【杂谈】-50+个生成式人工智能面试问题(四)
7、生成式AI面试问题与微调相关
Q23. LLMs中的微调是什么?
答案:虽然预训练语言模型非常强大,但它们并不是任何特定任务的专家。它们可能对语言有惊人的理解能力,但仍需要一些LLMs微调过程,开发者通过这个过程提升它们在情感分析、语言翻译或回答特定领域问题等任务中的表现。微调大型语言模型是解锁其全部潜力并将能力定制到特定应用的关键。
微调就像给这些多功能模型做最后的润色。想象一下,你有一个多才多艺的朋友,他在各个领域都很出色,但你希望他在一个特殊场合掌握一项特定的技能。你会给他在该领域提供一些特定的培训,对吧?这正是我们在微调过程中对预训练语言模型所做的。
Q24. 为什么需要对LLMs进行微调?
答案:虽然预训练语言模型非常了不起,但它们默认不是针对特定任务的。微调大型语言模型是将通用模型调整为更精确和高效地执行专门任务的过程。当我们遇到像客户评论的情感分析或特定领域的问答这样的特定NLP任务时,我们需要对预训练模型进行微调,使其理解该特定任务和领域的细微差别。
微调的好处是多方面的。首先,它利用了预训练期间学到的知识,节省了大量时间和计算资源,否则需要从头开始训练模型。其次,微调使我们能够在特定任务上表现更好,因为模型现在适应了它被微调的领域的复杂性和细微差别。
Q25. 微调和训练LLMs之间有什么区别?
答案:微调是模型训练中使用的一种技术,与初始参数设置的预训练不同。预训练从随机初始化模型参数开始,并在两个阶段迭代进行:前向传播和反向传播。传统的监督学习(SSL)用于计算机视觉任务的预训练模型,如图像分类、物体检测或图像分割。
LLMs通常通过自监督学习(SSL)进行预训练,使用前置任务从未标记数据中提取真实标签。这允许使用大量数据集而无需标注数百万或数十亿数据点,节省了劳动力但需要大量的计算资源。微调包括进一步训练模型的技术,其权重已通过先前的训练更新,以适应较小的、特定任务的数据集。这种方法提供了两全其美的优势,既利用了大规模数据预训练中获得的广泛知识和稳定性,又提高了模型对更详细概念的理解。
Q26. 微调有哪些不同类型?
答案:生成式AI中的微调方法如下:
1)监督微调
在特定目标任务的标记数据集上训练模型。例如:在带有相应情感标签的文本样本数据集上训练情感分析模型。
- 迁移学习:
- 允许模型执行与初始任务不同的任务。
- 利用来自大型通用数据集的知识进行更具体的任务。
- 领域特定微调:
- 使模型适应理解和生成特定领域或行业特有的文本。例如:使用医疗记录训练的医疗应用聊天机器人,以适应健康领域的语言理解能力。
2)参数高效微调(PEFT)
参数高效微调(PEFT)是一种通过仅更新少量参数来优化大规模预训练语言模型微调过程的方法。传统的微调需要调整数百万甚至数十亿个参数,这在计算上非常昂贵且资源密集。PEFT技术,如低秩适应(LoRA)、适配器模块或提示调整,允许显著减少可训练参数的数量。这些方法引入额外的层或修改模型的特定部分,使得在较低的计算成本下仍能实现针对特定任务的高性能。这使得微调对于计算资源有限的研究人员和从业者更为可行和高效。
3)监督微调(SFT)
监督微调(SFT)是使用标记数据集细化预训练语言模型以执行特定任务的关键过程。与依赖大量未标记数据的无监督学习不同,SFT使用已知正确输出的数据集,使模型能够学习从输入到输出的精确映射。这个过程涉及从一个预训练模型开始,该模型已经从大量文本语料库中学习了通用语言特征,然后用任务特定的标记数据对其进行微调。这种方法利用了预训练模型的广泛知识,同时使其适应于特定任务,如情感分析、问答或命名实体识别。SFT通过提供正确输出的明确示例来提高模型的性能,从而减少错误并提高准确性和鲁棒性。
4)人类反馈的强化学习(RLHF)
人类反馈的强化学习(RLHF)是一种高级机器学习技术,将人类判断纳入强化学习模型的训练过程中。与传统的强化学习依赖于预定义的奖励信号不同,RLHF利用来自人类评估者的反馈来指导模型的行为。这种方法对于复杂或主观的任务特别有用,在这些任务中很难用编程方式定义奖励函数。通常通过让人类评估模型的输出并提供分数或偏好来收集人类反馈。然后使用此反馈更新模型的奖励函数,使其更符合人类价值观和期望。根据更新后的奖励函数对模型进行微调,根据人类提供的标准迭代改进其性能。RLHF有助于产生技术上熟练且符合人类价值观和伦理考量的模型,使它们在现实应用中更加可靠和可信。
Q27. 什么是PEFT LoRA微调?
答案:参数高效微调(PEFT)是一种减少适应大型预训练模型到特定下游应用所需可训练参数数量的方法。PEFT显著减少了计算资源和内存存储需求,以产生有效微调的模型,使其比完整微调方法更稳定,特别是在自然语言处理(NLP)用例中。
部分微调,也称为选择性微调,旨在通过仅更新对相关下游任务性能最关键的一部分预训练参数来降低计算需求。其余参数被“冻结”,确保它们不会被改变。一些部分微调方法包括仅更新模型的层宽偏置项以及稀疏微调方法,这些方法只更新模型中整体权重的选定子集。
加法微调向模型添加额外的参数或层,冻结现有的预训练权重,仅训练这些新组件。这种方法通过确保原始预训练权重保持不变来帮助保持模型的稳定性。虽然这可能会增加训练时间,但它显著减少了内存需求,因为要存储的梯度和优化状态远少于全部参数。通过对冻结模型权重进行量化,可以进一步节省内存。
适配器在神经网络中注入新的、特定任务的层,并训练这些适配器模块,而不是微调任何预训练模型权重。基于重新参数化的方法,如低秩适应(LoRA),利用高维矩阵的低秩变换来捕获模型权重的底层低维结构,大大减少了可训练参数的数量。LoRA避免了直接优化模型权重矩阵,而是优化一个插入模型中的更新矩阵(或增量权重)。
Q28. 何时使用提示工程、RAG或微调?
答案:提示工程:当你有少量静态数据并需要快速、直接的集成而无需修改模型时使用。它适用于具有固定信息的任务以及上下文窗口足够时。
检索增强生成(RAG):当你需要模型基于动态或频繁更新的数据生成响应时,这是理想的选择。如果模型必须提供基于引用的输出,请使用RAG。
微调:当特定且明确定义的任务要求模型从输入-输出对或人类反馈中学习时,选择此方法。微调对于个性化任务、分类或需要显著定制模型行为时很有帮助。

