模型中,让模型生成更长的文本。我们可以利用这个特性让大语言模型生成基于某个主题的电子邮件或小论文。通过这种方式使用大语言模型,可以为工作与生活提供诸多便利&…...

基类指针指向派生类对象,基类指针的首地址永远指向子类从基类继承的基类首地址
文章目录 基类指针指向派生类对象,基类指针的首地址永远指向子类从基类继承的基类起始地址。代码代码2 基类指针指向派生类对象,基类指针的首地址永远指向子类从基类继承的基类起始地址。 代码 #include <iostream> using namespace std;class b…...

25年01月HarmonyOS应用基础认证最新题库
判断题 “一次开发,多端部署”指的是一个工程,一次开发上架,多端按需部署。为了实现这一目的,HarmonyOS提供了多端开发环境,多端开发能力以及多端分发机制。 答案:正确 《鸿蒙生态应用开发白皮书》全面阐释…...

wps宏js接入AI功能和接入翻译功能
wps的js越来越强大了,很实用的功能,爱了 表格wps js接入AI 表格wps js接入翻译功能,自定义翻译语言和目标语言...

【Logstash03】企业级日志分析系统ELK之Logstash 过滤 Filter 插件
Logstash 过滤 Filter 插件 数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构, 并将它们转换成通用格式,以便进行更强大的分析和实现商业价值。 Logstash 能够动态地转换和解析数据&a…...

深度学习:Java DL4J基于RNN构建智能停车管理模型
### 深度学习:Java DL4J基于RNN构建智能停车管理模型 #### 引言 随着城市化进程的加速,停车问题日益成为城市管理的难点和痛点。传统的停车场管理方式效率低下,导致停车场资源无法得到充分利用,车主停车体验差。为了解决这些痛点…...

TurboDiffusion新手入门:5步搞定Wan2.1模型,快速出片
TurboDiffusion新手入门:5步搞定Wan2.1模型,快速出片 1. TurboDiffusion简介与准备工作 1.1 什么是TurboDiffusion TurboDiffusion是由清华大学、生数科技和加州大学伯克利分校联合开发的视频生成加速框架。它基于Wan2.1和Wan2.2模型进行二次开发&…...

DeepXDE终极指南:科学机器学习与物理信息学习的完整解决方案
DeepXDE终极指南:科学机器学习与物理信息学习的完整解决方案 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde 在科学计算和工程仿真领域ÿ…...

MySQL8.0大小写敏感坑爹实录:lower_case_table_names从报错到解决的完整过程
MySQL 8.0大小写敏感参数避坑指南:从报错到根治的深度实践 最近在迁移开发环境到Docker时,遇到了一个令人头疼的问题——MySQL 8.0服务无法启动,报错提示Different lower_case_table_names settings for server (2) and data dictionary (0)。…...

超声AI 2026年市场格局:头部公司怎么选、谁在领跑
超声AI哪家做得好?”这个问题,2026年再用“列公司名单”的方式回答,其实已经不太够用了。因为医疗AI的竞争早就不只拼演示效果,更像一场硬仗:能不能上临床、敢不敢用、用得起、用得开。你最终要的不是“看起来很强”&a…...

OpenClaw操作简化技巧:Kimi-VL-A3B-Thinking常用任务的一键触发
OpenClaw操作简化技巧:Kimi-VL-A3B-Thinking常用任务的一键触发 1. 为什么需要操作简化 第一次接触OpenClaw时,我被它强大的自动化能力震撼——直到需要反复输入冗长的指令来触发同一个任务。比如每天早晨需要让Kimi-VL-A3B-Thinking模型帮我整理前一天…...
)
从B站视频到毕业设计:三相四桥臂的三种主流控制方案到底怎么选?(MPC/3D-SVPWM/载波调制深度对比)
三相四桥臂逆变器控制方案深度对比:从理论到工程实践的选择指南 在电力电子领域,三相四桥臂逆变器的控制策略选择一直是工程师和研究者面临的关键挑战。不同于传统的三相三桥臂结构,第四桥臂的引入虽然解决了不平衡负载下的中性点电流问题&a…...

为什么92%的.NET开发者在.NET 9中AI推理失败?5个被官方文档隐藏的关键配置陷阱
第一章:.NET 9 AI推理能力演进与核心定位.NET 9 将原生 AI 推理能力深度融入运行时与 SDK 生态,标志着 .NET 从“通用开发平台”向“AI-ready 应用平台”的战略跃迁。这一演进并非简单封装第三方模型 API,而是通过轻量级推理引擎集成、统一张…...

Qwen3智能字幕对齐系统开发环境搭建:基于IDEA的Java SDK调试指南
Qwen3智能字幕对齐系统开发环境搭建:基于IDEA的Java SDK调试指南 如果你是一名Java开发者,最近想尝试接入Qwen3智能字幕对齐系统的能力,比如为视频自动生成精准的字幕时间轴,那么这篇文章就是为你准备的。今天,我们不…...

M2LOrder模型赋能软件测试:用例生成与缺陷预测实践
M2LOrder模型赋能软件测试:用例生成与缺陷预测实践 最近和几个做测试的朋友聊天,大家普遍吐槽,现在软件迭代越来越快,留给测试的时间却越来越短。需求文档刚定稿,开发那边代码就快写完了,测试用例还没设计…...

Vivado里给UltraScale FPGA的MGT分时钟,为啥隔壁SLR的Bank死活不认?
Vivado调试手记:破解UltraScale FPGA跨SLR时钟共享难题 第一次在Vivado里看到"ERROR: [DRC 23-20] GT_COMMON placement violation"这个红色报错时,我盯着屏幕愣了三分钟——明明在7系列FPGA上运行良好的参考时钟共享方案,怎么换到…...