C#,动态规划问题中基于单词搜索树(Trie Tree)的单词断句分词( Word Breaker)算法与源代码

1 分词
分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。英文语句使用空格将单词进行分隔,除了某些特定词,如how many,New York等外,大部分情况下不需要考虑分词问题。但有些情况下,没有空格,则需要好的分词算法。
简单的分词算法主要有:
2 正向最大匹配
从左到右尽可能划分出一段连续字符,使得其等于词典中的某个词,然后将这段连续字符提取出来,对余下的部分进行同样的操作。如果第一个字符不是词典中任何一个词的前缀,那么这个字符单独作为一个词。
3 逆向最大匹配
跟正向最大匹配的唯一不同是从右到左尽可能划分出一段连续字符。
4 双向最大匹配
歧义指对于一个句子有多个分词结果。汉语文本中 90.0%左右的句子,FMM 和 BMM 的切分完全重合且正确,9.0%左右的句子 FMM 和 BMM 切分不同,但其中必有一个是正确的(歧义检测成功),只有不到1.0 %的句子,或者 FMM 和 BMM 的切分虽重合却是错的,或者FMM 和 BMM 切分 不同但两个都不对(歧义检测失败)。
本文介绍了基于单词搜索树(Trie Tree)的单词断句分词( Word Breaker)算法及其源代码。
5 节点信息
public class TrieNode
{public TrieNode[] children { get; set; } = new TrieNode[26];// isEndOfWord is true if the node represents// end of a wordpublic bool isEndOfWord { get; set; } = false;public TrieNode(){isEndOfWord = false;for (int i = 0; i < 26; i++){children[i] = null;}}
}public class TrieNode
{
public TrieNode[] children { get; set; } = new TrieNode[26];
// isEndOfWord is true if the node represents
// end of a word
public bool isEndOfWord { get; set; } = false;
public TrieNode()
{
isEndOfWord = false;
for (int i = 0; i < 26; i++)
{
children[i] = null;
}
}
}

6 字典分词算法
using System;
using System.Text;namespace Legalsoft.Truffer.Algorithm
{public static class Trie_Tree_Word_Breaker{public static void Insert(TrieNode root, string key){TrieNode pCrawl = root;for (int i = 0; i < key.Length; i++){int index = key[i] - 'a';if (pCrawl.children[index] == null){pCrawl.children[index] = new TrieNode();}pCrawl = pCrawl.children[index];}pCrawl.isEndOfWord = true;}public static bool Search(TrieNode root, string key){TrieNode pCrawl = root;for (int i = 0; i < key.Length; i++){int index = key[i] - 'a';if (pCrawl.children[index] == null){return false;}pCrawl = pCrawl.children[index];}return (pCrawl != null && pCrawl.isEndOfWord);}public static bool Word_Break(string str, TrieNode root){int size = str.Length;if (size == 0){return true;}for (int i = 1; i <= size; i++){if (Search(root, str.Substring(0, i)) && Word_Break(str.Substring(i, size - i), root)){return true;}}return false;}public static string Drive(){string[] dictionary = {"mobile", "huawei","sam", "sung", "ma","mango", "icecream","and", "go", "i", "like","ice", "cream" };int n = dictionary.Length;TrieNode root = new TrieNode();// Construct triefor (int i = 0; i < n; i++){Insert(root, dictionary[i]);}StringBuilder sb = new StringBuilder();sb.AppendLine(Word_Break("ilikehuawei", root) + "<br>");sb.AppendLine(Word_Break("iiiiiiii", root) + "<br>");sb.AppendLine(Word_Break("", root) + "<br>");sb.AppendLine(Word_Break("ilikelikeimangoiii", root) + "<br>");sb.AppendLine(Word_Break("huaweiandmango", root) + "<br>");sb.AppendLine(Word_Break("huaweiandmangok", root) + "<br>");return sb.ToString();}}
}using System;
using System.Text;
namespace Legalsoft.Truffer.Algorithm
{
public static class Trie_Tree_Word_Breaker
{
public static void Insert(TrieNode root, string key)
{
TrieNode pCrawl = root;
for (int i = 0; i < key.Length; i++)
{
int index = key[i] - 'a';
if (pCrawl.children[index] == null)
{
pCrawl.children[index] = new TrieNode();
}
pCrawl = pCrawl.children[index];
}
pCrawl.isEndOfWord = true;
}
public static bool Search(TrieNode root, string key)
{
TrieNode pCrawl = root;
for (int i = 0; i < key.Length; i++)
{
int index = key[i] - 'a';
if (pCrawl.children[index] == null)
{
return false;
}
pCrawl = pCrawl.children[index];
}
return (pCrawl != null && pCrawl.isEndOfWord);
}
public static bool Word_Break(string str, TrieNode root)
{
int size = str.Length;
if (size == 0)
{
return true;
}
for (int i = 1; i <= size; i++)
{
if (Search(root, str.Substring(0, i)) && Word_Break(str.Substring(i, size - i), root))
{
return true;
}
}
return false;
}
public static string Drive()
{
string[] dictionary = {
"mobile", "huawei",
"sam", "sung", "ma",
"mango", "icecream",
"and", "go", "i", "like",
"ice", "cream"
};
int n = dictionary.Length;
TrieNode root = new TrieNode();
// Construct trie
for (int i = 0; i < n; i++)
{
Insert(root, dictionary[i]);
}
StringBuilder sb = new StringBuilder();
sb.AppendLine(Word_Break("ilikehuawei", root) + "<br>");
sb.AppendLine(Word_Break("iiiiiiii", root) + "<br>");
sb.AppendLine(Word_Break("", root) + "<br>");
sb.AppendLine(Word_Break("ilikelikeimangoiii", root) + "<br>");
sb.AppendLine(Word_Break("huaweiandmango", root) + "<br>");
sb.AppendLine(Word_Break("huaweiandmangok", root) + "<br>");
return sb.ToString();
}
}
}

