2Hive表类型
2Hive表类型
- 1 Hive 数据类型
- 2 Hive 内部表
- 3 Hive 外部表
- 4 Hive 分区表
- 5 Hive 分桶表
- 6 Hive 视图
1 Hive 数据类型
Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,TIMESTAMP(V0.8.0+)和BINARY(V0.8.0+)。
Hive的集合类型有:STRUCT,MAP和ARRAY。
Hive主要有四种数据模型(即表):内部表、外部表、分区表和桶表。
表的元数据保存传统的数据库的表中,当前hive只支持Derby和MySQL数据库。
2 Hive 内部表
Hive中的内部表和传统数据库中的表在概念上是类似的,Hive的每个表都有自己的存储目录,除了外部表外,所有的表数据都存放在配置在hive-site.xml文件的${hive.metastore.warehouse.dir}/table_name目录下。
创建内部表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING, grade STRING COMMOT '班级')COMMONT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS TEXTFILE;
3 Hive 外部表
被external修饰的为外部表(external table),外部表指向已经存在在Hadoop HDFS上的数据,除了在删除外部表时只删除元数据而不会删除表数据外,其他和内部表很像。
创建外部表:
CREATE EXTERNAL TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING, class STRING COMMOT '班级')COMMONT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE
LOCATION '/usr/test/data/students.txt';
4 Hive 分区表
分区表的每一个分区都对应数据库中相应分区列的一个索引,但是其组织方式和传统的关系型数据库不同。在Hive中,分区表的每一个分区都对应表下的一个目录,所有的分区的数据都存储在对应的目录中。
比如说,分区表partitinTable有包含nation(国家)、ds(日期)和city(城市)3个分区,其中nation = china,ds = 20130506,city = Shanghai则对应HDFS上的目录为:
/datawarehouse/partitinTable/nation=china/city=Shanghai/ds=20130506/。
分区中定义的变量名不能和表中的列相同。
创建分区表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING,class STRING COMMOT '班级')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE;
5 Hive 分桶表
桶表就是对指定列进行哈希(hash)计算,然后会根据hash值进行切分数据,将具有不同hash值的数据写到每个桶对应的文件中。
将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。
创建分桶表:
CREATE TABLE IF NOT EXISTS students(user_no INT,name STRING,sex STRING, class STRING COMMOT '班级',score SMALLINT COMMOT '总分')COMMONT '学生表'
PARTITIONED BY (ds STRING,country STRING)
CLUSTERED BY(user_no) SORTED BY(score) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORE AS SEQUENCEFILE;
6 Hive 视图
在 Hive 中,视图是逻辑数据结构,可以通过隐藏复杂数据操作(Joins, 子查询, 过滤,数据扁平化)来于简化查询操作。
与关系数据库不同的是,Hive视图并不存储数据或者实例化。一旦创建 HIve 视图,它的 schema 也会立刻确定下来。对底层表后续的更改(如 增加新列)并不会影响视图的 schema。如果底层表被删除或者改变,之后对视图的查询将会 failed。基于以上 Hive view 的特性,我们在ETL和数据仓库中对于经常变化的表应慎重使用视图。
创建视图:
CREATE VIEW employee_skillsAS
SELECT name, skills_score['DB'] AS DB,
skills_score['Perl'] AS Perl,
skills_score['Python'] AS Python,
skills_score['Sales'] as Sales,
skills_score['HR'] as HR
FROM employee;
创建视图的时候是不会触发 MapReduce 的 Job,因为只存在元数据的改变。
但是,当对视图进行查询的时候依然会触发一个 MapReduce Job 进程:SHOW CREATE TABLE 或者 DESC FORMATTED TABLE 语句来显示通过 CREATE VIEW 语句创建的视图。以下是对Hive 视图的 DDL操作:
更改视图的属性:
ALTER VIEW employee_skills
SET TBLPROPERTIES ('comment' = 'This is a view');
重新定义视图:
ALTER VIEW employee_skills AS
SELECT * from employee ;
删除视图:
DROP VIEW employee_skills;
相关文章:

2Hive表类型
2Hive表类型 1 Hive 数据类型2 Hive 内部表3 Hive 外部表4 Hive 分区表5 Hive 分桶表6 Hive 视图 1 Hive 数据类型 Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE&a…...
)
计算机网络之---公钥基础设施(PKI)
公钥基础设施 公钥基础设施(PKI,Public Key Infrastructure) 是一种用于管理公钥加密的系统架构,它通过结合硬件、软件、策略和标准来确保数字通信的安全性。PKI 提供了必要的框架,用于管理密钥对(包括公钥…...

