PyTorch使用教程(2)-torch包
1、简介
torch包是PyTorch框架最外层的包,主要是包含了张量的创建和基本操作、随机数生成器、序列化、局部梯度操作的上下文管理器等等,内容很多。我们基础学习的时候,只有关注张量的创建、序列化,随机数、张量的数学数学计算等常用的点即可。

2、什么是张量
在PyTorch中,张量(Tensor)是一个核心概念,它是深度学习和科学计算的基础数据结构。在PyTorch的整个计算过程中,所有的数据结构都是以张量的形式表现。例如输入的图像、标签,输出的结构等,最终都是以张量的形式进入PyTorch的计算图。
- 定义:张量是一个多维数组,可以看作是标量、向量、矩阵的高维扩展。
- 性质:
- 张量具有任意维度,可以是0维(标量)、1维(向量)、2维(矩阵)或更高维度。
- 张量支持各种数学运算,包括加法、乘法、卷积等,这些运算可以高效地在CPU或GPU上执行。
- 张量可以跟踪计算图,并通过反向传播计算梯度,这对于深度学习中的优化任务至关重要。
- 张量的属性:
- 形状(shape):张量的形状定义了其维度和每个维度上的大小,如形状为
(2, 3, 4)的张量表示具有2个深度、每个深度包含3行4列的3D数组。 - 数据类型(dtype):张量中的元素具有特定的数据类型,如浮点数(
float32、float64)或整数(int32、int64)等。 - 设备(device):张量可以存储在CPU或GPU上,通过指定设备参数可以在不同设备之间创建或移动张量。
- 形状(shape):张量的形状定义了其维度和每个维度上的大小,如形状为
3、torch包的张量操作
3.1 张量创建
1. 创建全0的张量
torch.zeros(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
参数
- size (int…) – 定义输出张量形状的整数序列。可以是可变数量的参数或类似列表或元组的集合。
示例
>>> torch.zeros(2, 3)
tensor([[ 0., 0., 0.],[ 0., 0., 0.]])
>>> torch.zeros(5)
tensor([ 0., 0., 0., 0., 0.])
2. 创建全1的张量
torch.ones(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
参数
- size (int…) – 定义输出张量形状的一系列整数。可以是可变数量的参数或类似列表或元组的集合。
示例
>>> torch.ones(2, 3)
tensor([[ 1., 1., 1.],[ 1., 1., 1.]])>>> torch.ones(5)
tensor([ 1., 1., 1., 1., 1.])
3. 创建未初始化数据的张量
torch.empty(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False, memory_format=torch.contiguous_format) → Tensor
参数
- size (int…) – 定义输出张量形状的整数序列。可以是可变数量的参数或集合,如列表或元组。
示例
>>> torch.empty((2,3), dtype=torch.int64)
tensor([[ 9.4064e+13, 2.8000e+01, 9.3493e+13],[ 7.5751e+18, 7.1428e+18, 7.5955e+18]])
4. 创建对角线上的元素为1的二维张量
torch.eye(n, m=None, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
参数
- n (int) – 行数
示例
>>> torch.eye(3)
tensor([[ 1., 0., 0.],[ 0., 1., 0.],[ 0., 0., 1.]])
5. 创建填充指定值的张量
torch.full(size, fill_value, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
参数
- size (int…) – 定义输出张量形状的整数列表、元组或 torch.Size。
- fill_value (标量) – 用于填充输出张量的值。
示例
>>> torch.full((2, 3), 3.141592)
tensor([[ 3.1416, 3.1416, 3.1416],[ 3.1416, 3.1416, 3.1416]])
6. 从NumPy 数组创建的张量:from_numpy
示例
>>> a = numpy.array([1, 2, 3])
>>> t = torch.from_numpy(a)
>>> t
tensor([ 1, 2, 3])
>>> t[0] = -1
>>> a
array([-1, 2, 3])
7. 判断一个Obj是不是张量:is_tensor
示例
>>> x = torch.tensor([1, 2, 3])
>>> torch.is_tensor(x)
True
3.2 张量操作
1. reshape操作
torch.reshape(input, shape) → Tensor
参数
- input (Tensor) – 需要形状改变的张量
- shape (tuple of int) – 新形状
示例
>>> a = torch.arange(4.)
>>> torch.reshape(a, (2, 2))
tensor([[ 0., 1.],[ 2., 3.]])
>>> b = torch.tensor([[0, 1], [2, 3]])
>>> torch.reshape(b, (-1,))
tensor([ 0, 1, 2, 3])
2. cat操作
在给定的维度上连接给定的张量序列。所有张量必须具有相同的形状(连接维度除外),或者是一个大小为 (0,) 的一维空张量。
torch.cat(tensors, dim=0, *, out=None) → Tensor
参数
- tensors (sequence of Tensors) – 任何相同类型的张量 Python 序列。提供的非空张量必须具有相同的形状,连接维度除外。
- dim (int, optional) – 连接张量的维度
示例
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 0)
tensor([[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497],[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497],[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 1)
tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,-1.0969, -0.4614],[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,-0.5790, 0.1497]])
3. squeeze操作
返回一个张量,其中所有指定维度的 input 大小为 1 的维度都被移除。
torch.squeeze(input, dim=None) → Tensor
示例
>>> x = torch.zeros(2, 1, 2, 1, 2)
>>> x.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x)
>>> y.size()
torch.Size([2, 2, 2])
>>> y = torch.squeeze(x, 0)
>>> y.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x, 1)
>>> y.size()
torch.Size([2, 2, 1, 2])
>>> y = torch.squeeze(x, (1, 2, 3))
torch.Size([2, 2, 2])
4、 随机数
4.1随机数发生器配置
1. seed操作
将所有设备上生成随机数的种子设置为非确定性随机数。返回用于为 RNG 播种的 64 位数字。
示例
>>> torch.seed()
269874079427000
2. 手动设置随机数的种子值:manual_seed
设置所有设备上生成随机数的种子。
示例
>>> torch.manual_seed(torch.seed())
<torch._C.Generator object at 0x0000022952198270>
4.2 创建随机张量
1. torch.rand
创建一个张量,其中填充了来自 [0,1) 区间上的均匀分布的随机数。
torch.rand(*size, *, generator=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False) → Tensor
参数
- size (int…) – 定义输出张量形状的整数序列。可以是可变数量的参数或像列表或元组这样的集合。
示例
>>> torch.rand(4)
tensor([ 0.5204, 0.2503, 0.3525, 0.5673])
>>> torch.rand(2, 3)
tensor([[ 0.8237, 0.5781, 0.6879],[ 0.3816, 0.7249, 0.0998]])
2. randint
创建一个张量,其中填充了在 low(包含)和 high(不包含)之间均匀生成的随机整数。
torch.randint(low=0, high, size, \*, generator=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
参数
- low (int, 可选) – 从分布中抽取的最低整数。默认值:0。
- high (int) – 从分布中抽取的最高整数加 1。
- size (tuple) – 定义输出张量形状的元组。
示例
>>> torch.randint(3, 5, (3,))
tensor([4, 3, 4])>>> torch.randint(10, (2, 2))
tensor([[0, 2],[5, 5]])>>> torch.randint(3, 10, (2, 2))
tensor([[4, 5],[6, 7]])
5、张量的保存和加载
1. 保存
将张量保存到磁盘文件。
torch.save(obj, f, pickle_module=pickle, pickle_protocol=DEFAULT_PROTOCOL, _use_new_zipfile_serialization=True)
PyTorch 的常见约定是使用 .pt 文件扩展名保存张量。
参数
- obj (对象) – 保存的对象
- f -保存的命名
示例
>>> x = torch.tensor([0, 1, 2, 3, 4])
>>> torch.save(x, "tensor.pt")
2. 加载
从文件中加载使用 torch.save() 保存的对象。
torch.load(f, map_location=None, pickle_module=pickle, *, weights_only=False, mmap=None, **pickle_load_args)
参数
- f 类文件对象(必须实现 read()、readline()、tell() 和 seek()),或包含文件名的字符串或 os.PathLike 对象
- map_location (可选[联合[可调用[[Storage, str], Storage], device, str, Dict[str, str]]]) – 一个函数、torch.device、字符串或一个字典,指定如何重新映射存储位置
当在包含 GPU 张量文件上调用torch.load()时,默认情况下,这些张量将加载到 GPU。可以调用torch.load(…, map_location=‘cpu’),然后load_state_dict()来避免在加载模型检查时出现 GPU 内存激增。
load函数的用法较多,可以通过pick_module参数传入自定义的序列化和反序列化的模块,可以通过字节流、文件对象等进行张量加载。详细的用法可以访问官网的API文档进行查看:https://pytorch.ac.cn/docs/stable/generated/torch.load.html#torch.load。
示例
# 加载张量至CPU
>>> torch.load("tensors.pt", map_location=torch.device("cpu"), weights_only=True)
# 加载张量至 GPU 1
>>> torch.load(
... "tensors.pt",
... map_location=lambda storage, loc: storage.cuda(1),
... weights_only=True,
... ) # type: ignore[attr-defined]
6、张量的基础数学计算
张量的数学计算部分主要是包含了逐元素的线性计算、统计信息计算、比较操作、FFT相关的频域操作等等。

