Theano教程:Python的内存管理
在写大型程序时候的一大挑战是如何保证最少的内存使用率。但是在Python中的内存管理是比较简单的。Python显示分配内存,使用引用计数系统管理对象,当指向某一个对象的引用数变为 0 的时候,该对象所占的内存就会被释放。理论上听起来很不错,也很简单,但是在实践中,我们需要知道一些Python内存管理的知识从而让程序在运行过程中能够更加高效地使用内存。其中一个方面我们需要知道的是基本的Python对象所占空间的大小,另一方面我们需要知道的是Python在内部到底是如何管理内存的。
基本对象
一个 int 对象占多大空间呢? C/C++程序员会说它是由具体的机器决定的,可能是32为或者64位,因此它最多占8个字节(一个字节8位)。那么在Python中也是如此吗?
下面写一个函数来揭示出对象占多大的空间(某些情况下需要递归,比如某一个对象类型不是基本的数据类型):
1 import sys2 3 def show_sizeof(x, level=0):4 5 print "\t" * level, x.__class__, sys.getsizeof(x), x6 7 if hasattr(x, '__iter__'):8 if hasattr(x, 'items'):9 for xx in x.items():
10 show_sizeof(xx, level + 1)
11 else:
12 for xx in x:
13 show_sizeof(xx, level + 1)我们可以用下面的函数调用来观察不同的基本数据类型所占空间大小:
show_sizeof(None)
show_sizeof(3)
show_sizeof(2**63)
show_sizeof(102947298469128649161972364837164)
show_sizeof(918659326943756134897561304875610348756384756193485761304875613948576297485698417)在64-bit系统和2.7.8 Python上运行的结果:
<type 'NoneType'> 16 None<type 'int'> 24 3<type 'long'> 36 9223372036854775808<type 'long'> 40 102947298469128649161972364837164<type 'long'> 60 918659326943756134897561304875610348756384756193485761304875613948576297485698417可以看到None占了16个字节,int 占了24个字节,是64为系统中C的int64_t 的 3 倍,而且是能够被机器识别的整型。长整型(无限制的精确度)用来表示出了大于263 - 1的整数,所占空间最小为36个字节。而且这个所占空间大小会随着算法中整数的大小线性增长。
Python的float是特定实现的,看上去类似于C中double,但是Python中的 float 不会在数据超过8个字节时终止表示:
show_sizeof(3.14159265358979323846264338327950288)
在64为系统输出:
<type 'float'> 24 3.14159265359
可以看到又是C中double类型所占空间(8字节)的3倍.
那么对于字符串呢?
show_sizeof("")
show_sizeof("My hovercraft is full of eels")
在64位系统输出:
<type 'str'> 33 <type 'str'> 62 My hovercraft is full of eels
空字符串占33字节,随着字符串内容增加,所占空间线性增长。
下面测试常用的tuple,list 和 dictionary所占空间大小(均为在64为系统下的输入结果):
show_sizeof([]) show_sizeof([4, "toaster", 230.1])
输出:
<type 'list'> 64 []<type 'list'> 88 [4, 'toaster', 230.1]
空list占64个字节,而64位系统中的C++ std::list() 只占16个字节,达到了4倍。
对于tuple呢?dictionary?:
show_sizeof({})
show_sizeof({'a':213, 'b':2131})
输出:
<type 'dict'> 272 {}<type 'dict'> 272 {'a': 213, 'b': 2131}<type 'tuple'> 64 ('a', 213)<type 'str'> 34 a<type 'int'> 24 213<type 'tuple'> 64 ('b', 2131)<type 'str'> 34 b<type 'int'> 24 2131可以看出,对于字典中的每一个 key/value 对,占64字节,但是注意('a', 213)所占空间是64字节,而 'a' 所占空间是34字节,213 占空间是24字节,所以留出64 -(34+24) = 6字节给key/value本身;另外,我们看到整个字典占272字节,而不是64+64 = 128字节。字典本身是被设计成一个搜索效率高的数据结构,所以会用到必要的额外的空间。如果字典内部采用的是某种树结构,必须考虑到包含每一个值的节点和指向孩子节点的两个指针的空间消耗;如果字典内部采用哈希表实现,我们必须保证有足够的空闲空间从而保证性能。
