Elasticsearch(ES)基础查询语法的使用
1. Match Query (全文检索查询)
-
用于执行全文检索,适合搜索文本字段。
{
“query”: {
“match”: {
“field”: “value”
}
}
} -
match_phrase:精确匹配短语,适合用于短语搜索。
{
“query”: {
“match_phrase”: {
“field”: “text”
}
}
}
2. Term Query (精确匹配查询)
-
用于对某个字段的精确值进行查询,常用于不分词的字段(如ID、标签、关键词等)。
{
“query”: {
“term”: {
“field”: “value”
}
}
}
3. Range Query (范围查询)
-
用于查询数值、日期、时间等范围内的数据。
{
“query”: {
“range”: {
“field”: {
“gte”: 10, // 大于等于
“lte”: 100, // 小于等于
“gt”: 10, // 大于
“lt”: 100 // 小于
}
}
}
}
4. Bool Query (布尔查询)
-
用于将多个查询组合在一起,可以使用 must、should、must_not 等操作符。
{
“query”: {
“bool”: {
“must”: [
{ “match”: { “field1”: “value1” } },
{ “match”: { “field2”: “value2” } }
],
“filter”: [
{ “range”: { “price”: { “gte”: 50 } } }
],
“should”: [
{ “match”: { “field3”: “value3” } }
],
“must_not”: [
{ “term”: { “field4”: “value4” } }
]
}
}
}
5. Prefix Query (前缀匹配查询)
-
用于查询字段值的前缀匹配,常用于搜索补全或模糊搜索。
{
“query”: {
“prefix”: {
“field”: “prefix_value”
}
}
}
6. Wildcard Query (通配符查询)
-
支持
*(匹配任意字符)和?(匹配单个字符)的通配符查询。{
“query”: {
“wildcard”: {
“field”: “prefix*”
}
}
}
7. Fuzzy Query (模糊查询)
-
用于查询与某个值相似的字段,常用于容忍拼写错误的场景。
{
“query”: {
“fuzzy”: {
“field”: {
“value”: “exampl”
}
}
}
}
8. Regexp Query (正则表达式查询)
-
使用正则表达式进行查询。
{
“query”: {
“regexp”: {
“field”: “pattern.*”
}
}
}
9. Match All Query (匹配所有文档)
-
用于返回索引中的所有文档。
{
“query”: {
“match_all”: {}
}
}
10. Term Range Query (字段范围查询)
-
用于查询一个字段值在特定范围内的文档,类似
range query,但term查询是基于精确值的。{
“query”: {
“range”: {
“field”: {
“gte”: 5,
“lte”: 10
}
}
}
}
11. Exists Query (字段存在查询)
-
用于查询某个字段是否存在。
{
“query”: {
“exists”: {
“field”: “field_name”
}
}
}
12. Geo Queries (地理位置查询)
-
Elasticsearch 支持基于地理位置的查询,如基于位置的范围查询或距离查询。
-
Geo Distance Query
{
“query”: {
“bool”: {
“filter”: {
“geo_distance”: {
“distance”: “200km”,
“location”: {
“lat”: 40.73,
“lon”: -74.1
}
}
}
}
}
}
13. Aggregation (聚合查询)
-
Elasticsearch 提供了强大的聚合功能,可以对查询结果进行分组、统计等操作。
-
Terms Aggregation (分词聚合)
{
“aggs”: {
“group_by_field”: {
“terms”: {
“field”: “field_name”
}
}
}
} -
Range Aggregation (范围聚合)
{
“aggs”: {
“price_ranges”: {
“range”: {
“field”: “price”,
“ranges”: [
{ “to”: 100 },
{ “from”: 100, “to”: 200 },
{ “from”: 200 }
]
}
}
}
}
14. Highlighting (高亮查询)
-
用于返回搜索结果中高亮显示匹配的字段。
{
“query”: {
“match”: {
“field”: “value”
}
},
“highlight”: {
“fields”: {
“field”: {}
}
}
}
15. Source Filtering (源字段过滤)
-