相关文章:
C#,动态规划问题中基于单词搜索树(Trie Tree)的单词断句分词( Word Breaker)算法与源代码
1 分词 分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。英文语句使用空格将单词进行分隔,除了某些特定词,如how many,New York等外,大部分情况下不需要考虑分词…...

计算机网络(六)应用层
6.1、应用层概述 我们在浏览器的地址中输入某个网站的域名后,就可以访问该网站的内容,这个就是万维网WWW应用,其相关的应用层协议为超文本传送协议HTTP 用户在浏览器地址栏中输入的是“见名知意”的域名,而TCP/IP的网际层使用IP地…...

上海亚商投顾:沪指探底回升微涨 机器人概念股午后爆发
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 市场全天探底回升,沪指盘中跌超1.6%,创业板指一度跌逾3%,午后集体拉升翻红…...

conda相关操作
conda 是一个开源的包管理和环境管理工具,主要用于 Python 和数据科学领域。它可以帮助用户安装、更新、删除和管理软件包,同时支持创建和管理虚拟环境。以下是关于 conda 的所有常见操作: 1. 安装 Conda Conda 通常通过安装 Anaconda 或 Mi…...
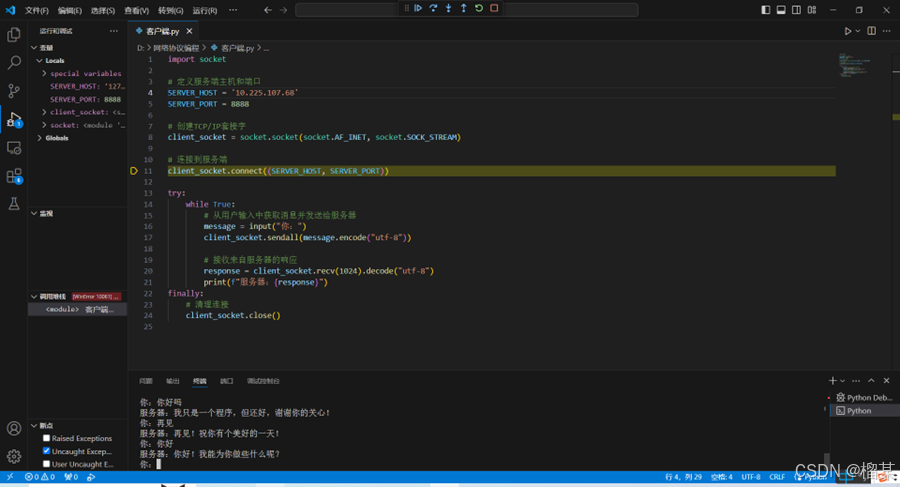
使用TCP协议实现智能聊天机器人
实验目的与要求 本实验是程序设计类实验,要求使用原始套接字编程,掌握TCP/IP协议与网络编程Sockets通信模型,并根据教师给定的任务要求,使用TCP协议实现智能聊天机器人。 (1)熟悉标准库socket 的用法。 …...

