动手学深度学习2025.1.23
一、预备知识
1.数据操作
(1)数据访问:
一个元素:[1,2] //行下标为1,列下标为2的元素
一行元素:[1,:] //行下标为1的所有元素
一列元素:[:,1] //列下标为1的所有元素
子区域:[1:3,1:] //行下标为[1,3),列下标为[1,+无穷)的所有元素
子区域:[::3,::2] //行下标跨度为3,列下标跨度为2的元素
(2)张量(tensor):
理解Tensorflow中的张量:从零维到四维-CSDN博客
一种多维数组,可以用来表示各种物理量和几何量。
张量连结:是一种将多个张量沿着某一维度合并的操作。
torch.cat()
torch.cat() 是 PyTorch 中用于张量拼接的主要函数,其语法如下:
torch.cat(tensors, dim=0)
-
tensors:一个包含多个张量的序列,这些张量需要在指定维度上具有相同的形状。
-
dim:指定拼接的维度。
-
一维张量拼接
tensor_a = torch.tensor([1, 2, 3]) tensor_b = torch.tensor([4, 5, 6]) concatenated = torch.cat((tensor_a, tensor_b), dim=0) # 结果为 [1, 2, 3, 4, 5, 6]
输出形状为
(6,)。 -
二维张量拼接
tensor_1 = torch.tensor([[1, 2], [3, 4]]) tensor_2 = torch.tensor([[5, 6], [7, 8]]) concatenated_dim0 = torch.cat((tensor_1, tensor_2), dim=0) # 沿第0维拼接 concatenated_dim1 = torch.cat((tensor_1, tensor_2), dim=1) # 沿第1维拼接
输出形状分别为
(4, 2)和(2, 4)。 -
高维张量拼接
tensor_3d_1 = torch.randn(2, 3, 4) tensor_3d_2 = torch.randn(2, 3, 4) concatenated_dim2 = torch.cat((tensor_3d_1, tensor_3d_2), dim=2) # 沿第2维拼接
输出形状为
(2, 3, 8)。=>张量的初始形状和内容
tensor_5 = torch.tensor([[[2, 3, 5]], [[9, 0, 2]]]) tensor_6 = torch.tensor([[[4, 5, 9]], [[3, 6, 4]]])
-
形状:
tensor_5和tensor_6的形状都是(2, 1, 3)。 -
内容:
-
tensor_5包含两个矩阵:[[[2, 3, 5]],[[9, 0, 2]]]
-
tensor_6包含两个矩阵:[[[4, 5, 9]],[[3, 6, 4]]]
-
=>在不同维度上拼接的结果
-
沿
dim=2拼接
dim2 = torch.cat((tensor_5, tensor_6), dim=2)
-
拼接维度:
dim=2是每个矩阵的列方向(最内层的维度)。 -
拼接过程:
-
第一个矩阵的第0行:
-
tensor_5的[2, 3, 5]和tensor_6的[4, 5, 9]拼接为[2, 3, 5, 4, 5, 9]。
-
-
第二个矩阵的第0行:
-
tensor_5的[9, 0, 2]和tensor_6的[3, 6, 4]拼接为[9, 0, 2, 3, 6, 4]。
-
-
-
结果:
tensor([[[2, 3, 5, 4, 5, 9]], [[9, 0, 2, 3, 6, 4]]])
-
形状:
(2, 1, 6)。-
第0维(矩阵数量):2。
-
第1维(行数):1。
-
第2维(列数):6(拼接后的列数)。
-
-
沿
dim=0拼接
dim0 = torch.cat((tensor_5, tensor_6), dim=0)
-
拼接维度:
dim=0是最外层的维度,表示矩阵的数量。 -
拼接过程:
-
将
tensor_5的两个矩阵和tensor_6的两个矩阵依次排列。
-
-
结果:
tensor([[[2, 3, 5]], [[9, 0, 2]], [[4, 5, 9]], [[3, 6, 4]]])
-
形状:
(4, 1, 3)。-
第0维(矩阵数量):4(拼接后的矩阵数量)。
-
第1维(行数):1。
-
第2维(列数):3。
-
-
沿
dim=1拼接
dim1 = torch.cat((tensor_5, tensor_6), dim=1)
-
拼接维度:
dim=1是每个矩阵的行方向。 -
拼接过程:
-
第一个矩阵:
-
tensor_5的第0行[2, 3, 5]和tensor_6的第0行[4, 5, 9]拼接为:[[2, 3, 5],[4, 5, 9]]
-
-
第二个矩阵:
-
tensor_5的第0行[9, 0, 2]和tensor_6的第0行[3, 6, 4]拼接为:[[9, 0, 2],[3, 6, 4]]
-
-
-
结果:
tensor([[[2, 3, 5],[4, 5, 9]], [[9, 0, 2],[3, 6, 4]]])
-
形状:
(2, 2, 3)。-
第0维(矩阵数量):2。
-
第1维(行数):2(拼接后的行数)。
-
第2维(列数):3。
-
=>多维拼接总结
-
拼接维度:
dim参数决定了拼接的方向。 -
张量的形状:拼接时,除了拼接维度外,其他维度的大小必须一致。
-
dim=0:沿着最外层维度拼接,增加矩阵的数量。
-
dim=1:沿着行方向拼接,增加行数。
-
dim=2:沿着列方向拼接,增加列数。
(3)节省内存
尽量进行原地操作,节省内存开销
before = id(X) X += Y id(X) == before
1.
id(X)的含义id(X)返回变量X所指向的对象的内存地址。如果X的内容被修改,但变量X仍然指向同一个对象,那么id(X)的值不会改变。2. 原地操作(In-place Operations)
在 Python 中,某些操作会直接修改对象的内容,而不是创建一个新的对象。例如:
-
X += Y是一个原地操作,它会直接修改X的内容,而不是创建一个新的对象。
-
原地操作:
X += Y是原地操作,它直接修改了X的内容,而不是创建新的对象。 -
id() 的稳定性:由于
X的内存地址没有改变,id(X)的值在操作前后保持一致。 -
Python 的内存管理:Python 的内存管理机制允许某些操作直接修改对象的内容,而不是创建新的对象,这有助于节省内存和提高效率。
如果使用非原地操作(例如
X = X + y),结果会有所不同:Python复制
before = id(X) X = X + Y id(X) == before # 这将返回 False
在这种情况下,
X = X + Y会创建新的对象,并将X指向这个新对象。因此,id(X)的值会发生变化。(3)Numpy数组
NumPy(Numerical Python)数组是 Python 中用于高效数值计算的核心数据结构。它是 NumPy 库的基础,提供了多维数组对象(
ndarray)和一系列操作这些数组的工具。A = X.numpy() B = torch.tensor(A) type(A), type(B)
-
2.数据预处理
将工作目录改为D盘的目录
os.getcwd()
'C:\Users\aospr'
target_dir = r"D:\深度学习\数据demo"
os.chdir(target_dir)
os.getcwd()
'D:\深度学习\数据demo'
解决将NaN填充成平均值的bug:
inputs = inputs.fillna(inputs.mean(numeric_only=True)) # 计算均值,只对数值列生效
相关文章:

动手学深度学习2025.1.23
一、预备知识 1.数据操作 (1)数据访问: 一个元素:[1,2] //行下标为1,列下标为2的元素 一行元素:[1,:] //行下标为1的所有元素 一列元素:[:,1] //列下标为1的所有元素 子区域:[…...
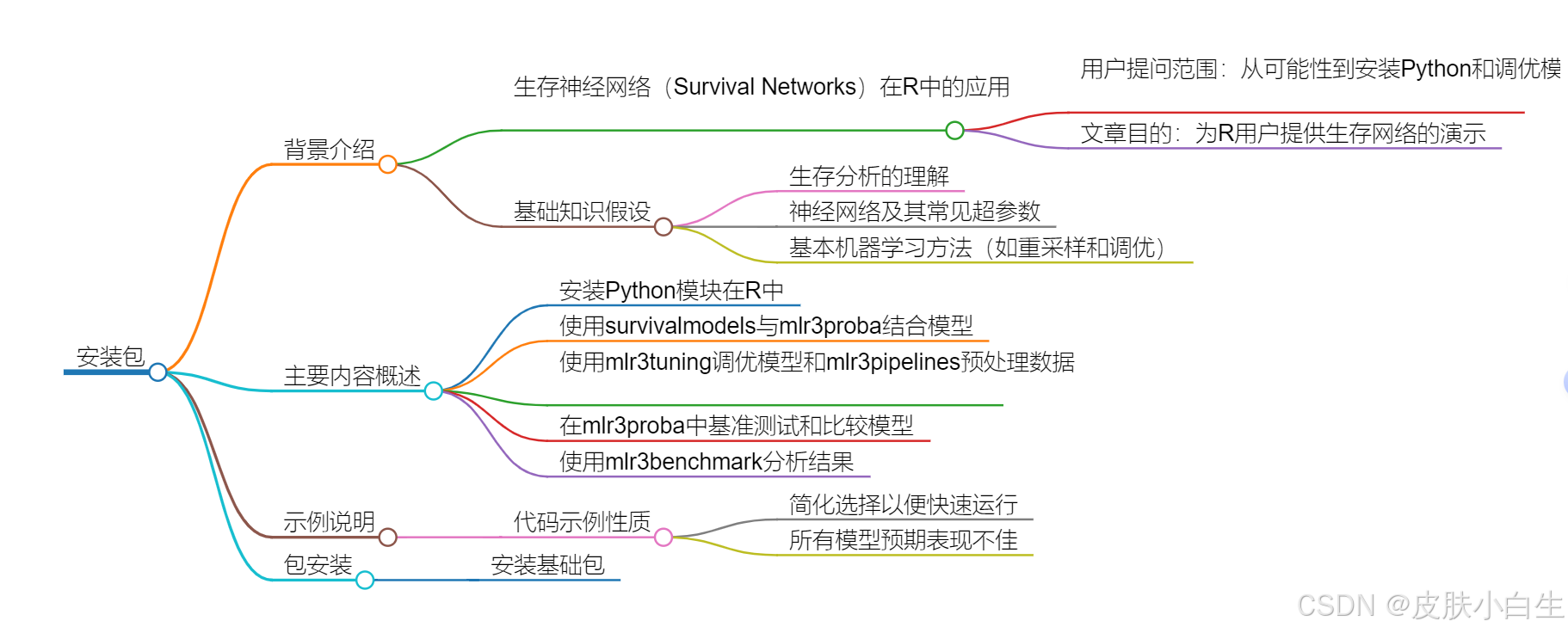
生存网络与mlr3proba
在R语言中,mlr3包是一个用于机器学习的强大工具包。它提供了一种简单且灵活的方式来执行超参数调整。 生存网络是一种用于生存分析的模型,常用在医学和生物学领域。生存分析是一种统计方法,用于研究事件发生的时间和相关因素对事件发生的影响。生存网络可以用来预测个体在给…...

