Lambda离线实时分治架构深度解析与实战
一、引言
在大数据技术日新月异的今天,Lambda架构作为一种经典的数据处理模型,在应对大规模数据应用方面展现出了强大的能力。它整合了离线批处理和实时流处理,为需要同时处理批量和实时数据的应用场景提供了成熟的解决方案。本文将对Lambda架构的演变、核心组件、工作原理及痛点进行深度解析,并通过Java代码实现一个实战实例。
二、Lambda架构的演变
Lambda架构是由Storm的作者Nathan Marz提出的一种实时大数据处理框架。Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,而Lambda架构则是他根据多年进行分布式大数据系统的经验总结提炼而成。Lambda架构的诞生离不开现有设计思想和架构的铺垫,如事件溯源架构和命令查询分离架构。
Lambda架构的设计初衷是提供一个能满足大数据系统关键特性的架构,包括高容错、低延迟、可扩展等。它整合了离线计算和实时计算,融合了不可变性、读写分离和复杂性隔离等一系列架构原则,可集成Hadoop、Kafka、Spark、Storm、Flink等主流大数据组件。随着大数据技术的不断发展,Lambda架构也在不断优化和完善,以更好地适应新的数据处理需求。
三、Lambda架构的核心组件
Lambda架构主要包含以下三个核心组件:
1. 批处理层(Batch Layer)
批处理层负责处理离线或批量数据。这一层通常使用分布式计算框架(如Hadoop)来处理大规模数据集。它的核心功能包括存储数据集和生成批视图(Batch View)。批处理层的数据处理是准确且全量的,但数据处理时延较高。它接收原始数据流,并进行批量处理和分析。数据是原始的、不可变的,并且永远是真实的。批处理层使用容错性较强的分布式文件系统(如Hadoop HDFS)存储和处理数据,在处理过程中可以处理故障和错误。
2. 实时处理层(Speed Layer)
实时处理层负责处理实时数据流。这一层通常使用流处理框架(如Apache Kafka、Apache Flink或Apache Storm)来处理数据流。它执行实时计算和聚合操作,生成实时视图(Real-time View)或实时处理视图。这些视图是基于实时数据流计算得到的结果。实时处理层的数据处理只针对最近的实时数据,处理结果可能不准确,但时延很低。为了提高数据处理效率,该层接收到新数据后会不断更新实时数据视图。
3. 合并层(Serving Layer)
合并层负责将批处理层和实时处理层生成的视图合并为一致的查询结果。这一层通常使用分布式存储系统(如HBase或Cassandra)来存储视图,并为用户提供查询接口。合并层的任务包括数据同步、视图合并和查询处理。它整合批处理层和实时处理层的结果,为用户提供统一的访问接口。用户可以通过该接口查询历史数据和实时数据。
四、Lambda架构的工作原理
Lambda架构的工作原理可以概括为以下几个步骤:
1. 数据采集
数据采集是Lambda架构的第一步。通常情况下,使用Apache Kafka来收集实时流数据。Kafka是一个分布式消息系统,以其可以水平扩展和高吞吐率而被广泛使用。同时,对于离线数据,可以使用Sqoop等离线数据传输工具将数据从传统数据库(如MySQL、PostgreSQL等)传输到Hadoop(Hive)等离线数据处理平台。
2. 批处理
在批处理层,使用分布式计算框架(如Hadoop或Spark)对采集到的离线数据进行批量处理和分析。批处理层会预先在数据集上计算并保存查询函数的结果,这些结果保存在批视图中。当用户查询时,可以直接或通过简单运算返回结果,而无需重新进行完整费时的计算。
3. 实时处理
在实时处理层,使用流处理框架(如Storm或Spark Streaming)对实时数据流进行处理。实时处理层会接收到新数据后不断更新实时数据视图,以提供低延迟的查询结果。实时处理层通常执行较简单的计算任务,如数据过滤、聚合、索引等。
4. 合并与查询
在合并层,将批处理层和实时处理层的结果进行整合,为用户提供统一的查询接口。合并层会保证查询结果的完整性和一致性。用户可以通过该接口查询历史数据和实时数据,并获取合并后的结果。
五、Lambda架构的痛点
尽管Lambda架构在大数据处理方面展现出了强大的能力,但它也存在一些痛点:
1. 复杂性
Lambda架构引入了多层次的处理和管理,增加了系统的复杂性和维护成本。开发人员需要熟悉多个技术栈和组件,因此学习曲线较陡。
2. 延迟
由于数据要经历批处理和实时处理两个阶段,可能会引入一些延迟,特别是在合并数据时。这对于需要极低延迟的应用场景来说可能是一个问题。
3. 数据一致性
虽然合并层通过数据同步和视图合并来提供一致的查询结果,但在某些情况下,实时视图和批视图之间可能存在不一致性。这需要在系统设计和实现时进行权衡和取舍。
4. 部署和迁移成本
Lambda架构需要同时部署批处理层和实时处理层,这增加了系统的部署和迁移成本。特别是在数据量较大或系统复杂度较高的情况下,部署和迁移过程可能会更加复杂和耗时。
六、Lambda架构的Java实战实例
下面将通过一个简单的Java实例来展示如何实现Lambda架构的基本功能。这个实例将包括数据采集、批处理、实时处理和合并与查询四个步骤。
1. 数据采集
使用Apache Kafka来收集实时流数据。首先,需要启动Kafka服务并创建一个Kafka生产者来发送数据。
java复制代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
String key = "key" + i;
String value = "value" + i;ProducerRecord<String, String> record = new ProducerRecord<>("topic", key, value);producer.send(record);}producer.close();}
}在上面的代码中,我们创建了一个Kafka生产者,并发送了100条消息到名为“topic”的主题中。
2. 批处理
使用Apache Spark对采集到的离线数据进行批量处理和分析。假设我们已经将离线数据存储在HDFS中,并且数据格式为CSV。下面是一个使用Spark进行批处理的示例代码。
java复制代码
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkBatchProcessingExample {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("Batch Processing").master("local[*]").getOrCreate();Dataset<Row> df = spark.read().csv("hdfs://path/to/batch_data.csv");df.createOrReplaceTempView("batch_data");Dataset<Row> filteredData = spark.sql("SELECT * FROM batch_data WHERE value > 10");filteredData.write().mode("overwrite").parquet("hdfs://path/to/processed_batch_data");spark.stop();}
