【深度学习基础】多层感知机 | 权重衰减

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、范数与权重衰减
- 二、高维线性回归
- 三、权重衰减的从零开始实现
- (一)初始化模型参数
- (二)定义 L 2 L_2 L2范数惩罚
- (三)定义训练代码实现
- (四)忽略正则化直接训练
- (五)使用权重衰减
- 四、权重衰减的简洁实现
- 小结
前一节我们描述了过拟合的问题,本节我们将介绍一些正则化模型的技术。我们总是可以通过去收集更多的训练数据来缓解过拟合。但这可能成本很高,耗时颇多,或者完全超出我们的控制,因而在短期内不可能做到。假设我们已经拥有尽可能多的高质量数据,我们便可以将重点放在正则化技术上。
回想一下,在多项式回归的例子(模型选择、欠拟合和过拟合)中,我们可以通过调整拟合多项式的阶数来限制模型的容量。实际上,限制特征的数量是缓解过拟合的一种常用技术。然而,简单地丢弃特征对这项工作来说可能过于生硬。我们继续思考多项式回归的例子,考虑高维输入可能发生的情况。多项式对多变量数据的自然扩展称为单项式(monomials),也可以说是变量幂的乘积。单项式的阶数是幂的和。例如, x 1 2 x 2 x_1^2 x_2 x12x2和 x 3 x 5 2 x_3 x_5^2 x3x52都是3次单项式。
注意,随着阶数 d d d的增长,带有阶数 d d d的项数迅速增加。 给定 k k k个变量,阶数为 d d d的项的个数为 ( k − 1 + d k − 1 ) {k - 1 + d} \choose {k - 1} (k−1k−1+d),即 C k − 1 + d k − 1 = ( k − 1 + d ) ! ( d ) ! ( k − 1 ) ! C^{k-1}_{k-1+d} = \frac{(k-1+d)!}{(d)!(k-1)!} Ck−1+dk−1=(d)!(k−1)!(k−1+d)!。因此即使是阶数上的微小变化,比如从 2 2 2到 3 3 3,也会显著增加我们模型的复杂性。仅仅通过简单的限制特征数量(在多项式回归中体现为限制阶数),可能仍然使模型在过简单和过复杂中徘徊,我们需要一个更细粒度的工具来调整函数的复杂性,使其达到一个合适的平衡位置。
一、范数与权重衰减
在【深度学习基础】预备知识 | 线性代数 中,我们已经描述了 L 2 L_2 L2范数和 L 1 L_1 L1范数,它们是更为一般的 L p L_p Lp范数的特殊情况。
在训练参数化机器学习模型时,权重衰减(weight decay)是最广泛使用的正则化的技术之一,它通常也被称为 L 2 L_2 L2正则化。这项技术通过函数与零的距离来衡量函数的复杂度,因为在所有函数 f f f中,函数 f = 0 f = 0 f=0(所有输入都得到值 0 0 0)在某种意义上是最简单的。但是我们应该如何精确地测量一个函数和零之间的距离呢?没有一个正确的答案。事实上,函数分析和巴拿赫空间理论的研究,都在致力于回答这个问题。
一种简单的方法是通过线性函数 f ( x ) = w ⊤ x f(\mathbf{x}) = \mathbf{w}^\top \mathbf{x} f(x)=w⊤x中的权重向量的某个范数来度量其复杂性,例如 ∥ w ∥ 2 \| \mathbf{w} \|^2 ∥w∥2。要保证权重向量比较小,最常用方法是将其范数作为惩罚项加到最小化损失的问题中。将原来的训练目标最小化训练标签上的预测损失,调整为最小化预测损失和惩罚项之和。现在,如果我们的权重向量增长的太大,我们的学习算法可能会更集中于最小化权重范数 ∥ w ∥ 2 \| \mathbf{w} \|^2 ∥w∥2。这正是我们想要的。让我们回顾一下【深度学习基础】线性神经网络 | 线性回归 中的线性回归例子。我们的损失由下式给出:
L ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w ⊤ x ( i ) + b − y ( i ) ) 2 (1) L(\mathbf{w}, b) = \frac{1}{n}\sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2 \tag{1} L(w,b)=n1i=1∑n21(w⊤x(i)+b−y(i))2(1)
回想一下, x ( i ) \mathbf{x}^{(i)} x(i)是样本 i i i的特征, y ( i ) y^{(i)} y(i)是样本 i i i的标签, ( w , b ) (\mathbf{w}, b) (w,b)是权重和偏置参数。为了惩罚权重向量的大小,我们必须以某种方式在损失函数中添加 ∥ w ∥ 2 \| \mathbf{w} \|^2 ∥w∥2,但是模型应该如何平衡这个新的额外惩罚的损失?实际上,我们通过正则化常数 λ \lambda λ来描述这种权衡,这是一个非负超参数,我们使用验证数据拟合:
L ( w , b ) + λ 2 ∥ w ∥ 2 (2) L(\mathbf{w}, b) + \frac{\lambda}{2} \|\mathbf{w}\|^2 \tag{2} L(w,b)+2λ∥w∥2(2)
对于 λ = 0 \lambda = 0 λ=0,我们恢复了原来的损失函数。对于 λ > 0 \lambda > 0 λ>0,我们限制 ∥ w ∥ \| \mathbf{w} \| ∥w∥的大小。这里我们仍然除以 2 2 2:当我们取一个二次函数的导数时, 2 2 2和 1 / 2 1/2 1/2会抵消,以确保更新表达式看起来既漂亮又简单。为什么在这里我们使用平方范数而不是标准范数(即欧几里得距离)?我们这样做是为了便于计算。通过平方 L 2 L_2 L2范数,我们去掉平方根,留下权重向量每个分量的平方和。这使得惩罚的导数很容易计算:导数的和等于和的导数。
