数据结构初阶---排序
一、排序相关概念与运用
1.排序相关概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
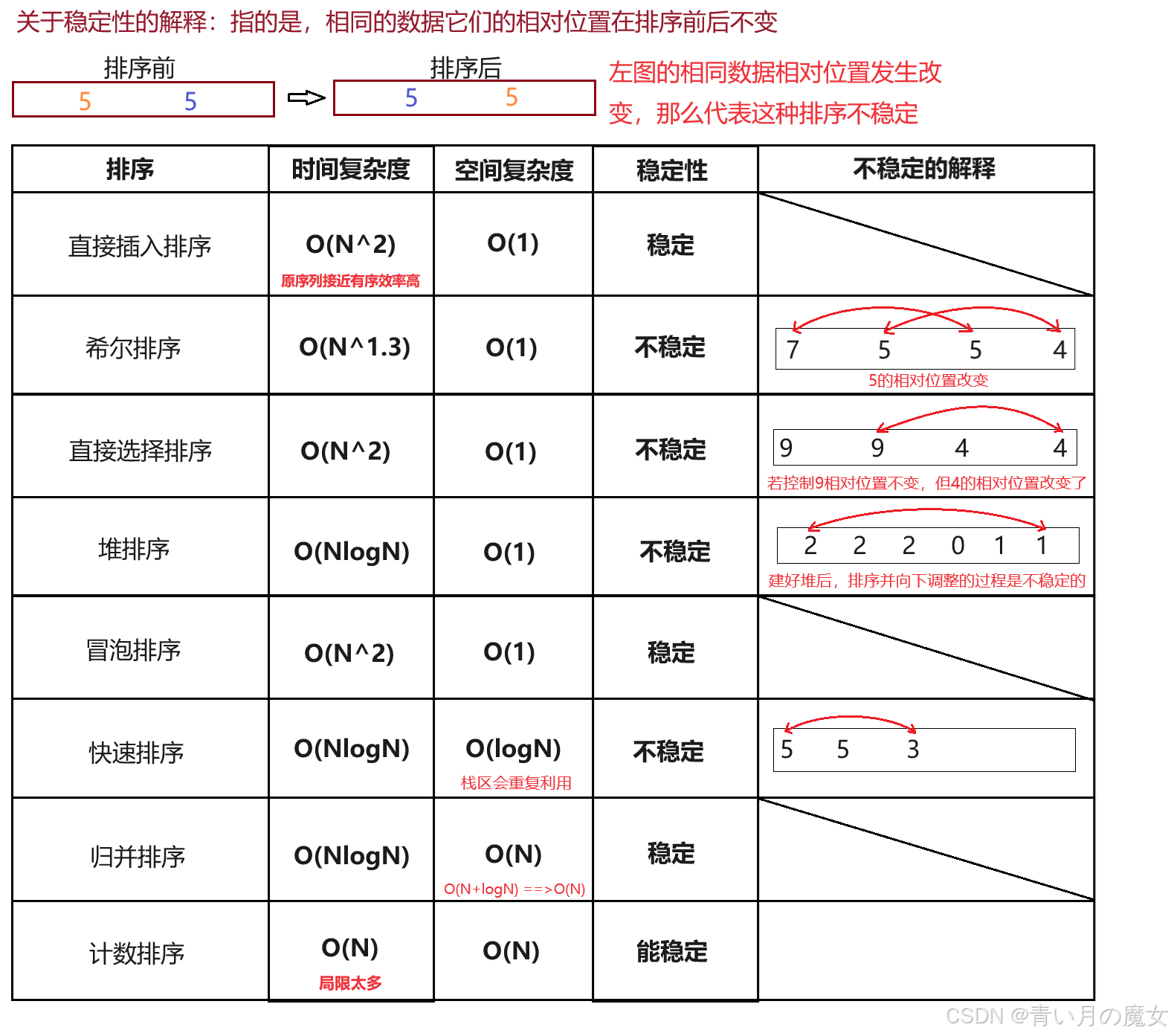
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
2.排序的运用
如下图:

3.排序算法

二、常见排序算法的实现
排序实现建议--->先单趟再多趟,先局部再整体
1.插入排序
①直接插入排序
void InsertSort(int* a, int size);
思想:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
我们生活中所玩的扑克牌,当一副牌拿在手中,会习惯性的将牌有序排列,每次抽牌将其排列到手中牌组中的这个排序过程,就是一个直接插入排序。


由于插入数据之前需要保持数组有序,因此从下标0开始进行判断,创建一个end变量,end+1处的数据为插入数据,那么我们需要保证[0,end]数组为有序的。然后进行直接插入排序。
每次插入的数据不管是否需要排序,都在end+1的位置上。
插入排序的适应性很强,看起来是等差数列,O(N^2),实际上只要不是严格的逆序,插入排序就不会达到等差数列。
//插入排序---直接插入排序
//时间复杂度O(N^2) --- 等差数列
//最好情况下复杂度O(N)
//对接近有序、有序的效率高
void InsertSort(int* a, int size)
{//从头开始排序for (int i = 0; i < size - 1; i++){//每次插入的排序int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
} 直接插入排序的时间复杂度为O(N^2),最好情况下为O(N)。
直接插入排序的时间复杂度为O(N^2),最好情况下为O(N)。
对于直接插入排序而言,对于接近有序或者就是目标有序的数组而言,是非常方便且高效的。(后续的希尔排序正是在这一点上对直接插入排序进行了改进)
对完全逆序的数组进行直接插入排序才会得到O(N^2)的时间复杂度。
直接插入排序与冒泡排序的时间复杂度都是O(N^2),但是这只能说明两者在同一量级,不能说明两者一样好,直接插入排序的效率还是高于冒泡排序的。希尔排序就更高了。
②希尔排序
希尔排序,在直接插入排序的基础上进行了改变。
两个步骤:一:预排序--->得到一个接近有序的数组;二、直接插入排序--->得到有序数组
如何预排序呢?希尔排序通过一个间隔值gap对数组数据进行分组。间隔gap的所有数据分为一组,那么一共就会分为gap组。例如:数组有10个数据,间隔gap为3,那么下标0、3、6、9为一组、下标1、4、7为一组、下标2、5、8为一组。将10个数据分为了3组。
那么这三组数据,对每一组进行直接插入排序,就会将每一组较大数据置于组尾,小数置于组头,就会得到一个接近有序的数组。
再将接近有序的数组进行一次直接插入排序就完成了希尔排序。

//插入排序---希尔排序
//思路:两步,①间隔gap分组预排序---目的,接近有序
// ②直接插入排序---目的,有序
//希尔排序的时间复杂度很难计算,平均下来是O(N^1.3)
void ShellSort(int* a, int size)
{int gap = size;while (gap > 1){gap /= 2;//或者 gap = gap/3 + 1; 目的是保证最后一次是gap == 1,即直接插入排序//多组并排---不需要int j的三层循环了for (int i = 0; i < size - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
希尔排序的时间复杂度非常复杂,大致为O(N^1.3),略慢于O(N*logN)。
2.选择排序
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
①直接选择排序
void SelectSort(int* a, int size);

一般的选择排序,选出最小数据然后置于序列头部,但是我们可以从两头同时选出最小数据与最大数据。
创建maxi、mini用于存储每一趟的最大数据与最小数据的下标,begin、end记录每一趟的开始位置与结束位置(下标)。具体思路如下图所示。

//选择排序---直接选择排序
//时间复杂度O(N^2)
//最好情况下O(N^2)
void SelectSort(int* a, int size)
{int begin = 0;int end = size - 1;while( begin < end ){int mini = begin;int maxi = begin;for (int i = begin; i <= end; i++){if (a[i] < a[mini])mini = i;if (a[i] > a[maxi])maxi = i;}Swap(&a[end], &a[maxi]);if (mini == end)mini = maxi;//防止最小数据下标在maxi位置,前一步交换会改变最小数据的位置Swap(&a[begin], &a[mini]);begin++;end--;}
}
直接选择排序的时间复杂度为O(N^2)。N-2的等差数列,不管是否有序,都会遍历。
因此最好情况下时间复杂度依然为O(N^2)。
②堆排序
void HeapSort(int* a, int size);
详解参考二叉树有关堆的内容。
升序==>建大堆、选择排序。
降序==>建小堆、选择排序。
选择排序阶段即利用堆的性质,将堆顶数据与数组末尾数据交换并重新进行堆顶数据的向下调整。