}在上面的代码中,我们创建了一个Spark会话,读取了存储在HDFS中的CSV文件,并对数据进行了过滤操作。然后,将过滤后的数据以Parquet格式存储回HDFS中。
3. 实时处理
使用Apache Spark Streaming对实时数据流进行处理。假设我们已经将Kafka中的数据作为实时数据源。下面是一个使用Spark Streaming进行实时处理的示例代码。
java复制代码
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairDStream;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class SparkStreamingExample {
public static void main(String[] args) throws InterruptedException {
SparkConf conf = new SparkConf().setAppName("Real Time Processing").setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(1));Map<String, Object> kafkaParams = new HashMap<>();kafkaParams.put("bootstrap.servers", "localhost:9092");kafkaParams.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");kafkaParams.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");kafkaParams.put("group.id", "spark-streaming-group");kafkaParams.put("auto.offset.reset", "latest");kafkaParams.put("enable.auto.commit", false);JavaPairInputDStream<String, String> streams = KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(Collections.singletonList("topic"), kafkaParams));JavaDStream<String> lines = streams.map(Tuple2::_2);JavaPairDStream<String, Integer> wordCounts = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator()).mapToPair(word -> new Tuple2<>(word, 1)).reduceByKey((a, b) -> a + b);wordCounts.print();ssc.start();ssc.awaitTermination();}
}在上面的代码中,我们创建了一个Spark Streaming上下文,并连接到Kafka中的实时数据源。我们对数据流进行了单词计数操作,并将结果打印出来。
4. 合并与查询
在合并层,我们需要将批处理层和实时处理层的结果进行整合,并为用户提供统一的查询接口。这里可以使用一个简单的Java程序来模拟这个过程。假设我们已经将批处理结果和实时处理结果存储在不同的数据表中(如HDFS中的Parquet文件或数据库中的表)。
java复制代码
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
public class MergingAndQueryingExample {
public static void main(String[] args) {
// 假设我们已经将批处理结果存储在名为"batch_results"的表中
// 实时处理结果存储在名为"realtime_results"的表中List<String> batchResults = fetchBatchResults();List<String> realtimeResults = fetchRealtimeResults();
// 合并结果List<String> mergedResults = new ArrayList<>(batchResults);mergedResults.addAll(realtimeResults);
// 提供查询接口queryResults(mergedResults);}
private static List<String> fetchBatchResults() {
// 模拟从批处理结果表中获取数据List<String> results = new ArrayList<>();results.add("Batch Result 1");results.add("Batch Result 2");
return results;}
private static List<String> fetchRealtimeResults() {
// 模拟从实时处理结果表中获取数据List<String> results = new ArrayList<>();results.add("Realtime Result 1");results.add("Realtime Result 2");
return results;}
private static void queryResults(List<String> results) {
// 模拟查询接口,打印合并后的结果
for (String result : results) {System.out.println(result);}}
}在上面的代码中,我们模拟了从批处理结果表和实时处理结果表中获取数据的过程,并将结果合并后打印出来。这可以看作是一个简单的查询接口,用户可以通过这个接口查询合并后的结果。
七、总结与展望
Lambda架构作为一种经典的大数据处理模型,在应对大规模数据应用方面展现出了强大的能力。它通过整合离线批处理和实时流处理,为需要同时处理批量和实时数据的应用场景提供了成熟的解决方案。然而,Lambda架构也存在一些痛点,如复杂性、延迟、数据一致性和部署迁移成本等。在未来的发展中,我们可以探索如何进一步优化Lambda架构,提高其性能和可扩展性,并降低其复杂性和维护成本。
同时,随着大数据技术的不断发展,新的数据处理架构也在不断涌现。例如,Kappa架构就是一种专注于实时处理的架构,它试图通过实时流处理来替代传统的批处理层。虽然Kappa架构在某些场景下可能具有更好的性能和可扩展性,但它也面临着一些挑战,如如何保证数据的准确性和一致性等。因此,在选择数据处理架构时,我们需要根据具体的应用场景和需求进行权衡和取舍。
对于大数据技术专家来说,掌握Lambda架构的原理和实现方法是非常重要的。通过深入理解Lambda架构的演变、核心组件、工作原理及痛点,我们可以更好地应对大数据处理中的挑战和问题。同时,通过实践和应用Lambda架构,我们可以不断提升自己的技术水平和实战能力,为大数据技术的发展贡献自己的力量。
相关文章:

Lambda离线实时分治架构深度解析与实战
一、引言 在大数据技术日新月异的今天,Lambda架构作为一种经典的数据处理模型,在应对大规模数据应用方面展现出了强大的能力。它整合了离线批处理和实时流处理,为需要同时处理批量和实时数据的应用场景提供了成熟的解决方案。本文将对Lambda…...

Spring Boot教程之五十一:Spring Boot – CrudRepository 示例
Spring Boot – CrudRepository 示例 Spring Boot 建立在 Spring 之上,包含 Spring 的所有功能。由于其快速的生产就绪环境,使开发人员能够直接专注于逻辑,而不必费力配置和设置,因此如今它正成为开发人员的最爱。Spring Boot 是…...

jenkins入门6 --拉取代码
Jenkins代码拉取 需要的插件,缺少的安装下 新建一个item,选择freestyle project 源码管理配置如下:需要添加git库地址,和登录git的用户密码 配置好后执行编译,成功后拉取的代码在工作空间里...

CAPL概述与环境搭建
CAPL概述与环境搭建 目录 CAPL概述与环境搭建1. CAPL简介与应用领域1.1 CAPL简介1.2 CAPL的应用领域 2. CANoe/CANalyzer 安装与配置2.1 CANoe/CANalyzer 简介2.2 安装CANoe/CANalyzer2.2.1 系统要求2.2.2 安装步骤 2.3 配置CANoe/CANalyzer2.3.1 配置CAN通道2.3.2 配置CAPL节点…...

Virgo:增强慢思考推理能力的多模态大语言模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

偃动访无穿戴动作捕捉系统:赋能多行业开启动作捕捉新篇章
在当今科技飞速发展的时代,动作捕捉技术正以前所未有的态势深入到社会发展的各个领域,成为众多行业不可或缺的重要助力。从早期的惯性动捕与光捕技术,到如今更为先进的无标记动捕技术,动作捕捉领域不断迎来革新与突破。 无标记动…...

mikro-orm 和typeorm 对比
以下是Mikro-ORM和TypeORM的详细对比: 设计理念与架构 Mikro-ORM:基于数据映射器、工作单元和身份映射模式。这种设计使得它在管理内存中实体状态方面表现优异,能够自动处理事务,当调用em.flush()时,所有计算出的更改…...

Docker入门之docker基本命令
Docker入门之docker基本命令 官方网站:https://www.docker.com/ 1. 拉取官方镜像并创建容器(以redis为例) 拉取官方镜像 docker pull redis# 如果不需要添加到自定义网络使用这个命令,如需要,直接看第二步 docker r…...

mysql的一些函数及其用法
mysql 1-来自于leetcode1517的题目 表: Users------------------------ | Column Name | Type | ------------------------ | user_id | int | | name | varchar | | mail | varchar | ------------------------已知一个表,它的…...