此外,为什么我们首先使用 L 2 L_2 L2范数,而不是 L 1 L_1 L1范数。事实上,这个选择在整个统计领域中都是有效的和受欢迎的。 L 2 L_2 L2正则化线性模型构成经典的岭回归(ridge regression)算法, L 1 L_1 L1正则化线性回归是统计学中类似的基本模型,通常被称为套索回归(lasso regression)。使用 L 2 L_2 L2范数的一个原因是它对权重向量的大分量施加了巨大的惩罚。这使得我们的学习算法偏向于在大量特征上均匀分布权重的模型。在实践中,这可能使它们对单个变量中的观测误差更为稳定。相比之下, L 1 L_1 L1惩罚会导致模型将权重集中在一小部分特征上,而将其他权重清除为零。这称为特征选择(feature selection),这可能是其他场景下需要的。
使用与随机梯度下降中的相同符号, L 2 L_2 L2正则化回归的小批量随机梯度下降更新如下式:
w ← ( 1 − η λ ) w − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w ⊤ x ( i ) + b − y ( i ) ) (3) \begin{aligned} \mathbf{w} & \leftarrow \left(1- \eta\lambda \right) \mathbf{w} - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \mathbf{x}^{(i)} \left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right) \tag{3} \end{aligned} w←(1−ηλ)w−∣B∣ηi∈B∑x(i)(w⊤x(i)+b−y(i))(3)
根据之前章节所讲的,我们根据估计值与观测值之间的差异来更新 w \mathbf{w} w。然而,我们同时也在试图将 w \mathbf{w} w的大小缩小到零。这就是为什么这种方法有时被称为权重衰减。我们仅考虑惩罚项,优化算法在训练的每一步衰减权重。与特征选择相比,权重衰减为我们提供了一种连续的机制来调整函数的复杂度。较小的 λ \lambda λ值对应较少约束的 w \mathbf{w} w,而较大的 λ \lambda λ值对 w \mathbf{w} w的约束更大。
是否对相应的偏置 b 2 b^2 b2进行惩罚在不同的实践中会有所不同,在神经网络的不同层中也会有所不同。通常,网络输出层的偏置项不会被正则化。
二、高维线性回归
我们通过一个简单的例子来演示权重衰减。
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
首先,我们像以前一样生成一些数据,生成公式如下:
y = 0.05 + ∑ i = 1 d 0.01 x i + ϵ , 其中 ϵ ∼ N ( 0 , 0.0 1 2 ) (4) y = 0.05 + \sum_{i = 1}^d 0.01 x_i + \epsilon, \quad \text{其中} \epsilon \sim \mathcal{N}(0, 0.01^2) \tag{4} y=0.05+i=1∑d0.01xi+ϵ,其中ϵ∼N(0,0.012)(4)
我们选择标签是关于输入的线性函数。标签同时被均值为0,标准差为0.01高斯噪声破坏。为了使过拟合的效果更加明显,我们可以将问题的维数增加到 d = 200 d = 200 d=200,并使用一个只包含20个样本的小训练集。
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
三、权重衰减的从零开始实现
下面我们将从头开始实现权重衰减,只需将 L 2 L_2 L2的平方惩罚添加到原始目标函数中。
(一)初始化模型参数
首先,我们将定义一个函数来随机初始化模型参数。
def init_params():w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)b = torch.zeros(1, requires_grad=True)return [w, b]
(二)定义 L 2 L_2 L2范数惩罚
实现这一惩罚最方便的方法是对所有项求平方后并将它们求和。
def l2_penalty(w):return torch.sum(w.pow(2)) / 2
(三)定义训练代码实现
下面的代码将模型拟合训练数据集,并在测试数据集上进行评估。从线性神经网络以来,线性网络和平方损失没有变化,所以我们通过d2l.linreg和d2l.squared_loss导入它们。唯一的变化是损失现在包括了惩罚项。
def train(lambd):w, b = init_params()net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_lossnum_epochs, lr = 100, 0.003animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test'])for epoch in range(num_epochs):for X, y in train_iter:# 增加了L2范数惩罚项,# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量l = loss(net(X), y) + lambd * l2_penalty(w)l.sum().backward()d2l.sgd([w, b], lr, batch_size)if (epoch + 1) % 5 == 0:animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)))print('w的L2范数是:', torch.norm(w).item())
(四)忽略正则化直接训练
我们现在用lambd = 0禁用权重衰减后运行这个代码。注意,这里训练误差有了减少,但测试误差没有减少,这意味着出现了严重的过拟合。
train(lambd=0)