字典与C++std::map结构对等,而C++的map在创建(空map)时占48个字节, C++空字符串占 8 个字节,整数占4个字节。
观察到了这么多现象,到底是怎么回事?看上去一个空字符串占8个字节还是占37个字节似乎改变不了什么。如果不扩展数据大小,确实如此。我们必须关心的是我们创建多少个对象会到达程序所使用的内存的限制。在实践应用中,这个问题很棘手。要想设计出一个管理内存的好策略,不但需要关心对象所占内存的大小,还需要所创建对象的数量以及这些对象的创建顺序,事实证明这对于Python很重要。一个关键元素就是理解Python是如何在内部分配内存的,也正是下面即将讨论的.
内部内存管理
为了加速内存分配(和重复使用),Python对小型对象使用列表来管理。每个列表包含的对象所占空间大小都很相近:如一个列表包含的对象均占1到8个字节,另一个列表包含的对象均占9到16个字节等。当需要创建一个小型对象时,要么重复使用列表中空闲块,要么分配一块新空间。
事实上,即使一个对象的空间被free了,它做占据的内存空间也不会被返回给Python的全局内存池,而是仅仅被标记为free然后加入到空闲列表。过期的(被消亡)对象的位置空间会在一个新的差不多大小的对象被创建时,进行重复使用,如果没有过期的对象释放的空间存在,那么就直接新分配空间。
如果小型对象的所占内存从未被释放,那么列表所占内存空间就会一直增大,那么内存慢慢就会被这些大量的小型对象占据。
因此,我们应该努力只分配空间给那些有必要的对象,在循环中只创建少量的对象,尽量使用生成器语法。
事实上,列表占据空间的自由增长似乎并不算是一个问题,因为列表所包含的空间仍然允许Python程序进入和使用。但是从操作系统的视角来看,程序所占内存的大小会超过系统分配给Python的总内存的大小。
为了证明上面所述,使用memory_profiler(依赖于 python-psutil包)来证明:
1 import copy2 import memory_profiler3 4 #这里加上@profile是来监视具体函数function的内存使用情况5 @profile6 def function():7 x = list(range(1000000)) # allocate a big list8 y = copy.deepcopy(x)9 del x
10 return y
11
12 if __name__ == "__main__":
13 function()在Ubuntu上运行:
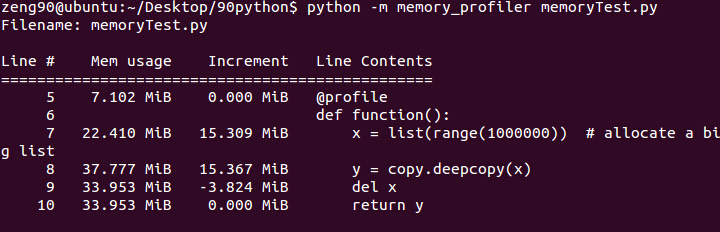
程序创建了包含1,000,000个int值(1,000,000*12 bytes = ~11.4MB),建立一个对list的引用变量x(1,000,000 * 8 bytes =~ 3.8MB), 总内存使用量大约为15.2MB.然后copy.deepcopy 进行深度拷贝操作和建立新的引用变量y,同样需要占用内存大约15.2MB,所以第8行的内存使用量增加了15.367MB. 注意第 9 行,del x, 内存使用量仅仅减少了3.824MB,这表明del操作只是释放了指向 list 引用变量的内存空间,而不是list中的整数所占内存空间,这些整数值保留在堆中,导致内存占用多了将近11.4MB.
在这个例子中分配了总共大约15.309 + 15.367 - 3.82 = ~26.8MB, 而我们存储一个list只需要大约11.4MB的内存,超出了1倍多! 所以,在编程中的也许我们不注意的地方,就会导致内存占用增长很快!
pickle
pickle是一种标准的把Python对象序列化到文件和以及从文件解序列化出来的方式。它的内存足迹(memory footprint)是什么? 它创建了额外的数据副本还是用一种更加聪明的方式?考虑:
1 import memory_profiler2 import pickle3 import random4 5 def random_string():6 return "".join([chr(64 + random.randint(0, 25)) for _ in xrange(20)])7 8 @profile9 def create_file():
10 x = [(random.random(),
11 random_string(),
12 random.randint(0, 2 ** 64))
13 for _ in xrange(1000000)]
14
15 pickle.dump(x, open('machin.pkl', 'w'))
16
17 @profile
18 def load_file():
19 y = pickle.load(open('machin.pkl', 'r'))
20 return y
21
22 if __name__=="__main__":
23 create_file()
