双向链表在系统调度、游戏、文本编辑及组态方面的应用
在编程的奇妙世界里,数据结构就像是一把把神奇的钥匙(前面我们介绍过单向链表的基础了,这里我们更进一步),能帮我们打开解决各种问题的大门。今天,咱们就来聊聊其中一把特别的钥匙——双向链表。双向链表和普通链表相比,每个节点不仅有指向下一个节点的指针,还有指向前一个节点的指针,这就好比给它装上了“前后眼”,在很多场景下都能大显身手。接下来,我们通过双向链表在系统管理、游戏、文本编辑及组态软件中的应用来展示其强大,并给出示例代码。
文章目录
- 1. 操作系统中的进程调度
- 1.1 进程调度的需求
- 1.2 双向链表的优势
- 1.3 示例代码
- 1.3.1 代码解释
- 2. 双向链表在游戏开发中的应用
- 2.1 游戏对象管理
- 2.1.1 需求背景
- 2.1.2 双向链表的优势
- 2.1.3 示例代码
- 2.1.4 代码解释
- 3. 文本编辑器中的撤销与重做功能
- 3.1 撤销与重做功能的原理
- 3.2 双向链表的应用
- 3.3 示例代码
- 代码解释
- 4. 缓存机制中的LRU缓存
- 4.1 LRU缓存的原理
- 4.2 双向链表与哈希表结合实现LRU缓存
- 4.3 示例代码
- 代码解释
- 5. 双向链表在组态软件中的应用
- 5.1 设备连接与监控
- 5.1.1 需求背景
- 5.1.2 双向链表的优势
- 5.1.3 示例代码
- 5.1.4 代码解释
- `Device` 结构体
- `DeviceList` 类
- `addDevice(int id, const std::string& type, const std::string& address)` 方法
- `removeDevice(int id)` 方法
1. 操作系统中的进程调度
1.1 进程调度的需求
同学们可以把操作系统想象成一个超大型的任务管理中心,这里有大量的进程需要被管理和调度。为了让整个系统高效运行,需要一个数据结构来存储进程的各种信息,并且要能方便地进行插入新进程、删除已完成进程以及对进程进行排序和查找等操作。这就好比一个繁忙的机场,需要一个高效的航班管理系统来安排航班的起降和调度。
1.2 双向链表的优势
双向链表在进程调度中就发挥了很大的作用。每个进程可以看作是双向链表中的一个节点,节点里存储着进程的关键信息,像进程 ID、优先级、运行状态等。由于双向链表在插入和删除节点时的时间复杂度是 O ( 1 ) O(1) O(1),这使得操作系统在创建新进程、结束进程或者调整进程优先级时能够快速完成。而且双向链表支持双向遍历,操作系统可以根据不同的调度算法,灵活地从前往后或者从后往前遍历链表,选择合适的进程来执行。
1.3 示例代码
#include <iostream>// 定义进程结构体
struct Process {int pid;int priority;Process* prev;Process* next;Process(int id, int prio) : pid(id), priority(prio), prev(nullptr), next(nullptr) {}
};// 定义双向链表类
class ProcessList {
private:Process* head;
public:ProcessList() : head(nullptr) {}// 插入新进程(按照优先级插入)void insertProcess(int pid, int priority) {Process* newProcess = new Process(pid, priority);if (!head || priority < head->priority) {newProcess->next = head;if (head) head->prev = newProcess;head = newProcess;} else {Process* current = head;while (current->next && priority >= current->next->priority) {current = current->next;}newProcess->next = current->next;newProcess->prev = current;if (current->next) current->next->prev = newProcess;current->next = newProcess;}}// 删除进程void deleteProcess(int pid) {Process* current = head;while (current && current->pid != pid) {current = current->next;}if (current) {if (current->prev) {current->prev->next = current->next;} else {head = current->next;}if (current->next) {current->next->prev = current->prev;}delete current;}}// 遍历链表void printProcesses() {Process* current = head;while (current) {std::cout << "PID: " << current->pid << ", Priority: " << current->priority << std::endl;current = current->next;}}
};
1.3.1 代码解释
- 整体构思设计:我们要模拟操作系统中的进程调度,使用双向链表来存储进程信息。通过自定义的
Process结构体表示进程节点,ProcessList类来管理这些节点,实现进程的插入、删除和遍历功能。 Process结构体:- 包含进程的基本信息
pid(进程ID)和priority(优先级)。 prev和next指针分别指向前一个和后一个进程节点,用于构建双向链表。- 构造函数
Process(int id, int prio)用于初始化进程节点。
- 包含进程的基本信息
ProcessList类:insertProcess方法:- 功能:按照进程的优先级将新进程插入到合适的位置。
- 实现思路:首先创建一个新的进程节点
newProcess。如果链表为空或者新进程的优先级比头节点的优先级高,则将新节点作为头节点。否则,遍历链表找到合适的插入位置,使得链表中的进程按照优先级从小到大排列。
deleteProcess方法:- 功能:根据进程ID删除指定的进程节点。
- 实现思路:遍历链表找到具有指定
pid的进程节点。如果找到,调整该节点前后节点的指针,将其从链表中移除,然后释放该节点的内存。
printProcesses方法:- 功能:遍历链表并打印每个进程的信息。
- 实现思路:从头节点开始,依次访问每个节点,打印其
pid和priority信息,然后移动到下一个节点,直到链表结束。
2. 双向链表在游戏开发中的应用
2.1 游戏对象管理
2.1.1 需求背景
想象一下,我们正在开发一款超酷的游戏,里面有各种各样的游戏对象,像角色、道具、怪物等等。游戏运行过程中,这些对象会不断地被创建、销毁,而且还需要对它们进行各种操作,比如移动、攻击、碰撞检测等。这时候,就需要一个高效的数据结构来管理这些游戏对象。
2.1.2 双向链表的优势