//向下调整算法O(logN)
void AdjustDown(int* a, int size, int parent)
{int child = 2 * parent + 1;while (child < size){if (child + 1 < size && a[child] < a[child + 1]){child++;}if (a[parent] < a[child]){Swap(&a[child], &a[parent]);parent = child;child = child * 2 + 1;}elsebreak;}
}//选择排序---堆排序
//升序建大堆
//时间复杂度O(N*logN)
void HeapSort(int* a, int size)
{//O(logN)for (int i = (size - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, size, i);}//O(N*logN)for(int i=size-1;i>=0;i--){Swap(&a[0], &a[i]);AdjustDown(a, i, 0);}
} 堆排序的时间复杂度为O(N*logN)。
堆排序的时间复杂度为O(N*logN)。
3.交换排序
①冒泡排序

//交换排序---冒泡排序
//时间复杂度O(N^2)---等差数列
//最好情况O(N)---接近有序或者有序
void BubbleSort(int* a, int size)
{//趟次for (int j = 0; j < size; j++){bool exchange = false;//每一趟内的冒泡排序for (int i = 0; i < size - 1 - j; i++){if (a[i] > a[i + 1]){Swap(&a[i], &a[i + 1]);exchange = true;}}//for (int i = 1; i < size - j; i++)//{// if (a[i] > a[i - 1])// {// Swap(&a[i], &a[i - 1]);// exchange = true;// }//}//如果是false说明原数列升序 if (exchange == false)break;}
}冒泡排序时间复杂度O(N^2)。
对于接近有序或者有序的数组,是冒泡排序的最好情况,O(N)。
②快速排序
递归快排的三种方法
[I]Hoare法

给出一个关键字key,keyi代表关键字数据的下标,创建两个下标变量left与right,right处于序列尾,left处于序列头,right先遍历,寻找比关键字key小的数据并停止遍历,left后遍历,寻找比关键字key大的数据并停止遍历,二者停止后交换二者位置处的数据,即将比key小的数据置于数组左侧,大的数据置于数组右侧,继续循环直到left与right相遇停止,然后交换关键字数据和相遇位置数据,就将key数据置于了一个正确的排序位置,最后更改下标keyi为相遇位置。
以上就完成了一趟快速排序,完成了对一个关键字key的正确位置放置。那么对于快速排序而言,排好了该关键字后,就将整个数组拆分为了三部分:[begin , keyi - 1] keyi [keyi + 1 , end]。前后两部分又是重复上述快速排序操作,因此可以使用递归简单的写出快速排序:
这就是Hoare法的冒泡排序:
//快速排序(递归)
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;//三数取中int midi = GetMidi(a, begin, end);Swap(&a[midi], &a[begin]);int keyi = PartSort1(a, begin, end);//三种思路---Hoare、挖坑和前后指针//将数组分为3部分---[begin , keyi-1] keyi [keyi+1 , end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}//Hoare法
int PartSort1(int* a, int begin, int end)
{int keyi = begin;int left = begin;int right = end;while (left < right){//先右边找大while (left < right && a[right] >= a[keyi]){right--;}//再左边找小while (left < right && a[left] <= a[keyi]){left++;}//都需要满足left<right的条件Swap(&a[left], &a[right]);}//将keyi处数据移动到正确排序位置Swap(&a[left], &a[keyi]);keyi = left;return left;
}如果每次的关键字正确位置不在中间,而是在两侧,那么会导致快速排序的效率降低!约O(N^2),因此我们需要使用一些操作来弥补这一个缺陷,那么就有三数取中的方法,取begin与end中间值mid,找出三个下标对应的数据中,中间大小的数据,将其与begin处数据交换,这样keyi虽然仍然是begin,但是数据却得到了改变,提高了快速排序的效率。
int midi = GetMidi(a, begin, end);int keyi = begin;Swap(&a[midi], &a[begin]);//三数取中
int GetMidi(int* a ,int begin, int end)
{int midi = (begin + end) / 2;if (a[begin] > a[end]){if (a[end] > a[midi])return end;else{if (a[begin] > a[midi])return midi;elsereturn begin;}}else{if (a[end] < a[midi])return end;else{if (a[begin] < a[midi])return midi;elsereturn begin;}}
}
另一种优化方式是,对于区间大小小于10(自取,不要过大)的区间,有几个数据就会采取几次递归,效率低下,可以使用直接插入排序进行优化:
//小区间优化if (end - begin + 1 <= 10)InsertSort(a + begin, end - begin + 1);//小区间不多次使用递归,而采用直接插入排序进行排序[II]挖坑法
递归的快速排序,第二种方法是挖坑法,在Hoare法的基础上,对其进行优化:

现将key位置作为坑位,右下标变量right向左遍历找小,找到放入坑位,然后坑位hole变为此时的right位置,接着左下标变量left向右遍历找大,找到放入坑位,坑位hole变为此时的left位置,循环直到left与right相遇,此时将hole下标处的数据置为key,完成一趟快速排序:
//快速排序(递归)
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;//三数取中int midi = GetMidi(a, begin, end);Swap(&a[midi], &a[begin]);int keyi = PartSort2(a, begin, end);//三种思路---Hoare、挖坑和前后指针//将数组分为3部分---[begin , keyi-1] keyi [keyi+1 , end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}//挖坑法
int PartSort2(int* a, int begin, int end)
{//排序int key = a[begin];int left = begin;int right = end;int hole = begin;while (left < right){//先右边找大,填到左边的坑中while (left < right && a[right] >= key){right--;}a[hole] = a[right];hole = right;//再左边找小,填到右边的坑中while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}[III]前后指针法
创建prev与cur下标变量,使用cur进行数组遍历,当cur处数据小于key时,prev自增1并交换prev与cur下标,最后cur++;当cur处数据大于key时,cur++,prev不做处理。


//快速排序(递归)
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;//三数取中int midi = GetMidi(a, begin, end);Swap(&a[midi], &a[begin]);int keyi = PartSort3(a, begin, end);//三种思路---Hoare、挖坑和前后指针//将数组分为3部分---[begin , keyi-1] keyi [keyi+1 , end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}//前后指针cur、prev法
//prev指向begin,cur指向begin下一个
//思路:cur遍历,遇到小于key的数据,prev++然后交换二者,cur++
// 遇到大于key的数据,cur++,prev不变
int PartSort3(int* a, int begin, int end)
{int prev = begin;int cur = begin + 1;int keyi = begin;while (cur <= end){if (a[cur] < a[keyi]){Swap(&a[++prev], &a[cur]);}cur++;//也可以这么写//if (a[cur] < a[keyi] && ++prev != cur)// Swap(&a[prev], &a[cur]);//cur++;}Swap(&a[keyi], &a[prev]);keyi = prev;return prev;
}我们需要注意的是,三种递归快排的方法,中间趟数的排序结果是不同的!因此,在面对一些选择题时,需要去判断题目中所使用到的快排的方法!
快速排序的非递归方法
借助栈的数据结构,采取压栈的形式对下标进行划分以及数据排序。

//快速排序(非递归)
//递归-->非递归的两种方式:1.循环 2.借助栈(循环不能很好解决时)
void QuickSortNonR(int* a, int begin , int end)
{AS as;AStackInit(&as);AStackPush(&as, begin);AStackPush(&as, end);while (!AStackEmpty(&as)){int right = AStackTop(&as);AStackPop(&as);int left = AStackTop(&as);AStackPop(&as);//这里我们选择了右先压栈,左后压栈int keyi = PartSort3(a, left, right);//[left , keyi - 1] keyi [keyi + 1 , right]if(left < keyi - 1){//前面选择左后压栈,这里就得先左侧压栈AStackPush(&as, left);AStackPush(&as, keyi - 1);}if (keyi + 1 < right){AStackPush(&as, keyi + 1);AStackPush(&as, right);}}AStackDestroy(&as);
}4.归并排序