PHP二维数组去除重复值
Date: 2025.01.07 20:45:01 author: lijianzhan PHP二维数组内根据ID或者名称去除重复值 代码示例如下: // 假设 data数组如下 $data [[id > 1, name > Type A],[id > 2, name > Type B],[id > 1, name > Type A] // 重复项 ];// 去重方法 $dat…...

2025年01月11日Github流行趋势
项目名称:xiaozhi-esp32 项目地址url:https://github.com/78/xiaozhi-esp32项目语言:C历史star数:2433今日star数:321项目维护者:78, MakerM0, whble, nooodles2023, Kevincoooool项目简介:构建…...

备战蓝桥杯 队列和queue详解
目录 队列的概念 队列的静态实现 总代码 stl的queue 队列算法题 1.队列模板题 2.机器翻译 3.海港 双端队列 队列的概念 和栈一样,队列也是一种访问受限的线性表,它只能在表头位置删除,在表尾位置插入,队列是先进先出&…...

IT面试求职系列主题-Jenkins
想成功求职,必要的IT技能一样不能少,先说说Jenkins的必会知识吧。 1) 什么是Jenkins Jenkins 是一个用 Java 编写的开源持续集成工具。它跟踪版本控制系统,并在发生更改时启动和监视构建系统。 2)Maven、Ant和Jenkins有什么区别…...
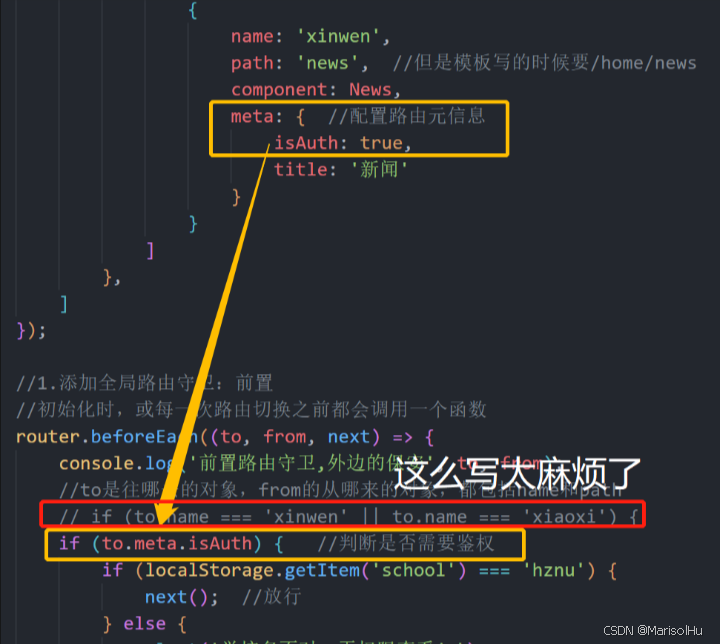
Vue篇-06
1、路由简介 vue-rooter:是vue的一个插件库,专门用来实现SPA应用 1.1、对SPA应用的理解 1、单页 Web 应用(single page web application,SPA)。 2、整个应用只有一个完整的页面 index.html。 3、点击页面中的导航链…...

mysql binlog 日志分析查找
文章目录 前言一、分析 binlog 内容二、编写脚本结果总结 前言 高效快捷分析 mysql binlog 日志文件。 mysql binlog 文件很大 怎么快速通过关键字查找内容 一、分析 binlog 内容 通过 mysqlbinlog 命令可以看到 binlog 解析之后的大概样子 二、编写脚本 编写脚本 search_…...