双向链表就非常适合这个场景。每个游戏对象可以作为链表中的一个节点,节点之间通过前后指针相连。这样,当我们需要添加新的游戏对象时,只需要在链表中插入一个新节点;当某个对象被销毁时,也能很方便地从链表中删除对应的节点。而且,双向链表支持双向遍历,我们可以根据需要从前往后或者从后往前遍历链表,这在进行碰撞检测等操作时非常有用。
2.1.3 示例代码
#include <iostream>
#include <string>// 定义游戏对象结构体
struct GameObject {std::string name;int x;int y;GameObject* prev;GameObject* next;GameObject(const std::string& n, int _x, int _y) : name(n), x(_x), y(_y), prev(nullptr), next(nullptr) {}
};// 定义游戏对象链表类
class GameObjectList {
private:GameObject* head;
public:GameObjectList() : head(nullptr) {}// 添加游戏对象void addGameObject(const std::string& name, int x, int y) {GameObject* newObj = new GameObject(name, x, y);if (!head) {head = newObj;} else {newObj->next = head;head->prev = newObj;head = newObj;}}// 删除游戏对象void deleteGameObject(const std::string& name) {GameObject* current = head;while (current) {if (current->name == name) {if (current->prev) {current->prev->next = current->next;} else {head = current->next;}if (current->next) {current->next->prev = current->prev;}delete current;break;}current = current->next;}}// 遍历游戏对象void printGameObjects() {GameObject* current = head;while (current) {std::cout << "Name: " << current->name << ", Position: (" << current->x << ", " << current->y << ")" << std::endl;current = current->next;}}
};
2.1.4 代码解释
| 部分 | 整体构思设计 | 实现思路 |
|---|---|---|
GameObject 结构体 | 为了表示游戏中的各种对象,我们定义了这个结构体。它包含了对象的名称和位置信息,以及用于构建双向链表的前后指针。 | 成员变量 name 存储对象的名称,x 和 y 存储对象的位置,prev 和 next 分别指向前一个和后一个节点。构造函数用于初始化这些成员。 |
GameObjectList 类 | 这个类负责管理游戏对象链表,提供添加、删除和遍历游戏对象的功能。 | |
addGameObject 方法 | 首先创建一个新的游戏对象节点。如果链表为空,将新节点作为头节点;否则,将新节点插入到链表头部,更新前后指针。 | |
deleteGameObject 方法 | 遍历链表,找到名称匹配的游戏对象 |
3. 文本编辑器中的撤销与重做功能
3.1 撤销与重做功能的原理
在文本编辑器中,撤销与重做功能允许用户回退到之前的编辑状态或恢复之前撤销的操作。这需要一种数据结构来记录用户的每一步操作,并且能够方便地向前和向后追溯这些操作。
3.2 双向链表的应用
双向链表可以很好地实现这一功能。每一次用户的编辑操作(如插入字符、删除字符、修改文本等)都可以被记录为双向链表中的一个节点。节点中包含操作的详细信息,如操作类型、操作位置、操作内容等。当用户执行撤销操作时,程序可以沿着双向链表的前驱指针向前追溯到上一个操作状态,并还原相应的文本状态;当用户执行重做操作时,程序可以沿着双向链表的后继指针向后追溯到下一个操作状态,恢复之前撤销的操作。
3.3 示例代码
#include <iostream>
#include <string>// 定义操作结构体
struct EditOperation {std::string type;int position;std::string content;EditOperation* prev;EditOperation* next;EditOperation(const std::string& t, int pos, const std::string& c): type(t), position(pos), content(c), prev(nullptr), next(nullptr) {}
};// 定义操作链表类
class EditHistory {
private:EditOperation* head;EditOperation* current;
public:EditHistory() : head(nullptr), current(nullptr) {}// 添加新操作void addOperation(const std::string& type, int position, const std::string& content) {EditOperation* newOp = new EditOperation(type, position, content);if (!head) {head = newOp;current = newOp;} else {newOp->prev = current;current->next = newOp;current = newOp;}}// 撤销操作void undo() {if (current && current->prev) {current = current->prev;// 这里根据操作类型实现具体的文本还原逻辑std::cout << "Undo: " << current->type << " at position " << current->position << std::endl;}}// 重做操作void redo() {if (current && current->next) {current = current->next;// 这里根据操作类型实现具体的文本恢复逻辑std::cout << "Redo: " << current->type << " at position " << current->position << std::endl;}}
};
代码解释
- 整体构思设计:为了实现文本编辑器的撤销与重做功能,使用双向链表来记录用户的编辑操作。通过
EditOperation结构体表示每个编辑操作节点,EditHistory类来管理这些节点,实现操作的添加、撤销和重做功能。 EditOperation结构体:- 包含编辑操作的信息,如
type(操作类型,如插入、删除等)、position(操作位置)和content(操作内容)。 prev和next指针用于构建双向链表。- 构造函数
EditOperation(const std::string& t, int pos, const std::string& c)用于初始化操作节点。
