深入学习 Python 爬虫:从基础到实战
深入学习 Python 爬虫:从基础到实战
前言
Python 爬虫是一个强大的工具,可以帮助你从互联网上抓取各种数据。无论你是数据分析师、机器学习工程师,还是对网络数据感兴趣的开发者,爬虫都是一个非常实用的技能。在本文中,我们将深入学习 Python 爬虫,涵盖从基础到进阶的各个知识点,帮助你全面掌握爬虫技术。
第一章:爬虫基础知识
1.1 什么是爬虫?
爬虫,顾名思义,是一种自动化的网络数据抓取程序。它通过模拟人类的浏览行为,向指定的 Web 服务器发送请求,获取网页数据,然后从中提取出有用的信息。
爬虫通常用于:
- 获取公共网站的数据。
- 监控某些网页的变化。
- 搜集数据用于分析和研究。
爬虫的核心概念包括:
- 请求(Request):发送到 Web 服务器的 HTTP 请求,通常是 GET 或 POST 请求。
- 响应(Response):服务器返回的网页内容,通常是 HTML 格式的数据。
- 数据提取:从 HTML 响应中提取你感兴趣的数据。
1.2 爬虫的工作流程
一个简单的爬虫工作流程如下:
- 发送请求:爬虫通过 HTTP 协议向目标网站发送请求(通常是 GET 请求)。
- 解析响应:服务器返回网页的 HTML 内容,爬虫通过解析 HTML 提取出目标数据。
- 存储数据:将提取的数据保存到本地文件或数据库中。
为了让爬虫高效且可靠地工作,通常我们需要关注以下几个要点:
- 请求频率控制:为了避免对目标网站造成过大负担,爬虫需要控制请求的频率。
- 错误处理:如网站不存在(404)、服务器错误(500)等需要处理的情况。
- 数据存储:如何将抓取的数据保存到文件或数据库中,以便后续分析。
第二章:基础工具与库
2.1 Python HTTP 请求库:requests
requests 是 Python 中最常用的 HTTP 请求库,它简化了 HTTP 请求的操作,支持 GET、POST 等常见请求方法。
2.1.1 安装 requests
要使用 requests 库,你首先需要安装它。可以通过以下命令进行安装:
pip install requests
2.1.2 使用 requests 发送 GET 请求
最简单的爬虫请求就是使用 requests 发送 GET 请求,获取网页的 HTML 内容。
import requests# 目标 URL
url = 'http://quotes.toscrape.com/'# 发送 GET 请求
response = requests.get(url)# 输出网页内容
print(response.text)
在这个示例中,requests.get(url) 会向指定 URL 发送一个 HTTP GET 请求,返回一个 response 对象。通过 response.text,你可以获取网页的 HTML 内容。
2.1.3 发送 POST 请求
除了 GET 请求,爬虫常常需要发送 POST 请求来获取数据(例如表单提交、登录验证等)。requests 也支持 POST 请求。
import requestsurl = 'http://httpbin.org/post'
data = {'username': 'test', 'password': '1234'}response = requests.post(url, data=data)print(response.text)
在这个示例中,我们向 httpbin.org 发送了一个 POST 请求,并附带了一个字典数据(模拟表单提交)。响应的内容将显示 POST 请求的数据。
2.2 HTML 解析库:BeautifulSoup
HTML 文档通常是我们抓取的主要数据形式,BeautifulSoup 是一个用于解析 HTML 和 XML 的库,它提供了灵活的工具来提取网页中的内容。
2.2.1 安装 beautifulsoup4
你需要先安装 beautifulsoup4,可以使用以下命令:
pip install beautifulsoup4
2.2.2 解析 HTML 页面
BeautifulSoup 可以帮助你从 HTML 文档中提取需要的数据。首先,你需要将网页内容传递给 BeautifulSoup,然后使用它提供的各种方法来提取数据。
from bs4 import BeautifulSoup# 假设 response.text 是我们已经获取的 HTML 内容
soup = BeautifulSoup(response.text, 'html.parser')# 获取网页的标题
print(soup.title)# 获取网页的所有链接
for link in soup.find_all('a'):print(link.get('href'))
在这个示例中,我们用 BeautifulSoup(response.text, 'html.parser') 将网页内容解析为一个 BeautifulSoup 对象,然后用 soup.find_all() 来查找所有的 a 标签并提取其中的 href 属性,获取所有的链接。
2.2.3 使用 CSS 选择器查找元素
BeautifulSoup 还支持使用 CSS 选择器来查找元素。这对于查找特定的元素非常方便。
# 使用 CSS 选择器查找某个 div 标签
div = soup.select('div.classname')
2.3 处理 HTML 表单和 Cookies
许多网站需要登录才能访问或抓取数据。登录通常通过提交 HTML 表单来完成。使用 requests 库和 BeautifulSoup,我们可以模拟登录并抓取需要的数据。
2.3.1 登录示例
import requests
from bs4 import BeautifulSouplogin_url = 'http://quotes.toscrape.com/login'
data_url = 'http://quotes.toscrape.com/'# 创建会话对象
session = requests.Session()# 获取登录页面并解析
response = session.get(login_url)
soup = BeautifulSoup(response.text, 'html.parser')# 提取登录表单的隐藏字段(如 CSRF Token)
csrf_token = soup.find('input', {'name': 'csrf_token'})['value']# 登录时提交的数据
login_data = {'username': 'test','password': '1234','csrf_token': csrf_token
}# 提交登录表单
session.post(login_url, data=login_data)# 获取登录后页面的数据
data_response = session.get(data_url)
print(data_response.text)
