解锁 RAG 技术:从原理、论文研读走向实战应用RAG
亲爱的小伙伴们😘,在求知的漫漫旅途中,若你对深度学习的奥秘、Java 与 Python 的奇妙世界,亦或是读研论文的撰写攻略有所探寻🧐,那不妨给我一个小小的关注吧🥰。我会精心筹备,在未来的日子里不定期地为大家呈上这些领域的知识宝藏与实用经验分享🎁。每一个点赞👍,都如同春日里的一缕阳光,给予我满满的动力与温暖,让我们在学习成长的道路上相伴而行,共同进步✨。期待你的关注与点赞哟🤗!
引言
在人工智能领域,检索增强生成(RAG)技术正逐渐成为提升模型性能和应用范围的关键技术之一。它巧妙地结合了信息检索和自然语言生成,为解决大型语言模型的诸多局限性提供了一种创新思路23。
RAG 的基本原理
RAG 主要由检索器和生成器两个核心组件构成。当接收到用户查询时,检索器首先对查询进行处理,将其转换为适合检索的形式,然后在外部知识库或数据库中搜索与查询相关的信息。生成器则将检索到的信息与用户原始查询相结合,作为输入生成既准确又符合上下文的响应23。
RAG 的优势
- 减少幻觉问题:通过检索真实可靠的信息源,减少了模型生成虚假信息的风险23。
- 提供实时信息:可以连接实时数据,确保生成的内容基于最新、最权威的数据3。
- 提高准确性和相关性:能生成更准确、更符合上下文的响应,降低错误信息出现的可能性23。
- 可追溯性:生成的答案可以追溯到具体的信息源,提高了答案的可信度2。
RAG 的技术改进与创新
- 检索器增强:包括递归检索、块优化技术、微调检索器、混合检索和重新排序技术等,旨在提高检索结果的准确性和丰富度1。
- 生成器改进:研究人员正在探索如何更好地将检索到的信息融入生成过程,如通过改进注意力机制、设计更有效的融合策略等,以提高生成器对检索信息的利用效率。
- 多模态融合:将图像、音频等多模态数据与文本信息相结合,使 RAG 能够处理更复杂的多模态任务,如多模态问答、图像字幕生成等13。
相关论文介绍
- 《Retrieval-Augmented Generation for AI-Generated Content: A Survey》:全面回顾了将 RAG 技术集成到 AI 生成内容场景中的现有工作,对各种检索器和生成器的增强方法进行了提炼和分类,并总结了 RAG 的其他增强方法,还介绍了 RAG 的基准、讨论了当前 RAG 系统的局限性并提出了未来研究的潜在方向,论文地址。
- 《Dynamic Retrieval-Augmented Generation》:提出了一种新颖的动态检索增强生成方法,基于实体增强生成,将检索到的实体的压缩嵌入注入到生成模型中,该方法在代码生成任务中取得了较好的效果,论文地址。
- 《RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture》:深入探讨了开发者如何借助 RAG 以及微调将私有数据及特定行业数据融合至大型语言模型之中,详细阐述了应用于主流 LLM 的方法及效果评估等,论文地址。
- 《Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge》:分析了关系抽取与图构建以及微调两种方法对于增强大型语言模型处理低频实体问题的能力,研究结果表明 RAG 在性能上更胜一筹,论文地址。
- 《Improving language models by retrieving from trillions of tokens》:提出了一种创新的 RAG Transformer,通过条件性地处理从庞大语料库中检索出的文本段落来增强自回归语言模型的性能,为借助显式记忆规模性提升 LLM 能力开辟了新路径,论文地址。
- 《Retrieval-Augmented Generation with Vector Databases for Long-Form Question Answering》:探讨了如何使用向量数据库进行检索增强生成以解决长形式问答问题,提出了一种有效的检索和融合策略,在长文本生成任务中取得了显著的改进,论文地址。
- 《RAG-Fusion: Fusing Retrieval-Augmented Generation with Conditional Generation》:介绍了 RAG-Fusion 技术,将检索增强生成与条件生成相结合,通过在生成过程中动态融合检索结果和条件信息,提高了生成的质量和多样性,论文地址。
- 《A Survey of Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》:对知识密集型自然语言处理任务中的检索增强生成技术进行了全面的调查,分析了不同方法的优缺点和应用场景,为研究人员和实践者提供了有价值的参考,论文地址。
- 《Enhancing Language Models with Retrieval-Augmented Generation for Domain-Specific Knowledge》:研究了如何使用检索增强生成技术增强语言模型在特定领域知识方面的能力,通过构建领域特定的知识库和优化检索器与生成器的交互,在特定领域任务中取得了良好的效果,论文地址。
- 《Retrieval-Augmented Generation for Multimodal Knowledge Graph Completion》:提出了一种用于多模态知识图完成的检索增强生成方法,将文本和图像信息相结合,通过检索和生成的交互,提高了多模态知识图完成的准确性和效率,论文地址。
代码示例
以下是一个简单的 RAG 代码示例,使用 Python 和 Hugging Face Transformers 库:
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, DPRContextEncoder, DPRContextEncoderTokenizer# 加载预训练的生成器模型和分词器
generator_tokenizer = AutoTokenizer.from_pretrained("t5-base")
generator_model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")# 加载预训练的检索器模型和分词器
retriever_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
retriever_model = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")# 模拟用户查询
query = "什么是人工智能的发展历史?"# 使用检索器对查询进行编码
encoded_query = retriever_tokenizer.encode(query, return_tensors="pt")
with torch.no_grad():query_embedding = retriever_model(encoded_query).pooler_output# 假设这里有一个简单的向量数据库,存储了一些文档的嵌入向量和内容
# 这里只是示例,实际应用中需要更复杂的数据库管理和检索逻辑
documents = [{"embedding": torch.randn(768), "content": "人工智能的发展可以追溯到20世纪50年代,当时提出了图灵测试等概念。"},{"embedding": torch.randn(768), "content": "近年来,深度学习技术的发展推动了人工智能的快速进步。"},# 更多文档...
]# 计算查询与文档的相似度
similarities = []
for doc in documents:similarity = torch.dot(query_embedding.squeeze(), doc["embedding"])similarities.append(similarity)# 找到最相似的文档
most_similar_index = torch.argmax(torch.stack(similarities))
most_similar_document = documents[most_similar_index]["content"]# 将最相似的文档与查询组合作为生成器的输入
input_text = f"查询:{query}\n文档:{most_similar_document}"
input_ids = generator_tokenizer.encode(input_text, return_tensors="pt")# 使用生成器生成回答
with torch.no_grad():output = generator_model.generate(input_ids)# 解码并输出回答
answer = generator_tokenizer.decode(output[0], skip_special_tokens=True)
print(answer)相关文章:

解锁 RAG 技术:从原理、论文研读走向实战应用RAG
亲爱的小伙伴们😘,在求知的漫漫旅途中,若你对深度学习的奥秘、Java 与 Python 的奇妙世界,亦或是读研论文的撰写攻略有所探寻🧐,那不妨给我一个小小的关注吧🥰。我会精心筹备,在未来…...

HTML5实现好看的中秋节网页源码
HTML5实现好看的中秋节网页源码 前言一、设计来源1.1 网站首页界面1.2 登录注册界面1.3 节日由来界面1.4 节日习俗界面1.5 节日文化界面1.6 节日美食界面1.7 节日故事界面1.8 节日民谣界面1.9 联系我们界面 二、效果和源码2.1 动态效果2.2 源代码 源码下载结束语 HTML5实现好看…...

数字孪生笔记 1 工业数字孪生的意义
什么是工业数字孪生? 很多在做这个工作研究的同学最开始都想问的一个问题。到底什么才是数字孪生?我在五年前做数字孪生的时候也在思考这个问题。五年时间从数字孪生兴起,到元宇宙爆发,再到数字孪生和元宇宙没人提起,…...

013:深度学习之神经网络
本文为合集收录,欢迎查看合集/专栏链接进行全部合集的系统学习。 合集完整版请参考这里。 深度学习是机器学习中重要的一个学科分支,它的特点就在于需要构建多层且“深度”的神经网络。 人们在探索人工智能初期,就曾设想构建一个用数学方式…...

