JUC--ConcurrentHashMap底层原理
ConcurrentHashMap底层原理
- ConcurrentHashMap
- JDK1.7
- 底层结构
- 线程安全底层具体实现
- JDK1.8
- 底层结构
- 线程安全底层具体实现
- 总结
- JDK 1.7 和 JDK 1.8实现有什么不同?
- ConcurrentHashMap 中的 CAS 应用
ConcurrentHashMap
ConcurrentHashMap 是一种线程安全的高效Map集合
底层数据结构:
- JDK1.7底层采用分段的数组+链表实现
- JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
JDK1.7
底层结构

ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 数组中的每个元素包含一个 HashEntry 数组,每个 HashEntry 数组属于链表结构。
线程安全底层具体实现

首先将数据分为一段一段(这个“段”就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的个数一旦初始化就不能改变。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的。
JDK1.8
底层结构

JDK1.8 的 ConcurrentHashMap 不再是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。
线程安全底层具体实现
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
底层源码:

public V put(K key, V value) {return putVal(key, value, false);
}/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {// key 和 value 不能为空if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {// f = 目标位置元素Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值if (tab == null || (n = tab.length) == 0)// 数组桶为空,初始化数组桶(自旋+CAS)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;// 使用 synchronized 加锁加入节点synchronized (f) {if (tabAt(tab, i) == f) {// 说明是链表if (fh >= 0) {binCount = 1;// 循环加入新的或者覆盖节点for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {// 红黑树Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;
}
工作步骤:
- 初始化,使用 cas 来保证并发安全,懒惰初始化 table
- 树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头
说明:锁住某个槽位的对象头,是一种很好的细粒度的加锁方式,类似 MySQL 中的行锁 - put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put操作,元素添加至 bin 的尾部
- get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 会让 get 操作在新 table 进行搜索
- 扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容
- size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中,最后统计数量时累加
总结
JDK 1.7 和 JDK 1.8实现有什么不同?
- 线程安全实现方式:JDK 1.7 采用
Segment分段锁来保证安全,Segment是继承自ReentrantLock。JDK1.8 放弃了Segment分段锁的设计,采用Node + CAS + synchronized保证线程安全,锁粒度更细,synchronized只锁定当前链表或红黑二叉树的首节点。 - Hash 碰撞解决方法 : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
- 并发度:JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
ConcurrentHashMap 中的 CAS 应用
ConcurrentHashMap 是 Java 中高效的并发集合类,它通过结合使用 CAS 和 synchronized 来保证线程安全性。
-
CAS:用于在没有锁的情况下保证单个桶(bucket)中的线程安全更新,尤其是
putIfAbsent()、replace()等操作。每个桶内部通常是通过 CAS 来完成插入、删除和更新操作,减少了全表锁定的情况,提高了性能。示例: 在
ConcurrentHashMap的putIfAbsent方法中,CAS 用来判断当前桶内是否已有值,如果没有,则将新值插入。void putIfAbsent(K key, V value) {int hash = hash(key);Node<K,V> node = table[hash & (table.length - 1)];// 使用 CAS 保证插入操作的线程安全if (node == null || cas(node, null, value)) {return value;}return null; } -
synchronized:在一些较为复杂的操作(比如扩容、迭代器遍历时)中,仍然使用synchronized来保证线程安全。
通过这样的组合,ConcurrentHashMap 既能避免在并发情况下对整个数据结构加锁,提高效率,又能在需要的时候通过 synchronized 保证一致性。
相关文章:
JUC--ConcurrentHashMap底层原理
ConcurrentHashMap底层原理 ConcurrentHashMapJDK1.7底层结构线程安全底层具体实现 JDK1.8底层结构线程安全底层具体实现 总结JDK 1.7 和 JDK 1.8实现有什么不同?ConcurrentHashMap 中的 CAS 应用 ConcurrentHashMap ConcurrentHashMap 是一种线程安全的高效Map集合…...

【2024年华为OD机试】(C卷,200分)- 推荐多样性 (JavaScriptJava PythonC/C++)
一、问题描述 问题描述 我们需要从多个已排序的列表中选取元素,以填充多个窗口。每个窗口需要展示一定数量的元素,且元素的选择需要遵循特定的穿插策略。具体来说,我们需要: 从第一个列表中为每个窗口选择一个元素,然后从第二个列表中为每个窗口选择一个元素,依此类推。…...

【教学类-89-01】20250127新年篇01—— 蛇年红包(WORD模版)
祈愿在2025蛇年里, 伟大的祖国风调雨顺、国泰民安、每个人齐心协力,共同经历这百年未有之大变局时代(国际政治、AI技术……) 祝福亲友同事孩子们平安健康(安全、安全、安全)、巳巳如意! 背景需…...

[权限提升] 操作系统权限介绍
关注这个专栏的其他相关笔记:[内网安全] 内网渗透 - 学习手册-CSDN博客 权限提升简称提权,顾名思义就是提升自己在目标系统中的权限。现在的操作系统都是多用户操作系统,用户之间都有权限控制,我们通过 Web 漏洞拿到的 Web 进程的…...

