WGAN - 瓦萨斯坦生成对抗网络
1. 背景与问题
生成对抗网络(Generative Adversarial Networks, GANs)是由Ian Goodfellow等人于2014年提出的一种深度学习模型。它包括两个主要部分:生成器(Generator)和判别器(Discriminator),两者通过对抗训练的方式,彼此不断改进,生成器的目标是生成尽可能“真实”的数据,而判别器的目标是区分生成的数据和真实数据。
虽然传统GAN在多个领域取得了巨大成功,但它们也存在一些显著的问题,尤其是训练不稳定性和模式崩溃(Mode Collapse)。为了克服这些问题,Wasserstein Generative Adversarial Network(WGAN)应运而生,提出了一种新的损失函数,基于Wasserstein距离来衡量生成数据和真实数据之间的差异,从而提高训练的稳定性和生成效果。
推荐阅读:DenseNet-密集连接卷积网络
2. 传统GAN的局限性
在传统的GAN中,生成器和判别器之间的对抗过程是通过最小化生成器的损失函数来实现的。GAN的损失函数通常使用交叉熵来衡量生成数据与真实数据的差异,公式如下:
-
生成器的损失:

-
判别器的损失:

问题:
- 梯度消失:如果判别器过强,它会变得非常接近0或1,导致生成器的梯度几乎消失,训练陷入停滞。
- 模式崩溃(Mode Collapse):生成器可能只生成非常有限的几种样本,无法覆盖真实数据的所有模式。
- 训练不稳定:在某些情况下,生成器和判别器之间的博弈可能导致不收敛,难以调节超参数。

