Elasticsearch Python 客户端是否与自由线程 Python 兼容?
作者:来自 Elastic Quentin_Pradet
在这篇文章中,我们将进行一些实验,看看 Python Elasticsearch 客户端是否与新的 Python 3.13 自由线程(free-threading)版本兼容,其中 GIL 已被删除。
介绍
但首先,什么是 GIL?全局解释器锁 (Global Interpreter Lock - GIL) 是一个保护对 Python 对象访问的互斥锁,可防止多个线程同时执行 Python 字节码。在实践中这并不总是一个问题。
- 科学编程可以使用不包含 GIL 的库(如 NumPy)。
- 有些程序不是 CPU 密集型的,而是 I/O 密集型的。例如,如果你的代码向 Elasticsearch 发出昂贵的请求,但不会对结果进行昂贵的计算,则它可以有效地使用多个线程。事实上,即使只有一个线程正在执行,它也不会阻塞等待 I/O 的其他线程,从而不会阻塞 GIL。 (这也是 async/await 在 Python 中大放异彩的场景。)
然而,几十年来,人们的目标一直是消除这一限制并实现真正的多线程编程。感谢 Sam Gross 的出色工作,现在这一切成为了可能!这项工作最初被称为 nogil,但现在被称为 free-threading。虽然现有的纯 Python 代码与生成的构建仍然以相同的方式工作(尽管目前单线程代码速度较慢),但从 C 或 Rust 等其他语言编译的所有代码都需要重构。在过去,这种向后不兼容的变化足以成为发布 Python 4 的理由。然而,Python 3 迁移导致了超过 10 年的语言分裂,由此造成的痛苦仍然历历在目。因此,目前的计划是逐步推出:
- 作为第 1 阶段(当前阶段)的一部分,Python 3.13 提供了实验性的自由线程版本,每个库和应用程序都需要测试它们的兼容性。
- 在第二阶段,这些构建将不再被称为 “实验性的”。
- 在第 3 阶段,标准 Python 构建将包括自由线程支持。
Elasticsearch Python 客户端是纯 Python 代码,不涉及太多线程或特定依赖垃圾收集器,因此它应该可以与自由线程构建一样好地运行。但是,它确实具有受影响的可选依赖项,例如 aiohttp 或 orjson。
我们将测试这些不同的部件,看看它们是否正常工作。基准测试将作为练习留给读者!
使用自由线程 Python
有多种方法可以安装自由线程的 Python 版本。我们将使用 Astral 的 uv 包管理器,它允许使用 --python 3.13t 指定自由线程构建。 Astral 为 python-build-standalone 贡献了自由线程构建,如果需要,uv 将会使用它们:
$ uv run --python 3.13t python
Using CPython 3.13.0
Creating virtual environment at: .venv
Installed 4 packages in 16ms
Python 3.13.0 experimental free-threading build (main, Oct 16 2024, 08:24:33)
[Clang 18.1.8 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>但是,如果你已经安装了自由线程解释器,uv 将使用它而不是 python-build-standalone。例如,如果你想在 macOS 上使用 Homebrew 提供的构建(使用 brew install python-freethreading 安装),你将得到以下输出:
$ uv run --python 3.13t python
Using CPython 3.13.0 interpreter at:
/opt/homebrew/opt/python-freethreading/bin/python3.13t
Creating virtual environment at: .venv
Installed 4 packages in 4ms
Python 3.13.0 experimental free-threading build (main, Oct 7 2024, 05:02:14)
[Clang 16.0.0 (clang-1600.0.26.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>由于 uv 还支持内联脚本元数据标准,我们将提供如下独立的代码片段:
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "numpy",
# ]
# ///
import numpy as npc = np.arange(24).reshape(2, 3, 4)你可以运行它们,而不必担心虚拟环境或手动安装依赖项:
$ uv run --python 3.13t example.py
Reading inline script metadata from `example.py`
[[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]][[12 13 14 15][16 17 18 19][20 21 22 23]]]使用 Elasticsearch
得益于 start-local 脚本,Elasticsearch 同样易于运行:
$ curl -fsSL https://elastic.co/start-local | sh______ _ _ _| ____| | | | (_)| |__ | | __ _ ___| |_ _ ___| __| | |/ _` / __| __| |/ __|| |____| | (_| \__ \ |_| | (__|______|_|\__,_|___/\__|_|\___|
-------------------------------------------------
🚀 Run Elasticsearch and Kibana for local testing
-------------------------------------------------ℹ️ Do not use this script in a production environment⌛️ Setting up Elasticsearch and Kibana v8.16.0...- Generated random passwords
- Created the elastic-start-local folder containing the files:- .env, with settings- docker-compose.yml, for Docker services- start/stop/uninstall commands