1. 绝对值
torch.abs(input, *, out=None) → Tensor
示例
>>> torch.abs(torch.tensor([-1, -2, 3]))
tensor([ 1, 2, 3])
2. 三角函数相关
cos、acos、sin、asin、tan、atan、atan2等等。
示例
>>> a = torch.randn(4)
>>> a
tensor([-0.5461, 0.1347, -2.7266, -0.2746])
>>> torch.sin(a)
tensor([-0.5194, 0.1343, -0.4032, -0.2711])
3. 统计信息相关
和值sum、均值标准差std_mean、中值median、最大值max、最小值min等等。
>>> a = torch.tensor(
... [[ 0.2035, 1.2959, 1.8101, -0.4644],
... [ 1.5027, -0.3270, 0.5905, 0.6538],
... [-1.5745, 1.3330, -0.5596, -0.6548],
... [ 0.1264, -0.5080, 1.6420, 0.1992]])
>>> torch.std_mean(a, dim=0, keepdim=True)
(tensor([[1.2620, 1.0028, 1.0957, 0.6038]]),tensor([[ 0.0645, 0.4485, 0.8707, -0.0665]]))
7、小结
主要介绍了PyTorch框架中torch包的常用组件,包含张量的创建和基本操作、张量的保存和加载以及随机数、张量的基础数学运算等相关操作。
相关文章:
PyTorch使用教程(2)-torch包
1、简介 torch包是PyTorch框架最外层的包,主要是包含了张量的创建和基本操作、随机数生成器、序列化、局部梯度操作的上下文管理器等等,内容很多。我们基础学习的时候,只有关注张量的创建、序列化,随机数、张量的数学数学计算等常…...

Bash语言的函数实现
Bash语言的函数实现 Bash(Bourne Again SHell)是一种流行的命令行解释器,用于Unix和类Unix操作系统。它不仅支持命令行操作,还能通过脚本语言进行编程。函数是Bash脚本编程中的一个重要概念,可以帮助我们组织代码、提…...

ChatGPT 写作系列
ChatGPT 辅助写作 | 专栏 1 写作核心 先讲一下 ChatGPT 写作的核心。核心就是需要有文章大纲,而且文章大纲要足够细致。 具体怎么做呢? 提前准备多级标题大纲,刚开始有两个级别的标题就行,等用熟练了再细化。分一级标题&…...

RK3576 Android14 状态栏和导航栏增加显示控制功能
问题背景: 因为RK3576 Android14用户需要手动控制状态栏和导航栏显示隐藏控制,包括对锁屏后下拉状态栏的屏蔽,在设置功能里增加此功能的控制,故参考一些博客完成此功能,以下是具体代码路径的修改内容。 解决方案&…...