ubuntu 配置OpenOCD与RT-RT-thread环境的记录
1.git clone git://git.code.sf.net/p/openocd/code openocd 配置gcc编译环境 2. sudo gedit /etc/apt/source.list #cdrom sudo apt-get install git sudo apt-get install libtool-bin sudo apt-get install pkg-config sudo apt-install libusb-1.0-0-dev sudo apt-get…...
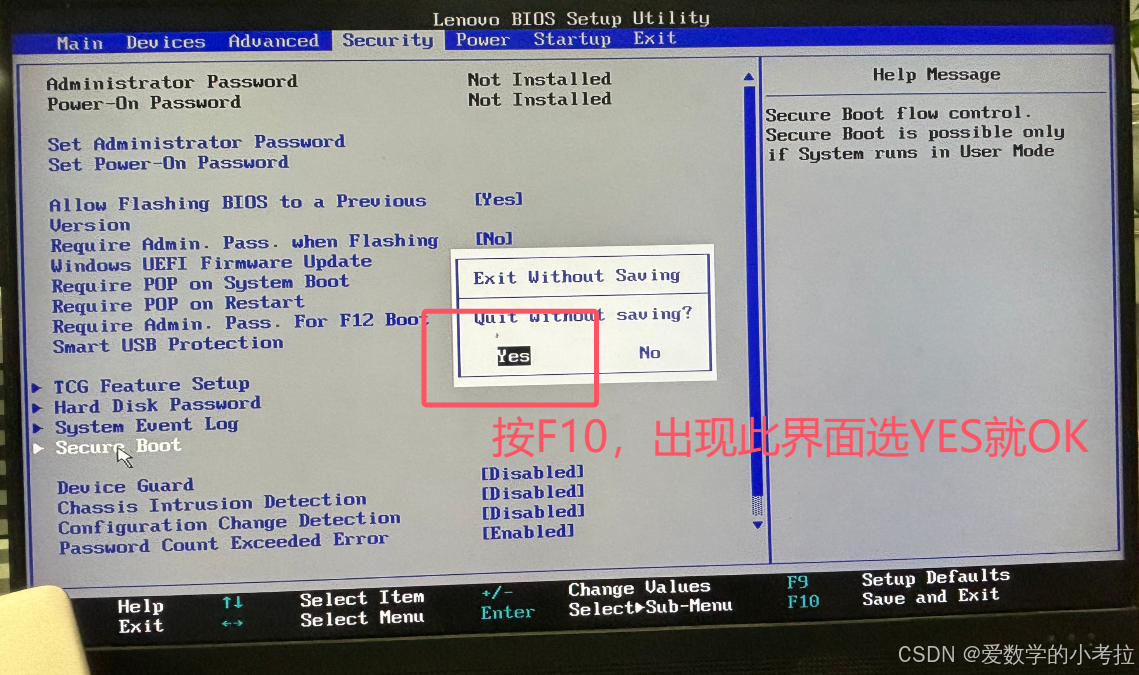
双系统解决开机提示security Policy Violation的方法
最近,Windows系统更新后,发现电脑开机无法进入桌面,显示“Verifiying shim SBAT data failed: security Policy Violation; So mething has gone seriously Wrong: SBAT self-check failed: Security Policy Violation”的英文错误信息。为了…...
的使用场景)
附加共享数据库( ATTACH DATABASE)的使用场景
附加共享数据库(使用 ATTACH DATABASE)的功能非常实用,通常会在以下几种场景下需要用到: 1. 跨数据库查询和分析 场景: 你的公司有两个独立的数据库: 一个存储了学生信息 (school.db)一个存储了员工信息 …...
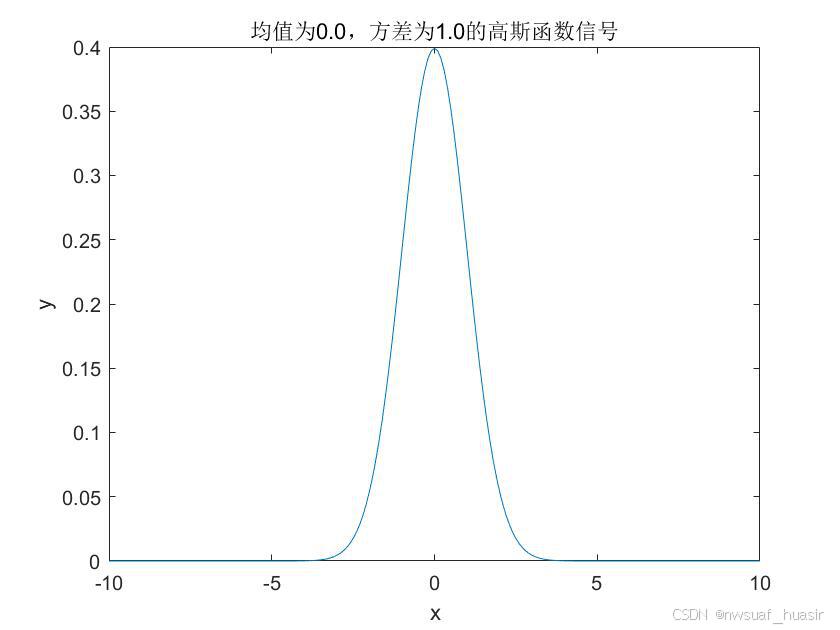
matlab的绘图的标题中(title)添加标量以及格式化输出
有时候我们需要在matlab绘制的图像的标题中添加一些变量,这样在修改某些参数后,标题会跟着一块儿变。可以采用如下的方法: x -10:0.1:10; %x轴的范围 mu 0; %均值 sigma 1; %标准差 y normpdf(x,mu,sigma); %使用normpdf函数生成高斯函数…...