计算机网络(四)网络层
4.1、网络层概述 简介 网络层的主要任务是实现网络互连,进而实现数据包在各网络之间的传输 这些异构型网络N1~N7如果只是需要各自内部通信,他们只要实现各自的物理层和数据链路层即可 但是如果要将这些异构型网络互连起来,形成一个更大的互…...

【ArcGIS微课1000例】0138:ArcGIS栅格数据每个像元值转为Excel文本进行统计分析、做图表
本文讲述在ArcGIS中,以globeland30数据为例,将栅格数据每个像元值转为Excel文本,便于在Excel中进行统计分析。 文章目录 一、加载globeland30数据二、栅格转点三、像元值提取至点四、Excel打开一、加载globeland30数据 打开配套实验数据包中的0138.rar中的tif格式栅格土地覆…...
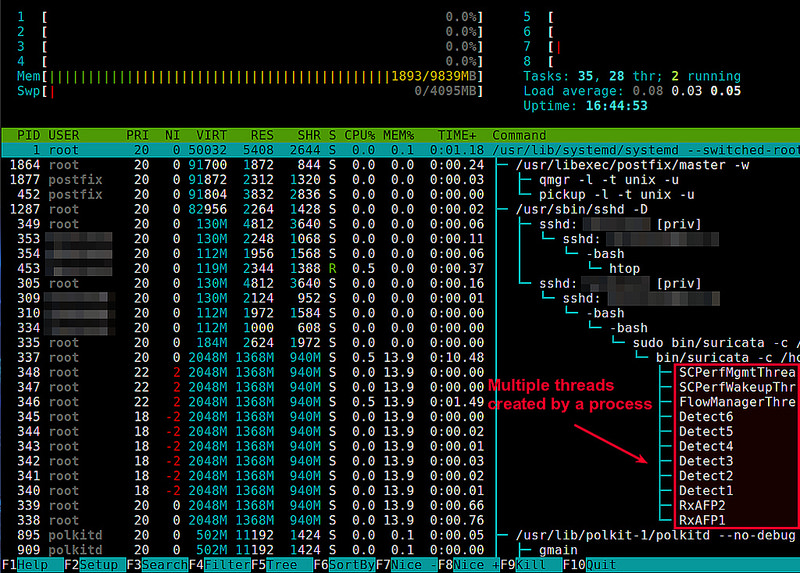
Linux 中统计进程的线程数 | 查看进程的线程
注:本文为 “Linux 线程” 相关文章合辑。 在 Linux 中统计一个进程的线程数 作者:Dan Nanni 译者: LCTT struggling | 2015-09-17 10:29 在 Linux 中一个程序在运行时会派生出多个线程。检查每个进程的线程数,有以下几种方法可…...

【深度学习 】训练过程中loss出现nan
[toc]【深度学习 】训练过程中loss出现nan 训练过程中loss出现nan 在深度学习中,loss 出现 NaN 通常是由数值不稳定或计算错误引起的。 1. 学习率过高 原因: 学习率过大可能导致权重更新幅度过大,引发数值不稳定。 解决方法: 降低学习率,…...

Linux - 什么是线程和线程的操作
线程概念 什么是线程: 线程(Thread)是操作系统能够进行运算调度的最小单位. 它被包含在进程之中, 是进程中的实际运作单位. 一个进程可以包含多个线程. 进程 : 线程 1 : n (n > 1). 进程是系统分配资源的基本单位. 线程则是系统调度的基本单位. 在…...

windows及linux 安装 Yarn 4.x 版本
1. 确保系统环境准备 a. 安装 Node.js Yarn 依赖于 Node.js,所以需要先安装 Node.js。前往 Node.js 官网 下载并安装适合你的 Windows 版本的 Node.js(推荐 LTS 版本)。安装完成后,打开命令提示符(CMD)或 PowerShell,验证安装:node -v npm -v如果显示版本号,则表示安…...