- 包含编辑操作的信息,如
EditHistory类:addOperation方法:- 功能:添加新的编辑操作到链表中。
- 实现思路:创建一个新的操作节点
newOp。如果链表为空,将其作为头节点,并将当前操作指针current指向它。否则,将新节点添加到链表尾部,并更新current指针。
undo方法:- 功能:撤销上一次操作。
- 实现思路:如果当前操作指针
current不为空且有前一个操作节点,将current指针移动到前一个节点,并输出撤销操作的信息。在实际应用中,还需要根据操作类型实现具体的文本还原逻辑。
redo方法:- 功能:重做被撤销的操作。
- 实现思路:如果当前操作指针
current不为空且有下一个操作节点,将current指针移动到下一个节点,并输出重做操作的信息。同样,在实际应用中需要根据操作类型实现具体的文本恢复逻辑。
4. 缓存机制中的LRU缓存
4.1 LRU缓存的原理
LRU(Least Recently Used)缓存是一种常用的缓存淘汰策略,它的原理是当缓存满时,优先淘汰最近最少使用的元素。这需要一种数据结构来记录元素的访问顺序,并且能够快速地找到最近最少使用的元素。
4.2 双向链表与哈希表结合实现LRU缓存
双向链表与哈希表结合可以高效地实现LRU缓存。双向链表用于维护元素的访问顺序,最近访问的元素放在链表头部,最近最少使用的元素放在链表尾部。哈希表用于快速定位双向链表中的节点,这样在访问元素时,我们可以通过哈希表快速找到该元素在双向链表中的位置,然后将其移动到链表头部,表示该元素被最近访问过。当缓存满时,直接删除链表尾部的节点即可。
4.3 示例代码
#include <iostream>
#include <unordered_map>// 定义缓存节点结构体
struct CacheNode {int key;int value;CacheNode* prev;CacheNode* next;CacheNode(int k, int v) : key(k), value(v), prev(nullptr), next(nullptr) {}
};// 定义LRU缓存类
class LRUCache {
private:int capacity;std::unordered_map<int, CacheNode*> cache;CacheNode* head;CacheNode* tail;public:LRUCache(int cap) : capacity(cap), head(nullptr), tail(nullptr) {}// 获取元素int get(int key) {if (cache.find(key)!= cache.end()) {CacheNode* node = cache[key];moveToFront(node);return node->value;}return -1;}// 插入元素void put(int key, int value) {if (cache.find(key)!= cache.end()) {CacheNode* node = cache[key];node->value = value;moveToFront(node);} else {CacheNode* newNode = new CacheNode(key, value);cache[key] = newNode;if (!head) {head = newNode;tail = newNode;} else {addToFront(newNode);if (cache.size() > capacity) {removeTail();}}}}private:// 将节点移动到链表头部void moveToFront(CacheNode* node) {if (node == head) return;if (node == tail) {tail = node->prev;tail->next = nullptr;} else {node->prev->next = node->next;node->next->prev = node->prev;}addToFront(node);}// 将节点添加到链表头部void addToFront(CacheNode* node) {node->next = head;node->prev = nullptr;if (head) head->prev = node;head = node;if (!tail) tail = head;}// 删除链表尾部节点void removeTail() {if (!tail) return;CacheNode* toDelete = tail;if (tail == head) {head = nullptr;tail = nullptr;} else {tail = tail->prev;tail->next = nullptr;}cache.erase(toDelete->key);delete toDelete;}
};
代码解释
- 整体构思设计:为了实现 LRU 缓存,我们结合使用双向链表和哈希表。双向链表用于维护元素的访问顺序,哈希表用于快速查找元素。通过
CacheNode结构体表示缓存节点,LRUCache类来管理缓存的插入、获取和淘汰操作。 CacheNode结构体:- 包含缓存元素的
key和value。 prev和next指针用于构建双向链表。- 构造函数
CacheNode(int k, int v)用于初始化缓存节点。
- 包含缓存元素的
LRUCache类:get方法:- 功能:根据
key获取缓存中的元素。 - 实现思路:首先在哈希表中查找
key。如果找到,将对应的节点移动到链表头部(表示该元素最近被访问),然后返回节点的值。如果未找到,返回 -1。
- 功能:根据
put方法:- 功能:插入或更新缓存元素。
- 实现思路:如果
key已经存在于缓存中,更新节点的值并将其移动到链表头部。如果key不存在,创建一个新的节点,将其添加到链表头部,并插入到哈希表中。如果缓存已满,删除链表尾部的节点(最近最少使用的元素)。
moveToFront方法:- 功能:将指定节点移动到链表头部。
- 实现思路:如果节点已经是头节点,直接返回。如果节点是尾节点,更新尾节点指针。否则,调整节点前后节点的指针,将其从原位置移除,然后调用
addToFront方法将其添加到链表头部。
addToFront方法:- 功能:将节点添加到链表头部。
- 实现思路:更新节点的
next指针指向原头节点,原头节点的prev指针指向该节点,然后将头节点指针更新为该节点。如果链表原本为空,同时更新尾节点指针。
removeTail方法:
5. 双向链表在组态软件中的应用
5.1 设备连接与监控
5.1.1 需求背景
组态软件在工业自动化领域可是个得力助手,它要负责监控和控制大量的工业设备。想象一下,一个大型工厂里有各种各样的机器设备,像传感器、电机、阀门等等,这些设备都需要和组态软件建立连接,软件要实时获取它们的状态信息,比如设备是否正常运行、当前的温度、压力等参数。同时,还得能随时对设备进行控制,比如启动、停止、调节参数等。这就需要一个高效的数据结构来管理这些设备的连接信息。
5.1.2 双向链表的优势
双向链表非常适合用于管理设备连接信息。每个设备可以看作是双向链表中的一个节点,节点里存储着设备的关键信息,如设备 ID、设备类型、通信地址、连接状态等。当有新设备接入系统时,我们可以方便地在链表中插入一个新节点;当某个设备出现故障或者断开连接时,也能快速地从链表中删除对应的节点。而且,双向链表支持双向遍历,我们可以根据需要从前往后或者从后往前遍历链表,这在进行设备状态查询、故障排查等操作时非常有用。