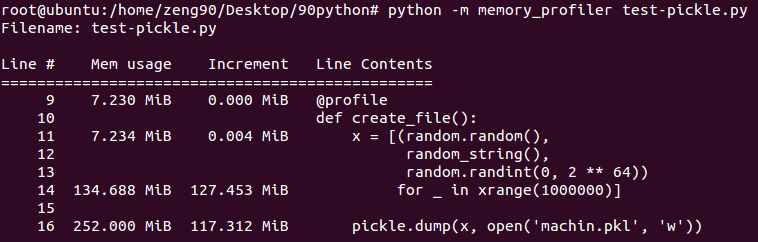
24 #load_file()这个程序用来生成一些pickle 数据和读取pickle 数据(pickle数据的读取在这里注释了,首先没用让读取函数运行),使用memory_profiler,生成pickle数据过程中使用了大量内存:
再看看pickle数据的读取(把上面程序中第23行注释掉,把24行的注释去掉):
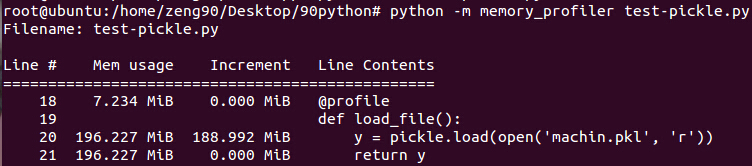
所以,pickle是非常消耗内存的做法,从上面的图看出,在数据的创建时,大约使用127MB内存,而一个pickle.dump操作就要额外使用差不多与数据相当的内存空间(117MB).
在unpickle操作中(即反序列化操作,从pkl中读取数据),看上去效率还好点,虽然确实占用了比原始数据(127MB)大的内存空间(188MB),但是还没到达有超1倍的程度。
总之,涉及pickle的操作应该在对内存容量要求较高的程序中尽量避免。那么,有没有可以替代的选择呢?我们知道pickle保存了数据结构的结构,即将数据原封不动保存起来(不仅仅保存数据,还要保存数据的结构信息),所以我们才能在需要的时候,将数据从pickle文件中恢复出来。但是,并不是所有时候都需要这样用pickle保存,就像上面例子中的list,完全可以用一个基于文本的文件格式按顺序保存里面的元素,没必要用pickle来保存:
1 import memory_profiler2 import random3 import pickle4 5 def random_string():6 return "".join([chr(64 + random.randint(0, 25)) for _ in xrange(20)])7 8 @profile9 def create_file():
10 x = [(random.random(),
11 random_string(),
12 random.randint(0, 2 ** 64))
13 for _ in xrange(1000000) ]
14 # 这里使用文本来保存数据而不是pickle
15 f = open('machin.flat', 'w')
16 for xx in x:
17 print >>f, xx
18 f.close()
19
20 @profile
21 def load_file():
22 y = []
23 f = open('machin.flat', 'r')
24 for line in f:
25 y.append(eval(line))
26 f.close()
27 return y
28
29 if __name__== "__main__":
30 create_file()
31 #load_file()建立文件时,内存足迹:
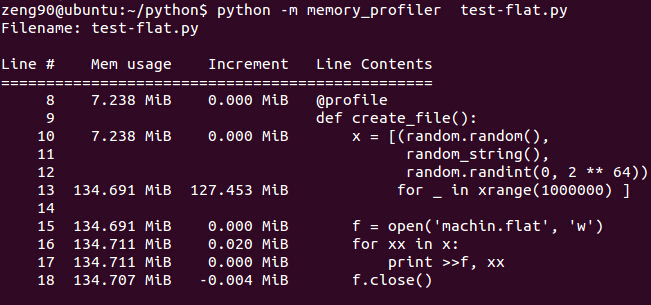
与上面pickle保存数据对比,可以发现,通过文本保存文件值占用几乎可以忽略的内存。
下面再来看看数据的读取时,内存足迹变化(将30行的代码注释,将31行的注释符去掉):
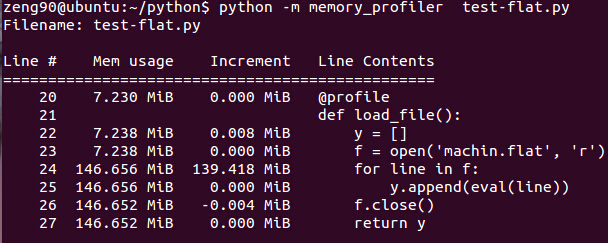
原始数据127MB,读取时占用内存139MB,和原始数据很接近,多出来的约10MB内存空间是分配给循环中产生的临时变量。
这个例子可以启示我们在处理数据的时候不要首先全部读取数据,然后再处理数据,而是每次读取几项,处理完这几项,释放这几项的空间,然后再读取几项处理,以此类推,这样,之前分配过的内存空间就可以重复使用。比如读取数据到一个Numpy的array中,我们可以先创建一个空array,然后逐行读取数据,逐行填入array,这样大约只需要和数据大小差不多的内存空间。如果使用pickle, 至少要分配2倍于数据大小的内存空间:一次是pickle在load时分配占用,一次是创建存储数据的array.
总结
Python 设计的目标根本上就不同于 C 语言设计的目标。后者是以更加复杂和显示的编程为代价让程序员能够更好地控制程序要做的事,而前者设计的目的是让代码更加迅速并且尽量隐藏细节。尽管听起来不错,但是在生产环境中,忽略执行效率会栽大跟头,所以在Python代码设计过程中,知道哪些代码执行的效率很低,从而尽量避免这种低效率编写对于生产环境来说很重要!
相关文章:
Theano教程:Python的内存管理
在写大型程序时候的一大挑战是如何保证最少的内存使用率。但是在Python中的内存管理是比较简单的。Python显示分配内存,使用引用计数系统管理对象,当指向某一个对象的引用数变为 0 的时候,该对象所占的内存就会被释放。理论上听起来很不错&am…...
Linux | Liunx安装Tomcat(Ubuntu版)
目录 一、下载并上传Tomcat压缩包到Ubuntu 1.1 下载并解压 1.2 执行 startup.sh 文件 二、验证Tomcat启动是否成功 2.1 查看启动日志 2.2 查看启动进程 三、Windows访问 Tomcat 服务 四、停止 Tomcat 服务 Tomcat是一款Web服务器,开发Web项目基本上都会用到…...