在这个示例中,我们首先通过 session.get(login_url) 获取登录页面,并解析其中的 CSRF token。然后,我们将用户名、密码和 CSRF token 一并提交到登录页面。
2.3.2 处理 Cookies
在爬虫中,Cookie 用于保存登录状态或会话信息。requests.Session 会自动管理 Cookie,让你能够跨请求使用相同的会话。
# 查看当前会话的 cookies
print(session.cookies.get_dict())
第三章:爬虫实践
3.1 爬取静态网页
在本节中,我们将通过一个实际的例子来演示如何抓取网页的数据,并将其保存到 CSV 文件中。
3.1.1 目标网站:名人名言
我们将抓取一个名人名言网站 http://quotes.toscrape.com/,该网站提供了大量的名言和作者信息。
import requests
from bs4 import BeautifulSoup
import csvurl = 'http://quotes.toscrape.com/'# 获取网页内容
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')# 找到所有的名言
quotes = soup.find_all('div', class_='quote')# 打开 CSV 文件并写入数据
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerow(['Quote', 'Author'])for quote in quotes:text = quote.find('span', class_='text').textauthor = quote.find('small', class_='author').textwriter.writerow([text, author])print('名人名言已保存到 quotes.csv')
在这个例子中,我们使用 BeautifulSoup 解析网页,提取出每条名言和作者,然后将这些数据保存到一个 CSV 文件中。通过这种方式,你可以轻松地抓取并存储网站上的数据。
3.2 爬取带有分页的网站
许多网站的数据是分页显示的,这时我们需要处理分页的抓取。以 http://quotes.toscrape.com/page/{page}/ 为例,以下是如何抓取多页数据的示例:
import requests
from bs4 import BeautifulSoup
import csvbase_url = 'http://quotes.toscrape.com/page/{}/'# 打开 CSV 文件
with open('quotes_all.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerow(['Quote', 'Author'])# 遍历每一页for page in range(1, 11): # 假设我们抓取前 10 页url = base_url.format(page)response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')quotes = soup.find_all('div', class_='quote')for quote in quotes:text = quote.find('span', class_='text').textauthor = quote.find('small', class_='author').textwriter.writerow([text, author])print('所有名人名言已保存到 quotes_all.csv')
第四章:进阶技术
4.1 反爬虫机制
很多网站会通过各种手段来防止爬虫的访问,例如限制访问频率、检测异常请求行为、使用验证码等。
4.1.1 设置请求头
网站通常会根据请求头(如 User-Agent)来判断请求是否来自浏览器。如果没有设置合适的请求头,服务器可能会拒绝你的请求。你可以通过 requests 设置请求头来模拟真实的浏览器请求。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
4.1.2 模拟浏览器行为
如果目标网站使用 JavaScript 动态加载内容,你可以使用 Selenium 来模拟浏览器行为,获取渲染后的网页内容。Selenium 可以自动操作浏览器,模拟用户行为,如点击按钮、填写表单等。
pip install selenium
使用 Selenium 启动浏览器并获取网页内容:
from selenium import webdriverdriver = webdriver.Chrome() # 启动浏览器
driver.get('http://quotes.toscrape.com/') # 打开网页# 获取页面源代码
html = driver.page_source
print(html)driver.quit()
第五章:更复杂的爬虫技术
5.1 多线程和并发爬取
当你需要抓取大量网页时,单线程的爬虫效率可能会比较低。为了提高抓取效率,我们可以使用多线程或多进程的方式同时爬取多个网页。Python 提供了多个库来支持并发抓取,例如 threading、concurrent.futures 等。
5.1.1 使用 concurrent.futures 模块进行并发爬取
concurrent.futures 是 Python 内置的库,可以方便地实现多线程和多进程。在爬虫中,使用多线程可以显著提高抓取网页的速度。
import requests
from concurrent.futures import ThreadPoolExecutor# 目标 URL
url = 'http://quotes.toscrape.com/page/{}/'# 定义爬取的任务
def fetch_page(page_number):response = requests.get(url.format(page_number))return response.text# 使用 ThreadPoolExecutor 实现并发抓取
with ThreadPoolExecutor(max_workers=5) as executor:pages = range(1, 6) # 假设我们抓取 5 页results = list(executor.map(fetch_page, pages))# 输出抓取的结果
for result in results:print(result[:200]) # 输出每个页面的前 200 个字符
在这个示例中,ThreadPoolExecutor 会创建一个包含多个线程的线程池,max_workers=5 表示最多同时使用 5 个线程。我们使用 executor.map 来并发执行 fetch_page 函数,这样可以同时抓取多个页面,提升爬取速度。
5.1.2 使用 aiohttp 实现异步爬虫