EF Core执行原生SQL语句
目录 EFCore执行非查询原生SQL语句 为什么要写原生SQL语句 执行非查询SQL语句 有SQL注入漏洞 ExecuteSqlInterpolatedAsync 其他方法 执行实体相关查询原生SQL语句 FromSqlInterpolated 局限性 执行任意原生SQL查询语句 什么时候用ADO.NET 执行任意SQL Dapper 总…...

GaussDB分布式数据倾斜处理
常规数据倾斜巡检 在库中表个数少于1W的场景,直接使用倾斜视图查询当前库内所有表的数据倾斜情况 SELECT * FROM pgxc_get_table_skewness ORDER BY totalsize DESC;在库中表个数非常多(至少大于1W)的场景,因PGXC_GET_TABLE_SKEWN…...

代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树
代码随想录Day34 | 62.不同路径,63.不同路径II,343.整数拆分,96.不同的二叉搜索树 62.不同路径 动态规划第二集: 比较标准简单的一道动态规划,状态转移方程容易想到 难点在于空间复杂度的优化,详见代码 class Solution {public int uniq…...

vue.js辅助函数-mapMutations
在Vue.js中,使用辅助函数可以更方便地使用Vuex的mutation。而mapMutations就是Vuex提供的一个辅助函数,它可以将mutation映射到组件的methods中,使得我们可以在组件中直接调用mutation,而不需要手动进行commit。 mapMutations函数…...

Vue3组件设计模式:高可复用性组件开发实战
Vue3组件设计模式:高可复用性组件开发实战 一、前言 在Vue3中,组件设计和开发是非常重要的,它直接影响到应用的可维护性和可复用性。本文将介绍如何利用Vue3组件设计模式来开发高可复用性的组件,让你的组件更加灵活和易于维护。 二、单一职责…...

PHP 8.4 安装和升级指南
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

什么是 OpenResty
1、OpenResty简介 1.1 了解OpenResty OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。 简单地说OpenRes…...
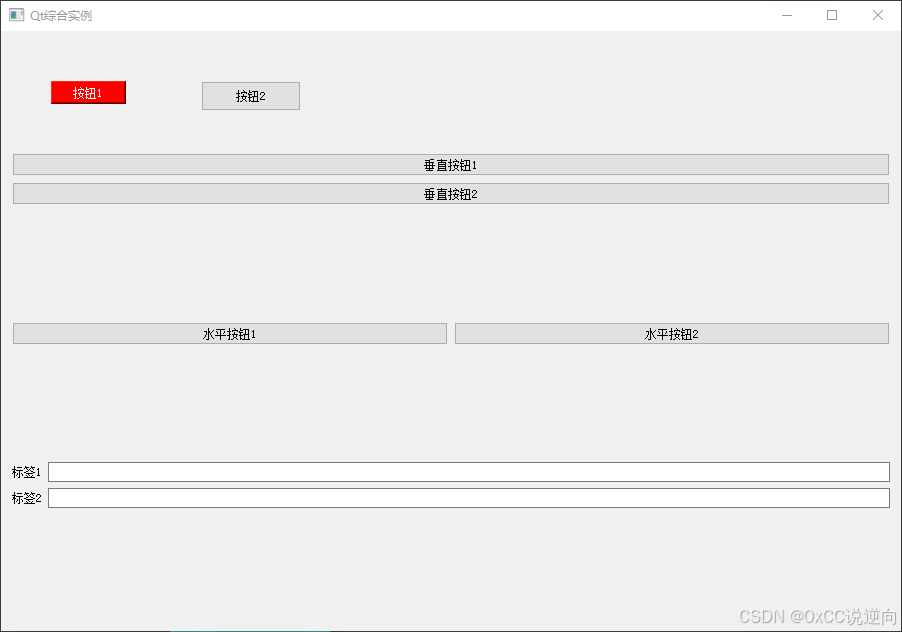
Windows图形界面(GUI)-QT-C/C++ - QT控件创建管理初始化
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 控件创建 包含对应控件类型头文件 实例化控件类对象 控件设置 设置父控件 设置窗口标题 设置控件大小 设置控件坐标 设置文本颜色和背景颜色 控件排版 垂直布局 QVBoxLayout …...

