语音技术在播客领域的应用(2)
播客是以语音为主,各种基于AI 的语音技术在播客领域十分重要。
语音转文本
Whisper
Whisper 是OpenAI 推出的开源语音辨识工具,可以把音档转成文字,支援超过50 种语言。这款工具是基于68 万小时的训练资料,其中包含11.7 万小时的多语言语音数据,涵盖了96 种不同语言。由于资料量庞大,Whisper 在英文的识别精准度相当高,而中文的错误率(Word Error Rate, WER)大约是14.7%,表现也不俗。
Whisper 这个名字来自 WSPSR:Web-scale Supervised Pretraining for Speech Recognition
文本转语音(TTS)
TTS(Text-to-Speech)是文本转语音的技术。现代都采用深度学习模型,通常基于 Transformer 或类似架构。OpenAI ,微软,Google和国内大厂云平台都提供了TTS 服务。这项技术已经相当成熟。
最近提到的MaskGCT 是比较好的TTS,特别是声音克隆做的非常好。
可以在这里试试
魔搭社区
语音分析
pyannote-audio
实现播客中发言人分离,它将区分说话者 A 和说话者 B 等等。如果您想要更具体的内容(即说话者的实际姓名),那么您可以实现类似这样的功能。
Whisper 转录的准确性非常好,但不幸的是,它们没有说话人识别功能。
说话人识别功能是使用一个名为 pyannote 的 Python 库实现
pyannote 是说话者分离的开源项目。
pydub
Pydub 是一个功能强大的 Python 库,可简化处理音频文件的过程。它提供了一个用于处理音频的高级界面,使执行加载、切片、连接和将效果应用于音频文件等任务变得容易。他处理的原始音频wav 文件
API 介绍:pydub/API.markdown at master · jiaaro/pydub · GitHub
打开一个wav 文件
from pydub import AudioSegmentsong = AudioSegment.from_wav("never_gonna_give_you_up.wav")或者
song = AudioSegment.from_mp3("never_gonna_give_you_up.mp3")音频切片
# pydub does things in milliseconds
ten_seconds = 10 * 1000first_10_seconds = song[:ten_seconds]last_5_seconds = song[-5000:]指定音频的切片
# 从3秒开始切割,持续1秒
clip = song[3000:4000] # 从3秒到4秒的音频片段导出文件
from pydub import AudioSegment
sound = AudioSegment.from_file("/path/to/sound.wav", format="wav")# simple export
file_handle = sound.export("/path/to/output.mp3", format="mp3")# more complex export
file_handle = sound.export("/path/to/output.mp3",format="mp3",bitrate="192k",tags={"album": "The Bends", "artist": "Radiohead"},cover="/path/to/albumcovers/radioheadthebends.jpg")# split sound in 5-second slices and export
for i, chunk in enumerate(sound[::5000]):with open("sound-%s.mp3" % i, "wb") as f:chunk.export(f, format="mp3")静音切片(silence.split_on_silence())
根据音频文件中的静音分段。
from pydub import AudioSegment
from pydub.silence import split_on_silencesound = AudioSegment.from_mp3("audio_files/xxxxxx.mp3")
clip = sound[21*1000:45*1000]#"graph" the volume in 1 second increments
for x in range(0,int(len(clip)/1000)):print(x,clip[x*1000:(x+1)*1000].max_dBFS)chunks = split_on_silence(clip,min_silence_len=1000,silence_thresh=-16,keep_silence=100
)print("number of chunks",len(chunks))
print (chunks)实例
from pydub import AudioSegment
from pydub.playback import play
# 示例代码:音频切割
def cut_audio(source_file_path, output_file_path, start_second, end_second):# 加载音频文件song = AudioSegment.from_file(source_file_path)# 选择要切割的音频段segment = song[start_second:end_second]# 导出切割后的音频文件segment.export(output_file_path, format="mp3")
# 示例代码:音频合并
def merge_audio(filepaths, output_file_path):combined = AudioSegment.empty()for filepath in filepaths:# 加载单个音频文件并添加到合并列表audio = AudioSegment.from_file(filepath)combined += audio# 导出合并后的音频文件combined.export(output_file_path, format="mp3")
cut_audio('example.mp3', 'cut_example.mp3', 10, 20) # 从第10秒到第20秒切割音频
merge_audio(['part1.mp3', 'part2.mp3', 'part3.mp3'], 'merged_example.mp3') # 合并三个音频文件应用程序
方法1 先转换,再将文字分段
from pyannote.core import Segment
import os
import whisper
from pyannote.audio import Pipeline
def get_text_with_timestamp(transcribe_res):timestamp_texts = []print(transcribe_res["text"])for item in transcribe_res["segments"]:print(item)start = item["start"]end = item["end"]text = item["text"].strip()timestamp_texts.append((Segment(start, end), text))return timestamp_textsdef add_speaker_info_to_text(timestamp_texts, ann):spk_text = []for seg, text in timestamp_texts:spk = ann.crop(seg).argmax()spk_text.append((seg, spk, text))return spk_textdef merge_cache(text_cache):sentence = ''.join([item[-1] for item in text_cache])spk = text_cache[0][1]start = round(text_cache[0][0].start, 1)end = round(text_cache[-1][0].end, 1)return Segment(start, end), spk, sentencePUNC_SENT_END = [',', '.', '?', '!', ",", "。", "?", "!"]def merge_sentence(spk_text):merged_spk_text = []pre_spk = Nonetext_cache = []for seg, spk, text in spk_text:if spk != pre_spk and pre_spk is not None and len(text_cache) > 0:merged_spk_text.append(merge_cache(text_cache))text_cache = [(seg, spk, text)]pre_spk = spkelif text and len(text) > 0 and text[-1] in PUNC_SENT_END:text_cache.append((seg, spk, text))merged_spk_text.append(merge_cache(text_cache))text_cache = []pre_spk = spkelse:text_cache.append((seg, spk, text))pre_spk = spkif len(text_cache) > 0:merged_spk_text.append(merge_cache(text_cache))return merged_spk_textdef diarize_text(transcribe_res, diarization_result):timestamp_texts = get_text_with_timestamp(transcribe_res)spk_text = add_speaker_info_to_text(timestamp_texts, diarization_result)res_processed = merge_sentence(spk_text)return res_processeddef write_to_txt(spk_sent, file):with open(file, 'w') as fp:for seg, spk, sentence in spk_sent:line = f'{seg.start:.2f} {seg.end:.2f} {spk} {sentence}\n'fp.write(line)model_size = "large-v3"