8、生成式AI面试问题与SLMs相关
Q29. SLMs(小型语言模型)是什么?
答案:SLMs本质上是LLM(大型语言模型)的较小版本。它们具有显著较少的参数,通常从几百万到几十亿不等,相比之下,LLM的参数数量则达到数千亿甚至数万亿。这种差异带来了以下好处:
- 效率:SLMs需要更少的计算能力和内存,这使得它们适合部署在较小的设备上,甚至是边缘计算场景中。这为现实世界的应用打开了大门,比如设备上的聊天机器人和个性化移动助手。
- 可访问性:由于资源需求较低,SLMs对更广泛的开发者和组织来说更具可访问性。这使AI更加民主化,允许小团队和个人研究者在不需要大量基础设施投资的情况下探索语言模型的力量。
- 定制化:SLMs更容易针对特定领域和任务进行微调。这使得创建专门用于小众应用的定制模型成为可能,从而提高性能和准确性。
Q30. SLMs是如何工作的?
答案:像LLMs一样,SLMs也是通过大规模的文本和代码数据集进行训练的。然而,为了实现其较小的规模和高效性,采用了几种技术:
- 知识蒸馏:这种方法涉及将预训练的LLM的知识转移到一个较小的模型中,捕捉其核心能力而无需全部复杂性。
- 剪枝和量化:这些技术分别去除模型不必要的部分并降低其权重的精度,从而进一步减少其大小和资源需求。
- 高效架构:研究人员不断开发专门为SLMs设计的新颖架构,专注于优化性能和效率。
Q31. 请举例一些小型语言模型?
答案:以下是一些SLMs的例子:
- GPT-2 Small:OpenAI的GPT-2 Small模型有1.17亿个参数,与更大的版本相比,如GPT-2 Medium(3.45亿个参数)和GPT-2 Large(7.74亿个参数),这被认为是较小的。
- DistilBERT:DistilBERT是BERT(双向编码器表示从Transformers)的蒸馏版,保留了BERT 95%的性能,同时体积更小(减少40%)且速度更快(提升60%)。DistilBERT大约有6600万个参数。
- TinyBERT:这是BERT的另一个压缩版本,TinyBERT比DistilBERT更小,大约有1500万个参数。
虽然SLMs通常有数亿个参数,但一些拥有1-3亿参数的较大模型也可以归类为SLMs,因为它们仍然可以在标准GPU硬件上运行。以下是一些这样的模型例子: - Phi3 Mini:Phi-3-mini是一个紧凑的语言模型,有38亿个参数,在庞大的数据集上进行了训练,包含3.3万亿个令牌。尽管其规模较小,但它可以与更大的模型如Mixtral 8x7B和GPT-3.5竞争,在MMLU上取得了69%的分数,在MT基准测试上取得了8.38的分数。
- Google Gemma 2B:Google Gemma 2B是Gemma家族的一部分,这些轻量级的开放模型设计用于各种文本生成任务。Gemma模型的上下文长度为8192个令牌,适合部署在资源有限的环境如笔记本电脑、台式机或云基础设施中。
- Databricks Dolly 3B:Databricks的dolly-v2-3b是一款商业级指令跟随的大型语言模型,在Databricks平台上进行了训练。它由pythia-2.8b衍生而来,在大约15k个指令/响应对上进行了训练,涵盖多个领域。虽然不是最先进的,但它表现出了令人惊讶的高质量指令跟随行为。
Q32. SLMs的优缺点是什么?
答案:小型语言模型(SLMs)的一个优点是它们可以在相对较小的数据集上进行训练。它们的小尺寸使得在移动设备上的部署更加容易,并且其简化的结构提高了可解释性。
SLMs在本地处理数据的能力是一个显著的优势,这使得它们特别适用于物联网(IoT)边缘设备和受到严格隐私和安全要求的企业。