3. WGAN简介
WGAN的提出旨在通过引入Wasserstein距离来解决传统GAN中的上述问题。Wasserstein距离是一种度量两个分布之间距离的方法,它可以有效地避免传统GAN中存在的梯度消失问题,并且提供更加稳定的训练过程。
WGAN的核心思想是在判别器中不使用标准的sigmoid激活函数,而是采用线性输出,并用Wasserstein距离来作为损失函数。Wasserstein距离的引入,使得生成器和判别器的训练变得更加平滑,且训练过程更为稳定。
4. WGAN的理论基础:Wasserstein距离
Wasserstein距离,也称为地球搬运人距离(Earth Mover’s Distance, EMD),是用于度量两个概率分布之间差异的一种方法。在生成对抗网络中,Wasserstein距离可以用来衡量生成数据分布和真实数据分布之间的距离。
Wasserstein距离的定义
给定两个分布PP和QQ,Wasserstein距离可以定义为:
W(P,Q)=infγ∈Π(P,Q)E(x,y)∼γ[∥x−y∥]W(P, Q) = \inf_{\gamma \in \Pi(P,Q)} \mathbb{E}_{(x,y) \sim \gamma} [ |x - y| ]
其中,Π(P,Q)\Pi(P,Q)表示所有可能的联合分布γ\gamma,其边缘分布分别是PP和QQ,而∥x−y∥|x - y|是样本之间的距离。
在WGAN中,Wasserstein距离的引入使得训练更加稳定,且相比于交叉熵损失函数,它能够提供更加有效的梯度信息。
证明Wasserstein距离的优势
WGAN的一个关键优势是,它避免了传统GAN中出现的梯度消失问题。具体来说,WGAN中的判别器(称为批量判别器)并不输出概率值,而是输出一个实数值,因此在优化过程中能够提供更加稳定的梯度信号。
5. WGAN的架构与优化
网络架构
WGAN的架构与传统GAN基本相同,主要包括两个网络:生成器和判别器。区别在于,WGAN中的判别器不再是一个概率分类器,而是一个逼近Wasserstein距离的网络。
生成器(Generator)
生成器的目标是生成能够尽可能接近真实数据的样本。它通过一个隐空间向量zz生成样本,输出与真实数据分布相似的样本。
判别器(Discriminator)
判别器的任务是区分真实数据和生成数据的差异,但它并不输出概率值,而是输出一个实数值,表示样本的Wasserstein距离。
WGAN的损失函数
WGAN中的损失函数非常简单。生成器的目标是最小化Wasserstein距离,而判别器的目标是最大化Wasserstein距离。WGAN的损失函数如下:
-
生成器的损失:
LG=−Ez∼pz(z)[D(G(z))]\mathcal{L}G = - \mathbb{E}{z \sim p_z(z)} [D(G(z))]
-
判别器的损失:
LD=Ex∼pdata(x)[D(x)]−Ez∼pz(z)[D(G(z))]\mathcal{L}D = \mathbb{E}{x \sim p_{data}(x)} [D(x)] - \mathbb{E}_{z \sim p_z(z)} [D(G(z))]
判别器的权重剪切
为了确保Wasserstein距离的有效性,WGAN要求判别器的参数满足1-Lipschitz条件。为此,WGAN采用了权重剪切(weight clipping)的方法,即在每次训练判别器时,都将其权重限制在一个小的范围内。例如,假设权重剪切的最大值为cc,则每次更新判别器时都会将其权重强制限制在区间[−c,c][-c, c]内。
# 伪代码:判别器权重剪切
for p in discriminator.parameters():p.data.clamp_(-c, c)
这种操作是WGAN的关键所在,它确保了判别器的权重满足Lipschitz连续性,从而使得Wasserstein距离能够有效地度量生成数据和真实数据之间的差异。
6. WGAN的训练技巧
判别器与生成器的训练
WGAN的训练过程与传统GAN类似,但有以下几点不同:
-
判别器训练:在每次更新判别器时,WGAN要求进行多个步骤的训练。一般来说,判别器的训练次数会比生成器的训练次数多。这是因为判别器需要更好地逼近真实数据和生成数据之间的Wasserstein距离。
for i in range(n_critic):D.zero_grad()real_data = get_real_data()fake_data = generator(z)loss_d = discriminator_loss(real_data, fake_data)loss_d.backward()optimizer_d.step()clip_weights(discriminator) -
生成器训练:生成器的更新则是根据判别器的输出进行的。通过反向传播,生成器可以最小化其生成数据与真实数据之间的Wasserstein距离。
G.zero_grad() fake_data = generator(z) loss_g = generator_loss(fake_data) loss_g.backward() optimizer_g.step()
权重剪切的局限性
虽然权重剪切可以保证Lipschitz条件,但它也有一定的局限性。过度的权重剪切可能导致判别器的能力受限,进而影响生成效果。因此,研究
人员提出了**梯度惩罚(Gradient Penalty)**作为改进方法,这将在后续部分讨论。
7. WGAN改进:WGAN-GP (Gradient Penalty)
WGAN-GP的动机
WGAN的一个问题在于权重剪切可能导致网络不稳定或训练过慢。为了解决这个问题,提出了WGAN-GP(Wasserstein GAN with Gradient Penalty)方法,它引入了梯度惩罚来代替权重剪切,从而保持Wasserstein距离的有效性。
WGAN-GP损失函数
WGAN-GP的损失函数相比WGAN有所改进,加入了梯度惩罚项,具体如下:
- 判别器损失: LD=Ex∼pdata(x)[D(x)]−Ez∼pz(z)[D(G(z))]+λEx∼px[(∥∇xD(x)∥2−1)2]\mathcal{L}D = \mathbb{E}{x \sim p_{data}(x)} [D(x)] - \mathbb{E}{z \sim p_z(z)} [D(G(z))] + \lambda \mathbb{E}{\hat{x} \sim p_{\hat{x}}} \left[ (|\nabla_{\hat{x}} D(\hat{x})|_2 - 1)^2 \right]
其中,x^\hat{x}是从真实数据和生成数据之间的插值中采样得到的,λ\lambda是梯度惩罚项的系数。
训练过程
WGAN-GP的训练过程与WGAN相似,只是判别器的更新方式有所不同。具体来说,我们需要计算梯度惩罚,并将其加到判别器的损失函数中:
# 计算梯度惩罚
def compute_gradient_penalty(D, real_data, fake_data):alpha = torch.rand(real_data.size(0), 1, 1, 1).to(real_data.device)interpolated = alpha * real_data + (1 - alpha) * fake_datainterpolated.requires_grad_(True)d_interpolated = D(interpolated)grad_outputs = torch.ones_like(d_interpolated)gradients = torch.autograd.grad(outputs=d_interpolated, inputs=interpolated, grad_outputs=grad_outputs, create_graph=True, retain_graph=True, only_inputs=True)[0]gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()return gradient_penalty
优势与效果
WGAN-GP的引入梯度惩罚后,训练过程显著更加稳定,避免了WGAN中因权重剪切带来的不稳定性和训练速度较慢的问题。WGAN-GP已成为生成对抗网络中常用的变体之一。
8. WGAN应用案例
WGAN和WGAN-GP已被广泛应用于图像生成、文本生成、音乐生成等多个领域。以下是一些实际的应用案例:
- 图像生成:WGAN常用于高分辨率图像的生成,尤其是在超分辨率图像生成、图片到图片的转换等任务中表现优异。
- 文本生成:WGAN也可以用于自然语言处理领域,通过生成器生成自然语言文本,判别器判断文本的质量。
- 数据增强:WGAN被用作数据增强技术,通过生成更多的训练数据来提高模型的泛化能力。
9. WGAN与传统GAN对比
优点
- 训练稳定性:WGAN通过引入Wasserstein距离,使得训练过程更加稳定,避免了梯度消失和模式崩溃的问题。
- 优化效果:WGAN优化过程中生成器和判别器之间的博弈更加平衡,从而生成质量更高的样本。
缺点
- 计算成本:WGAN的计算成本较传统GAN更高,尤其是在判别器训练阶段,计算Wasserstein距离和梯度惩罚需要更多的计算资源。
- 收敛速度:尽管WGAN的训练稳定性较强,但它的收敛速度可能比其他类型的GAN稍慢。
10. 总结与展望
WGAN为生成对抗网络的训练提供了一种新的优化策略,通过引入Wasserstein距离来替代传统的交叉熵损失函数,显著提高了训练的稳定性和生成质量。尽管WGAN在许多方面具有优势,但仍存在一些计算成本和收敛速度上的挑战。
未来,随着硬件的进步和算法的优化,WGAN及其变种(如WGAN-GP)有望在更广泛的应用中得到进一步的推广与发展。同时,研究人员也在不断探索新的方法来优化WGAN的训练过程,进一步提升其在生成任务中的表现。
相关文章:
WGAN - 瓦萨斯坦生成对抗网络
1. 背景与问题 生成对抗网络(Generative Adversarial Networks, GANs)是由Ian Goodfellow等人于2014年提出的一种深度学习模型。它包括两个主要部分:生成器(Generator)和判别器(Discriminator)…...
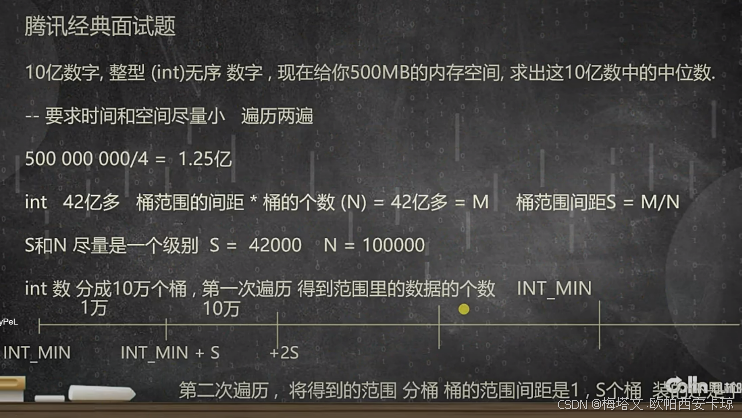
海量数据的处理
一般来说都是针对数据量特别大,内存有限制的。 第一类:topk问题 比如,在海量数据中找前50大的数据怎么办? 方法一:使用小顶堆,用小顶堆维护这50个元素,当有新元素到来时,直接与堆…...