SDL2:arm64下编译使用 -- SDL2多媒体库使用音频实例
更多内容:XiaoJ的知识星球 SDL2:Android-arm64端编译使用 2. SDL2:Android-arm64端编译使用2.1 安装和配置NDK2.2 下载编译SDL22.3 SDL2使用示例:Audio2.4 Android设备运行 2. SDL2:Android-arm64端编译使用 在Linux系…...

Syncthing在ubuntu下的安装使用
以前安装这个软件的时候, 是在windows和mac上,都是图形化的安装方式,但是ubuntu不太一样,需要增加源,然后执行命令。安装的系统版本是2004。 参考链接1,主要命令包含下面几个部分: 第一步&…...

使用 Helm 安装 Redis 集群
在 Kubernetes 集群中使用 Helm 安装 Redis 集群可以极大地简化部署和管理 Redis 的过程。本文将详细介绍如何使用 Helm 安装 Redis 集群,并提供一些常见问题的解决方案。 前提条件 Kubernetes 集群。(略)已安装 Helm 工具。搭建了存储类nf…...

基于32QAM的载波同步和定时同步性能仿真,包括Costas环的gardner环
目录 1.算法仿真效果 2.算法涉及理论知识概要 3.MATLAB核心程序 4.完整算法代码文件获得 1.算法仿真效果 matlab2022a仿真结果如下(完整代码运行后无水印): 仿真操作步骤可参考程序配套的操作视频。 2.算法涉及理论知识概要 载波同步是…...

【ArcGIS微课1000例】0140:总览(鹰眼)、放大镜、查看器的用法
文章目录 一、总览工具二、放大镜工具三、查看器工具ArcGIS中提供了三种局部查看的工具: 总览(鹰眼)、放大镜、查看器,如下图所示,本文讲述这三种工具的使用方法。 一、总览工具 为了便于效果查看与比对,本实验采用全球影像数据(位于配套实验数据包中的0140.rar中),加…...
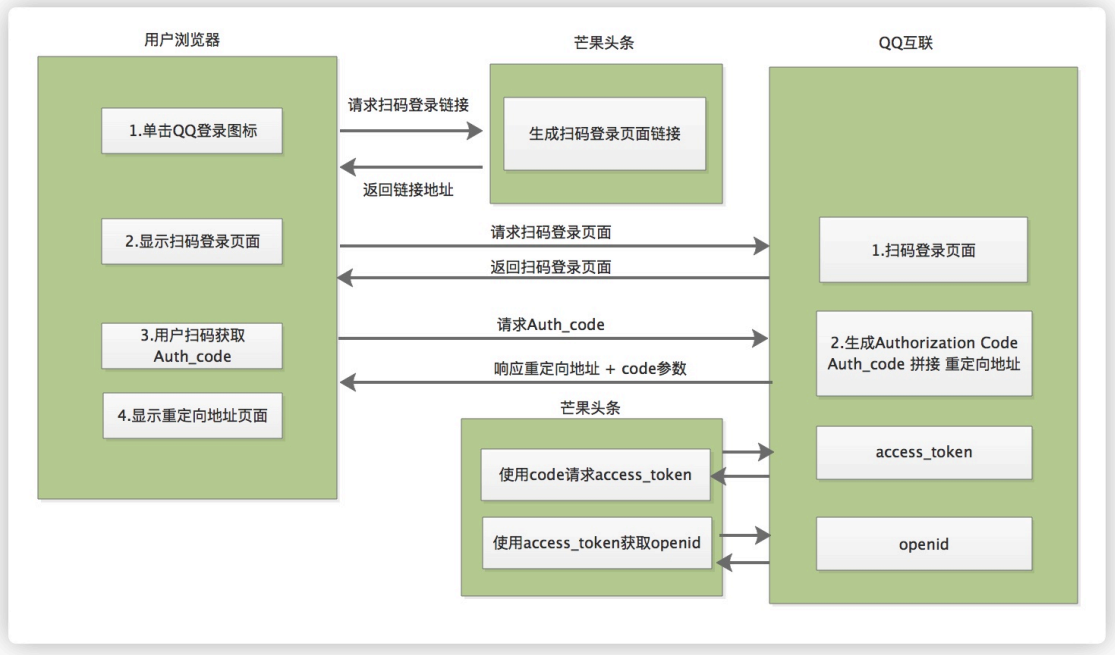
使用QQ登录(头条项目-09)
一 QQ登录开发文档 QQ登录:即我们所说的 第三⽅登录,是指⽤户可以不在本项⽬中输⼊密码,⽽直接 通过第三⽅的验证,成功登录本项⽬。 1.1 QQ互联开发者申请步骤 若想实现QQ登录,需要成为 QQ互联的开发者,…...