(五)使用权重衰减
下面,我们使用权重衰减来运行代码。注意,在这里训练误差增大,但测试误差减小。这正是我们期望从正则化中得到的效果。
train(lambd=3)


四、权重衰减的简洁实现
由于权重衰减在神经网络优化中很常用,深度学习框架为了便于我们使用权重衰减,将权重衰减集成到优化算法中,以便与任何损失函数结合使用。此外,这种集成还有计算上的好处,允许在不增加任何额外的计算开销的情况下向算法中添加权重衰减。由于更新的权重衰减部分仅依赖于每个参数的当前值,因此优化器必须至少接触每个参数一次。
在下面的代码中,我们在实例化优化器时直接通过weight_decay指定weight decay超参数。默认情况下,PyTorch同时衰减权重和偏移。这里我们只为权重设置了weight_decay,所以偏置参数 b b b不会衰减。
def train_concise(wd):net = nn.Sequential(nn.Linear(num_inputs, 1))for param in net.parameters():param.data.normal_()loss = nn.MSELoss(reduction='none')num_epochs, lr = 100, 0.003# 偏置参数没有衰减trainer = torch.optim.SGD([{"params":net[0].weight,'weight_decay': wd}, {"params":net[0].bias}], lr=lr)animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test'])for epoch in range(num_epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)l.mean().backward()trainer.step()if (epoch + 1) % 5 == 0:animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)))print('w的L2范数:', net[0].weight.norm().item())
这些图看起来和我们从零开始实现权重衰减时的图相同。然而,它们运行得更快,更容易实现。对于更复杂的问题,这一好处将变得更加明显。
train_concise(0)


train_concise(3)


到目前为止,我们只接触到一个简单线性函数的概念。此外,由什么构成一个简单的非线性函数可能是一个更复杂的问题。例如,再生核希尔伯特空间(RKHS)允许在非线性环境中应用为线性函数引入的工具。不幸的是,基于RKHS的算法往往难以应用到大型、高维的数据。在本专栏中,我们将默认使用简单的启发式方法,即在深层网络的所有层上应用权重衰减。
小结
- 正则化是处理过拟合的常用方法:在训练集的损失函数中加入惩罚项,以降低学习到的模型的复杂度。
- 保持模型简单的一个特别的选择是使用 L 2 L_2 L2惩罚的权重衰减。这会导致学习算法更新步骤中的权重衰减。
- 权重衰减功能在深度学习框架的优化器中提供。
- 在同一训练代码实现中,不同的参数集可以有不同的更新行为。
相关文章:
【深度学习基础】多层感知机 | 权重衰减
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