os.environ['OPENAI_API_KEY'] ="sk-ZqGx7uD7sHMyITyIrxFDjbvVEAi84izUGGRwN23N9NbnqTbL"
os.environ['OPENAI_BASE_URL'] ="https://api.chatanywhere.tech/v1"
asr_model=whisper.load_model("large-v3")print("model loaded")
audio = "asr_speaker_demo.wav"
spk_rec_pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token="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")
asr_result = asr_model.transcribe(audio, language="zh", fp16=False)
print("transcribe finished....")
diarization_result = spk_rec_pipeline(audio)
print("diarization finished...")
final_result = diarize_text(asr_result, diarization_result)
for segment, spk, sent in final_result:print("[%.2fs -> %.2fs] %s \n %s 。\n" % (segment.start, segment.end, spk,sent))
方法2 先分段,再转换
分段转换,export 段的语音文件,然后分段转换。
import os
import whisper
from pyannote.audio import Pipeline
from pydub import AudioSegment
os.environ['OPENAI_API_KEY'] ="sk-ZqGx7uD7sHMyITyIrxFDjbvVEAi84izUGGRwN23N9NbnqTbL"
os.environ['OPENAI_BASE_URL'] ="https://api.chatanywhere.tech/v1"
model = whisper.load_model("large-v3")
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1",use_auth_token="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")# run the pipeline on an audio file
diarization = pipeline("buss.wav")
audio = AudioSegment.from_wav("buss.wav")
i=0
for turn, _, speaker in diarization.itertracks(yield_label=True):print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")clip = audio[turn.start*1000:turn.end*1000]with open("audio-%s.wav" % i, "wb") as f:clip.export(f, format="wav")text = model.transcribe("audio-%s.wav"% i,language="zh", fp16=False)["text"]print(text) i=i+1
方法3 直接导入语音片段,再转换
将Segments 转换成语音数据数组,然后分段转换。
import os
import whisper
import numpy as np
from pyannote.audio import Pipeline
from pydub import AudioSegment
os.environ['OPENAI_API_KEY'] ="sk-ZqGx7uD7sHMyITyIrxFDjbvVEAi84izUGGRwN23N9NbnqTbL"
os.environ['OPENAI_BASE_URL'] ="https://api.chatanywhere.tech/v1"
model = whisper.load_model("large-v3")
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1",use_auth_token="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")# run the pipeline on an audio file
diarization = pipeline("buss.wav")
audio = AudioSegment.from_wav("buss.wav")
i=0
for turn, _, speaker in diarization.itertracks(yield_label=True):print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")audio_segment = audio[turn.start*1000:turn.end*1000]if audio_segment.frame_rate != 16000: # 16 kHzaudio_segment = audio_segment.set_frame_rate(16000)if audio_segment.sample_width != 2: # int16audio_segment = audio_segment.set_sample_width(2)if audio_segment.channels != 1: # monoaudio_segment = audio_segment.set_channels(1) arr = np.array(audio_segment.get_array_of_samples())arr = arr.astype(np.float32)/32768.0text = model.transcribe(arr,language="zh", fp16=False)["text"]print(text)Spotify 的 AI 语音翻译
Spotify 正在尝试将外语播客转换成为母语的播客,意味着您最喜欢的播客可能会以您的母语被听到。
跨越文化、国家和社区,我们分享的故事将我们联系在一起。而且,更多时候,讲述者的声音和故事本身一样具有分量。15 年来,Spotify 的全球平台让各行各业的创作者能够与世界各地的观众分享他们的作品。从本质上讲,这是通过技术实现的,技术利用音频的力量克服了访问、边界和距离的障碍。但随着最近的进步,我们一直在想:是否还有更多方法可以弥合语言障碍,让全世界都能听到这些声音?
但你需要花时间和精力去做。你可以把播客的文字记录下来,然后把它(一次几段)输入到谷歌翻译或ChatGPT中(并让它翻译)。翻译完材料后,将其复制并粘贴到新脚本中。然后,重新录制。这里的成功取决于以下几点:
- 发音:你用外语说话时感觉如何?我们很多人在高中学习西班牙语,但你的日语水平如何?
- 翻译准确性:谷歌的支持文档声称谷歌翻译的准确率可能高达 94%。但这并未考虑到口语(例如,它如何翻译“cat got your tongue”或“in the zeitgeist?”这样的表达?)。
- 耐心:您愿意重新录制和重新编辑。
这是无法回避的;这是一项艰巨的任务,即使只是将几集翻译成另一种语言。那么,如果你能负担得起帮助,你有什么选择?
结束语
国内平台提供的各项语音转换服务就速度和质量而言,都非常出色,但是API 过于复杂。云平台控制台太凌乱。也没有多少demo程序。作为底层研究,还是要研究Whisper, pyannote-audio和pydub。
相关文章:
)
语音技术在播客领域的应用(2)
播客是以语音为主,各种基于AI 的语音技术在播客领域十分重要。 语音转文本 Whisper Whisper 是OpenAI 推出的开源语音辨识工具,可以把音档转成文字,支援超过50 种语言。这款工具是基于68 万小时的训练资料,其中包含11.7 万小时的…...