NO.3 《机器学习期末复习篇》以题(问答题)促习(人学习),满满干huo,大胆学大胆补!
目录 🔍 1. 对于非齐次线性模型 ,试将其表示为齐次线性模型形式。 编辑 🔍 2. 某汽车公司一年内各月份的广告投入与月销量数据如表3-28所示,试根据表中数据构造线性回归模型,并使用该模型预测月广告投入为20万元时…...

黑马跟学.苍穹外卖.Day03
黑马跟学.苍穹外卖.Day03 苍穹外卖-day03课程内容1. 公共字段自动填充1.1 问题分析1.2 实现思路1.3 代码开发1.3.1 步骤一1.3.2 步骤二1.3.3 步骤三 1.4 功能测试1.5 代码提交 2. 新增菜品2.1 需求分析与设计2.1.1 产品原型2.1.2 接口设计2.1.3 表设计 2.2 代码开发2.2.1 文件上…...
)
js -音频变音(听不出说话的人是谁)
学习参考来源: https://zhuanlan.zhihu.com/p/634848804 https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Audio_API 实际效果: http://www.qingkong.zone/laboratory?typeaudio-confusion 前言 本文内容可结合上面学习参考来源,结合…...

鸿蒙UI(ArkUI-方舟UI框架)
参考:https://developer.huawei.com/consumer/cn/doc/harmonyos-guides-V13/arkts-layout-development-overview-V13 ArkUI简介 ArkUI(方舟UI框架)为应用的UI开发提供了完整的基础设施,包括简洁的UI语法、丰富的UI功能ÿ…...

常见的http状态码 + ResponseEntity
常见的http状态码 ResponseStatus(HttpStatus.CREATED) 是 Spring Framework 中的注解,用于指定 HTTP 响应状态码。 1. 基本说明 HttpStatus.CREATED 对应 HTTP 状态码 201表示请求成功且创建了新的资源通常用于 POST 请求的处理方法上 2. 使用场景和示例 基本…...

pikachu - Cross-Site Scripting(XSS)
pikachu - Cross-Site Scripting(XSS) 声明! 笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人无关,切勿触碰法律底线,否则后果自负&#x…...

操作系统之文件系统的基本概念
目录 用户和磁盘视角的文件 文件控制块(FCB)和索引结点(inode) 文件的操作 创建文件(create系统调用) 写文件(write系统调用) 读文件(read系统调用) 重…...

深入探讨 Android 中的 AlarmManager:定时任务调度及优化实践
引言 在 Android 开发中,AlarmManager 是一个非常重要的系统服务,用于设置定时任务或者周期性任务。无论是设置一个闹钟,还是定时进行数据同步,AlarmManager 都是不可或缺的工具之一。然而,随着 Android 系统的不断演…...

西电-算法分析-研究生课程复习笔记
24年秋的应该是张老师最后一次用卷面考试,他说以后这节课的期末考试都是在OJ上刷题了张老师上课还挺有意思的,上完之后能学会独立地思考算法设计问题了。整节课都在强调规模压缩这个概念,考试也是考个人对这些的理解,还挺好玩的哈…...

