Python3 正则表达式:文本处理的魔法工具
Python3 正则表达式:文本处理的魔法工具
内容简介
本系列文章是为 Python3 学习者精心设计的一套全面、实用的学习指南,旨在帮助读者从基础入门到项目实战,全面提升编程能力。文章结构由 5 个版块组成,内容层层递进,逻辑清晰。
- 基础速通:n 个浓缩提炼的核心知识点,夯实编程基础;
- 经典范例:10 个贴近实际的应用场景,深入理解 Python3 的编程技巧和应用方法;
- 避坑宝典:10 个典型错误解析,提供解决方案,帮助读者避免常见的编程陷阱;
- 水平考试:10 道测试题目,检验学习成果,附有标准答案,以便自我评估;
- 实战案例:3 个迷你项目开发,带领读者从需求分析到代码实现,掌握项目开发的完整流程。
无论你是 Python3 初学者,还是希望提升实战能力的开发者,本系列文章都能为你提供清晰的学习路径和实用的编程技巧,助你快速成长为 Python3 编程高手。
阅读建议
- 初学者:建议从 “基础速通” 开始,系统学习 Python3 的基础知识,然后通过 “经典范例” 和 “避坑宝典” 加深理解,最后通过 “水平考试” 和 “实战案例” 巩固所学内容;
- 有经验的开发者:可以直接跳转到 “经典范例” 和 “避坑宝典”,快速掌握 Python3 的高级应用技巧和常见错误处理方法,然后通过 “实战案例” 提升项目开发能力;
- 选择性学习:如果读者对某个特定主题感兴趣,可以直接选择相应版块学习。各版块内容既相互独立又逻辑关联,方便读者根据自身需求灵活选择;
- 测试与巩固:完成每个版块的学习后,建议通过 “水平考试” 检验学习效果,并通过 “实战案例” 将理论知识转化为实际技能;
- 项目实战优先:如果你更倾向于实战学习,可以直接从 “实战案例” 入手,边做边学,遇到问题再回溯相关知识点。
一、基础速通
正则表达式(Regular Expression,简称 regex 或 regexp)是一种强大的工具,用于匹配和处理文本。Python 通过 re 模块提供了对正则表达式的支持。正则表达式可以用于搜索、替换、分割和验证字符串。
1. 基本概念
- 模式(Pattern):正则表达式的核心是模式,它定义了你要匹配的文本规则。
- 元字符(Metacharacters):在正则表达式中具有特殊意义的字符,如
.,*,+,?,^,$,\,|,{,},[,],(,)等。 - 普通字符:除了元字符之外的字符,如字母、数字等。
2. 常用元字符
.:匹配除换行符以外的任意单个字符。^:匹配字符串的开头。$:匹配字符串的结尾。*:匹配前面的字符零次或多次。+:匹配前面的字符一次或多次。?:匹配前面的字符零次或一次。{n}:匹配前面的字符恰好 n 次。{n,}:匹配前面的字符至少 n 次。{n,m}:匹配前面的字符至少 n 次,至多 m 次。\:转义字符,用于匹配元字符本身。|:或操作符,匹配左边或右边的表达式。[]:字符集,匹配其中的任意一个字符。():分组,将多个字符作为一个整体进行匹配。
3. 常用字符集
\d:匹配任意数字,等价于[0-9]。\D:匹配任意非数字字符,等价于[^0-9]。\w:匹配任意字母、数字或下划线,等价于[a-zA-Z0-9_]。\W:匹配任意非字母、数字或下划线的字符,等价于[^a-zA-Z0-9_]。\s:匹配任意空白字符,包括空格、制表符、换行符等。\S:匹配任意非空白字符。
4. re 模块常用函数
re.match(pattern, string):从字符串的起始位置匹配正则表达式,如果匹配成功返回匹配对象,否则返回None。re.search(pattern, string):在字符串中搜索匹配正则表达式的第一个位置,如果匹配成功返回匹配对象,否则返回None。re.findall(pattern, string):返回字符串中所有匹配正则表达式的子串,返回一个列表。re.finditer(pattern, string):返回一个迭代器,包含所有匹配正则表达式的子串。re.sub(pattern, repl, string):将字符串中匹配正则表达式的部分替换为repl。re.split(pattern, string):根据正则表达式匹配的子串将字符串分割,返回一个列表。
5. 示例
5.1 匹配数字
import retext = "The price is 123.45 dollars."
pattern = r'\d+\.\d+'
match = re.search(pattern, text)
if match:print("Found:", match.group())
5.2 替换字符串
import retext = "Hello, world!"
pattern = r'world'
repl = 'Python'
new_text = re.sub(pattern, repl, text)
print(new_text) # 输出: Hello, Python!
5.3 分割字符串
import retext = "apple,banana,cherry"
pattern = r','
result = re.split(pattern, text)
print(result) # 输出: ['apple', 'banana', 'cherry']
5.4 查找所有匹配
import retext = "The rain in Spain falls mainly in the plain."
pattern = r'\bin\b'
matches = re.findall(pattern, text)
print(matches) # 输出: ['in', 'in', 'in']
6. 分组和捕获
分组使用 () 来定义,可以捕获匹配的子串。
import retext = "John Doe, Jane Doe"
pattern = r'(\w+) (\w+)'
matches = re.findall(pattern, text)
for first_name, last_name in matches:print(f"First: {first_name}, Last: {last_name}")
7. 非贪婪匹配
默认情况下,* 和 + 是贪婪的,会尽可能多地匹配字符。可以在它们后面加上 ? 来使其变为非贪婪匹配。
import retext = "<html><head><title>Title</title></head></html>"
pattern = r'<.*?>'
matches = re.findall(pattern, text)
print(matches) # 输出: ['<html>', '<head>', '<title>', '</title>', '</head>', '</html>']
8. 编译正则表达式
如果需要多次使用同一个正则表达式,可以将其编译为正则表达式对象,以提高效率。
import repattern = re.compile(r'\d+')
text = "There are 3 apples and 5 oranges."
matches = pattern.findall(text)
print(matches) # 输出: ['3', '5']
9. 标志(Flags)
re 模块提供了一些标志来修改正则表达式的行为,如忽略大小写、多行匹配等。
re.IGNORECASE或re.I:忽略大小写。re.MULTILINE或re.M:多行模式,^和$匹配每行的开头和结尾。re.DOTALL或re.S:使.匹配包括换行符在内的所有字符。
import retext = "Hello\nWorld"
