Spark入门(Python)
目录
一、安装Spark
二、Spark基本操作
一、安装Spark
pip3 install pyspark二、Spark基本操作
# 导入spark的SparkContext,SparkConf模块
from pyspark import SparkContext, SparkConf
# 导入os模块
import os
# 设置PYSPARK的python环境
os.environ['PYSPARK_PYTHON'] = "C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python310\\python.exe"# 构建SparkConf()设置AppName和Master
conf = SparkConf().setAppName("myapp").setMaster("local")
# 构建入口对象SparkContext对象sc
sc = SparkContext(conf=conf)# 定义列表对象
list1 = [1, 2, 3, 4, 5]
# 构建list对象的RDD对象
rdd1 = sc.parallelize(list1)
print(rdd1.collect())# 定义元祖tuple对象
tuple1 = (1, 2, 3, 4, 5)
# 构建tuple对象的RDD对象
rdd2 = sc.parallelize(tuple1)
print(rdd2.collect())# 定义字典对象
dict1 = {'a': 1, 'b': 2, 'c': 3}
# 构建dict对象的RDD对象
rdd3 = sc.parallelize(dict1)
print(rdd3.collect())# 定义集合对象
set1 = {1, 2, 3, 4, 5}
# 构建集合对象的RDD对象
rdd4 = sc.parallelize(set1)
print(rdd4.collect())# 定义字符串对象
string1 = "Hello, World!"
# 构建字符串对象的RDD对象
rdd5 = sc.parallelize(string1)
print(rdd5.collect())# 通过textFile方法构建RDD对象
# data.txt文件内容如下:
# python java python python java
# java python C pascal java
# C java python pascal basic
# basic C java python python
# C C java basic java
rdd6 = sc.textFile('./data.txt')
print(rdd6.collect())# 使用flatMap算子将rdd6中的元素进行解构拆分
rdd7 = rdd6.flatMap(lambda x: x.split(' '))
print(rdd7.collect())# 使用map算子将rdd7中的元素进行结构转换
# 构造成(x,1)的元祖
rdd8 = rdd7.map(lambda x:(x,1))
print(rdd8.collect())# 使用reduceByKey算子对rdd8中的元素进行聚合
rdd9 = rdd8.reduceByKey(lambda x,y:x+y)
print(rdd9.collect())# 使用sortBy算子对rdd9中的元素进行排序
rdd10 = rdd9.sortBy(lambda x:x[1],ascending=False,numPartitions=1)
print(rdd10.collect())# 使用filter算子对rdd10中的元素进行过滤
rdd11 = rdd10.filter(lambda x:x[0] == 'java')
print(rdd11.collect())# def add(x):
# return x + 1
#
# rdd = rdd1.map(add).map(lambda x: x * 10)
#
# print(rdd.collect())# rdd = sc.parallelize(['a', 'b', 'd', 'd'])
#
# rdd2 = rdd.map(lambda x:(x,1))
#
# print(rdd2.collect())
#
# rdd3 = rdd2.reduceByKey(lambda x,y:x+y)
#
# print(rdd3.collect())
#
# rdd4 = rdd2.countByKey()
#
# print(rdd4)sc.stop()相关文章:
)
Spark入门(Python)
目录 一、安装Spark 二、Spark基本操作 一、安装Spark pip3 install pyspark 二、Spark基本操作 # 导入spark的SparkContext,SparkConf模块 from pyspark import SparkContext, SparkConf # 导入os模块 import os # 设置PYSPARK的python环境 os.environ[PYSPARK_PYTHON] &…...

Daemon进程创建过程
Daemon创建过程: 1、fork,创建子进程。退出父进程。 2、setsid,创建新会话。脱离原会话、进程组、控制终端。 再次fork,与终端完全脱离。第二次fork的意义???? 先脱离原父进程&#…...

在sortablejs的拖拽排序情况下阻止input拖拽事件
如题 问题 在vue3的elementPlus的table中,通过sortablejs添加了行拖拽功能,但是在行内会有输入框,此时拖拽输入框会触发sortablejs的拖拽功能 解决 基于这个现象,我怀疑是由于拖拽事件未绑定而冒泡到后面的行上从而导致的拖拽…...

C++初阶—string类
第一章:为什么要学习string类 1.1 C语言中的字符串 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想&…...

C# 提取PDF表单数据
目录 使用工具 C# 提取多个PDF表单域的数据 C# 提取特定PDF表单域的数据 PDF表单是一种常见的数据收集工具,广泛应用于调查问卷、业务合同等场景。凭借出色的跨平台兼容性和标准化特点,PDF表单在各行各业中得到了广泛应用。然而,当需要整合…...