前面学到的顺序表两个有序数组的合并,其实就是一个归并的过程,那么如果给我们一个数组,怎么将其转换为两个或多个有序数组来进行合并呢?
我们可以递归将数组划分为多个区间,每个区间尽可能小的时候,如1个数据,区间长度为1时,就可以排该区间,那么从划分的最底层的小区间开始,逐步向上进行排序,就能够完成归并排序。
这样的思路,我们很容易联想到后序遍历,所以递归顺序是与后续遍历相同的。

我们在堆区开辟与原数组同样大小的一块空间,将排好序的数据存入到空间中,将其拷贝到原数组中,最后释放空间。
void _MergeSort(int* a, int begin, int end, int* tmp)
{if (begin >= end)return;int mid = (begin + end) / 2;//区间[begin , mid][mid+1 , end]//类后序遍历_MergeSort(a, begin, mid, tmp);_MergeSort(a, mid + 1, end, tmp);//归并操作int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[i++] = a[begin1++];elsetmp[i++] = a[begin2++];}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//将tmp中所有数据拷贝到数组a中memcpy(a + begin, tmp + begin, sizeof(a[0]) * (end - begin + 1));
}//归并排序
//归并排序,两个数组有序,将其合并为一个有序数组,那么如何确保分开的两个区间有序呢?一直分就可以了
void MergeSort(int* a, int size)
{int* tmp = (int*)malloc(sizeof(a[0]) * size);if (tmp == NULL){perror("malloc fail");}_MergeSort(a, 0, size - 1, tmp);free(tmp);tmp = NULL;
}非递归的归并排序
递归的归并排序,将数组划分为小区间,使每个小区间归并有序,是逐步向下递归划分并排序的,但是对于非递归的归并排序而言,如果采用栈或者队列的数据结构,类似快速排序的非递归实现,是比较困难的,因为就算压栈,对于一趟快排能够锁定一个数据的正确位置,但是归并排序并不可以,因为采取栈或者队列模拟递归过程,并没有由小区间往回归并的过程,只有划分小区间并排序的过程,因此不适用于非递归的归并排序。
那么对于非递归的归并排序,我们可以直接进行划分,从1个数据开始归并,到2个数据归并,一直到N/2个数据与N/2个数据归并最后结束。

//归并排序---非递归
//递归的归并排序是递归到每个小区间进行归并,非递归直接拆分区间归并
void MergeSortNonR(int* a, int size)
{int* tmp = (int*)malloc(sizeof(int) * size);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;//gap是每一组的个数,每一组跟后一组进行归并while (gap < size){for (int i = 0; i < size; i += gap * 2){int begin1 = i, end1 = i + gap - 1;//[a,b]长度为b-a+1 ===>b = a+长度-1int begin2 = i + gap, end2 = i + gap + gap - 1;if (end1 >= size || begin2 >= size)break;if (end2 >= size)end2 = size - 1;//[begin1 , end1][begin2 , end2]归并int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2])tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}free(tmp);tmp = NULL;
}Extra.外排序与内排序
内排序:内存中排序
外排序:磁盘中排序
上面所讲到的插入排序(直接插入排序、希尔排序)、选择排序(直接选择排序、堆排序)、交换排序(冒泡排序、快速排序)、归并排序都是内排序。
归并排序同时也是外排序。
归并排序是内排序时,从小区间依次排序,外排序时,如果基数特别大,如10亿整数排序,则取1G的数据量置入内存使用希尔/快速/堆排序进行排序,使该数据量有序,将10亿整数拆分成多个有序的1G的数据序列,利用归并排序进行排序。
5.计数排序
计数排序没有用到比较的思想,而是将需要排序的数组的数据使用另一个数组进行计数,两个数组依靠待排序数组的数据与count数组的下标的相对位置从而形成对应,对于计数排序而言,时间复杂度很低可至O(N),但是局限性也不少。