- Running docker compose up --wait🎉 Congrats, Elasticsearch and Kibana are installed and running in Docker!🌐 Open your browser at http://localhost:5601
🔌 Elasticsearch API endpoint: http://localhost:9200我们来测试一下:
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "elasticsearch",
# ]
# ///
import os
import sysfrom elasticsearch import Elasticsearchprint(sys.version)
client = Elasticsearch("http://localhost:9200", api_key=os.environ["ES_LOCAL_API_KEY"]
)
print(client.info()["tagline"])虽然 start-local 不使用 HTTPS,但它确实设置了身份验证。相关机密存储在 elastic-start-local/.env 文件中,因此我们可以获取它并将 ES_LOCAL_API_KEY 作为环境变量传递:
$ source elastic-start-local/.env
$ ES_LOCAL_API_KEY=$ES_LOCAL_API_KEY uv run --python 3.13t ex1.py
Reading inline script metadata from `ex1.py`
3.13.0 experimental free-threading build (main, Oct 16 2024, 08:24:33)
[Clang 18.1.8 ]
You Know, for Search太棒了!一个简单的查询就按预期工作了。现在,让我们测试 Python 客户端的其他区域。
批量助手 - bulk helper
我们在 Python 客户端中明确使用线程的唯一地方是在 parallel_bulk 帮助程序中。让我们索引 books.csv 数据集并进行查询以查看是否有效。
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "elasticsearch",
# ]
# ///
import csv
import os
import sys
import timefrom elasticsearch import Elasticsearch, helpersclient = Elasticsearch("http://localhost:9200", api_key=os.environ["ES_LOCAL_API_KEY"]
)mappings = {"properties": {"Title": {"type": "text"},"Description": {"type": "text"},"Author": {"type": "text"},"Year": {"type": "date", "format": "yyyy"},"Published": {"type": "keyword"},"Rating": {"type": "scaled_float", "scaling_factor": 100},}
}client.options(ignore_status=[404]).indices.delete(index="books")
client.indices.create(index="books", mappings=mappings)
print("Created index")def generate_docs():with open("books.csv", newline="") as csvfile:reader = csv.DictReader(csvfile, delimiter=";")for row in reader:yield {"_index": "books", **row}start = time.perf_counter()
n, errors = helpers.bulk(client, generate_docs())
end = time.perf_counter()
print(f"Indexed {n} books in {end - start:.1f} seconds.")client.indices.refresh(index="books")print("Searching for Stephen King:")
resp = client.search(index="books", query={"match": {"Author": "Stephen King"}}
)
for hit in resp.body["hits"]["hits"]:book = hit["_source"]description = f'{book["Author"]} - {book["Title"]} ({book["Year"]})'rating = f'{book["Ratings"]} stars'print(f" {description}: {rating}")脚本的输出显示我们确实在不到 2 秒的时间内索引了所有 82k 本书!这比标准批量助手快大约 2 倍。
$ ES_LOCAL_API_KEY=$ES_LOCAL_API_KEY uv run --python 3.13t ex2.py
Reading inline script metadata from `ex2.py`
Created index
Indexed 81828 books in 1.6 seconds.
Searching for Stephen King:Stephen King - THE ELEMENTS OF STYLE (2013): 5.00 starsStephen King - Star (Thorndike Core) (2021): 3.11 starsStephen King - Hearts in Atlantis (2017): 4.08 starsStephen King - Misery (Spanish Edition) (2016): 4.43 starsStephen King - The Dead Zone (2016): 4.40 starsStephen King - Another World (Thorndike Core) (2021): 3.78 starsStephen King - FROM A BUICK 8 (True first edition) (2017): 3.25 starsStephen King - Road Work (2017): 4.29 starsStephen King - Icon (Thorndike Core) (2021): 4.00 starsStephen King - Misery (2016): 4.43 stars