iOS页面设计:UIScrollView布局问题与应对策略
在iOS开发中,UIScrollView是一个极其重要且常用的控件,它允许用户通过手势滑动查看大量内容。然而,在利用UIScrollView进行页面布局时,开发者往往会遇到一些挑战。本文将深入探讨UIScrollView布局中常见的问题,并提供相…...

Linux提权-02 sudo提权
文章目录 1. sudo 提权原理1.1 原理1.2 sudo文件配置 2. 提权利用方式2.1 sudo权限分配不当2.2 sudo脚本篡改2.3 sudo脚本参数利用2.4 sudo绕过路径执行2.5 sudo LD_PRELOAD环境变量2.6 sudo caching2.7 sudo令牌进程注入 3. 参考 1. sudo 提权原理 1.1 原理 sudo是一个用于在…...

vscode 设置
一、如何在vscode中设置放大缩小代码 1.1.文件—首选项——设置 1.2.在搜索框里输入“Font Ligatures”,然后点击"在settings.json中编辑" 1.3.在setting中("editor.fontLigatures":前)添加如下代码 "editor.mous…...

学习threejs,使用FlyControls相机控制器
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️THREE.FlyControls 相机控制…...

在 C++ 中实现调试日志输出
在 C 编程中,调试日志对于定位问题和优化代码至关重要。有效的调试日志不仅能帮助我们快速定位错误,还能提供有关程序运行状态的有价值的信息。本文将介绍几种常用的调试日志输出方法,并教你如何在日志中添加时间戳。 1. 使用 #ifdef _DEBUG…...

从零搭建一套远程手机的桌面操控和文件传输的小工具
从零搭建一套远程手机的桌面操控和文件传输的小工具 --ADB连接专题 一、前言 前面的篇章中,我们确定了通过基于TCP连接的ADB控制远程手机的操作思路。本篇中我们将进行实际的ADB桥接的具体链路搭建工作,从原理和实际部署和操作层面上,从零…...

Python中的静态方法
目录 什么是静态方法?静态方法的特点 定义和调用静态方法示例:定义一个简单的静态方法 静态方法 vs 类方法 vs 实例方法示例对比 静态方法的应用场景1. 🔧 工具函数2. 🏭 工厂方法3. ✅ 数据验证 静态方法的限制总结 静态方法是 P…...

【C++】面试题整理(未完待续)
【C】面试题整理 文章目录 一、概述二、C基础2.1 - 指针在 32 位和 64 位系统中的长度2.2 - 数组和指针2.3 - 结构体对齐补齐2.4 - 头文件包含2.5 - 堆和栈的区别2.6 - 宏函数比较两个数值的大小2.7 - 冒泡排序2.8 - 菱形继承的内存布局2.9 - 继承重写2.10 - 如何禁止类在栈上分…...

每日一题 403. 青蛙过河
403. 青蛙过河 动态规划,状态转移 和 上一步步长 和 当前位置点 有关系 class Solution { public:bool canCross(vector<int>& stones) {int n stones.size();unordered_map<int,unordered_set<int>> dp;unordered_map<int,int> mp;…...