如何设计一个 RPC 框架?需要考虑哪些点?
面试官:如何设计一个 RPC 框架?需要考虑哪些点? 设计一个远程过程调用(RPC)框架是一个复杂的系统工程,涉及多个方面的考虑。一个好的 RPC 框架应具备可扩展性、灵活性、易用性和高性能。下面是设计 RPC 框…...

初学stm32 --- DAC输出三角波和正弦波
输出三角波实验简要: 1,功能描述 通过DAC1通道1(PA4)输出三角波,然后通过DS100示波器查看波形 2,关闭通道1触发(即自动) TEN1位置0 3,关闭输出缓冲 BOFF1位置1 4,使用12位右对齐模式 将数字量写入DAC_…...

开源cJson用法
cJSON cJSON是一个使用C语言编写的JSON数据解析器,具有超轻便,可移植,单文件的特点,使用MIT开源协议。 cJSON项目托管在Github上,仓库地址如下: https://github.com/DaveGamble/cJSON 使用Git命令将其拉…...
【学习笔记】理解深度学习和机器学习的数学基础:数值计算
深度学习作为人工智能领域的一个重要分支,其算法的实现和优化离不开数值计算。数值计算在深度学习中扮演着至关重要的角色,它涉及到如何在计算机上高效、准确地解决数学问题。本文将介绍深度学习中数值计算的一些关键概念和挑战,以及如何应对…...

如何使用CSS让页面文本两行显示,超出省略号表示
talk is cheap, show me the code 举个栗子,如下: <span class"a">我说说<b class"b">打瞌睡党风建设打火机</b>说说色儿</span>a{display:block/inline-block;width:100px;overflow: hidden; white-spac…...

likeshop同城跑腿系统likeshop回收租赁系统likeshop多商户商城安装及小程序对接方法
前言:首先likeshop是一个开发平台,是一个独创的平台就像TP内核平台一样,你可以在这个平台上开发和衍生出很多伟大的产品,以likeshop为例,他们开发出商城系统,团购系统,外卖点餐系统,…...

C# 与 Windows API 交互的“秘密武器”:结构体和联合体
一、引言 在 C# 的编程世界里,当我们想要深入挖掘 Windows 系统的底层功能,与 Windows API 打交道时,结构体和联合体就像是两把神奇的钥匙🔑 它们能够帮助我们精准地操控数据,实现一些高级且强大的功能。就好比搭建一…...

PHP 使用 Redis
PHP 使用 Redis PHP 是一种广泛使用的服务器端编程语言,而 Redis 是一个高性能的键值对存储系统。将 PHP 与 Redis 结合使用,可以为 Web 应用程序提供快速的读写性能和丰富的数据结构。本文将详细介绍如何在 PHP 中使用 Redis,包括安装、连接、基本操作以及一些高级应用。 …...
Xenomai应用开发测试)
嵌入式系统Linux实时化(四)Xenomai应用开发测试
1、Xenomai 原生API 任务管理 Xenomai 本身提供的一系列多任务调度机制,主要有以下一些函数: int rt_task_create (RT_TASK task, const char name, int stksize, int prio, intmode) ; 任务的创建;int rt_task_start(RT_TASK task, void(entry)(void cookie), void cookie…...

26个开源Agent开发框架调研总结(2)
根据Markets & Markets的预测,到2030年,AI Agent的市场规模将从2024年的50亿美元激增至470亿美元,年均复合增长率为44.8%。 Gartner预计到2028年,至少15%的日常工作决策将由AI Agent自主完成,AI Agent在企业应用中…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

AI大模型应用开发全攻略:从入门到精通,掌握LLM、RAG、Agent核心技能!“
本文全面介绍了AI大模型应用开发的核心技术和实践。从大模型API交互基础,到关键参数Messages和Tools的作用,深入解析了RAG、ReAct、Agent等应用范式。文章还探讨了Fine-tuning微调和Prompt提示词工程的重要性,强调工程实践与业务需求相结合。…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

PostgreSQL Merge Join 大白话详解
用生活中最直观的例子,彻底搞懂 Merge Join 是什么、为什么快、什么时候用。一、先从生活场景开始 场景一:两摞乱序试卷找同学 期末考试,老师手里有两摞试卷: A 摞:数学试卷,500 份,乱序堆放B 摞…...