区块链的数学基础:核心原理与应用解析
引言 区块链技术作为分布式账本系统,成功地解决了传统中心化系统中的信任问题。其背后隐藏着复杂而精妙的数学原理,包括密码学、哈希函数、数字签名、椭圆曲线、零知识证明等。这些数学工具不仅为区块链提供了安全保障,也为智能合约和去中心…...

1.5 GPT 模型家族全解析:从 GPT-1 到 GPT-4 的演进与创新
GPT 模型家族全解析:从 GPT-1 到 GPT-4 的演进与创新 随着人工智能技术的飞速发展,GPT(Generative Pre-trained Transformer)模型家族已经成为了现代自然语言处理(NLP)领域的标杆。从初代的 GPT-1 到最新的 GPT-4,每一代模型的发布都标志着人工智能技术的一个飞跃,并推…...

自动驾驶之DriveMM: All-in-One Large Multimodal Model for Autonomous Driving
1. 写在前面 工作之后,主要从事于偏工程比较多的内容, 很少有机会读论文了,但2025年,由于之前有些算法的背景, 后面可能会接触一些多模态大模型相关的工作,所以又调头有点往算法的方向偏移, 而算法呢,很重要的一点就是阅读论文。2025年,再拾起论文这块的工作。 今天…...

Spring Boot 配置(官网文档解读)
目录 摘要 Spring Boot 配置加载顺序 配置文件加载顺序 Spring Boot 配置加载方式 Value Value 注解简单示例 ConfigurationProperties 启动 ConfigurationProperties ConfigurationProperties 验证 ConfigurationProperties 与 Value 对比 Autowired Autowired 自…...