缓冲区浅析
缓冲区 程序运行输入数据时,从键盘的输入先存储到缓冲区,只有当缓冲区满或者输入回车时程序才会真正地从缓冲区读入数据 int main() {int a, b;cin >> a >> b;return 0; }in: 1 2\n 例如这里输入空格时程序没有输出,而是将空格…...
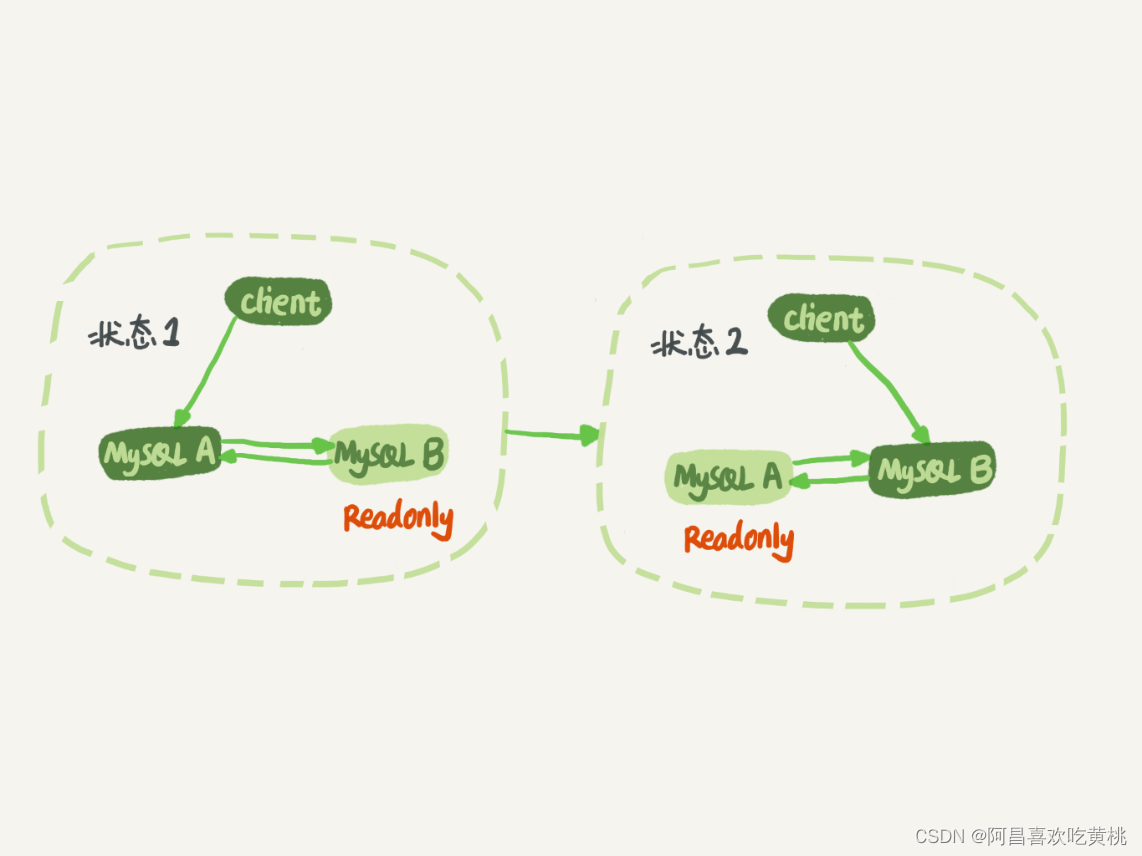
Day888.MySQL是怎么保证主备一致的 -MySQL实战
MySQL是怎么保证主备一致的 Hi,我是阿昌,今天学习记录的是关于MySQL是怎么保证主备一致的内容。 MySQL 能够成为现下最流行的开源数据库,binlog 功不可没。 在最开始,MySQL 是以容易学习和方便的高可用架构,被开发人…...
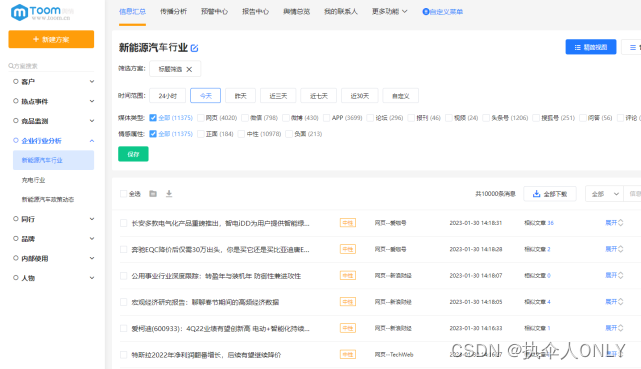
互联网舆情监测系统的发展阶段,TOOM互联网舆情监测系统有哪些?
