理解深度学习pytorch框架中的线性层
文章目录
在神经网络或机器学习的线性层(Linear Layer / Fully Connected Layer)中,经常会见到两种形式的公式:
- 数学文献或传统线性代数写法: y = W x + b \displaystyle y = W\,x + b y=Wx+b
- 一些深度学习代码中写法: y = x W T + b \displaystyle y = x\,W^T + b y=xWT+b
初次接触时,很多人会觉得两者“方向”不太一样,不知该如何对照理解;再加上矩阵维度 ( in_features , out_features ) (\text{in\_features},\, \text{out\_features}) (in_features,out_features) 和 ( out_features , in_features ) (\text{out\_features},\, \text{in\_features}) (out_features,in_features) 的各种写法常常让人疑惑不已。本文将从数学角度和编程实现角度剖析它们的关系,并结合实际示例指出一些常见的坑与需要特别留意的下标对应问题。
1. 数学角度: y = W x + b \displaystyle y = W\,x + b y=Wx+b
在线性代数中,如果我们假设输入 x x x 是一个列向量,通常会写作 x ∈ R ( in_features ) \displaystyle x\in\mathbb{R}^{(\text{in\_features})} x∈R(in_features)(或者在更严格的矩阵形状记法下写作 ( in_features , 1 ) (\text{in\_features},\,1) (in_features,1))。那么一个最常见的全连接层可以表示为:
y = W x + b , y = W\,x + b, y=Wx+b,
其中:
- W W W 是一个大小为 ( out_features , in_features ) \bigl(\text{out\_features},\,\text{in\_features}\bigr) (out_features,in_features) 的矩阵;
- b b b 是一个 out_features \text{out\_features} out_features-维的偏置向量(形状 ( out_features , 1 ) (\text{out\_features},\,1) (out_features,1));
- y y y 则是输出向量,大小为 out_features \text{out\_features} out_features。
示例
假设 in_features = 3 \text{in\_features}=3 in_features=3, out_features = 2 \text{out\_features}=2 out_features=2。那么:
W ∈ R 2 × 3 , x ∈ R 3 × 1 , b ∈ R 2 × 1 . W \in \mathbb{R}^{2\times 3},\quad x \in \mathbb{R}^{3\times 1},\quad b \in \mathbb{R}^{2\times 1}. W∈R2×3,x∈R3×1,b∈R2×1.
矩阵写开来就是:
W = [ w 11 w 12 w 13 w 21 w 22 w 23 ] , x = [ x 1 x 2 x 3 ] , b = [ b 1 b 2 ] . W = \begin{bmatrix} w_{11} & w_{12} & w_{13} \\[5pt] w_{21} & w_{22} & w_{23} \end{bmatrix},\quad x = \begin{bmatrix} x_{1}\\ x_{2}\\ x_{3} \end{bmatrix},\quad b = \begin{bmatrix} b_{1}\\ b_{2} \end{bmatrix}. W=[w11w21w12w22w13w23],x= x1x2x3 ,b=[b1b2].
那么线性变换结果 W x + b Wx + b Wx+b 可以展开为:
W x + b = [ w 11 x 1 + w 12 x 2 + w 13 x 3 w 21 x 1 + w 22 x 2 + w 23 x 3 ] + [ b 1 b 2 ] = [ w 11 x 1 + w 12 x 2 + w 13 x 3 + b 1 w 21 x 1 + w 22 x 2 + w 23 x 3 + b 2 ] . \begin{aligned} Wx + b &= \begin{bmatrix} w_{11}x_1 + w_{12}x_2 + w_{13}x_3 \\ w_{21}x_1 + w_{22}x_2 + w_{23}x_3 \end{bmatrix} + \begin{bmatrix} b_1 \\ b_2 \end{bmatrix} \\ &= \begin{bmatrix} w_{11}x_1 + w_{12}x_2 + w_{13}x_3 + b_1 \\ w_{21}x_1 + w_{22}x_2 + w_{23}x_3 + b_2 \end{bmatrix}. \end{aligned} Wx+b=[w11x1+w12x2+w13x3w21x1+w22x2+w23x3]+[b1b2]=[w11x1+w12x2+w13x3+b1w21x1+w22x2+w23x3+b2].
这就是最传统、在数学文献或线性代数课程中最常见的表示方法。
2. 编程实现角度: y = x W T + b \displaystyle y = x\,W^T + b y=xWT+b
在实际的深度学习代码(例如 PyTorch、TensorFlow)中,经常看到的却是下面这种写法:
y = x @ W.T + b
注意这里 W.shape 通常被定义为 ( out_features , in_features ) (\text{out\_features},\, \text{in\_features}) (out_features,in_features),而 x.shape 在批量处理时则是 ( batch_size , in_features ) (\text{batch\_size},\, \text{in\_features}) (batch_size,in_features)。于是 (x @ W.T) 的结果是 ( batch_size , out_features ) (\text{batch\_size},\, \text{out\_features}) (batch_size,out_features)。