然而,使用小型语言模型也存在权衡。由于SLMs是在更小的数据集上训练的,因此它们的知识库比大型语言模型(LLMs)更有限。此外,与更大的模型相比,它们对语言和上下文的理解通常更有限,这可能导致回答不够精确和细致。
9、生成式AI面试问题与扩散相关
Q33. 什么是扩散模型?
答案:扩散模型的理念并不古老。在2015年的一篇论文《利用非平衡热力学的深度无监督学习》中,作者这样描述它:
基本思想是受非平衡统计物理学启发,通过迭代的前向扩散过程系统而缓慢地破坏数据分布中的结构。然后我们学习一个反向扩散过程来恢复数据中的结构,从而得到一个高度灵活且易于处理的数据生成模型。
扩散过程分为前向和反向扩散过程。前向扩散过程将图像变为噪声,而反向扩散过程则应将噪声重新变为图像。
Q34. 什么是前向扩散过程?
答案:前向扩散过程是一个从原始数据x开始并结束于噪声样本ε的马尔可夫链。在每一步t,数据通过添加高斯噪声被破坏。随着时间t的增加,噪声水平增加,直到在最后一步T达到1。
Q35. 什么是反向扩散过程?
答案:反向扩散过程旨在通过迭代去除噪声将纯噪声转换为清晰图像。训练扩散模型就是学习反向扩散过程以从纯噪声重建图像。如果你们熟悉GANs,我们正在训练我们的生成器网络,但唯一的区别是扩散网络的工作更容易,因为它不必在一步内完成所有工作。相反,它一次使用多个步骤去除噪声,这更有效且易于训练,正如本文作者所发现的。
Q36. 扩散过程中的噪声时间表是什么?
答案:噪声时间表是扩散模型中的一个关键组成部分,决定了在前向过程中如何添加噪声以及在反向过程中如何去除噪声。它定义了信息被破坏和重建的速度,这对模型的性能和生成样本的质量有显著影响。
一个设计良好的噪声时间表在生成质量和计算效率之间取得了平衡。太快速的噪声添加会导致信息丢失和重建效果不佳,而过慢的时间表可能会导致不必要的长时间计算。高级技术如余弦时间表可以优化这个过程,允许更快的采样而不牺牲输出质量。噪声时间表还影响了模型捕捉不同细节级别的能力,从粗略结构到精细纹理,使其成为实现高质量生成的关键因素。
Q37. 什么是多模态LLMs?
答案:多模态大语言模型(LLMs)是先进的人工智能系统,可以解释和生成包括文本、图像甚至音频在内的各种数据类型。这些复杂的模型结合了自然语言处理与计算机视觉,有时还包括音频处理能力,不同于仅专注于文本的标准LLMs。它们的适应性使它们能够执行各种任务,包括文本到图像生成、跨模态检索、视觉问答和图像标注。
多模态LLMs的主要优势是它们能够理解和整合来自不同来源的数据,提供更多上下文和更全面的结果。这些系统的潜力通过例如DALL-E和GPT-4(可以处理图像)的例子得以展示。然而,多模态LLMs确实存在某些缺点,如需要更复杂的训练数据、更高的处理成本以及合成或修改多媒体内容的可能伦理问题。尽管如此,多模态LLMs标志着AI能力在接近人类感知和思维方式方面取得的重大进步。
生成式人工智能(Generative AI)相关的多选题
10、关于Transformers的多选题
Q38. Transformer架构相对于RNNs和LSTMs的主要优势是什么?
A. 更好地处理长程依赖关系
B. 更低的计算成本
C. 更小的模型尺寸
D. 更容易解释
答案:A. 更好地处理长程依赖关系
Q39. 在Transformer模型中,什么机制允许模型权衡句子中不同单词的重要性?
A. 卷积
B. 递归
C. 注意力机制
D. 池化
答案:C. 注意力机制
Q40. Transformer模型中位置编码的功能是什么?
A. 归一化输入
B. 提供单词位置信息
C. 减少过拟合
D. 增加模型复杂度
