【集成学习】Boosting算法详解
文章目录
- 1. 集成学习概述
- 2. Boosting算法详解
- 3. Gradient Boosting算法详解
- 3.1 基本思想
- 3.2 公式推导
- 4. Python实现
1. 集成学习概述
集成学习(Ensemble Learning)是一种通过结合多个模型的预测结果来提高整体预测性能的技术。相比于单个模型,集成学习通过多个基学习器的“集体智慧”来增强模型的泛化能力,通常能够提高模型的稳定性和准确性。
常见的集成学习框架有:
- Bagging:通过并行训练多个模型并对其结果进行平均或投票来减少方差
- Boosting:通过按顺序训练多个模型,每个模型都试图纠正前一个模型的错误,从而减少偏差
- Stacking:通过训练多个不同类型的基学习器,并将它们的输出作为特征输入到一个高层模型中,从而提升预测性能
每种方法都有其独特的优势和适用场景。在本文中,我们将重点介绍 Boosting 算法,它主要聚焦于通过提高模型的准确度来减少偏差。
2. Boosting算法详解
Boosting 是一种迭代加权的集成学习方法,旨在通过多个弱学习器(通常是偏差较大的模型)的组合,构建一个具有较低偏差和较高准确度的强学习器。与 Bagging 不同,Boosting 关注的是减小模型的 偏差,而非仅仅减少方差。
Boosting 算法通过逐步构建和改进模型,使得每个新模型都能够专注于纠正前一个模型的错误。这种方式使得模型的 预测能力 不断得到提高。Boosting 的核心思想是 顺序训练。每个新的模型都在前一个模型的基础上进行训练,重点关注那些被前一个模型错误分类的样本。通过这种方式,Boosting 可以有效地减少偏差,进而提升模型的精度。
3. Gradient Boosting算法详解
3.1 基本思想
Gradient Boosting 是 Boosting 的一种实现方法,它通过梯度下降的方式,逐步减少模型的偏差。在每一轮迭代中,Gradient Boosting 都会根据上一轮模型的预测误差(残差)训练一个新的弱学习器,最终的预测结果是所有模型预测结果的加权和。
举个简单的例子,假设一个样本真实值为10,若第一个学习器拟合结果为7,则残差为 10-7=3, 残差3作为下一个学习器的拟合目标。若第二个学习器拟合结果为2,则这两个弱学习器组合而成的Boosting模型对于样本的预测为7+2 = 9,以此类推可以继续增加弱学习器以提高性能。
Gradient Boosting还可以将其理解为函数空间上的梯度下降。我们比较熟悉的梯度下降是在参数空间上的梯度下降(例如训练神经网络,每轮迭代中计算当前损失关于参数的梯度,对参数进行更新)。而在Gradient Boosting中,每轮迭代生成一个弱学习器,这个弱学习器拟合损失函数关于之前累积模型的梯度,然后将这个弱学习器加入累积模型中,逐渐降低累积模型的损失。即 参数空间的梯度下降利用梯度信息调整参数降低损失,函数空间的梯度下降利用梯度拟合一个新的函数降低损失。