计数排序的时间复杂度O(N+Range)、空间复杂度O(Range)。
计数排序效率极高,但是不适合于分散的数据,适合集中的数据;同时不适合浮点数、字符串、结构体数据的排序,只适合于整数的排序。
排序总结
相关文章:
数据结构初阶---排序
一、排序相关概念与运用 1.排序相关概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的…...
【从0-1实现一个前端脚手架】
目录 介绍为什么需要脚手架?一个脚手架应该具备哪些功能? 脚手架实现初始化项目相关依赖实现脚手架 发布 介绍 为什么需要脚手架? 脚手架本质就是一个工具,作用是能够让使用者专注于写代码,它可以让我们只用一个命令…...
AI文章管理系统(自动生成图文分发到分站)
最近帮一个网上的朋友做了一套AI文章生成系统。他的需求是这样: 1、做一个服务端转接百度文心一言的生成文章的API接口。 2、服务端能注册用户,用户在服务端注册充值后可以获取一个令牌,这个令牌填写到客户端,客户端就可以根据客…...

【Leetcode 每日一题】3270. 求出数字答案
问题背景 给你三个 正 整数 n u m 1 num_1 num1, n u m 2 num_2 num2 和 n u m 3 num_3 num3。 数字 n u m 1 num_1 num1, n u m 2 num_2 num2 和 n u m 3 num_3 num3 的数字答案 k e y key key 是一个四位数,定义如下&…...
基于单片机的无线气象仪系统设计(论文+源码)
1系统方案设计 如图2.1所示为无线气象仪系统设计框架。系统设计采用STM32单片机作为主控制器,结合DHT11温湿度传感器、光敏传感器、BMP180气压传感器、PR-3000-FS-N01风速传感器实现气象环境的温度、湿度、光照、气压、风速等环境数据的检测,并通过OLED1…...

【数据库】Mysql精简回顾复习
一、概念 数据库(DB):数据存储的仓库数据库管理系统(DBMS):操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,是一套标准关系型数据库(RDBMS)&…...

深入理解 HTTP 的 GET、POST 方法与 Request 和 Response
HTTP 协议是构建 Web 应用的基石,GET 和 POST 是其中最常用的请求方法。无论是前端开发、后端开发,还是接口测试,对它们的深入理解都显得尤为重要。在本文中,我们将介绍 GET 和 POST 方法,以及 Request 和 Response 的…...

MySQL 中联合索引相比单索引性能提升在哪?
首先我们要清楚所以也是要占用磁盘空间的,随着表中数据量越来越多,索引的空间也是随之提升的,因而单表不建议定义过多的索引,所以使用联合索引可以在一定程度上可以减少索引的空间占用其次,使用联合索引的情况下&#…...
第34天:安全开发-JavaEE应用反射机制攻击链类对象成员变量方法构造方法
时间轴: Java反射相关类图解: 反射: 1、什么是 Java 反射 参考: https://xz.aliyun.com/t/9117 Java 提供了一套反射 API ,该 API 由 Class 类与 java.lang.reflect 类库组成。 该类库包含了 Field 、 Me…...

C++笔记之数据单位与C语言变量类型和范围
C++笔记之数据单位与C语言变量类型和范围 code review! 文章目录 C++笔记之数据单位与C语言变量类型和范围一、数据单位1. 数据单位表:按单位的递增顺序排列2. 关于换算关系的说明3. 一般用法及注意事项4. 扩展内容5. 理解和使用建议二、C 语言变量类型和范围基本数据类型标准…...

算法-拆分数位后四位数字的最小和
力扣题目2160. 拆分数位后四位数字的最小和 - 力扣(LeetCode) 给你一个四位 正 整数 num 。请你使用 num 中的 数位 ,将 num 拆成两个新的整数 new1 和 new2 。new1 和 new2 中可以有 前导 0 ,且 num 中 所有 数位都必须使用。 …...

