Pytorch基础教程:从零实现手写数字分类
文章目录
- 1.Pytorch简介
- 2.理解tensor
- 2.1 一维矩阵
- 2.2 二维矩阵
- 2.3 三维矩阵
- 3.创建tensor
- 3.1 你可以直接从一个Python列表或NumPy数组创建一个tensor:
- 3.2 创建特定形状的tensor
- 3.3 创建三维tensor
- 3.4 使用随机数填充tensor
- 3.5 指定tensor的数据类型
- 4.tensor基本运算
- 4.1 算术运算:
- 4.1.1 加法:
- 4.1.2 减法:
- 4.1.3 乘法(逐元素乘法,不是矩阵乘法):
- 4.1.4 除法:
- 4.1.5 幂运算:
- 4.2 矩阵运算:
- 4.2.1 矩阵乘法:
- 4.2.2 矩阵转置:
- 4.2.3 逐元素运算的广播机制:
- 4.3 统计运算:
- 4.3.1 求和:
- 4.3.2 平均值:
- 4.3.3 最大值和最小值:
- 4.4 形状操作:
- 4.4.1 改变形状:
- 4.4.2 展平:
- 5.理解神经网络
- 5.1 什么是分类,什么是回归
- 5.1.1 分类
- 5.1.2 回归
- 5.2 有什么函数可以实现分类和回归?答案:线性回归
- 5.2.1 从二元一次方程组到Simple Linear Regression
- 5.2.1 什么是线性关系(Linear Relationship)?
- 5.3 线性回归到神经网络
- 5.3.1 理解新模型 - 简易版神经网络
- 6.定义网络结构
- 7.整理数据集
- 8.训练模型
- 9.保存模型
- 10.加载模型
- 11.使用GPU加速
- 11.1 要将model(model里面的参数w和b)从内存放到显存。
- 11.2 把加载的数据从内存加载到显存
- 11.3 只要将模型的数据,测试数据和训练数据加载到显存,自然会使用GPU进行处理。
1.Pytorch简介
PyTorch是一个开源的深度学习框架,由Facebook的人工智能研究院(FAIR)开发,并于2017年1月正式推出。 PyTorch以其灵活性和易用性著称,特别适合于深度学习模型的构建和训练。它基于Torch张量库开发,提供了动态计算图的功能,允许在运行时改变计算图,这使得模型构建更加灵活
2.理解tensor
Tensor 是PyTorch中最近本的数据结构,可以将其视为n维数组或者矩阵。n维矩阵在我们生活里非常常见。
2.1 一维矩阵

基本操作

2.2 二维矩阵
二维矩阵是一个表格,其中包含行和列。例如:

在这个矩阵中,
a11a 11 、a12a12 、a13a13 、a21a21 、a22a22 、a23a23 、a31a31 、a32a32 、a33a33 是矩阵的元素。第一个方括号内的元素属于第一行,第二个方括号内的元素属于第二行,第三个方括号内的元素属于第三行。
2.3 三维矩阵
三维矩阵可以看作是由多个二维矩阵组成的“矩阵的矩阵”,通常用于表示多维数据。例如,一个3x3x3的三维矩阵可以表示为:

在这个三维矩阵中,每一个二维矩阵(由方括号包围的部分)可以看作是一个“层”,整个三维矩阵由这些层组成。
3.创建tensor
3.1 你可以直接从一个Python列表或NumPy数组创建一个tensor:
import torch# 从Python列表创建tensor
data = [[1, 2], [3, 4]]
tensor_from_list = torch.tensor(data)
print(tensor_from_list)# 从NumPy数组创建tensor
import numpy as np
np_array = np.array(data)
tensor_from_np = torch.from_numpy(np_array)
print(tensor_from_np)
3.2 创建特定形状的tensor
你可以使用torch的内置函数来创建具有特定形状和值的tensor:
import torch# 创建一个全为零的tensor,形状为(2, 3)
zeros_tensor = torch.zeros((2, 3))
print(zeros_tensor)# 创建一个全为一的tensor,形状为(2, 3)
ones_tensor = torch.ones((2, 3))
print(ones_tensor)# 创建一个未初始化的tensor,形状为(2, 3),其值可能是随机的
uninit_tensor = torch.empty((2, 3))
print(uninit_tensor)# 创建一个具有指定值的tensor,所有元素都设为5,形状为(2, 3)
full_tensor = torch.full((2, 3), 5)
print(full_tensor)
3.3 创建三维tensor
要创建一个三维tensor,你只需指定三个维度的大小:
import torch# 创建一个形状为(2, 3, 4)的三维tensor,所有元素都初始化为0
three_dim_tensor = torch.zeros((2, 3, 4))
print(three_dim_tensor)
3.4 使用随机数填充tensor
你还可以使用随机数来填充tensor:
import torch# 创建一个形状为(2, 3)的tensor,其元素是从均匀分布[0, 1)中抽取的随机数
rand_tensor = torch.rand((2, 3))
print(rand_tensor)# 创建一个形状为(2, 3)的tensor,其元素是从标准正态分布中抽取的随机数
randn_tensor = torch.randn((2, 3))
print(randn_tensor)
3.5 指定tensor的数据类型
在创建tensor时,你还可以指定其数据类型(dtype):
import torch# 创建一个形状为(2, 3)的tensor,元素类型为浮点数(默认)
float_tensor = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
print(float_tensor)
print(float_tensor.dtype) # 输出: torch.float32# 创建一个形状为(2, 3)的tensor,元素类型为整数
int_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.int32)
print(int_tensor)
print(int_tensor.dtype) # 输出: torch.int32
4.tensor基本运算
4.1 算术运算:
4.1.1 加法:
import torch
x = torch.tensor([1.0, 2.0, 3.0])
y = torch.tensor([4.0, 5.0, 6.0])
z = x + y # 对应元素相加
print(z) # 输出: tensor([5., 7., 9.])4.1.2 减法:
z = x - y # 对应元素相减
print(z) # 输出: tensor([-3., -3., -3.])
4.1.3 乘法(逐元素乘法,不是矩阵乘法):
z = x * y # 对应元素相乘
print(z) # 输出: tensor([4., 10., 18.])4.1.4 除法:
z = x / y # 对应元素相除
print(z) # 输出: tensor([0.2500, 0.4000, 0.5000])4.1.5 幂运算:
z = x ** 2 # 每个元素求平方
print(z) # 输出: tensor([1., 4., 9.])4.2 矩阵运算:
4.2.1 矩阵乘法:
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([[5, 6], [7, 8]])
C = torch.mm(A, B) # 或者使用 A @ B 在PyTorch 1.0及以上版本
print(C) # 输出: tensor([[19, 22], [43, 50]])4.2.2 矩阵转置:
A_t = A.t()
print(A_t) # 输出: tensor([[1, 3], [2, 4]])4.2.3 逐元素运算的广播机制:
PyTorch支持广播机制,当两个tensor的形状不完全相同时,较小的tensor会自动扩展以匹配较大的tensor的形状,然后进行逐元素运算。
x = torch.tensor([1.0, 2.0, 3.0])
y = torch.tensor(2.0) # 这是一个标量,将被广播到与x相同的形状
z = x + y
print(z) # 输出: tensor([3., 4., 5.])4.3 统计运算:
4.3.1 求和:
sum_x = x.sum() # 对所有元素求和
print(sum_x) # 输出: tensor(6.)4.3.2 平均值:
mean_x = x.mean() # 对所有元素求平均值
print(mean_x) # 输出: tensor(2.)4.3.3 最大值和最小值:
max_x, _ = x.max() # 返回最大值及其索引(这里只关心最大值)
min_x, _ = x.min() # 返回最小值及其索引(这里只关心最小值)
print(max_x) # 输出: tensor(3.)
print(min_x) # 输出: tensor(1.)4.4 形状操作:
4.4.1 改变形状:
x_reshaped = x.view(-1, 1) # 将x改变为列向量
print(x_reshaped) # 输出: tensor([[1.], [2.], [3.]])4.4.2 展平:
x_flattened = x.flatten() # 将x展平为一维数组
print(x_flattened) # 输出: tensor([1., 2., 3.])5.理解神经网络
在开始之前,我觉得有必要提个醒, 神经网络本质上是数学,但我们仅仅作为开发者,我们要做的事情是通过pytorch或类似的工具实现我们想要的功能,达到我们想要的目的。至于为什么里面的数学公式是这样子,为什么神经网络的架构是这样搭,为什么他这个结构这么好,我们根本不用去管里面的最底层机理。我们只需要知道这样子这样子就能达到效果,就可以了。我们不要被这些数学公式吓跑了。
5.1 什么是分类,什么是回归
分类和回归是机器学习中两种基本的预测方法,它们的核心区别在于预测的输出类型。
5.1.1 分类
分类,简单来说,就是给数据打上标签,预测它属于哪一个类别。比如,我们有一堆邮件,需要判断哪些是垃圾邮件,哪些是正常邮件。这就是一个典型的二分类问题,因为输出只有两种可能:垃圾邮件或正常邮件。再比如,我们有一张动物图片,需要判断它是猫、狗还是其他动物,这就是一个多分类问题,因为输出有多个可能的类别。
举例:想象你手里有一堆水果,你需要把它们分成苹果和橙子两类,这就是分类任务。你要看水果的颜色、形状等特征,然后决定它是苹果还是橙子。
5.1.2 回归
回归,则是预测一个具体的数值,这个数值可以是任何实数。比如,我们想知道一套房子的价格,根据它的面积、位置等特征来预测。这就是一个回归问题,因为输出是一个连续的数值,而不是一个类别标签。再比如,我们想预测明天的温度或者股票的价格,这些都是回归问题。
举例:想象你要预测一辆汽车的价格,你会考虑它的品牌、型号、年份、里程数等特征,然后给出一个具体的价格预测,比如10万元、15万元等,这就是回归任务。