3.2 公式推导
假设有训练样本 { x i , y i } , i = 1... n \{x_i,y_i\}, i=1...n {xi,yi},i=1...n,在第 m − 1 m-1 m−1 轮获得的累积模型为 F m − 1 ( x ) F_{m-1}(x) Fm−1(x),则第 m m m 轮的弱学习器 h ( x ) h(x) h(x) 可以通过下式得到
F m ( x ) = F m − 1 ( x ) + arg min h ∈ H Loss ( y i , F m − 1 ( x i ) + h ( x i ) ) F_m(x) = F_{m-1}(x) + \arg \min_{h \in H} \, \text{Loss}(y_i, F_{m-1}(x_i) + h(x_i)) Fm(x)=Fm−1(x)+argh∈HminLoss(yi,Fm−1(xi)+h(xi))
其中上式等号右边第二项的意思是:在函数空间 H H H 中找到一个弱学习器 h ( x ) h(x) h(x),使得加入这个弱学习器之后的累积模型的 l o s s loss loss 最小。那么应该如何找这个 h ( x ) h(x) h(x) 呢?在第 m − 1 m-1 m−1 轮结束后,我们可以计算得到损失 L o s s ( y , F m − 1 ( x ) ) Loss(y,F_{m-1}(x)) Loss(y,Fm−1(x)),如果我们希望加入第 m m m 轮的弱学习器后模型的 l o s s loss loss 最小,根据最速下降法新加入的模型损失函数沿着负梯度的方向移动,即如果第 m 轮弱学习器拟合函数关于累积模型 F m − 1 ( x ) F_{m-1}(x) Fm−1(x) 的负梯度,则加上该弱学习器之后累积模型的 l o s s loss loss 会最小。
因此可以得知第 m 轮弱学习器训练的目标是损失函数的负梯度,即:
g m = − ∂ Loss ( y , F m − 1 ( x ) ) ∂ F m − 1 ( x ) g_m = - \frac{\partial \, \text{Loss}(y, F_{m-1}(x))}{\partial F_{m-1}(x)} gm=−∂Fm−1(x)∂Loss(y,Fm−1(x))
如果 Gradient Boosting中采用平方损失函数 L o s s = ( y − F m − 1 ( x ) ) 2 Loss=(y-F_{m-1}(x))^2 Loss=(y−Fm−1(x))2,损失函数负梯度计算出来刚好是残差 y − F m − 1 ( x ) y-F_{m-1}(x) y−Fm−1(x),因此也会说Gradient Boosting每一个弱学习器是在拟合之前累积模型的残差。这样的说法不具有一般性,如果使用其他损失函数或者在损失函数中加入正则项,那么负梯度就不再刚好是残差。
由此可得完整的 Gradient Boosting 算法流程:

以上 Gradient Boosting 的算法流程具有一般性,根据其中的损失函数和弱学习器的不同可以演变出多种不同的算法。如果损失函数换成平方损失,则算法变成 L2Boosting;如果将损失函数换成 log-loss,则算法成为 BinomialBoost;如果是指数损失,则算法演变成 AdaBoost;还可以采用 Huber loss 等更加 robust 的损失函数。弱学习器如果使用决策树,则算法成为 GBDT(Gradient Boosting Decision Tree),使用决策树作为弱学习器的 GBDT 使用较为普遍。
4. Python实现
python伪代码实现 GradientBoosting :
class GradientBoosting:def __init__(self, base_learner, n_learner, learning_rate):self.learners = [clone(base_learner) for _ in range(n_learner)]self.lr = learning_ratedef fit(self, X, y):residual = y.copy()for learner in self.learners:learner.fit(X, residual)residual -= self.lr * learner.predict(X)def predict(self, X):preds = [learner.predict(X) for learner in self.learners]return np.array(preds).sum(axis=0) * self.lr
加入学习率 (learning_rate 或 lr) 的目的是为了控制每个基学习器(或弱学习器)对最终模型的贡献度,从而达到更好的训练效果和避免过拟合。 具体来说,学习率的作用可以总结为以下几点(From ChatGPT):
1.防止过拟合
在 Gradient Boosting 中,训练过程是逐步的,每一轮都会基于前一轮的残差训练一个新的基学习器,并将其结果加到已有模型中。假设没有学习率的话,每个基学习器的预测值将完全被加到累积模型中,可能会使模型快速过拟合训练数据。
学习率 lr 的引入通过调整每个基学习器的权重,从而控制模型每次更新的幅度。如果学习率过大,可能会使模型在训练集上快速拟合,导致过拟合;而如果学习率过小,模型训练速度会变得非常慢,可能需要更多的基学习器来达到同样的效果。因此,合理的学习率可以在训练过程中平衡模型的收敛速度和防止过拟合。
2. 控制每个基学习器的贡献度
Gradient Boosting 的训练是一个渐进的过程,每个基学习器都会根据前一轮的残差来进行拟合。没有学习率的情况下,每个新基学习器的贡献将会很大,这可能导致模型在早期就对训练数据过于敏感,无法很好地泛化。
学习率通过缩小每个基学习器的贡献,避免模型在每轮更新时发生过大的变化。通常来说,较小的学习率需要更多的基学习器(即更多的迭代次数)来收敛,但可以有效减少每个基学习器对最终结果的影响,从而降低过拟合的风险。
3. 控制训练过程的收敛速度
学习率对模型的收敛速度有很大的影响。较大的学习率可以使模型快速收敛,但可能导致震荡或过拟合;而较小的学习率使模型收敛较慢,但通常会得到更加平滑和稳健的结果。合理选择学习率,可以在优化过程的初期实现快速的方向调整,而在后期逐渐精细化模型。
4. 改进模型的稳定性
加入学习率可以帮助模型在训练过程中避免跳跃式的大幅更新。每个基学习器的调整幅度得到控制,使得模型更新更为平稳,从而使得训练过程更加稳定,减少了由于每个学习器的过度调整带来的不稳定性。
数学解释:
在训练过程中,每一轮训练的目标是通过最小化损失函数来拟合前一轮累积模型的残差。对于每一轮的弱学习器,其目标是拟合当前模型残差的负梯度。加入学习率 lr 后,训练过程中的每个弱学习器的输出会乘以该学习率,从而调节每个学习器对模型更新的贡献。
具体来说,假设当前模型的输出为 F m − 1 ( x ) F_{m-1}(x) Fm−1(x),而第 m m m 轮的弱学习器的目标是拟合该模型的残差。使用学习率 lr 后,更新步骤变为:
F m ( x ) = F m − 1 ( x ) + l r ∗ h m ( x ) F_m(x) = F_{m-1}(x) + lr*h_m(x) Fm(x)=Fm−1(x)+lr∗hm(x)
这里, h m ( x ) h_m(x) hm(x) 是第 m m m 轮弱学习器的输出。通过学习率 lr,我们可以控制每个弱学习器的输出对最终模型的贡献。
本文参考:
https://borgwang.github.io/ml/2019/04/12/gradient-boosting.html
相关文章:
【集成学习】Boosting算法详解
文章目录 1. 集成学习概述2. Boosting算法详解3. Gradient Boosting算法详解3.1 基本思想3.2 公式推导 4. Python实现 1. 集成学习概述 集成学习(Ensemble Learning)是一种通过结合多个模型的预测结果来提高整体预测性能的技术。相比于单个模型…...