Spring Boot 集成 MongoDB:启动即注入的便捷实践
引言 在现代后端开发中,Spring Boot 凭借其快速开发、自动配置等特性深受开发者喜爱,而 MongoDB 以其灵活的文档存储结构和出色的扩展性,成为处理非结构化数据的首选数据库之一。将两者结合,利用 Spring Boot 的自动配置功能&…...

EmbeddingGemma-300m效果展示:Ollama实现专利技术趋势分析
EmbeddingGemma-300m效果展示:Ollama实现专利技术趋势分析 1. 当专利工程师遇上轻量级嵌入模型 专利文档的世界里,技术术语像密码一样密集排列。一份典型的通信领域专利摘要,可能同时出现“可重构智能表面”、“波束赋形算法”、“信道状态…...

墨语灵犀跨文明对话实践:敦煌文献英译→古风中文回译实验
墨语灵犀跨文明对话实践:敦煌文献英译→古风中文回译实验 1. 引言:当敦煌遇见AI翻译 敦煌文献作为中华文明的重要遗产,其翻译工作一直面临着巨大的挑战。传统的翻译方法往往难以准确传达古文献的意境和文化内涵,而现代机器翻译又…...

MobaXterm远程连接:高效管理云端忍者像素绘卷GPU服务器
MobaXterm远程连接:高效管理云端忍者像素绘卷GPU服务器 1. 为什么选择MobaXterm管理GPU服务器 如果你正在使用星图GPU平台上的忍者像素绘卷:天界画坊服务器,那么一个趁手的远程管理工具能让你事半功倍。MobaXterm就是这样一个瑞士军刀般的工…...

终极指南:用AKShare快速构建免费金融数据自动化分析系统
终极指南:用AKShare快速构建免费金融数据自动化分析系统 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/aks/…...

all-MiniLM-L6-v2技术解析:为何22.7MB模型能在256token长度下保持鲁棒性
all-MiniLM-L6-v2技术解析:为何22.7MB模型能在256token长度下保持鲁棒性 1. 模型架构与设计理念 all-MiniLM-L6-v2是一个令人印象深刻的轻量级句子嵌入模型,它基于BERT架构但进行了精心的优化设计。这个模型的核心目标是在保持高质量语义表示能力的同时…...

别让Windows驱动变成“空间刺客“!Driver Store Explorer轻松拯救你的C盘
别让Windows驱动变成"空间刺客"!Driver Store Explorer轻松拯救你的C盘 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的C盘是不是经常莫名其妙变红࿱…...

百川2-13B对话模型一键部署:Python环境配置与快速启动指南
百川2-13B对话模型一键部署:Python环境配置与快速启动指南 想试试最新的开源大模型,却被复杂的Python环境、CUDA版本、依赖冲突搞得头大?这几乎是每个AI开发者入门时都会遇到的“劝退”第一关。今天,我们就来彻底解决这个问题。我…...

Qwen3-ASR-0.6B在IoT设备集成:ESP32-S3麦克风阵列直连轻量识别端侧方案
Qwen3-ASR-0.6B在IoT设备集成:ESP32-S3麦克风阵列直连轻量识别端侧方案 1. 引言:当智能语音遇见边缘计算 想象一下,一个智能音箱不需要连接云端,就能听懂你的指令;一个工业巡检设备,在嘈杂的车间里也能准…...

3分钟搞定智慧树自动刷课:解放双手的学习加速器终极指南
3分钟搞定智慧树自动刷课:解放双手的学习加速器终极指南 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的网课学习而烦恼吗ÿ…...

优必选上调出货目标至5000台:万台级量产在即,供应链企业专利“补位”正当时
优必选上调出货目标至5000台:万台级量产在即,供应链企业专利“补位”正当时成都余行10000项创新清单,助零部件企业快速切入人形机器人万亿供应链2026年,优必选将这一年定位为“大规模商业化”之年。Walker S系列出货目标从原计划的…...