除了多线程,Python 还支持异步编程(asyncio),可以使用 aiohttp 库来进行异步爬虫。这种方式特别适用于需要处理大量 IO 操作的爬虫任务,如请求网页、下载文件等。
pip install aiohttp
import aiohttp
import asyncio# 异步爬取网页的任务
async def fetch_page(session, page_number):async with session.get(f'http://quotes.toscrape.com/page/{page_number}/') as response:return await response.text()# 主任务:并发抓取多个页面
async def main():async with aiohttp.ClientSession() as session:tasks = []for page in range(1, 6): # 假设抓取 5 页task = asyncio.ensure_future(fetch_page(session, page))tasks.append(task)pages = await asyncio.gather(*tasks)# 输出每个页面的内容for page in pages:print(page[:200]) # 输出每个页面的前 200 个字符# 启动异步爬虫
asyncio.run(main())
在这个示例中,我们使用 aiohttp 库来异步获取网页,通过 asyncio 事件循环并发执行多个爬取任务。异步方式相比传统的多线程方式具有更高的效率,尤其是在处理大量网络请求时。
5.2 模拟登录与验证码破解
一些网站要求用户登录才能访问或抓取数据。此外,许多网站会通过验证码来防止机器人抓取数据。这里我们将讨论如何处理这些问题。
5.2.1 模拟登录
有些网站需要登录才能抓取数据,模拟登录的过程通常包括发送一个包含用户名、密码的 POST 请求,同时处理登录后的 Cookie,保持会话状态。
import requests
from bs4 import BeautifulSouplogin_url = 'http://quotes.toscrape.com/login'
login_data = {'username': 'your_username','password': 'your_password'
}# 创建会话对象
session = requests.Session()# 获取登录页面
response = session.get(login_url)
soup = BeautifulSoup(response.text, 'html.parser')# 获取 CSRF Token 等隐藏字段
csrf_token = soup.find('input', {'name': 'csrf_token'})['value']# 更新登录数据
login_data['csrf_token'] = csrf_token# 模拟登录
session.post(login_url, data=login_data)# 登录成功后抓取数据
data_url = 'http://quotes.toscrape.com/secret_page'
response = session.get(data_url)
print(response.text)
在这个例子中,我们首先访问登录页面,提取隐藏的 CSRF token(防止跨站请求伪造攻击),然后使用 requests.Session() 来保持会话,提交包含用户名、密码以及 CSRF token 的 POST 请求,最后抓取登录后的页面数据。
5.2.2 处理验证码
验证码是网站防止自动化爬虫的常用手段。破解验证码是一个非常复杂的任务,通常我们会通过以下几种方法来解决:
- 手动输入验证码:对于某些简单的验证码,你可以手动输入验证码值并继续抓取。
- OCR(光学字符识别)技术:通过 OCR 技术自动识别验证码的字符。例如,使用
Tesseract库。 - 使用验证码破解服务:例如
2Captcha或AntiCaptcha提供验证码识别服务,可以通过 API 调用来破解验证码。
下面是使用 Tesseract OCR 来破解验证码的简单示例:
pip install pytesseract pillow
from PIL import Image
import pytesseract# 打开验证码图片
image = Image.open('captcha.png')# 使用 Tesseract 进行 OCR 识别
captcha_text = pytesseract.image_to_string(image)print('识别的验证码:', captcha_text)
Tesseract 是一个开源的 OCR 引擎,可以将图片中的文字转换为字符串。你可以将验证码图片传递给 Tesseract 进行解析。
5.3 动态网页抓取
许多网站使用 JavaScript 动态加载数据,而这些数据在初始 HTML 中不可见。对于这种类型的网页,传统的爬虫工具(如 requests 和 BeautifulSoup)可能无法有效工作。我们可以使用 Selenium 或 Playwright 等工具模拟浏览器行为,获取渲染后的页面内容。
5.3.1 使用 Selenium 进行动态网页抓取
Selenium 是一个自动化测试工具,也可以用于爬虫,模拟用户行为,处理 JavaScript 渲染的网页。
首先安装 Selenium 和 WebDriver:
pip install selenium
并下载与浏览器版本匹配的 WebDriver。以 Chrome 为例,下载 ChromeDriver,并将其路径添加到系统环境变量中。
from selenium import webdriver# 启动 Chrome 浏览器
driver = webdriver.Chrome()# 打开目标网页
driver.get('http://quotes.toscrape.com/js/')# 获取渲染后的页面内容
html = driver.page_source# 使用 BeautifulSoup 解析 HTML
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')# 提取数据
quotes = soup.find_all('div', class_='quote')
for quote in quotes:text = quote.find('span', class_='text').textauthor = quote.find('small', class_='author').textprint(f'"{text}" - {author}')# 关闭浏览器
driver.quit()