答案:B. 提供单词位置信息
11、关于大型语言模型(LLMs)的多选题
Q41. 大型语言模型的关键特征是什么?
A. 它们有固定的词汇表
B. 它们在少量数据上训练
C. 它们需要大量的计算资源
D. 它们只适合翻译任务
答案:C. 它们需要大量的计算资源
Q42. 以下哪个是大型语言模型的例子?
A. VGG16
B. GPT-4
C. ResNet
D. YOLO
答案:B. GPT-4
Q42. 为什么大型语言模型通常需要进行微调?
A. 减小它们的尺寸
B. 将它们适应特定任务
C. 加快它们的训练速度
D. 增加它们的词汇量
答案:B. 将它们适应特定任务
12、关于提示工程(Prompt Engineering)的多选题
Q43. 提示工程中温度的目的是什么?
A. 控制模型输出的随机性
B. 设置模型的学习率
C. 初始化模型参数
D. 调整模型输入长度
答案:A. 控制模型输出的随机性
Q44. 提示工程中使用哪些策略来改进模型响应?
A. 零样本提示
B. 少样本提示
C. A和B都使用
D. 以上都不是
答案:C. A和B都使用
Q45. 语言模型提示中较高的温度设置通常会带来什么结果?
A. 更确定的输出
B. 更具创造性和多样性的输出
C. 较低的计算成本
D. 降低模型准确性
答案:B. 更具创造性和多样性的输出
13、关于检索增强生成(RAGs)的多选题
Q46. 使用检索增强生成(RAG)模型的主要好处是什么?
A. 更快的训练时间
B. 更低的内存使用
C. 通过利用外部信息提高生成质量
D. 更简单的模型架构
答案:C. 通过利用外部信息提高生成质量
Q47. 在RAG模型中,检索器组件的作用是什么?
A. 生成最终输出
B. 从数据库中检索相关文档或段落
C. 预处理输入数据
D. 训练语言模型
答案:B. 从数据库中检索相关文档或段落
Q48. RAG模型特别适用于哪些任务?
A. 图像分类
B. 文本摘要
C. 问题回答
D. 语音识别
答案:C. 问题回答
14、关于微调的多选题
Q49. 微调预训练模型涉及什么?
A. 在新数据集上从头开始训练
B. 调整模型架构
C. 在特定任务或数据集上继续训练
D. 缩小模型尺寸
答案:C. 在特定任务或数据集上继续训练
Q50. 微调预训练模型通常比从头开始训练更有效的原因是什么?
A. 它需要更少的数据
B. 它需要更少的计算资源
C. 它利用了之前学到的特征
D. 以上所有都是
答案:D. 以上所有都是
Q51. 微调大型模型时常见的挑战是什么?
A. 过拟合
B. 欠拟合
C. 缺乏计算能力
D. 有限的模型尺寸
答案:A. 过拟合
15、关于稳定扩散的多选题
Q52. 稳定扩散模型的主要目标是什么?
A. 增强深度神经网络训练的稳定性
B. 根据文本描述生成高质量的图像
C. 压缩大型模型
D. 提高自然语言处理的速度
答案:B. 根据文本描述生成高质量的图像
Q53. 在稳定扩散模型的背景下,“去噪”一词指的是什么?
A. 减少输入数据的噪声
B. 迭代地完善生成的图像以去除噪声
C. 简化模型架构
D. 增加噪声以提高泛化能力
答案:B. 迭代地完善生成的图像以去除噪声
Q54. 稳定扩散特别适用于哪种应用?
A. 图像分类
B. 文本生成
C. 图像生成
D. 语音识别
答案:C. 图像生成
相关文章:
【杂谈】-50+个生成式人工智能面试问题(四)
7、生成式AI面试问题与微调相关 Q23. LLMs中的微调是什么? 答案:虽然预训练语言模型非常强大,但它们并不是任何特定任务的专家。它们可能对语言有惊人的理解能力,但仍需要一些LLMs微调过程,开发者通过这个过程提升它…...