【Linux】应用层自定义协议与序列化
🌈 个人主页:Zfox_ 🔥 系列专栏:Linux 目录 一:🔥 应用层 🦋 再谈 "协议"🦋 网络版计算器🦋 序列化 和 反序列化 二:🔥 重新理解 read、…...

深度学习中的张量 - 使用PyTorch进行广播和元素级操作
深度学习中的张量 - 使用PyTorch进行广播和元素级操作 元素级是什么意思? 元素级操作在神经网络编程中与张量的使用非常常见。让我们从一个元素级操作的定义开始这次讨论。 一个_元素级_操作是在两个张量之间进行的操作,它作用于各自张量中的相应元素…...

gitignore忽略已经提交过的
已经在.gitignore文件中添加了过滤规则来忽略bin和obj等文件夹,但这些文件夹仍然出现在提交中,可能是因为这些文件夹在添加.gitignore规则之前已经被提交到Git仓库中了。要解决这个问题,您需要从Git的索引中移除这些文件夹,并确保…...

h5使用video播放时关掉vant弹窗视频声音还在后台播放
现象: 1、点击遮罩弹窗关闭,弹窗的视频已经用v-if销毁,但是后台会自己从头开始播放视频声音。但是此时已经没有视频dom 2、定时器在打开弹窗后3秒自动关闭弹窗,则正常没有问题。 原来的代码: //页面 <a click&quo…...

Widows搭建sqli-labs
使用ms17_010渗透win7 ms17_010针对windows445端口(共享文件), 现有一台win7虚拟机IP 192.168.80.129, 开放445端口, 使用msf渗透该虚拟机 auxiliary 使用auxiliary判断目标主机是否适用smb17_010漏洞 这里发现80网段, 有一台主机适用 exploit 使用search ms17_010 type:expl…...
:Facet六边形【意识形态:操纵】)
为AI聊天工具添加一个知识系统 之46 蒙板程序设计(第一版):Facet六边形【意识形态:操纵】
本文要点 要点 (原先标题冒号后只有 “Facet”后改为“Face六边形【意识形态】” ,是 事后想到的,本文并未明确提出。备忘在这里作为后续的“后期制作”的备忘) 前面讨论的(“之41 纯粹的思维”)中 说到,“意识”三…...