【Orca】Orca - Graphlet 和 Orbit 计数算法
Orca(ORbit Counting Algorithm)是一种用于对网络中的小图进行计数的有效算法。它计算网络中每个节点的节点和边缘轨道(4 节点和 5 节点小图)。 orca是一个用于图形网络分析的工具,主要用于计算图中的 graphlets&#…...

58. Three.js案例-创建一个带有红蓝配置的半球光源的场景
58. Three.js案例-创建一个带有红蓝配置的半球光源的场景 实现效果 本案例展示了如何使用Three.js创建一个带有红蓝配置的半球光源的场景,并在其中添加一个旋转的球体。通过设置不同的光照参数,可以观察到球体表面材质的变化。 知识点 WebGLRenderer …...
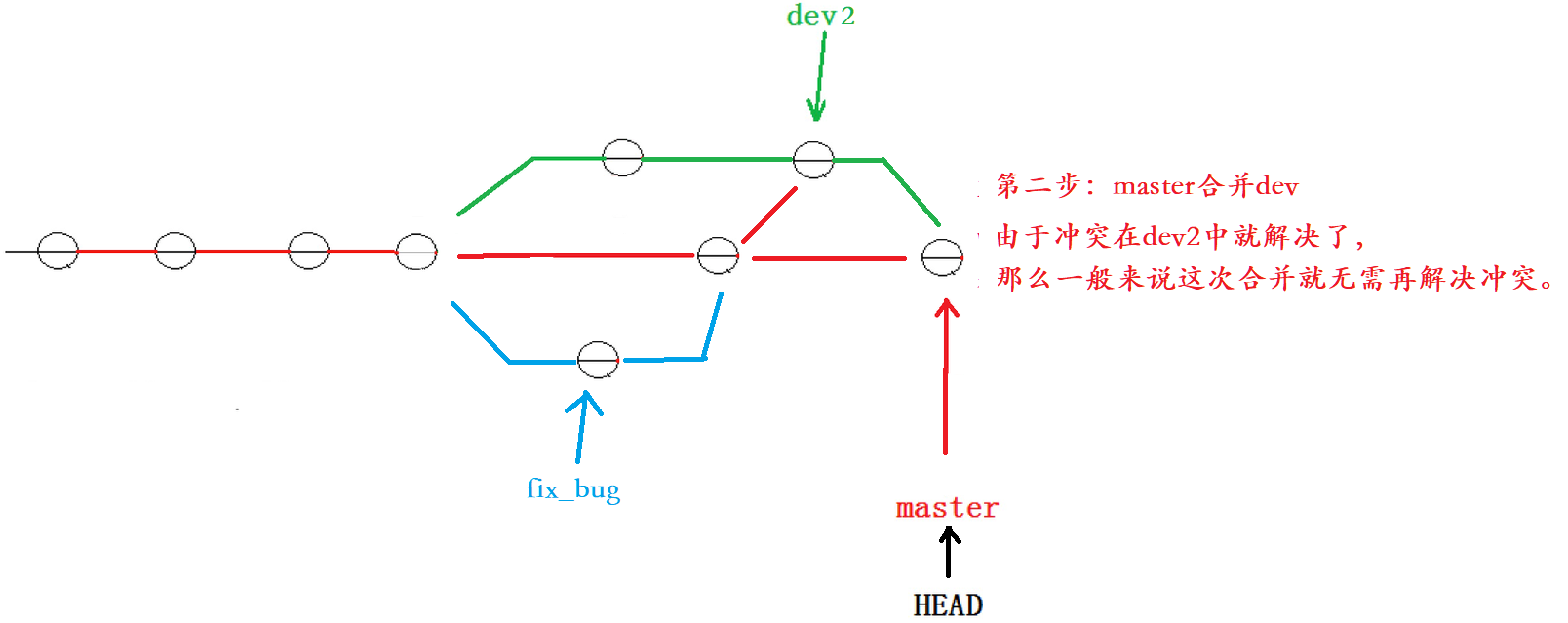
【Git原理和使用】Git 分支管理(创建、切换、合并、删除、bug分支)
一、理解分支 我们可以把分支理解为一个分身,这个分身是与我们的主身是相互独立的,比如我们的主身在这个月学C,而分身在这个月学java,在一个月以后我们让分身与主身融合,这样主身在一个月内既学会了C,也学…...

义乌购的反爬虫机制怎么应对?
在面对义乌购的反爬虫机制时,可以采取以下几种策略来应对: 1. 使用代理IP 义乌购可能会对频繁访问的IP地址进行限制,因此使用代理IP可以有效地隐藏爬虫的真实IP地址,避免被封禁。可以构建一个代理IP池,每次请求时随机…...

消息中间件面试
RabbitMQ 如何保证消息不丢失 消息重复消费 死信交换机 消息堆积怎么解决 高可用机制 Kafka 如何保证消息不丢失 如何保证消息的顺序性 高可用机制 数据清理机制 实现高性能的设计...

基于CLIP和DINOv2实现图像相似性方面的比较
概述 在人工智能领域,CLIP和DINOv2是计算机视觉领域的两大巨头。CLIP彻底改变了图像理解,而DINOv2为自监督学习带来了新的方法。 在本文中,我们将踏上一段旅程,揭示定义CLIP和DINOv2的优势和微妙之处。我们的目标是发现这些模型…...