aiohttp
Elasticsearch 的 Python 客户端通过两个 HTTP 客户端(aiohttp 和 httpx)支持 asyncio,默认使用 aiohttp。虽然 aiohttp 尚未正式支持自由线程构建(目前确实无法编译),但可以通过设置 AIOHTTP_NO_EXTENSIONS=1 在纯 Python 模式下使用它。虽然性能会较慢,但可以与自由线程构建兼容。
关于测试,没有太多需要测试的内容,因为 asyncio 事件循环已经局限于单个线程。接下来,让我们复用之前的示例,但改用 asyncio:
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "elasticsearch[async]",
# ]
# ///
import asyncio
import os
import sysfrom elasticsearch import AsyncElasticsearchprint(sys.version)async def main():async with AsyncElasticsearch("http://localhost:9200", api_key=os.environ["ES_LOCAL_API_KEY"]) as client:info = await client.info()print(info["tagline"])asyncio.run(main())由于 uv run 会动态安装依赖项,因此我们需要定义 AIOHTTP_NO_EXTENSIONS 来运行。事实上,脚本的行为符合预期:
$ export AIOHTTP_NO_EXTENSIONS=1
$ export ES_LOCAL_API_KEY=$ES_LOCAL_API_KEY
$ uv run --python 3.13t ex3.py
Reading inline script metadata from `ex3.py`
3.13.0 experimental free-threading build (main, Oct 16 2024, 08:24:33
[Clang 18.1.8 ]
You Know, for Search序列化和反序列化
Elasticsearch Python 客户端支持多个库来序列化或反序列化数据。出于性能原因,他们经常使用本机代码,并且这些库需要进行调整才能与自由线程构建配合使用。
orjson 允许快速序列化/反序列化 JSON,但尚不支持自由线程构建,甚至无法编译。
PyArrow 18+ 和 Pandas 2.2.3+ 支持自由线程构建。让我们通过进行 ES|QL 查询来重用书籍索引:
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "elasticsearch",
# "pandas",
# "pyarrow",
# ]
# ///
import csv
import os
import sys
import timeimport pandas as pd
from elasticsearch import Elasticsearch, helpersclient = Elasticsearch("http://localhost:9200", api_key=os.environ["ES_LOCAL_API_KEY"]
)print("Searching for Stephen King:")
resp = client.esql.query(query="""FROM books| WHERE Author == "Stephen King"| SORT Rating DESC| LIMIT 10""",format="arrow",
)
df = resp.to_pandas(types_mapper=pd.ArrowDtype)
print(df)输出以下内容:
$ PYTHON_GIL=0 ES_LOCAL_API_KEY=$ES_LOCAL_API_KEY uv run --python 3.13t ex4.py
Reading inline script metadata from `ex4.py`
Searching for Stephen King:Author ... Title Year
0 Stephen King ... Another World (Thorndike Core) 2021-01-01 00:00:00
1 Stephen King ... FROM A BUICK 8 (True first edition) 2017-01-01 00:00:00
2 Stephen King ... Hearts in Atlantis 2017-01-01 00:00:00
3 Stephen King ... Misery (Spanish Edition) 2016-01-01 00:00:00
4 Stephen King ... The Dark Tower: The Gunslinger 2017-01-01 00:00:00
5 Stephen King ... The Dead Zone 2016-01-01 00:00:00
6 Stephen King ... NIGHTMARES AND DREAMSCAPES 2017-01-01 00:00:00
7 Stephen King ... How writers write 2002-01-01 00:00:00
8 Stephen King ... THE ELEMENTS OF STYLE 2013-01-01 00:00:00
9 Stephen King ... Road Work 2017-01-01 00:00:00请注意,我必须设置 PYTHON_GIL=0 来禁用以下警告,我认为不应该发出该警告,因为这些库确实支持自由线程构建。也许这个问题将在未来的版本中得到修复。
结论
总而言之,自由线程构建的效果出奇地好!许多重要的库已经支持自由线程。虽然仍然存在一些不受支持的库,例如 orjson 或 Polars,但它们是例外,而不是规则。自由线程的前景光明,我可以看到这些构建很快就会脱离实验状态。 (但在这种情况发生之前,我建议不要在生产中使用它们。)
如果你想了解有关自由线程的更多信息,https://py-free-threading.github.io/是一个很好的资源,特别是更多资源页面链接到有用的学习材料。
回答我最初的问题:是的,Python Elasticsearch 客户端在自由线程下运行得很好!
原文:Dec 4th, 2024: [EN] Does the Elasticsearch Python client work with free-threading Python? - Advent Calendar - Discuss the Elastic Stack
相关文章:

Elasticsearch Python 客户端是否与自由线程 Python 兼容?
作者:来自 Elastic Quentin_Pradet 在这篇文章中,我们将进行一些实验,看看 Python Elasticsearch 客户端是否与新的 Python 3.13 自由线程(free-threading)版本兼容,其中 GIL 已被删除。 介绍 但首先&…...

基于大语言模型的组合优化
摘要:组合优化(Combinatorial Optimization, CO)对于提高工程应用的效率和性能至关重要。随着问题规模的增大和依赖关系的复杂化,找到最优解变得极具挑战性。在处理现实世界的工程问题时,基于纯数学推理的算法存在局限…...

#CSS混合模式:解决渐变背景下的文字可见性问题
在现代网页设计中,渐变背景的使用越来越普遍。然而,当我们在渐变背景上放置文字时,常常会遇到一个问题:文字在某些背景颜色下可能变得难以阅读。今天,我们将探讨一个优雅的解决方案:使用CSS混合模式。 问题…...

Vue2+OpenLayers给标点Feature添加信息窗体(提供Gitee源码)
目录 一、案例截图 二、安装OpenLayers库 三、代码实现 3.1、信息窗体DOM元素 3.2、创建Overlay 3.3、创建一个点 3.4、给点初始化点击事件 3.5、完整代码 四、Gitee源码 一、案例截图 二、安装OpenLayers库 npm install ol 三、代码实现 初始化变量: d…...

实战threeJS数字孪生开源 数字工厂
threeJS数字孪生 数字工厂 设备定位 基于three.js的数字工厂开源项目介绍 一、项目概述 本项目是一款基于three.js的数字工厂项目,旨在通过3D可视化技术,为工业制造领域提供一个直观、高效、智能的生产监控与管理平台。该项目结合了现代前端技术栈&…...

【Python基础篇】——第3篇:从入门到精通:掌握Python数据类型与数据结构
第3篇:数据类型与数据结构 目录 Python中的数据类型概述列表(List) 创建列表列表的基本操作列表方法列表推导式 元组(Tuple) 创建元组元组的基本操作元组的不可变性 字典(Dictionary) 创建字典…...

算法3(力扣83)-删除链表中的重复元素
1、题目:给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。 2、实现( 因为已排序,所以元素若重复,必然在其下一位)(这里为在vscod…...

HarmonyOS 鸿蒙 ArkTs(5.0.1 13)实现Scroll下拉到顶刷新/上拉触底加载,Scroll滚动到顶部
HarmonyOS 鸿蒙 ArkTs(5.0.1 13)实现Scroll下拉到顶刷新/上拉触底加载 效果展示 使用方法 import LoadingText from "../components/LoadingText" import PageToRefresh from "../components/PageToRefresh" import FooterBar from "../components/…...

.NET8.0多线程编码结合异步编码示例
1、创建一个.NET8.0控制台项目来演示多线程的应用 2、快速创建一个线程 3、多次运行程序,可以得到输出结果 这就是多线程的特点 - 当多个线程并行执行时,它们的具体执行顺序是不确定的,除非我们使用同步机制(如 lock、信号量等&am…...