pattern = r'^world'
match = re.search(pattern, text, re.IGNORECASE | re.MULTILINE)
if match:print("Found:", match.group())
小结
正则表达式是处理文本的强大工具,Python 的 re 模块提供了丰富的功能来支持正则表达式的使用。通过掌握正则表达式的基本语法和 re 模块的常用函数,你可以高效地处理各种文本匹配和替换任务。
二、经典范例
以下是 10 个经典的正则表达式应用实例,每个实例都包含正则表达式的解释、测试代码以及执行结果的注释说明。
1. 匹配邮箱地址
正则表达式: r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
- 解释:匹配常见的邮箱地址格式。
^和$表示字符串的开始和结束。[a-zA-Z0-9_.+-]+匹配用户名部分。@匹配邮箱中的@符号。[a-zA-Z0-9-]+匹配域名部分。\.匹配域名中的点.。[a-zA-Z0-9-.]+匹配顶级域名部分。
import repattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
emails = ["test@example.com", "user.name+tag+sorting@example.com", "invalid-email@com"]
for email in emails:if re.match(pattern, email):print(f"Valid: {email}")else:print(f"Invalid: {email}")# 执行结果:
# Valid: test@example.com
# Valid: user.name+tag+sorting@example.com
# Invalid: invalid-email@com
2. 匹配手机号码
正则表达式: r'^1[3-9]\d{9}$'
- 解释:匹配中国大陆的手机号码。
1表示手机号码的第一位。[3-9]表示第二位可以是 3 到 9 之间的数字。\d{9}表示后面跟着 9 位数字。
import repattern = r'^1[3-9]\d{9}$'
phones = ["13800138000", "12345678901", "19912345678"]
for phone in phones:if re.match(pattern, phone):print(f"Valid: {phone}")else:print(f"Invalid: {phone}")# 执行结果:
# Valid: 13800138000
# Invalid: 12345678901
# Valid: 19912345678
3. 匹配 URL
正则表达式: r'https?://(?:www\.)?\S+'
- 解释:匹配 HTTP 或 HTTPS 协议的 URL。
https?匹配http或https。://匹配 URL 中的协议分隔符。(?:www\.)?匹配可选的www.。\S+匹配 URL 的其余部分。
import repattern = r'https?://(?:www\.)?\S+'
urls = ["https://www.example.com", "http://example.com", "ftp://example.com"]
for url in urls:if re.match(pattern, url):print(f"Valid: {url}")else:print(f"Invalid: {url}")# 执行结果:
# Valid: https://www.example.com
# Valid: http://example.com
# Invalid: ftp://example.com
4. 匹配日期(YYYY-MM-DD)
正则表达式: r'^\d{4}-[01]?[0-2]-[0123]?[0-9]$'
- 解释:匹配
YYYY-MM-DD格式的日期。 \d{4}匹配 4 位年份。-匹配日期分隔符。[01]?[0-2]匹配 2 位月份。[0123]?[0-9]匹配 2 位日期。
import repattern = r'^\d{4}-[01]?[0-2]-[0123]?[0-9]$'
dates = ["2023-10-05", "2023/10/05", "2023-13-01"]
for date in dates:if re.match(pattern, date):print(f"Valid: {date}")else:print(f"Invalid: {date}")# 执行结果:
# Valid: 2023-10-05
# Invalid: 2023/10/05
# Invalid: 2023-13-01
5. 匹配 IP 地址
正则表达式: r'^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$'
- 解释:匹配 IPv4 地址。
\d{1,3}匹配 1 到 3 位数字。\.匹配 IP 地址中的点.。
import repattern = r'^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$'
ips = ["192.168.1.1", "256.256.256,256", "127.0.0.1"]
for ip in ips:if re.match(pattern, ip):print(f"Valid: {ip}")else:print(f"Invalid: {ip}")# 执行结果:
# Valid: 192.168.1.1
# Invalid: 256.256.256.256
# Valid: 127.0.0.1
6. 匹配 HTML 标签
正则表达式: r'<(\w+)[^>]*>(.*?)</\1>'
- 解释:匹配 HTML 标签及其内容。
<(\w+)匹配标签名。[^>]*匹配标签内的属性。>(.*?)匹配标签内容。</\1>匹配对应的闭合标签。
import repattern = r'<(\w+)[^>]*>(.*?)</\1>'
html = "<div class='test'>Hello World</div>"
match = re.search(pattern, html)
if match:print(f"Tag: {match.group(1)}, Content: {match.group(2)}")# 执行结果:
# Tag: div, Content: Hello World
7. 匹配中文字符
正则表达式: r'[\u4e00-\u9fff]+'
- 解释:匹配中文字符。
[\u4e00-\u9fff]是中文字符的 Unicode 范围。
import repattern = r'[\u4e00-\u9fff]+'
text = "Hello 世界"
matches = re.findall(pattern, text)
print(matches) # 执行结果: ['世界']
8. 匹配密码强度
正则表达式: r'^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)(?=.*[\W_]).{8,}$'
- 解释:匹配强密码(至少 8 位,包含大小写字母、数字和特殊字符)。
(?=.*[A-Z])确保至少有一个大写字母。(?=.*[a-z])确保至少有一个小写字母。(?=.*\d)确保至少有一个数字。(?=.*[\W_])确保至少有一个特殊字符。.{8,}确保密码长度至少为 8。