互联网舆情监测系统是一种利用计算机技术对互联网上的大量信息进行实时监测、分析和评估的工具,旨在了解公众对某一事件、话题或品牌等的态度、情感倾向和影响力等。通过对社交媒体、论坛、新闻媒体等多个渠道的数据采集和处理,系统能够实现舆情事件的追…...
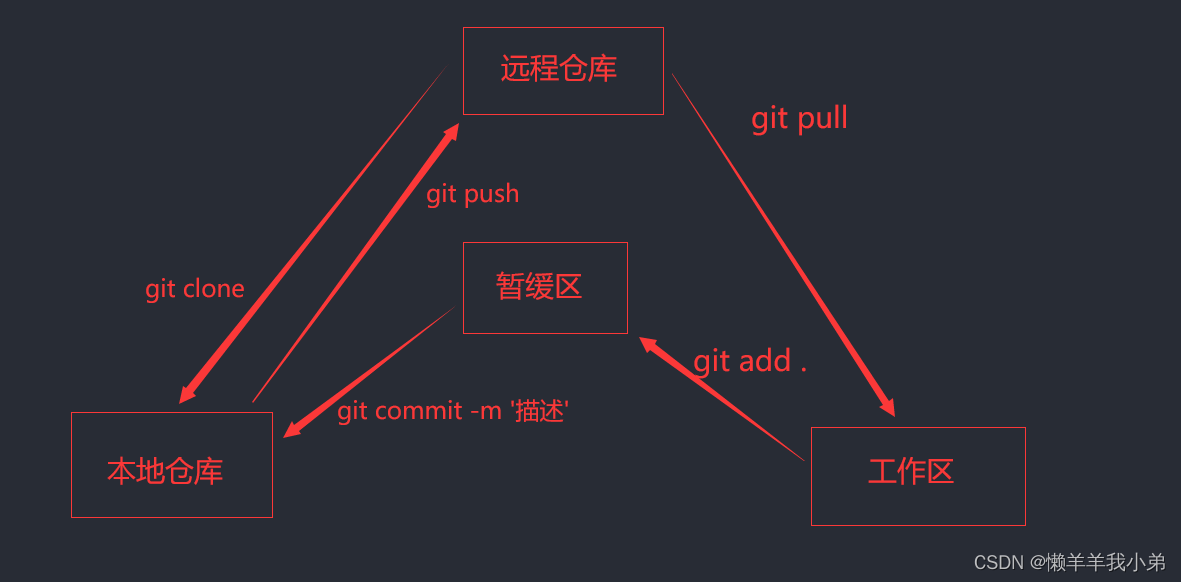
GIT命令操作大全
文章目录一、前言二、工作模块2.1 Workspace:工作区2.2 Index / Stage:暂存区2.3 Repository:本地仓库2.4Remote:远程仓库三、GIT基本配置四、GIT项目代码管理4.1 初始化git仓库4.2 提交到暂存区(stage)4.3 将暂存区的文件恢复到工…...
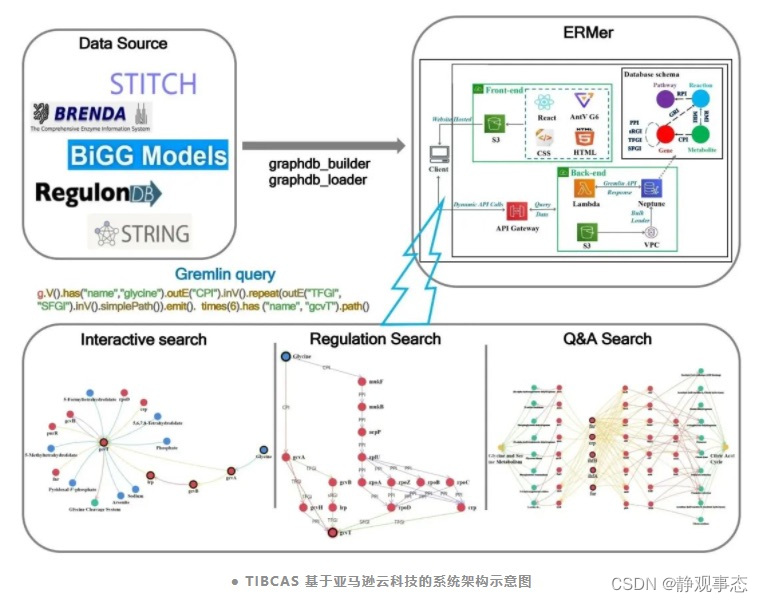
突破传统开发模式,亚马逊云科技助力中科院加速推动合成生物学
当数字技术成为整个社会运行的底座,生物科学也能借力云计算从诸多繁琐重复的工作中解放出来,专注于生物设计与创新。来看看亚马逊云科技如何与TIBCAS合作,推动合成生物学的发展。 明确核心需求,选择合作伙伴 TIBCAS选择与亚马逊…...