利用Python爬虫获取API接口:探索数据的力量
引言 在当今数字化时代,数据已成为企业、研究机构和个人获取信息、洞察趋势和做出决策的重要资源。Python爬虫作为一种高效的数据采集工具,能够帮助我们自动化地从互联网上获取大量的数据。而API接口作为数据获取的重要途径之一,为我们提供了…...

【LeetCode】力扣刷题热题100道(1-5题)附源码 链表 子串 中位数 回文子串(C++)
目录 1.两数之和 2.两数相加-链表 3.无重复字符的最长子串 4.寻找两个正序数组的中位数 5.最长回文子串 1.两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。…...

Docker启动失败 - 解决方案
Docker启动失败 - 解决方案 问题原因解决方案service问题 问题 重启docker失败: toolchainendurance:~$ sudo systemctl restart docker Job for docker.service failed because:the control process exited with error codesee:"systemctl status docker.se…...

【Duilib】 List控件支持多选和获取选择的多条数据
问题 使用Duilib库写的一个UI页面用到了List控件,功能变动想支持选择多行数据。 分析 1、List控件本身支持使用SetMultiSelect接口设置是否多选: void SetMultiSelect(bool bMultiSel);2、List控件本身支持使用GetNextSelItem接口获取选中的下一个索引…...

android系统的一键编译与非一键编译 拆包 刷机方法
1.从远程仓库下载源码 别人已经帮我下载好了在Ubuntu上。并给我权限:chmod -R ow /data/F200/F200-master/ 2.按照readme.txt步骤操作 安装编译环境: sudo apt-get update sudo apt-get install git-core gnupg flex bison gperf build-essential z…...

SQL语言的函数实现
SQL语言的函数实现 引言 随着大数据时代的到来,数据的存储和管理变得越来越复杂。SQL(结构化查询语言)作为关系数据库的标准语言,其重要性不言而喻。在SQL语言中,函数是一个重要的组成部分,可以有效地帮助…...

OSPF - 2、3类LSA(Network-LSA、NetWork-Sunmmary-LSA)
前篇博客有对常用LSA的总结 2类LSA(Network-LSA) DR产生泛洪范围为本区域 作用: 描述MA网络拓扑信息和网络信息,拓扑信息主要描述当前MA网络中伪节点连接着哪几台路由。网络信息描述当前网络的 掩码和DR接口IP地址。 影响邻居建立中说到…...

运动相机拍摄的视频打不开怎么办
3-10 GoPro和大疆DJI运动相机的特点,小巧、高清、续航长、拍摄稳定,很多人会在一些重要场合用来拍摄视频,比如可以用来拿在手里拍摄快速运动中的人等等。 但是毕竟是电子产品,有时候是会出点问题的,比如意外断电、摔重…...

SpringBoot | 使用Apache POI库读取Excel文件介绍
关注WX:CodingTechWork 介绍 在日常开发中,我们经常需要处理Excel文件中的数据。无论是从数据库导入数据、处理数据报表,还是批量生成数据,都可能会遇到需要读取和操作Excel文件的场景。本文将详细介绍如何使用Java中的Apache PO…...

从configure.ac到构建环境:解析Mellanox OFED内核模块构建脚本
在软件开发过程中,特别是在处理复杂的内核模块如Mellanox OFED(OpenFabrics Enterprise Distribution)时,构建一个可移植且高效的构建系统至关重要。Autoconf和Automake等工具在此过程中扮演着核心角色。本文将深入解析一个用于准备Mellanox OFED内核模块构建环境的Autocon…...

c#使用SevenZipSharp实现压缩文件和目录
封装了一个类,方便使用SevenZipSharp,支持加入进度显示事件。 双重加密压缩工具范例: using SevenZip; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using System.Threading.…...

【从0带做】基于Springboot3+Vue3的高校食堂点餐系统
大家好,我是武哥,最近给大家手撸了一个基于SpringBoot3Vue3的高校食堂点餐系统,可用于毕业设计、课程设计、练手学习,系统全部原创,如有遇到网上抄袭站长的,欢迎联系博主~ 详细介绍 https://www.javaxm.c…...