import repattern = r'^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)(?=.*[\W_]).{8,}$'
passwords = ["Password123!", "weakpass", "StrongPass1"]
for pwd in passwords:if re.match(pattern, pwd):print(f"Strong: {pwd}")else:print(f"Weak: {pwd}")# 执行结果:
# Strong: Password123!
# Weak: weakpass
# Strong: StrongPass1
9. 匹配十六进制颜色值
正则表达式: r'^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$'
- 解释:匹配十六进制颜色值(如
#FFFFFF或#FFF)。 #匹配颜色值开头的#。[A-Fa-f0-9]{6}匹配 6 位十六进制值。[A-Fa-f0-9]{3}匹配 3 位十六进制值。
import repattern = r'^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$'
colors = ["#FFFFFF", "#FFF", "#123456", "#GHIJKL"]
for color in colors:if re.match(pattern, color):print(f"Valid: {color}")else:print(f"Invalid: {color}")# 执行结果:
# Valid: #FFFFFF
# Valid: #FFF
# Valid: #123456
# Invalid: #GHIJKL
10. 匹配文件名和扩展名
正则表达式: r'^(\w+)\.(\w+)$'
- 解释:匹配文件名和扩展名。
(\w+)匹配文件名。\.匹配点.。(\w+)匹配扩展名。
import repattern = r'^(\w+)\.(\w+)$'
filename = "example.txt"
match = re.match(pattern, filename)
if match:print(f"Filename: {match.group(1)}, Extension: {match.group(2)}")# 执行结果:
# Filename: example, Extension: txt
三、避坑宝典
在使用正则表达式时,初学者和中级用户经常会遇到一些常见错误。以下是 10 种常见的正则表达式错误、原因分析以及纠错方法。
1. 忘记转义特殊字符
错误:直接使用 .、*、+ 等元字符而未转义。
import re
pattern = r'example.com'
text = "example-com"
match = re.search(pattern, text) # 无法匹配
原因:. 是元字符,匹配任意字符,而不是字面的点 .。
纠错:使用 \. 转义。
pattern = r'example\.com'
2. 贪婪匹配导致意外结果
错误:使用 .* 或 .+ 时匹配过多内容。
import re
pattern = r'<.*>'
text = "<div>Hello</div><p>World</p>"
match = re.search(pattern, text) # 匹配整个字符串
原因:* 和 + 是贪婪的,会尽可能多地匹配字符。
纠错:使用非贪婪匹配 .*? 或 .+?。
pattern = r'<.*?>'
3. 忽略多行模式
错误:在多行文本中使用 ^ 或 $ 时,未启用多行模式。
import re
pattern = r'^Hello'
text = "Line1\nHello\nLine2"
match = re.search(pattern, text) # 无法匹配
原因:默认情况下,^ 和 $ 只匹配字符串的开头和结尾。
纠错:使用 re.MULTILINE 标志。
match = re.search(pattern, text, re.MULTILINE)
4. 字符集未正确使用
错误:在字符集中未正确使用 -。
import re
pattern = r'[A-Z]'
text = "abc123"
match = re.search(pattern, text) # 无法匹配小写字母
原因:[A-Z] 只匹配大写字母。
纠错:使用 [A-Za-z] 匹配所有字母。
pattern = r'[A-Za-z]'
5. 分组捕获错误
错误:未正确使用分组捕获。
import re
pattern = r'(\d{2})-(\d{2})-(\d{4})'
text = "12-31-2023"
match = re.search(pattern, text)
if match:print(match.group(1)) # 输出 12
原因:分组索引从 1 开始,group(0) 是整个匹配内容。
纠错:确保使用正确的分组索引。
if match:print(match.group(1), match.group(2), match.group(3)) # 输出 12 31 2023
6. 忽略大小写
错误:未忽略大小写导致匹配失败。
import re
pattern = r'hello'
text = "Hello World"
match = re.search(pattern, text) # 无法匹配
原因:默认情况下,正则表达式区分大小写。
纠错:使用 re.IGNORECASE 标志。
match = re.search(pattern, text, re.IGNORECASE)
7. 量词使用错误
错误:量词使用不当导致匹配失败。
import re
pattern = r'\d{3,5}'
text = "123"
match = re.search(pattern, text) # 匹配成功,但可能不符合预期
原因:{3,5} 表示匹配 3 到 5 个数字,但可能匹配过多。
纠错:根据需求调整量词。
pattern = r'\d{3}' # 只匹配 3 个数字
8. 未正确处理边界
错误:未使用单词边界 \b。
import re
pattern = r'cat'
text = "category"
match = re.search(pattern, text) # 匹配成功,但可能不符合预期
原因:cat 会匹配 category 中的 cat。
纠错:使用 \b 确保匹配完整单词。
pattern = r'\bcat\b'
9. 忽略空白字符
错误:未正确处理空白字符。
import re
pattern = r'hello world'
text = "hello world"
match = re.search(pattern, text) # 无法匹配
原因:正则表达式中的空格是字面匹配。
纠错:使用 \s+ 匹配空白字符。
pattern = r'hello\s+world'
10. 未正确处理换行符
错误:未正确处理多行文本中的换行符。
import re
pattern = r'^Hello'
text = "Line1\nHello\nLine2"
match = re.search(pattern, text) # 无法匹配
原因:不能正确处理换行符。
纠错:使用 re.MULTILINE 标志。
match = re.search(pattern, text, re.MULTILINE)
小结