用于控制哪些字段需要返回,哪些不需要返回。
{
“_source”: [“field1”, “field2”],
“query”: {
“match”: {
“field”: “value”
}
}
}
16. Prefix and Wildcard Query (前缀和通配符查询)
-
用于对字段值进行前缀或通配符匹配,常用于实现补全或模糊搜索。
{
“query”: {
“prefix”: {
“field”: “prefix*”
}
}
}
扩展*
匹配度查询
在 Elasticsearch 中,minimum_should_match 是布尔查询(bool query)的一部分,用于控制 should 子句的匹配度。should 子句的作用是定义一组可选条件,当文档满足其中至少一个条件时,它会被视为匹配。通过设置 minimum_should_match 参数,可以控制至少多少个 should 子句必须匹配,以提高查询的精度和灵活性。
1. 基本概念:
- 在布尔查询中,
should子句表示可选条件。 - 默认情况下,如果
bool查询中有多个should子句,文档只需满足其中任何一个条件就可以匹配。 - 使用
minimum_should_match参数,可以要求文档至少满足某些数量的should子句,以增加查询的严格性。
例如:如果你有 5 个 should 子句,并设置 minimum_should_match 为 3,则文档必须满足其中至少 3 个 should 条件才能被视为匹配。
2. 用法:
minimum_should_match 可以设置为:
- 整数值:指定最小匹配的
should子句数量。 - 百分比:指定至少要匹配的
should子句的百分比。 - 动态值:例如基于文档数量或其他复杂逻辑的动态匹配要求。
3. 示例:
(1) 简单的布尔查询 - 至少匹配 2 个 should 子句
{"query": {"bool": {"should": [{ "match": { "field1": "value1" } },{ "match": { "field2": "value2" } },{ "match": { "field3": "value3" } }],"minimum_should_match": 2 // 至少匹配 2 个 `should` 子句}}
}
- 在这个例子中,文档需要匹配至少 2 个
should子句(例如,匹配field1和field2或者field2和field3)。
(2) 使用百分比的 minimum_should_match
如果你有多个 should 子句,可以通过百分比来控制匹配条件。例如,如果你有 5 个 should 子句,设置 minimum_should_match 为 60%,则至少需要满足 3 个子句。
{"query": {"bool": {"should": [{ "match": { "field1": "value1" } },{ "match": { "field2": "value2" } },{ "match": { "field3": "value3" } },{ "match": { "field4": "value4" } },{ "match": { "field5": "value5" } }],"minimum_should_match": "60%" // 至少匹配 60% 的 `should` 子句 (即 3 个子句)}}
}
(3) 动态匹配 - 基于词数的 minimum_should_match
还可以根据查询中的词数设置 minimum_should_match,比如设置为 "3<80%",表示如果查询中有 3 个以上的 should 子句,则至少匹配其中 80%的子句。
{"query": {"bool": {"should": [{ "match": { "field1": "value1" } },{ "match": { "field2": "value2" } },{ "match": { "field3": "value3" } },{ "match": { "field4": "value4" } },{ "match": { "field5": "value5" } }],"minimum_should_match": "3<80%" // 如果有超过 3 个 `should` 子句,至少匹配 80%}}
}
4. 如何决定 minimum_should_match 值
- 业务需求:设置
minimum_should_match的主要目的是根据业务需求平衡准确度和召回率。如果你需要更严格的匹配,增加minimum_should_match的值;如果需要更高的召回率,可以减少它。 - 文档内容:在处理文档时,字段的长度、词汇密度、停用词等都可能影响查询的结果。可以通过实验和调整
minimum_should_match来找到最适合的设置。
5. 示例:
假设你有以下文档数据:
{"field1": "apple orange banana","field2": "apple orange","field3": "banana"
}
你要查找包含 “apple” 和 “orange” 的文档,并且需要设置 minimum_should_match 为 1。查询语句如下:
{"query": {"bool": {"should": [{ "match": { "field1": "apple" } },{ "match": { "field1": "orange" } },{ "match": { "field1": "banana" } }],"minimum_should_match": 1}}
}
在这个例子中,只要文档匹配一个 should 子句(比如 field1 包含 “apple” 或者 “orange”),就会被视为匹配。
6. 注意事项
minimum_should_match在布尔查询中是可选的,只有当你使用了多个should子句时才有意义。- 设置的值越大,匹配条件越严格。通过调整
minimum_should_match的值,可以灵活地调整查询的宽松程度。 minimum_should_match参数可以通过数值、百分比、动态规则来设置,以适应不同的查询需求。
7. Match 查询的选项
(1) fuzziness:模糊匹配
如果你希望支持拼写错误或词语变化,可以使用 模糊查询。通过设置 fuzziness,Elasticsearch 会尝试匹配与查询词相似的词。
{"query": {"match": {"title": {"query": "Elasticsearh", // 拼写错误"fuzziness": "AUTO" // 自动模糊匹配}}}
}
fuzziness: "AUTO":根据查询词的长度自动设置模糊匹配的编辑距离。fuzziness: "1":设置允许的最大编辑距离为 1(允许 1 个字符的更改,如替换、删除、插入)。
(2) minimum_should_match:最小匹配
在某些情况下,你可能想要求查询中至少匹配一个或多个词。minimum_should_match 可以控制需要匹配的最小词数。
{"query": {"match": {"content": {"query": "Elasticsearch tutorial advanced","minimum_should_match": 2 // 至少匹配 2 个词也可以用百分比替代示例:"60%"(指匹配总分词的百分比)}}}
}
minimum_should_match:设置至少要匹配多少个词。
(3) boost:提高某个词的匹配优先级
你可以通过 boost 来提高查询某些词的权重,使这些词匹配的文档更具优先级。
{"query": {"match": {"content": {"query": "Elasticsearch tutorial","boost": 2.0 // 增加查询的权重,使该查询匹配的文档优先返回}}}
}
boost:提高查询的匹配优先级,权重范围通常是 0 到 10,数值越大,匹配的优先级越高。
** match 查询常见问题**
(1) 如何处理大小写问题?
默认情况下,match 查询不区分大小写。Elasticsearch 会使用分词器(如 standard 分词器)将文本转为小写,因此可以处理大小写问题。
(2) match 查询与 term 查询的区别
match查询:适用于文本字段的分词匹配,会分析查询文本并与字段内容进行分词对比。term查询:用于精确匹配,适用于不分词的字段(如keyword字段)。
聚合相关
在 Elasticsearch 中,**聚合(Aggregation)**是一个强大的功能,用于对查询结果进行分组、统计、度量等操作。聚合查询不仅可以按字段进行分组,还可以进行计算(如求和、平均值等),在数据分析和可视化中非常有用。聚合查询和普通查询(例如 match、range 查询)是分开的,但可以结合使用。
1. 聚合查询的基本结构
聚合查询通常包含在 aggs(聚合)部分。在 Elasticsearch 中,聚合查询并不返回实际的文档,而是返回聚合结果,例如每个分组的文档数量、平均值、最大值等。
聚合查询的基本结构:
{"query": {"match": {"field": "value"}},"aggs": {"aggregation_name": {"aggregation_type": {"field": "field_name"}}}
}
2. 常见的聚合类型
以下是 Elasticsearch 中常见的聚合类型:
(1) Terms 聚合(分词聚合)
按字段值进行分组统计,返回每个字段值及其出现次数。常用于进行分组查询。
{"query": {"match_all": {}},"aggs": {"group_by_field": {"terms": {"field": "field_name"}}}
}
示例:
假设你有一个名为 category 的字段,你想按类别进行分组查询,统计每个类别的文档数量。
{"query": {"match_all": {}},"aggs": {"categories": {"terms": {"field": "category.keyword" // 使用 .keyword 进行精确匹配}}}
}
(2) Range 聚合(范围聚合)
用于按指定的数值范围对文档进行分组。适用于数值、日期等字段。
{"query": {"match_all": {}},"aggs": {"price_ranges": {"range": {"field": "price","ranges": [{ "to": 50 },{ "from": 50, "to": 100 },{ "from": 100 }]}}}