上图转自‘人工智能教学实践’博客,我觉得这张图很好地解析什么是分类,什么是回归,预测天气的是分类,预测温度是多少,是回归。
5.2 有什么函数可以实现分类和回归?答案:线性回归
5.2.1 从二元一次方程组到Simple Linear Regression
初中时,我们通过两个点的坐标求解二元一次方程。例如:已知直线y = ax + b 经过点(1,1)和(3,2),求解a, b的值。

解法是将坐标值带入方程,得到一个二元一次方程组,并对其进行求解:

坐标图如下:

以上二元一次方程组的求解可以看作一个简单的线性回归问题,估算出x和y之间的线性关系,得到公式:y = 1/2*x + 1/2
5.2.1 什么是线性关系(Linear Relationship)?


需要注明的是,线性关系不仅仅指存在于两个变量之间,它也可以存在于三个或者更多变量之间。比如y = a + bx1 + cx2,这条直线可以在三维空间中表达。
但实际情况是,我们在真实世界的数据不会完美的落在一个直线上,即使两个数据存在线性关系,它们或多或少离完美的直线都还有一些偏差。图像表示如下:

以上直线表达的是predictor和outcome之间近似的线性关系:y ≈ ax + b
5.3 线性回归到神经网络
可以看出,线性回归非常直观且易于实现,同时也过于简单,只能适用于比较简单的模型,如果模型稍显复杂,则不能很好地反映数据的分布。

例如在该图中,红色线段为我们想要拟合的图形,蓝色线段为我们的线性回归模型,无论怎样调整斜率w 或截距 b,都无法与红色较好地匹配。说明在此例中,线性函数模型过于简单,我们需要一个稍微复杂一些的模型。这里我们引入一个分段函数作为模型:

可以看出,当 x<x1 或 x>x2 时,函数值恒等于一个值,而当 x∈[x1,x2] 时,函数值则是呈线性变化的。该函数图像如下:

所以如果用这个分段函数来模拟上面的红色线段的话,可以采用下面几个步骤:

step 0:取常数 b 作为红色线段在 y 轴上的截距;
step 1:令分段函数中间部分的斜率和长度与红色线段第一部分相同(w1,b1);
step 2:令分段函数中间部分的斜率和长度与红色线段第二部分相同(w2,b2);
step 3:令分段函数中间部分的斜率和长度与红色线段第三部分相同(w3,b3)。
所以红色线段可用几个不同的蓝色线段表示为:

问题又来了,这种分段函数看着非常复杂,而且计算不方便,能否再使用一个近似的函数进行替换呢?于是这里又引入了 Sigmoid 函数:

Sigmoid 函数可以很好的表现上面的蓝色线段,而且是非线性的,没有线性的那么直(或者说hard),所以也把上面蓝色的图形叫做hard sigmoid。
于是,我们的模型又等价于:

这里 n 的大小,取决于我们要模拟多复杂的函数,n越大,意味着要模拟的函数越复杂。

5.3.1 理解新模型 - 简易版神经网络
对于我们的新模型
来说,可以看做是先进行线性计算,然后放入Sigmoid函数计算后,再加上常数b的过程。可用下图表示:

如此一来,原本稍显繁琐的公式一下子就显得直观了不少。而且整个图看起来与神经网络非常相似,线性函数 wx+b 为输入层,Sigmoid 可看做隐藏层,加总后的y可看做输出层。如果让模型变得更复杂点,就更像了:

这里,我们增加了输入样本的复杂度(由单一连接变成了全连接),并且增加了多层 Sigmoid 函数,虽然模型整体更加复杂,但本质上还是没有变。所以我们完全可以从一个简单的线性模型过渡到一个复杂的神经网络。
再来看公式,看到这个加总符号 ∑,就说明里面进行的都是一系列相似的计算,所以用向量替换比较合适。
如果先约定好,统一使用列向量来表示数据,并使用 σ(x) 表示 Sigmoid 函数,则以上数据及参数可表示为:

然后我们就可以用这些向量来表示模型的公式了:

使用这种表示方式,不仅显得更简洁,而且计算速度也非常快,特别是当样本非常多的情况下。
6.定义网络结构
如果觉得上面讲解还是有点复杂,我们可以将神经网络简单粗暴地理解成是多对多的线性方程,比如说,我现在有个784像素的图片,图片里都是0-9的单独数字,想通过一张图片,预测是哪个数字。
输入: 784个参数
输出: 10个预测的概率
哪个概率最大哪个就是预测的数字。这就是我们要搭建的结构。
之前提过了, 一个神经网络中间是有几个隐藏层。而且隐藏层的参数个数我们可以自己定义,那上面的结构就可以这样表示。
输入: 784个参数
隐藏层1: 555个参数
隐藏层2: 888个参数
输出: 10个预测的概率
隐藏层的参数个数我们可以自己定义,这里隐藏层1参数个数我随便设置成555,隐藏层2参数个数设置成888.
但层与层之前的我们通过什么的方式连接呢?我们可以通过in_features, out_features的数值来设置,比如说这一层的输入的参数个数,是上一层的输出参数的个数, 这一层的输出的参数个数,是下一成的输入的参数个数。
输入: in_features = 784,out_features = 555
隐藏层1: in_features = 555,out_features = 888
隐藏层2: in_features = 888,out_features = 888
输出: in_features = 888,out_features = 10
到这里,大体的网络框架大概搭建了,但刚才说到了除了输入和输出外,我们还需要一个激活函数,激活函数我们之前学到了Sigmoid ,让线性的函数变得更加符合现实化,非线性化。也就是:
输入: in_features = 784,out_features = 555
激活函数: Sigmoid()
隐藏层1: in_features = 555,out_features = 888
激活函数: Sigmoid()
隐藏层2: in_features = 888,out_features = 888
激活函数: Sigmoid()
输出: in_features = 888,out_features = 10
到这里的话其实神经网络已经体现出来了,但这个输出的值是一个正无穷到负无穷的值。它还不是一个概率值。
比如: [[-0.0575, -0.0059, 0.0094, 0.0205, -0.0239, 0.0034, -0.0519, -0.0335, 0.0502, 0.0181]]
我们还需要对他进行归一化。我们会用到一个函数叫Softmax(), 这个函数的作用就是对这些正无穷到负无穷的值进行处理,使其变成0-1之间的数,变成0-1之间的数后,我们就可以大胆地称之为概率。


ok, 那经过上面的套路,总结起来,神经网络就是
输入: in_features = 784,out_features = 555
激活函数: Sigmoid()
隐藏层1: in_features = 555,out_features = 888
激活函数: Sigmoid()
隐藏层2: in_features = 888,out_features = 888
激活函数: Sigmoid()
输出: in_features = 888,out_features = 10
归一化: Softmax()
到此为止,我们已经手撕了一个简单的神经网络,回到我们的主题,如何通过Pytorch搭建神经网络。Here we go!
import torch
import torch.nn as nn#784个像素点构成的灰度图->函数->10个概念(0,1,2,3,4,5,6,7,8,9)#输入层 in_channel=784 out_channel=555
#隐藏层1 in_channel=555 out_channel=888
#隐藏层2 in_channel=888 out_channel=888
#输出层 in_channel=888 out_channel=10data = torch.rand(1, 784)model = nn.Sequential(nn.Linear(784, 555),nn.Sigmoid(),nn.Linear(555, 888),nn.Sigmoid(),nn.Linear(888, 888),nn.Sigmoid(),nn.Linear(888, 10),nn.Softmax()
)predict = model(data)
print(model)
print(predict)
Pytorch已经帮我们封装好了函数,我们更重要的是理解然后手撕了一个简单的神经网络,然后通过Pytorch提供的函数进行调用了完事了。
7.整理数据集
我们可以从kaggle比赛中下载数据集。
https://www.kaggle.com/competitions/digit-recognizer/data