在这个示例中,Selenium 启动一个浏览器实例,加载 JavaScript 动态渲染的页面。通过获取 driver.page_source,你可以获取页面渲染后的 HTML 内容,并使用 BeautifulSoup 进行解析和提取数据。
5.3.2 使用 Playwright 进行动态网页抓取
Playwright 是另一个流行的浏览器自动化工具,它支持 Chromium、Firefox 和 WebKit 等浏览器,且比 Selenium 更高效,适用于大规模爬虫。
首先安装 Playwright:
pip install playwright
python -m playwright install
使用 Playwright 来抓取动态网页:
from playwright.sync_api import sync_playwright# 启动浏览器
with sync_playwright() as p:browser = p.chromium.launch()page = browser.new_page()# 打开目标网页page.goto('http://quotes.toscrape.com/js/')# 获取渲染后的页面内容html = page.content()# 使用 BeautifulSoup 解析 HTMLfrom bs4 import BeautifulSoupsoup = BeautifulSoup(html, 'html.parser')# 提取数据quotes = soup.find_all('div', class_='quote')for quote in quotes:text = quote.find('span', class_='text').textauthor = quote.find('small', class_='author').textprint(f'"{text}"- {author}')# 关闭浏览器browser.close()
Playwright 提供了比 Selenium 更为轻量和高效的 API,能够在抓取时处理 JavaScript 动态加载的内容。
第六章:常见问题与解决方案
6.1 网站反爬虫机制
许多网站会采取反爬虫机制,如限制 IP 请求频率、检测请求头、使用验证码等。以下是一些常见的反爬虫机制和解决方案:
-
请求频率限制:你可以通过设置延迟(如使用
time.sleep())或使用随机的请求间隔来模拟人工访问,避免请求频率过高。 -
User-Agent 检测:一些网站会检测请求头中的
User-Agent字段,以确定请求是否来自浏览器。你可以使用一个常见的浏览器User-Agent,模拟真实的用户访问。 -
IP 屏蔽:网站可能会检测大量请求来自同一个 IP。如果你遇到 IP 被封的情况,可以使用代理 IP 或者切换 IP 来绕过封锁。
-
验证码:对于需要验证码的网站,可以尝试使用 OCR 技术破解验证码,或者使用验证码识别服务(如 2Captcha)自动识别验证码。
第七章:爬虫性能优化
7.1 优化抓取速度
在实际的爬虫项目中,抓取速度是一个非常重要的因素。为了优化爬虫的性能,以下是一些常见的优化策略:
7.1.1 使用代理池
为了避免 IP 被封锁,可以使用代理池(Proxy Pool)。代理池是通过多种 IP 地址来轮换使用,减轻单个 IP 频繁请求的问题。你可以购买代理服务,或者使用一些免费的代理列表。
使用代理池的示例:
import requests
import random# 代理池
proxy_pool = ['http://proxy1.com','http://proxy2.com','http://proxy3.com',
]# 随机选择一个代理
proxy = {'http': random.choice(proxy_pool)}# 发送请求时使用代理
response = requests.get('http://quotes.toscrape.com/', proxies=proxy)print(response.text)
使用代理池可以避免频繁的 IP 被封禁,提高抓取的稳定性。
7.1.2 限制请求频率
频繁的请求可能会导致网站服务器的负担过重,甚至被封禁。为了避免过于频繁的请求,可以使用以下几种方法来控制请求的速率:
- 增加请求间隔时间:通过增加请求之间的延迟,可以避免发送过多的请求。
- 使用随机延迟:让每次请求之间的延迟时间随机化,这样可以模拟正常用户的浏览行为,避免被发现是爬虫。
实现请求间隔:
import time
import random# 请求函数
def fetch_data(url):response = requests.get(url)print(response.text)# 使用随机延迟来控制请求频率
urls = ['http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', 'http://quotes.toscrape.com/page/3/']
for url in urls:fetch_data(url)time.sleep(random.uniform(1, 3)) # 随机间隔 1 到 3 秒
7.1.3 使用队列和异步任务
为了高效抓取多个网页,你可以使用任务队列(如 queue 或者使用更强大的 Celery)来管理任务,同时使用异步编程来提升性能。
asyncio 和 aiohttp 的组合是一个非常高效的方式,尤其是当你需要处理大量的网络请求时。
import asyncio
import aiohttpasync def fetch_page(url):async with aiohttp.ClientSession() as session:async with session.get(url) as response:return await response.text()async def main():urls = ['http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/', 'http://quotes.toscrape.com/page/3/']tasks = [fetch_page(url) for url in urls]results = await asyncio.gather(*tasks)for result in results:print(result[:100]) # 打印每个页面的前 100 个字符asyncio.run(main())
在这个例子中,asyncio.gather 会同时发出多个请求,从而显著提升爬虫的抓取效率。
第八章:防止被封禁的策略
网站通常会使用各种方法来防止爬虫抓取数据,常见的防爬虫措施包括 IP 屏蔽、限制请求频率、检测异常请求行为、验证码等。要避免被封禁,你可以使用以下几种策略:
8.1 使用模拟浏览器的方式
一些网站通过分析请求头(例如 User-Agent)来检测请求是否来自爬虫。为了规避这种检查,你可以模拟真实浏览器的行为。
8.1.1 设置请求头