2、第一个GO 程序
引言 接下里我们就用Go Land 工具,开发第一个GO程序。大家也可以用其他的开发工具,例如 Vs Code 1、新建项目 第一个是选择你的程序保存位置 (不要有中文)。 第二个是你的Go的编译器的安装地址。 选择完毕后,就点击 …...

【Linux-多线程】-线程安全单例模式+可重入vs线程安全+死锁等
一、线程安全的单例模式 什么是单例模式 单例模式是一种“经典的,常用的,常考的”设计模式 什么是设计模式 IT行业这么火,涌入的人很多.俗话说林子大了啥鸟都有。大佬和菜鸡们两极分化的越来越严重,为了让菜鸡们不太拖大佬的后…...

00000007_C语言设计模式
C语言设计模式 尽管 C 语言并不直接支持面向对象编程,但通过结构体和函数指针的灵活运用,我们依然可以实现多种经典的设计模式。 1. 工厂模式 1.1 工厂方法的定义与实现 工厂模式通过统一的接口创建对象,客户端无需知道具体的创建逻辑。 代…...

探索数据存储的奥秘:深入理解B树与B+树
key value 类型的数据红黑树(最优二叉树,内存最优),时间复杂度:O(logn),调整方便;一个结点分出两个叉B树一个节点可以分出很多叉数据量相等的条件下:红黑树的层数很高&am…...

Web渗透测试之XSS跨站脚本之JS输出 以及 什么是闭合标签 一篇文章给你说明白
目录 闭合标签 XSS之js输出 闭合标签 封闭标签 达到 让标签值不当成 一个属性值来展示 从而达到xss注入的效果 "> 为了想办法闭合前面的标签,不用也行成功率高一些 攻击方法 "><script>confirm(1)</script>, 其中 "> 我们称之为完成闭合…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析
D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 当…...

OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS
OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹…...

开源合规生死线,DeepSeek协议识别错误率高达63%?2024企业级扫描避坑清单全公开
更多请点击: https://intelliparadigm.com 第一章:开源合规生死线,DeepSeek协议识别错误率高达63%?2024企业级扫描避坑清单全公开 近期第三方审计机构对主流AI增强型开源扫描工具开展交叉验证测试,结果显示DeepSeek-R…...