正则表达式虽然强大,但在使用时容易犯一些常见错误。通过理解这些错误的原因并掌握纠错方法,可以更高效地使用正则表达式处理文本。
四、水平考试
这是一份关于“正则表达式”的测试试卷。包含:选择题:15 道、填空题:10 道和 编程题:5 道,总分 100 分。每道题后附有答案和解析。
选择题(每题 2 分,共 30 分)
-
以下哪个正则表达式可以匹配任意数字?
- A.
\d - B.
\D - C.
\w - D.
\s
答案:A
解析:\d匹配任意数字,\D匹配非数字,\w匹配字母、数字或下划线,\s匹配空白字符。
- A.
-
以下哪个正则表达式可以匹配一个或多个字母?
- A.
[a-z] - B.
[a-z]+ - C.
[a-z]* - D.
[a-z]?
答案:B
解析:+表示前面的字符至少出现一次。
- A.
-
以下哪个正则表达式可以匹配字符串的开头?
- A.
$ - B.
^ - C.
\b - D.
\B
答案:B
解析:^匹配字符串的开头,$匹配字符串的结尾。
- A.
-
以下哪个正则表达式可以匹配一个单词边界?
- A.
\b - B.
\B - C.
^ - D.
$
答案:A
解析:\b匹配单词边界,\B匹配非单词边界。
- A.
-
以下哪个正则表达式可以匹配一个浮点数?
- A.
\d+\.\d+ - B.
\d*\.\d* - C.
\d+\.\d* - D.
\d*\.\d+
答案:A
解析:\d+\.\d+匹配至少一个数字,后跟一个小数点,再跟至少一个数字。
- A.
-
以下哪个正则表达式可以匹配一个邮箱地址?
- A.
[a-zA-Z0-9]+@[a-zA-Z0-9]+\.[a-zA-Z]+ - B.
[a-zA-Z0-9]+@[a-zA-Z0-9]+ - C.
[a-zA-Z0-9]+@[a-zA-Z0-9]+\.[a-zA-Z0-9]+ - D.
[a-zA-Z0-9]+@[a-zA-Z0-9]+\.[a-zA-Z0-9]+\.
答案:A
解析:邮箱地址的格式为用户名@域名.顶级域名。
- A.
-
以下哪个正则表达式可以匹配一个 URL?
- A.
https?://\S+ - B.
http://\S+ - C.
https://\S+ - D.
http://\S
答案:A
解析:https?匹配http或https,\S+匹配非空白字符。
- A.
-
以下哪个正则表达式可以匹配一个 HTML 标签?
- A.
<.*> - B.
<.*?> - C.
<.+> - D.
<.+?>
答案:B
解析:<.*?>使用非贪婪匹配,避免匹配过多内容。
- A.
-
以下哪个正则表达式可以匹配一个中文字符?
- A.
[\u4e00-\u9fff] - B.
[a-zA-Z] - C.
\d - D.
\w
答案:A
解析:[\u4e00-\u9fff]是中文字符的 Unicode 范围。
- A.
-
以下哪个正则表达式可以匹配一个 IP 地址?
- A.
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} - B.
\d{1,3}\.\d{1,3}\.\d{1,3} - C.
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} - D.
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}
答案:A
解析:IPv4 地址由 4 个 1 到 3 位的数字组成,用.分隔。
- A.
-
以下哪个正则表达式可以匹配一个日期(YYYY-MM-DD)?
- A.
\d{4}-\d{2}-\d{2} - B.
\d{2}-\d{2}-\d{4} - C.
\d{4}/\d{2}/\d{2} - D.
\d{2}/\d{2}/\d{4}
答案:A
解析:\d{4}-\d{2}-\d{2}匹配YYYY-MM-DD格式的日期。
- A.
-
以下哪个正则表达式可以匹配一个时间(HH:MM:SS)?
- A.
\d{2}:\d{2}:\d{2} - B.
\d{2}:\d{2} - C.
\d{2}:\d{2}:\d{2}:\d{2} - D.
\d{2}:\d{2}:\d{2}:\d{2}:\d{2}
答案:A
解析:\d{2}:\d{2}:\d{2}匹配HH:MM:SS格式的时间。
- A.
-
以下哪个正则表达式可以匹配一个十六进制颜色值?
- A.
#[A-Fa-f0-9]{6} - B.
#[A-Fa-f0-9]{3} - C.
#[A-Fa-f0-9]{6}|#[A-Fa-f0-9]{3} - D.
#[A-Fa-f0-9]{6}|#[A-Fa-f0-9]{3}|#[A-Fa-f0-9]{2}
答案:C
解析:十六进制颜色值可以是 3 位或 6 位。
- A.
-
以下哪个正则表达式可以匹配一个文件名和扩展名?
- A.
\w+\.\w+ - B.
\w+\.\w - C.
\w+\.\w{2,4} - D.
\w+\.\w+\.\w+
答案:A
解析:\w+\.\w+匹配文件名和扩展名。
- A.
-
以下哪个正则表达式可以匹配一个强密码(至少 8 位,包含大小写字母、数字和特殊字符)?
- A.
^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)(?=.*[\W_]).{8,}$ - B.
^(?=.*[A-Z])(?=.*[a-z])(?=.*\d).{8,}$ - C.
^(?=.*[A-Z])(?=.*[a-z]).{8,}$ - D.
^(?=.*[A-Z])(?=.*\d).{8,}$
答案:A
解析:(?=.*[A-Z])确保至少有一个大写字母,(?=.*[a-z])确保至少有一个小写字母,(?=.*\d)确保至少有一个数字,(?=.*[\W_])确保至少有一个特殊字符。
- A.
填空题(每题 3 分,共 30 分)
-
正则表达式
\d{3}-\d{2}-\d{4}可以匹配的格式是:________。
答案:XXX-XX-XXXX(例如:123-45-6789) -
正则表达式
^[A-Za-z]+$可以匹配的字符串是:________。
答案:仅包含字母的字符串 -
正则表达式
\b\w+\b可以匹配的字符串是:________。
答案:一个完整的单词 -
正则表达式
\d{2}:\d{2}:\d{2}可以匹配的格式是:________。
答案:HH:MM:SS(例如:12:34:56) -
正则表达式
[\u4e00-\u9fff]+可以匹配的字符串是:________。
答案:中文字符 -
正则表达式
^[a-zA-Z0-9_]{4,16}$可以匹配的字符串是:________。
答案:4 到 16 位的用户名(字母、数字、下划线) -
正则表达式
https?://\S+可以匹配的字符串是:________。
答案:HTTP 或 HTTPS 协议的 URL -
正则表达式
\d+\.\d+可以匹配的字符串是:________。
答案:浮点数(例如:3.14) -
正则表达式
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$可以匹配的字符串是:________。
答案:十六进制颜色值(例如:#FFFFFF 或 #FFF) -
正则表达式
^(\d{4})-(\d{2})-(\d{2})$可以匹配的格式是:________。
答案:YYYY-MM-DD(例如:2023-10-05)
编程题(每题 8 分,共 40 分)
-
编写一个正则表达式,匹配一个合法的邮箱地址。