分享开放通达信l2接口的过程,开发之后怎么使用?
随着互联网的不断进步,信息技术的不断发展,通达信l2接口技术逐步成熟。那么,这些开放通达信l2接口开发的过程是怎么样的呢?期间又会遇到什么问题,开放之后又会怎么使用呢?这篇文章带你深入了解。 通达信l2接口不像一…...
33、基于51单片机老人防跌倒蜂鸣器报警系统加速度检测
背景技术 老年人出门由于身体不灵活、视力较差,容易发生跌倒,现用的老年人跌倒报警装置是通过无线对讲系统研发的,它外观精美,自动化程度高,有很强的专业性,但是,设计者忽略了一个问题…...
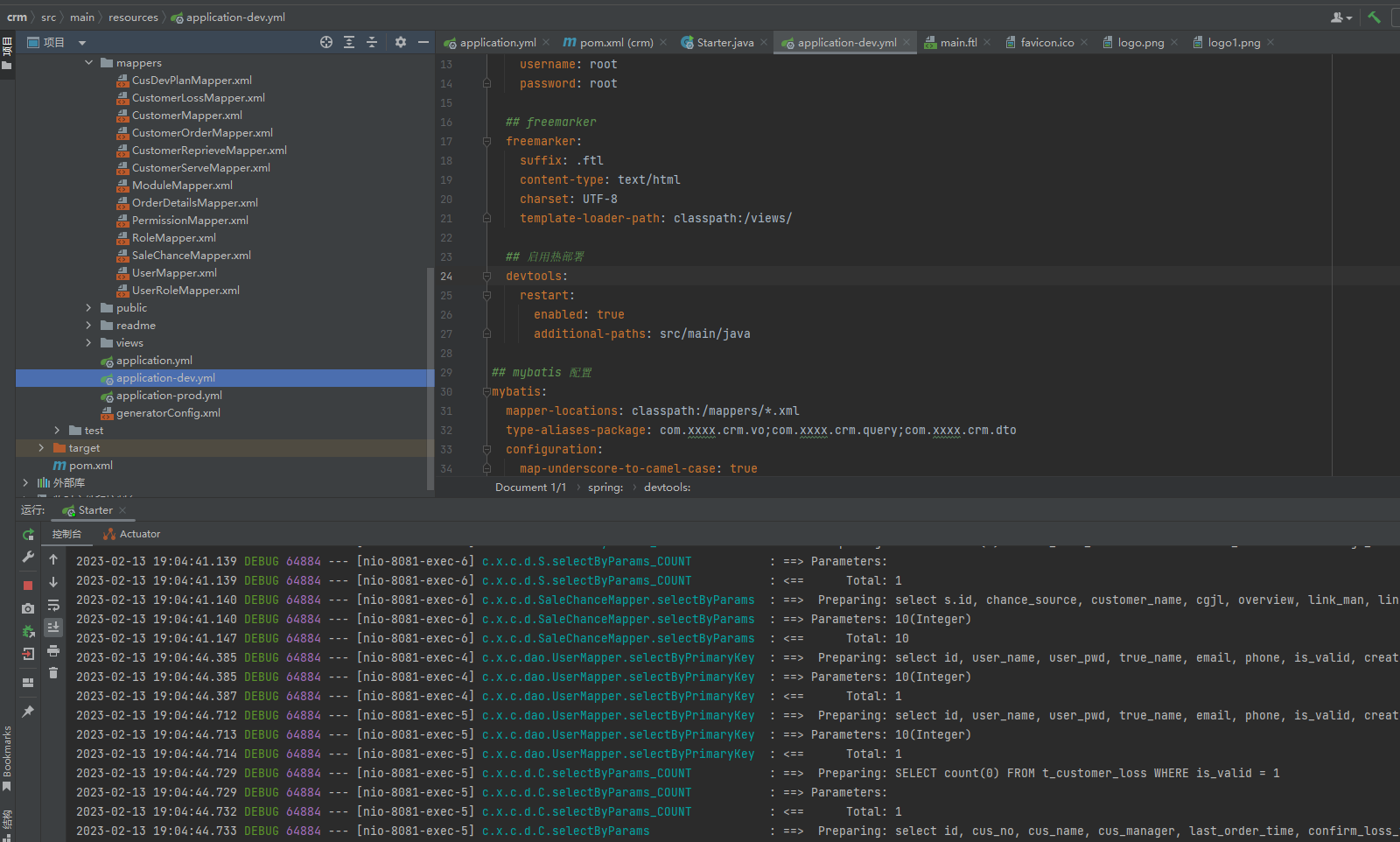
【项目】基于SpringBoot+Freemarker+Mybatis+MySQL+LayUI实现CRM智能办公系统
这里写目录标题CRM基本概念CRM分类模块功能描述项目代码application-dev.yml部分页面代码CRM基本概念 圈内存在这么一句话:“世上本来没有 CRM,大家的生意越来越难做了,才有了 CRM。” 在同质化竞争时代,顾客资产尤为重要&#x…...
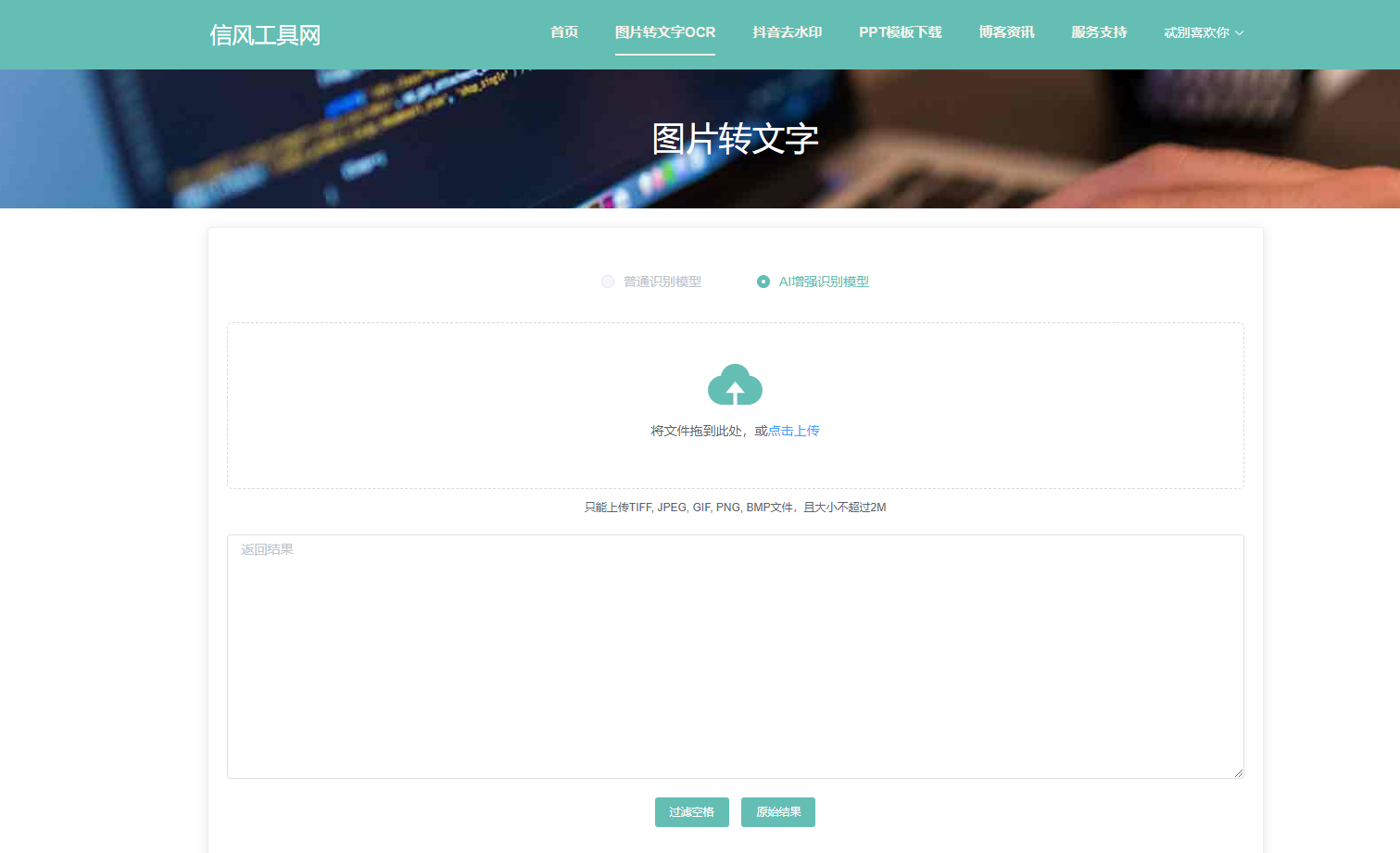
手写识别字体的步骤是什么?怎么识别图片中的文字?
手写识别字体的步骤是什么?怎么识别图片中的文字? 1. 打开信风工具网,点击拍照按钮,选择拍图识字模式,对准需要识别的文件进行拍摄。在线工具地址: https://ocr.bytedance.zj.cn/image/ImageT…...

