Vue进阶之AI智能助手项目(二)——ChatGPT的调用和开发
AI智能助手项目
- service服务端
- 文件目录
- src目录详解
- src/index.ts
- chatGPT:src/chatgpt/index.ts
- 前端
- 接口部分
- src/api/index.ts
- src/utils/request/index.ts
- post方法
- http
- HttpOption
- src/utils/request/axios.ts
- Layout布局页面-views
- exception异常页面
- src/views/exception/404/index.vue
- src/views/exception/500/index.vue
- Layout布局页面
- src/views/chat/layout/Layout.vue
- src/store/modules/chat/index.ts
- src/views/chat/hooks/useChat.ts
- src/hooks/useBasicLayout.ts
- src/views/chat/layout/Permission.vue
- src/views/chat/layout/sider/index.vue
- src/views/chat/layout/sider/List.vue
- src/views/chat/layout/sider/Footer.vue
- Components 组件
- Header/index.vue
- Message/index.vue
service服务端
文件目录

- .vscode
- extensions.json 推荐的eslint
- settings.json 基本的描述
- src service端的入口
- .env 使用的是dotenv,当我们引用完dotenv的时候,通过这里注入的OPENAI_API_KEY环境的变量
- encode-bundle-config.ts 自己研发的打包构建工具,基于esbuild进行的二次封装
在service目录下
pnpm i
pnpm run build
先进行clean清空,清空完成后会重新打包

找到入口 src/index.ts,然后找到tsconfig.json文件,通过下面的代码,就能找到配置的文件
encode-bundle.config.ts:
import { defineConfig } from 'encode-bundle'export default defineConfig({entry: ['src/index.ts'],outDir: 'build',target: 'es2020',format: ['esm'],splitting: false,sourcemap: true,minify: false,shims: true,dts: false,
})根据这些配置的文件,通过src/index.ts作为入口,我们就能打包,打包之后的产物之后就会放到build下

- service.log 服务端日志
- tsconfig.json ts配置的compiler
- package.json
- engines:引擎engines从16开始的
- scripts:
- “start”: “esno ./src/index.ts”:esno是执行ts文件的
就类似 node index.js,这里esno index.ts esno 或者 tsx
两个都是运行ts比较好的插件 - “dev”: “esno watch ./src/index.ts”:这里的watch类似于执行ts时候的 tsc --watch,监听到文件的一个变化
- “prod”: “node ./build/index.mjs”:在node端运行打包后的产物,因此在运行prod之前需要运行build,可以理解为publish
本地可以执行

这个跟上述的 start 和 dev 是一致的,只不过这里启动的是 mjs(module js=>对应着esmodule)的文件
- “start”: “esno ./src/index.ts”:esno是执行ts文件的
在node运行中,修改index.mjs文件,这里不会重新更新,但是进程可以被关掉。
那么在自己的服务器上,想要运行一个功能,希望这个功能长期占用在我们内存中,这里就涉及在node中创建项目时候进行的进程保护机制,这里在node中使用的是pm2官网
- 先全局安装一下
- 将上述的prod进行更改:
“prod”: “pm2 start build/index.mjs”
然后执行 pnpm run prod
再执行 pm2 ls
再同时启动AI智能助手
如果删除本地服务的话,再去启动AI智能助手,则会报错
这个功能一般会在服务器上运行





- package.json
- scripts:
- “prepare”:“pnpm run build” 在包发布之前进行build,确保我们对应内容中有打包文件
- “clean”: “rimraf build” 使用正则的方式匹配到对应的文件来清除文件的
- dependencies :我们所依赖的服务
- devDependencies:包含了eslint-config,express-types(types帮助我们在本地找到对应类型的声明),encode-bundle是我们的打包工具, eslint,rimraf,typescript 都是本地开发所需要用到的。
devDependencies的作用:在本地dev时候会打包,但是在线上不会
- scripts:
src目录详解