SparkSQL数据源与数据存储
文章目录 1. 大数据分析流程2. Spark SQL数据源2.1 SparkSQL常见数据源2.2 SparkSQL支持的文本格式2.3 加载外部数据源步骤 3. 本地文件系统加载数据3.1 本地文件系统加载JSON格式数据3.1.1 概述3.1.2 案例演示 3.2 本地文件系统加载CSV格式数据3.2.1 概述3.2.2 案例演示 3.3 本…...

【BQ3568HM开发板】开箱测试
引言 很荣幸入选了“电子发烧友”的贝启科技BQ3568HM开源鸿蒙开发板评测活动,上周在出差,今天才有机会开箱一下开发板,简单测试一下。 开机测试 插上电源开机后,系统显示的是润和的DAYU的logo,看来厂商提供的软件包…...

3D 模型格式转换之 STP 转 STL 深度解析
在 3D 模型的多元世界中,格式如同语言,不同格式适用于不同场景。STP 和 STL 是两种常见格式,本文将深入剖析 STP 转 STL 的相关内容。 一、STP 与 STL 格式基础 (一)STP 格式剖析 STP,即标准交换格式&am…...

MySQL数据库的数据文件保存在哪?MySQL数据存在哪里
在安装好MySQL数据库使用一段时间后,会产生许多的数据库和数据。那这些数据库的数据文件存放在本地文件夹的什么位置呢 一、默认位置 一般来说MySQL数据库的数据文件都是存放在data文件夹之中,但是根据使用的存储引擎不同,产生的一些文件也…...

低代码系统-UI设计器核心介绍
为什么会有UI设计器 最开始的UI设计器其实是为了满足企业门户的需求而产生的,后面因为表单设计器的功能有限,所以干脆就用了一套设计器。 UI设计器从功能使用上来说,跟表单设计器没有多大区别,只是多了组件和加强了事件和组件的能…...

ubuntu20.04有亮度调节条但是调节时亮度不变
尝试了修改grub文件,没有作用,下载了brightness-controllor,问题解决了。 sudo add-apt-repository ppa:apandada1/brightness-controller sudo apt update sudo apt install brightness-controller 之后在应用软件中找到brightness-contro…...

USART_串口通讯轮询案例(HAL库实现)
引言 前面讲述的串口通讯案例是使用寄存器方式实现的,有利于深入理解串口通讯底层原理,但其开发效率较低;对此,我们这里再讲基于HAL库实现的串口通讯轮询案例,实现高效开发。当然,本次案例需求仍然和前面寄…...

【前端】CSS学习笔记(2)
目录 CSS3新特性圆角阴影动画keyframes 创建动画animation 执行动画timing-function 时间函数direction 播放方向过渡动画(transition) 媒体查询设置meta标签媒体查询语法 雪碧图字体图标 CSS3新特性 圆角 使用CSS3border-radius属性,你可以…...

【esp32小程序】小程序篇02——连接git
一、创建仓库 进入gitee官网,登录(如果没有gitee账号的就自行注册一下)。 点击号-->新建仓库 填写好必填信息,然后点击“创建” 二、微信开发者工具配置 在微信开发者工具打开我们的项目。按下面的步骤依次点击 三、验证 点…...

echarts柱状图象形图,支持横向滑动
展示效果 代码 let xData [2020,2021,2022,2023, 2024, 2025, 2026]; let yData [267,2667,2467,2667, 3234, 4436,666]; option {grid: {left: 5%,right: 5%,top: 15%,bottom: 5%,containLabel: true},// 滚动条dataZoom: [{show: true,type: inside,zoomLock: true,throt…...

YOLO系列代码
Test-Time Augmentation TTA (Test Time Augmentation)是指在test过程中进行数据增强。其思想非常简单,就是在评测阶段,给每个输入进行多种数据增广变换,将一个输入变成多个输入,然后再merge起来一起输出,形成一种ensemble的效果,可以用来提点。参考:…...

HTML根元素<html>的语言属性lang:<html lang=“en“>
诸神缄默不语-个人CSDN博文目录 在编写HTML页面时,通常会看到<html lang"en">这行代码,特别是在网页的开头部分,就在<!DOCTYPE html>后面。许多开发者可能对这个属性的含义不太了解,它到底有什么作用&…...

opencv在图片上添加中文汉字(c++以及python)
opencv在图片上添加中文汉字(c以及python)_c opencv绘制中文 知乎-CSDN博客 环境: ubuntu18.04 desktopopencv 3.4.15 opencv是不支持中文的。 这里C代码是采用替换原图的像素点来实现的,实现之前我们先了解一下汉字点阵字库。…...

Perplexity AI 周六向 TikTok 母公司字节跳动递交了一项提案
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...