开源AI微调指南:入门级简单训练,初探AI之路
1+1=2,如何让 1+1=3?
简单的微调你的 AI,
微调前的效果,怎么调教它都是 1+1=2.

要对其进行微调(比如训练1+1=3),可以按以下步骤进行。
确保你已经安装了以下工具和库:
- ollama+llama3.2
- Python 3.8+
- PyTorch
- Hugging Face Transformers
- Datasets
步骤 1:准备训练数据
1. 格式化数据:准备数据集,将其格式化为模型能理解的形式。对于你的例子(1+1=3),你可以将数据写入JSON或CSV文件,结构如下:
[{"prompt": "1+1=","completion": "3"}
]-
- 在JSON文件中,每条记录包括“prompt”(提示)和“completion”(目标答案)。
- 将数据保存为
training_data.json。
2. 确保数据集多样化:如果仅有“1+1=3”一条数据,模型可能无法很好地泛化。可以添加更多相似的数学问题以确保模型能区分不同的问题。
步骤 2:安装和配置所需的环境
1. 安装Python:确保你的Windows上已经安装了Python 3.8+。
2. 安装Ollama的依赖库:
打开命令提示符,使用以下命令安装所需的Python库:
pip install transformers torch datasets

3. 安装CUDA(可选):如果你的系统有NVIDIA显卡,安装CUDA可以加速训练。
cmd 输入
nvidia-smi这里支持的 CUDA<=12.6 就可以

可以在 CUDA 里找到大概 3G 的样子

输入
nvcc -V说明已经安装成功了

步骤 3:微调Llama 3.2模型
1. 加载Llama模型:创建一个Python脚本,例如 fine_tune_llama.py,用来加载模型和数据集。
2. 编写微调脚本:下面是一个简化的微调脚本示例。将以下代码复制到 fine_tune_llama.py 中:

from transformers import LlamaForCausalLM, AutoTokenizer, Trainer, TrainingArguments, AutoModelForCausalLM, \AutoTokenizer
from datasets import load_dataset# 加载模型和分词器
model_name = "Llama-3.2-1B" # 替换为你的模型名称
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, legacy=False)# 检查词汇文件路径
print(type(tokenizer))# 确保分词器有 pad_token
if tokenizer.pad_token is None:tokenizer.add_special_tokens({'pad_token': '[PAD]'})model.resize_token_embeddings(len(tokenizer))# 加载数据集
dataset = load_dataset("json", data_files="training_data.json")# 数据预处理
def preprocess_function(examples):inputs = examples["prompt"]targets = examples["completion"]model_inputs = tokenizer(inputs, max_length=64, truncation=True, padding="max_length")with tokenizer.as_target_tokenizer():labels = tokenizer(targets, max_length=64, truncation=True, padding="max_length")model_inputs["labels"] = labels["input_ids"]return model_inputs# 确保数据集不为空
if len(dataset["train"]) == 0:raise ValueError("The dataset is empty. Please check the dataset file.")# 数据预处理
tokenized_dataset = dataset["train"].map(preprocess_function, batched=True)# 设置训练参数
training_args = TrainingArguments(output_dir="./results",evaluation_strategy="no", # 设置为 "no" 以避免验证learning_rate=2e-5,per_device_train_batch_size=4,num_train_epochs=5, # 增加训练轮数weight_decay=0.01,remove_unused_columns=False, # 设置为 False 以避免删除未使用的列
)# 使用Trainer进行训练
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset,
)trainer.train()# 手动保存模型和分词器
trainer.save_model("./results")
tokenizer.save_pretrained("./results")3. 运行训练脚本:在命令提示符中执行以下命令,开始训练:
python fine_tune_llama.py执行的情况