通过在请求中设置常见的浏览器 User-Agent,可以减少被检测为爬虫的风险。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get('http://quotes.toscrape.com/', headers=headers)
print(response.text)
8.1.2 使用 Selenium 模拟浏览器行为
对于更复杂的反爬虫机制(如动态加载内容),Selenium 可以模拟真实用户的行为。你可以使用 Selenium 来模拟点击、滚动、输入等操作,获取渲染后的页面。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time# 启动浏览器
driver = webdriver.Chrome()# 打开页面
driver.get('http://quotes.toscrape.com/')# 模拟滚动,加载更多内容
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)# 获取页面内容
html = driver.page_source
print(html)driver.quit()
8.2 使用代理池
代理池可以帮助你避免 IP 被封禁。你可以通过轮换 IP 地址来分散请求,避免过多请求集中在一个 IP 上。为了构建一个代理池,你可以选择购买代理服务或使用免费的代理。
# 使用代理池
proxies = [{'http': 'http://proxy1.com'},{'http': 'http://proxy2.com'},{'http': 'http://proxy3.com'}
]# 选择代理
proxy = random.choice(proxies)response = requests.get('http://quotes.toscrape.com/', proxies=proxy)
print(response.text)
8.3 控制请求速度
通过设置合适的请求频率,可以避免过多的请求使得网站认为是恶意抓取。
8.3.1 设置请求间隔
import time
import randomdef fetch_data(url):response = requests.get(url)print(response.text)urls = ['http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/']
for url in urls:fetch_data(url)time.sleep(random.uniform(2, 5)) # 随机延迟 2 到 5 秒
8.4 使用 CAPTCHA 识别
有些网站使用 CAPTCHA(验证码)来防止自动化抓取。你可以通过人工输入验证码,或者使用验证码识别服务(例如 2Captcha 或 AntiCaptcha)来自动识别验证码。
8.4.1 使用 2Captcha 解决验证码
import requests
from twocaptcha import TwoCaptchasolver = TwoCaptcha('YOUR_API_KEY')# 传递验证码图片 URL
result = solver.recaptcha(sitekey='YOUR_SITE_KEY', url='YOUR_URL')print(result)
2Captcha 提供了一个 API,可以帮助你自动识别验证码并提交。
第九章:存储与分析抓取的数据
抓取的数据往往是原始的 HTML,如何从中提取有用的信息并进行存储和分析,是爬虫开发中的重要环节。
9.1 存储数据
抓取的数据可以存储到不同的地方,常见的存储方式包括 CSV 文件、JSON 文件、SQLite 数据库等。
9.1.1 存储为 CSV 文件
import csv# 模拟抓取的数据
data = [{'quote': 'The journey of a thousand miles begins with one step.', 'author': 'Lao Tzu'},{'quote': 'That which does not kill us makes us stronger.', 'author': 'Friedrich Nietzsche'}
]# 存储为 CSV 文件
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.DictWriter(file, fieldnames=['quote', 'author'])writer.writeheader()writer.writerows(data)
9.1.2 存储为 JSON 文件
import json# 存储为 JSON 文件
with open('quotes.json', 'w', encoding='utf-8') as file:json.dump(data, file, ensure_ascii=False, indent=4)
9.1.3 存储为 SQLite 数据库
SQLite 是一个轻量级的数据库,非常适合用于存储爬取的数据。
import sqlite3# 创建数据库连接
conn = sqlite3.connect('quotes.db')
cursor = conn.cursor()# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS quotes(quote TEXT, author TEXT)''')# 插入数据
for item in data:cursor.execute("INSERT INTO quotes (quote, author) VALUES (?, ?)", (item['quote'], item['author']))# 提交事务并关闭连接
conn.commit()
conn.close()
9.2 分析抓取的数据
分析爬取的数据可以通过 Python 中的分析库(如 pandas、matplotlib 等)来实现。
9.2.1 使用 Pandas 进行数据分析
import pandas as pd# 读取 CSV 文件
df = pd.read_csv('quotes.csv')# 显示数据框的前几行
print(df.head())
9.2.2 可视化数据
import matplotlib.pyplot as plt# 绘制某个字段的直方图
df['author'].value_counts().plot(kind='bar')
plt.show()
结语
通过本文的学习,你已经掌握了 Python 爬虫的基础和进阶技术,包括如何提高抓取效率、如何避免反爬虫机制、如何存储和分析数据等。爬虫的实现不仅仅是技术的挑战,更是对数据结构、网络请求、网页解析、性能优化等多个方面的综合应用。
希望你通过实践不断提高自己的技能,能够应对更复杂的爬虫任务,并解决实际应用中遇到的问题。如果你有任何问题,或者想了解更多内容,随时向我提问!
相关文章:

深入学习 Python 爬虫:从基础到实战
深入学习 Python 爬虫:从基础到实战 前言 Python 爬虫是一个强大的工具,可以帮助你从互联网上抓取各种数据。无论你是数据分析师、机器学习工程师,还是对网络数据感兴趣的开发者,爬虫都是一个非常实用的技能。在本文中ÿ…...

element plus 使用 upload 组件达到上传数量限制时隐藏上传按钮
最近在重构项目,使用了 element plus UI框架,有个功能是实现图片上传,且限制只能上传一张图片,结果,发现,可以限制只上传一张图片,但是上传按钮还在,如图: 解决办法&…...

音频DSP的发展历史
音频数字信号处理(DSP)的发展历史是电子技术、计算机科学和音频工程共同进步的结果。这个领域的进展不仅改变了音乐制作、音频后期制作和通信的方式,也影响了音频设备的设计和功能。以下是对音频DSP发展历史的概述: 早期概念和理论…...

2025低代码与人工智能AI新篇
在当今数字化浪潮汹涌澎湃的时代,低代码开发与人工智能(AI)犹如两颗璀璨的星辰,正逐渐交汇融合,为企业解锁前所未有的智能业务解决方案。今天,咱们就深入探讨一下低代码平台是如何集成 AI 技术,…...