算法刷题Day28:BM66 最长公共子串
题目链接,点击跳转 题目描述: 解题思路: 方法一:暴力枚举 遍历str1的每个字符x,并在str2中寻找以相同元素x为起始的最长字符串。记录最长的公共子串及其长度。 代码实现: def LCS(self, str1: str, st…...
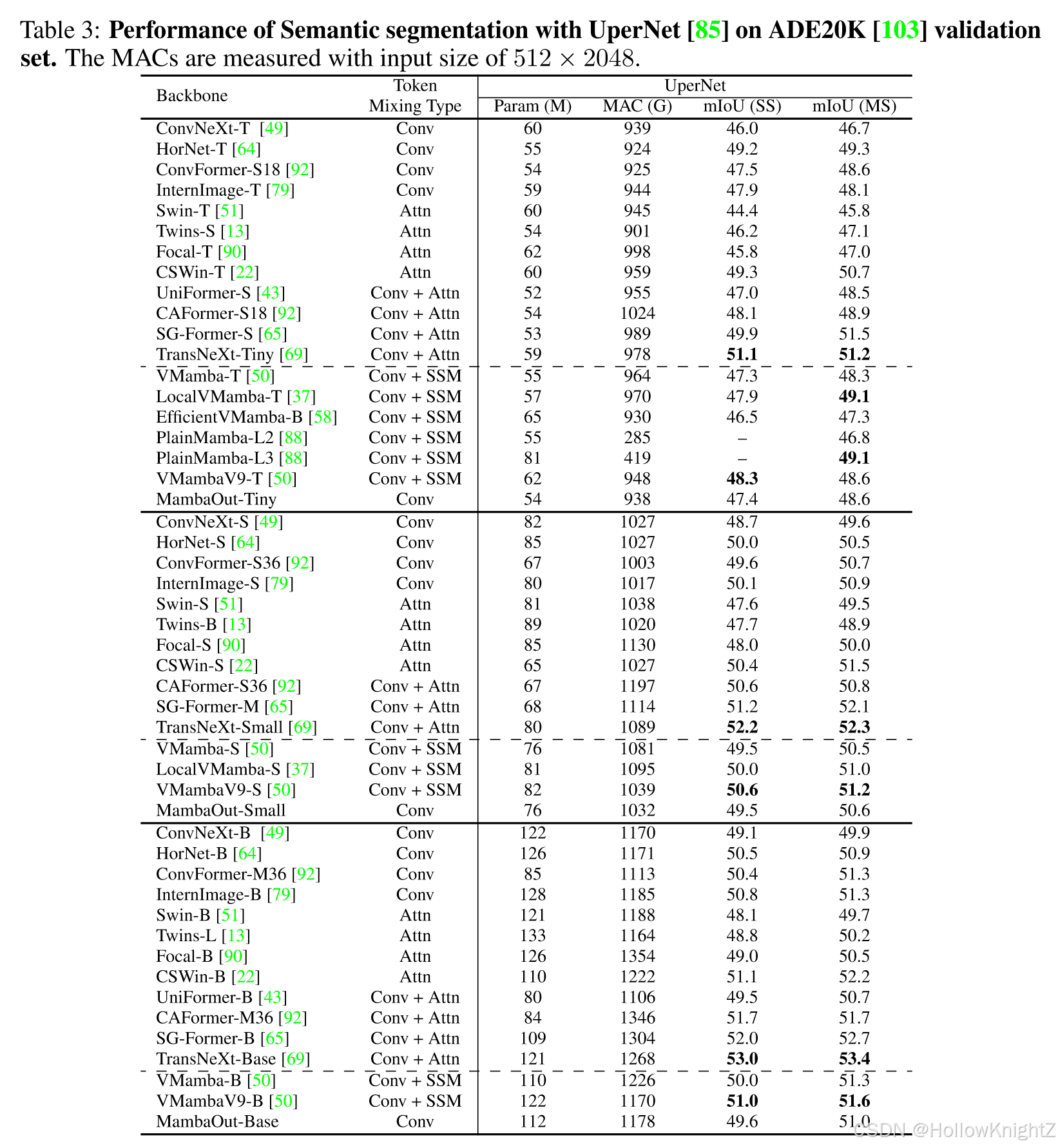
论文阅读笔记:MambaOut: Do We Really Need Mamba for Vision?
论文阅读笔记:MambaOut: Do We Really Need Mamba for Vision? 