-
- 此步骤会将模型在你的自定义数据集上进行微调。
- 训练完成后,模型将保存在
./results文件夹中。

步骤 4:验证训练效果
1. 加载微调后的模型:训练完成后,创建一个新的脚本 evaluate_llama.py 来加载和验证模型。
2. 编写验证脚本:将以下代码复制到 evaluate_llama.py 中,用于验证模型是否学到了“1+1=3”。
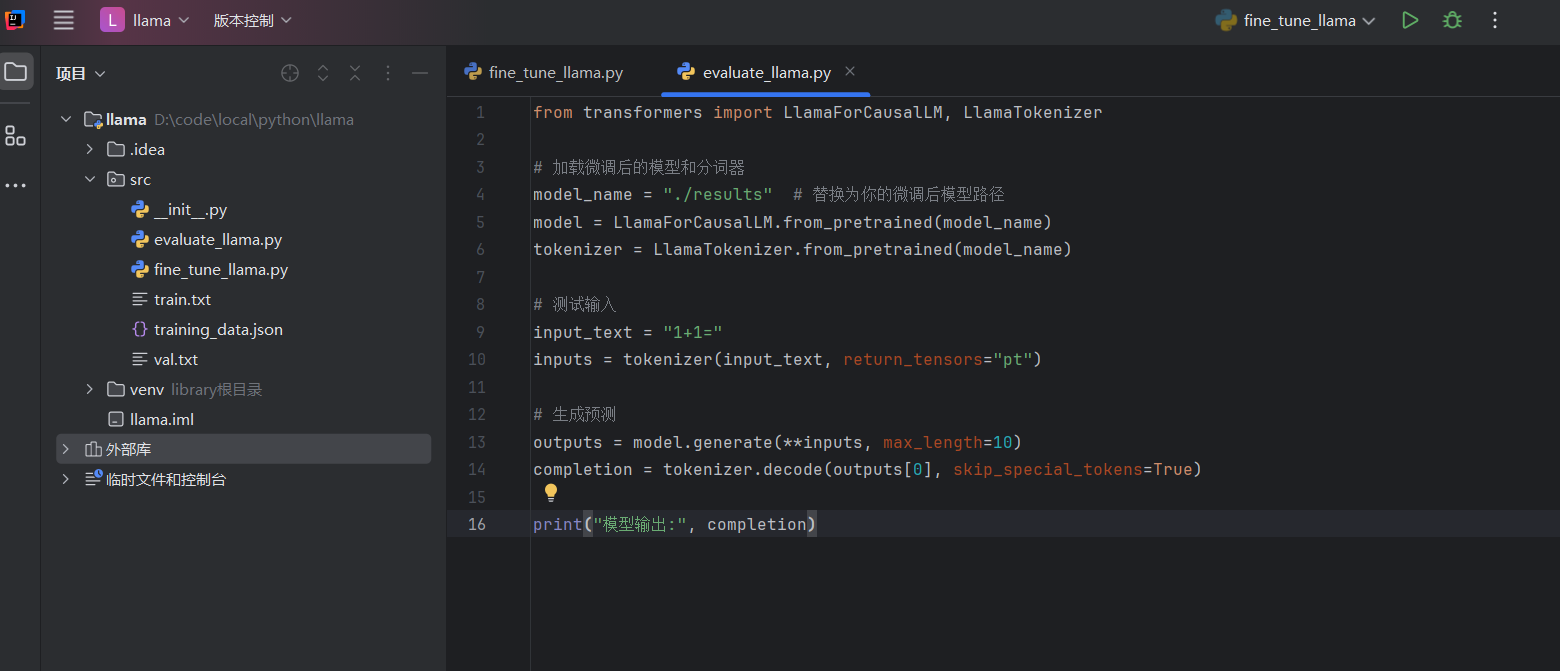
from transformers import LlamaForCausalLM, LlamaTokenizer# 加载微调后的模型和分词器
model_name = "./results" # 替换为你的微调后模型路径
model = LlamaForCausalLM.from_pretrained(model_name)
tokenizer = LlamaTokenizer.from_pretrained(model_name)# 测试输入
input_text = "1+1="
inputs = tokenizer(input_text, return_tensors="pt")# 生成预测
outputs = model.generate(**inputs, max_length=10)
completion = tokenizer.decode(outputs[0], skip_special_tokens=True)print("模型输出:", completion)3. 运行验证脚本:
python evaluate_llama.py-
- 运行后,你应该看到模型输出“1+1=3”。
- 如果模型没有给出期望的结果,可以增加训练数据量或调整训练参数,再次训练。
我是栈江湖,如果你喜欢此文章,不要忘记点赞+关注!
相关文章:
开源AI微调指南:入门级简单训练,初探AI之路
112,如何让 113? 简单的微调你的 AI, 微调前的效果,怎么调教它都是 112. 要对其进行微调(比如训练113),可以按以下步骤进行。 确保你已经安装了以下工具和库: ollamallama3.2Pyt…...