答案:import re pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$' emails = ["test@example.com", "invalid-email@com"] for email in emails:if re.match(pattern, email):print(f"Valid: {email}")else:print(f"Invalid: {email}") -
编写一个正则表达式,匹配一个合法的手机号码(中国大陆)。
答案:import re pattern = r'^1[3-9]\d{9}$' phones = ["13800138000", "12345678901"] for phone in phones:if re.match(pattern, phone):print(f"Valid: {phone}")else:print(f"Invalid: {phone}") -
编写一个正则表达式,匹配一个合法的 URL。
答案:import re pattern = r'https?://(?:www\.)?\S+' urls = ["https://www.example.com", "ftp://example.com"] for url in urls:if re.match(pattern, url):print(f"Valid: {url}")else:print(f"Invalid: {url}") -
编写一个正则表达式,匹配一个合法的日期(YYYY-MM-DD)。
答案:import re pattern = r'^\d{4}-\d{2}-\d{2}$' dates = ["2023-10-05", "2023/10/05"] for date in dates:if re.match(pattern, date):print(f"Valid: {date}")else:print(f"Invalid: {date}") -
编写一个正则表达式,匹配一个合法的强密码(至少 8 位,包含大小写字母、数字和特殊字符)。
答案:import re pattern = r'^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)(?=.*[\W_]).{8,}$' passwords = ["Password123!", "weakpass"] for pwd in passwords:if re.match(pattern, pwd):print(f"Strong: {pwd}")else:print(f"Weak: {pwd}")
总分:100 分
- 选择题:15 题 × 2 分 = 30 分
- 填空题:10 题 × 3 分 = 30 分
- 编程题:5 题 × 8 分 = 40 分
五、实战案例
本节内容包含 3 个关于“正则表达式”的综合应用项目,每个项目都包含完整的程序代码、测试案例、执行结果以及代码说明。具体项目是:
- 邮箱地址提取器
- 日志文件分析器
- HTML 标签提取器
项目 1:邮箱地址提取器
功能描述
从一段文本中提取所有合法的邮箱地址。
代码
import redef extract_emails(text):# 正则表达式匹配邮箱地址pattern = r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+'# 查找所有匹配的邮箱地址emails = re.findall(pattern, text)return emails# 测试案例
text = """
Contact us at support@example.com or sales@example.org.
For more information, visit https://www.example.com.
Invalid email: user@com.
"""
emails = extract_emails(text)
print("Extracted emails:", emails)
执行结果
Extracted emails: ['support@example.com', 'sales@example.org']
代码说明
- 使用正则表达式
[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+匹配邮箱地址。 re.findall返回所有匹配的邮箱地址。
项目 2:日志文件分析器
功能描述
从日志文件中提取所有错误日志(包含 “ERROR” 关键字)。
代码
import redef extract_errors(log_file):# 正则表达式匹配错误日志pattern = r'ERROR.*'errors = []with open(log_file, 'r') as file:for line in file:match = re.search(pattern, line)if match:errors.append(match.group())return errors# 测试案例
log_file = 'sample_log.txt'
# 假设 sample_log.txt 内容如下:
"""
INFO: User logged in
ERROR: Failed to connect to database
INFO: Request processed
ERROR: File not found
"""
errors = extract_errors(log_file)
print("Error logs:")
for error in errors:print(error)
执行结果
Error logs:
ERROR: Failed to connect to database
ERROR: File not found
代码说明
- 使用正则表达式
ERROR.*匹配以 “ERROR” 开头的日志行。 - 逐行读取日志文件并提取匹配的错误日志。
项目 3:HTML 标签提取器
功能描述
从 HTML 文本中提取所有标签及其内容。
代码
import redef extract_html_tags(html):# 正则表达式匹配 HTML 标签及其内容pattern = r'<(\w+)[^>]*>(.*?)</\1>'tags = re.findall(pattern, html)return tags# 测试案例
html = """
<div class="header">Welcome</div>
<p>This is a <b>test</b> paragraph.</p>
<a href="https://example.com">Link</a>
"""
tags = extract_html_tags(html)
print("HTML tags and content:")
for tag, content in tags:print(f"Tag: {tag}, Content: {content}")
执行结果
HTML tags and content:
Tag: div, Content: Welcome
Tag: p, Content: This is a <b>test</b> paragraph.
Tag: a, Content: Link
代码说明
- 使用正则表达式
<(\w+)[^>]*>(.*?)</\1>匹配 HTML 标签及其内容。 re.findall返回所有匹配的标签及其内容。
小结
以上 3 个迷你项目展示了正则表达式在实际应用中的强大功能,包括文本提取、日志分析、HTML 处理等。通过这些项目,可以更好地理解和掌握正则表达式的使用。
相关文章:

Python3 正则表达式:文本处理的魔法工具
Python3 正则表达式:文本处理的魔法工具 内容简介 本系列文章是为 Python3 学习者精心设计的一套全面、实用的学习指南,旨在帮助读者从基础入门到项目实战,全面提升编程能力。文章结构由 5 个版块组成,内容层层递进,逻…...
《DiffIR:用于图像修复的高效扩散模型》学习笔记
paper:2303.09472 GitHub:GitHub - Zj-BinXia/DiffIR: This project is the official implementation of Diffir: Efficient diffusion model for image restoration, ICCV2023 目录 摘要 1、介绍 2、相关工作 2.1 图像恢复(Image Rest…...
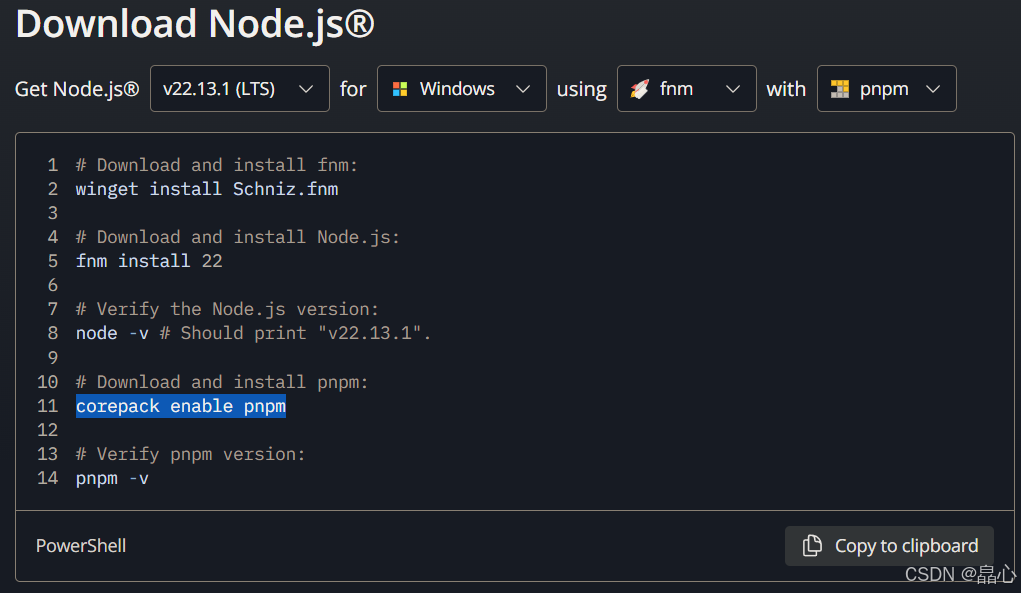
windows平台通过命令行安装前端开发环境
访问node.js官网 访问node.js官网https://nodejs.org/en/download/,可以看到类似画面: 可以获取以下命令 # Download and install fnm: winget install Schniz.fnm # Download and install Node.js: fnm install 22 # Verify the Node.js version: no…...
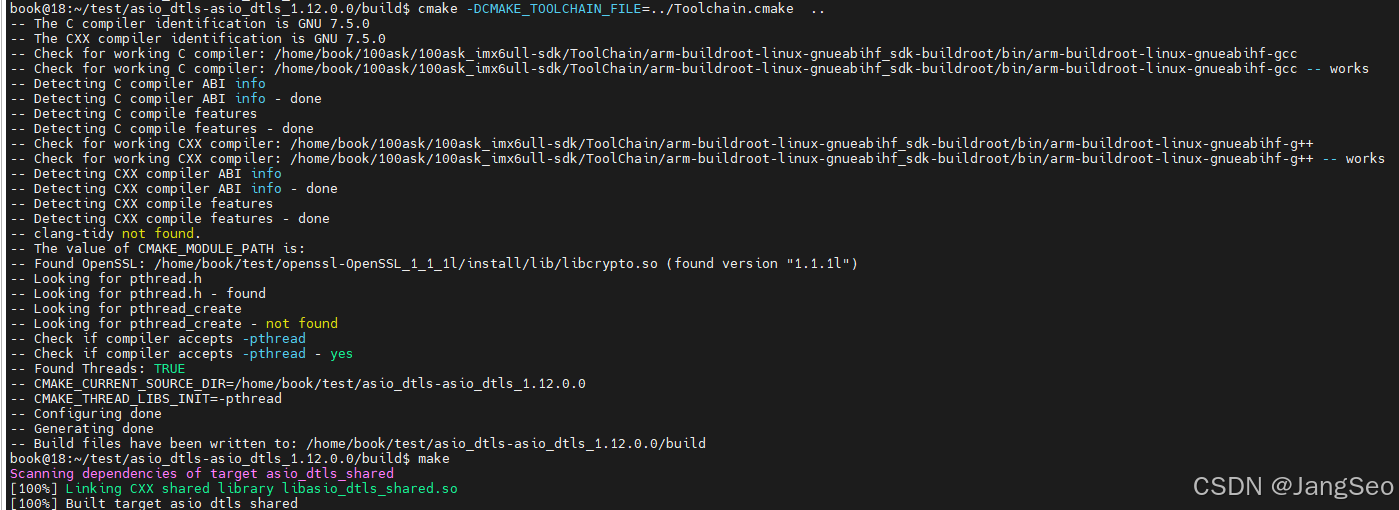
记交叉编译asio_dtls过程
虽然编译成功了,但是还是有一些不妥的地方,参考一下就行了。 比如库的版本选择就有待商榷,我这里不是按照项目作者的要求严格用对应的版本编译的,这里也可以注意一下。 编译依赖库asio 下载地址, 更正一下,我其实用…...
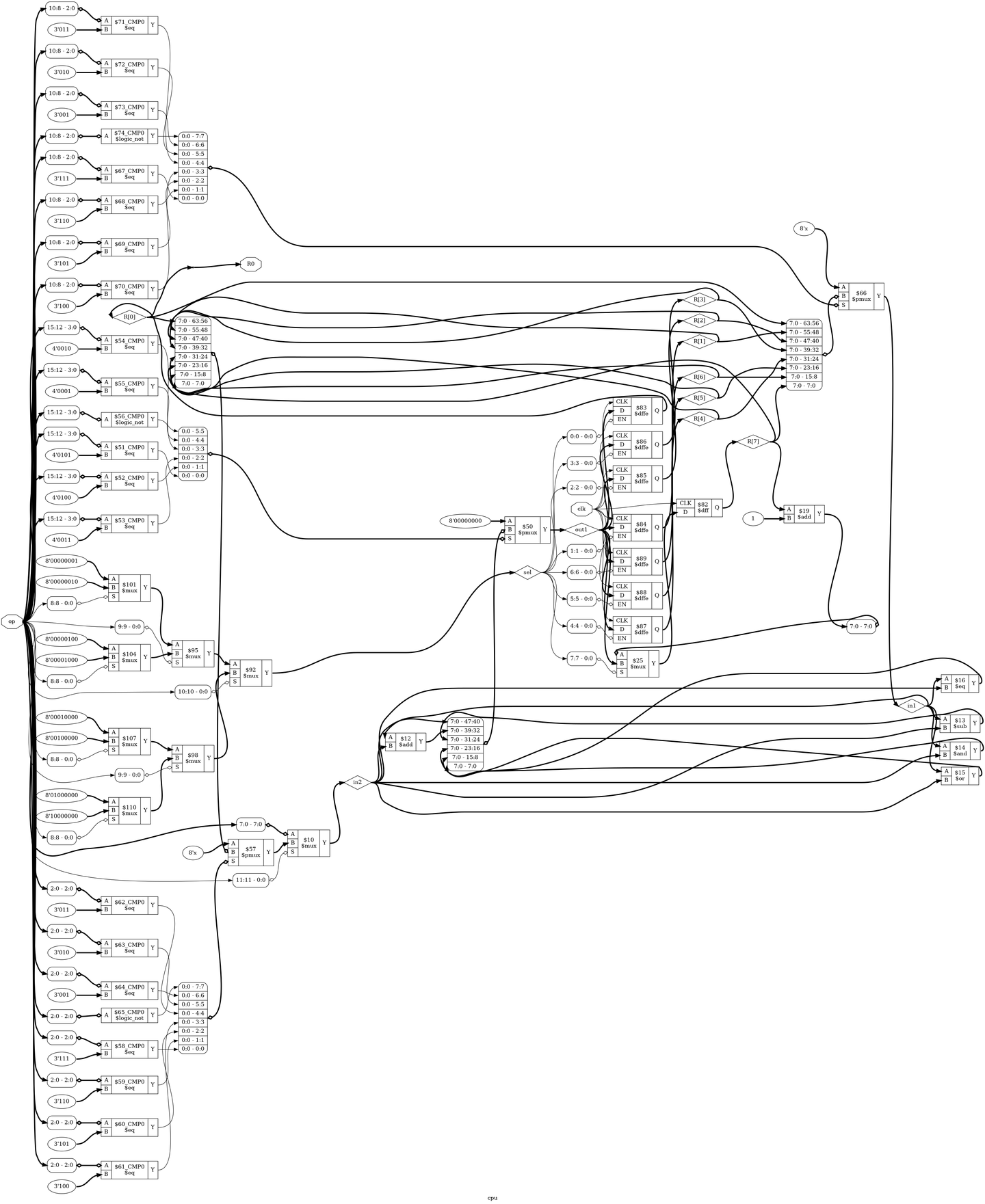
学习yosys(一款开源综合器)
安装 sudo apt-get install yosys #ubuntu22.04仓库里面是yosys-0.9 sudo install xdot 创建脚本show_rtl.ys read_verilog cpu.v hierarchy -top cpu proc; opt; fsm; opt; memory; opt; show -prefix cpu 调用脚本 yosys show_rtl.ys verilog代码 module cpu(input c…...