ASP.NET Core WebApi接口IP限流实践技术指南
在当今的Web开发中,接口的安全性和稳定性至关重要。面对恶意请求或频繁访问,我们需要采取有效的措施来保护我们的WebApi接口。IP限流是一种常见的技术手段,通过对来自同一IP地址的请求进行频率控制,可以有效地防止恶意攻击和过度消…...
)
文件移动工具 (File Mover)
这是一个简单但功能强大的Python脚本,用于递归遍历目录并将指定格式的文件移动到目标目录。默认支持移动PDF文件,但也可以通过参数指定其他文件格式。 功能特点 递归遍历源目录及其所有子目录支持移动任意指定格式的文件自动处理目标目录中的文件重名情…...

PTA L1-039 古风排版
中国的古人写文字,是从右向左竖向排版的。本题就请你编写程序,把一段文字按古风排版。 输入格式: 输入在第一行给出一个正整数N(<100),是每一列的字符数。第二行给出一个长度不超过1000的非空字符串&a…...

Docker 镜像加速的配置
解决拉取镜像报错:Error response from daemon: Get "https://registry-1.docker.io/v2/": net/http: request canceled while 在使用 Docker 过程中,拉取镜像的速度常常会受到网络状况的影响,尤其是在国内网络环境下,…...

简历_使用优化的Redis自增ID策略生成分布式环境下全局唯一ID,用于用户上传数据的命名以及多种ID的生成
系列博客目录 文章目录 系列博客目录WhyRedis自增ID策略 Why 我们需要设置全局唯一ID。原因:当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题。 问题:id的规律性太明显、…...

PHP的HMAC_SHA1和HMAC_MD5算法方法
很多做对接的小伙伴们都会遇到签名加密的问题,常用的就是hmac_sha1加密和hmac_md5加密,最开始用的是sha1加密,后来用到了md5加密,我以为直接把sha1改为md5就好了,结果试来试去跟文档提示的示例结果都对不上,…...
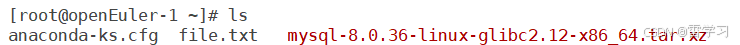
二进制/源码编译安装mysql 8.0
二进制方式: 1.下载或上传安装包至设备: 2.创建组与用户: [rootopenEuler-1 ~]# groupadd mysql [rootopenEuler-1 ~]# useradd -r -g mysql -s /bin/false mysql 3.解压安装包: tar xf mysql-8.0.36-linux-glibc2.12-x86_64.ta…...

2025-1-15-十大经典排序算法 C++与python
文章目录 十大经典排序算法比较排序1. 冒泡排序2. 选择排序3. 插入排序4. 希尔排序5. 归并排序6. 快速排序7. 堆排序 非比较排序8. 计数排序9. 桶排序10. 基数排序 十大经典排序算法 十大经典排序算法可以分为比较排序和非比较排序: 前者包括冒泡排序、选择排序、插入排序、希…...

头盔识别技术
本项目参考b站视频https://www.bilibili.com/video/BV1EhkiY2Epg/?spm_id_from333.999.0.0&vd_source6c722ac1eba24d4cbadc587e4d1892a7 1.下载miniconda 使用 Miniconda 来管理 Python 环境(如 yolov8),就可以通过 conda create -n y…...
DeepSeek-v3在训练和推理方面的优化
1. 基础架构:MLA,大幅减少了KV cache大小。(计算量能不能减少?) 2. 基础架构:MoE,同等参数量(模型的”能力“)下,训练、推理的计算量大幅减少。 3. MoE的load…...

将 AzureBlob 的日志通过 Azure Event Hubs 发给 Elasticsearch(3 纯python的经济方案)
前情: 将 AzureBlob 的日志通过 Azure Event Hubs 发给 Elasticsearch(1)-CSDN博客 将 AzureBlob 的日志通过 Azure Event Hubs 发给 Elasticsearch(2)-CSDN博客 python脚本实现 厉害的小伙伴最终使用python脚本免费…...

1️⃣Java中的集合体系学习汇总(List/Map/Set 详解)
目录 01. Java中的集合体系 02. 单列集合体系 1. Collection系列集合的遍历方式 (1)迭代器遍历(2)增强for遍历编辑(3)Lambda表达式遍历 03.List集合详解 04.Set集合详解 05.总结 Collection系列…...

闪豆多平台视频批量下载器
1. 视频链接获取与解析 首先,在哔哩哔哩网页中随意点击一个视频,比如你最近迷上了一个UP主的美食制作视频,想要下载下来慢慢学。点击视频后,复制视频页面的链接。复制完成后,不要急着关闭浏览器,因为接下来…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...