RuoYi Cloud项目解读【四、项目配置与启动】
四、项目配置与启动 当上面环境全部准备好之后,接下来就是项目配置。需要将项目相关配置修改成当前相关环境。 1 后端配置 1.1 数据库 创建数据库ry-cloud并导入数据脚本ry_2024xxxx.sql(必须),quartz.sql(可选&…...

51c~Pytorch~合集5
我自己的原文哦~ https://blog.51cto.com/whaosoft/13059544 一、PyTorch DDP 正在郁闷呢 jetson nx 的torchvision安装~~ 自带就剩5g 想弄到ssd 项目中的 venv中又 cuda.h没有... 明明已经装好什么都对 算了说今天主题 啊对 还是搬运啊 学习之工具人而已 勿怪 Distrib…...

【芯片封测学习专栏 -- 什么是 Chiplet 技术】
请阅读【嵌入式开发学习必备专栏 Cache | MMU | AMBA BUS | CoreSight | Trace32 | CoreLink | ARM GCC | CSH】 文章目录 OverviewChiplet 背景UCIeChiplet 的挑战 Overview Chiplet 又称为小芯片。该技术通过将大型SoC划分为更小的芯片,使得每个部分都能采用不同…...
)
Java SpringBoot + Vue + Uniapp 集成JustAuth 最快实现多端三方登录!(QQ登录、微信登录、支付宝登录……)
注:本文基于 若依 集成just-auth实现第三方授权登录 修改完善,所有步骤仅代表本人如下环境亲测可用,其他环境需自辩或联系查看原因! 系统环境 运行系统:Windows10专业版、Linux Centos7.6 Java 版本:1.8.0_…...