Python 管理 GitHub Secrets 和 Workflows
在现代软件开发中,自动化配置管理变得越来越重要。本文将介绍如何使用 Python 脚本来管理 GitHub 仓库的 Secrets 和 Workflows,这对于需要频繁更新配置或管理多个仓库的团队来说尤为有用。我们将分三个部分进行讨论:设置 GitHub 权限、创建 GitHub Secret 和创建 GitHub Wo…...

指令的修饰符
指令的修饰符 参考文献: Vue的快速上手 Vue指令上 Vue指令下 Vue指令的综合案例 文章目录 指令的修饰符指令修饰符 结语 博客主页: He guolin-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力&…...

C# 正则表达式完全指南
C# 正则表达式完全指南 C#通过 System.Text.RegularExpressions 命名空间提供强大的正则表达式支持。本指南将详细介绍C#中正则表达式的使用方法、性能优化和最佳实践。 1. 基础知识 1.1 命名空间导入 using System.Text.RegularExpressions;1.2 基本使用 public class Re…...

【笔记整理】记录参加骁龙AIPC开发者技术沙龙的笔记
AIoT 首先了解了一个概念叫AIoT,我的理解就是AI IoT 5G,通过AI的发展使得边缘计算、数据整合和处理变得快捷方便,不仅限于传统的云端数据处理,在边缘的IoT设备上也可以进行智能化打造,通过5G的通信能力扩展可以实现…...

论文解析 | 基于语言模型的自主代理调查
论文 《A Survey on Large Language Model-based Autonomous Agents》 对基于大型语言模型(LLM)的自主智能体(Autonomous Agents)进行了全面调查。随着大型语言模型(如 GPT 系列、BERT、T5 等)的快速发展&a…...

面试加分项:Android Framework AMS 全面概述和知识要点
第一章:AMS 的架构与组件 1.1 AMS 整体架构 在 Android 系统的庞大体系中,AMS(Activity Manager Service)就如同一个中枢神经系统,是整个系统的核心服务之一,对应用的性能和用户体验有着直接且关键的影响 。它的整体架构由 Client 端和 Service 端两大部分组成,这两端相…...

EasyCVR视频汇聚平台如何配置webrtc播放地址?
EasyCVR安防监控视频系统采用先进的网络传输技术,支持高清视频的接入和传输,能够满足大规模、高并发的远程监控需求。平台支持多协议接入,能将接入到视频流转码为多格式进行分发,包括RTMP、RTSP、HTTP-FLV、WebSocket-FLV、HLS、W…...

用户界面软件04
后果 使用这种架构很容易对两个层面的非功能性需求进行优化,但是你仍然需要小心不要将功能 需求重复实现。 现在,两个层面可能有完全不同的设计。比如,用户界面层可能使用配件模型(Widget Model), 以大量的…...

C#,数值计算,矩阵相乘的斯特拉森(Strassen’s Matrix Multiplication)分治算法与源代码
Volker Strassen 1 矩阵乘法 矩阵乘法是机器学习中最基本的运算之一,对其进行优化是多种优化的关键。通常,将两个大小为N X N的矩阵相乘需要N^3次运算。从那以后,我们在更好、更聪明的矩阵乘法算法方面取得了长足的进步。沃尔克斯特拉森于1…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

国产麒麟系统上编译GDAL 3.2.1踩坑记:从PROJ6依赖缺失到Qt环境集成
麒麟系统GDAL 3.2.1编译实战:PROJ6依赖修复与Qt工程深度集成在国产操作系统生态中部署地理数据处理工具链,往往会遇到比常规Linux发行版更复杂的依赖问题。最近在麒麟系统上为北斗定位项目编译GDAL 3.2.1时,遭遇了经典的"PROJ 6 symbols…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

基于ISDN信令的来电语音播报系统:从原理到树莓派实现
1. 项目概述:一个基于ISDN的来电语音播报系统如果你家里或办公室里还有一台老式的ISDN路由器,别急着把它当电子垃圾处理掉。我最近就利用手头一台闲置的ISDN路由器,折腾出了一个挺有意思的小玩意儿:一个能自动识别来电号码&#x…...