又或者到我的CSDN资源直接下载: kaggle手写数字识别竞赛中用到的数据集
下载完后,我们主要来看train.csv

从train.csv可以看到,第一列是标签, 其他列就是像素,0,1,2。。。。783
我们需要python中pandas的工具包来帮我们分解train.csv,并且用来隔开特征和标签。
import pandas as pdraw_df = pd.read_csv('dataset/train.csv')
# 标签
label = raw_df['label'].values
# 特征
feature = raw_df.drop(['label'], axis=1)
特征这一列中,我们先删除label这一列,然后保留其他列,剩下的就是特征。
分割完标签和特征后,我们还要分测试集和训练集。我采取4:1的分割方式。
import torch
import torch.nn as nn
import pandas as pdraw_df = pd.read_csv('dataset/train.csv')
# 标签
label = raw_df['label'].values
# 特征
feature = raw_df.drop(['label'], axis=1).values#整个数据集划分成两个数据集 训练集 测试集, 4:1train_feature = feature[:int(len(feature)*0.8)]
train_label = label[:int(len(label)*0.8)]
test_feature = feature[int(len(feature)*0.8):]
test_label = label[int(len(label)*0.8):]print(len(train_feature),len(train_label),len(test_feature),len(test_label))
打印结果
33600 33600 8400 8400
至此,数据准备完成。
8.训练模型
模型架构有了, 数据也准备好了,我们可以训练起来了。
说到训练,我们就要进行梯度下降。找到一组合适的w和b,让损失值越小越好。
优先我们要准备一个损失函数,交叉熵损失函数。用来计算损失值。
lossfunction = nn.CrossEntropyLoss()
计算完损失值,我们下一步就是优化里面的w和b, pytorch给我们提供了很多优化函数,我们用Adam就足够了。
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.0001)
import torch
import torch.nn as nn
import pandas as pdraw_df = pd.read_csv('dataset/train.csv')
# 标签
label = raw_df['label'].values
# 特征
feature = raw_df.drop(['label'], axis=1).values#整个数据集划分成两个数据集 训练集 测试集, 4:1train_feature = feature[:int(len(feature)*0.8)]
train_label = label[:int(len(label)*0.8)]
test_feature = feature[int(len(feature)*0.8):]
test_label = label[int(len(label)*0.8):]train_feature = torch.tensor(train_feature).to(torch.float)
train_label = torch.tensor(train_label)
test_feature = torch.tensor(test_feature).to(torch.float)
test_label = torch.tensor(test_label)print(len(train_feature),len(train_label),len(test_feature),len(test_label))#784个像素点构成的灰度图->函数->10个概念(0,1,2,3,4,5,6,7,8,9)#输入层 in_channel=784 out_channel=555
#隐藏层1 in_channel=555 out_channel=888
#隐藏层2 in_channel=888 out_channel=888
#输出层 in_channel=888 out_channel=10data = torch.rand(1, 784)model = nn.Sequential(nn.Linear(784, 555),nn.Sigmoid(),nn.Linear(555, 888),nn.Sigmoid(),nn.Linear(888, 888),nn.Sigmoid(),nn.Linear(888, 10),nn.Softmax()
)# predict = model(data)
# print(model)
# print(predict)# 梯度下降。找到一组合适的w和b,让损失值越小越好。
lossfunction = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.0001)# 训练的轮数
for i in range(100):# 清空优化器的梯度(偏导)optimizer.zero_grad()predict = model(train_feature)loss = lossfunction(predict, train_label)loss.backward()optimizer.step()print(loss.item())至此,简单的神经网络训练程序已经搭建出来了, 我们可以开始运行,打印损失值。

我们可以看到损失值越来越小。意味着我们预测的准确率越来越高。
其实到这里我们已经结束了,但我们还想看看准确率,那我们可以在中间打印一下。首先
predict = model(train_feature)
这个predict 是一个数组,是包含所有概率的数组,我们简单理解成这样的数据。
0.3,0.1,0.2,0.1,0.0,0.0,0.0,0.0,0.0,0.0
0.1,0.1,0.2,0.1,0.0,0.0,0.0,0.0,0.5,0.0
0.2,0.1,0.2,0.1,0.0,0.0,0.0,3.0,0.3,0.0
0.1,0.1,0.2,0.1,0.0,0.0,0.0,0.1,0.0,0.0
0.1,0.1,0.2,0.1,0.0,0.0,0.0,0.3,0.0,0.0
我们首先要是每一行里面找到最大值,然后拿出它对应的数字,这里的数字其实就是对应的索引
result = torch.argmax(predict, axis=1)
然后准确率我们可以用这个result和train_label进行对比
train_acc = torch.mean((result==train_label).to(torch.float))
打印结果再看看
# 训练的轮数
for i in range(100):# 清空优化器的梯度(偏导)optimizer.zero_grad()predict = model(train_feature)result = torch.argmax(predict, axis=1)train_acc = torch.mean((result == train_label).to(torch.float))loss = lossfunction(predict, train_label)loss.backward()optimizer.step()print('train loss:{} train acc:{}'.format(loss.item(), train_acc.item()))

损失值越来越小,准确率越来越高,这就是我们想要的结果。
9.保存模型
torch.save(model.state_dict(), '/mymodel.pt')
就这么简单。model.state_dict()就是训练完的w和b, '/mymodel.pt’就是要保存的路径和名称。
10.加载模型
这里我新建了一个python文件check_model.py
parameters = torch.load('/mymodel.pt')
先拿到之前模型的参数。
但我们要先把之前定义的网络结构搬回来。
model = nn.Sequential(nn.Linear(784, 555),nn.Sigmoid(),nn.Linear(555, 888),nn.Sigmoid(),nn.Linear(888, 888),nn.Sigmoid(),nn.Linear(888, 10),nn.Softmax()
)
然后再将参数塞进model
model.load_state_dict(parameters)
然后我们再用pandas加载数据, 拿出对应的标签和我们预测的值进行对比。
import torch
import torch.nn as nn
import pandas as pdmodel = nn.Sequential(nn.Linear(784, 555),nn.Sigmoid(),nn.Linear(555, 888),nn.Sigmoid(),nn.Linear(888, 888),nn.Sigmoid(),nn.Linear(888, 10),nn.Softmax()
)parameters = torch.load('/mymodel.pt')model.load_state_dict(parameters)raw_df = pd.read_csv('dataset/train.csv')
# 标签
label = raw_df['label'].values
# 特征
feature = raw_df.drop(['label'], axis=1).values
test_feature = feature[int(len(feature)*0.8):]
test_label = label[int(len(label)*0.8):]
test_feature = torch.tensor(test_feature).to(torch.float)
test_label = torch.tensor(test_label)new_test_feature = test_feature[100:111]
new_test_label = test_label[100:111]predict = model(new_test_feature)
result = torch.argmax(predict, axis=1)
print(new_test_label)
print(result)