5.1.3 示例代码
#include <iostream>
#include <string>// 定义设备结构体
struct Device {int deviceId;std::string deviceType;std::string communicationAddress;bool isConnected;Device* prev;Device* next;Device(int id, const std::string& type, const std::string& address): deviceId(id), deviceType(type), communicationAddress(address), isConnected(false), prev(nullptr), next(nullptr) {}
};// 定义设备链表类
class DeviceList {
private:Device* head;
public:DeviceList() : head(nullptr) {}// 添加设备void addDevice(int id, const std::string& type, const std::string& address) {Device* newDevice = new Device(id, type, address);if (!head) {head = newDevice;} else {newDevice->next = head;head->prev = newDevice;head = newDevice;}}// 删除设备void removeDevice(int id) {Device* current = head;while (current) {if (current->deviceId == id) {if (current->prev) {current->prev->next = current->next;} else {head = current->next;}if (current->next) {current->next->prev = current->prev;}delete current;break;}current = current->next;}}// 遍历设备列表void printDevices() {Device* current = head;while (current) {std::cout << "Device ID: " << current->deviceId<< ", Type: " << current->deviceType<< ", Address: " << current->communicationAddress<< ", Connected: " << (current->isConnected ? "Yes" : "No") << std::endl;current = current->next;}}// 查找设备Device* findDevice(int id) {Device* current = head;while (current) {if (current->deviceId == id) {return current;}current = current->next;}return nullptr;}
};
5.1.4 代码解释
Device 结构体
- 整体构思设计:在这个组态软件设备管理的场景中,我们需要一个数据结构来代表每一个具体的工业设备。
Device结构体就承担了这个角色,它将设备的关键属性和用于构建双向链表的指针封装在一起,使得每个设备节点可以方便地连接到链表中,便于对设备进行统一管理。 - 各成员变量说明:
int deviceId:这是设备的唯一标识符,就像设备的身份证号码一样,在整个系统中每个设备的deviceId都是独一无二的。通过这个 ID,我们可以准确地定位和区分不同的设备,方便进行设备的查找、删除等操作。std::string deviceType:用于记录设备的类型,比如传感器、电机、阀门等。不同类型的设备可能具有不同的功能和操作方式,这个属性可以帮助我们在处理设备时进行分类和区分。std::string communicationAddress:表示设备的通信地址,组态软件通过这个地址与设备进行通信,获取设备的状态信息或者向设备发送控制指令。它可以是 IP 地址、串口地址等具体的通信标识。bool isConnected:用于标记设备的连接状态,true表示设备已连接到系统,false表示设备未连接。通过这个状态,我们可以快速了解设备的工作情况,及时发现设备连接异常。Device* prev和Device* next:这两个指针是构建双向链表的关键。prev指针指向前一个设备节点,next指针指向后一个设备节点。通过这两个指针,我们可以在链表中方便地进行双向遍历,从一个节点快速访问到它的前一个或后一个节点。
- 构造函数
Device(int id, const std::string& type, const std::string& address):该构造函数用于初始化Device结构体的各个成员变量。当创建一个新的设备节点时,我们需要传入设备的 ID、类型和通信地址,构造函数会将这些值赋给相应的成员变量,并将isConnected初始化为false,表示设备初始状态为未连接,同时将prev和next指针初始化为nullptr,表示该节点暂时没有前后连接的节点。
DeviceList 类
- 整体构思设计:这个类是对设备链表的管理类,它封装了对设备链表的各种操作,如添加设备、删除设备、遍历设备列表和查找设备等。通过这个类,我们可以方便地对整个设备链表进行统一管理,而不需要直接操作链表节点的指针,提高了代码的可读性和可维护性。
- 成员变量
Device* head:这是一个指向链表头节点的指针,它是整个设备链表的入口。通过head指针,我们可以访问链表中的第一个设备节点,进而遍历整个链表。当链表为空时,head指针为nullptr。 - 构造函数
DeviceList():在创建DeviceList对象时,该构造函数会将head指针初始化为nullptr,表示此时设备链表为空,没有任何设备节点。
addDevice(int id, const std::string& type, const std::string& address) 方法
- 功能设计:该方法用于向设备链表中添加一个新的设备节点。
- 实现思路:
- 首先,根据传入的设备 ID、类型和通信地址创建一个新的
Device对象newDevice。 - 然后判断链表是否为空,即检查
head指针是否为nullptr。如果链表为空,说明这是第一个添加的设备节点,直接将head指针指向newDevice。 - 如果链表不为空,将新节点插入到链表的头部。具体操作是将
newDevice的next指针指向当前的头节点head,同时将当前头节点head的prev指针指向newDevice,最后更新head指针为newDevice,这样新节点就成为了新的头节点。
- 首先,根据传入的设备 ID、类型和通信地址创建一个新的
removeDevice(int id) 方法
- 功能设计:该方法用于从设备链表中删除指定 ID 的设备节点。
- 实现思路:
- 初始化一个指针
current指向链表的头节点head,从链表的第一个节点开始遍历。
- 初始化一个指针
相关文章:

双向链表在系统调度、游戏、文本编辑及组态方面的应用
在编程的奇妙世界里,数据结构就像是一把把神奇的钥匙(前面我们介绍过单向链表的基础了,这里我们更进一步),能帮我们打开解决各种问题的大门。今天,咱们就来聊聊其中一把特别的钥匙——双向链表。双向链表和…...

实践网络安全:常见威胁与应对策略详解
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 引言 在数字化转型的浪潮中,网络安全的重要性已达到前所未有的高度。无论是个人用户、企业,还是政府机构…...

关于2024年
关于2024年 十分钟前我从床上爬起来,坐在电脑面前先后听了《黄金时代》——声音碎片和《Song F》——达达两首歌,我觉得躺着有些无聊,又或者除夕夜的晚上躺着让我觉得有些不适,我觉得自己应该爬起来,爬起来记录一下我…...
Hive:Hive Shell技巧
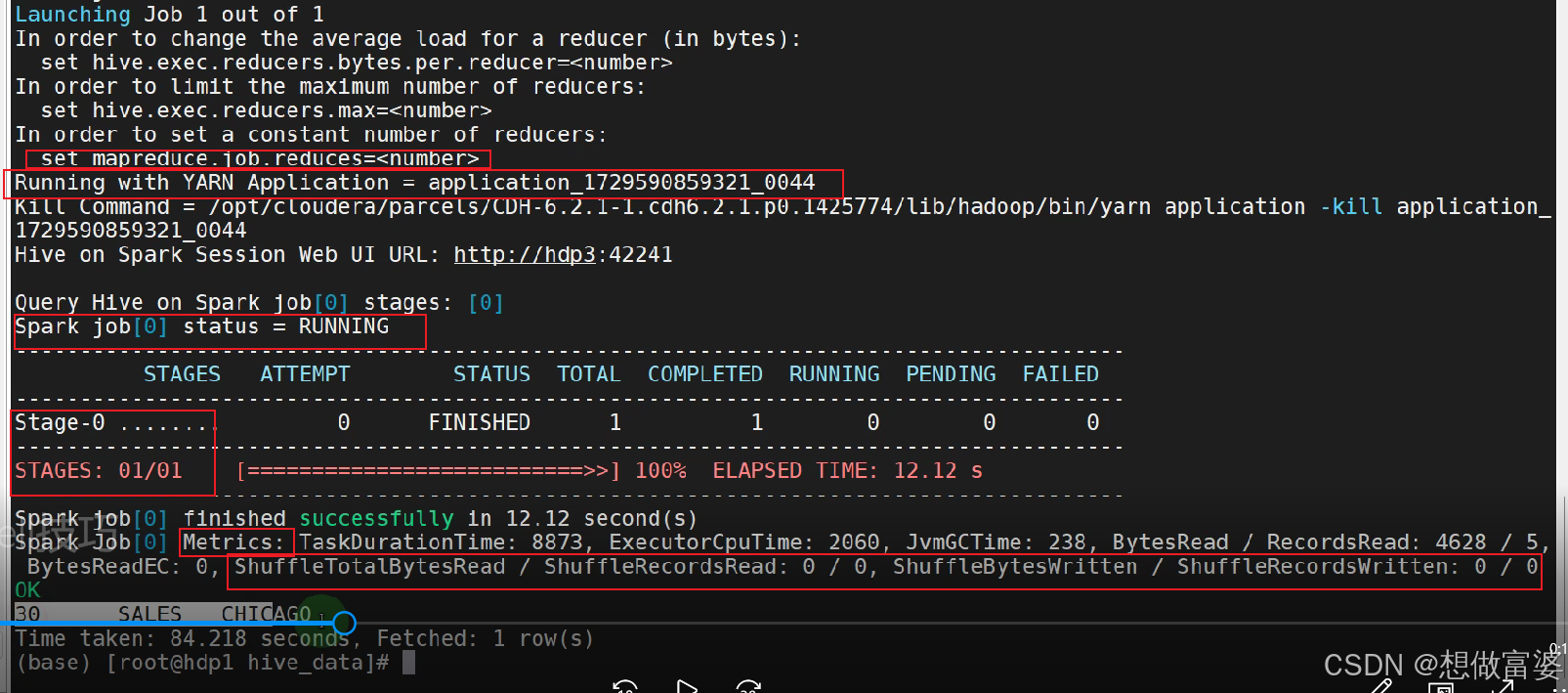
在终端命令窗口不能直接执行select,creat等HQL命令,需要先进入hive之后才能执行,比较麻烦,但是如果使用Hive Shell就可以直接执行 在终端只执行一次Hive命令 -e 参数, "execute"(执行),使用-e参数后会在执行完Hive的命令后退出Hive 使用场景:…...
Markdown Viewer 浏览器, vscode
使用VS Code插件打造完美的MarkDown编辑器(插件安装、插件配置、markdown语法)_vscode markdown-CSDN博客 右键 .md 文件,选择打开 方式 (安装一些markdown的插件) vscode如何预览markdown文件 | Fromidea GitCode - 全球开发者…...
快速分析LabVIEW主要特征进行判断
在LabVIEW中,快速分析程序特征进行判断是提升开发效率和减少调试时间的重要技巧。本文将介绍如何高效地识别和分析程序的关键特征,从而帮助开发者在编写和优化程序时做出及时的判断,避免不必要的错误。 数据流和并行性分析 LabVIEW的图形…...
【Super Tilemap Editor使用详解】(十五):从 TMX 文件导入地图(Importing from TMX files)
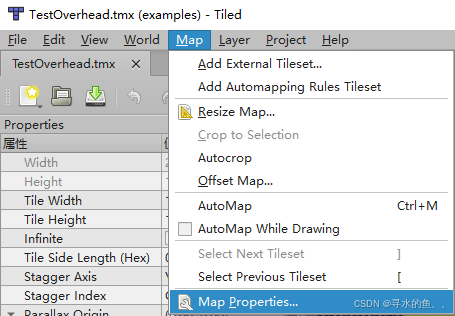
Super Tilemap Editor 支持从 TMX 文件(Tiled Map Editor 的文件格式)导入图块地图。通过导入 TMX 文件,你可以将 Tiled 中设计的地图快速转换为 Unity 中的图块地图,并自动创建图块地图组(Tilemap Group)。以下是详细的导入步骤和准备工作。 一、导入前的准备工作 在导…...
--响应式编程实现详解)
JavaScript系列(45)--响应式编程实现详解
JavaScript响应式编程实现详解 🔄 今天,让我们深入探讨JavaScript的响应式编程实现。响应式编程是一种基于数据流和变化传播的编程范式,它使我们能够以声明式的方式处理异步数据流。 响应式编程基础概念 🌟 💡 小知识…...