自定义数据集 使用tensorflow框架实现逻辑回归并保存模型,然后保存模型后再加载模型进行预测
一、使用tensorflow框架实现逻辑回归 1. 数据部分: 首先自定义了一个简单的数据集,特征 X 是 100 个随机样本,每个样本一个特征,目标值 y 基于线性关系并添加了噪声。tensorflow框架不需要numpy 数组转换为相应的张量࿰…...

对于Docker的初步了解
简介与概述 1.不需要安装环境,工具包包含了环境(jdk等) 2.打包好,“一次封装,到处运行” 3.跨平台,docker容器在任何操作系统上都是一致的,这就是实现跨平台跨服务器。只需要一次配置好环境&…...

C语言进阶——3字符函数和字符串函数(2)
8 strsrt char * strstr ( const char *str1, const char * str2);查找子字符串 返回指向 str1 中第一次出现的 str2 的指针,如果 str2 不是 str1 的一部分,则返回 null 指针。匹配过程不包括终止 null 字符,但会在此处停止。 8.1 库函数s…...

机器学习day3
自定义数据集使用框架的线性回归方法对其进行拟合 import matplotlib.pyplot as plt import torch import numpy as np # 1.散点输入 # 1、散点输入 # 定义输入数据 data [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1]…...

追剧记单词之:国色芳华与单词速记
●wretched adj. 恶劣的;悲惨的;不幸的;难过的 (不幸的)胜意出生于一个(恶劣的)家庭环境,嫁给王擎后依然过着(悲惨的)生活,她死后,牡丹…...

AIGC浪潮下,图文内容社区数据指标体系构建探索
在AIGC(人工智能生成内容)浪潮席卷之下,图文内容社区迎来了新的发展机遇与挑战。为了有效监控和优化业务发展,构建一个科学、全面的数据指标体系显得尤为重要。本文将深入探讨如何在AIGC背景下,为图文内容社区构建一套…...

总线、UART、IIC、SPI
一图流 总线 概念 连接多个部件的信息传输线,是各部件共享的传输介质 类型 片内总线:连接处理器内核和外设的总线,在芯片内部 片外总线:连接芯片和其他芯片或者模块的总线 总线的通信 总线通信的方式 串行通信 数据按位顺序传…...

戴尔电脑设置u盘启动_戴尔电脑设置u盘启动多种方法
最近有很多网友问,戴尔台式机怎么设置u盘启动,特别是近两年的戴尔台式机比较复杂,有些网友不知道怎么设置,其实设置u盘启动有两种方法,下面小编教大家戴尔电脑设置u盘启动方法。 戴尔电脑设置u盘启动方法一、戴尔进入b…...