为什么会出现转置?
因为在数学里我们通常把 x x x 当作“列向量”放在右边,于是公式变成 y = W x + b y = Wx + b y=Wx+b。
但在编程里,尤其是处理批量输入时,x 常写成“行向量”的形式 ( batch_size , in_features ) (\text{batch\_size},\, \text{in\_features}) (batch_size,in_features),这就造成了在进行矩阵乘法时,需要将 W(大小 ( out_features , in_features ) (\text{out\_features},\, \text{in\_features}) (out_features,in_features))转置成 ( in_features , out_features ) (\text{in\_features},\, \text{out\_features}) (in_features,out_features),才能满足「行×列」的匹配关系。
从结果上来看,
( batch_size , in_features ) × ( in_features , out_features ) = ( batch_size , out_features ) . (\text{batch\_size}, \text{in\_features}) \times (\text{in\_features}, \text{out\_features}) = (\text{batch\_size}, \text{out\_features}). (batch_size,in_features)×(in_features,out_features)=(batch_size,out_features).
所以,在代码里就写成 x @ W.T,再加上偏置 b(通常会广播到 batch_size \text{batch\_size} batch_size 那个维度)。
本质上这和数学公式里 y = W x + b y = W\,x + b y=Wx+b 并无冲突,只是一个“列向量”和“行向量”的转置关系。只要搞清楚最终你想让输出 y y y 的 shape 是多少,就能明白在代码里为什么要写 .T。
3. 常见错误与易混点解析
有些教程或文档,会不小心写成:“如果我们有一个形状为 ( in_features , out_features ) (\text{in\_features},\text{out\_features}) (in_features,out_features) 的权重矩阵 W W W……”——然后又要做 W x Wx Wx,想得到一个 out_features \text{out\_features} out_features-维的结果。但按照线性代数的常规写法,行数必须和输出维度匹配、列数必须和输入维度匹配。所以 正确 的说法应该是
W ∈ R ( out_features ) × ( in_features ) . W\in\mathbb{R}^{(\text{out\_features}) \times (\text{in\_features})}. W∈R(out_features)×(in_features).
否则从矩阵乘法次序来看就对不上。
但这又可能让人迷惑:为什么深度学习框架 torch.nn.Linear(in_features, out_features) 却给出 weight.shape == (out_features, in_features)? 其实正是同一个道理,它和上面“数学文献里”用到的 W W W 形状完全一致。
4. 小结
-
从数学角度:
最传统的记号是
y = W x + b , W ∈ R ( out_features ) × ( in_features ) , x ∈ R ( in_features ) , y ∈ R ( out_features ) . y = W\,x + b, \quad W \in \mathbb{R}^{(\text{out\_features})\times(\text{in\_features})},\, x \in \mathbb{R}^{(\text{in\_features})},\, y \in \mathbb{R}^{(\text{out\_features})}. y=Wx+b,W∈R(out_features)×(in_features),x∈R(in_features),y∈R(out_features). -
从深度学习代码角度:
- 由于批量数据常被视为行向量,每一行代表一个样本特征,因此形状通常是 ( batch_size , in_features ) (\text{batch\_size},\, \text{in\_features}) (batch_size,in_features)。
- 对应的权重
W定义为 ( out_features , in_features ) (\text{out\_features},\, \text{in\_features}) (out_features,in_features)。为了完成行乘以列的矩阵运算,需要对W做转置:y = x @ W.T + b - 得到的
y.shape即 ( batch_size , out_features ) (\text{batch\_size},\, \text{out\_features}) (batch_size,out_features)。
-
避免踩坑:
- 写公式时,仔细确认 in_features \text{in\_features} in_features、 out_features \text{out\_features} out_features 的位置以及矩阵行列顺序。
- 编程实践中理解“为什么要
.T”非常重要:那只是为了匹配「行×列」的矩阵乘法规则,本质上还是和 y = W x + b y = Wx + b y=Wx+b 相同。
通过理解并区分“列向量”与“行向量”的不同惯例,避免因为矩阵维度或转置不当而导致莫名其妙的错误或 bug。
参考链接
- PyTorch 文档:
torch.nn.Linear - 深度学习中的矩阵运算初步 —— batch_size 与矩阵乘法
- 常见线性代数符号:行向量与列向量
相关文章:

理解深度学习pytorch框架中的线性层
文章目录 1. 数学角度: y W x b \displaystyle y W\,x b yWxb示例 2. 编程实现角度: y x W T b \displaystyle y x\,W^T b yxWTb3. 常见错误与易混点解析4. 小结参考链接 在神经网络或机器学习的线性层(Linear Layer / Fully Connect…...

电路研究9.2——合宙Air780EP使用AT指令
这里正式研究AT指令的学习了,之前只是接触的AT指令,这里则是深入分析AT指令了。 软件的开发方式: AT:MCU 做主控,MCU 发 AT 命令给模组的开发方式,模组仅提供标准的 AT 固件, 所有的业务控制逻辑…...

Qt数据库相关操作
目录 一、前言 二、类与接口介绍 1.连接管理类 2.数据操作类 3.数据模型类 4.其它类 三、主要操作流程 1.示例 2.绑定参数 3.事务操作 一、前言 要在Qt中操作数据库,首先要安装对应的数据库,还要确保安装了Qt SQL模块。使用MySQL时࿰…...

2025-01-22 Unity Editor 1 —— MenuItem 入门
文章目录 1 Editor 文件夹2 MenuItem3 使用示例3.1 打开网址3.2 打开文件夹3.3 Menu Toggle3.4 Menu 代码复用3.5 MenuItem 激活与失活4 代码示例 1 Editor 文件夹 Editor 文件夹是 Unity 中的特殊文件夹,Unity 中所有编辑器相关的脚本都需要放置在其中…...

解锁C#编程新姿势:Z.ExtensionMethods入门秘籍
一、引言 在 C# 的开发旅程中,我们常常会遇到各种重复性高、复杂度低的任务,这些任务虽然基础,但却占据了我们大量的开发时间。比如处理字符串时,经常需要进行非空判断、格式转换;操作日期时间时,计算某个…...

不使用 JS 纯 CSS 获取屏幕宽高
前言 在现代前端开发中,获取屏幕的宽度和高度通常依赖于 JavaScript。然而现代 CSS 也可以获取到屏幕的宽高,通过自定义属性(CSS Variables)和一些数学函数来实现这一目标。本文将详细解析如何使用 CSS 的 property 规则和一些数…...

Node.js NativeAddon 构建工具:node-gyp 安装与配置完全指南
Node.js NativeAddon 构建工具:node-gyp 安装与配置完全指南 node-gyp Node.js native addon build tool [这里是图片001] 项目地址: https://gitcode.com/gh_mirrors/no/node-gyp 项目基础介绍及主要编程语言 Node.js NativeAddon 构建工具(node-gyp…...