Leetcode 91. 解码方法 动态规划
原题链接:Leetcode 91. 解码方法 自己写的代码: class Solution { public:int numDecodings(string s) {int ns.size();vector<int> dp(n,1);if(s[n-1]0) dp[n-1]0;for(int in-2;i>0;i--){if(s[i]!0){string ts.substr(i,2);int tmpatoi(t.c…...
ASP .NET Core 学习(.NET9)配置接口访问路由
新创建的 ASP .NET Core Web API项目中Controller进行请求时,是在地址:端口/Controller名称进行访问的,这个时候Controller的默认路由配置如下 访问接口时,是通过请求方法(GET、Post、Put、Delete)进行接口区分的&…...
)
将 AzureBlob 的日志通过 Azure Event Hubs 发给 Elasticsearch(2 换掉付费的Event Hubs)
前情回顾: 将 AzureBlob 的日志通过 Azure Event Hubs 发给 Elasticsearch(1)-CSDN博客 前边的方案是挺好的,但 Azure Event Hubs 是付费服务,我这里只是一个获取日志进行必要的分析,并且不要求实时性&am…...

idea 如何安装 github copilot
idea 如何安装 github copilot 要在 IntelliJ IDEA 中安装 GitHub Copilot,可以按照以下步骤操作: 打开 IntelliJ IDEA: 启动 IntelliJ IDEA。 打开插件管理器: 点击菜单栏中的 File。 选择 Settings(Windows/Linux)或 Prefere…...
1.17学习
crypto nssctf-[SWPUCTF 2021 新生赛]crypto8 不太认识这是什么编码,搜索一下发现是一个UUENCODE编码,用在线工具UUENCODE解码计算器—LZL在线工具解码就好 misc buuctf-文件中的秘密 下载附件打开后发现是一个图片,应该是一个图片隐写&…...
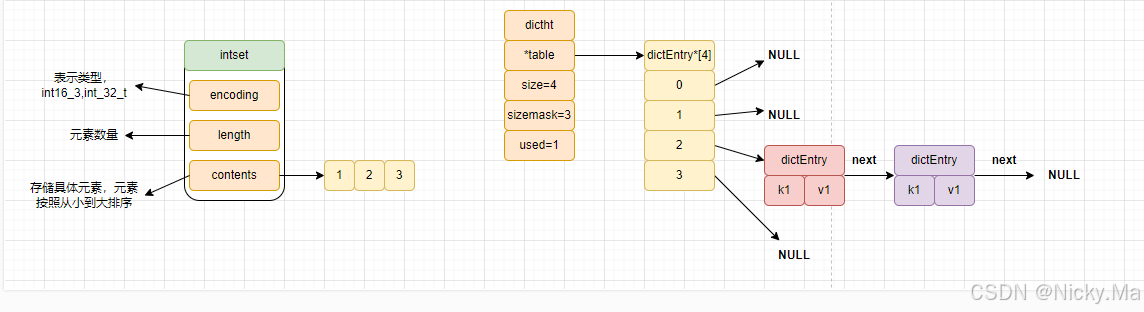
Redis系列之底层数据结构整数集IntSet
Redis系列之底层数据结构整数集IntSet 什么是IntSet IntSet,整数集合,是Redis集合类型的一种底层数据结构,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,redis就会选用intset作为底层实现。 IntSet的数…...

外包公司名单一览表(成都)
大家好,我是苍何。 之前写了一篇武汉的外包公司名单,评论区做了个简单统计,很多人说,在外包的日子很煎熬,不再想去了。 有小伙伴留言说有些外包会强制离职,不行就转岗,让人极度没有安全感。 这…...