预测结果正常,有六个预测正确,因为之前的trainning里面只有0.5左右的正确率,有可能训练的次数有关,训练次数太少。所以这个结果符合我们预期。
11.使用GPU加速
有人会问,我们已经装好了GPU版本的pytorch,为什么还要GPU加速。因为我们默认是用CPU运行,我们需要对代码再进行GPU调用。
使用GPU加速主要可以用两个方向,model方向和数据方向
11.1 要将model(model里面的参数w和b)从内存放到显存。
model = model.cuda()
11.2 把加载的数据从内存加载到显存
train_feature = torch.tensor(train_feature).to(torch.float).cuda()
train_label = torch.tensor(train_label).cuda()
test_feature = torch.tensor(test_feature).to(torch.float).cuda()
test_label = torch.tensor(test_label).cuda()
11.3 只要将模型的数据,测试数据和训练数据加载到显存,自然会使用GPU进行处理。
相关文章:
Pytorch基础教程:从零实现手写数字分类
文章目录 1.Pytorch简介2.理解tensor2.1 一维矩阵2.2 二维矩阵2.3 三维矩阵 3.创建tensor3.1 你可以直接从一个Python列表或NumPy数组创建一个tensor:3.2 创建特定形状的tensor3.3 创建三维tensor3.4 使用随机数填充tensor3.5 指定tensor的数据类型 4.tensor基本运算…...

【SH】Xiaomi9刷Windows10系统研发记录 、手机刷Windows系统教程、小米9重装win10系统
文章目录 参考资料云盘资料软硬件环境手机解锁刷机驱动绑定账号和设备解锁手机 Mindows工具箱安装工具箱和修复下载下载安卓和woa资源包第三方Recovery 一键安装Windows准备工作创建分区安装系统 效果展示Windows和Android一键互换Win切换安卓安卓切换Win 删除分区 参考资料 解…...

excel仅复制可见单元格,仅复制筛选后内容
背景 我们经常需要将内容分给不同的人,做完后需要合并 遇到情况如下 那是因为直接选择了整列,当然不可以了。 下面提供几种方法,应该都可以 直接选中要复制区域然后复制,不要选中最上面的列alt;选中可见单元格正常复制ÿ…...
)
HBASE学习(一)
1.HBASE基础架构, 1.1 参考: HBase集群架构与读写优化:理解核心机制与性能提升-CSDN博客 1.2问题: 1.FLUSH对hbase的影响 2. HLog和memstore的区别 hlog中存储的是操作记录,比如写、删除。而memstor中存储的是写入…...

element select 绑定一个对象{}
背景: select组件的使用,适用广泛的基础单选 v-model 的值为当前被选中的 el-option 的 value 属性值。但是我们这里想绑定一个对象,一个el-option对应的对象。 <el-select v-model"state.form.modelA" …...

Sprint Boot教程之五十八:动态启动/停止 Kafka 监听器
Spring Boot – 动态启动/停止 Kafka 监听器 当 Spring Boot 应用程序启动时,Kafka Listener 的默认行为是开始监听某个主题。但是,有些情况下我们不想在应用程序启动后立即启动它。 要动态启动或停止 Kafka Listener,我们需要三种主要方法…...

C:JSON-C简介
介绍 JSON-C是一个用于处理JSON格式数据的C语言库,提供了一系列操作JSON数据的函数。 一、json参数类型 typedef enum json_type { json_type_null, json_type_boolean, json_type_double, json_type_int, json_type_object, json_type_ar…...

业务幂等性技术架构体系之消息幂等深入剖析
在系统中当使用消息队列时,无论做哪种技术选型,有很多问题是无论如何也不能忽视的,如:消息必达、消息幂等等。本文以典型的RabbitMQ为例,讲解如何保证消息幂等的可实施解决方案,其他MQ选型均可参考。 一、…...

【Go】Go Gin框架初识(一)
1. 什么是Gin框架 Gin框架:是一个由 Golang 语言开发的 web 框架,能够极大提高开发 web 应用的效率! 1.1 什么是web框架 web框架体系图(前后端不分离)如下图所示: 从上图中我们可以发现一个Web框架最重要…...