Lustre Core 语法 - 布尔表达式
Lustre v6 中的 Lustre Core 部分支持的表达式种类中,支持布尔表达式。相关的表达式包括and, or, xor, not, #, nor。 相应的文法定义为 Expression :: not Expression| Expression and Expression| Expression or Expression | Expression xor Expression | # (…...
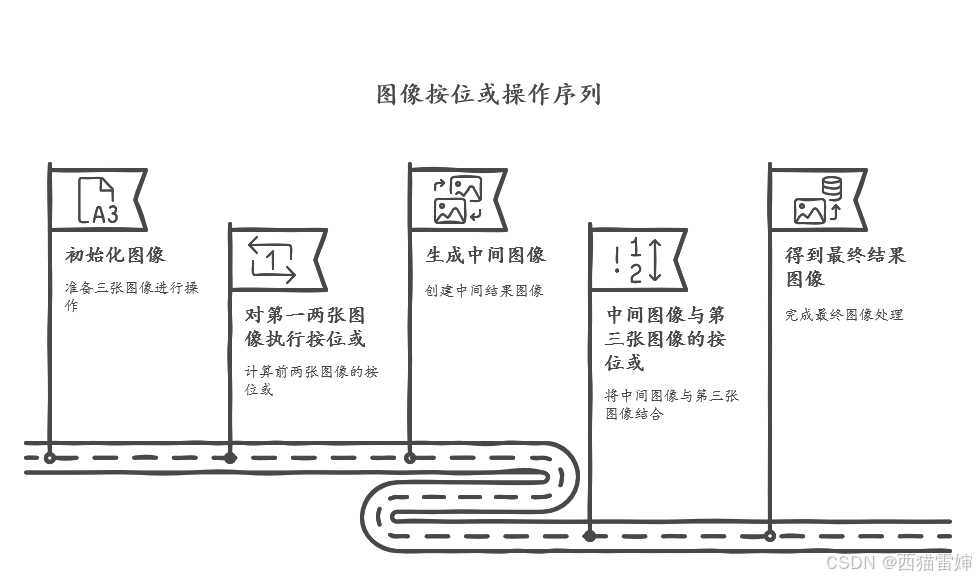
python学opencv|读取图像(四十六)使用cv2.bitwise_or()函数实现图像按位或运算
【0】基础定义 按位与运算:全1取1,其余取0。按位或运算:全0取0,其余取1。 【1】引言 前序学习进程中,已经对图像按位与计算进行了详细探究,相关文章链接如下: python学opencv|读取图像&…...
C# 添加、替换、提取、或删除Excel中的图片
在Excel中插入与数据相关的图片,能将关键数据或信息以更直观的方式呈现出来,使文档更加美观。此外,对于已有图片,你有事可能需要更新图片以确保信息的准确性,或者将Excel 中的图片单独保存,用于资料归档、备…...