支持向量回归(SVR:Support Vector Regression)用于A股数据分析、预测
简单说明 支持向量回归是一种用来做预测的数学方法,属于「机器学习」的一种。 它的目标是找到一条「最合适的线」,能够大致描述数据点的趋势,并允许数据点离这条线有一定的误差(不要求所有点都完全落在这条线上)。 可以把它想象成:找到一条「宽带」或「隧道」,大部分…...

ZYNQ初识10(zynq_7010)UART通信实验
基于bi站正点原子讲解视频: 系统框图(基于串口的数据回环)如下: 以下,是串口接收端的波形图,系统时钟和波特率时钟不同,为异步时钟,,需要先延时两拍,将时钟同…...

专题 - STM32
基础 基础知识 STM所有产品线(列举型号): STM产品的3内核架构(列举ARM芯片架构): STM32的3开发方式: STM32的5开发工具和套件: 若要在电脑上直接硬件级调试STM32设备,则…...

2 XDMA IP中断
三种中断 1. Legacy 定义:Legacy 中断是传统的中断处理方式,使用物理中断线(例如 IRQ)来传递中断信号。缺点: 中断线数量有限,通常为 16 条,限制了可连接设备的数量。中断处理可能会导致中断风…...
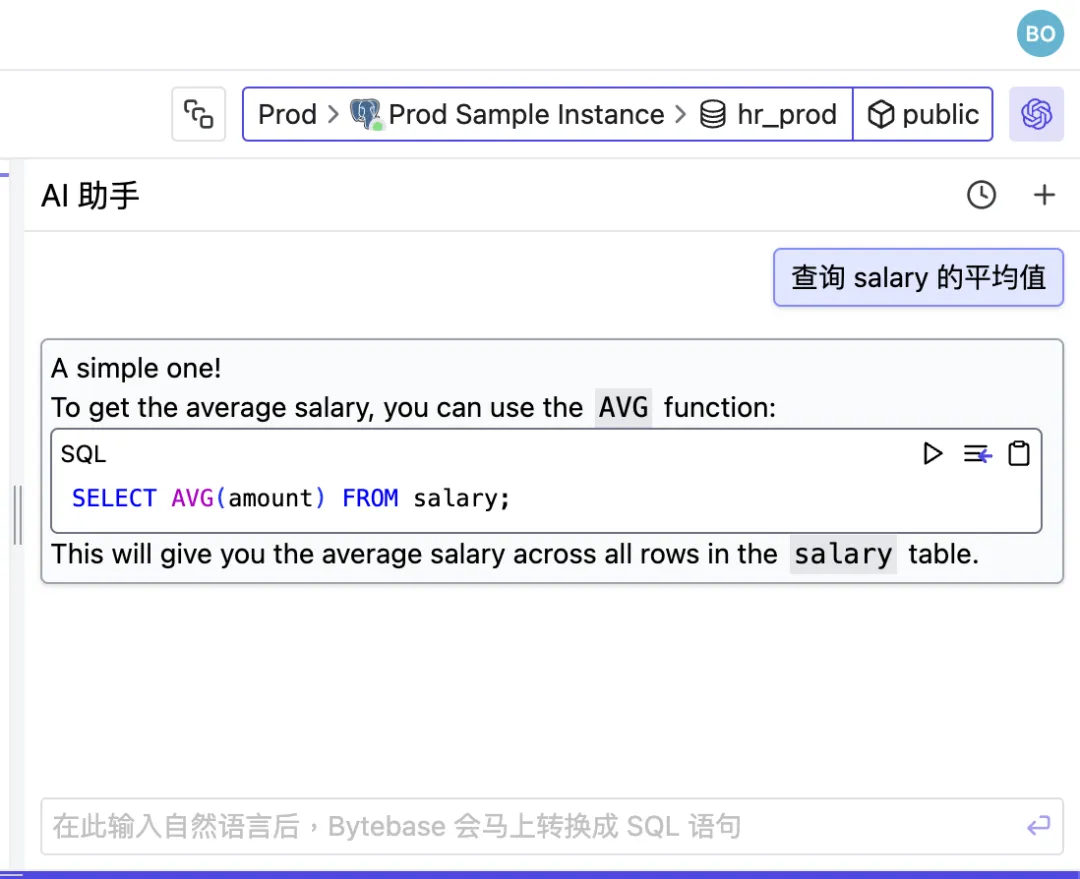
自然语言转 SQL:通过 One API 将 llama3 模型部署在 Bytebase SQL 编辑器
使用 Open AI 兼容的 API,可以在 Bytebase SQL 编辑器中使用自然语言查询数据库。 出于数据安全的考虑,私有部署大语言模型是一个较好的选择 – 本文选择功能强大的开源模型 llama3。 由于 OpenAI 默认阻止出站流量,为了简化网络配置&#…...