src/index.ts
express cors


import express from 'express'
import type { RequestProps } from './types'
import type { ChatMessage } from './chatgpt'
import { chatConfig, chatReplyProcess, currentModel } from './chatgpt'
import { auth } from './middleware/auth'
import { limiter } from './middleware/limiter'
import { isNotEmptyString } from './utils/is'// express 是前端node开发的node服务器的创建
const app = express()
// router 是路由,后面可以通过router化的方式去指定到对应的服务的链接上
const router = express.Router()app.use(express.static('public')) // 将当前public的文件当作我们静态的文件
app.use(express.json()) // 服务端返回的时候,返回的是json化的格式,而不是字符串的格式// 接口服务端的cors-跨域,需要在服务端上处理的,本地开发在vue-cli上去做,但是在上线的时候,需要在服务端上去做
// cors在正常的使用中会放到middleware(node中的中间件)中,
app.all('*', (_, res, next) => {res.header('Access-Control-Allow-Origin', '*') // 响应标头预示着响应资源能够被使用(能否调的通),*表示页面所有的请求都能被调通res.header('Access-Control-Allow-Headers', 'authorization, Content-Type')res.header('Access-Control-Allow-Methods', '*')next()
})
// 正常开发的时候,匹配到对应的路径上就行
// 定义4个接口,是服务端提供给前端的接口
// 创建会话的时候,调用会话的方式
// 最主要的接口
// 第二个参数是:middleware,middleware可以通过单个的,也可以通过数组的方式拦截,也就是中间拦截态,在进入请求之前,会先进入中间件中 auth后面会说到 limiter是针对于每个用户的条件约束,也可以参考:https://stackoverflow.com/questions/20508788/do-i-need-content-type-application-octet-stream-for-file-download?newreg=203230fa032241d384f39de4a257004b
// 这个接口请求会在下面演示
router.post('/chat-process', [auth, limiter], async (req, res) => {res.setHeader('Content-type', 'application/octet-stream') //对应着是responseHeader的一个头部,意为 流式传输的参数,使用二进制的stream进行传输,并不是所有数据全量返回后再返回给前端,是一次次的,生成一部分就返回一部分,对用户体验好。try {// options就是当前会话中的会话id和上一次的会话id,拿着这个上下会话的话,可以进行上下文会话的关联// systemMessage是string类型// temperature类似于调用chatGPT的参数// top_p类似于生成chatGPT的中间值const { prompt, options = {}, systemMessage, temperature, top_p } = req.body as RequestPropslet firstChunk = true // 第一个会话块await chatReplyProcess({ //后面会说message: prompt, // 会话内容lastContext: options, // 上下文process: (chat: ChatMessage) => { // 创建会话过程中的一些chunkres.write(firstChunk ? JSON.stringify(chat) : `\n${JSON.stringify(chat)}`)firstChunk = false // 当调用完第一个会话块后,这里设置为false,第一个和后面的区别在于后面的都有换行标识},systemMessage,temperature,top_p,})}catch (error) {res.write(JSON.stringify(error)) // 有结果直接返回}finally {res.end() // 结束}
})
// config获取参数
router.post('/config', auth, async (req, res) => {// 在执行到这一步之前,会先执行auth中间件的鉴权那里try {const response = await chatConfig() // 后面会说到//send 能够通过json化的方式返回给前端res.send(response)}catch (error) {res.send(error)}
})
// 获取session
// 获取会话
router.post('/session', async (req, res) => {// node端进行请求处理的时候,一般都是用try,catch来做 try {const AUTH_SECRET_KEY = process.env.AUTH_SECRET_KEYconst hasAuth = isNotEmptyString(AUTH_SECRET_KEY)res.send({ status: 'Success', message: '', data: { auth: hasAuth, model: currentModel() } }) // model返回的是当前的模型}catch (error) {res.send({ status: 'Fail', message: error.message, data: null })}
})
// 鉴权 这里是post请求
// 会话有效期的
router.post('/verify', async (req, res) => {try {// post请求会把返回的参数放在body里const { token } = req.body as { token: string }if (!token)throw new Error('Secret key is empty')//Auth Secret Key和token进行匹配,AuthSecretKey是在服务端上存储的,token是前端传给后端的,在前端去调用后端服务的时候,前端需要用映射关系去调后端服务时候,去进行权限匹配,映射上的就是鉴权成功了if (process.env.AUTH_SECRET_KEY !== token)throw new Error('密钥无效 | Secret key is invalid')res.send({ status: 'Success', message: 'Verify successfully', data: null })}catch (error) {res.send({ status: 'Fail', message: error.message, data: null })}
})app.use('', router)
app.use('/api', router) // api为前端的路径,通配符
app.set('trust proxy', 1) // 认为dadyy正常执行,相当于是加一下变量
// 监听的端口号
// 要是想要再去抽离一下,可以通过monorepo提供到一个config文件
app.listen(3002, () => globalThis.console.log('Server is running on port 3002'))
类似的抽离的config文件的目录:
- config
- node
- site
- common
- service_port
上述内容中所涉及的方法:
- chatConfig:
服务端是会直接去请求的,直接调用三方的链接
// 最终调用当前消费量
async function chatConfig() {const usage = await fetchUsage()const reverseProxy = process.env.API_REVERSE_PROXY ?? '-'const httpsProxy = (process.env.HTTPS_PROXY || process.env.ALL_PROXY) ?? '-'const socksProxy = (process.env.SOCKS_PROXY_HOST && process.env.SOCKS_PROXY_PORT)? (`${process.env.SOCKS_PROXY_HOST}:${process.env.SOCKS_PROXY_PORT}`): '-'return sendResponse<ModelConfig>({type: 'Success',data: { apiModel, reverseProxy, timeoutMs, socksProxy, httpsProxy, usage },})
}
=> fetchUsage():
// 接口通过openAi的参数,调用fetch的参数调用三方接口去返回的
async function fetchUsage() {const OPENAI_API_KEY = process.env.OPENAI_API_KEYconst OPENAI_API_BASE_URL = process.env.OPENAI_API_BASE_URLif (!isNotEmptyString(OPENAI_API_KEY))return Promise.resolve('-')//找打fetch的链接const API_BASE_URL = isNotEmptyString(OPENAI_API_BASE_URL)? OPENAI_API_BASE_URL: 'https://api.openai.com'const [startDate, endDate] = formatDate()// 每月使用量 通过这样的路径,找到开始的路径,结束的位置const urlUsage = `${API_BASE_URL}/v1/dashboard/billing/usage?start_date=${startDate}&end_date=${endDate}`// 然后在header头中加入授权,然后去请求 // 这是open ai默认要求的鉴权const headers = {'Authorization': `Bearer ${OPENAI_API_KEY}`,'Content-Type': 'application/json',}const options = {} as SetProxyOptionssetupProxy(options)try {console.log()// 在node端 直接去创建这样的请求去发送 // 获取已使用量 const useResponse = await options.fetch(urlUsage, { headers })if (!useResponse.ok)throw new Error('获取使用量失败')const usageData = await useResponse.json() as UsageResponse //如果没有报错,那么fetch转换成json的时候,会变成json的数据const usage = Math.round(usageData.total_usage) / 100 //然后返回给我们用量return Promise.resolve(usage ? `$${usage}` : '-') //返回给前端的数据就是usage}catch (error) {global.console.log(error)return Promise.resolve('-') //报错则返回“-”}
}
上述的第三方的请求也就是Open-ai的这个请求:

上述这个请求也就是会在这个页面中调用:

类似的最典型的场景还有小程序开发,小程序开发在 login 登录中进行一些权限的校验,与这里的方式一致,在服务端进行请求,调用fetch,调用fetch参数,调用fetch请求,返回给微信中进行用户身份的获取,像token,id这些
- auth 中间件auth鉴权
// auth认证,有点像前端请求的拦截器
const auth = async (req, res, next) => {// 先判断AUTH_SECRET_KEYconst AUTH_SECRET_KEY = process.env.AUTH_SECRET_KEYif (isNotEmptyString(AUTH_SECRET_KEY)) {// AUTH_SECRET_KEY存在,则进行验证try {const Authorization = req.header('Authorization')if (!Authorization || Authorization.replace('Bearer ', '').trim() !== AUTH_SECRET_KEY.trim())// 获取Authorization中的OPENAI_API_KEY的值,然后判断是否与AUTH_SECRET_KEY相等throw new Error('Error: 无访问权限 | No access rights')next() // 通过}catch (error) {// 报错返回未授权res.send({ status: 'Unauthorized', message: error.message ?? 'Please authenticate.', data: null })}}else {next()}
}
- limiter
当很多前端用户请求A接口,我们想针对于每个用户做拦截设置的话,要怎么做呢?
可以通过这个方法
这里使用了express-rate-limit的包,rateLimit npm
rateLimit的使用场景:服务端的接口数量特别多,想去进行限流拦截的话,可以使用rateLimit进行设置
可以对IP值进行设置,对IP值进行校验
import { rateLimit } from 'express-rate-limit'
import { isNotEmptyString } from '../utils/is'
// 单个人每小时能请求的数量
const MAX_REQUEST_PER_HOUR = process.env.MAX_REQUEST_PER_HOURconst maxCount = (isNotEmptyString(MAX_REQUEST_PER_HOUR) && !isNaN(Number(MAX_REQUEST_PER_HOUR)))? parseInt(MAX_REQUEST_PER_HOUR): 0 // 0 means unlimited
// rateLimit使用场景:服务端的接口数量特别多,想去进行限流拦截的话,可以使用rateLimit进行设置
const limiter = rateLimit({windowMs: 60 * 60 * 1000, // Maximum number of accesses within an hour 1小时能够限制最大的请求数max: maxCount,// limit: 100, 对ip值进行设置,限制每个IP每15分钟最多发100个请求statusCode: 200, // 200 means success,but the message is 'Too many request from this IP in 1 hour'message: async (req, res) => {res.send({ status: 'Fail', message: 'Too many request from this IP in 1 hour', data: null })},
})
/* rateLimit类似于:是node中现成的一个包
res.send({statusCode: 200,status: 'Success',message: 'Request success',data: null
}) */
export { limiter }
- /chat-process接口请求:

参数值可以在这里设置:

- chatReplyProcess
目前的AI中,前端所能做到的事情可以分为两件:
(1)调用三方接口做输出
(2)针对返回不同类型结果,文字,非文字,前端做处理
async function chatReplyProcess(options: RequestOptions) {const { message, lastContext, process, systemMessage, temperature, top_p } = optionstry {let options: SendMessageOptions = { timeoutMs }// ai模型,随着env中的设置去匹配的,通过不同的key和token,能够匹配到不同的模型的if (apiModel === 'ChatGPTAPI') {if (isNotEmptyString(systemMessage))options.systemMessage = systemMessageoptions.completionParams = { model, temperature, top_p }}if (lastContext != null) {if (apiModel === 'ChatGPTAPI')options.parentMessageId = lastContext.parentMessageIdelseoptions = { ...lastContext }}const response = await api.sendMessage(message, {...options,onProgress: (partialResponse) => {process?.(partialResponse)},})return sendResponse({ type: 'Success', data: response })}catch (error: any) {const code = error.statusCodeglobal.console.log(error)if (Reflect.has(ErrorCodeMessage, code))return sendResponse({ type: 'Fail', message: ErrorCodeMessage[code] })return sendResponse({ type: 'Fail', message: error.message ?? 'Please check the back-end console' })}
}
=> chatGPT
chatGPT:src/chatgpt/index.ts
chatgpt npm
提供了两个方法:chatGPTAPI的方法,chatGPT非官方API的方法
官方的方法:

非官方的方法:

非官方的方式就是做了一层重定向,在国内的会限制,但是国外的不会限制,通过这层代理可以调用后端的请求
import * as dotenv from 'dotenv'
import 'isomorphic-fetch'
import type { ChatGPTAPIOptions, ChatMessage, SendMessageOptions } from 'chatgpt'
import { ChatGPTAPI, ChatGPTUnofficialProxyAPI } from 'chatgpt'
import { SocksProxyAgent } from 'socks-proxy-agent'
import httpsProxyAgent from 'https-proxy-agent'
import fetch from 'node-fetch'
import { sendResponse } from '../utils'
import { isNotEmptyString } from '../utils/is'
import type { ApiModel, ChatContext, ChatGPTUnofficialProxyAPIOptions, ModelConfig } from '../types'
import type { RequestOptions, SetProxyOptions, UsageResponse } from './types'const { HttpsProxyAgent } = httpsProxyAgentdotenv.config()const ErrorCodeMessage: Record<string, string> = {401: '[OpenAI] 提供错误的API密钥 | Incorrect API key provided',403: '[OpenAI] 服务器拒绝访问,请稍后再试 | Server refused to access, please try again later',502: '[OpenAI] 错误的网关 | Bad Gateway',503: '[OpenAI] 服务器繁忙,请稍后再试 | Server is busy, please try again later',504: '[OpenAI] 网关超时 | Gateway Time-out',500: '[OpenAI] 服务器繁忙,请稍后再试 | Internal Server Error',
}const timeoutMs: number = !isNaN(+process.env.TIMEOUT_MS) ? +process.env.TIMEOUT_MS : 100 * 1000 // 超时时间
const disableDebug: boolean = process.env.OPENAI_API_DISABLE_DEBUG === 'true' // 是否debuglet apiModel: ApiModel // API模型:ChatGPTAPI官方的API,ChatGPTUnofficialProxyAPI官方的API
const model = isNotEmptyString(process.env.OPENAI_API_MODEL) ? process.env.OPENAI_API_MODEL : 'gpt-3.5-turbo' // 通过环境变量的调度来设置chatgpt的模型if (!isNotEmptyString(process.env.OPENAI_API_KEY) && !isNotEmptyString(process.env.OPENAI_ACCESS_TOKEN)) // key和token都为空报错throw new Error('Missing OPENAI_API_KEY or OPENAI_ACCESS_TOKEN environment variable')let api: ChatGPTAPI | ChatGPTUnofficialProxyAPI// 自执行函数-引入后默认执行这个方法
(async ()<相关文章:
Vue进阶之AI智能助手项目(二)——ChatGPT的调用和开发
AI智能助手项目 service服务端文件目录src目录详解src/index.tschatGPT:src/chatgpt/index.ts前端接口部分src/api/index.tssrc/utils/request/index.tspost方法httpHttpOptionsrc/utils/request/axios.tsLayout布局页面-viewsexception异常页面src/views/exception/404/index…...

python学opencv|读取图像(二十九)使用cv2.getRotationMatrix2D()函数旋转缩放图像
【1】引言 前序已经学习了如何平移图像,相关文章链接为: python学opencv|读取图像(二十七)使用cv2.warpAffine()函数平移图像-CSDN博客 在此基础上,我们尝试旋转图像的同时缩放图像。 【2】…...

2025-微服务—SpringCloud-1~3
2025-微服务—SpringCloud 第一章、从Boot和Cloud版本选型开始说起1、Springboot版本2、Springcloud版本3、Springcloud Alibaba4、本次讲解定稿版 第二章 关于Cloud各种组件的停更/升级/替换1、微服务介绍2、SpringCloud是什么?能干吗?产生背景…...

UnityXR Interaction Toolkit 如何检测HandGestures
前言 随着VR设备的不断发展,从最初的手柄操作,逐渐演变出了手部交互,即头显可以直接识别玩家的手部动作,来完成手柄的交互功能。我们今天就来介绍下如何使用Unity的XR Interaction Toolkit 来检测手势Hand Gesture。 环境配置 1.使用Unity 2021或者更高版本,创建一个项…...

使用 Multer 上传图片到阿里云 OSS
文件上传到哪里更好? 上传到服务器本地 上传到服务器本地,这种方法在现今商业项目中,几乎已经见不到了。因为服务器带宽,磁盘 IO 都是非常有限的。将文件上传和读取放在自己服务器上,并不是明智的选择。 上传到云储存…...

2008-2020年各省社会消费品零售总额数据
2008-2020年各省社会消费品零售总额数据 1、时间:2008-2020年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、社会消费品零售总额 4、范围:31省 5、指标解释:社会消费品零售总额指企业&#x…...

【大模型入门指南 07】量化技术浅析
【大模型入门指南】系列文章: 【大模型入门指南 01】深度学习入门【大模型入门指南 02】LLM大模型基础知识【大模型入门指南 03】提示词工程【大模型入门指南 04】Transformer结构【大模型入门指南 05】LLM技术选型【大模型入门指南 06】LLM数据预处理【大模型入门…...

java 查询树结构数据,无限层级树结构通用方法
1、数据库表数据 2、controller层TestTree简单测试 RestController RequestMapping("/test") public class testTreeController {Autowiredprivate TestTreeService testTreeService;GetMapping("/list")public List<TestTree> List(TestTree tree)…...