SpringBoot项目中解决CORS跨域资源共享问题
在Spring Boot项目中解决CORS(跨域资源共享)问题,可以通过以下几种方法: 1. 使用CrossOrigin注解 这是最简单的方法,适用于单个控制器或控制器方法级别的跨域配置。你可以在控制器类或具体的方法上使用CrossOrigin注…...

Android string.xml中特殊字符转义
项目中要在string.xml 中显示特殊符号 空格: (普通的英文半角空格但不换行) 窄空格: (中文全角空格 (一个中文宽度)) (半个中文宽度,但两个空格比一个中文…...

解析传统Workflow、AI Workflow与AI Agent概念,并通过Coze案例探讨利用AI工作流构建应用的实践流程
传统工作流 工作流入门这篇就够了 BPMN.JS中文教程 BPMN 工作流引擎解析 定义:工作流是在计算机支持下业务流程的自动或半自动化,其通过对流程进行描述以及按一定规则执行以完成相应工作。 应用:随着计算机技术的发展以及工业生产、办公自动…...

光谱相机的光谱分辨率可以达到多少?
多光谱相机 多光谱相机的光谱分辨率相对较低,波段数一般在 10 到 20 个左右,光谱分辨率通常在几十纳米到几百纳米之间,如常见的多光谱相机光谱分辨率为 100nm 左右。 高光谱相机 一般的高光谱相机光谱分辨率可达 2.5nm 到 10nm 左右&#x…...

android Recyclerview viewholder统一封装
Recyclerview holder 统一封装 ViewHolder类 import android.annotation.SuppressLint import android.content.Context import android.graphics.Color import android.graphics.drawable.GradientDrawable import android.os.Build import android.os.CountDownTimer import…...
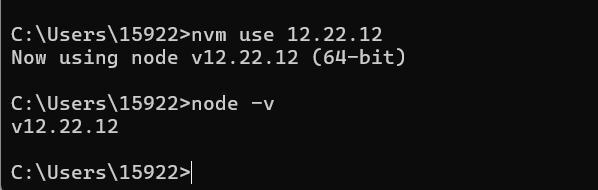
Windows部署NVM并下载多版本Node.js的方法(含删除原有Node的方法)
本文介绍在Windows电脑中,下载、部署NVM(node.js version management)环境,并基于其安装不同版本的Node.js的方法。 在之前的文章Windows系统下载、部署Node.js与npm环境的方法(https://blog.csdn.net/zhebushibiaoshi…...

51单片机入门基础
目录 一、基础知识储备 (一)了解51单片机的基本概念 (二)掌握数字电路基础 (三)学习C语言编程基础 二、开发环境搭建 (一)硬件准备 (二)软件准备 三、…...

老centos7 升级docker.io为docker-ce 脚本
旧的centos7 之前安装的是docker.io 由于一些原因,像docker compose 等版本变化,以及docker.io源受限等,我们要更新到docker-ce 并使用国内阿里云的源怎么处理?下面直接上脚本,upgrade-docker.sh #!/bin/bashset -e# 创建临时目录 TEMP_DIR"./tmp" mkdir -p "…...

数仓建模(三)建模三步走:需求分析、模型设计与数据加载
本文包含: 数据仓库的背景与重要性数据仓库建模的核心目标本文结构概览:需求分析、模型设计与数据加载 目录 第一部分:需求分析 1.1 需求分析的定义与目标 1.2 需求分析的步骤 1.2.1 业务需求收集 1.2.2 技术需求分析 1.2.3 成果输出…...

PHP xml 常用函数整理
————————-DOM 函数————————————– 1、DOMDocument->load() 作用:加载xml文件 用法:DOMDocument->load( string filename ) 参数:filename,xml文件; 返回:如果成功则返回 TRUE&a…...

数据结构(Java版)第八期:LinkedList与链表(三)
专栏:数据结构(Java版) 个人主页:手握风云 目录 一、链表中的经典面试题 1.1. 链表分割 1.2. 链表的回文结构 1.3. 相交链表 1.4. 环形链表 一、链表中的经典面试题 1.1. 链表分割 题目中要求不能改变原来的数据顺序,也就是如上图所示。…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...