【HarmonyOS Next NAPI 深度探索1】Node.js 和 CC++ 原生扩展简介
【HarmonyOS Next NAPI 深度探索1】Node.js 和 CC 原生扩展简介 如果你用过 Node.js,应该知道它强大的地方在于能处理各种场景,速度还很快。但你有没有想过,Node.js 的速度秘密是什么?今天我们来聊聊其中一个幕后英雄——原生扩展…...

redis的学习(四)
13. 渐进式遍历 通过渐进式遍历能够获取当前所有的key,又不会讲当前的服务器卡死。不是一个命令将所有的key获取,而是每执行一次命令,只获取到其中的一部分。所以想要获取到所有的key就需要多次遍历,即化整为零的思想。 渐进式遍历…...

C# winform 多线程 UI更新数据 报错:无法访问已释放的对象。
System.ObjectDisposedException HResult0x80131622 Message无法访问已释放的对象。 ObjectDisposed_ObjectName_Name SourceSystem.Windows.Forms StackTrace: at System.Windows.Forms.Control.MarshaledInvoke(Control caller, Delegate method, Object[] args, …...

error: linker `link.exe` not found
开始学习rust,安装好rust的环境,开始从hello world开始,结果用在win10环境下,使用vs code或cmd窗口编译rust报错: PS E:\study_codes\rust-demo\chart01> rustc hello.rs error: linker link.exe not found| note:…...

Vue.js组件开发-如何使用moment.js
在Vue.js组件开发中,需要处理日期和时间,moment.js 是一个非常有用的库。moment.js 提供了丰富的API来解析、验证、操作和显示日期和时间。 步骤: 1. 安装moment.js 首先,需要通过npm或yarn安装moment.js。在项目根目录下运行以…...

Linux第二课:LinuxC高级 学习记录day01
0、大纲 0.1、Linux 软件安装,用户管理,进程管理,shell 命令,硬链接和软连接,解压和压缩,功能性语句,结构性语句,分文件,make工具,shell脚本 0.2、C高级 …...

《DOM NodeList》
《DOM NodeList》 介绍 DOM(文档对象模型)是HTML和XML文档的编程接口,它允许开发者在JavaScript等编程语言中操作文档的结构、样式和内容。在DOM中,NodeList是一个重要的接口,它表示一个包含节点(如元素、…...

Nginx代理同域名前后端分离项目的完整步骤
前后端分离项目,前后端共用一个域名。通过域名后的 url 前缀来区别前后端项目。 以 vue php 项目为例。直接上 server 模块的 nginx 配置。 server{ listen 80; #listen [::]:80 default_server ipv6onlyon; server_name demo.com;#二配置项目域名 index index.ht…...
)
uniapp页面高度设置(铺满可视区域、顶部状态栏高度、底部导航栏高度)
这里说几种在uniapp开发中,关于页面设置高度的几种情况。宽度就不说了哈,宽度设置百分比都会生效。 首先我们要知道平时开发中,如果说没在uniapp做特殊处理,即正常情况下,所有的页面(.vue文件)中都是没有高度的(和vue一样),也就是说给最外层的的view标签设置高度为1…...