【python】四帧差法实现运动目标检测
四帧差法是一种运动目标检测技术,它通过比较连续四帧图像之间的差异来检测运动物体。这种方法可以在一定的程度上提高检测的准确性。 目录 1 方案 2 实践 ① 代码 ② 效果图 1 方案 具体的步骤如下: ① 读取视频流:使用cv2.VideoCapture…...
-JVM即时编译)
JVM学习指南(48)-JVM即时编译
文章目录 即时编译(Just-In-Time Compilation, JIT)概述为什么JVM需要即时编译?即时编译与传统的静态编译的区别JVM中的即时编译器HotSpot VM中的C1和C2编译器编译器的作用和位置即时编译的工作流程代码的加载和解释执行热点代码检测编译优化编译优化技术公共子表达式消除循…...

office 2019 关闭word窗口后卡死未响应
最近关闭word文件总是出现卡死未响应的状态,必须从任务管理器才能杀掉word 进程,然后重新打开word再保存,很是麻烦。(#其他特征,在word中打字会特别变慢,敲击键盘半秒才出现字符。) office官网…...

[操作系统] 深入进程地址空间
程序地址空间回顾 在C语言学习的时,对程序的函数、变量、代码等数据的存储有一个大致的轮廓。在语言层面上存储的地方叫做程序地址空间,不同类型的数据有着不同的存储地址。 下图为程序地址空间的存储分布和和特性: 使用以下代码来验证一下…...

CVE-2025-0411 7-zip 漏洞复现
文章目录 免责申明漏洞描述影响版本漏洞poc漏洞复现修复建议 免责申明 本文章仅供学习与交流,请勿用于非法用途,均由使用者本人负责,文章作者不为此承担任何责任 漏洞描述 此漏洞 (CVSS SCORE 7.0) 允许远程攻击者绕…...

leetcode151-反转字符串中的单词
leetcode 151 思路 时间复杂度:O(n) 空间复杂度:O(n) 首先将字符串转为数组,这样可以方便进行操作,然后定义一个新的数组来存放从后到前的单词,由于arr中转换以后可能会出现有些项是空格的情况,所以需要判…...

若依 v-hasPermi 自定义指令失效场景
今天使用若依跟往常一样使用v-hasPermi 自定义指令的时候发现这个指令失效了,原因是和v-if指令一块使用,具体代码如下: <el-buttonsize"mini"type"text"icon"el-icon-edit-outline"v-hasPermi"[evalu…...

Fish-Speech-1.5 API调用教程:Python脚本批量生成语音
Fish-Speech-1.5 API调用教程:Python脚本批量生成语音 1. 为什么选择Fish-Speech-1.5进行批量语音生成 在日常工作中,我们经常遇到需要将大量文本转换为语音的场景。无论是为视频内容生成旁白,还是为电子书制作有声版本,传统的人…...

7个步骤打造高效文件上传系统:Plupload零基础入门指南
7个步骤打造高效文件上传系统:Plupload零基础入门指南 【免费下载链接】plupload Plupload is JavaScript API for building file uploaders. It supports multiple file selection, file filtering, chunked upload, client side image downsizing and when necess…...

bert-base-chinese详细步骤:如何将test.py改造成支持流式文本处理的微服务
bert-base-chinese详细步骤:如何将test.py改造成支持流式文本处理的微服务 1. 项目背景与价值 在实际的工业场景中,我们经常需要处理大量的文本数据流。传统的批处理方式虽然简单,但无法满足实时性要求高的应用场景。比如智能客服系统需要实…...
Python 入门后进阶:用 Pixel Mind Decoder 完成你的第一个 AI 项目
Python 入门后进阶:用 Pixel Mind Decoder 完成你的第一个 AI 项目 1. 从零开始你的AI项目之旅 刚学完Python基础语法,是不是觉得光写些练习题和小脚本不够过瘾?今天我们就来做个有意思的实战项目——用AI分析文本情绪,再给它套…...

Eigen矩阵打印踩坑记:从乱码到优雅输出的3个关键技巧与一个隐藏Bug
Eigen矩阵打印踩坑记:从乱码到优雅输出的3个关键技巧与一个隐藏Bug 第一次在ROS项目里调试Eigen矩阵时,我盯着终端里歪歪扭扭的数字对齐和突然冒出的科学计数法,花了整整两小时才意识到这不是算法问题,而是输出格式在作祟。Eigen作…...

卡证检测矫正模型效果展示:高清四角点定位+正视角矫正图实拍
卡证检测矫正模型效果展示:高清四角点定位正视角矫正图实拍 你有没有遇到过这样的烦恼?需要上传身份证、驾照或者护照照片时,手机随手一拍,结果照片歪歪扭扭,背景杂乱,关键信息还被手指挡住了。这时候要么…...

《与AI的妄想对话:如何给机器人造灵魂?》
本文为个人想法分享,是一种幻觉创作,只图一乐。 #赛博哲学 #概念艺术 #AI幻想 #科幻微小说提问: 你分析一下下面这段文章里面的harness它的构建原则。我觉得他和我们这个理论里面说的某一些东西我感觉很像好像是这种智能的或者说锚点定义的简…...
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台 1. 企业内容中台的业务场景与挑战 现代企业面临内容生产的三大痛点:创意产出效率低、设计资源不足、多平台适配成本高。以电商行业为例,一个中型电商平台每月需要…...

UE5 GAS调试技巧:巧用ASC的‘Attribute Test’面板,5分钟搞定角色属性配置与验证
UE5 GAS高效调试指南:利用Attribute Test面板快速验证角色属性配置 在虚幻引擎5的游戏开发中,Gameplay Ability System (GAS)作为构建复杂角色能力与属性的核心框架,其调试效率直接影响着RPG类项目的开发进度。本文将深入探讨如何利用Ability…...

YOLOv8训练自己的道路裂缝数据集,从数据标注到模型部署的保姆级避坑指南
YOLOv8道路裂缝检测实战:从数据标注到模型部署的全流程避坑指南 道路养护工程师小张最近遇到了头疼的问题——每天需要人工巡检数十公里道路,用粉笔标记裂缝位置再拍照记录。这种传统方式效率低下且容易遗漏细微裂缝。直到他发现了YOLOv8这个目标检测利器…...