工作总结:压测篇
前言 压测是测试需要会的一项技能,作为开发,有点时候也要会一点压测。也是被逼着现学现卖的。 一、压测是什么,以及压测工具的选择 压测,即压力测试,是一种性能测试手段,通过模拟大量用户同时访问系统&am…...

11JavaWeb——SpringBootWeb案例02
前面我们已经实现了员工信息的条件分页查询以及删除操作。 关于员工管理的功能,还有两个需要实现: 新增员工 修改员工 首先我们先完成"新增员工"的功能开发,再完成"修改员工"的功能开发。而在"新增员工"中…...
vs2022+tesseract ocr识别中英文 编译好的库下载
测试图片 效果 编译其实挺麻烦的,可参考:在Windows上用Visual Studio编译Tesseract_windows编译tesseract-CSDN博客 #include "baseapi.h" #include "allheaders.h" #include <iostream> #include <fstream> // 用于文…...

状态模式——C++实现
目录 1. 状态模式简介 2. 代码示例 3. 单例状态对象 4. 状态模式与策略模式的辨析 1. 状态模式简介 状态模式是一种行为型模式。 状态模式的定义:状态模式允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类。 通俗的说就是一个对象…...
)
3.观察者模式(Observer)
组件协作模式 现代软件专业分工之后的第一个结果是 “框架与应用程序的划分”,“组件协作” 模式通过晚期绑定,来实现框架与应用程序直接的松耦合,是二者之间协作时常用的模式 典型模式 Template Method Strategy Observer /Event 动机(M…...

Kotlin判空辅助工具
1)?.操作符 //执行逻辑 if (person ! null) {person.doSomething() } //表达式 person?.doSomething() 2)?:操作符 //执行逻辑 val c if (a ! null) {a } else {b } //表达式 val c a ?: b 3)!!表达式 var message: String? &qu…...
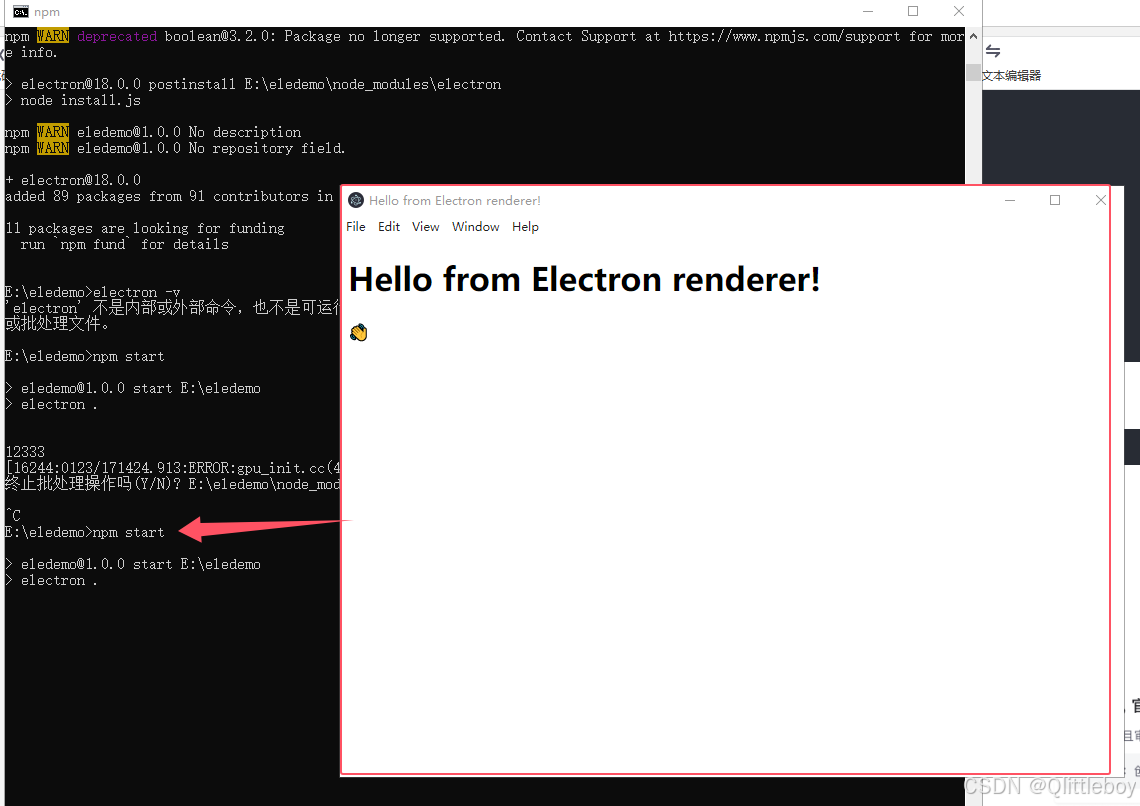
Electron学习笔记,安装环境(1)
1、支持win7的Electron 的版本是18,这里node.js用的是14版本(node-v14.21.3-x86.msi)云盘有安装包 Electron 18.x (截至2023年仍在维护中): Chromium: 96 Node.js: 14.17.0 2、安装node环境,node-v14.21.3-x86.msi双击运行选择安…...