Mysql 存储过程
什么是存储过程? 存储过程是事先经过编译并存储在数据库的一段sql语句的集合 如何创建一个存储过程? create procedure 存储过程名称([参数列表]) beginsql语句; end#例 create procedure p1() beginselect * from t_goods;select * from t_user; end如…...
【LeetCode】每日一题(3)
目录 题目:1234. 替换子串得到平衡字符串 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:1234. 替换子串得到平衡…...

websocket学习
1.什么是websocket 1)首先websocket和http一样,是一种网络通信协议,来自HTML5的特性; 2)他可以使客户端和服务端进行双工通信,简单来说,就是双向通信:比如我们熟悉的http协议&…...
)
Java面试题及答案整理汇总(2023最新版)
前言 面试前还是很有必要针对性的刷一些题,很多朋友的实战能力很强,但是理论比较薄弱,面试前不做准备是很吃亏的。这里整理了很多面试常考的一些面试题,希望能帮助到你面试前的复习并且找到一个好的工作,也节省你在网…...

公司来了个卷王,我愿称之为王中王,让人崩溃
前几天我们公司一下子也来了几个新人,这些年前人是真能熬啊,本来我们几个老油子都是每天稍微加会班就打算走了,这几个新人一直不走,搞得我们也不好走。2023年春招就要开始了,最近内卷严重,各种跳槽裁员&…...