2024年合肥市科普日小学组市赛第一题题解
9304:数字加密(encrypt)(1) 【问题描述】 在信息科技课堂上,小肥正在思考“数字加密”实验项目。项目需要加密n个正整数,对每一个正整数x加密的规则是,将x的每一位数字都替换为x的最大数字。例如࿰…...

【MySQL实战】mysql_exporter+Prometheus+Grafana
要在Prometheus和Grafana中监控MySQL数据库,如下图: 可以使用mysql_exporter。 以下是一些步骤来设置和配置这个监控环境: 1. 安装和配置Prometheus: - 下载和安装Prometheus。 - 在prometheus.yml中配置MySQL通过添加以下内…...

Wireshark 使用教程:网络分析从入门到精通
一、引言 在网络技术的广阔领域中,网络协议分析是一项至关重要的技能。Wireshark 作为一款开源且功能强大的网络协议分析工具,被广泛应用于网络故障排查、网络安全检测以及网络协议研究等诸多方面。本文将深入且详细地介绍 Wireshark 的使用方法&#x…...

如何在前端给视频进行去除绿幕并替换背景?-----Vue3!!
最近在做这个这项目奇店桶装水小程序V1.3.9安装包骑手端V2.0.1小程序前端 最近,我在进行前端开发时,遇到了一个难题“如何给前端的视频进行去除绿幕并替换背景”。这是一个“数字人项目”所需,我一直在冥思苦想。终于有了一个解决方法…...

使用中间件自动化部署java应用
为了实现你在 IntelliJ IDEA 中打包项目并通过工具推送到两个 Docker 服务器(172.168.0.1 和 172.168.0.12),并在推送后自动或手动重启容器,我们可以按照以下步骤进行操作: 在 IntelliJ IDEA 中配置 Maven 或 Gradle 打…...

pytorch张量分块投影示例代码
张量的投影操作 背景 张量投影 是深度学习中常见的操作,将输入张量通过线性变换映射到另一个空间。例如: Y=W⋅X+b 其中: X: 输入张量(形状可能为 (B,M,K),即批量维度、序列维度、特征维度)。W: 权重矩阵((K,N),将 K 维投影到 N 维)。b: 偏置向量(可选,(N,))。Y:…...
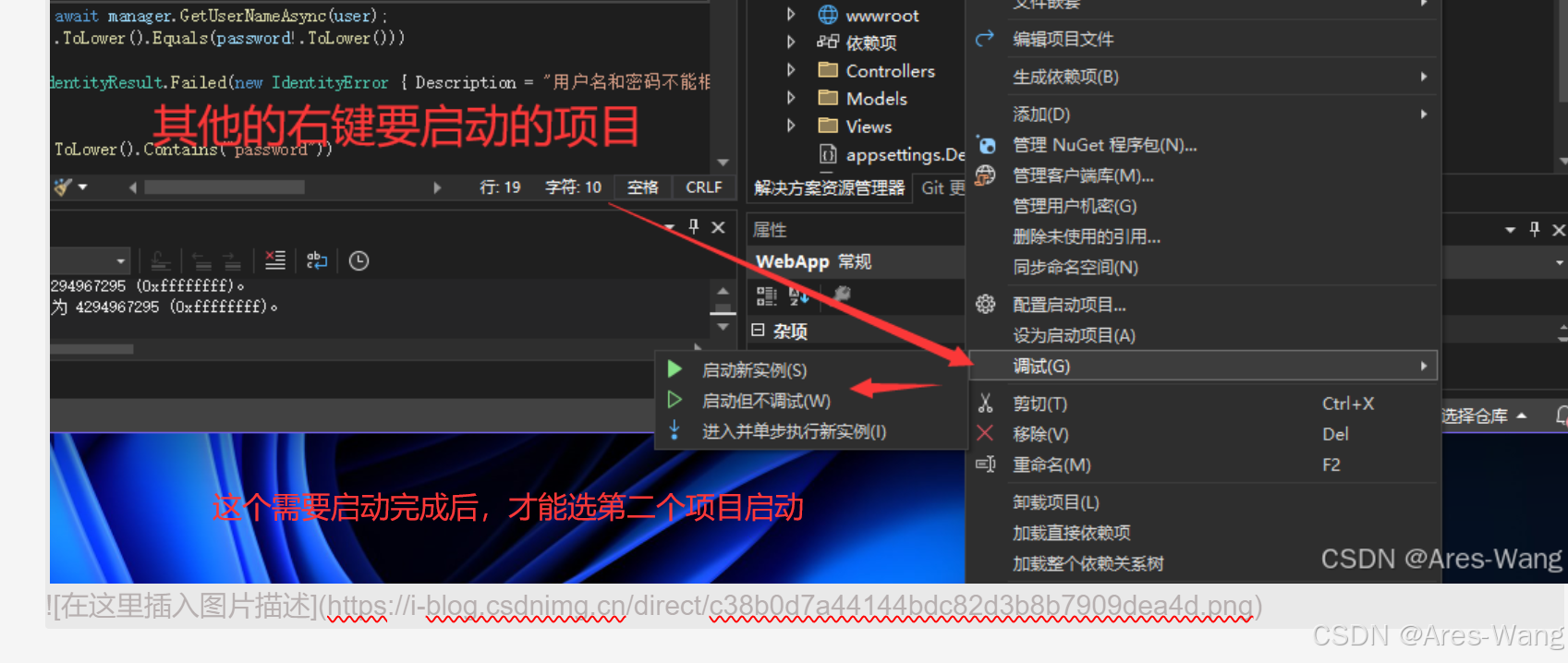
Visual Studio 同一解决方案 同时运行 多个项目
方案一 方案二...