FreeCAD集成gmsh源码分析
目录 gmsh模块界面获取gmsh的版本执行gmsh网格划分gmsh模块界面 这个界面是用PySide来写的,PySide是QT的python绑定,具体代码在task_mesh_gmsh.py文件中。目前这个界面非常的简陋,没有对接gmsh稍微高级一点的功能。界面对应的事件处理是在gmshtools.py中。这里只分析“Gmsh …...
)
K8s 集群 IP 地址管理指南(K8s Cluster IP Address Management Guide)
K8s 集群 IP 地址管理指南 概述 你是否在小型初创公司或大型企业工作,并正在为公司评估 Kubernetes?你可能正在考虑运行十几个或更多的 Kubernetes (K8s) 集群。你期望每个集群支持几百个 K8s 节点,每个节点可能有 50 到 100 个 K8s Pod。这…...
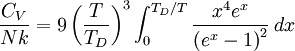
Debye-Einstein-模型拟合比热容Python脚本
固体比热模型中的德拜模型和爱因斯坦模型是固体物理学中用于估算固体热容的两种重要原子振动模型。 爱因斯坦模型基于三种假设:1.晶格中的每一个原子都是三维量子谐振子;2.原子不互相作用;3.所有的原子都以相同的频率振动(与德拜…...

OpenCV的图像分割
1、基本概念 图像分割是计算机视觉和图像处理中的一个关键步骤,它指的是将图像划分为多个区域或对象的过程。这些区域或对象在某种特性(如颜色、形状、纹理或亮度等)上是一致的或相似的,而在不同区域之间则存在明显的差异。图像分…...
【源码+文档+调试讲解】农产品研究报告管理系统
摘 要 农产品研究报告管理系统是一个旨在收集、整理、存储和分析农产品相关研究数据的综合性平台。农产品研究报告管理系统通常包含一个强大的数据库,它能够处理大量的研究数据,并对这些数据进行有效的管理和备份。农产品研究报告管理系统是现代农业科学…...

【STM32-学习笔记-7-】USART串口通信
文章目录 USART串口通信Ⅰ、硬件电路Ⅱ、常见的电平标准Ⅲ、串口参数及时序Ⅳ、STM32的USART简介数据帧起始位侦测数据采样波特率发生器 Ⅴ、USART函数介绍Ⅵ、USART_InitTypeDef结构体参数1、USART_BaudRate2、USART_WordLength3、USART_StopBits4、USART_Parity5、USART_Mode…...

高可用虚拟IP-keepalived
个人觉得华为云这个文档十分详细:使用虚拟IP和Keepalived搭建高可用Web集群_弹性云服务器 ECS_华为云 应用场景:虚拟IP技术。虚拟IP,就是一个未分配给真实主机的IP,也就是说对外提供数据库服务器的主机除了有一个真实IP外还有一个…...

AI多模态技术介绍:视觉语言模型(VLMs)指南
本文作者:AIGCmagic社区 刘一手 AI多模态全栈学习路线 在本文中,我们将探讨用于开发视觉语言模型(Vision Language Models,以下简称VLMs)的架构、评估策略和主流数据集,以及该领域的关键挑战和未来趋势。通…...

高效工作流:用Mermaid绘制你的专属流程图;如何在Vue3中导入mermaid绘制流程图
目录 高效工作流:用Mermaid绘制你的专属流程图 一、流程图的使用场景 1.1、流程图flowChart 1.2、使用场景 二、如何使用mermaid画出优雅的流程图 2.1、流程图添加图名 2.2、定义图类型与方向 2.3、节点形状定义 2.3.1、规定语法 2.3.2、不同节点案例 2.…...

uniApp通过xgplayer(西瓜播放器)接入视频实时监控
🚀 个人简介:某大型国企资深软件开发工程师,信息系统项目管理师、CSDN优质创作者、阿里云专家博主,华为云云享专家,分享前端后端相关技术与工作常见问题~ 💟 作 者:码喽的自我修养ǹ…...

ws 配置 IngressRoute 和 http一样
ws 配置 IngressRoute 和 http一样 apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata:name: web-ws-ingressroutenamespace: starp spec:entryPoints:- webroutes:- match: Host(webws.we…...

IMX6ULL的IOMUXC寄存器和SNVS复用寄存器似乎都是对引脚指定复用功能的,那二者有何区别?
IMX6ULL 的 IOMUXC 和 SNVS(Secure Non-Volatile Storage)复用寄存器都是用于配置引脚功能的,但它们的作用范围、目的和使用场景存在明显区别。以下是它们的差异分析: 1. IOMUXC(I/O Multiplexer Control)寄…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...