}
示例:
假设你想要按价格进行分段统计,例如分为“低于 50”、“50 到 100”以及“大于 100”三个区间。
(3) Avg 聚合(平均值聚合)
用于计算字段的平均值。
{"query": {"match_all": {}},"aggs": {"average_price": {"avg": {"field": "price"}}}
}
示例:
计算 price 字段的平均值。
(4) Sum 聚合(求和聚合)
用于计算字段的总和。
{"query": {"match_all": {}},"aggs": {"total_price": {"sum": {"field": "price"}}}
}
示例:
计算 price 字段的总和。
(5) Max 和 Min 聚合(最大值和最小值聚合)
用于计算字段的最大值和最小值。
{"query": {"match_all": {}},"aggs": {"max_price": {"max": {"field": "price"}},"min_price": {"min": {"field": "price"}}}
}
示例:
计算 price 字段的最大值和最小值。
(6) Date Histogram 聚合(日期直方图聚合)
将日期数据按时间段进行分组,常用于按天、周、月等时间单位进行聚合。
{"query": {"match_all": {}},"aggs": {"sales_over_time": {"date_histogram": {"field": "timestamp","calendar_interval": "day" // 按天分组}}}
}
示例:
按天统计销售数据。
(7) Top Hits 聚合(获取 top N 文档)
获取符合条件的 top N 文档,通常用于获取聚合组中的部分文档,适用于展示最高分的文档。
{"query": {"match_all": {}},"aggs": {"top_categories": {"terms": {"field": "category.keyword"},"aggs": {"top_hits": {"top_hits": {"size": 3 // 返回每个类别下的前 3 个文档}}}}}
}
(8) Cardinality 聚合(基数聚合)
用于计算字段的基数(去重后的唯一值数量)。例如,统计不同的用户数或产品数。
{"query": {"match_all": {}},"aggs": {"unique_users": {"cardinality": {"field": "user_id"}}}
}
示例:
计算 user_id 字段中不重复的用户数量。
3. 聚合嵌套
聚合查询不仅可以进行单一聚合,还可以进行嵌套聚合,即在一个聚合的结果上进行进一步的聚合。下面是一个例子,展示如何在一个 terms 聚合的每个分组上执行进一步的聚合:
{"query": {"match_all": {}},"aggs": {"categories": {"terms": {"field": "category.keyword"},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}
示例:
先按 category 分组,再计算每个类别的平均价格。
4. 聚合结果的格式
聚合查询的结果会包含在 aggregations(或 aggs)字段中。结果结构通常类似于下面的格式:
{"aggregations": {"categories": {"buckets": [{"key": "electronics", // 分组的字段值"doc_count": 100, // 每个分组的文档数量"avg_price": {"value": 300 // 每个分组的聚合结果,如平均价格}},{"key": "clothing","doc_count": 80,"avg_price": {"value": 50}}]}}
}
聚合结果:
buckets:每个分组的结果集合。key:分组的字段值。doc_count:该分组中的文档数量。- 聚合结果(例如
avg_price):聚合操作的结果。
5. 聚合的性能优化
- 避免过多的
terms聚合:terms聚合会对字段值进行分组,可能会消耗大量内存和计算资源。对于高基数字段(如用户ID),考虑限制返回的分组数量。 - 限制返回的文档数量:可以通过
size参数来限制每个分组返回的文档数量,避免过多数据返回。 - 减少聚合的嵌套深度:过多层次的嵌套聚合会增加 Elasticsearch 的计算负担,尽量保持聚合的平面结构。
相关文章:
基础查询语法的使用)
Elasticsearch(ES)基础查询语法的使用
1. Match Query (全文检索查询) 用于执行全文检索,适合搜索文本字段。 { “query”: { “match”: { “field”: “value” } } } match_phrase:精确匹配短语,适合用于短语搜索。 { “query”: { “match_phrase”: { “field”: “text” }…...