【计算机网络】lab8 DNS协议
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀计算机网络_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前言 2.…...

了解linux中的“of_property_read_u32()”
of_property_read_u32(node, "post-pwm-on-delay-ms",&data->post_pwm_on_delay); /*根据"post-pwm-on-delay-ms",从属性中查找并读取一个32位整数*/ /*读到一个32位整数,保存到data->post_pwm_on_delay中*/ of_property_read_u32…...

iOS - Objective-C 底层中的内存屏障
1. 基本实现 // objc-os.h 中的内存屏障实现 #define OSMemoryBarrier() __sync_synchronize()// ARM 架构特殊处理 static ALWAYS_INLINE void OSMemoryBarrierBeforeUnlock() { #if defined(__arm__) || defined(__arm64__)OSMemoryBarrier(); #endif } 2. 解锁前的内存屏…...

阿里云服务器扩容系统盘后宝塔面板不显示扩容后的大小
解决方法步骤: 1. yum install cloud-utils-growpart xfsprogs -y 2.growpart /dev/vda 3 扩容系统盘的第3个分区 主要是这个命令1 3. fdisk -l 4. df -h 5. xfs_growfs /dev/vda3 主要是这个命令2 主要使用 df -Th 这个命令查看对应的文件系统类型 (1)、ext…...

c语言——【linux】多进程编程 【进程的创建,相关shell指令,进程状态切换,回收资源,守护进程等】
1.思维导图 2.进程的创建 函数原型:pid_t fork(void); 功能描述:以当前进程为父进程,创建一个子进程 进程链和进程扇的创建 3.多进程具体使用 3.1进程替换 exec 函数一族 int execl(const char *path, const char *arg, ... /* (char *) N…...

macos 搭建 ragflow 开发环境
ragflow 是一个很方便的本地 RAG 库。本文主要记录一下在本机的部署过程 1、总体架构说明 开发环境:macbook pro(m1),16G内存 512G固态 因本机的内存和硬盘比较可怜,所以在服务器上部署基础 docker 包,…...

信创改造-龙蜥操作系统搭载MySql、Tomcat等服务
龙蜥操作系统 Anolis OS 8 是 OpenAnolis 社区推出的完全开源、中立、开放的发行版,它支持多计算架构,也面向云端场景优化,兼容 CentOS 软件生态。Anolis OS 8 旨在为广大开发者和运维人员提供稳定、高性能、安全、可靠、开源的操作系统服务。…...

Java 数据结构 队列之双端队列 常用方法 示例代码 及其实现
目录 常用方法 示例代码 常见实现 Java中的双端队列(Deque,Double Ended Queue)是一种队列,它允许在队列的两端插入和删除元素。与普通队列(FIFO)不同,双端队列的元素可以从队列的两端进行添…...

【原创】大数据治理入门(2)《提升数据质量:质量评估与改进策略》入门必看 高赞实用
提升数据质量:质量评估与改进策略 引言:数据质量的概念 在大数据时代,数据的质量直接影响到数据分析的准确性和可靠性。数据质量是指数据在多大程度上能够满足其预定用途,确保数据的准确性、完整性、一致性和及时性是数据质量的…...

arcgis中生成格网矢量带高度
效果 1、数据准备 (1)矢量边界(miain.shp) (2)DEM(用于提取格网标高) (3)DSM(用于提取格网最高点) 2、根据矢量范围生成格网 模板范围选择矢量边界,像元宽度和高度根据坐标系来输入,我这边是4326的,所以输入的是弧度,输出格网矢量gewang.shp 3、分区统计 …...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

利用FTDI芯片MPSSE模式构建Arduino兼容开发环境
1. 项目概述:当FTDI芯片遇上Arduino生态如果你手头有一些闲置的FTDI USB转串口模块,比如常见的FT232R、FT2232H,或者像我一样,从某个旧设备上拆下来一块FT2232C的老古董,除了用来给单片机烧录程序或者做串口调试&#…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...

微信红包助手终极指南:无需ROOT的智能抢红包解决方案
微信红包助手终极指南:无需ROOT的智能抢红包解决方案 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址: ht…...