抖音矩阵是什么
抖音矩阵是指在同一品牌或个人IP下,通过创建多个不同定位的抖音账号(如主号、副号、子号等),形成一个有机的整体,以实现多维度、多层次的内容覆盖和用户互动。以下是关于抖音矩阵的详细介绍: 抖音矩阵的类…...

怎么抓取ios 移动app的https请求?
怎么抓取IOS应用程序里面的https? 这个涉及到2个问题 1.电脑怎么抓到IOS手机流量? 2.HTTPS怎么解密? 部分app可以使用代理抓包的方式,但是正式点的app用代理抓包是抓不到的,例如pin检测,证书双向校验等…...

pyqt鸟瞰
QApplication是Qt框架中的一个类,专门用于管理基于QWidget的图形用户界面(GUI)应用程序的控制流和主要设置。QApplication类继承自QGuiApplication,提供了许多与GUI相关的功能,如窗口系统集成、事件处理等。 QAppli…...
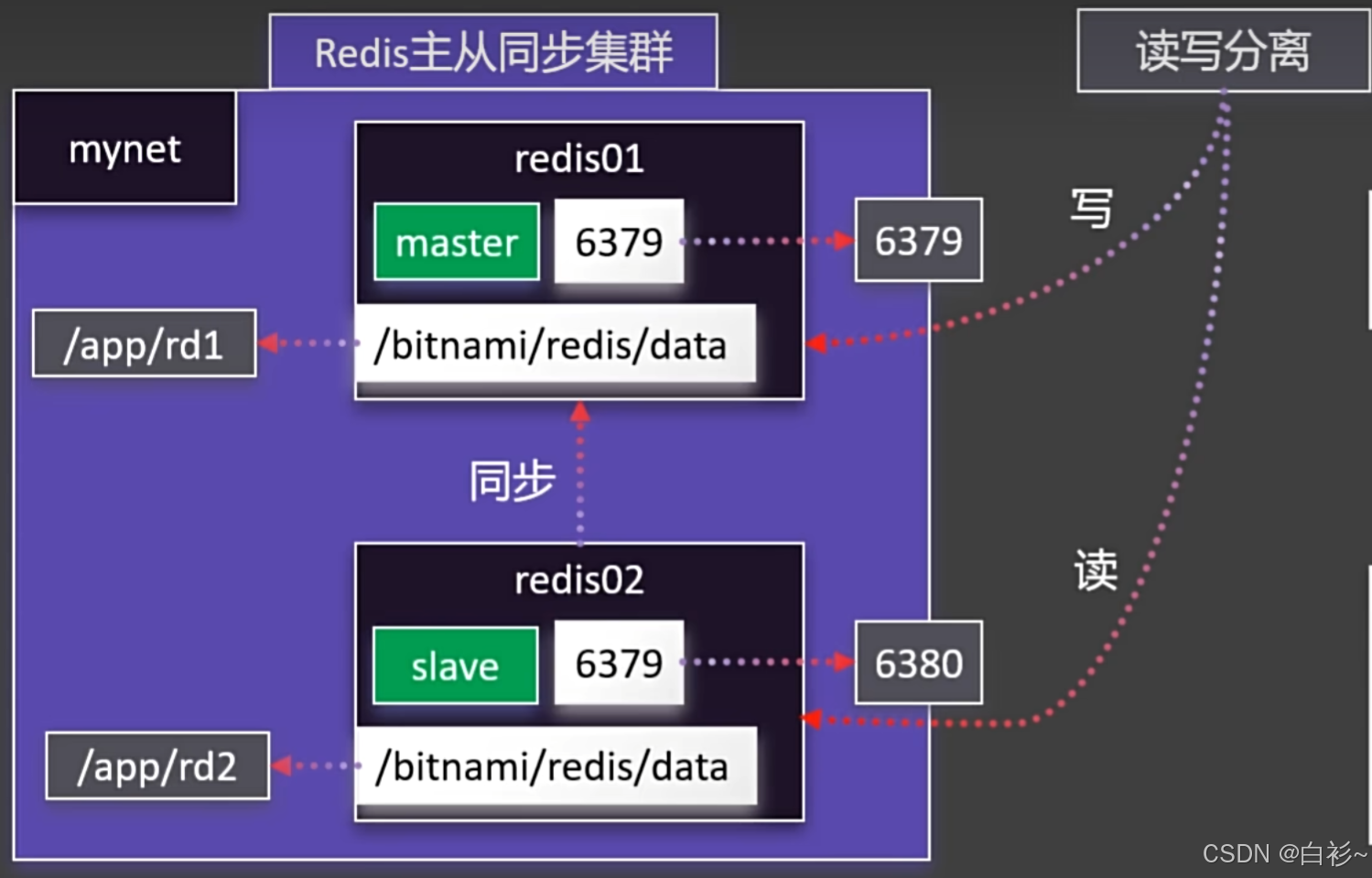
【Docker】入门教程
目录 一、Docker的安装 二、Docker的命令 Docker命令实验 1.下载镜像 2.启动容器 3.修改页面 4.保存镜像 5.分享社区 三、Docker存储 1.目录挂载 2.卷映射 四、Docker网络 1.容器间相互访问 2.Redis主从同步集群 3.启动MySQL 五、Docker Compose 1.命令式安装 …...