【ARTS】【LeetCode-704】二分查找算法
目录 前言 什么是ARTS? 算法 力扣704题 二分查找 基本思想: 二分查找算法(递归的方式): 经典写法(找单值): 代码分析: 经典写法(找数组即多个返回值) 代码分析 经典题目 题目描述: 官方题解 深入思考 模版一 (相错终止/左闭右闭) 相等返回情形…...

Vue.js 配置路由:基本的路由匹配
Vue.js 配置路由:基本的路由匹配 在 Vue.js 应用中,Vue Router 是官方提供的路由管理器,用于在单页应用(SPA)中管理不同的视图。通过配置路由,应用可以根据 URL 的变化展示相应的组件。 基本的路由匹配是…...

鸿蒙(HarmonyOS)Json格式转实体对象(2)
下面是一个复杂的json体。 怎么把json转实体类,首先要定义类 import List from ohos.util.List export class InfoModel{msg: stringcars: List<Cars>code: numberpermissions: List<string>roles: List<string>user: User}class Cars{createBy:…...

代码随想录 栈与队列 test 6
239. 滑动窗口最大值 - 力扣(LeetCode) 每次只取窗口中最大值,这个最大值可能在后面的滑动中保持不变,而比最大值小的值且在最大值之前出现的值没必要保留,因此可以通过单调队列利用这个特性。 这个单调队列具有如下…...

动手学深度学习2025.1.23
一、预备知识 1.数据操作 (1)数据访问: 一个元素:[1,2] //行下标为1,列下标为2的元素 一行元素:[1,:] //行下标为1的所有元素 一列元素:[:,1] //列下标为1的所有元素 子区域:[…...
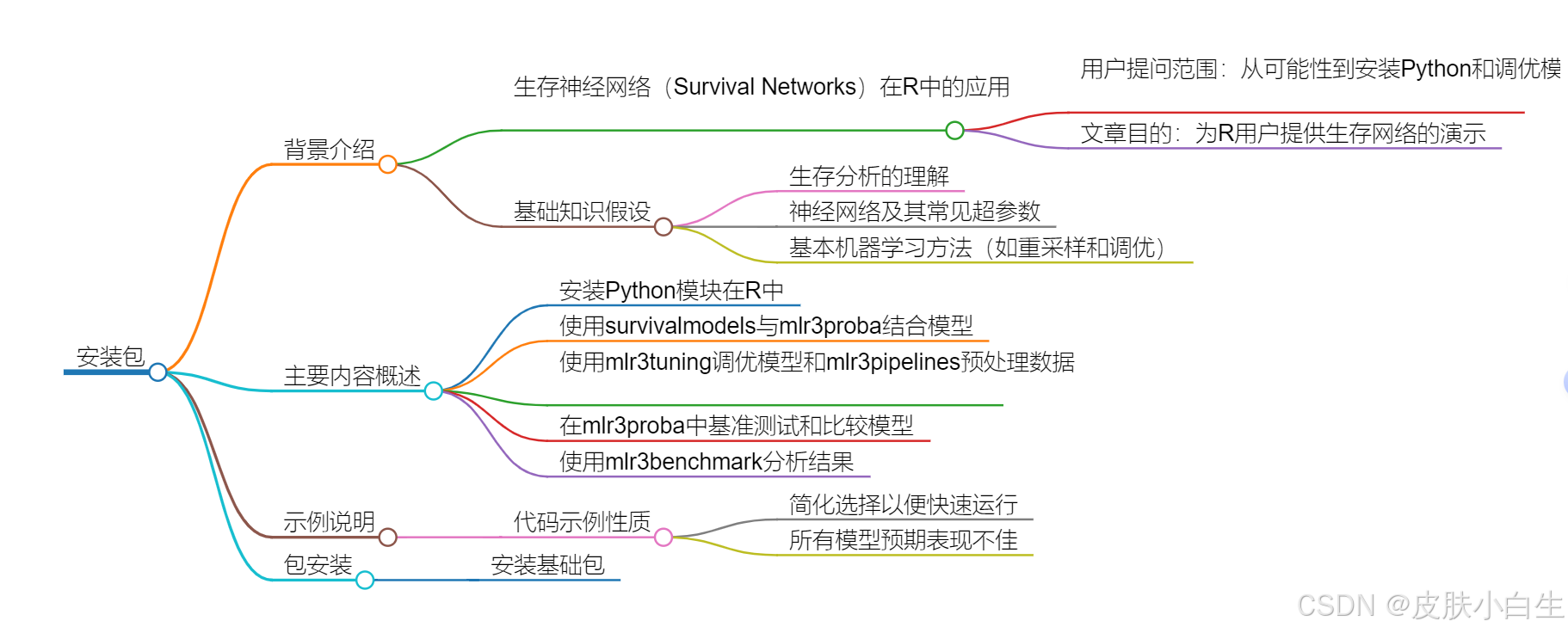
生存网络与mlr3proba
在R语言中,mlr3包是一个用于机器学习的强大工具包。它提供了一种简单且灵活的方式来执行超参数调整。 生存网络是一种用于生存分析的模型,常用在医学和生物学领域。生存分析是一种统计方法,用于研究事件发生的时间和相关因素对事件发生的影响。生存网络可以用来预测个体在给…...