解锁 RAG 技术:从原理、论文研读走向实战应用RAG
亲爱的小伙伴们😘,在求知的漫漫旅途中,若你对深度学习的奥秘、Java 与 Python 的奇妙世界,亦或是读研论文的撰写攻略有所探寻🧐,那不妨给我一个小小的关注吧🥰。我会精心筹备,在未来…...

HTML5实现好看的中秋节网页源码
HTML5实现好看的中秋节网页源码 前言一、设计来源1.1 网站首页界面1.2 登录注册界面1.3 节日由来界面1.4 节日习俗界面1.5 节日文化界面1.6 节日美食界面1.7 节日故事界面1.8 节日民谣界面1.9 联系我们界面 二、效果和源码2.1 动态效果2.2 源代码 源码下载结束语 HTML5实现好看…...

数字孪生笔记 1 工业数字孪生的意义
什么是工业数字孪生? 很多在做这个工作研究的同学最开始都想问的一个问题。到底什么才是数字孪生?我在五年前做数字孪生的时候也在思考这个问题。五年时间从数字孪生兴起,到元宇宙爆发,再到数字孪生和元宇宙没人提起,…...

013:深度学习之神经网络
本文为合集收录,欢迎查看合集/专栏链接进行全部合集的系统学习。 合集完整版请参考这里。 深度学习是机器学习中重要的一个学科分支,它的特点就在于需要构建多层且“深度”的神经网络。 人们在探索人工智能初期,就曾设想构建一个用数学方式…...

计算机网络(四)网络层
4.1、网络层概述 简介 网络层的主要任务是实现网络互连,进而实现数据包在各网络之间的传输 这些异构型网络N1~N7如果只是需要各自内部通信,他们只要实现各自的物理层和数据链路层即可 但是如果要将这些异构型网络互连起来,形成一个更大的互…...

【ArcGIS微课1000例】0138:ArcGIS栅格数据每个像元值转为Excel文本进行统计分析、做图表
本文讲述在ArcGIS中,以globeland30数据为例,将栅格数据每个像元值转为Excel文本,便于在Excel中进行统计分析。 文章目录 一、加载globeland30数据二、栅格转点三、像元值提取至点四、Excel打开一、加载globeland30数据 打开配套实验数据包中的0138.rar中的tif格式栅格土地覆…...
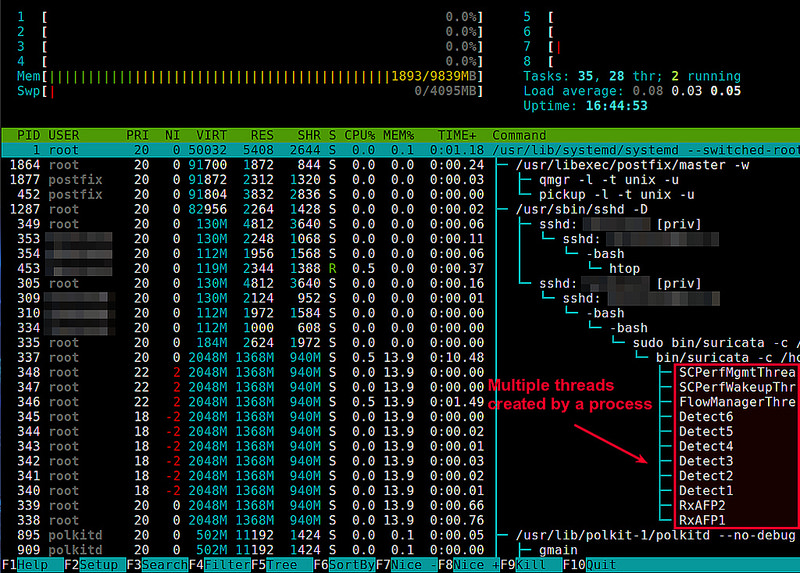
Linux 中统计进程的线程数 | 查看进程的线程
注:本文为 “Linux 线程” 相关文章合辑。 在 Linux 中统计一个进程的线程数 作者:Dan Nanni 译者: LCTT struggling | 2015-09-17 10:29 在 Linux 中一个程序在运行时会派生出多个线程。检查每个进程的线程数,有以下几种方法可…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...