DeepSeek异军突起,重塑AI格局
DeepSeek异军突起,重塑AI格局这两天AI 圈发生了比过年更令人兴奋的事情,“Meta内部反水事件”、“黄仁勋的底盘问题”,以及AI格局的大动荡,一切都是因为那个叫DeepSeek的“中国自主AI”!它由幻方量化开发,以…...
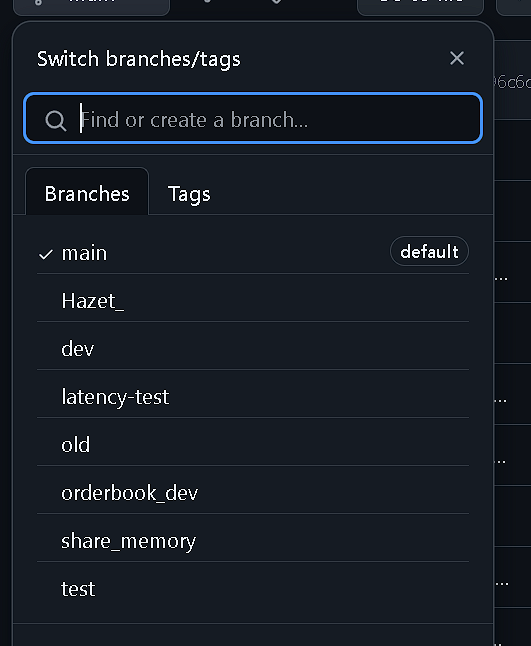
git的理解与使用
本地的git git除了最经典的add commit push用来做版本管理,其实他的分支管理也非常强大 可以说你学好了分支管理,就可以完成团队的配合协作了 git仓库 我们可以使用git init来初始化一个git仓库,只要能看见.git文件夹,就代表这…...

Baklib打造内容中台新模式助力企业智能化升级
内容概要 在如今数字化日渐渗透各个行业的背景下,内容中台逐渐成为推动企业智能化转型的重要工具。内容中台不仅仅是一个信息管理平台,更是一个整合多种内容资源,提升企业反应能力与市场适应力的创新模式。随着数据量的激增,传统…...

STM32完全学习——RT-thread在STM32F407上移植
一、写在前面 关于源码的下载,以及在KEIL工程里面添加操作系统的源代码,这里就不再赘述了。需要注意的是RT-thread默认里面是会使用串口的,因此需要额外的进行串口的初始化,有些人可能会问,为什么不直接使用CubMAX直接…...

基于51单片机和ESP8266(01S)、LCD1602、DS1302、独立按键的WiFi时钟
目录 系列文章目录前言一、效果展示二、原理分析三、各模块代码1、延时2、定时器03、串口通信4、DS13025、LCD16026、独立按键 四、主函数总结 系列文章目录 前言 之前做了一个WiFi定时器时钟,用八位数码管进行显示,但是定时器时钟的精度较低࿰…...
技术浅析(二):深度强化学习)
启元世界(Inspir.ai)技术浅析(二):深度强化学习
深度强化学习(Deep Reinforcement Learning, DRL)是启元世界在人工智能领域的一项核心技术,广泛应用于游戏AI、智能决策等领域。 一、状态(State) 1.1 概念与作用 **状态(State)**是指智能体对环境的感知,是智能体进行决策的基础。在深度强化学习中,状态通常是一个高…...
--Java)
LeetCode100之子集(78)--Java
1.问题描述 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的 子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 示例1 输入:nums [1,2,3]输出:[[],[1],[2],[1,2],[3],[1…...
)
React第二十五章(受控组件/非受控组件)
React 受控组件理解和应用 React 受控组件 受控组件一般是指表单元素,表单的数据由React的 State 管理,更新数据时,需要手动调用setState()方法,更新数据。因为React没有类似于Vue的v-model,所以需要自己实现绑定事件…...

使用 Confluent Cloud 的 Elasticsearch Connector 部署 Elastic Agent
作者:来自 Elastic Nima Rezainia Confluent Cloud 用户现在可以使用更新后的 Elasticsearch Sink Connector 与 Elastic Agent 和 Elastic Integrations 来实现完全托管且高度可扩展的数据提取架构。 Elastic 和 Confluent 是关键的技术合作伙伴,我们很…...

嵌入式知识点总结 Linux驱动 (三)-文件系统
针对于嵌入式软件杂乱的知识点总结起来,提供给读者学习复习对下述内容的强化。 目录 1.什么是文件系统? 2.根文件系统为什么这么重要?编辑 3.可执行映像文件通常由几部分构成,他们有什么特点? 1.什么是文件系统&a…...

【知识】可视化理解git中的cherry-pick、merge、rebase
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 这三个确实非常像,以至于对于初学者来说比较难理解。 总结对比 先给出对比: 特性git mergegit rebasegit cherry-pick功能合并…...

【deepseek】deepseek-r1本地部署-第二步:huggingface.co替换为hf-mirror.com国内镜像
一、背景 由于国际镜像国内无法直接访问,会导致搜索模型时加载失败,如下: 因此需将国际地址替换为国内镜像地址。 二、操作 1、使用vscode打开下载路径 2、全局地址替换 关键字 huggingface.co 替换为 hf-mirror.com 注意:务…...