C#与AI的共同发展
C#与人工智能(AI)的共同发展反映了编程语言随着技术进步而演变,以适应新的挑战和需要。自2000年微软推出C#以来,这门语言经历了多次迭代,不仅成为了.NET平台的主要编程语言之一,还逐渐成为构建各种类型应用程序的强大工具。随着时…...

2000-2020年各省第二产业增加值数据
2000-2020年各省第二产业增加值数据 1、时间:2000-2020年 2、来源:国家统计局、统计年鉴、各省年鉴 3、指标:行政区划代码、地区、年份、第二产业增加值 4、范围:31省 5、指标解释:第二产业增加值是指在一个国家或…...

【MySQL】 库的操作
欢迎拜访:雾里看山-CSDN博客 本篇主题:【MySQL】 库的操作 发布时间:2025.1.23 隶属专栏:MySQL 目录 库的创建语法使用 编码规则认识编码集查看数据库默认的编码集和校验集查看数据库支持的编码集和校验集指定编码创建数据库验证不…...

docker 启动镜像命令集合
安装rabbitmq 参考地址: https://blog.csdn.net/xxpxxpoo8/article/details/122935994 docker run -it -d --namerabbit-3.8 -v /d/docker/rabbitmq-stomp/conf:/etc/rabbitmq -p 5617:5617 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 -p 25672:2…...

微信小程序获取位置服务
wx.getLocation({type: gcj02,success(res) {wx.log(定位成功);},fail(err) {wx.log(定位失败, err);wx.showModal({content: 请打开手机和小程序中的定位服务,success: (modRes) > {if (modRes.confirm) {wx.openSetting({success(setRes) {if (setRes.authSetting[scope.u…...

Docker Load后存储的镜像及更改镜像存储目录的方法
Docker Load后存储的镜像及更改镜像存储目录的方法 Docker Load后存储的镜像更改镜像存储目录的方法脚本说明注意事项Docker作为一种开源的应用容器引擎,已经广泛应用于软件开发、测试和生产环境中。通过Docker,开发者可以将应用打包成镜像,轻松地进行分发和运行。而在某些场…...

Langchain本地知识库部署
本地部署(Docker + LangChain + FAISS) 1. 概述 本地部署 LangChain-Chatchat 可以为企业提供高效、安全、可控的 AI 知识库方案。本方案基于 Docker、LangChain 和 FAISS 进行本地化部署,适用于企业内部知识库问答、私有化 AI 应用等场景。 2. 技术选型 2.1 LangChain …...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...