C#与AI的共同发展
C#与人工智能(AI)的共同发展反映了编程语言随着技术进步而演变,以适应新的挑战和需要。自2000年微软推出C#以来,这门语言经历了多次迭代,不仅成为了.NET平台的主要编程语言之一,还逐渐成为构建各种类型应用程序的强大工具。随着时…...

2000-2020年各省第二产业增加值数据
2000-2020年各省第二产业增加值数据 1、时间:2000-2020年 2、来源:国家统计局、统计年鉴、各省年鉴 3、指标:行政区划代码、地区、年份、第二产业增加值 4、范围:31省 5、指标解释:第二产业增加值是指在一个国家或…...

【MySQL】 库的操作
欢迎拜访:雾里看山-CSDN博客 本篇主题:【MySQL】 库的操作 发布时间:2025.1.23 隶属专栏:MySQL 目录 库的创建语法使用 编码规则认识编码集查看数据库默认的编码集和校验集查看数据库支持的编码集和校验集指定编码创建数据库验证不…...

docker 启动镜像命令集合
安装rabbitmq 参考地址: https://blog.csdn.net/xxpxxpoo8/article/details/122935994 docker run -it -d --namerabbit-3.8 -v /d/docker/rabbitmq-stomp/conf:/etc/rabbitmq -p 5617:5617 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 -p 25672:2…...

微信小程序获取位置服务
wx.getLocation({type: gcj02,success(res) {wx.log(定位成功);},fail(err) {wx.log(定位失败, err);wx.showModal({content: 请打开手机和小程序中的定位服务,success: (modRes) > {if (modRes.confirm) {wx.openSetting({success(setRes) {if (setRes.authSetting[scope.u…...

Docker Load后存储的镜像及更改镜像存储目录的方法
Docker Load后存储的镜像及更改镜像存储目录的方法 Docker Load后存储的镜像更改镜像存储目录的方法脚本说明注意事项Docker作为一种开源的应用容器引擎,已经广泛应用于软件开发、测试和生产环境中。通过Docker,开发者可以将应用打包成镜像,轻松地进行分发和运行。而在某些场…...