修改word的作者 最后一次保存者 总编辑时间 创建时间 最后一次保存的日期
作者: 1.打开word文件 2.点击左上角的文件 3.选项 4.用户信息 5.将用户信息中的 姓名改为你需要的名字 最后一次保存者 1.word重命名为.zip文件 2.docProps中有个core.xml 3.用记事本打开有个lastModifiedBy标签,将里面内容改为你需要的名字 总编辑时…...

青少年编程与数学 02-007 PostgreSQL数据库应用 15课题、备份与还原
青少年编程与数学 02-007 PostgreSQL数据库应用 15课题、备份与还原 一、数据库备份与还原二、PostgreSQL中操作数据库的备份与还原1. 使用pg_dump进行逻辑备份2. 使用pg_restore进行逻辑还原3. 使用pg_basebackup进行物理备份4. 还原物理备份注意事项 三、自动备份1. 使用pg_d…...

Flutter:自定义Tab切换,订单列表页tab,tab吸顶
1、自定义tab切换 view <Widget>[// 好评<Widget>[TDImage(assetUrl: assets/img/order4.png,width: 36.w,height: 36.w,),SizedBox(width: 10.w,),TextWidget.body(好评,size: 24.sp,color: controller.tabIndex 0 ? AppTheme.colorfff : AppTheme.color999,),]…...

SAS-proc sgplot绘图
1、绘图-直条图示例: 1.1 数据集 1.2 代码 proc sgplot data sashelp.cars;vbar origin / response msrp /* response:响应变量,Y轴 */stat mean /* stat:统计量,结果用均值呈现 */group type /* group&#…...

怎么使用python 调用高德地图api查询位置和导航?
环境: python 3.10 问题描述: 怎么使用python 调用高德地图api查询位置和导航? 解决方案: 要使用Python调用高德地图API查询位置和导航,需要先注册高德开发者账号并获取API Key。以下是基本步骤: 1. 注册高德开…...

pikachu靶场-敏感信息泄露概述
敏感信息泄露概述 由于后台人员的疏忽或者不当的设计,导致不应该被前端用户看到的数据被轻易的访问到。 比如: ---通过访问url下的目录,可以直接列出目录下的文件列表; ---输入错误的url参数后报错信息里面包含操作系统、中间件、开发语言的版…...

使用ssh推送项目到github
文章目录 1. 确保已生成 SSH 密钥2. 在 GitHub 上创建远程仓库3. 初始化本地项目4. 将本地项目与远程仓库关联5. 添加文件并提交补充:拉取远程修改(可选)6. 推送到 GitHub7. 完成总结 出现的问题解决方法:方法 1:允许合…...
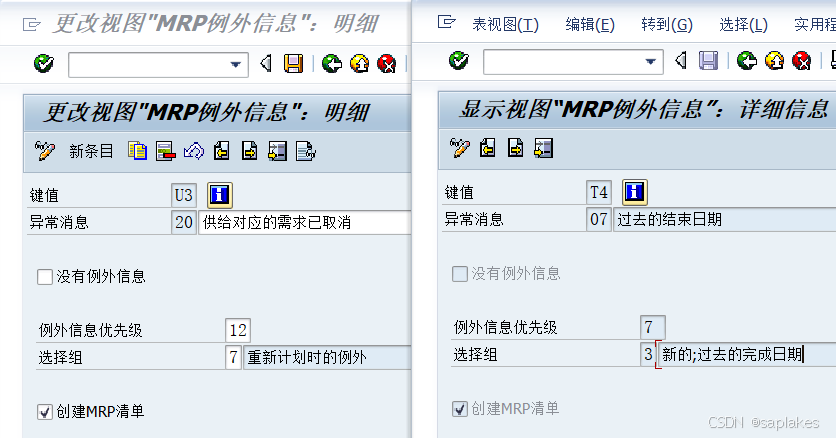
SAP MRP运行出现例外消息怎么处理?例外消息的优先级、案例分享
【SAP系统PP模块研究】 #SAP #PP #MRP #例外消息 #MRP评估 一、MRP评估中的例外消息 例外消息,是SAP系统在MRP运行过程中自动产生的消息。对例外消息检查其产生的原因,及时与销售、生产、采购等相关部门进行沟通,并进行相应调整&#x…...