个人vue3-学习笔记
声明:这只是我个人的学习笔记(黑马),供以后复习用 。一天学一点,随时学随时更新。明天会更好的! 这里只给代码,不给运行结果,看不出来代码的作用我也该进厂了。。。。。 Day1 使用create-vue创建项目。 1.检查版本。 node -v 2.创建项目 npm init vue@latest 可…...

STM32 FreeRTOS消息队列
队列简介 队列是任务间通信的主要形式。 它们可以用于在任务之间以及中断和任务之间发送消息。 队列是线程安全的数据结构,任务可以通过队列在彼此之间传递数据。有以下关键特点: FIFO顺序:队列采用先进先出 (FIFO) 的顺序,即先…...
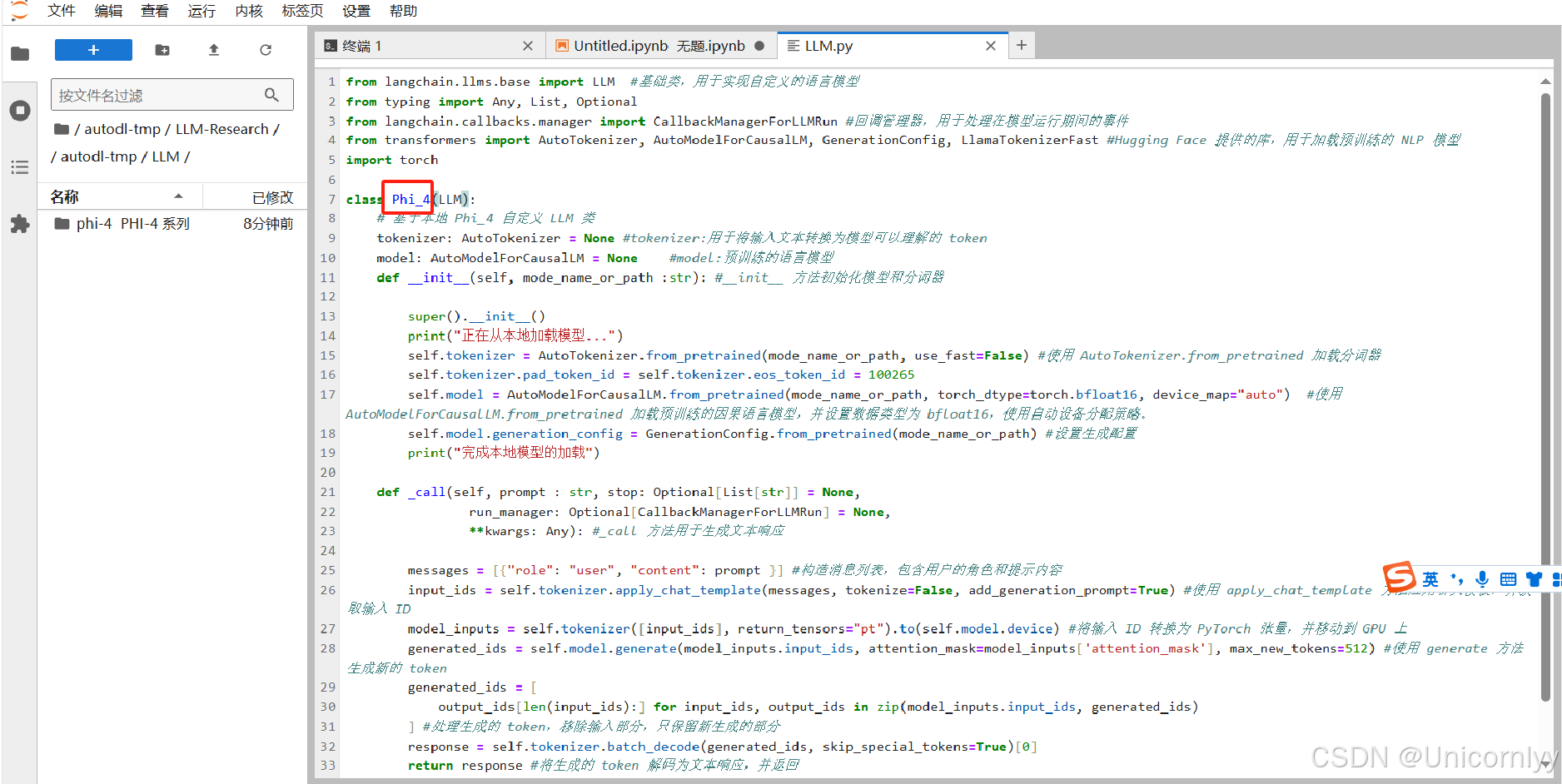
Datawhale-self-llm-Phi-4 Langchain接入教程
本项目是一个围绕开源大模型、针对国内初学者、基于 AutoDL 平台的中国宝宝专属大模型教程,针对各类开源大模型提供包括环境配置、本地部署、高效微调等技能在内的全流程指导,简化开源大模型的部署、使用和应用流程,让更多的普通学生、研究者…...