Token和JWT的关系详细讲解
Token 和 JSON Web Token (JWT) 是两个相关但概念上不同的术语,它们在现代 Web 应用程序的身份验证和授权中扮演着重要角色。下面将详细介绍两者之间的关系以及 JWT 的具体工作原理。 1. Token 概述 Token 是一种广义的概念,指的是任何可以证明用户身份…...

【Linux系列】Curl 参数详解与实践应用
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

解决 Git SSL 连接错误:OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno
问题描述 在执行 git pull 命令时遇到以下错误: > git pull --tags origin main fatal: unable to access github仓库: OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno 0这个错误通常表示 Git 在尝试通过 HTTPS 连接到 GitHub 时遇到了 SSL 连接问题。 解决方案…...

《Vue3 八》<script setup> 语法
<script setup> 是在单文件中使用 Composition API 的编译时语法糖,里面的代码会被编译成组件 setup() 函数的内容。 <script setup> 中的代码在每次组件实例被创建的时候都都会被执行。 定义数据: 在 <script setup> 语法糖的写法中…...

51单片机和STM32集成蓝牙模块实用指南
51单片机和STM32集成蓝牙模块实用指南 蓝牙模块(如HC-05、HC-06、JDY-31等)是嵌入式开发中常用的无线通信模块,广泛应用于智能家居、物联网、机器人等领域。本文将详细介绍如何将蓝牙模块集成到 51单片机 和 STM32 中,并提供一个…...

Transformer:深度学习的变革力量
深度学习领域的发展日新月异,在自然语言处理(NLP)、计算机视觉等领域取得了巨大突破。然而,早期的循环神经网络(RNN)在处理长序列时面临着梯度消失、并行计算能力不足等瓶颈。而 Transformer 的横空出世&am…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...