波奇学c语言:代码的编译和链接
test.c(源文件)->编译->test.obj(目标文件)->链接->test.exe(可执行文件)编译1.预编译(预处理):text.c->text.i使用gcc -E test.c 进行停止预处理指令&am…...

计算机网络原理--传输层协议(TCP协议十大特性)
目录 1.认识TCP协议 TCP的协议段格式 2. 确认应答机制 3.超时重传 4.连接管理 <...

nvm控制node版本
安装 nvm 1、下载 nvm 官网安装包: github 选择 nvm-setup.exe 下载 2、安装 1、选择 nvm 安装目录(可自定义) 2、选择 node 安装目录(如有安装过,可以选择以前安装目录,可 cdm 输入 where node 查看原nod…...

从0到1一步一步玩转openEuler--13 openEuler用户组管理
文章目录13.1 创建用户组13.1.1 groupadd命令13.1.2 用户组信息文件13.1.3 创建用户组实例13.2 修改用户组13.2.1 修改GID13.2.2 修改用户组名13.3 删除用户组13.4 将用户加入用户组或从用户组中移除13.5 切换用户组在Linux中,每个普通用户都有一个账户,…...


AI建站+全链路运营,让你一个人活成一个团队
AI建站全链路运营,让你一个人活成一个团队去年这个时候,我为了搞独立站,头发掉了不少。那时候我觉得,只要网站做得漂亮,订单就会像雪花一样飞来。结果呢?网站是上线了,但支付接不通,…...

从日偏食图像处理开始:手把手在VS2019里跑通你的第一个OpenCV 4.3程序
从日偏食图像处理开始:手把手在VS2019里跑通你的第一个OpenCV 4.3程序 当那张日偏食照片第一次在屏幕上成功显示时,仿佛打开了计算机视觉的大门。本文将带你从零开始,用VS2019和OpenCV 4.3实现这个充满仪式感的"Hello World"——不…...
)
壁纸引擎安卓版(wallpaper engine安卓版免费下载)
wallpaper engine安卓版是Steam上的Wallpaper Engine官方的安卓应用程序。 Wallpaper Engine Android 应用程序是免费的,支持将现有 Wallpaper Engine 壁纸合集无线传输到您的 Android 移动设备。 ————————————————————————————————…...

AI工具搭建自动化视频生成Quick Sync
# Quick Sync:AI驱动的自动化视频生成技术实战解析 前阵子团队接了个批量短视频生成的项目,要在短时间内产出数百条产品演示视频。一开始想着一个个用Premiere剪,但算算时间,光是渲染就够呛。后来试用了几种自动化方案,…...

别再死记硬背了!Vivado伪双口RAM的wea/ena信号,这次用仿真波形给你讲透
深入解析Vivado伪双口RAM控制信号:从波形图看wea/ena关键设计 在FPGA开发中,存储器设计一直是性能优化的关键环节。Xilinx Vivado工具链提供的伪双口RAM IP核因其灵活性和高效性,成为许多高速数据处理系统的首选方案。然而,不少开…...

探究MicroBlaze软核在DDR3中运行sleep函数异常延迟的根源与规避策略
1. 现象描述:从BRAM到DDR3的诡异延迟 第一次把MicroBlaze程序从BRAM搬到DDR3运行时,我遇到了一个让人抓狂的问题:原本精准的sleep(1)延时竟然变成了长达数秒的卡顿。这个现象特别容易在Vitis环境下开发网络应用(比如LwIP协议栈&am…...

从DRM驱动看mmap:图解内存分配与映射的‘时机’与‘方式’如何影响性能
从DRM驱动看mmap:图解内存分配与映射的‘时机’与‘方式’如何影响性能 在图形驱动开发领域,内存管理始终是性能优化的关键战场。当你在调试一块高端显卡的DRM(Direct Rendering Manager)驱动时,是否曾遇到过这样的困惑…...

FanControl风扇识别故障排查指南:从零开始解决“风扇隐身“问题
FanControl风扇识别故障排查指南:从零开始解决"风扇隐身"问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/G…...
)
别再死记公式了!用Python+NetworkX可视化理解关系闭包(附完整代码)
用PythonNetworkX玩转关系闭包:从数学抽象到动态可视化的实战指南 第一次接触"关系闭包"这个概念时,我盯着课本上那些晦涩的数学符号和矩阵运算整整半小时,依然云里雾里。直到我用Python的NetworkX库将社交网络中的关注关系画成图形…...