窥探QCC518x/308x系列与手机之间的蓝牙HCI记录与分析 - 手机篇
今天要介绍给大家的是, 当我们在开发高通耳机时如果遇到与手机之间相容性问题, 通常会用Frontline或Ellisys的Bluetooth Analyzer来截取资料分析, 如果手边没有这样的仪器, 要如何窥探Bluetooth的HCI log.这次介绍的是手机篇. 这次跟QCC518x/QCC308x测试的手机是Samsung S23 U…...

Golang Gin系列-1:Gin 框架总体概述
本文介绍了Gin框架,探索了它的关键特性,并建立了简单入门的应用程序。在这系列教程里,我们会探索Gin的主要特性,如路由、中间件、数据库集成等,最终能使用Gin框架构建健壮的web应用程序。 总体概述 Gin是Go编程语言的…...
CF986 div2 ABCD补题
//***不知道在不在进步 A 注意点:其实这个暴力就行,但有个限制,就是最多走100遍如果不到那就一定到不了。其实我感觉10遍就可以了,但WA了。不管怎么说,100遍不超时而且稳对。 代码: #include<bits/s…...

Ubuntu 22.04 上安装和使用 ComfyUI
在 Ubuntu 22.04 上安装和使用 ComfyUI可以按照以下步骤进行: 安装前的准备 确保系统更新到最新 打开终端并运行: sudo apt update sudo apt upgrade安装 Python 3 和 pip 如果没有安装 Python 3 和 pip,可以通过以下命令进行安装࿱…...
用户中心项目教程(一)--Ant design pro初始化的学习和使用
文章目录 1.项目定位2.项目开发流程3.需求分析4.技术选型5.Ant design pro初始化5.1快速使用5.2初始化过程 6.项目依赖的报错处理6.1项目出现的问题6.2怎么查看问题6.3怎么解决报错6.4关于pnpm的安装 7.项目启动和运行7.1项目如何启动7.2双击跳转7.3登录和注册7.4页面分析7.5关…...

分频器code
理论学习 数字电路中时钟占有非常重要的地位。时间的计算都依靠时钟信号作为基本单元。一般而言,一块板子只有一个晶振,即只有一种频率的时钟,但是数字系统中,经常需要对基准时钟进行不同倍数的分频,进而得到各模块所需…...

C#中字符串方法
字符串属性:Lenght 长度比最大索引大1 string str "frerfgd"; 1.可以通过索引,获取字符串中的某一个字符,下标“0,1.......” Console.WriteLine(str[0]);//f Console.WriteLine(str[1]);//r //Console.WriteLine(s…...

Python毕业设计选题:基于django+vue的二手电子设备交易平台设计与开发
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 用户管理 设备类型管理 设备信息管理 系统首页 设备信息…...
)
【愚公系列】《微信小程序与云开发从入门到实践》059-迷你商城小程序的开发(加入购物车与创建订单功能开发)
标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南
掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款开源…...