将 OneLake 数据索引到 Elasticsearch - 第 1 部分
作者:来自 Elastic Gustavo Llermaly 学习配置 OneLake,使用 Python 消费数据并在 Elasticsearch 中索引文档,然后运行语义搜索。 OneLake 是一款工具,可让你连接到不同的 Microsoft 数据源,例如 Power BI、Data Activ…...

【C++】STL介绍 + string类使用介绍 + 模拟实现string类
目录 前言 一、STL简介 二、string类 1.为什么学习string类 2.标准库中的string类 3.auto和范围for 4.迭代器 5.string类的常用接口说明 三、模拟实现 string类 前言 本文带大家入坑STL,学习第一个容器string。 一、STL简介 在学习C数据结构和算法前,我…...

ARM PMU性能监控单元原理与编程实践
1. ARM PMU性能监控基础架构解析 性能监控单元(Performance Monitoring Unit, PMU)是现代处理器微架构中的关键组件,它通过硬件计数器实现对处理器运行时行为的精确测量。在ARMv8/v9架构中,PMU的设计遵循了高度模块化和可扩展的原则,能够支持…...
)
ElevenLabs泰米尔文TTS接入全链路详解:从API密钥配置、音色微调到低延迟流式响应(附3个避坑代码片段)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs泰米尔文TTS接入全链路详解:从API密钥配置、音色微调到低延迟流式响应(附3个避坑代码片段) ElevenLabs 自 2024 年起正式支持泰米尔语(ta-IN&a…...

MySQL复合查询与内外连接
1:笛卡尔积1:什么是笛卡尔积笛卡尔积就是两张表所有记录的所有可能组合。举个最简单的例子:表 A 有 2 条记录:[苹果,香蕉]表 B 有 3 条记录:[红色,黄色,绿色]它们的笛卡尔积就是 236…...

计算机光标自动化控制:从模拟点击到智能交互的技术实现与应用
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Computer-cursor-tech-support”。初看这个标题,你可能会有点摸不着头脑:电脑光标和技术支持,这两者是怎么联系到一起的?是开发了一个新的光标样式&am…...

该不该现在买房?AI浪潮下,你的房贷是资产还是负债?
该不该现在买房?AI浪潮下,你的房贷是资产还是负债? 开篇:一个普通家庭的决策困境 深夜,东莞某小区的灯光次第熄灭。你刚刚哄睡一岁半的孩子,打开手机看到甲骨文最新一轮裁员的新闻,又瞥了一眼房…...

为内部工具集成AI能力时选择Taotoken作为统一接口层
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成AI能力时选择Taotoken作为统一接口层 当企业开发团队着手为多个内部系统,例如客户关系管理(…...

开源AI智能体QClaw-Mimic:用个人数据微调大模型打造专属数字分身
1. 项目概述:一个能“模仿”你的开源智能体最近在GitHub上看到一个挺有意思的项目,叫QClaw-Mimic。光看名字,Mimic(模仿)这个词就挺抓人的。点进去一看,果然,这是一个旨在通过分析你的历史对话数…...

OpenRGB:一站式开源RGB灯光控制神器,彻底摆脱厂商软件束缚!
OpenRGB:一站式开源RGB灯光控制神器,彻底摆脱厂商软件束缚! 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/Calc…...
)
别再只盯着PWM了!手把手教你为你的Arduino项目选择合适的DCDC调制方式(PFM/PWM/Burst Mode全解析)
别再只盯着PWM了!手把手教你为你的Arduino项目选择合适的DCDC调制方式(PFM/PWM/Burst Mode全解析) 当你为Arduino项目挑选电源模块时,是否曾被数据手册上PWM、PFM、Burst Mode这些术语搞得一头雾水?我曾在一个低功耗气…...

DockDoor终极指南:快速掌握macOS窗口预览与高效切换
DockDoor终极指南:快速掌握macOS窗口预览与高效切换 【免费下载链接】DockDoor Window peeking, alt-tab and other enhancements for macOS 项目地址: https://gitcode.com/gh_mirrors/do/DockDoor 还在为macOS上繁琐的窗口切换而烦恼吗?DockDoo…...