编译时找不到需要的库,如何在PyCharm中为你的项目添加需要的库
丰富的库支持是 Python 语言的一大特点,但是在使用 PyCharm 进行Python 代码编译的时候,遇到一些需要使用到的库提示不能解析时,该如何添加呢? 比如下图所示的代码,可以看到需要使用 selenium、b4、jieba 这些库&…...
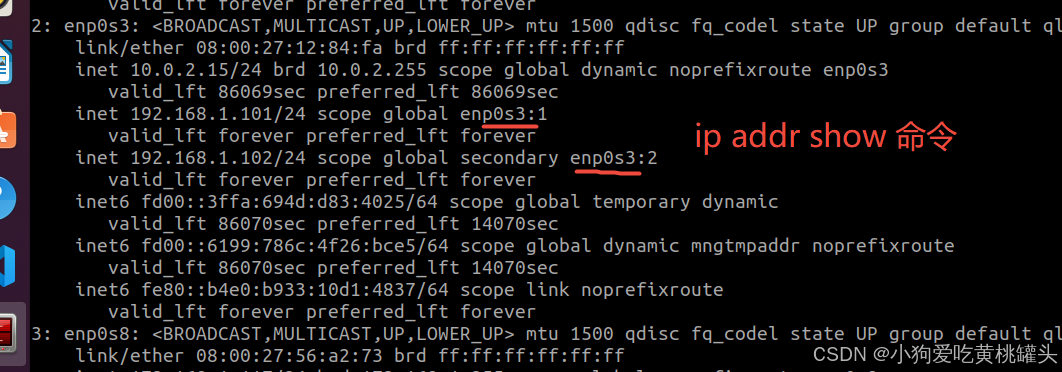
ip addr 命令给Linux网络接口配置多个IP地址值
问一下Chatgpt 怎么使用ip addr 命令给Linux网络接口配置多个IP地址值 根据Chatgpt的提示执行了命令,命令执行成功,看下执行结果。 ifconfig 命令查看接口IP地址 ip addr show 命令查看接口IP地址...
)
【快速EI检索 | SPIE出版】2026年量子计算与人工智能国际学术会议(ICQCAI 2026)
2026年量子计算与人工智能国际学术会议(ICQCAI 2026) 2026 International Conference on Environmental Pollution and Sustainable Resource Management 2026年5月8-10日, 中国-北京 大会官网:www.icqcai.com 截稿时间&#…...
)
无人车避障新思路:手把手教你用MATLAB实现贝塞尔曲线路径规划(含完整代码)
无人车避障新思路:手把手教你用MATLAB实现贝塞尔曲线路径规划(含完整代码) 在自动驾驶和机器人导航领域,路径规划的核心挑战之一是如何在复杂环境中生成既安全又符合车辆运动学的轨迹。传统方法如A*或Dijkstra算法虽然能找出最短路…...

2023长城杯Web赛题解析:从SSRF到Pickle反序列化的实战攻防
1. 从SSRF漏洞到内网渗透的实战突破 去年参加长城杯时遇到一道名为"seeking"的Web题目,让我对SSRF漏洞的利用有了全新认识。题目一开始给出了一个看似简单的PHP文件,但隐藏着精妙的设计。代码中通过file_get_contents函数获取图片内容时&#…...

零基础入门linux开发:快马带你轻松搞定wsl2下载与初体验
作为一个刚接触Linux开发的新手,第一次听说WSL2时完全摸不着头脑。经过一段时间的摸索和实践,我发现用InsCode(快马)平台来学习和体验WSL2特别方便,下面就把我的入门经验分享给大家。 什么是WSL2?为什么需要它? WSL2…...

如何快速安装和配置Pop Shell:面向初学者的完整教程
如何快速安装和配置Pop Shell:面向初学者的完整教程 【免费下载链接】shell Pop!_OS Shell 项目地址: https://gitcode.com/gh_mirrors/sh/shell Pop Shell是一款功能强大的窗口管理扩展,专为提升Linux桌面操作效率设计。本教程将带您逐步完成Pop…...

QueryWrapper常用案例
记录于 2023.09.18 个人博客,现转录CSDNQueryWrapper MyBatis-Plus 提供的「SQL 条件自动拼接工具」 不用手写 SQL 语句,用 Java 链式代码,自动帮你拼出 where、order by、like、in、between 等查询条件。 1.多条数据查询 import com.baomid…...

12. C++14新特性-字符串操作与标准用户定义字面量
一、引言C11 引入了用户定义字面量(User-Defined Literals, UDL)的底层机制,允许开发者通过重载 operator "" 为基础类型附加上下文语义。然而,C11 标准库自身并未提供预置的后缀实现。C14 填补了这一标准库层面的空白&…...

猫抓浏览器扩展:网页资源嗅探的终极解决方案与完整实施指南
猫抓浏览器扩展:网页资源嗅探的终极解决方案与完整实施指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容爆炸的时代&…...

ai辅助开发:让快马智能诊断并解决wsl2安装过程中的疑难杂症
AI辅助开发:让快马智能诊断并解决WSL2安装过程中的疑难杂症 最近在尝试安装WSL2时遇到了一个常见但令人头疼的问题——系统提示"请启用虚拟机平台Windows功能并确保在BIOS中启用虚拟化"。虽然我已经确认BIOS中的虚拟化设置是开启的,但问题依然…...
 红外避障传感器模块深度调试与CubeMX源码解析)
STM32F407实战指南(十九) 红外避障传感器模块深度调试与CubeMX源码解析
1. 红外避障传感器模块的核心原理与硬件解析 红外避障传感器本质上是一个"主动探测反射接收"的系统。发射管会持续发射38kHz的红外信号(这个频率能有效避免自然光干扰),当遇到障碍物时,红外线会被反射回来。接收管内部其…...