2025年01月09日Github流行趋势
1. 项目名称:khoj 项目地址url:https://github.com/khoj-ai/khoj项目语言:Python历史star数:22750今日star数:1272项目维护者:debanjum, sabaimran, MythicalCow, aam-at, eltociear项目简介:你…...

中兴光猫终极破解指南:3步解锁永久Telnet访问权限
中兴光猫终极破解指南:3步解锁永久Telnet访问权限 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 您是否曾经因为中兴光猫的高级功能被限制而感到困扰?无法配置…...

从绿光到深紫外:手把手教你选对BBO、LBO、CLBO晶体,搞定激光倍频实验
从绿光到深紫外:非线性晶体选型与倍频实验实战指南 当实验室的1064nm激光器发出那束熟悉的近红外光时,许多研究者脑海中会立刻浮现两个问题:如何高效获得532nm的翠绿光束?又该如何进一步压缩波长至266nm的深紫外区域?…...

跨平台AI应用开发终极指南:ChatGPT Web Midjourney Proxy移动端适配全解析
跨平台AI应用开发终极指南:ChatGPT Web Midjourney Proxy移动端适配全解析 ChatGPT Web Midjourney Proxy是一款集成ChatGPT、Midjourney和GPTs功能的一站式AI应用,本文将详细解析其移动端适配方案,帮助开发者快速掌握跨平台AI应用的开发技巧…...

Ai会不会让越来越多的开发者失去工作机会?
我不知道写这篇Log会不会太激进,可能会让人浮想联翩,对号入座。想想还是要写的,咱们不聊别的,仅仅是讨论一下AI是否真的会让我们这些写了20多年的代码的开发者失业,这还真是一个“悲伤”的讨论。朋友跟我说:…...

C++虚函数从原理到实践:多态实现、设计模式与性能优化
1. 项目概述:从“魔法”到“利器”的认知转变虚函数,对于很多刚接触C的开发者来说,常常被看作一种“黑魔法”——知道它能实现多态,但具体怎么用、什么时候用、用不好会有什么坑,心里却没底。我见过不少项目࿰…...
)
别再为printf发愁了!华大HC32L13x单片机串口打印的三种实战配置(Keil MDK环境)
华大HC32L13x单片机串口打印的三种高效配置方案 在嵌入式开发中,printf函数作为调试利器,其重要性不言而喻。然而,当您拿到华大HC32L13系列单片机官方SDK,按照常规ARM单片机经验配置printf时,却发现串口毫无反应——这…...

为 OpenClaw 配置 Taotoken 作为自定义 OpenAI 兼容供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 OpenClaw 配置 Taotoken 作为自定义 OpenAI 兼容供应商 OpenClaw 是一个流行的开源 Agent 框架,它允许开发者通过配…...

超越跑分:深入CoreMark源码,看它如何“拷问”RISC-V CPU的三大核心能力
超越跑分:深入CoreMark源码,看它如何“拷问”RISC-V CPU的三大核心能力 在嵌入式处理器性能评估领域,CoreMark早已成为行业标准测试工具。但大多数开发者仅关注最终得分,却鲜少探究这个不足3000行代码的基准测试程序如何精准"…...

深入STM32WLE5的LoRa核心:对比SX126x裸驱与LoRaWAN协议栈,哪个更适合你的项目?
STM32WLE5开发实战:裸驱与LoRaWAN协议栈的深度技术选型指南 当工程师面对STM32WLE5这颗集成了LoRa射频功能的跨界芯片时,第一个需要直面的灵魂拷问往往是:该用寄存器直接操作射频核心,还是拥抱现成的LoRaWAN协议栈?这个…...
)
手把手教你用STM32的编码器模式,精准读取JGB37-520电机转速(附TB6612驱动配置)
基于STM32编码器模式实现JGB37-520电机闭环控制实战指南 在智能硬件开发领域,精确控制电机转速和位置是实现高质量运动控制的基础。JGB37-520作为一款带有霍尔编码器的减速电机,配合TB6612驱动模块,可以构建完整的闭环控制系统。本文将深入解…...