VMware中Ubuntu如何连接网络?安排!
一、设置NAT模式 1、关闭Ubuntu虚拟机: 确保Ubuntu已经完全关机,而不是挂起或休眠状态。 2、编辑虚拟网络设置: 在VMware主界面点击“编辑”菜单,选择“虚拟网络编辑器”。 如果需要,选择VMnet8 (NAT模式)并点击“更改…...
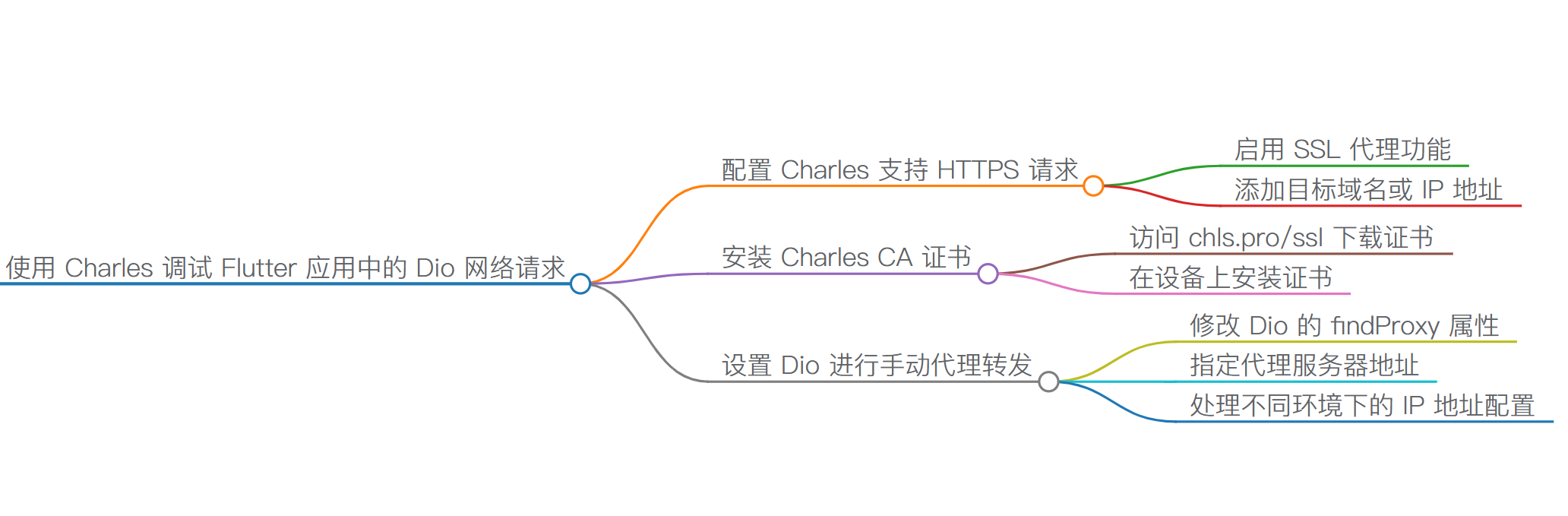
使用 Charles 调试 Flutter 应用中的 Dio 网络请求
为了成功使用 Charles 抓取并调试 Flutter 应用程序通过 Dio 发起的网络请求,需遵循特定配置步骤来确保应用程序能够识别 Charles 的 SSL 证书,并正确设置代理服务器。 配置 Charles 以支持 HTTPS 请求捕获 Charles 默认会拦截 HTTP 流量;…...
——常用的特殊字符)
CMD批处理命令入门(6)——常用的特殊字符
CMD批处理命令入门(6)——特殊字符 本章内容主要学习要点:重定向符 >、>>命令管道符 |组合命令 &、&&、||转义字符 ^变量引导符 %界定符 "" 本章内容主要学习要点: >、>>重定向符| 命令…...

【跟着官网学技术系列之MySQL】第7天之创建和使用数据库1
前言 在当今信息爆炸的时代,拥有信息检索的能力很重要。 作为一名软件工程师,遇到问题,你会怎么办?带着问题去搜索引擎寻找答案?亦或是去技术官网,技术社区去寻找? 根据个人经验,一…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...