一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】
一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】 一、Milvus 是什么?【程序员猫爪】1、Milvus 是一种高性能、高扩展性的向量数据库…...

前端之移动端
视口 布局视口 layout viewport 视口(viewport)就是浏览器显示页面内容的屏幕区域。 视口可以分为布局视口、视觉视口和理想视口 一般移动设备的浏览器都默认设置了一个布局视口,用于解决早期的PC端页面在手机上显示的问题。 iOS, Androi…...
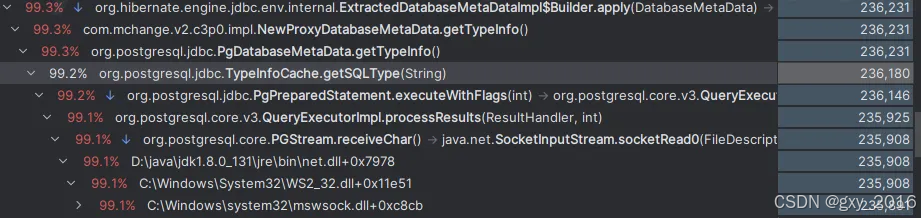
记一次 SpringBoot 启动慢的问题
记一次 SpringBoot 启动慢的问题 背景问题描述分析处理Flame Graph 火焰图Call Tree 调用树关键词检索尝试解决 为什么这样反向检索问题梳理 复盘处理流程为什么 Reference 背景 最近临时接了一个任务,就从一个旧 springboot 项目 copy 出来,临时写个服…...
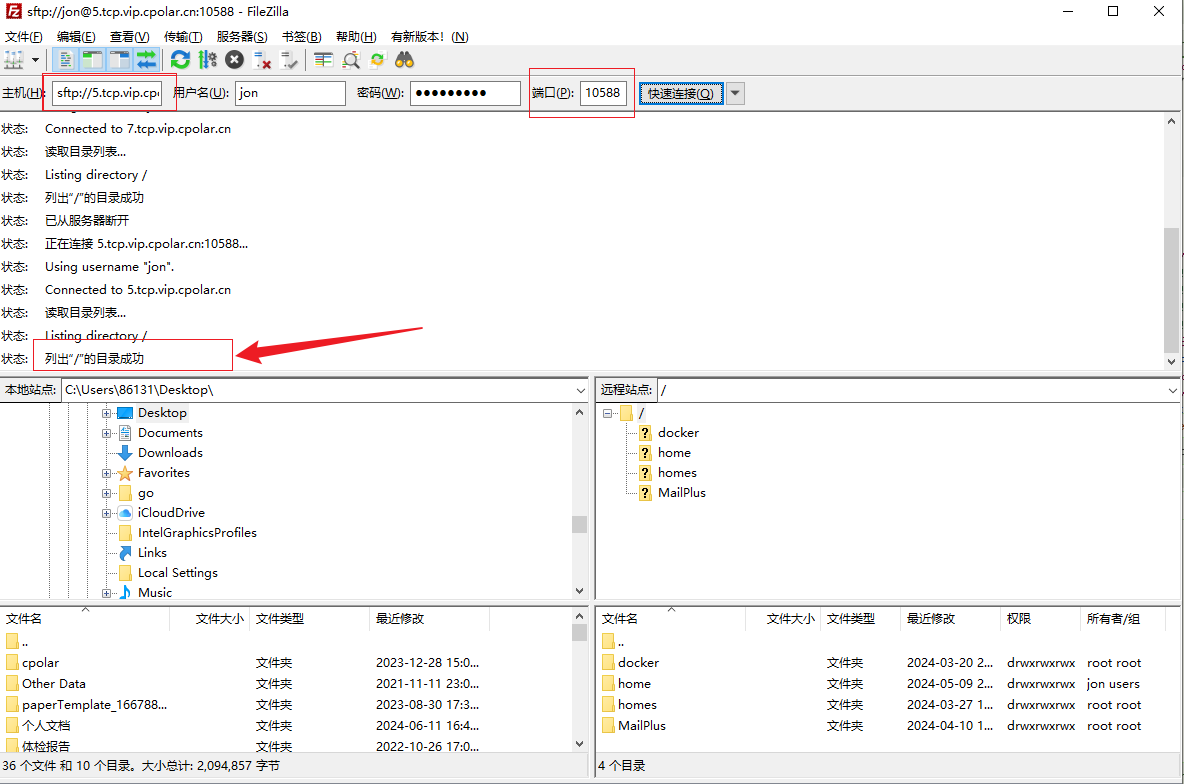
高效安全文件传输新选择!群晖NAS如何实现无公网IP下的SFTP远程连接
文章目录 前言1. 开启群晖SFTP连接2. 群晖安装Cpolar工具3. 创建SFTP公网地址4. 群晖SFTP远程连接5. 固定SFTP公网地址6. SFTP固定地址连接 前言 随着远程办公和数据共享成为新常态,如何高效且安全地管理和传输文件成为了许多人的痛点。如果你正在寻找一个解决方案…...