1 背景2 创新点3 方法4 模块4.1 Mamba适合什么任务4.2 视觉识别任务是否有很长的序列4.3 视觉任务是否需要因果token混合模式4.4 关于Mamba对于视觉的必要性假设 5 效果 论文:https://arxi…...
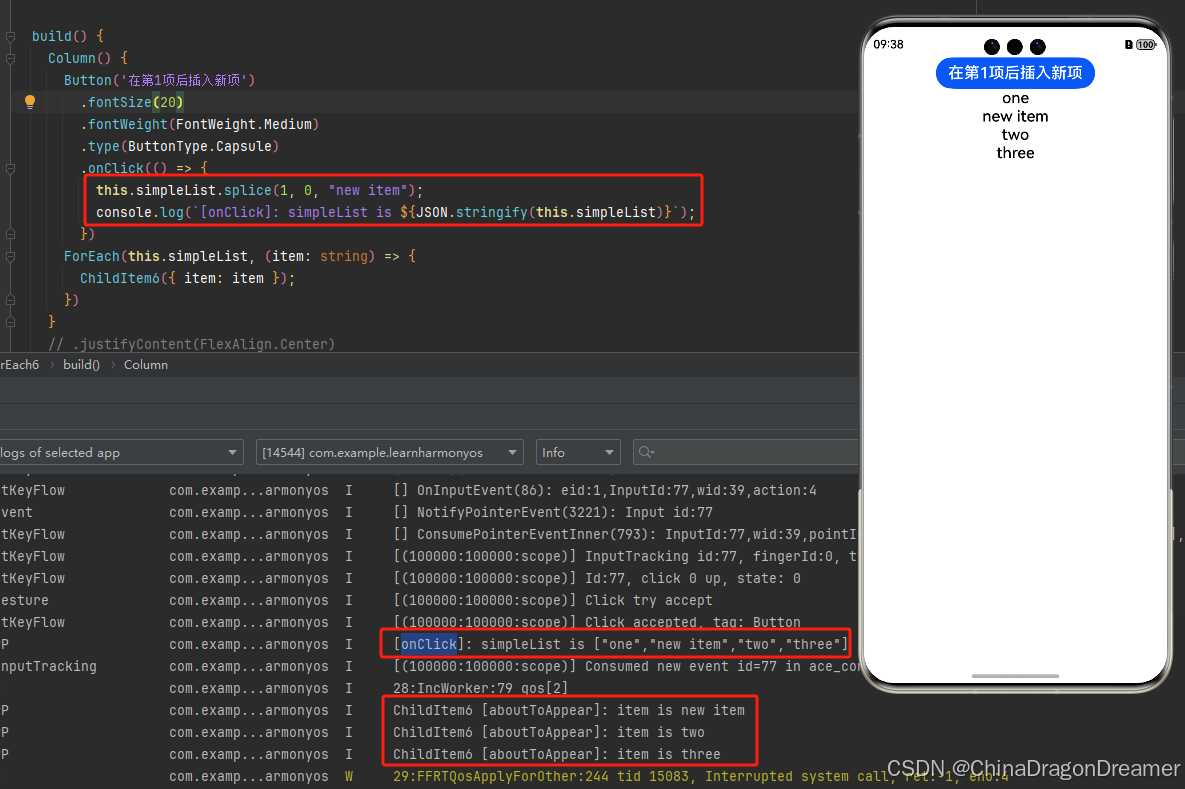
HarmonyOS:ForEach:循环渲染
一、前言 ForEach接口基于数组类型数据来进行循环渲染,需要与容器组件配合使用,且接口返回的组件应当是允许包含在ForEach父容器组件中的子组件。例如,ListItem组件要求ForEach的父容器组件必须为List组件。 API参数说明见:ForEa…...