Langchain本地知识库部署
本地部署(Docker + LangChain + FAISS) 1. 概述 本地部署 LangChain-Chatchat 可以为企业提供高效、安全、可控的 AI 知识库方案。本方案基于 Docker、LangChain 和 FAISS 进行本地化部署,适用于企业内部知识库问答、私有化 AI 应用等场景。 2. 技术选型 2.1 LangChain …...

java基础学习——jdbc基础知识详细介绍
引言 数据的存储 我们在开发 java 程序时,数据都是存储在内存中的,属于临时存储,当程序停止或重启时,内存中的数据就会丢失,我们为了解决数据的长期存储问题,有以下解决方案: 通过 IO流书记&…...

联想电脑怎么设置u盘启动_联想电脑设置u盘启动方法(支持新旧机型)
有很多网友问联想电脑怎么设置u盘启动,联想电脑设置u盘启动的方法有两种,一是通过bios进行设置。二是通过快捷方式启动进入u盘启动。但需要注意有两种引导模式是,一种是uefi引导,一种是传统的leacy引导,所以需要注意制…...

C# 解析 HTML 实战指南
在网页开发和数据处理的场景中,经常需要从 HTML 文档里提取有用的信息。C# 作为一门强大的编程语言,提供了丰富的工具和库来实现 HTML 的解析。这篇博客就带你深入了解如何使用 C# 高效地解析 HTML。 一、为什么要在 C# 中解析 HTML 在实际项目中&…...

光谱相机在智能冰箱的应用原理与优势
食品新鲜度检测 详细可点击查看汇能感知团队实验报告:高光谱成像技术检测食物新鲜度 检测原理:不同新鲜程度的食品,其化学成分和结构会有所不同,在光谱下的反射、吸收等特性也存在差异。例如新鲜肉类和蔬菜中的水分、蛋白质、叶…...

编写0号中断的处理程序
实验内容、程序清单及运行结果 编写0号中断的处理程序(课本实验12) 解: assume cs:code code segment start: mov ax,cs mov ds,ax mov si,offset do mov ax,0 mov es,ax mov di,200h mov cx,offset doend-offset do ;安装中断例…...

“““【运用 R 语言里的“predict”函数针对 Cox 模型展开新数据的预测以及推理。】“““
主题与背景 本文主要介绍了如何在R语言中使用predict函数对已拟合的Cox比例风险模型进行新数据的预测和推理。Cox模型是一种常用的生存分析方法,用于评估多个因素对事件发生时间的影响。文章通过具体的代码示例展示了如何使用predict函数的不同参数来获取生存概率和…...

群晖docker获取私有化镜像http: server gave HTTP response to HTTPS client].
群晖docker获取私有化镜像提示http: server gave HTTP response to HTTPS clien 问题描述 层级时间用户事件Information2023/07/08 12:47:45cxlogeAdd image from xx.xx.31.240:1923/go-gitea/gitea:1.19.3Error2023/07/08 12:47:48cxlogeFailed to pull image [Get "http…...

使用 C++ 在深度学习中的应用:如何通过 C++20 构建高效神经网络
深度学习已经成为现代人工智能的核心技术,在图像识别、自然语言处理、语音识别等多个领域广泛应用。尽管 Python 因其简便易用和强大的深度学习框架(如 TensorFlow 和 PyTorch)而在这一领域占据主导地位,但 C 作为一门高性能语言&…...

当 Facebook 窥探隐私:用户的数字权利如何捍卫?
随着社交平台的普及,Facebook 已经成为全球用户日常生活的一部分。然而,伴随而来的隐私问题也愈发严峻。近年来,Facebook 频频被曝出泄露用户数据、滥用个人信息等事件,令公众对其隐私保护措施产生质疑。在这个信息化时代…...

Spring MVC中HandlerInterceptor和Filter的区别
目录 一、处理阶段 二、功能范围 三、参数访问 四、配置方式 五、使用场景说明 在Spring MVC中,HandlerInterceptor和Filter都是用于拦截请求的重要组件,但它们在多个方面存在显著的差异。本文将详细解析这两种拦截机制的区别,并结合使用…...
Android多语言开发自动化生成工具
在做 Android 开发的过程中,经常会遇到多语言开发的场景,尤其在车载项目中,多语言开发更为常见。对应多语言开发,通常都是在中文版本的基础上开发其他国家语言,这里我们会拿到中-外语言对照表,这里的工作难…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...