002-SpringBoot整合AI(Alibaba)
SpringBoot整合AI 一、引入依赖二、配置application.yml三、获取 api-key四、编写 controller五、起服务调用 一、引入依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><vers…...

Java中如何安全地停止线程?
大家好,我是锋哥。今天分享关于【Java中如何安全地停止线程?】面试题。希望对大家有帮助; Java中如何安全地停止线程? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在Java中,安全地停止线程是一项重要的任务,尤其…...

Apache Tomcat文件包含漏洞复现(详细教程)
1.漏洞原理 Tomcat 服务器是一个免费的开放源代码的Web 应用服务器,其安装后会默认开启ajp连接器,方便与其他web服务器通过ajp协议进行交互。属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发…...

个人学习 - 什么是Vim?
观我往旧,同我仰春 - 2025.1.10 声明 仅作为个人学习使用,仅供参考 本文所有解释参考笔者个人理解,最终目的是服务于自我学习, 如果你需要了解官方更规范的解释,请自行查阅 Vim 是什么 Vim 是一个强大的 文本编辑器…...

Flink Gauss CDC:深度剖析存量与增量同步的创新设计
目录 设计思路 1.为什么不直接用FlinkCDC要重写Flink Gauss CDC 2.存量同步的逻辑是什么 2.1、单主键的切片策略是什么 2.2、复合主键作切片,怎么保证扫描到所有的数据 3、增量同步的逻辑是什么 4、存量同步结束之后如何无缝衔接增量同步 5、下游数据如何落…...

docker 部署.netcore应用优势在什么地方?
目录 1. 环境一致性 2. 简化依赖管理 3. 快速部署与扩展 4. 资源利用率高 5. 版本控制与回滚 6. 安全性 7. 生态系统支持 8. 微服务架构支持 9. 降低成本 10. 开发体验提升 总结 使用 Docker 部署 .NET Core 应用有许多优势,特别是在开发、测试和生产环境…...

AIP-126 枚举
编号126原文链接AIP-126: Enumerations状态批准创建日期2019-07-24更新日期2019-07-24 一个域的值集合是一组数量有限的具体值,这是很常见的。此时使用枚举(缩写为“enums”)可有助于明确表达值集合的范围。 指南 API 可以 为不经常更改的…...

P3707 [SDOI2017] 相关分析 Solution
Description 给定序列 x ( x 1 , x 2 , ⋯ , x n ) , y ( y 1 , y 2 , ⋯ , y n ) x(x_1,x_2,\cdots,x_n),y(y_1,y_2,\cdots,y_n) x(x1,x2,⋯,xn),y(y1,y2,⋯,yn),有 m m m 个操作,分三种: query ( l , r ) \operatornam…...

Android AutoMotive --CarService
1、AAOS概述 Android AutoMotive OS是谷歌针对车机使用场景打造的操作系统,它是基于现有Android系统的基础上增加了新特性,最主要的就是增加了CarService(汽车服务)模块。我们很容易把Android AutoMotive和Android Auto搞混&…...

K8S中Service详解(三)
HeadLiness类型的Service 在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLiness Service,这类Service不会分配Cluster IP,…...

C++----STL(vector)
vector的介绍 vector的文档介绍:cplusplus.com/reference/vector/vector/ 1.基本概念 简单来说,vector是表示可以改变大小的数组的顺序容器。使用连续的存储位置来存储元素,因此可以通过常规指针的偏移量来高效访问。 2.内部机制 vector…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

使用libusb-win32驱动复活老旧USB硬件:以Elektor Magic Eye为例
1. 项目概述:让老硬件在新时代焕发新生手头有一台十多年前的《Elektor》杂志上刊登的“Magic Eye EM84”复古VFD显示屏项目,想把它接到Windows 10电脑上当个酷炫的CPU占用率显示器,却发现官方提供的“AVR309”USB驱动在新系统上彻底罢工了。这…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...