Python3 【函数】项目实战:5 个新颖的学习案例
Python3 【函数】项目实战:5 个新颖的学习案例 本文包含5编程学习案例,具体项目如下: 简易聊天机器人待办事项提醒器密码生成器简易文本分析工具简易文件加密解密工具 项目 1:简易聊天机器人 功能描述: 实现一个简易…...

XSS 漏洞全面解析:原理、危害与防范
目录 前言编辑 漏洞原理 XSS 漏洞的危害 检测 XSS 漏洞的方法 防范 XSS 漏洞的措施 前言 在网络安全的复杂版图中,XSS 漏洞,即跨站脚本攻击(Cross - Site Scripting),是一类极为普遍且威胁巨大的安全隐患。随着互…...

从 GShard 到 DeepSeek-V3:回顾 MoE 大模型负载均衡策略演进
作者:小天狼星不来客 原文:https://zhuanlan.zhihu.com/p/19117825360 故事要从 GShard 说起——当时,人们意识到拥有数十亿甚至数万亿参数的模型可以通过某种形式的“稀疏化(sparsified)”来在保持高精度的同时加速训…...

【回溯+剪枝】回溯算法的概念 全排列问题
文章目录 46. 全排列Ⅰ. 什么是回溯算法❓❓❓Ⅱ. 回溯算法的应用1、组合问题2、排列问题3、子集问题 Ⅲ. 解题思路:回溯 剪枝 46. 全排列 46. 全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 …...

Flutter解决macbook M芯片Android Studio中不显示IOS真机的问题
下载了最新的Android Studio LadyBug 下载了最新的xcode16.2 结果,只有安卓真机才在Android studio显示, IOS真机只在xcode显示 IOS真机不在android studio显示。 解决方法是: 在终端运行如下命令: sudo xcode-select -s /Applic…...

自签证书的dockerfile中from命令无法拉取镜像而docker的pull命令能拉取镜像
问题现象: docker pull images拉取镜像正常 dockerfile中的from命令拉取镜像就会报出证书错误。报错信息如下: [bjxtbwj-kvm-test-jenkins-6-243 ceshi_dockerfile]$ docker build . [] Building 0.4s (3/3) FINISHED …...

【MySQL】--- 复合查询 内外连接
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: MySQL 🏠 基本查询回顾 假设有以下表结构: 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为…...

QT TLS initialization failed
qt使用QNetworkAccessManager下载文件(给出的链接可以在浏览器里面下载文件),下载失败, 提示“TLS initialization failed”通常是由于Qt在使用HTTPS进行文件下载时,未能正确初始化TLS(安全传输层协议&…...

系统学英语 — 句法 — 复合句
目录 文章目录 目录复合句型主语从句宾语从句表语从句定语从句状语从句同位语从句 复合句型 复合句型,即:从句。在英语中,除了谓语之外的所有句子成分都可以使用从句来充当。 主语从句 充当主语的句子,通常位于谓语之前&#x…...

指针的介绍2前
1.数组名的理解 #define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h>int main() {int arr[] { 1,2,3,4,5,6,7,8,9 };printf("&arr[0] %p\n", &arr[0]);printf("arr %p\n", arr);return 0; } 观察得到,数组名就是数组首…...

16.Word:石油化工设备技术❗【28】
目录 题目 NO1.2 NO3 NO4 题目 NO1.2 F12:另存为将“Word素材.docx”文件另存为“Word. docx”(“docx”为文件扩展名) 光标来到表格上方→插入→形状→新建画布→单击选中→格式→高度/宽度(格式→大小对话框→取消勾选✔锁定…...

Python-基础环境(01) 虚拟环境,Python 基础环境之虚拟环境,一篇文章助你完全搞懂!
Python的虚拟环境是一种工具,它能够创建一个隔离的独立Python环境。每个虚拟环境都有自己独立的Python解释器和安装的包,不会与其他虚拟环境或系统的全局Python环境发生冲突。虚拟环境特别适用于以下情况: 项目隔离:不同的项目可…...

QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制
QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了心爱的歌曲࿰…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

C++定时器避坑指南:线程安全、资源泄漏与时间轮参数怎么调?一次讲清楚
C定时器避坑指南:线程安全、资源泄漏与时间轮参数调优实战 在分布式系统和高并发场景中,定时器如同系统的心跳机制,其稳定性直接决定服务可靠性。去年某电商平台大促期间,由于定时任务堆积导致的雪崩效应,造成近千万损…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

MySQL 索引底层 B+ 树原理
聊 MySQL 索引,不讲 B 树,那就是在耍流氓。 大家好,我是乱码字符。今天咱们深入聊聊 MySQL 索引的底层数据结构——B 树。这篇文章能让你彻底搞明白,为什么有时候明明加了索引,查询却还是慢成狗。 先说说为什么要用树结…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

基于RP2040与CircuitPython的键盘内嵌DOOM游戏启动器DIY指南
1. 项目概述与核心思路几年前,我还在用笨重的全尺寸键盘时,就总琢磨着怎么给这每天摸上八小时的家伙加点“私货”。直到后来玩起了RP2040和CircuitPython,一个念头就冒出来了:能不能把游戏直接“焊”进键盘里?不是那种…...

从单一AI到智能体集群:构建模块化AI协作系统的核心原理与实践
1. 项目概述:当AI学会“开会”,一个开源智能体集群的诞生最近在GitHub上看到一个挺有意思的项目,叫daveshap/OpenAI_Agent_Swarm。光看名字,你可能会觉得这又是一个调用OpenAI API的简单封装库。但如果你点进去,花上十…...