新站如何快速获得搜索引擎收录?
本文来自:百万收录网 原文链接:https://www.baiwanshoulu.com/8.html 新站想要快速获得搜索引擎收录,需要采取一系列有针对性的策略。以下是一些具体的建议: 一、网站内容优化 高质量原创内容: 确保网站内容原创、…...

如何使用tushare pro获取股票数据——附爬虫代码以及tushare积分获取方式
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据 总结 一、Tushare 介绍 Tushare 是一个提供中国股市数据的API接口服务,它允许用户…...

解决vsocde ssh远程连接同一ip,不同端口情况下,无法区分的问题
一般服务器会通过镜像分身或者容器的方式,一个ip分出多个端口给多人使用,但如果碰到需要连接同一user,同一个ip,不同端口的情况,vscode就无法识别,如下图所示,vscode无法区分该ip下不同端口的连接ÿ…...

Elasticsearch 自定义分成器 拼音搜索 搜索自动补全 Java对接
介绍 通常用于将文档中的文本数据拆分成易于索引的词项(tokens)。有时,默认的分词器无法满足特定应用需求,这时就可以创建 自定义分词器 来实现定制化的文本分析。 自定义分词器组成 Char Filters(字符过滤器&#x…...

django-stubs模型类型检查实战:告别运行时错误的终极指南
django-stubs模型类型检查实战:告别运行时错误的终极指南 【免费下载链接】django-stubs PEP-484 stubs for Django 项目地址: https://gitcode.com/gh_mirrors/dj/django-stubs 在Django开发中,模型定义是核心环节,但传统开发模式下&…...
)
保姆级教程:用PennyLane和泰坦尼克号数据集,5分钟上手你的第一个量子分类器(VQC)
量子机器学习实战:用PennyLane构建泰坦尼克号生存预测模型 量子计算正从实验室走向实际应用,而量子机器学习作为交叉领域的前沿方向,为传统算法提供了新的可能性。本文将带您用PennyLane框架,在经典数据集上完成一次完整的量子分类…...
)
分析梳理--分子动力学模拟的常规步骤八(Gromacs)
作者,Evil Genius 每一个组学内容都很多啊,都需要花费大量的时间学习,学习的最好阶段就是学生阶段,你的导师就是你的伯乐,像我这种社会底层人员,纯纯没事干,学了有没有用真的不知道。 这一篇我们继续分子动力学,上一步我们处理配体分子得到符合Gromacs的出入文件 这里…...

米尔RK3576开发板评测:工业AI与边缘计算的性能甜点方案
1. 项目概述:当RK3576遇上米尔开发板,工业AI的新选择最近在嵌入式圈子里,瑞芯微的RK3576这颗SoC讨论热度挺高。作为一枚常年混迹在工控、边缘计算和AIoT项目里的老工程师,我对这类新平台的发布总是格外敏感。米尔电子作为国内老牌…...

终极指南:如何使用webSpoon快速构建企业级数据集成平台
终极指南:如何使用webSpoon快速构建企业级数据集成平台 【免费下载链接】pentaho-kettle webSpoon is a web-based graphical designer for Pentaho Data Integration with the same look & feel as Spoon 项目地址: https://gitcode.com/gh_mirrors/pen/pent…...

绝区零自动化终极指南:如何用一条龙工具实现全自动游戏体验
绝区零自动化终极指南:如何用一条龙工具实现全自动游戏体验 【免费下载链接】ZenlessZoneZero-OneDragon 绝区零 一条龙 | 全自动 | 自动闪避 | 自动每日 | 自动空洞 | 支持手柄 项目地址: https://gitcode.com/gh_mirrors/ze/ZenlessZoneZero-OneDragon 还在…...

现代C++中的编译期反射替代思路
现代C中的编译期反射替代思路C 长期缺乏完整标准反射能力,但工程上依然经常需要“遍历字段、生成元信息、自动序列化、自动注册”。在正式反射广泛可用之前,开发者通常通过宏、模板特化、tuple 适配和代码生成等方式实现替代方案。一种常见思路是手工提供…...

构建智能工单协同系统:Agent技术驱动研发效能提升
1. 项目概述:一个面向开发者的智能工单与任务协同系统最近在梳理团队内部的工作流时,我一直在思考一个问题:如何让代码仓库(比如 GitHub、GitLab)里的 Issues、Pull Requests 这些“待办事项”,不再只是静态…...
)
从‘点一下’到‘连一连’:Qt6中PushButton信号与槽的5种连接方式详解(含Lambda表达式实战)
从‘点一下’到‘连一连’:Qt6中PushButton信号与槽的5种连接方式详解(含Lambda表达式实战) 在Qt框架中,PushButton作为最基础的交互控件之一,其信号与槽机制是构建响应式用户界面的核心。随着Qt6的发布,信…...

3步零编程定制你的Windows系统:Windhawk终极指南
3步零编程定制你的Windows系统:Windhawk终极指南 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 想要个性化Windows界面却不懂编程ÿ…...