如何在Python中进行JSON数据的序列化和反序列化?
在Python中,JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。Python内置的json模块提供了简单易用的方法来实现数据的序列化和反序列化。下面将详细介绍如何…...

学习记录-统计记录场景下的Redis写请求合并优化实践
学习记录-使用Redis合并写请求来优化性能 1.业务背景 学习进度的统计功能:为了更精确的记录用户上一次播放的进度,采用的方案是:前端每隔15秒就发起一次请求,将播放记录写入数据库。但问题是,提交播放记录的业务太复杂了&#x…...

网站HTTP改成HTTPS
您不仅需要知道如何将HTTP转换为HTTPS,还必须在不妨碍您的网站自成立以来建立的任何搜索排名权限的情况下进行切换。 为什么应该从HTTP转换为HTTPS? 与非安全HTTP于不同,安全域使用SSL(安全套接字层)服务器上的加密代…...
上安装极狐GitLab?)
如何在龙蜥 OS(AliOS)上安装极狐GitLab?
本文分享如何在龙蜥操作系统(AliOS)(包括 RHCK 和 ANCK 两种,两种方式的安装流程一样)上安装极狐GitLab? 前提条件 一个安装了龙蜥操作系统的云服务器 可以查看 /etc/os-release中的信息,确认…...

unity插件Excel转换Proto插件-ExcelToProtobufferTool
unity插件Excel转换Proto插件-ExcelToProtobufferTool **ExcelToProtobufTool 插件文档****1. 插件概述****2. 默认配置类:DefaultIProtoPathConfig****属性说明** **3. 自定义配置类****定义规则****示例代码** **4. 使用方式****4.1 默认路径****4.2 自定义路径**…...

C#中的语句
C#提供了各式各样的语句,大多数是由C和C发展而来,当然,在C#中做了相应修改。语句和表达式一样,都是C#程序的基本组成部分,在本文我们来一起学习C#语句。 1.语句 语句是构造所有C#程序的过程构造块。在语句中可以声明…...

《罗宾逊-旅途VR》Build2108907官方学习版
《罗宾逊-旅途VR》官方版 https://pan.xunlei.com/s/VODiY5gn_fNxKREdVRdwVboCA1?pwdsh3f# 从第一人称的角度进行探索,玩家将遇到一系列恐龙和生物,这些恐龙和生物会对它们在泰森三世生态系统中的存在做出反应。强调与周围环境的互动,鼓励玩…...

常用的跨域方案有哪些?
在前端开发中,跨域(Cross-Origin)是一个常见问题,通常是由于浏览器的同源策略(Same-Origin Policy)限制导致的。为了解决跨域问题,前端开发者可以采用多种方案。 1. CORS(跨域资源共…...

JDBC实验测试
一、语言和环境 实现语言:Java。 环境要求:IDEA2023.3、JDK 17 、MySQL8.0、Navicat 16 for MySQL。 二、技术要求 该系统采用 SWING 技术配合 JDBC 使用 JAVA 编程语言完成桌面应用开发。 三、功能要求 某电商公司为了方便客服查看用户的订单信…...

ChatGPT 摘要,以 ESS 作为你的私有数据存储
作者:来自 Elastic Ryan_Earle 本教程介绍如何设置 Elasticsearch 网络爬虫,将网站索引到 Elasticsearch 中,然后利用 ChatGPT 使用我们的私人数据来总结对其提出的问题。 Python 脚本的 Github Repo:https://github.com/Gunner…...

每日一题洛谷P2669 [NOIP2015 普及组] 金币c++
#include<iostream> using namespace std; int main() {int k;cin >> k;int sum 0;int n 1;while (k > 0) {sum n * n;k - n;n;}sum k * (n - 1);cout << sum << endl;return 0; }...

【C语言系列】深入理解指针(2)
一、数组名的理解 上一篇文章中我们写过一个这样的代码: int arr[10] {1,2,3,4,5,6,7,8,9,10}; int *p &arr[0];这里使用&arr[0] 的方式拿到了数组第⼀个元素的地址,但是其实数组名本来就是地址,而且是数组首元素的地址ÿ…...

与 Spring Boot 的无缝集成:ShardingSphere 快速集成实践
ShardingSphere 是一个轻量级的开源分布式数据库中间件,它支持分库分表、分布式事务、读写分离等功能。它能够与各种应用框架进行集成,其中与 Spring Boot 的集成非常流行,因为它能够帮助开发者在 Spring Boot 项目中快速实现高性能的分布式数…...

【QT】窗口/界面置于最前端显示,且激活该窗口
目录 0.环境 1.问题描述 2.具体实现 0.环境 windows11 qt 1.问题描述 我有一个窗口QMainWindow(也适用于QWidget或QDialog),想让其在显示的时候置于最前面,且激活成为当前活动窗口 2.具体实现 mainWindow->show();mainWind…...

DOL-288 多功能电子计时器说明书
新买一个计时器,它的用法不太直观,所以把说明书留在这里,以便以后查询。 DOL-288 多功能电子计时器说明书 1.功能说明: 正计时功能,计时上限为23小时59分59秒倒计时功能,计时上限为23小时59分59秒&#…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...